
基于深度强化学习的移动机器人视觉图像分级匹配算法
2023-03-09 12:49:44李晓峰
吉林大学学报(理学版) 2023年1期
李晓峰, 任 杰, 李 东
(1.黑龙江外国语学院 信息工程系, 哈尔滨 150025; 2.哈尔滨体育学院 体育教育训练学院, 哈尔滨 150008; 3.哈尔滨工业大学 计算机科学与技术学院, 哈尔滨 150001)
移动机器人可在多种环境中采集相关信息, 具有采集速度快、精度高等特点[1-3], 但其在图像采集过程中易受噪声干扰, 使视觉图像质量降低[4-6], 后续图像分析过程中无法获取有效的信息, 导致出现信息漏检和误检等情况.为此, 需研究图像匹配算法[7-10], 以提升图像的清晰度[11-12], 丰富图像的细节信息.
目前, 移动机器人视觉图像匹配的相关研究已有许多成果.例如: 王斐等[13]针对图像匹配精度低的问题, 研究图像匹配算法, 先将图像匹配问题变为组合优化问题, 再利用樽海鞘群算法求解该问题, 通过方向梯度直方图特征提取特征块并求解相似度, 完成特征匹配, 但该算法易受尺度变化的影响, 鲁棒性较差, 只能完成图像粗匹配;朱成德等[14]利用快速旋转不变特征(oriented fast and rotated brief, ORB)算法预匹配图像, 再通过随机抽样一致性剔除无关性特征点, 筛选出正确匹配点, 提升匹配效率, 但该算法中ORB特征为灰度特征, 并未考虑具有较高价值的颜色信息, 匹配精度较低;武玉坤等[15]通过回归学重建图像, 并优化重建图像, 再提取特征进行匹配, 提升匹配效果, 但该算法同样易受尺度变化的影响, 匹配稳定性较差, 不能实现图像精匹配;Singh等[16]提出了一种新的事件触发指数超扭转算法, 针对移动机器人路径跟踪进行了研究, 但该方法对跟踪过程图像匹配分析不详细;Chae等[17]设计了非完整移动机器人的稳健自主立体视觉惯性导航系统, 通过向侧面移动摄像机执行精确的视觉特征初始化, 以确保图像视差退化, 该方法将带有消失点修正的线特征观测模型应用于视觉惯性测速法, 使移动机器人在自主导航过程中能进行鲁棒的姿态估计, 该系统匹配误差较小, 但计算过程复杂导致耗时较长;Wang等[18]从分析力学的角度探讨了网络化多移动机器人系统的同步控制问题, 利用该算法, 网络移动机器人系统可在无领导情况下从任意初始条件实现同步, 并在明确给出路径的情况下实现精确轨迹跟踪, 但在非明确给出路径的条件下仅能完成粗跟踪.
为解决上述研究存在的不足, 本文设计一种基于深度强化学习的移动机器人视觉图像分级匹配算法, 通过融合深度学习的感知能力和强化学习的决策能力, 分层次进行图像粗匹配和细匹配, 有效提高了移动机器人视觉图像匹配精度, 降低了图像匹配耗时.本文算法具有如下优点: 首先, 深度强化学习融合了深度学习的感知能力和强化学习的决策能力, 能直接处理输入图像, 提升图像处理效果;其次, 利用深度强化学习网络结构中的策略网络和价值网络共同指导浮动图像按正确方向移至参考图像, 并在粗匹配过程中通过设计奖赏函数, 实现颜色特征粗匹配, 提升了图像匹配效率;最后, 在图像粗匹配的基础上, 利用改进尺度不变特征变换算法提取待匹配的图像局部特征, 按相似度进行移动机器人视觉图像分级匹配, 提升了匹配精度.
1 移动机器人视觉图像粗匹配
1.1 深度强化学习
将多线程异步强化学习(reinforcement learning, RL)算法内的策略函数π(ut|ct;θ)视为一个智能体, 其中ut表示动作,ct表示状态,θ是策略网络参数;智能体按目前π(ut|ct;θ)执行动作.假设价值网络参数为θv, 利用目前策略π下ct的价值函数V(ct;θv), 衡量已知ct情形下策略网络中ut的优劣.利用优势函数F建立策略梯度可减少策略梯度的方差, 提升优秀动作出现的概率[19-20].在状态和动作为ct,ut时,F的计算公式为
F(ut;ct)=Rt-V(ct;θv),
(1)
其中Rt为未来时间步长T的奖励总和.折扣因子为γ时Rt的计算公式为

(2)
其中τ表示学习速率[21],γ∈(0,1].假设F(ut;ct), 则θ和θv的更新公式为

为提升移动机器人视觉图像分级匹配效果, 将强化学习[22-23]与深度学习网络[24-25]相结合, 构建轻量级的深度RL(deep RL, DRL)框架, DRL框架根据异步的梯度下降法优化网络控制器参数, 可提升匹配速度和稳定性.网络参数利用线程交互, 令各线程利用式(3)和式(4)在t时异步更新网络参数.
假设(C,U,ot,λ)表示RL框架, 其中C为状态,U为移动动作,ot表示参考图像.后续需利用该框架中的策略网络和价值网络共同指导浮动图像按正确方向移至参考图像, 从而为图像粗匹配奠定基础.
1.2 图像粗匹配
令移动机器人视觉浮动图像为Xm,Xf为参考图像, 移动机器人视觉图像粗匹配的目标为估计至最优的空间变换B.在只参考近似变换时,B由平移参数bx和by、旋转参数α、缩放参数z组成, 表达式为
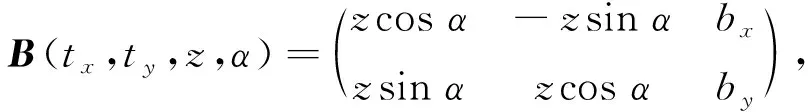
(5)
其中tx和ty表示图像的原始位置参数.

图1 深度强化学习网络体系结构Fig.1 Architecture of deep reinforcement learning network
深度强化学习网络体系结构由两个通道构成, 每个通道都包含卷积神经网络(CNN)[26-27]、全连接层和长短期记忆网络(long short-term memory, LSTM)[28-29], 其中全连接层负责对卷积神经网络与长短期记忆网络建立连接, 三者相结合构成深度强化学习网络的重要运算结构.在输入不同状态后通过深度强化学习结构运算生成新的全连接层, 再基于新的全连接层实现价值和图像匹配策略的更新.深度强化学习网络体系结构如图1所示.
该网络的输入是Xm与Xf构建的双通道图像, 经LSTM后存在两个全连接层(FC), 分别输出π(ct;θ)和V(ct;θv);在t时, 智能体使用ut后, 将Bt+1转换为ut∘Bt, “∘”为在Bt+1的参数(tx,ty,z,α)中展开一次转换,t时刻仅可转换一个参数.
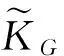
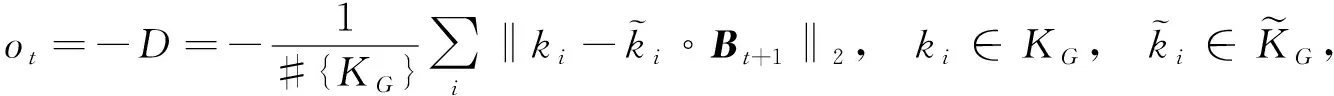
(6)
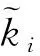
在智能体各部分网络内, 利用CNN提取粗匹配图像st特征, 获取各时间步的状态特征, 并依次与环境进行交互, 得到状态特征序列, 输入LSTM网络进行粗匹配.粗匹配中环境与at交互时, 智能体均是利用V(ct;θv)求解目前状态下的状态值v, 并将其作为衡量目前Xm和Xf粗匹配状态的标准,v与粗匹配效果成正比;测试阶段, 利用ot决定粗匹配是否完成, 直至ot达到设置阈值, 则粗匹配完成.
1.3 移动机器人视觉图像精匹配
利用改进尺度不变特征变换(scale invariant feature transform, SIFT)[30]算法在移动机器人视觉图像粗匹配的基础上进行精匹配.利用减法聚类减去多余的特征点, 完成SIFT改进.令改进SIFT检测粗匹配图像后获取n个特征点, 特征点集合为{x1,x2,…,xn}, 特征点检测步骤如下:
1) 求解特征点集合内各特征点的密度, 获取密度指标M(xi), 用公式表示为
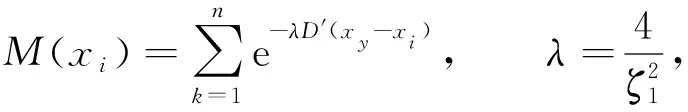
(7)
其中λ表示初始聚类中心,ζ1表示邻域半径,D′(xy-xi)表示xy和xi的欧氏距离;
2) 令搜索获取的最大M(xi)特征点是第一个聚类中心, 并与该特征点的密度相除, 求解剩余特征点的My(xi), 用公式表示为

(8)
其中μ表示当前聚类中心,ζ2=1.5ζ1;
3) 根据步骤1)和步骤2)再次搜索最大的M(xi), 将该特征点视为聚类中心, 以未产生新的聚类中心为止, 完成迭代.
改进SIFT算法利用二值化处理特征描述子b, 缩减数据量, 以确保b的全部信息不丢失.令l维特征向量Q=(Q0,Q1,…,Ql), 二值化处理b的步骤如下:
1) 求解同一向量中Qj与Qj+1(j∈l)差的绝对值, 用公式表示为

(9)
2) 根据Pj值求解二进制特征向量内各位数值bj, 获取二值化的b={b0,b1,…,bl-1}, 用公式表示为

(10)
其中W为差值阈值, 用于平衡式(9)求解差值的两个部分.
将Hash值作为索引, 利用Hamming距离获取b间的相似度, 提升移动机器人视觉图像精匹配速度.按照Hash函数求解表示特征点的二进制字符串的Hash值, 即
Nj=bj×8×20+bj×8×21+…+bj×8×27,
其中j=0,1,…,15,N16=N0, 且
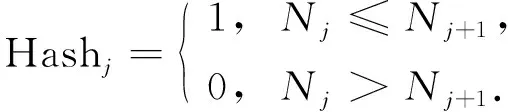
(11)
Hash函数定义为
Hash(Hash0,Hash1,…,Hash15)=Hash0×20+Hash1×21+…+Hash15×27,
(12)
利用式(12)可获取Hash值.
移动机器人视觉图像精匹配步骤如下:
输入: 移动机器人视觉图像;
输出: 移动机器人视觉图像分级匹配结果;
步骤1) 检测粗匹配移动机器人视觉图像特征点, 获取b;
步骤2) 利用式(12)求解二值化b的Hash值, 在Hash库内进行检索;
步骤3) 假设ni是图像i与查询图像间类似b的数量, 求解两个b间的Hamming距离, 如果该值未超过阈值, 则ni←ni+1, 说明具备匹配成功的特征;在Hash库内检索待匹配图像全部特征, 按ni匹配图像, 完成移动机器人视觉图像精匹配.
基于深度强化学习的移动机器人视觉图像分级匹配算法流程如图2所示.
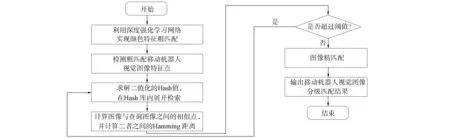
图2 移动机器人视觉图像分级匹配算法流程Fig.2 Flow chart of hierarchical matching algorithm of vision image for mobile robot
2 实验与结果分析
2.1 实验环境和数据集
本文实验采用PyTorch框架实现移动机器人视觉图像分级匹配, 基于Windows10 64操作系统, GPU为Nvidia GeForce RTX 3060 6 GB.
实验所用的数据集如下:
1) 数据集Robot@Home是来自家庭环境的原始和经过处理的感官数据集合, 包含87 000多个带时间戳的观测值, 为与其他研究方法进行比较, 本文实验将该数据集划分为20类训练集, 10类验证集和10类测试集;
2) 数据集MRPT中包含移动机器人数据集的所在地, 还包含一系列场景数据集, 类别层次丰富, 本文实验选取该数据集中的移动机器人轨迹数据集, 将该数据集划分为20类训练集, 10类验证集和10类测试集.
2.2 实验指标
选取文献[16]、文献[17]和文献[18]算法作为本文算法的对比算法.
1) 实际效果验证.以实验选取的数据集Robot@Home和数据集MRPT中的移动机器人视觉图像为研究对象, 利用本文算法进行移动机器人视觉图像分级匹配, 通过验证分级匹配结果及最佳阈值选取结果检验该方法的有效性.
2) 以不同视角和尺度变化时的重复率作为衡量4种算法特征检测的效果, 该值越高, 说明特征检测的稳定性越高, 重复率计算公式为

(13)
3) 匹配精度.匹配精度是指利用不同方法匹配完成后的图像与待参考高质量图像的相似程度, 该参数的计算公式为
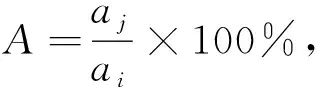
(14)
其中ai,aj分别表示待参考高质量图像和匹配完成后图像的参数值.
4) 匹配时间.匹配时间是指从匹配开始到匹配完成这一过程的时间消耗, 计算公式为
T=t1-t2,
(15)
其中t1,t2分别表示匹配结束和开始的时间.
5) 图像质量.利用非均匀性(NU)、平均梯度(AG)和熵(H)3个指标进一步考察4种算法在不同光照强度时匹配后图像的质量.其中: NU表示匹配后图像的灰度分布均匀情形, 其值越大, 图像灰度分布越不均匀, 计算公式为

(16)
式中u,k分别表示图像灰度值和灰度系数,n表示像素点数量;AG表示匹配后图像的清晰程度, 其值与清晰程度成正比;熵H表示匹配后图像内存在的信息量, 其值与细节丰富程度在成正比, 计算公式为
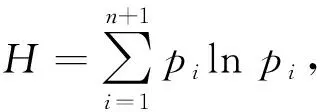
(17)
式中pi表示图像离散信息.
2.3 实验结果
在所采集的视觉图像内随机选取同一目标的两张不同图像, 利用本文算法分级匹配这两张图像, 分级匹配结果如图3所示.

图3 分级匹配结果Fig.3 Hierarchical matching results
由图3可见, 本文算法可有效匹配移动机器人视觉图像.本文算法中粗匹配仅针对图像特征进行匹配, 粗匹配后的结果与参考图像基本接近, 说明本文算法的粗匹配效果较优;在粗匹配结果的基础上, 本文算法可有效进行精匹配, 获取更清晰的图像, 提升图像视觉效果, 丰富图像细节信息, 为后续的图像分析提供更高质量的服务.
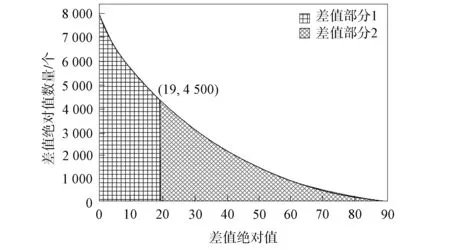
图4 最佳阈值选取结果Fig.4 Selection results of the best threshold
本文算法中精匹配时的重要参数为阈值, 阈值可使两种差值均匀分布, 为此在采集视觉图像内随机选取10张图像, 分析同一特征符128维数值间邻近数值差的绝对值信息, 获取最佳阈值, 提升分级匹配效果, 最佳阈值选取结果如图4所示.由图4可见, 当阈值为19时, 能将两部分差值的绝对信息平均分布, 提高本文算法的分级匹配效果.
在采集的视觉图像内, 随机选取一张图像, 并改变图像视角和尺度, 利用4种算法检测该图像的特征, 测试4种算法在不同视角变化时的特征检测重复率, 结果如图5所示.由图5可见, 随着角度的增加, 4种算法的重复率均不断减少, 在不同变化角度时, 本文算法的重复率均显著高于文献[16]、文献[17]和文献[18]算法;当变化角度为70°时, 本文算法的重复率已趋于稳定, 最低重复率约为50%, 文献[16]算法在变化角度为70°时, 重复率已低至0, 说明此时该算法已无法检测到特征点, 文献[17]和文献[18]算法的最低重复率相同均为5%.实验结果表明, 本文算法在不同视角变化时, 重复率均显著高于其他3种算法, 特征检测稳定性较优.
不同算法在不同尺度变化时的重复率如图6所示.由图6可见, 随着尺度的增加, 除本文算法外的其他3种算法的重复率均呈下降趋势, 本文算法的重复率未发生变化, 这是因为本文算法中提取到的特征为SIFT特征, 该特征不受尺度变化的影响.实验结果表明, 本文算法在不同尺度时的重复率未发生改变, 明显高于其他3种算法, 特征检测稳定性较优.
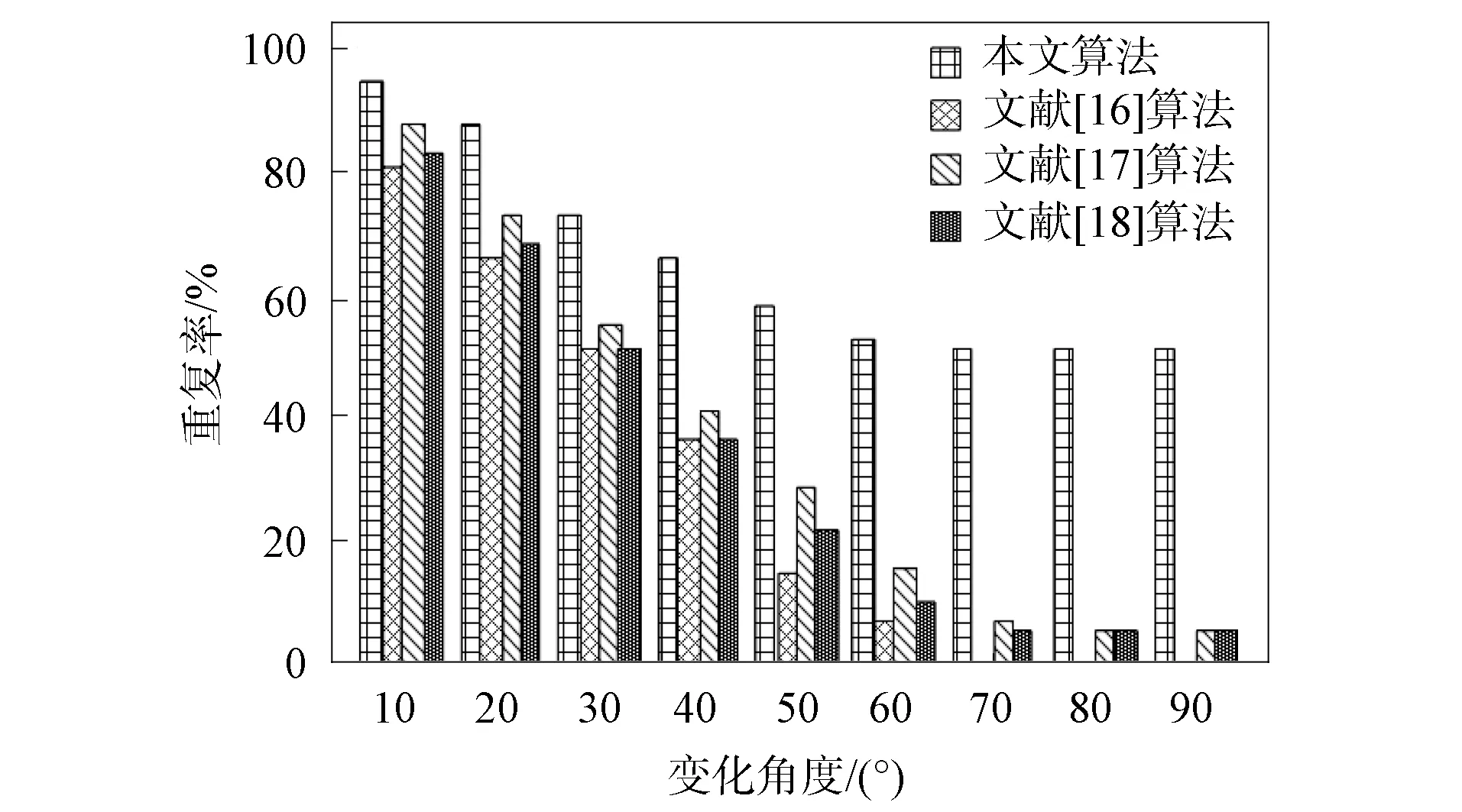
图5 不同算法在不同视角变化时的重复率比较Fig.5 Repetition rate comparison of different algorithms when different perspectives change
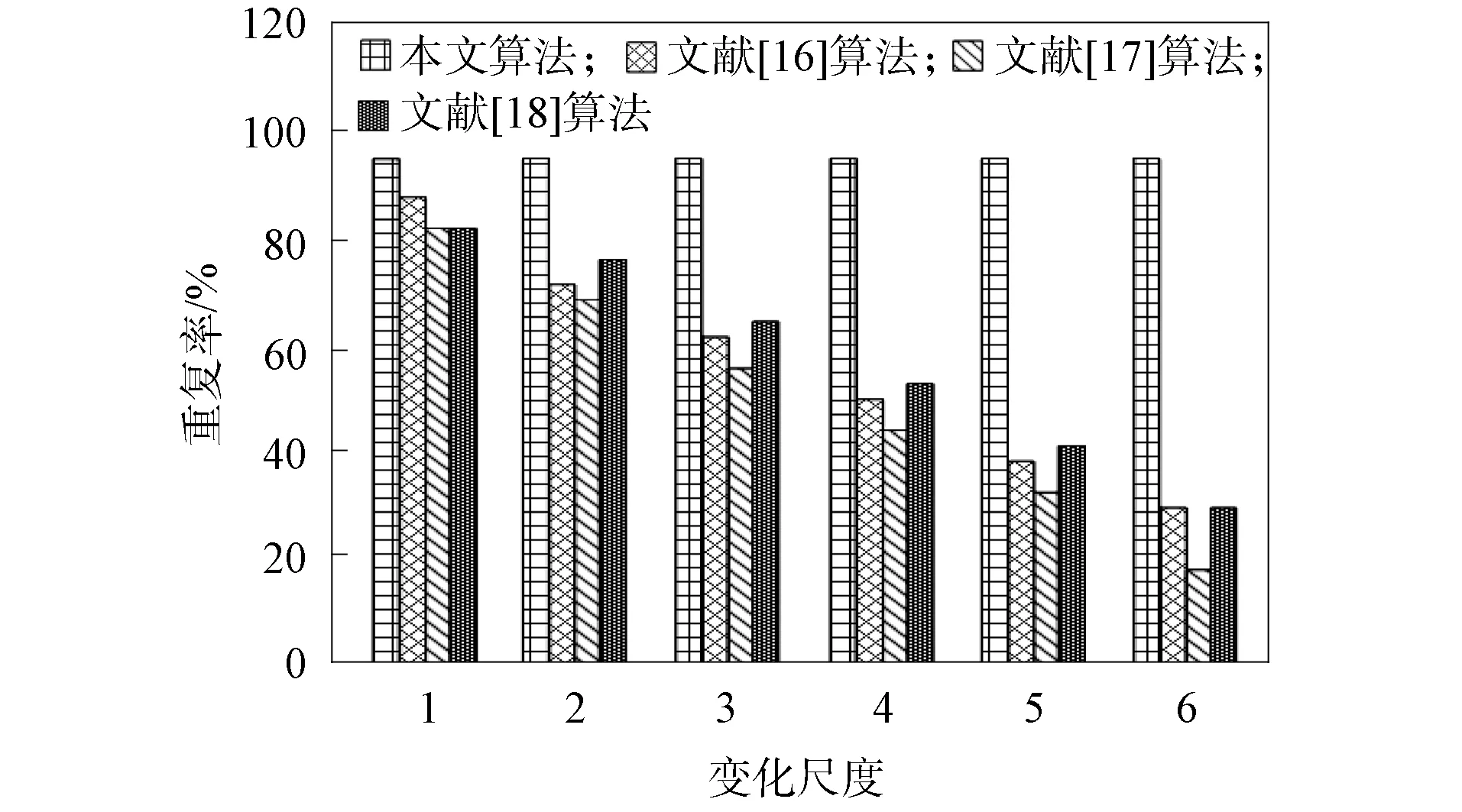
图6 不同算法在不同尺度变化时的重复率比较Fig.6 Repetition rate comparison of different algorithms when different scales change
测试4种算法在不同尺度变化、旋转变化与亮度变化时的匹配精度, 结果如图7所示.由图7可见, 本文算法在不同尺度变化、旋转变化和亮度变化时的匹配精度均保持在92%以上, 显著高于其他3种算法, 文献[16]、文献[17]、文献[18]算法的波动幅度较大, 稳定性较差.实验证明, 本文算法在3种不同情形下的匹配精度均较高, 具有较优的图像匹配效果.
不同算法的图像匹配时间对比结果如图8所示.由图8可见, 本文算法在不同尺度变化、旋转变化和亮度变化时的匹配时间均保持在70 ms以下, 均明显低于文献[16]、文献[17]、文献[18]算法, 且波动幅度较小, 实验证明本文算法在3种不同情形下的匹配时间均较短, 图像匹配效率较高.
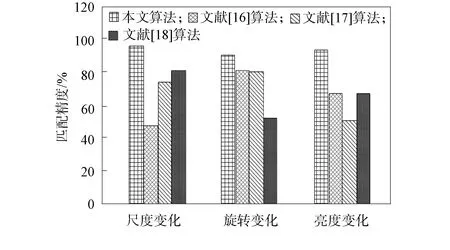
图7 不同算法匹配精度的比较Fig.7 Comparison of matching accuracy of different algorithms

图8 不同算法图像匹配时间比较Fig.8 Comparison of image matching time of different algorithms
在采集的视觉图像内随机选取同一目标不同光照下的图像, 利用4种算法对不同光照下的图像进行匹配, 测试4种算法匹配后图像的质量, 测试结果列于表1.由表1可见: 随着光照强度的不断提升, 4种算法的NU值均呈上升趋势, 本文算法的NU值明显低于其他3种算法, 说明本文算法匹配后图像的灰度分布更均匀;4种算法AG值均随光照强度的提升而下降, 本文算法的AG值均明显高于其他3种算法, 说明本文算法匹配后的图像清晰度更佳;4种算法的H值同样随光照强度的提升而下降, 本文算法的H值明显高于其他3种算法, 说明本文算法匹配后的图像细节更丰富.因此, 本文算法匹配后的图像质量最佳.
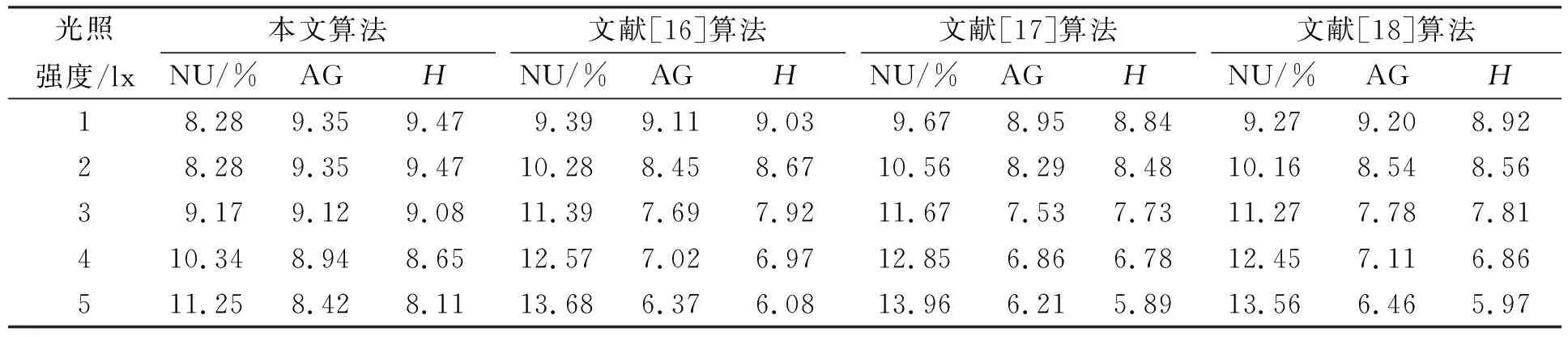
表1 4种算法匹配后图像质量测试结果
综上所述, 针对移动机器人采集的视觉图像存在清晰度不佳的问题, 本文提出了一种基于深度强化学习的移动机器人视觉图像分级匹配算法, 先利用深度强化学习粗匹配图像的颜色特征, 再在粗匹配的基础上, 通过改进SIFT算法精匹配图像, 获取更清晰的图像, 为后续图像分析提供更可靠的支撑.实验结果表明, 本文算法具有较优的匹配效果和匹配速度, 实际应用效果更好.
猜你喜欢
北京航空航天大学学报(2022年6期)2022-07-02 01:59:12
中国医疗保险(2017年6期)2017-07-18 11:28:19
计算机测量与控制(2017年6期)2017-07-01 16:23:31
制造技术与机床(2017年3期)2017-06-23 08:11:21
中国卫生(2016年5期)2016-11-12 13:25:50
中国卫生(2015年10期)2015-11-10 03:14:22
中国卫生(2015年6期)2015-11-08 12:02:44
集美大学学报(自然科学版)(2015年1期)2015-02-28 01:13:32
西安建筑科技大学学报(自然科学版)(2014年5期)2014-11-10 02:34:46
航天器工程(2014年4期)2014-03-11 16:35:37
