
果实目标深度学习识别技术研究进展
2023-03-07 07:20宋怀波尚钰莹何东健
农业机械学报 2023年1期
宋怀波 尚钰莹 何东健
(1.西北农林科技大学机械与电子工程学院, 陕西杨凌 712100;2.农业农村部农业物联网重点实验室, 陕西杨凌 712100)
0 引言
随着水果种植产业的迅速发展及劳动力资源的日益紧缺,开发智能化、自动化农业智能装备的需求在不断增加,果实采摘机器人已成为农业发展的重要方向[1]。利用机器人进行采摘作业不仅可以提高采摘效率且降低了劳动成本,有利于提高果农的经济效益[2]。实现自然场景下果实的准确识别与定位,可为果实采摘机器人的视觉系统提供关键的技术支持[3-4]。利用机器视觉技术对果实目标进行检测,对于果实的生长监测、产量预测[5-6]、果实分拣等任务也具有重要意义,是实施精准农业技术的重要步骤之一[7]。本文以果实采摘为例,对果实目标识别技术研究成果进行综述。
果实目标识别方法主要包括基于手工设计特征的传统识别方法和基于卷积神经网络(Convolutional neural network, CNN)的深度学习方法两种。传统目标检测算法主要包括区域选择、特征提取和分类3个步骤。传统目标检测算法相对成熟,然而,在复杂的自然场景下,果实目标检测任务仍存在难点:果实种类以及外观形态具有多样性;光照条件变化;复杂天气情况;复杂背景影响等。这些问题使得手工设计特征的过程更加复杂[8-9],且传统的目标检测算法存在检测精度较低、检测速度较慢、模型实时性较差、普适性不强等缺点,应用传统目标检测算法进行果实目标检测难以满足果实采摘机器人的实际作业要求。基于深度学习的果实目标检测模型是一种端到端的检测模型,可将目标的特征提取、特征选择和特征分类融合在同一模型中[10]。深度学习模型具有高度的层次结构和强大的学习能力[11],在复杂视觉信息与目标感知融合方面具有独特优势[12]。
虽然深度学习技术在果实目标识别方面取得了很好的效果和进展,然而距离实际作业应用还有一定的距离。如图1所示,本文对苹果、番茄、柑橘等28种果实的相关识别研究成果进行检索(图中没有标注数量的均为1),并以此为基础总结归纳国内外果实目标识别的研究进展、关键技术,分析果实目标识别任务存在的问题和面临的挑战,并对未来发展趋势进行展望,以期为果实目标识别任务的后续研究提供参考。

图1 引文中涉及到的果实种类及数量Fig.1 Species and quantity of fruit involved in citation
1 传统果实目标识别方法
传统的果实目标识别方法是基于颜色、几何形状、纹理等特征对果实目标进行分类、检测和分割[13]。基于颜色特征的果实目标识别方法主要通过选取合适的颜色模型,利用果实目标与背景区域的像素颜色特征差异,将果实目标与背景分开。利用YCbCr颜色模型对荔枝图像进行阈值分割,去除复杂背景,可实现荔枝果实与果梗的识别,综合识别率为95.50%[14]。基于归一化红绿色差的苹果分割方法可实现红色苹果与绿色背景的分割,然而当果实目标的颜色与背景颜色相似时,仅利用简单的颜色特征进行果实目标分割难以取得较好的效果[3]。以归一化的g分量和HSV颜色空间中H、S分量为特征参数的支持向量机(Support vector machine, SVM)分类器和以超绿算子(2G-R-B)为特征的阈值分类器,设计一种用于近色背景中绿色苹果目标识别的混合分类器,该方法平均识别正确率为89.30%[15]。
当果实目标与背景的颜色特征较为接近,或者光照条件对果实颜色的影响较大时,相比于颜色特征,利用果实与背景之间的形状和纹理特征的差异可以取得更好的分割效果。利用颜色、形状和纹理特征可识别自然环境中的绿色柑橘,其正确率为75.30%[16]。基于边缘曲率分析的重叠番茄识别方法对轻微遮挡的重叠番茄识别正确率为90.90%,对遮挡率在25%~50%之间的番茄目标的识别正确率为76.90%[17]。利用柠檬、柑橘等水果近球形的形态特征,结合其深度图像,实现对果实中心点的定位及果实图像的分割,可解决光照和近景色所造成的识别精度较低的问题[18]。
随着传统目标检测算法的不断发展,手工设计特征的算法性能逐渐趋于饱和[19],然而,传统目标检测算法仍存在以下局限性:在生成候选区域的过程易产生大量冗余区域;在复杂背景下,基于低级视觉线索设计的特征描述符较难提取具有代表性的语义信息[20]。所以,对于复杂场景下的果实目标检测,例如:背景较为复杂、目标之间存在严重遮挡、光照不均等情况,传统果实目标检测算法已不能满足需求,且传统目标检测算法在检测速度和模型大小方面均难以满足果实采摘机器人的要求,因此,基于传统方法的果实目标识别技术较难推广到实际应用领域。
2 基于深度学习的果实目标识别方法
深度学习是一种具有多层次表征的学习方法[21],深度学习方法通过引入多层感知器结构,利用低级特征形成高级特征,用于最终的目标检测任务[1]。与传统的目标检测算法相比,深度学习在图像分类、目标检测和识别方面优势明显。由于自然场景下的果实目标具有空间分布随机、存在重叠遮挡、形状多样等非结构化特征,而深度卷积网络可以自动从训练数据中学习特征。因此,深度学习方法可以在复杂的自然场景下表现出更加强大的果实目标识别能力。根据检测组件和目标区域的识别结果,深度学习模型可以分为分类检测模型和分割模型。如图2a、2b所示,分类检测模型包括图像分类和目标检测,目标检测的输出是目标类别及其边界框的区域,目标检测任务在完成图像分类任务的同时利用边界框反映目标的位置信息。图像分割是指根据图像属性与目标图像的一致性,对特征相对一致的目标图像进行分割,使同一子区域的特征具有一定的相似性和差异性[22]。分割模型需要精确的像素级掩码进行目标分割[12]。如图2c、2d所示,分割模型主要包括语义分割和实例分割,语义分割为每个像素分配特定的类别标签,但并不区分同一类别的多个对象,实例分割为每个目标分配单独的分类像素级掩码,可以区分同一类别的不同目标。学者们对于果实目标检测和分割的研究大多是基于在目标识别领域表现较好的网络模型,根据不同果实目标生长的自然环境以及果实目标本身的特点,对网络模型的输入端、骨干网络等结构进行改进,或是引入注意力机制、迁移学习、特征融合、密集连接等操作,以实现提高目标识别的效果,提高模型在复杂场景下的鲁棒性,或是实现模型的轻量化等目标。
2.1 数据集制备方法
图3为基于深度学习的果实目标识别及应用的基本步骤。首先是采集数据,通过对田间采集到的果实目标图像进行处理分析,以实现不同场景下、不同品种、不同生长阶段的果实目标识别任务。接着针对不同目标识别任务的特点进行数据预处理(数据集制备),该过程既包括利用图像增强技术进行图像的颜色、亮度、对比度等的调整,或对图像进行旋转、翻转、裁剪等操作,使输入到网络中的图像更适合于特定的目标识别任务或实现数据集规模的扩大,也包括对数据集进行标注,实现用于深度学习任务的标签文件制作。根据训练数据是否含有标签信息,可将训练过程分为监督学习、无监督学习和半监督学习3类。

图3 果实目标识别的基本步骤Fig.3 Basic steps of fruit target recognition
基于深度学习的目标识别任务需要一定规模的数据集进行训练,目前基于深度学习的果实目标检测方法大多是基于监督学习,通过向网络中输入一定数量的图像及其对应的标签文件进行模型训练,以提取目标的特征,实现目标识别任务。监督学习是解决分类和回归问题的常用方法[23]。对于田间果实目标识别任务,训练数据在一定程度上决定了目标检测任务的效果,其规模取决于果实图像的视觉复杂度和深度学习模型的种类。由于果实生长的田间环境较为复杂多变,该环境下采集到的果实目标可能存在遮挡、光照不均、果实目标大小不一、颜色变化等情况,网络的特征提取过程相对困难,因此需要较大规模的数据。对于网络结构较复杂、层数较深的网络,其精确度较高,然而也需要大量的训练数据[24],且对于不同品种果实的检测任务,都需制定合适的标注策略。
基于监督学习的数据标注过程耗时耗力,效率低下,且对某些特定的识别任务,数据标注过程需要相关专家提供指导。因此如何更有效地标记数据并使用更少的样本进行有效学习是目前该领域的关键问题。利用中小型数据进行半监督学习以获得高精度的结果,为此类研究提供了借鉴,半监督学习的训练数据中仅部分图像有对应的标签,且带标签的数据所占比例较小,通过从带标签的数据中提取到的局部特征进行图像分类[25]。
无监督学习可以完全脱离数据集标注过程,模型仅利用图像作为训练数据,其通过学习数据的结构,并从数据中提取可区分的信息或特征,将输入映射到特定输出[26]。聚类是最基本的无监督学习之一,其目标是将数据分成相似数据点的聚类[27]。因此,无监督学习在图像分割领域应用较多。尽管如此,监督学习仍然是目前的主流方法,关于半监督学习和无监督学习的研究相对较少。
2.2 基于深度学习的果实目标检测方法
目标检测任务可以分为目标定位和目标分类。随着计算机算力的提升和数据规模的不断扩大,基于深度卷积神经网络(Deep convolutional neural network, DCNN)的目标检测技术逐渐得到发展。自AlexNet[28]应用于图像分类任务并赢得ILSVRC-2012比赛冠军以来,诸多学者开始致力于DCNN的研究和应用。图4为基于深度学习的目标检测算法的发展历程,图中橙色箭头表示无锚框目标检测算法。基于深度学习的目标检测主要分为两大类:两阶段检测和单阶段检测。两阶段目标检测将目标定位和目标分类任务分离开,首先生成候选区域,再对区域进行分类。其代表算法有R-CNN[29]、SPPNet[30]、Fast R-CNN[31]、Faster R-CNN[32]等。单阶段目标检测省去了生成候选区域的过程,直接生成目标的类概率和位置坐标,其过程比两阶段目标检测简单。单阶段目标检测的代表算法有SSD系列、YOLO系列等。

图4 基于深度学习的目标检测算法发展历程Fig.4 Development of object detection algorithm based on deep learning
2.2.1两阶段果实目标检测方法
两阶段检测方法又称为基于候选区域的检测方法。将传统的机器学习方法与CNN相结合,提出一种基于R-CNN的检测框架,通过选择性搜索获得尽可能多的候选区域,利用CNN代替人工提取区域的特征并使用SVM进行分类。SPPNet引入自适应大小的池化,其运行速度比R-CNN更快。Fast R-CNN利用兴趣池化区域(Region of interest Pooling, RoI Pooling)层代替空间金字塔池化(Spatial pyramid pooling, SPP)层,加快了模型的速度。由于SPPNet和Fast R-CNN生成的候选区域数量过多,导致了大量的计算消耗,因此其应用场景受到了限制。一种区域生成网络(Region proposal network, RPN)方法用于生成候选区域,其输入为骨干网络输出的特征图,输出为一组矩形的候选区域,且每个区域均有一个目标得分[33]。
Faster R-CNN模型用RPN取代Fast R-CNN中的选择性搜索,且通过网络共享的方式生成候选区域,利用Softmax分类器完成训练和学习过程,其检测性能有了大幅提高,被广泛地应用于目标检测任务。Faster R-CNN算法由特征提取器、RPN和Fast R-CNN模块构成。首先对输入网络中的图像进行特征提取,再将提取到的特征输入RPN和Fast R-CNN,生成建议矩形框。如文献[7,33],利用Faster R-CNN模型可实现自然场景下的柑橘果实和芒果花穗的检测,然而其mAP均相对较低,检测效果不理想。
利用迁移学习的模型对Faster R-CNN的模型结构进行改进,可以提高模型的泛化性能和检测精度。如文献[34],利用迁移学习训练基于Faster R-CNN的柑橘目标识别模型,可有效降低训练模型的平均损失,且模型平均准确率较高。文献[35]利用迁移学习微调的AlexNet网络替换Faster R-CNN原始的特征提取层,可解决广域复杂环境中的猕猴桃因枝叶遮挡或部分果实重叠遮挡所导致的识别精度较低的问题。
为了提高检测准确率,降低目标的漏检率,同时提高模型在目标存在遮挡、目标形态和大小存在差异等复杂场景下的鲁棒性,一些学者对Faster R-CNN算法进行了改进。基于数据平衡进行数据扩增,可解决Faster R-CNN模型检测不同成熟度冬枣的样本数量相差悬殊导致的识别率较低的问题[36]。利用预训练的VGG16网络替换Faster R-CNN原始的特征提取层,并改进RPN的结构,可提高模型对在体青皮核桃和苹果果实的检测精度的漏检率[37-38]。将兴趣区域校准引入Faster R-CNN框架,可提高Faster R-CNN模型对不同形态刺梨的检测精度[39]。融合RGB图像和深度信息,并融合全局和局部信息,可提高Faster R-CNN对小目标百香果的检测效果[40]。
用于目标检测的基于区域的全卷积网络(Region-based fully convolutional networks, R-FCN),由共享的全卷积网络构成,可实现整个图像上的共享计算,有效减少了参数冗余,并引入位置敏感分数图解决了图像分类中的平移不变性与目标检测中的平移可变性间的矛盾,该模型具有较快的训练和检测速度[41]。利用ResNet-44替换R-FCN的原始特征提取网络,可有效识别重叠、枝叶遮挡、模糊及表面有阴影的苹果目标,并简化网络结构[42]。两阶段果实目标检测算法的相关研究成果如表1所示。
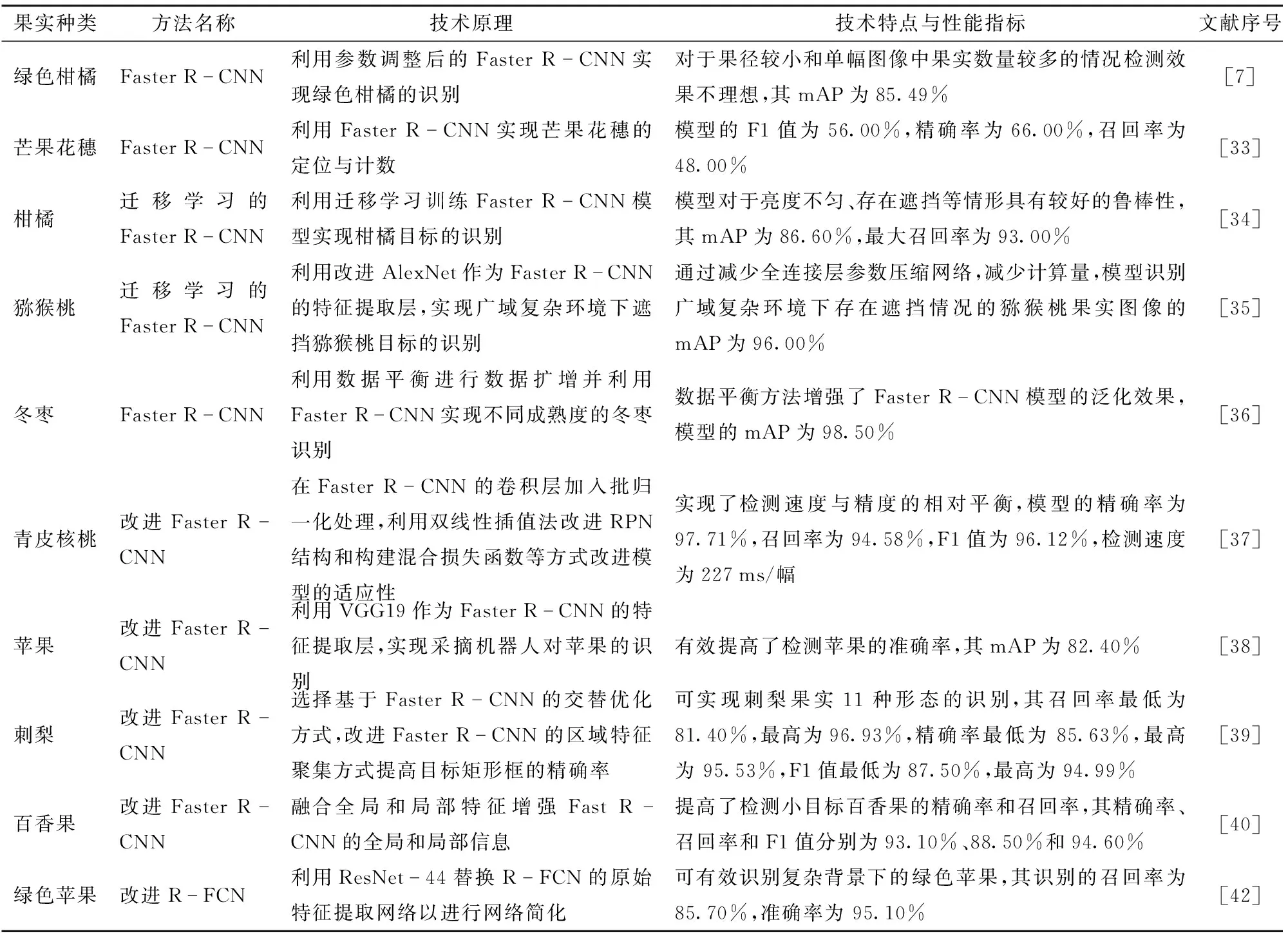
表1 基于两阶段算法的果实目标识别研究成果Tab.1 Research on fruit target recognition based on two-stage algorithm
2.2.2单阶段果实目标检测方法
虽然两阶段目标检测算法的检测精度较高,但其参数数量和计算量较大,检测速度较慢,难以完成实时检测任务,影响了采摘机器人的工作效率。
表2列出了基于单阶段目标检测算法的果实目标识别研究成果。单阶段目标检测算法又称为基于回归的检测方法。LIU等[17]提出了一种利用单个深度网络进行目标检测的SSD模型,其核心是利用小型卷积滤波器进行多尺度特征映射,生成并预测固定的默认边界框的类别得分和偏移量。由于SSD模型实现了端对端的训练,其具有易于训练和集成的优点,与两阶段检测方法相比,SSD基本实现了检测速度与精度的相对平衡,因此被广泛地应用于果实目标检测任务。利用ResNet-101模型替换SSD的原始主干网络,可实现苹果、荔枝等4种水果的识别,且该模型的检测精度高于原始SSD模型[43]。SSD模型采用特征金字塔来检测不同尺度的目标,然而由浅层网络生成的小目标特征缺乏足够的语义信息,导致其对小目标的检测性能较差。FSSD[78]是一种增加了特征融合的SSD模型,该模型在传统SSD的基础上增加一个轻量级、高效的特征融合模块,对不同比例的特征图进行融合,以提升对小目标的检测性能。基于改进的轻量化FSSD模型可实现灵武长枣的检测,该方法可为灵武长枣的智能化采摘提供一定的技术支持[44]。基于多重特征增强与特征融合的MFEFF-SSD模型可实现无人机拍摄图像中小目标荔枝的检测,然而该方法存在误检和漏检的情况[45]。基于改进FSSD的柚子目标检测模型可有效改善绿叶被误检为膨大期柚子果实的情况[46]。
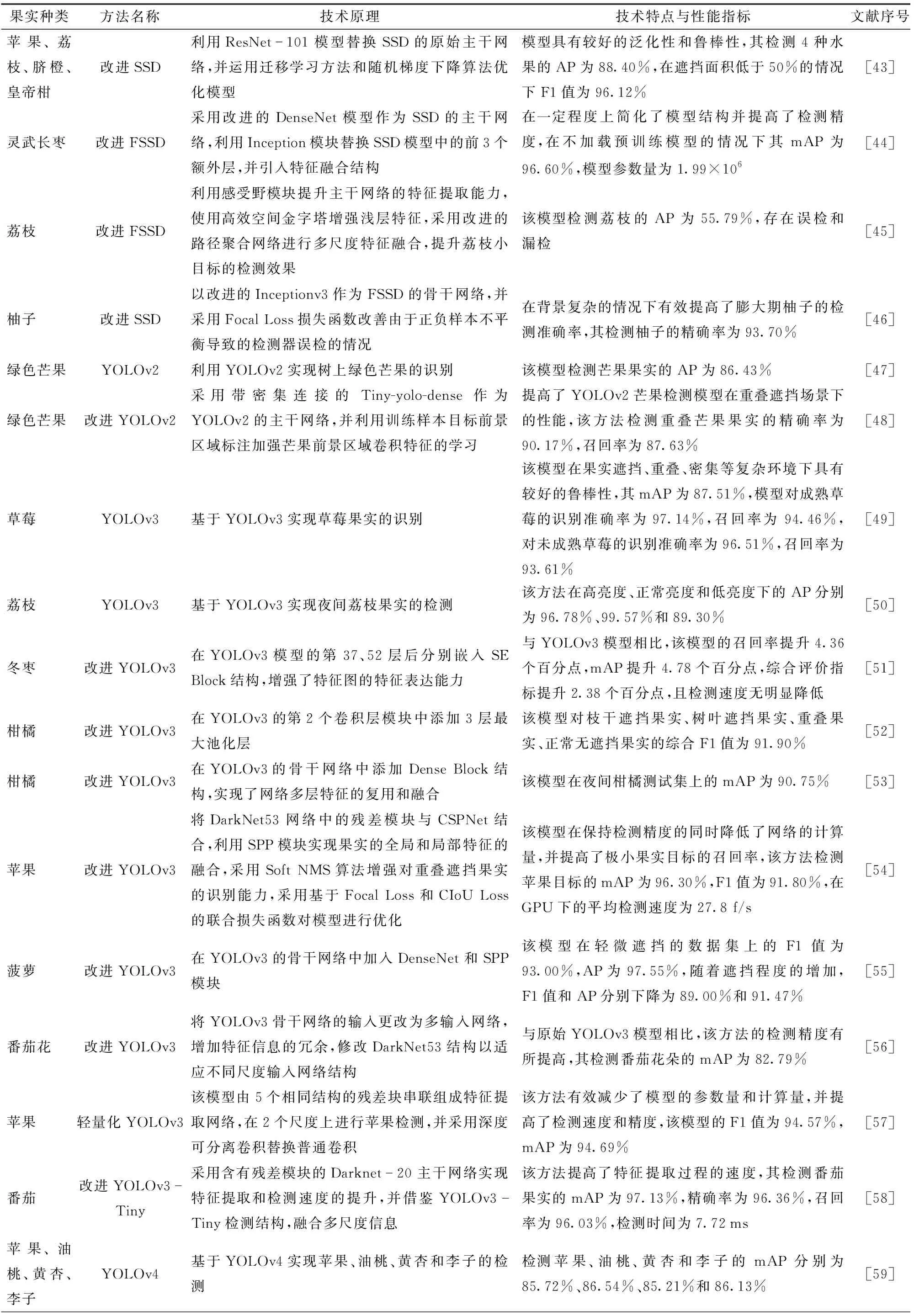
表2 基于单阶段算法的果实目标识别研究成果Tab.2 Research on fruit target recognition based on one-stage algorithm

续表2
YOLO(You only look once)是REDMON等[79]在2015年提出的一种目标检测算法,它是深度学习时期的第一个单阶段目标检测算法。YOLO将目标检测任务看作单一的回归问题,仅用单个网络便可实现多个边界框的位置和类别预测。YOLO检测速度快,对背景的误检率较低,且泛化性能较好,然而,YOLO算法存在以下局限性:YOLO的每个网格只能有两个预测框并预测一个类别,因此其对小目标的检测性能较差;YOLO从大量的训练数据中提取目标的特征,若测试数据中目标的长宽比与训练数据有较大不同,则网络检测效果欠佳;损失函数无差别地处理大小边界框的误差,大边界框的误差和小边界框的误差对交并比(Intersection over union, IoU)的影响差异较大。
YOLOv2[80]在YOLO的基础上对损失函数、骨干网络等进行改进,同时引入了锚点框、批量归一化、高分辨率分类器等结构,YOLOv2在检测速度、准确率等方面均有较大提升。基于YOLOv2可实现绿色芒果的检测,在图像中包含的芒果数量较多或者光线较暗的情况下,其检测效果不理想[47]。对于存在遮挡或重叠的目标,YOLOv2的检测效果有待提高。采用带密集连接的Tiny-yolo-dense作为YOLOv2的主干网络,可提高YOLOv2芒果检测模型在重叠遮挡场景下的性能,然而该方法需要复杂的前景区域标注过程[48]。
YOLOv3[81]引入了特征金字塔网络(Feature pyramid network, FPN)[82]和ResNet[83]结构,同时采用DarkNet53作为骨干网络,增加了多尺度预测结构,使网络的检测精度得到了提升。利用YOLOv3可实现复杂环境中草莓和荔枝的检测,然而该方法的效果受到光照强度的影响。由于果实生长的自然环境较为复杂,枝叶和果实间的遮挡、复杂的光照情况等为果实目标的准确检测带来困难,针对复杂场景中的果实目标检测以及小目标果实的检测,YOLOv3的检测性能尚需提高,对YOLOv3模型进行改进可以提高模型在复杂环境下的识别效果。利用YOLOv3-SE网络模型可实现枝叶遮挡、果实密集重叠等复杂场景下的冬枣识别[51]。为实现柑橘采摘机器人的识别定位,在YOLOv3模型中增加最大池化层可增强模型对采摘场景的理解,提高柑橘目标识别的准确率[52]。如文献[53-56],利用DenseNet、CSPNet和SPP模块等对YOLOv3的骨干网络进行改进,可提高其在夜间环境、遮挡目标和小目标等复杂场景下的检测性能。由于DarkNet53的网络层数过多,导致网络的运算量较大,检测速度较慢,对于一些场景较为简单的果实目标检测任务,可以通过简化网络层数以减小模型复杂度并提高检测速度。如文献[57-58],通过精简YOLOv3的骨干网络,可简化目标检测的特征图尺度,实现模型的轻量化,且模型在检测速度和准确率方面均有显著提高。
YOLOv4的输入端引入了Mosaic数据增强操作,其骨干网络在DarkNet53的基础上融合了CSPNet,采用SPP和FPN+路径聚合网络(Path aggregation network, PAN)作为瓶颈结构,并采用CIoU_loss作为预测端的损失函数[84],与YOLOv3相比,其检测速度和准确率都有了较大提升。利用YOLOv4可实现自然场景下苹果、油桃、黄杏、李子及香蕉串检测[59-60]。为提高YOLOv4网络在复杂场景下的果实识别效果,一些学者将颜色空间模型、残差神经网络、递归特征金字塔和视觉注意机制等与YOLOv4网络相结合,在一定程度上提高了模型的检测性能。基于YOLOv4+HSV的成熟番茄识别方法可解决遮挡和光照不均引起的番茄目标误识别的问题[61]。一种融合残差神经网络和YOLOv4的番茄检测方法可解决自然环境中光照变化、背景干扰和叶片遮挡等因素对番茄采摘机器人的检测精度的影响[62]。一种基于特征递归融合YOLOv4网络的FR-YOLOv4检测模型可实现自然场景下密集分布的小目标春见柑橘的检测和计数[63]。如文献[64-66],将SE模块、CBAM视觉注意机制等与YOLOv4模型相结合,可实现低质量苹果幼果、不同颜色和品种的苹果果实检测。
YOLOv4-Tiny对YOLOv4的网络结构进行了精简,YOLOv4-Tiny采用CSPDarkNet53-Tiny作为骨干网络,并将YOLOv4中的Mish激活函数修改为Leaky_ReLU激活函数。YOLOv4-Tiny模型的参数量更少,网络结构更简单,且检测速度更快[67]。利用CBAM视觉注意机制对YOLOv4-Tiny模型进行改进,可实现复杂环境下番茄和蓝莓果实的快速识别,并有效解决遮挡、逆光和小目标识别准确率低的问题[67-68]。通过减少YOLOv4-Tiny草莓检测模型的骨干网络中CSPNet模块的数量和精简CSPNet的网络结构,可进一步简化模型,提高模型的检测速度[69]。另一种简化YOLOv4模型的方法是进行通道剪枝,其本质是通过识别网络的通道来消除不重要的通道及其相关的输入和输出关系[85],简化后的模型可以减少需要存储的参数数量,并且具有较低的硬件要求,使其更易于部署在嵌入式设备和移动终端等小型计算平台上[86]。利用通道剪枝的YOLOv4可实现自然场景下的苹果花朵实时准确检测,剪枝后模型的检测精度基本不变,但模型的参数量和尺寸得到大幅压缩,且检测速度有较高的提升[70]。
YOLOv5的输入端引入了自适应锚框计算,以适应不同尺寸的目标,YOLOv5的骨干网络中引入了切片操作,并将CSPNet同时应用于骨干网络和瓶颈网络,YOLOv5的输出端采用了GIoU_loss损失函数。YOLOv5包含5种体系结构,分别为YOLOv5-nano、YOLOv5s、YOLOv5m、YOLOv5l和YOLOv5x,其主要区别在于特征提取模块和卷积核在网络特定位置的数量不同。与YOLOv4相比,YOLOv5的检测速度和精度都有较大的性能提升。如文献[71-73],利用YOLOv5s目标检测模型可以实现自然场景下的柑橘、苹果花朵、油茶果的准确快速检测,模型具有较好的鲁棒性,且模型的尺寸较小,适用于模型迁移。通过优化YOLOv5的损失函数,可有效提高模型对于遮挡番茄目标的识别准确率[74]。对YOLOv5模型的骨干网络进行简化或引入视觉注意机制模型,可在一定程度上减小模型的尺寸并提高其目标识别的效果。利用Transformer模块对YOLOv5的骨干网络进行改进,并利用BiPFN改进其Neck结构,可提高樱桃果实的识别准确率[75]。利用Bottleneck模块对YOLOv5m的骨干网络进行改进,并引入SE视觉注意机制模块,可提高模型对苹果目标的检测速度和精度[76]。
2.2.3无锚框目标检测算法
自从RPN提出以来,基于锚框的目标检测算法已经成为目标检测模型的主流,且取得了较好的检测效果。然而,基于锚框的检测器存在以下的缺点和局限性:为实现高召回率,基于锚框的检测器需要设计各种尺度和形状的锚框,以覆盖图像中不同尺度和形状的物体,这些冗余的锚框在训练时大多会被标记为负样本,导致训练中的正负样本不均衡;锚框的尺寸、长宽比、数量等参数设置决定了检测器的性能,因此锚框的设计过程较为复杂,且训练结果可能受到人为经验的影响;大量的锚框会增加整个检测过程的计算成本。
为了克服基于锚框的检测器的缺点,基于无锚框检测器的目标检测算法逐渐兴起,无锚框检测器不需预先设定锚框,直接对图像进行目标检测。YOLOv1是目标检测领域最早的无锚框模型,它将目标检测视为一个空间分离的边界框和相关概率回归问题,可直接从图像中预测边界框的位置和分类概率。该方法运算速度较快,但其召回率较低,且检测精度不理想。如图5所示,无锚框检测可大致分为两类:基于锚点检测和基于关键点检测[87]。锚点检测器通过将真实框编码为锚点,锚点是特征图上的像素点,其位置与特征相关联,其代表算法有CenterNet[88]、FCOS[89]、FoveaBox[90]等。关键点检测器通过预测包围盒中的几个关键点的位置,如角点、中心或极值点,将关键点解码到预测框中,其代表算法有CornerNet[91]、ExtremeNet[92]等。
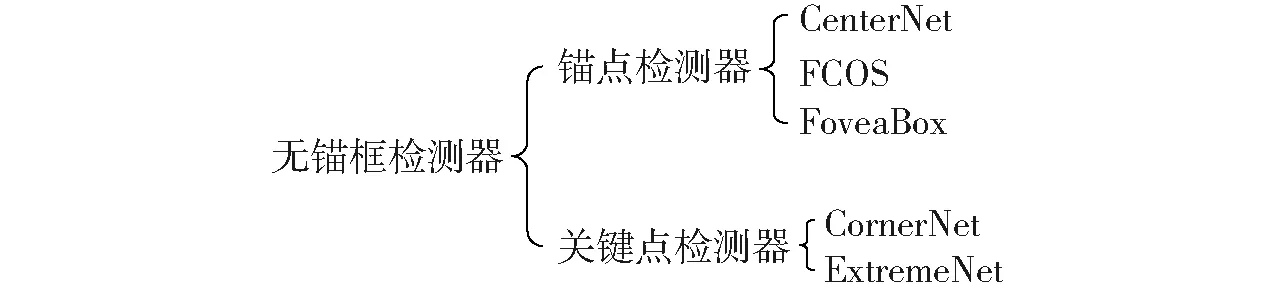
图5 无锚框检测器分类Fig.5 Classification of anchor-free detector
表3列出了无锚框目标检测算法的果实目标识别研究成果。对FCOS的骨干网络和损失函数进行改进实现自然场景下的苹果果实检测,可在提高检测性能的同时降低正负样本比例失衡带来的误差[93]。利用残差特征金字塔网络对FCOS的骨干网络进行改进,可实现光照变化和阴影重叠条件下的绿色苹果识别[94]。改进FoveaBox模型的骨干网络和特征提取网络可以提高模型对不同规模的绿色苹果的召回率[95]。利用Tiny Hourglass-24网络对CenterNet的骨干网络进行改进可实现密集场景下的多苹果目标的快速识别,然而该方法对于重度遮挡和果实表面亮度较高的情景存在个别目标漏检的情况[96]。利用改进的MobileNetv3作为CenterNet模型的骨干网络实现苹果目标的识别,可以在保证检测精度的前提下减小模型的尺寸并提高其检测速度[97]。

表3 基于无锚框算法的果实目标识别研究成果Tab.3 Research on fruit target recognition based on anchor-free algorithm
YOLOX[101]是YOLO的无锚框版本,其沿用了YOLOv4的特征提取网络CSPDarknet和YOLOv5的Mosaic增强技术,并创新了解耦检测头、无锚框和SimOTA标签分配策略[102],YOLOX模型的设计简单,且性能更具优势。利用YOLOX可实现冬枣的高精度检测和计数[98]。通过改进YOLOX-S的激活函数和损失函数,并转移浅层特征,可实现小目标猕猴桃的检测,该方法在减小了模型参数量的同时提高了模型的检测精度[99]。利用加入CBAM的轻量级网络ShuffleNetv2对YOLOX-Tiny的骨干网络进行改进,可实现对苹果果实的高精度和实时性检测[100]。
2.3 基于深度学习的果实目标分割方法
2.3.1基于深度学习的语义分割模型
语义分割是将图像的每个像素分配给预定义类别集合中的相应类别标签的任务,其目的是对图像中的每一个像素点进行分类。用于目标识别的CNN网络通常由卷积层、池化层和全连接层组成。然而,全连接层会损失目标的位置信息,因此CNN无法完成目标的分割任务。全卷积网络(Full convolutional networks, FCN)[103]是基于深度学习的语义分割模型的重要成果,通过将CNN网络中的全连接层替换为卷积层,得到全部由卷积层构成的FCN,与CNN相比,FCN可同时保留目标的位置信息和语义信息,可在像素层次上进行分类,完成目标分割任务。
RONNEBERGER等[104]提出的U-Net网络被广泛地应用于语义分割任务,U-Net包括编码器和解码器结构,编码器网络利用池化层进行下采样操作,其作用是进行特征提取,解码器网络利用反卷积进行上采样操作,编码器部分与解码器部分近似对称,整体网络呈“U”形结构。在上采样的过程中,利用跳跃连接操作可以将该级的特征图与编码器结构中其对应位置的特征图进行融合,使得解码器能够获取更多高分辨率特征,有利于提高分割精度。利用U-Net可实现苹果目标的分割,结果表明,当果实可以通过颜色区分时,传统分割算法的效果优于U-Net,当测试集数据与训练集相似时,U-Net的分割效果较好[105]。
CHEN等[106]结合深度卷积网络和概率图模型(DenseCRFs),提出了DeepLab语义分割模型,DeepLab以VGG-16为基础网络进行改进,首先将VGG-16的全连接层替换为卷积层,并移除原网络的最后两个池化层,使用空洞卷积进行上采样,在扩大了感受野的同时减小了参数量。DeepLabv2[107]对DeepLab进行了改进,DeepLabv2以ResNet101模型作为基础网络,并引入带有空洞卷积的空间金字塔结构(Atrous spatial pyramid pooling, ASPP),在多个尺度上进行图像分割,可以处理不同尺度的目标,与DeepLab相比,DeepLabv2的分割精度有所提升。SUN等[108]利用DeepLab-ResNet实现了苹果花、梨花和桃花的目标分割,该模型的平均F1值为80.90%。DeepLabv3[109]分别利用ResNet101和Xception作为骨干网络,并将深度可分离卷积应用于ASPP结构,在保持性能的同时有效降低了模型的计算复杂度。利用ResNet和DenseNet结构对DeepLabv3的骨干网络进行改进,可实现荔枝花朵的分割[110]。KANG等[111]提出了一种用于苹果语义分割的DasNet网络,该模型尝试分别利用ResNet-50、ResNet-101和轻量化网络LW-net0作为骨干网络,利用门控特征金字塔网络进行多级特征的融合,并采用ASPP增强目标的多尺度特征提取。结果表明,以ResNet-101为骨干网络的DasNet模型在语义分割和目标检测任务中表现最好,其检测苹果目标的F1值为83.20%,其分割苹果目标的F1值为87.60%。
2.3.2基于深度学习的实例分割模型
实例分割是将语义标签和实例标签分配给所有像素,以分割对象实例,实例分割可以提供比语义分割更详细的图像信息,例如检测对象的位置和数量。 其中Mask-R CNN为果实目标实例分割中最具代表性的算法。表4列出了利用基于深度学习的实例分割算法进行果实目标识别的研究成果。

表4 基于深度学习的实例分割算法的果实目标识别研究成果Tab.4 Research on fruit target recognition based on deep learning instance segmentation algorithm
HE等[122]提出了一种用于实例分割的Mask R-CNN网络,该网络通过在Faster R-CNN中添加一个用于预测目标掩码的并行分支实现。在非结构化环境中,Mask R-CNN不仅能准确识别目标类别并用边界框标出目标区域,还能在像素级别上从背景中提取目标区域。Mask R-CNN由3个阶段组成,首先利用ResNet骨干网络从输入图像中提取特征图;其次,特征图被输入到RPN用以生成候选区域;最后,这些候选区域被映射到原始图像中像素点对应的位置,以在共享特征映射中提取相应的目标特征,然后分别输出到全连接层和FCN,用于目标分类和实例分割。
如文献[112-115],基于Mask R-CNN可实现草莓果实、苹果果实、葡萄串和柑橘类果实的目标分割,且该方法在复杂场景下具有较好的鲁棒性。对于部分农业场景中数据量不足的问题,如文献[116],利用迁移学习预训练的Mask R-CNN模型可提高对自然场景下番茄果实的分割精度。如文献[117-118],利用ResNet、DenseNet等网络对Mask R-CNN的原始骨干网络进行改进,可实现重叠、遮挡等情况下苹果目标的精确分割。通过融合RGB图像、深度图像、红外图像等多源信息,对图像的颜色、形状空间位置等特征进行深度挖掘,可提高Mask R-CNN分割目标的准确率和鲁棒性。如文献[119-120],融合深度图像或红外图像等多源信息作为Mask R-CNN的输入,可提高模型对番茄果实的定位精度并提高模型的鲁棒性。
基于DasNet语义分割模型,在其FPN结构中添加实例分割的分支,开发一种用于进行苹果果实实例分割的DasNet-v2网络[121],该模型在田间实地测试中表现出优良的性能。
2.4 基于轻量化模型的果实目标识别方法
自然场景下的果实目标识别任务存在遮挡、光照不均等一系列挑战。为提高果实目标识别任务的精度,基于深度学习的果实目标识别网络在不断加深,以适应越来越复杂的目标检测任务。然而,随着网络深度的加深,模型的参数量和计算复杂度也在不断上升,模型大小和计算成本的爆炸性增长为模型在嵌入式设备上的部署带来了新的挑战[123-124]。目前,研究人员致力于研究轻量化的目标检测网络,以兼顾模型的移植部署、检测速度和检测精度,以期为果园采摘机器人的发展提供技术支持。
依据网络的结构层次,可以将网络的轻量化划分为模型的轻量化设计和模型压缩两大类,图6列出了常用轻量化模型和模型压缩的方法。

图6 网络轻量化的常用方法Fig.6 Common method of network lightweight
模型压缩是在原有模型的基础上进行修改,而轻量化模型则是在设计模型时就遵从轻量化的思想,例如采用深度可分离卷积、分组卷积等卷积方式,减少卷积的数量、增加网络的并行度、减少网络的碎片化程度等[125]。相比于模型压缩,轻量化模型的设计能够更大程度地减小模型的参数量和计算量,并提高模型的检测速度,因此轻量化模型是未来目标检测算法用于嵌入式设备移植和移动端的主要发展方向。如图6所示,近年来表现优秀的轻量化网络主要有SqueezeNet[126]、MobileNet系列、ShuffleNet系列、GhostNet[125]等。表5列出了基于轻量化模型的果实目标识别研究成果。

表5 基于轻量化模型的果实目标识别研究成果Tab.5 Research on fruit target recognition based on lightweight model
IANDOLA等[126]提出的SqueezeNet是最早的轻量化模型设计,SqueezeNet使用了新的网络架构“Fire模块”,整个SqueezeNet网络由若干“Fire模块”的堆叠组成。“Fire模块”由压缩层和扩展层组成,其中压缩层仅由1×1的卷积核组成,扩展层由1×1和3×3的卷积核组成,Fire模块的设计大大减少了模型的参数量和计算量,SqueezeNet的模型占用内存为0.5 MB。
HOWARD等[134]基于深度可分离卷积提出了MobileNet轻量化模型。该模型由深度可分离卷积与普通卷积模块堆叠组成,深度可分离卷积是将普通卷积拆分为深度卷积和逐点卷积的操作,利用深度可分离卷积可大大降低网络的计算量。以MobileNet模型分别替换YOLOv4和SSD的骨干网络,可实现龙眼果实的检测,其中MobileNet-YOLOv4模型具有更好的泛化性能[127]。MobileNetv2[135]网络中引入了线性瓶颈结构和倒残差结构,进一步压缩了模型占用内存。利用MobileNetv2对YOLOv3检测模型的骨干网络进行改进,可实现酿酒葡萄和柑橘的检测,与原始YOLOv3模型相比,该方法可在保证检测精度的情况下大幅提升检测速度并压缩模型的尺寸[128-129]。MobileNetv3[130]在MobileNetv2的倒残差结构的基础上加入了SE注意力模块和h-swish激活函数,并精简了卷积层的结构,同时引入了NAS模块搜索和NetAdapt层搜索结构进行网络结构的优化,与MobileNetv2相比,其准确率更高且减少了延迟。利用MobileNetv3模型可实现香蕉、柠檬、柑橘等水果的检测,其检测精确率和检测速度均优于Xception和DenseNet模型[130]。利用MobileNetv3对YOLOv4检测模型的骨干网络进行改进,开发一种YOLOv4-MobileNetv3轻量化模型,可实现火龙果、密集圣女果和苹果果实的准确快速识别,该方法在检测速度和模型尺寸方面具有显著优势[131-133]。
ZHANG等[137]提出了ShuffleNet轻量化模型,该模型提出了逐点组卷积和通道混洗操作,利用逐点组卷积降低模型的计算复杂度,并利用通道混洗操作解决组卷积造成的信息交互问题。对于一定的计算复杂度,ShuffleNet可以保证更多的特征映射信道,提高模型的性能。在此基础上,ShuffleNetv2[138]模型引入了通道分裂(Channel split)操作,在保证模型准确率的同时进一步降低了模型复杂度,提升了模型运行速度。
HAN等[125]提出了GhostNet轻量化模型,其基础模块为“Ghost Module”,Ghost模块可以通过生成“影子”特征图来减少卷积操作,进而减小模型的计算量,GhostNet的准确率高于MobileNetv3,且其模型的计算复杂度小于MobileNetv3。且Ghost Module可用于替换许多经典目标检测网络中的普通卷积模块,以减小模型的参数量和计算量,目前Ghost Module应用于简化果实目标检测模型的研究较少,该方法可为果实目标检测模型的轻量化提供新的研究思路。
3 存在的挑战和未来趋势展望
3.1 存在的挑战
基于深度学习的果实目标识别研究取得了一定的研究成果,然而距离模型的实际应用仍存在以下难点:
(1)大规模数据集的获取存在一定困难。为提高模型的准确率,果实目标识别任务中要求采集的数据样本数量足够大,为提高并验证模型的鲁棒性,数据集中的图像还应该包含有无遮挡、枝干叶片遮挡和不同果实目标间的遮挡、不同的光照情况、图像中包含单目标和多目标果实等情况。由于果实生长的自然环境复杂多变,存在许多人为不可控因素,且果实生长具有一定的周期性,必须在特定的时间段完成图像采集任务,因此大规模数据的采集是目前果实目标识别任务的难点之一。
(2)提高模型在复杂场景下的稳定性、泛化性和鲁棒性。由于采摘机器人作业的自然环境中存在各种复杂多变的情景,用于果实目标检测的模型需要兼具较高的稳定性、泛化性和鲁棒性,才能保证其稳定的作业效果和较高的作业效率。因此,在保证识别准确率的同时提高模型在复杂场景下的表现性能是目前目标识别领域的难题。
(3)提高模型的通用性。由于田间生长的果实目标在不同的生长阶段具有不同的颜色和大小,因此研发通用性较高的果实目标识别模型有利于进行果实的生长监测和提高采摘机器人决策的准确性。
3.2 未来研究趋势展望
(1)由于数据采集和标注任务需耗费大量的时间和人力,且大规模的数据采集任务存在一定的困难,利用较少的样本数据进行模型训练并减小标签数据的数量,对于降低人工成本和提高检测的灵活性非常重要[28]。而目前对于小规模数据集的模型、半监督和无监督模型用于果实目标检测的研究相对较少。因此,小规模数据模型和弱监督模型将是未来果实目标识别模型的发展方向。
(2)针对轻量化模型设计,部分学者已经进行相关研究并取得了一些进展,在保证识别精度的前提下,用于嵌入式设备的模型不仅要求较小的模型尺寸,还应该保证较快的检测速度以实现实时检测。因此,后续的研究应着重于提高轻量化模型在算力有限的嵌入式设备上的检测速度,开发可用于边缘设备进行实时准确检测果实目标的模型。
猜你喜欢
中等数学(2022年2期)2022-06-05
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
小学生学习指导(低年级)(2020年6期)2020-07-25
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
小学生学习指导(低年级)(2018年9期)2018-09-26
疯狂英语·新读写(2018年2期)2018-09-07
