
一种基于注意力机制的低光照下行人检测算法
2023-03-06 13:07师后勤张梦钰
物联网技术 2023年2期
师后勤,谢 辉,张梦钰,姜 凌,陈 瑞
(南京工程学院 信息与通信工程学院,江苏 南京 211167)
0 引 言
行人检测是计算机视觉研究中的热门和难点之一,它与其他技术结合可实现行人跟踪、行人重识别等更高级的应用。检测行人时除了要考虑行人的姿态和形状、摄像头的角度之外,还面临着视野遮挡、光线等不确定因素的影响,使行人检测具有挑战性。也因为摄影环境和设备问题,总会产生一些较低质量的图片。比如清晰度降低、色彩失真、失焦/跑焦等问题。为了后期改善图像处理的品质,设计高效的低照度增强算法十分必要。这些增强技术的使用范围广泛,且市场前景广阔。比如,视频监测、行人侦测、汽车自动驾驶。针对低光照下图像质量差的问题,研究者提出了各种解决方法,如基于去雾算法的模型也被尝试用于增强低光照图像,还有一些基于Retinex理论的传统方法在可控条件下具有较好的视觉效果,但应用于实际场景时,受限的建模能力导致图像噪声和颜色失真。基于上述问题,可基于分量增强,提升光照增强性能,同时融合注意力机制的光照鲁棒目标跟踪算法。
1 相关工作
随着科学技术的快速发展和社会生活的需要,目标检测被各个领域所需要,其中行人检测的需求在生活中占据很大比例[1]。如自动驾驶、视频监控等。依托科技的成熟,应用场景的多元化,行人检测技术被研究者不断优化,大致可分为三类:
(1)基于候选区域的two-stages方法,如faster RCNN;
(2)基于回归的one-stage方法,如YOLO系列;
(3)基于深度可分离卷积的轻量级深度神经网络,如MobileNet[2]。
本文采用YOLOv3进行行人检测。YOLOv3[3]是基于回归的目标检测算法,图像特征提取采用创建的深度残差网络DarkNet53,后采用区域推荐网络中的锚点机制,并将多个尺度融合,结构如图1所示。

图1 YOLOv3多尺度预测部分结构
YOLOv3算法借鉴了YOLOv1和YOLOv2,虽然缺乏明显的创新点,但在保留YOLO家族[4-6]速度优势的同时,提高了检测准确度,特别是对小物体的检测能力。YOLOv3算法使用一个单独神经网络作用在图像上,将图像划分为多个区域并且预测边界框和每个区域的概率。YOLOv3算法避免了细小问题的漏检,故本文基于该算法进行改进。
低光照图像是指在光照度低、光线不理想环境下获得的图像。低光照环境下的目标存在可见度低、信噪比低、色彩缺失等问题,导致图像在现有目标检测技术之下出错率高,甚至无法检测目标。此时,基于图像信息传达的高层计算机视觉任务失效,如行人检测、人脸识别、视频监控和医疗图像处理等。提高低光照环境下的图像识别精度可以采用一些物理方法,例如:购买高清摄像机或延长图像拍摄曝光时间等物理方法。但采用物理方法会大大增加目标检测成本,严重的话还会导致采集的目标图像出现过曝光或重影现象。因此,低光照图像增强即基于软件方法提升采集的低照度图片质量,恢复图像隐含信息内容的表达,已成为计算机底层视觉研究领域的重要研究内容。
对于低光照图像增强,各领域的研究者提出了有效的解决方法。其中最典型的是伽马变换及LLNet算法,但此算法缺少对像素间关系的思考,处理过后的图像容易出现曝光过少或过多的现象。因此出现了Retinex模型[7],这是受人类视觉注意力启发而出现的物理模型,用Retinex网络进行图像增强,提高图像的识别度。该算法简单易行,处理图片的速度快,精确度高,能有效提高目标检测的正确率,被广泛应用于目标检测领域。
2 本文算法
如前所述,YOLOv3目前还存在一些问题,例如anchor机制中的超参比较难设计,以及冗余框非常多。为了提高检测率,本文将注意力机制引入YOLOv3检测框架,再结合低光照图像增强方法,对行人目标进行检测,提高检测算法的光照鲁棒性。算法的总体框架如图2所示。

图2 算法框架
2.1 低光照图像增强
Retinex是研究者通过模仿人类视觉系统而发明的一种算法,Retinex已从单尺度算法发展到现在的多尺度算法[8-9]。Retinex理论的基本假设是初始图像G是光照图像H和反射率图像J的乘积,可表示为如下形式:
Retinex理论在彩色画面强化、图像去雾、彩色图像还原等方面都具有很好的有效性,其基本内涵就是物质的色彩是由物质对长波(红)、中波(绿)和短波(蓝)光的反映能力决定的,而并非由反射光强的绝对值决定。文中使用的RetinexNet模型由一个分解网络和一个增强网络构成,分解网络用于分解图像,而增强网络则用于调节光照条件,如图3所示。

图3 Retinex理论整体模型
图3中,图像的光照分量和反射分量会通过分解网络分开,经过回归模型后,增强网络会对其进行增强,最后再对分解后的分量做乘积便能得到一个新的增强后图像,即输出图像。这种方法只对我们需要的参数进行训练。在对图像进行分解后,利用增强网络对图像的亮度进行增强,最后结合去噪方法对图像去噪。
2.2 基于改进YOLOv3的行人检测
输入图像进行低光照图像增强之后,进入YOLOv3网络进行行人检测。本文将YOLOv3的主干网络替换为GhostNet,保留多尺度预测部分,减少深度网络模型参数和计算量以加快检测速度。然后,采用SE(Squeeze and Excitation)注意力机制模块,赋予重要特征更高的权值以提高检测跟踪的精确度,并引用目标检测的直接评价指数GIoU来指示回归任务。最后,用基于GhostNet的目标检测算法进行行人检测。
GhostNet结合了线性运算和普通卷积,将已得到的普通卷积特征图形进行线性变换可以得到相似的特征图形,进而产生高维卷积效果,从而降低建模参数和计算量。融合了卷积算法与线性计算的模型称为Ghost模块,如图4所示。图中,Y表示通过卷积生成的固有特征图,Y'表示通过线性运算生成的冗余特征图。

图4 Ghost模块原理
对于任意卷积层生成n个特征图Y0∈ Rp'×w'×n的操作可以表示为:
式中:X为输入数据,X∈Rz×p×w;f∈Rc×k×k×n为该层的卷积核;*表示卷积操作;b为偏置项。卷积过程所需要的浮点数为n·p'·w'·c·k·k。原输出的特征为某些内在特征且通常数量都很少,可以通过一个普通卷积操作生成,即:
式中:Y∈Rp'×w'×m为普通卷积输出;f'∈Rz×k×k×m为使用的卷积核。由于m≤n,将偏置项简化。现在需要得到n维特征图,对得到只有m维的固有特征图进行一系列简单线性变换:
式中:yq'为固有特征图中的第q个特征图;Φqp为第q个特征图进行的第p个线性变换的线性变换函数。最后,增加1个恒等映射Φqs将固有特征图叠加到经线性变换得到的特征图上,以保留固有特征图。
3 实验结果及分析
3.1 实验平台及数据集
本文算法使用Pytorch框架实现,在低光照数据集ExDark和VOC2012数据集上进行训练。硬件平台为Inter(R)Core i5-9300CPU,运行内存为8 GB,GPU为NVIDIA GeForce GTX 1650。
3.2 实验结果及分析
本文在YOLOv3以及卡尔曼滤波目标检测跟踪算法的基础上,加入注意力机制研究复杂环境下的行人跌倒检测算法和Retinex,提高算法对遮挡物影响、光照变化和阴影干扰等问题的鲁棒性,减少误判,提高检测的准确度。在ExDark数据集上的检测效果如图5所示。

图5 图像增强前后检测效果
在图5(a)图像中,由于光线不足导致图像昏暗,传统的YOLOv3算法无法检测出路面上的行人。经过图像增强之后得到图5(b)所示4张图片,这4张图像的特征明显,容易辨识出行人。因此能实现低光照环境下的行人检测。
此外,本文的算法在检测准确率上相比YOLOv3更高,实验结果比较见表1所列。
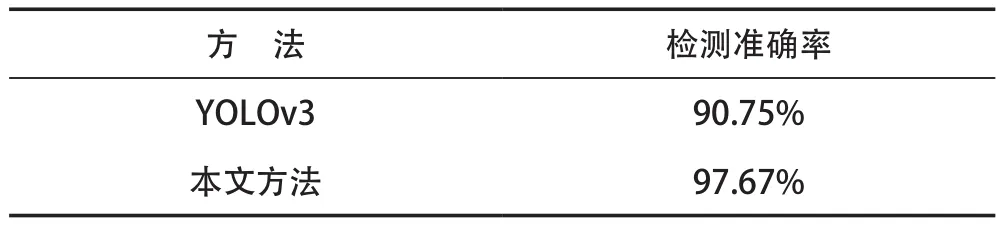
表1 实验结果比较
4 结 语
本文针对低光照环境下的行人检测错误率高且速度慢的问题,提出了基于注意力机制的低光照目标检测算法。将YOLOv3的主干网络加上基于Retinex视觉模型的低光照图像增强算法,构建融合注意力机制的行人检测,以期提高低光照环境下行人检测的准确率,解决YOLOv3在低光照下错误率高甚至无法检测目标的问题。实验结果表明,改进算法可以实现低光照环境下的行人检测,能够有效处理光照不足等复杂环境下行人检测时图像黑暗等问题,提高了检测的准确度,并且在现实中具有很强的实用性。
猜你喜欢
中国机械工程(2022年8期)2022-05-09
燃气涡轮试验与研究(2021年6期)2021-08-01
中国机械工程(2021年8期)2021-05-07
海洋信息技术与应用(2020年4期)2021-01-18
中国生物医学工程学报(2019年5期)2019-07-16
音乐教育与创作(2019年8期)2019-05-16
北京航空航天大学学报(2017年3期)2017-11-23
河南科技(2014年4期)2014-02-27
上海理工大学学报(2012年2期)2012-03-20
