
基于高斯积分法高精度获得各密度级平均密度并用Exce l实现的方法
2023-03-10 11:19:30申永强
煤炭与化工 2023年1期
申永强
(冀中能源股份有限公司 东庞矿,河北 邢台 054201)
0 引 言
煤矿对应煤层原煤浮沉基元灰分与密度的线性回归方程可以应用于该矿选煤厂实验数据的检验核对;在对原煤分组入洗确保最大产率时,也可使用线性回归方程对等基元灰分的分选密度进行预测;分配曲线的绘制也要用到平均密度,而分配曲线广泛地用于分选设备的评价和产品的预测优化。因此,平均密度的精确计算非常重要,一般情况下都是借助于计算机编程进行精确计算,复杂繁琐。本文提供了一种借助Excel完成平均密度精确计算的简便方法。
1 平均密度精确计算公式变形
根据《评定煤用重选设备工艺性能的计算机算法》的规定,遵循质量守恒原理,平均密度的计算可以按照如下公式进行精确计算:
通过对平均密度计算公式的变形,转化为数学计算问题,即密度曲线数学模型的建立和数值积分的计算。
2 密度曲线数学模型的建立
以东庞2号煤原煤50~0.5 mm粒度级浮沉试验数据为基础,利用改进的LOGITISC、双曲正切、复合双曲正切三种模型进行拟合,选择拟合误差最小的模型作为浮物累计产率与密度函数关系,求导获得的表达式。
2.1 浮物累计产率与密度函数关系的获得
东庞2号煤原煤50~0.5 mm粒度级浮沉数据见表1。
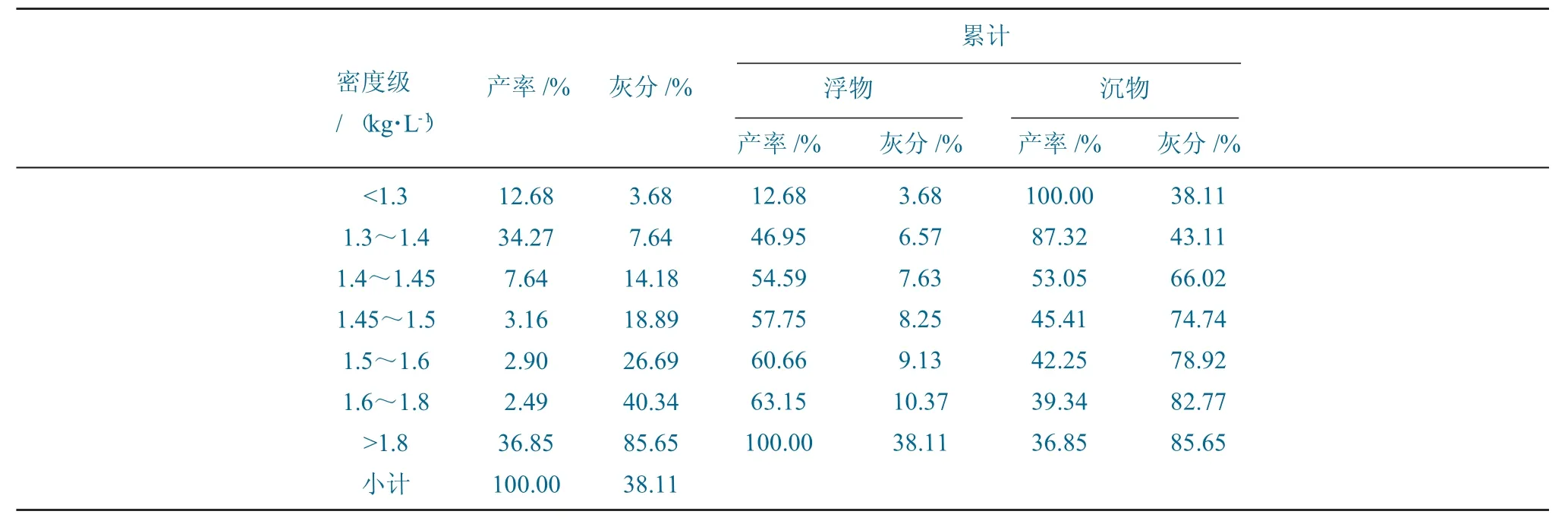
表1 东庞2号煤原煤50~0.5mm粒度级浮沉组成Table 1 Composition of 50~0.5 mm particle size grade float and sink of Dongpang No.2 coal
利用excel中规划求解功能,获得各种模型的参数和拟合误差[3],拟合过程不再叙述。密度曲线模型见表2。
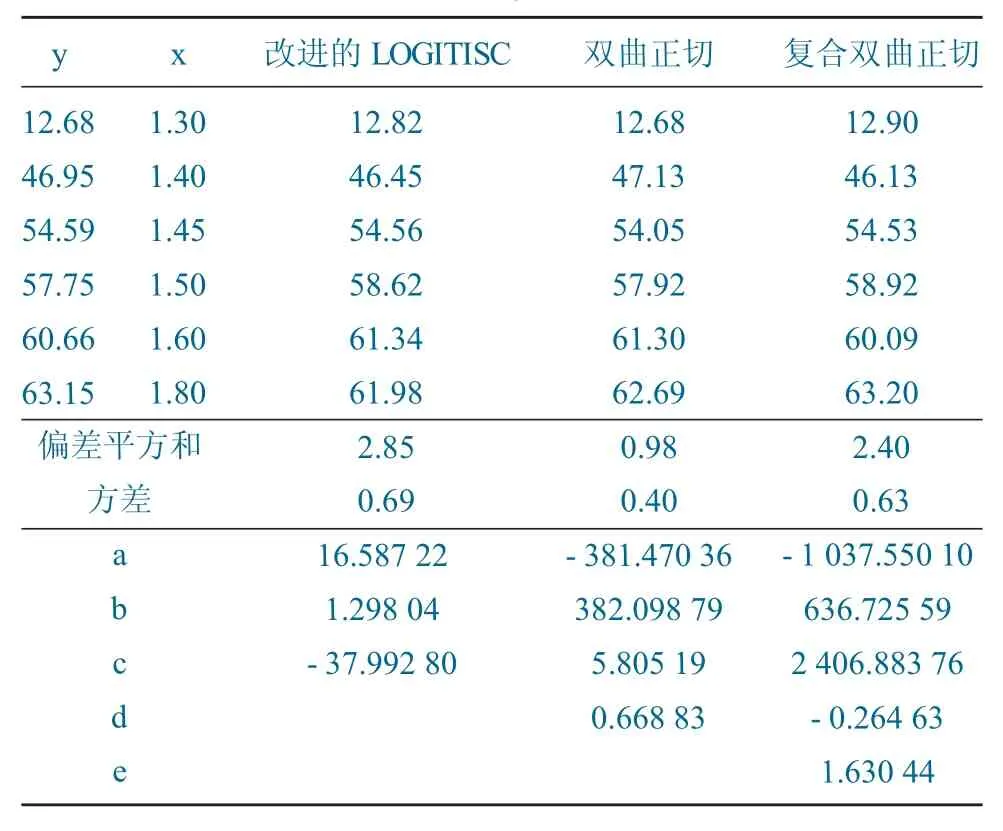
表2 密度曲线模型Table 2 Density curve model
双曲正切模型的拟合误差最小为0.40,满足《评定煤用重选设备工艺性能的计算机算法》的规定,故浮物累计产率与密度关系的表达式为:
对式(2)求导获得的表达式:
将式(3)的表达式代入式(1)中,获得平均密度的计算公式:
式(2)式(3)式(4)中,a=-381.470 36;b=382.098 80;c=5.805 19;d=0.668 83。
至此,将平均密度的计算公式转化为以密度为变量的定积分函数。
2.2 常用模型函数的导函数
为了方便获得平均密度变形公式的表达式,将选煤上常用数学模型函数的导函数进行汇总,见表3。

表3 常用模型函数的导函数Table 3 Derivative functions of common model functions
3 平均密度的确定
各密度级平均密度确定包括中间密度级和端部密度级。而端部密度级平均密度可以通过中间各密度级的平均密度对平均灰分的线性回归方程外推获得[4],计算较为简单,因此本文不再做端部密度平均密度的计算部分。
由于中间密度级的平均密度的精确计算公式式(4)中包含有积分项,用Excel直接计算较为困难,故利用数值积分计算方法[5]:只利用有限个节点和函数在有限个节点处的函数值的四则运算,近似计算出平均密度,进而再借助Excel工具实现平均密度的精确计算。
关于数值积分计算的方法较多,本文采用计算较为简单的三点高斯-勒让德求积公式进行近似计算,具有5次代数精度。
3.1 一般有限区间的三点高斯-勒让德求积公式
对于一般有限区间[a,b],三点高斯-勒让德求积公式:余项为:
式中:xi和Ai分别为高斯点和高斯系数,η∈(-1,1)。其中,余项的实质为近似计算的误差。
高斯-勒让德求积公式一般表达式转变为三点高斯-勒让德求积公式,高斯点和高斯系数通过查表获得。常用的高斯点和高斯系数见表4。

?
3.2 中间密度级平均密度的e xce l表格计算过程
为了方便理解计算,将所有步骤按表5格式在Excel中依次输入数据。
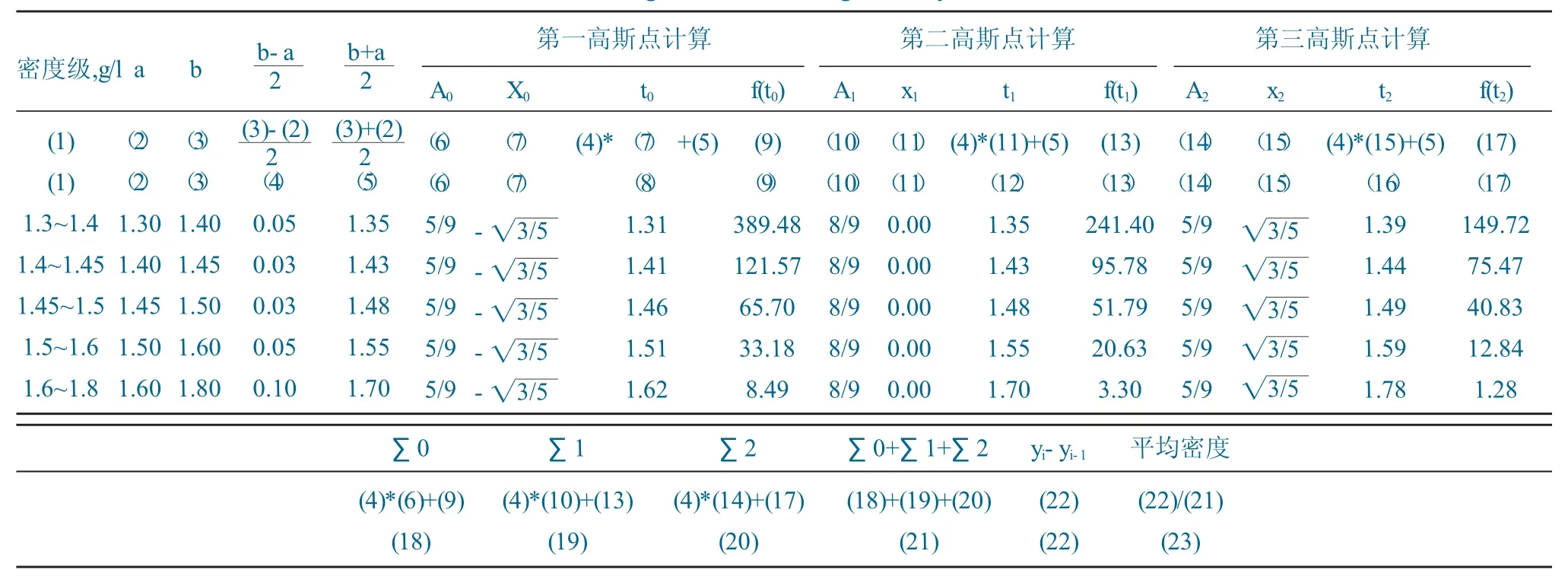
表5 高斯积分法平均密度计算表Table 5 Gauss integral method average density calculation table
(1)取中间各个密度级的下限和上限,分别放入第2、3列;计算(b-a)/2和(b+a)/2的值,分别放入第4、5列。
(2)从表4中选取A0、X0和A1、X1和A2、X2的值,分别放入第6、7列和第10、11列和第14、15列。
(3)分别计算当i=0、1、2时的值,作为t0、t1、t2,放入第8、12、16列。
(4)在第9、13、17列分别输入以t0、t1、t2单元格为变量的目标函数——式(4)积分项中的被积函数。其中a=-381.470 35、b=382.098 80、c=5.805 19、d=0.668 83,ti为变量。
(5)分别计算当i=0、1、2时的值,作为∑0、∑1、∑2,放入第18、19、20列;并计算∑0+∑1+∑2的值,放入第21列。
(6)各密度级的产率从表2中选取双曲正切列的数据,计算yi-yi-1的值,放入第22列;并计算(yi-yi-1)/(∑0+∑1+∑2)的值,放入第23列,即为平均密度。
3.3 高斯求积公式计算平均密度的误差分析
在对三点高斯-勒让德求积公式近似计算获得的平均密度的值进行误差分析时,虽然可以对式(7)所示的余项的表达式进行计算,但计算难度较大,较为复杂,且计算机编程计算结果的精度较高。故本文以计算机编程计算结果为真值,对高斯法计算平均密度进行误差分析,见表6。为了方便进行误差分析,增加表5中平均密度列所数据小数点后保留的位数,并列于表6中。

续表

表6 高斯法计算平均密度误差分析Table 6 Gauss method to calculate the average density error analysis
从表6可以看出,高斯法计算结果中,1.4~1.45和1.45~1.6密度级平均密度的计算误差最小,其次是1.3~1.4和1.5~1.6密度级,而1.6~1.8密度级计算误差最大,绝对误差停留在小数点后第四位。
从一般有限区间的三点高斯-勒让德求积公式余项的表达式也可以得出,密度级越宽,高斯法计算误差越大。
4 结 论
(1)借助Excel计算工具,运用三点高斯-勒让德求积公式,可以较为精确地获得各密度级的平均密度。
(2)该方法利用Excel可以完成所有计算,既简单精度又高,密度级范围为0.2 g/L时,绝对误差停留在小数点后第四位,密度级范围为0.1 g/L时,绝对误差停留在小数点后第六位,可以满足实际使用要求。
猜你喜欢
防爆电机(2022年4期)2022-08-17 05:59:50
矿山安全信息(2021年15期)2021-12-31 11:09:09
矿山安全信息(2021年15期)2021-12-31 11:09:09
数学物理学报(2020年2期)2020-06-02 11:29:10
安顺学院学报(2020年1期)2020-04-05 10:57:20
中国眼镜科技杂志(2019年9期)2019-11-11 12:15:26
现代计算机(2019年6期)2019-04-08 00:46:50
现代企业(2015年4期)2015-02-28 18:48:45
河南科技(2014年24期)2014-02-27 14:19:31
城市道桥与防洪(2014年5期)2014-02-27 07:26:16
