
审计知识图谱构建与推理在审计风险评估中的应用研究*
2023-03-21 02:22刘一鸣单鸿涛张高煜张勤涛袁先智
计算机时代 2023年3期
刘一鸣,单鸿涛,张高煜,张勤涛,袁先智
(1.上海工程技术大学,上海 201620;2.上海立信会计金融学院;3.上海机电股份有限公司(资产财务部);4.中山大学管理学院)
0 引言
传统的人工审计模式存在着流程复杂、审计广度有限等缺陷,面对大数据下信息量庞大、离散程度高的财务数据,就会产生处理数据耗时长、信息披露不全面等后果,难以支持实体经济。因此,有效地运用大数据背景下带来的海量数据,通过智能化的推理方法深度挖掘隐藏信息,成为了审计人员重点关注的问题。
本文基于自然语言处理和审计合规知识,提出并实现了审计知识图谱构建与推理的新型体系框架辅助审计风险评估,并通过案例公司——WD 医疗,从业务层面具体分析知识图谱构建与推理如何赋能审计风险评估程序。
本文的创新之处在于:目前审计领域尚未有学者提出普适性的审计语义网络定义,也未有资料提及审计知识图谱与规则推理的整个实现流程。本文在这几方面都提出了创新的解决方案与算法。
1 国内外文献综述
在智能审计研究领域,随着数据挖掘概念的提出与普及,有学者设计了3种数据挖掘方法,对于理论知识和方法实现详尽描述的同时,尝试将其运用于实际审计工作之中(McNamee D.and G,1998)[1]。有学者提出了持续审计智能服务(CAIaaS)的新架构,可以帮助审计师充分利用智能技术进行工作(Dai J,Vasarhelyi M A,2020)[2];另有学者提供了用于智能审计的智能检测引擎,自动实现对合约等模块的验证(Chakinam S,Tadepalli B,Pallapolu K C,2021)[3]。
国内对智能审计的研究起步较晚,但已有诸多学者专家进行了理论研究与实践。有学者针对知识审计提出研究内容与知识图谱、文献计量综合分析的方法,强调借助其他领域的研究成果补充审计理论知识,完善整个审计体系(孟志华,关瑞娣,2017)[4]。还有学者在医保审计方向进行相关研究与调查,开创性将医保审计知识图谱实战投入到审计实务之中,解决客观存有的实际问题,发挥了风险识别与监督作用(樊世昊,2018)[5];近两年,有学者提出关于知识图谱的未来发展方向主要包括时空多元关系抽取,动态知识的获取与表示,融合先验知识的实体链接等,基于图数据的混合存储,构建多模态知识图谱(杭婷婷,2021)[6]。
研究评述:在大数据环境下,诸多学者已关注到大数据对于传统审计带来的各种变化及影响,也逐渐关注到知识图谱,但对于将知识图谱与审计的跨学科研究内容成果匮乏,真正搭建审计业务知识图谱解析功能模块的文献较少。基于此,本文将从知识图谱构建与推理出发,对其在审计风险评估中的应用进行具体阐述。
2 审计知识图谱系统构建
审计知识图谱构建包含九个模块,模块间关系及系统设计架构如图1所示。

图1 审计知识图谱构建的模块及架构
2.1 基于财务和非财务指标的审计语义网络定义
要构建财务审计的语义网络,首先要对审计实体、关系以及属性进行定义。
2.1.1 审计实体
从原始数据集中,抽取出的独立存在的实体,定义为审计实体,分为财务实体与非财务实体。其中,财务实体依据财政部颁发的《企业会计准则应用指南》中的会计科目名称直接定义,例如库存现金、银行存款、应收票据等;对于非财务实体,由于标准化程度相对较低,所以需要根据搜集的各类企业信息进行归纳整理得出,数据来源包括企业的合同、产权证、凭证、票据、报关单等等,多为非结构化数据。
2.1.2 审计关系
审计实体间的语义关系定义为审计关系,包括数据间及数据与属性间的关系。
财务与财务数据之间的关系:主要形式为会计科目间的上下级关系,可以直接从被审计单位提供的内部数据中“科目名称”项作为实体和关系进行提取。
非财务与非财务数据之间的关系:即与经济活动相关联的非财务数据间的关系。包括公司的高管任免情况、关联交易情况等等,这类信息通常是非结构化的。
财务与非财务数据之间的关系:即财务数据与实际经营活动中产生的信息之间的关系。有两种挖掘方法:第一种根据被审计单位财务软件中存储的科目信息、凭证信息、摘要等抽取相关联的内容;第二种是根据文本信息进行关系挖掘。
2.1.3 审计实体的属性
审计实体的属性即被审计单位数据的具体信息,譬如固定资产科目中具体一项资产的编号、原值、折旧情况、购置日期等,作为对于实体的属性的补充。
2.2 数据获取
数据获取阶段的流程如图2所示。获取原始数据后,整合并建立三个数据库:被审计单位原始数据库、审计词典及法律法规库。审计词典库包含了会计和审计术语,作为财经文本实体关系抽取分词所需要的词典备用;法律法规库包含了上市公司遵循的会计和审计法律法规,作为审计规则库构建所需要的事实备用。

图2 数据获取模块及流程结构
2.3 数据预处理
由于大数据具有4V(即容量大、多样性、价值低、速度快)的特性,难以直接作为审计数据,因此需要进行列清洗、转化、标注等步骤,流程如图3所示。

图3 数据预处理模块及流程结构
2.4 审计实体抽取
由于审计实体较长、专业词汇复杂、文本定位困难等问题,给信息抽取带来了极大难度。如图4所示,本文的实体抽取通过Bert-BiLSTM-CRF模型实现。

图4 Bert-BiLSTM-CRF模型
Bert-BiLSTM-CRF 模型共分为三层,第一层为Bert 层,Bert 预训练模型运用了双向Transformer 的编码器,引入了自注意力机制以及位置编码表示。
第二层为BiLSTM(长短时记忆神经网络)层,在Bert 模型以及LSTM 基础上以句子为单位建模,解决了只能获取单向信息的问题,自动提取句子特征。
第三层为CRF(条件随机场)层,BiLSTM 层仅考量了上下文信息,缺乏对于标注序列间依赖信息的考虑。CRF可以为标签填写一些额外的约束予以补充。
2.5 审计关系抽取
关系抽取面向非结构化文本数据,通过抽取实体间的语义关系来组成结构化知识,本模块尝试使用依存句法分析和PCNN 神经网络实现,其在CNN 的基础上,对卷积层的输出进行优化,同时运用分段池化取代CNN 神经网络模型中的最大值池化操作。PCNN的分段池化是指以句中定位的两个实体的位置分为三个片段,对这三个独立的片段分别进行池化操作,提炼句中具体精细的语义特征。
在为PCNN构建数据集时,实体基于2.4中的实体抽取结果,关系基于依存句法分析结合关系抽取的规则对句中实体成分和关系成分的抽取,包含句子、关系、实体1、实体1 在句中的位置、实体2、实体2 在句中的位置。
2.6 审计规则库构建
该模块运用一阶谓词逻辑表示法构建审计规则,格式为:if(如果)……,then(则)……。规则中的if 部分包含了一个或多个前置条件,作为决策树的规则划分,then部分表示如果满足前置所有的前置条件(即各项指标),则根据前置条件可以推断出存在某一风险事项(即审计解释)。
2.7 审计实体关系统一及知识存储
在审计报告中“WD 医疗”、“WD 医疗科技股份有限公司”、“本公司”等财经文本中抽取出来的实体代表着相同的含义,但却通过简称、全称、口语化称呼抽取成为了三个不同的实体,因此需要进行统一。
知识图谱构建基础是由实体间的关系组合的“图”结构,因此在完成实体关系统一后采用适合语义网络的三元组资源描述框架表示并完成知识存储。
2.8 知识图谱生成及展示
基于导入Neo4j 图数据库中的实体关系三元组,构建与被审计单位相关的知识图谱。如图5 所示,以银行存款科目图谱为例,将银行账号作为节点,属性值包括开户银行、账户性质、币种、期初原币金额、期初本位币金额、本期增加额、本期减少额、期末原币金额、汇率、期末本位币金额等10余项信息。
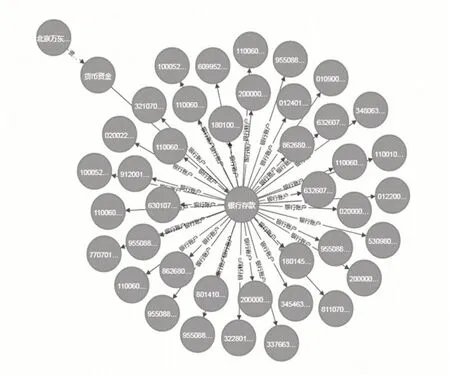
图5 WD医疗银行存款科目信息图谱
2.9 知识图谱推理
基于构建的知识图谱和审计规则库,知识图谱推理借助决策树和随机森林模型实现。由于审计决策树只能推理评判某一组维度的数据,而对于审计业务而言是由多维度的数据组成的,因此还需要通过随机森林模型进行全局补充。
3 知识图谱构建与推理应用分析
本文提出的知识图谱构建与推理开源代码在https://github.com/LaffitteZ。
基于第2 节图谱构建方法,对WD 医疗知识图谱构建与推理简要说明:
⑴研读审计法律法规及规范性文件,结合专家经验构建审计规则库;
⑵将采集的数据中结构化部分直接转换成三元组格式,非结构化数据则通过语句切分和序列标注,使用Bert-BiLSTM-CRF 模型进行实体抽取,使用依存句法分析+PCNN 模型进行关系抽取后转存,构建WD医疗知识图谱;
⑶根据企业规章制度以及会计审计准则,列示重点审计项目;
⑷以Neo4j中字段要求将审计规则进行列示;
⑸与财务负责人进行交流,了解字段存在位置,搞清对应名称关系;
⑹根据审计规则和交流结果设计校验逻辑,即图谱推理的过程,确定哪些情况属于会提示存在风险点的异常情况;
⑺对数据量进行把控,因为整个系统数据量巨大,故测试阶段首先以某一审计项目中的一项财务科目为例运行,以保证不会影响审计进程;
⑻从知识图谱中提取数据,从审计规则库中提取规则,进行图谱推理;
⑼对推理中发现的审计风险点在知识图谱中加以标注并提取;
⑽对于自动化识别评估的风险项追加执行审计程序予以核实。对于可以确认的项目修改后进行再评估,对于无法确认的则判定为风险事项。
以货币资金审计为例,实务中从法律法规、权限管理、资产安全、现金盘点、账务处理、银行账户余额及汇兑、对账单及余额调节表核对、开户银行查验、银行存款函证、发生额分析以及双向核对等10个风险点入手,基于知识图谱做智能推理。以法律法规项目为例,如果企业受到行政处罚或者刑事处罚,且处罚原因是货币资金造假,则说明存在违反法律法规风险,决策树如图6所示。

图6 审计风险点推理决策树
基于图谱推理货币资金审计的潜在风险点,综合判断10个决策树并进行融合,最终得出货币资金审计存在审计风险的评估结论。实现流程如图7所示。

图7 货币资金审计的随机森林模型
函证程序发函时发现,存在一项地址不一致的情况,发函地址为财神广场6 层C14 室,工商查询为金磊商厦6 层C14 室,是存在风险的。以地址核对举例来看,通过账户属性推理得出风险,并标注的结果如图8所示。

图8 地址核对风险标识
4 结束语
本文提出了一套基于知识图谱构建与推理的智能审计方法,以WD 医疗科技股份有限公司为案例公司进行应用研究。采集异构数据并进行预处理后,在实体抽取阶段运用BERT-BiLSTM-CRF 模型对审计财经文本进行实体抽取,结果准确率为84.94%,在关系抽取阶段通过依存句法分析和PCNN神经网络模型训练结果准确率为84.27%。通过知识统一和存储将抽取结果导入Neo4j 后构建审计知识图谱,结合设计的审计规则库,运用了决策树与随机森林模型将规则推理融入审计风险评估程序,辅助审计人员更有针对性地聚焦潜在风险的同时,从理论和实践方面为智能审计工作的开展提供参考与借鉴。
猜你喜欢
少先队活动(2020年12期)2021-01-14
中国外汇(2019年18期)2019-11-25
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
哲学评论(2017年1期)2017-07-31
中成药(2017年3期)2017-05-17
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
郑州大学学报(医学版)(2015年1期)2015-02-27
