
遮挡与几何感知模型下的头部姿态估计方法
2023-03-16 10:21贺建飚
计算机工程 2023年3期
付 齐,谢 凯,文 畅,贺建飚
(1.长江大学 电子信息学院,湖北 荆州 434023;2.长江大学 电工电子国家级实验教学示范中心,湖北 荆州 434023;3.长江大学 西部研究院,新疆 克拉玛依 834000;4.长江大学 计算机科学学院,湖北 荆州 434023;5.中南大学 计算机学院,长沙 410083)
0 概述
头部姿态估计指的是根据给定的图像推断出人的头部方向,包括俯仰角(pitch)、偏航角(yaw)、滚转角(roll)的三维向量[1]。近年来,随着计算机视觉和人工智能的发展,头部姿态估计在人机交互[2]、辅助驾驶[3]、智慧课堂[4]、活体检测[5]等领域得到了广泛应用。国内外不少研究人员对头部姿态估计算法进行了深入研究,提出多种头部姿态估计算法。根据有无面部关键点,一般可将其分为基于模型的方法和基于外观的方法两类[6]。
基于模型的方法通过检测面部关键点,建立三维空间到二维图像间的映射关系来估计头部姿态[7]。例如,文献[8]提出基于眼睛定位的头部姿态估计方法,利用眼睛的位置进行不同头部姿态的估计。文献[9]结合特征点的深度信息构建三维头部坐标系,然后将头部坐标系粗配准计算与点云配准算法相结合,最终得到精准的头部姿态参数。该方法的准确率和稳定性表现比较好,但是获取图像的深度信息要使用特殊的设备,成本较高。文献[10]先结合局部二值模式(Local Binary Pattern,LBP)特征进行面部关键点检测,然后采用支持向量机对头部姿态进行分类。
基于外观的方法通过大量已标记的数据,训练出样本到头部姿态角的映射模型。例如,文献[11]利用残差网络作为主干网络提取特征,有效提高了真实场景下的预测精度。文献[12]通过改变卷积深度、卷积核大小等手段优化LeNet-5 网络,使其能够更好地捕捉到丰富的特征,进而提高预测精度。文献[13]提出一种轻量级的特征聚合结构,使用多阶段回归估计头部姿态参数。
在真实环境下进行头部姿态估计是一个具有挑战性的难题。文献[14]为得到部分遮挡中面部特征的有效表示,从非遮挡人脸子区域中提取金字塔HoG 特征来估计头部姿态。文献[15]通过合成头部姿态图像,增加不同照明和遮挡条件下的样本图像,进而改善模型的性能。文献[16]利用Gabor 二进制模式对人脸进行处理,以解决部分遮挡和光照变化。文献[17]将遮挡字典引入到面部外观字典中,以从部分遮挡的面部外观中恢复面部形状,并对各种部分面部遮挡进行建模。
本文提出联合遮挡和几何感知模型下的头部姿态估计方法,采用人脸检测和图像增强技术,减小背景和光照变化的影响。通过面部遮挡感知网络和几何感知网络,在减小部分遮挡影响的基础上加入人脸的几何信息。在此基础上,采用设计的多损失混合模型精准地估计出头部姿态参数。
1 本文方法
本文提出一种新的头部姿态估计方法,在联合遮挡感知和几何感知的模型下进行头部姿态估计。如图1所示,本文方法分为4 个部分:(1)为图像预处理模块,目的是进行人脸检测和图像增强;(2)为面部遮挡感知模块,作用是通过遮挡感知网络减少面部遮挡的干扰;(3)为面部几何感知模块,应用堆叠胶囊自编码器[22]感知人脸几何信息;(4)为头部姿态估计模块,通过使用多损失混合模型输出头部姿态角。
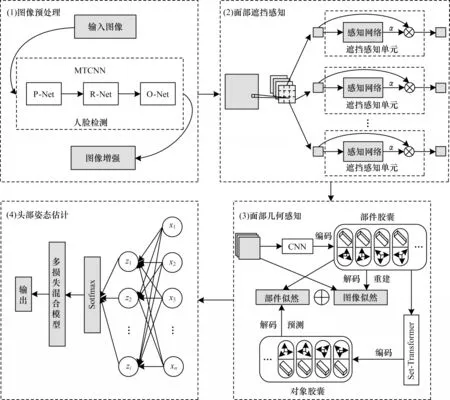
图1 本文方法框架Fig.1 Framework of the method in this paper
1.1 图像预处理
1.1.1 人脸检测
本文的头部姿态估计方法是从单张图像中推理出头部姿态角,建立图像中头部的空间特征信息到头部姿态角向量的映射关系。为减小背景环境的影响,先对输入图像进行人脸检测。在深度学习中,多任务卷积神经网 络(Multi-Task Convolutional Neural Networks,MTCNN)是一个较实用的、性能较好的人脸检测方法[18],由P-Net、R-Net、O-Net 3层网络组成,其核心思想是通过多任务的形式训练网络参数,实现多个任务共同完成的目标,使人脸检测的过程由简到精。在实际运用中,MTCNN 可以很好地应对头部的大幅度偏转,同时对光照变化和部分遮挡具有一定的鲁棒性。
1.1.2 图像增强
考虑到低曝光、光照不均匀等复杂的光照情况对头部姿态估计的影响,在提取特征之前,本文对检测到的人脸进行图像增强处理,以减小光照变化带来的影响。受文献[19-20]启发,本文先采用自适应亮度均衡对亮度图进行处理,然后采用色调映射技术对图像的整体亮度进一步调节,以解决低曝光问题。
首先,本文将输入图像从RGB 通道变换到HSV 通道,单独处理V 通道而不改变图像色彩。为达到保持边缘、降噪平滑的效果,本文对亮度图像进行滤波,得到图像的底层Ib和细节层Id,表达式如式(1)所示:
其中:I为输入图像;BF为双边滤波器,滤波过程可表示如下:
其中c(.)和s(.)分别表示像素位置间的相似度和像素值之间的相似度,定义如下:
提取到亮度图像后,本文采用自适应的方法对亮度进行平滑处理,具体处理流程如下:
其中:z(x,y)表示像素点(x,y)在一定范围内的亮度平均值;I′(x,y)代表处理后的图像。本文将某一点的亮度值与其邻域内的亮度平均值作比,得到参数α,假如α>1,则对图像进行亮度抑制,反之则对图像进行亮度增强,最终达到亮度均衡的效果。
为进一步调节图像亮度,本文对均衡后的底层图像进行自适应色调映射,因为人类视觉系统感知亮度近似为对数函数[21],所以可将映射函数定义如下:
其中:Im为I′的最大值;代表对数平均亮度,其表达式如式(9)所示。
通过式(9),本文可以对图像的整体亮度进行调整,为保留细节,本文将滤波后的细节层融入映射后的图像,该过程的表达式如下:
最后,将处理后的亮度分量与原有的色调和饱和度分量进行合成,并转化到RGB 空间得到最终的图像。
1.2 面部遮挡感知模型
如图1 中(2)所示,本文的面部遮挡感知模型先对处理后的图像进行卷积操作以减少参数量,得到特征图后将其划分成n个子区域。接着将这些子区域分别送入遮挡感知单元得到对应的遮挡感知因子,该参数反映了子区域的遮挡程度。最后将感知因子与对应子区域相乘并恢复成原特征图的形状,得到新的带有遮挡信息的特征图。
每个遮挡感知单元包含1 个遮挡感知网络,该网络可以感知遮挡的子区域,对于未遮挡的、信息丰富的子区域,网络输出较大的遮挡因子参数。详细网络结构如图2 所示。
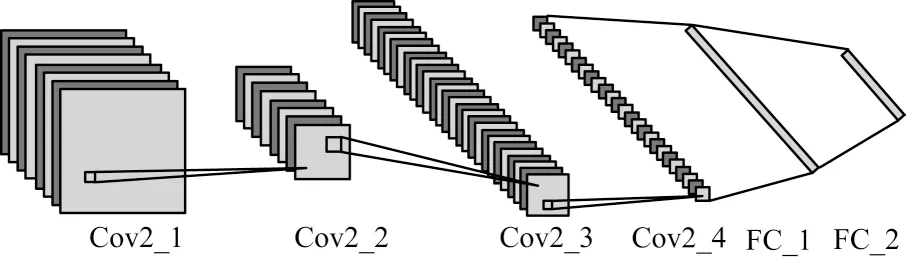
图2 遮挡感知网络结构示意图Fig.2 Schematic diagram of occlusion sensing network structure
由图2 可知,该网络包含4 个卷积层、2 个全连接层。网络的输入为划分好的子区域,通过遮挡感知网络后经Softmax 函数输出1 个遮挡因子,表示该区域的遮挡程度。在实际应用中,为充分细化遮挡程度,对于完全遮挡的、没有面部信息的子区域,网络输出遮挡因子数值为无穷小,依此类推,遮挡程度越小、信息越丰富的子区域,网络输出遮挡因子的数值越大。
本文定义第i块子区域为pi,则遮挡感知网络可表示如下:
其中:y表示从区域特征到输出的映射;αi表示该区域的遮挡因子。最后本文将每块子区域乘以对应的遮挡因子并拼接在一起,得到带有遮挡信息的新的特征图F,表达式如下:
1.3 基于SCAE 的面部几何感知
堆叠胶囊自编码器(Stacked Capsule Autoencoders,SCAE)[22]通过无监督方式描述几何关系,利用部件之间的几何关系重建原始图像。受到这一特点的启发,本文使用SCAE 对面部图像的组成部分和组成部分的姿态进行编码,深度感知面部各部分的几何关系,获取面部的几何表征,提高头部姿态估计准确率。如图1 中(3)所示,SCAE 由部件胶囊自编码器和对象胶囊自编码器堆叠而成。
1.3.1 部件胶囊自编码器
部件胶囊自编码器将输入的面部特征图编码成M个部件胶囊,每个胶囊包含1 个姿态向量xm,1 个存在概率dm和1 个特殊的特征zm参数,姿态向量里包含了面部各部分之间的相对位置,特殊的特征参与下一部分对象胶囊自编码器的编码。为了能更好地优化部件胶囊的参数,本文将卷积神经网络(Convolutional Neural Network,CNN)当作编码器,编码过程可以表示如下:
在解码过程中,本文首先为每个部件胶囊定义1 个模板Tm∈[0,1]h×w×1,为了获得带有模板的实际图像部分,本文使用获取到的姿态向量xm对模板进行仿射变换:
然后,本文用空间高斯混合模型(Gaussian Mixture Model,GMM)重建输入。图像似然值可表示如下:
元素及其化合物是中学化学基础知识之一,是解决化学反应过程中思维活动的基础,没有扎实的基础知识,就如同漏水的水桶,在解决问题时就会千疮百孔,漏洞百出。
这一阶段训练的目标是提取代表面部各部分的部件胶囊、姿态等参数,并得到部件的模板,用于第2 个阶段的对象胶囊自编码器。训练的目标函数是最大化图像似然函数。
1.3.2 对象胶囊自编码器
在第2 个阶段,对象胶囊自编码器对部件胶囊自编码器的输出进行编码,以获取各个部件胶囊之间的内部关系,并重建部分胶囊的姿态。
在对象胶囊自编码器阶段,本文将上一阶段得到的姿态向量、特殊的特征和模板作为输入,使用set-transform[23]作为编码器,将输入编码成K个对象胶囊,每个胶囊包含1 个特征向量ck、存在概率βk和1 个3×3 的对象,即视角关系矩阵Vk。编码过程可以表示如下:
其中:hcaps函数表示编码器。在解码过程中,对于每个对象胶囊,本文使用1 个多层感知器预测出N个候选区域,每个候选区域包含1 个条件概率βk,n、1 个联合的标量标准差λk,n和1 个3×3 的对象—部件关系矩阵Pk,n。解码过程如式(18)所示:
其中:μk,m和λk,m分别代表各向同性高斯分量的中心和标准差,μk,m=Vk×Pk,m,目标函数是最大化部件似然函数。
1.4 基于多损失的头部姿态估计混合模型
输入图像经过以上遮挡感知模块和几何感知模块后,本文得到了面部图像的遮挡表征和几何表征,然后本文利用这些特征建立映射模型,得到最终的头部姿态参数。在之前预测头部姿态的工作中,大多直接使用回归的方法建立映射模型,然而这种方法难以处理头部姿态的细微变化,预测精度不高。
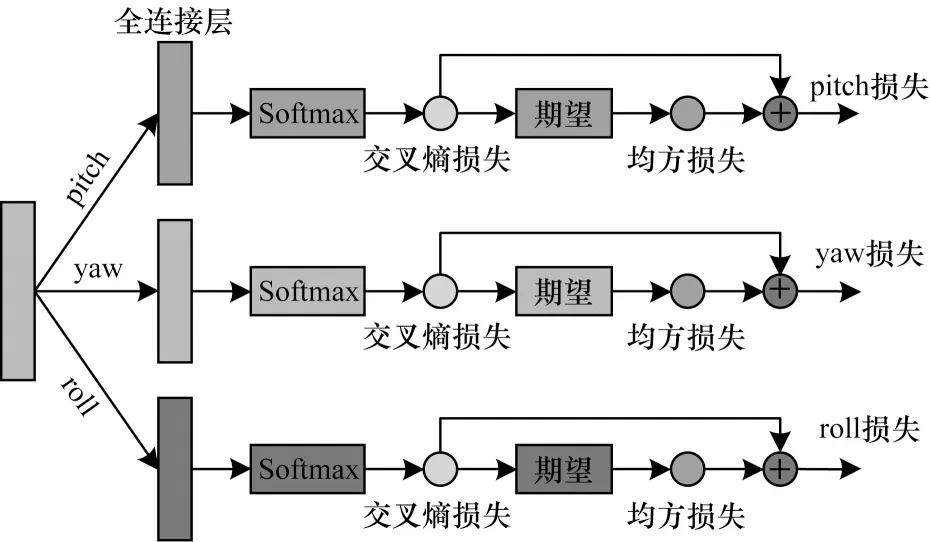
图3 多损失混合模型的网络结构Fig.3 Network structure of multi-loss hybrid model
其中:CEL 和MSE 分别代表交叉熵损失和均方损失;yi和分别代表真实值和预测值;α代表权值因子,该因子的评估将在2.2.2 节进行。本文将不同维度的3 个损失反向传播到网络,以加强模型学习,最终获得细粒度较高的预测结果。
2 实验结果与分析
2.1 实验数据集与评估指标
在3个公开的数据集上进行实验,以评估本文提出的头部姿态估计模型。图4所示为数据集图像示例,第1行为300W_LP[24]数据集样本,第2行为AFLW2000[24]数据集样本,第3行为BIWI[25]数据集样本。

图4 数据集图像示例Fig.4 Sample image of dataset
300W-LP 数据集由300W[26]数据集扩展而来,它标准化了多个用于面部对齐的数据集,使用带有3D图像网格的面部轮廓人工合成了61 225 个不同姿态的样本。AFLW2000 数据集是一个野外数据集,共有2 000 张受各种姿态、部分遮挡、光照、种族等因素影响的人脸图片,每张图像都标注了对应的姿态。BIWI 数据集是一个实验室数据集,记录了20 个志愿者(包括6 名女性和14 名男性)坐在Kinect 前(约1 m的距离)自由转动头部的视频序列,该数据集拥有超过15 000 张图像数据,其中头部姿态偏转角度变化范围在[-75°,75°]之间,俯仰角度在[-60°,60°]之间。
为训练遮挡感知网络,本文从上述数据集中随机选取200 张样本图像合成遮挡的样本,用作网络训练。本文的遮挡物选取了日常生活中常用的物品,将遮挡物随机叠加到人脸图像上生成遮挡数据集。图5 为遮挡数据集部分图像示例。

图5 遮挡数据集图像示例Fig.5 Sample images of occlusion dataset
本文将平均绝对误差(Mean Absolute Error,MAE)作为评估指标。假设给定一系列训练的人脸图像X={xn|n=1,2,…,N}和对应的头部姿态标签yn,将通过本文网络预测出的头部姿态设为,则MAE 定义如下:
2.2 实验设置和参数评估
2.2.1 实验设置
本文通过Pytorch 框架实现本文方法,实验平台为搭载Intel®CoreTMi710875 CPU、NVIDA RTX2070 GPU的计算机。实验以300W_LP 为训练集,将AFLW2000和BIWI 分别作为测试集。模型训练结合了无监督学习和有监督学习。本文将预处理后的图像通过已经训练好的遮挡感知网络提取出带有遮挡信息的面部特征,然后将特征送入几何感知网络进行无监督学习,在几何感知网络模型训练阶段,使用RMAProp 优化器训练网络,部件胶囊和对象胶囊的个数都设置为32,学习率设为0.000 1,迭代次数为500 次。在多损失预测头部姿态模型阶段,使用Adam 优化器进行训练,将初始学习率设为0.000 1,每迭代50 次学习率衰减0.000 001,最大迭代次数为400 次。
2.2.2 参数评估
针对多损失混合模型中交叉熵损失和均方损失间权重因子的评估,本文分别在AFLW2000数据集和BIWI数据集上评估不同权重因子下本文模型的性能,将权重因子分别设置为0、0.25、0.5、1、2、3,测试结果如图6所示。可以看到,当权重因子为2 时,模型在两个数据集上的MAE 均最小,模型预测准确率最高。
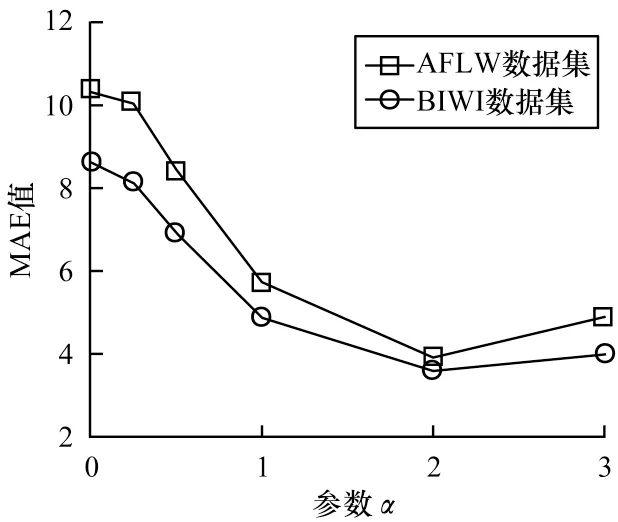
图6 不同权重因子下的测试结果Fig.6 Test results under different weight factors
2.3 图像预处理
本文在预处理阶段进行了人脸检测和亮度均衡操作,目的是减小背景和光照变化的干扰。图7 为部分预处理实验结果,图7 中第1 列图像代表输入的原图,第2 列图像为进行人脸检测后按一定比例裁剪的图像,第3 列为进行亮度均衡处理后的图像。

图7 预处理结果示例Fig.7 Example of preprocessing results
2.4 消融实验
为评估本文方法中遮挡感知模块和几何感知模块的影响,本文对比了模型在有无嵌入遮挡感知和几何感知情况下的性能,实验以300W_LP 为训练集,将AFLW2000 和BIWI 分别作为测试集,结果如图8 所示。
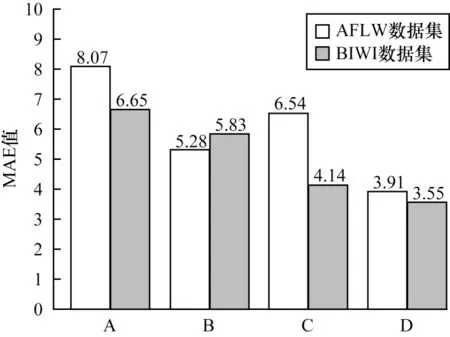
图8 不同模型的消融实验结果Fig.8 Results of ablation experiments of different models
在图8 中,A 组代表模型中既无遮挡感知块也无几何感知块,B 组表示只有遮挡感知块,C 组表示只有几何感知块,D 组表示两者都有。A、B 组对比结果显示,嵌入遮挡感知模块的模型在野外数据集AFLW2000 上测试性能明显提升,在BIWI 数据集上测试性能相近。A、C 组对比结果显示,嵌入几何感知模块后的模型在BIWI 数据集上测试性能明显提升,而因未考虑遮挡,所以在AFLW2000 数据集上测试结果没有B 组好。D 组在嵌入遮挡和几何感知块后,在两个数据集上的测试性能都明显提升,平均绝对误差均低于B 组和C 组。消融实验的结果表明,本文方法中的遮挡感知模块和几何感知模块有效提高了模型的估计性能,具有一定的实际应用价值。
2.5 对比实验与分析
本文对比了目前较好的姿态估计方法。前3 组方法是基于面部关键点的,后几组为无面部关键点的方法。其中,Dlib[27]是一个标准的人脸库,使用回归树集合估计人脸的关键点位置。FAN[28]是一种非常先进的面部关键点检测方法。该方法通过跨层多次合并特征获取多尺度信息。3DDFA[24]通过CNN将三维空间人脸的模型拟合到彩色图像上,在AFLW 数据集上取得了很好的效果。Hopenet[29]提出结合分类与回归计算三维头部姿态。FSA-Net[13]设计了一个细粒度回归学习映射模型。文献[30]提出一种新的三分支网络架构来学习每个姿态角的区别特征,再通过引入跨类别中心损失来约束潜在变量子空间的分布,得到更紧凑、更清晰的子空间。文献[31-32]探索了最近比较流行的VIT 在头部姿态估计的应用,取得了比较好的估计结果。
表1 和表2 分别为本文方法在2 个基准数据集上与最新方法(包括基于面部关键点的方法和无面部关键点的方法)的对比结果,其中“—”表示无此数据。本文是基于无面部关键点的方法,与基于面部关键点的方法(文献[24]、文献[27]和文献[28]方法)相比,本文方法准确率更高,这是因为基于面部关键点的方法受关键点检测过程的影响,依赖面部关键点,而对关键点外的面部特征学习能力较差,难以适应训练和测试之间的差异。
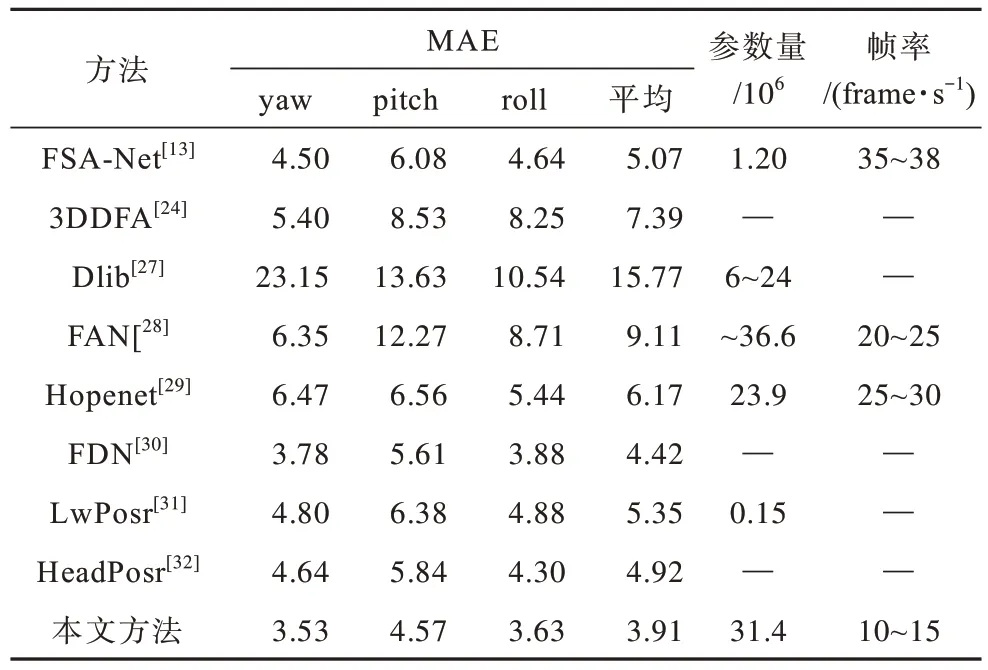
表1 AFLW2000 数据集上不同方法的对比结果Table 1 Results comparison of different methods under AFLW2000 dataset

表2 BIWI 数据集上不同方法的对比结果Table 2 Results comparison of different methods under BIWI dataset
由表1 和表2 还可以发现,在无面部关键点的方法中,本文方法的测试结果均优于其他方法,在AFLW2000数据集和BIWI 数据集上的平均绝对误差分别为3.91和3.55,比对比方法中表现最好的方法分别降低了11.53%和7.31%。BIWI 数据集为实验室数据集,本文方法通过几何感知网络提取了其他方法忽略的面部几何信息,使测试准确率有一定程度的提升。此外,本文方法在具有挑战性的AFLW2000 数据集上的测试结果与其他方法相比有所提升,这显示了本文方法的优越性,进一步证实了本文方法中遮挡感知模型和几何感知模型的有效性。
为评估本文方法的效率,本文采用模型参数量和运行的视频帧率(Frames Per Second,FPS)作为评定指标。由表1和表2可知,与FSA-Net[13]和LwPosr[31]相比,本文方法的模型参数量较多,这是因为FSA-Net[13]设计了轻量级的特征聚合结构,LwPosr[31]使用深度可分离卷积替换了普通卷积,能够减少模型参数量。而本文从解决复杂环境下的头部姿态估计问题出发,设计了遮挡感知模型和几何感知模型,导致模型参数量增加。另外,与其他方法相比,本文方法的帧率较低,这是因为本文方法进行了图像预处理,在该过程中会消耗较多的时间成本。但本文方法可以很好地适应复杂的现实场景,提高现实场景下头部姿态估计的准确率。
2.6 复杂环境下的性能测试
在得到训练好的网络模型后,本文选取光照变化差异大、有部分面部遮挡的样本图像进行测试,以直观地验证本文方法在复杂环境下的性能,测试结果如图9 所示。

图9 本文方法在复杂环境下的测试结果示例Fig.9 Example of test results of method in this paper under complex environment
在图9中,第1行是光照条件较差时的结果,第2行是面部有部分遮挡时的结果。可以看出,本文方法在光照不均、低曝光、部分遮挡等复杂环境下表现良好,达到在复杂条件下进行头部姿态估计的目标。
2.7 局限性分析
本文提出的头部姿态估计方法在一定程度上提高了在复杂环境下的预测准确率。然而,本文方法也存在一些局限性,本文可以很好地应对小部分面部遮挡情况,但当面部区域遮挡过大时,本文方法可能无法产生令人满意的结果,因为当面部区域遮挡过大时,本文提取的有效面部特征就会变少,进而影响模型预测头部姿态。另外,本文方法可能在移动嵌入式设备表现不佳,因为本文方法的模型参数较大。
3 结束语
本文提出一种基于遮挡感知模型和几何感知模型的头部姿态估计方法,通过图像预处理操作与使用遮挡感知网络,减少背景、光照变化、遮挡等环境因素的干扰,提高预测准确率。采用几何感知网络提取特征,为获取几何感知的人脸图像提供了一种无监督学习的解决方案。实验结果表明,本文方法能有效应对光照不均、部分遮挡、面部外观差异大等问题,在不同数据集上的表现较好。下一步将进行遮挡部分的复原工作[33],以丰富面部特征,提高头部姿态估计准确率。同时通过减少模型参数,使其适用于移动嵌入式设备。
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
基层中医药(2021年1期)2021-07-22
军事文摘(2020年22期)2021-01-04
动漫星空(2018年9期)2018-10-26
成都信息工程大学学报(2018年3期)2018-08-29
电子器件(2015年5期)2015-12-29
天津医科大学学报(2015年2期)2015-12-22
奇闻怪事(2014年5期)2014-05-13
电测与仪表(2014年13期)2014-04-04
