
基于深度学习的图像目标检测系统设计与实现
2023-03-05 08:21程忠梅李伟熊竹罗莲陈文
计算机应用文摘·触控 2023年4期
程忠梅 李伟 熊竹 罗莲 陈文
关键词:深度学习;Faster R-CNN;目标检测;可视化预测
1引言
随着社会经济的发展,图像信息成为与人们生活密切相关的重要数据,利用计算机来迅速地实现图像分类和目标检测,已成为当前图像处理最迫切的需求。目标检测是深度学习的一个重要应用,要求从图片背景中分离出感兴趣的目标。相较于庞大的图像数据信息的产生,图像分类和目标识别的速度、准确率也在快速提升。此前的研究证明,在大数据集上进行训练可以获得一个小数据集的实质性改进。一般来说,这些超大规模的数据集可以使局部识别性能大幅度提高[1]。随着数据越来越大,要求也会越来越高,也需要更加快速和精准的识别方法[2]。目前,最常用的图像目标检测的三个模型分别是Faster R-CNN.SSD和YOLO。所以,在本项目中基于深度学习的Faster R-CNN算法对图像目标进行识别,采用一个统一的系统来实现对图像分类、目标检测型和人脸分类三个不同的模型的统一管理,实现对图像目标的可视化预测。
2目标检测方法
深度学习目标检测方法主要分为两阶段目标检测算法和一阶段目标检测算法。两阶段目标检测算法常见的方法有R-CNN,Fast R-CNN和Faster R-CNN等,它需要生成一系列作为样本的候选框,然后通过卷积神经网络进行分类。一阶段目标检测算法常见的方法有YOLO,SSD等,它不需要产生候选框,而是直接将目标框定位的问题转化为回归问题来处理。其中,这两类方法各有优缺点,两阶段目标检测算法在检测准确率和定位精度上占优,而一阶段目标检测算法在速度上占优。本系统选择使用Faster R-CNN模型,来设计和实现图像目标检测系统。
在做图像分类任务时,通常要先使用卷积神经网络提取图像特征,再用这些特征预测分类概率[3]。通过对整张图像特征提取,将目标检测任务进行拆分。在图像上生成一系列可能包含物体的候选区域,把候选区域都当作一幅图像来看待,然后使用分类模型对它们进行分类和判断其所属类别,从而实现目标检测任务。
Fast R-CNN在候選区域选择上使用SelectiveSearch方法,它是整个流程中的时间消耗瓶颈,无法用GPU硬件与网络进行加速[4]。而Faster R-CNN在Fast-RCNN的基础上做了重大的创新改进[5]:(1)在Region Proposal阶段提出了使用RPN来代替SelectiveSearch;(2)使用了锚框。
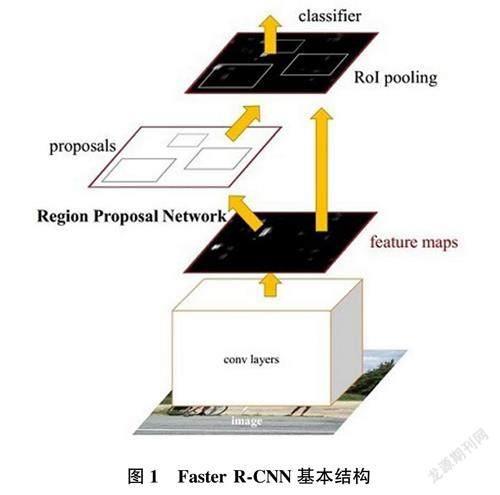
Faster R-CNN基本结构如图1所示。(1)需要输入测试图像;(2)将整张图片输入CNN来提取图像特征;(3)采用RPN生成一堆Anchor box,对其进行裁剪过滤后,通过softmax判断anchors属于前景或者后景;同时bounding box regression修正anchor box来形成较精确的proposal;(4)把建议窗口映射到CNN的最后一层卷积feature map上;(5)通过RoI pooling层,让每个RoI生成固定尺寸的feature map;(6)利用Softmax Loss和Smooth Ll Loss对分类概率和边框回归进行联合训练。
3系统设计
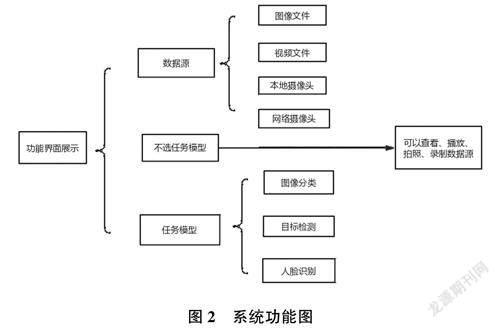
系统设计的目的是针对图像识别算法在进行图像检测时都会遇到图像显著性特征保留不完整的问题,基于深度学习的快速区域卷积神经网络(Fast R-CNN)框架,对深度学习在图像识别领域中的不同处理方法及模型的发展进行研究,从而得到相应的目标检测模型。同时,针对不同的数据集都需要训练一个模型,根据任务是针对图像分类模型或目标检测模型,每次都需要重新写一次代码来对不同的任务、不同的模型进行推理预测,针对该问题,需要采用一个统一的系统来实现不同任务、不同模型的统一管理,以实现对推理模型的可视化预测,系统功能如图2所示。因此,在使用的过程,把部署模型存放在对应的任务模型默认目录即可,分别是图像分类模型、目标检测模型和人脸分类模型。
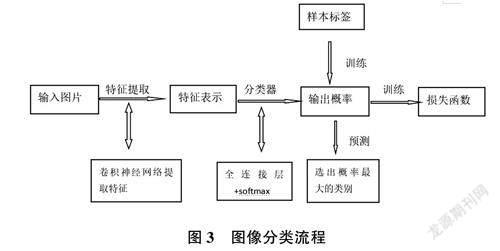
在做图像分类任务时,首先使用卷积神经网络提取图像特征,然后利用特征来预测分类的概率。根据训练样本标签建立起分类损失函数,最后开启端到端的训练,流程如图3所示。结合图片分类任务取得的成功经验,可以将目标检测任务进行拆分。基于深度学习的Fast R-CNN模型,在输入图片上生成一系列可能包含物体的候选区域,然后可以把每个候选区域单独当成一幅图像,使用图像分类模型对它进行分类.判断它属于哪个类别或者背景,从而实现目标检测任务,如图det-model(目标检测模型)。
系统的UI设计使用的是Qt Designer。系统界面组成有:(1)两个标签QLabel,用来显示源图像和预测结果后的目的图像。为了让界面能够自适应缩放,在适当的时候使用Horizontal Spacer和Vertical Spacer来撑起组件。(2)-个可编辑的文本框QTextEdit,用来存放文本信息。(3)数据源区由单选按钮和录像机的相关信息组成。(4)功能区包括图像缩放、任务模型、预览/预测、拍照、录像、关闭等功能选项。系统的两个资源文件包括:用来检测人脸的OpenCV人脸级联分类器xml文件,文件比较小,所以当成资源文件打包,运行程序时自动释放资源文件:程序启动的画面图像文件,用来读取资源图像。系统实现的关键代码如下。
if self.isimg:
4系统实现
软件开发环境使用Windows10系统,在学习人工智能深度学习时,因为经常需要训练模型,需要很强大的计算能力,这时仅依靠CPU是远远不够的[6]。因此,在Windowsl0系统下安装和配置好基于CUDA架构的GPU编程环境,将在很大程度上提高实验效率。同时,开发环境选用VScode环境,编程语言为Python。深度学习框架有Pytorch和Tensorflow等,选用百度的PaddlePaddle飞桨框架,让用户更加方便快速地使用GPU来加速训练模型。安装飞桨后,还需要安装PaddleX。PaddleX是飞桨全流程开发工具,用户可以十分方便地使用它。
深度学习是一个非常耗时的过程,随着图像数据集的增多,搭建一个性能良好的实验环境对提升学习效率很有帮助,系统选择的硬件配置如表1所列。训练用时大约28 min(GPU环境),训练最后一轮的mAP达到86%以上,表明训练的效果较好。通过调整训练参数,还可以提高mAP的值。
系统对图像目标识别中要应用的函数和方法进行了实现。cls-model(图像分类模型)的结果如图4所示,它利用计算机对图像进行相应的定量分析,把图像或图像中的每个元素或区域划分为多个类别中的某一种,以代替人的视觉判读。而det-model(目标检测模型)的结果如图5所示,它的主要作用是让计算机可以自动识别图片和视频帧中所有目标的类别,并在该目标周围绘制边界框,标示出目标所在图片中的位置。测试结果显示,预测结果的准确率较高,达到了预期目标检测的效果。
5结束语
本文围绕图像目标检测中存在的问题,对深度学习在图像识别领域中的不同处理方法及模型的发展进行研究。基于深度学习的快速区域卷积神经网络框架,使用相应的目标检测模型,以及采用一个统一的系统来实现不同任务和不同模型的统一管理,实现对推理模型的可视化预测。系统测试结果表明,基于深度学习的图像目标检测,可以从输入的图像或视频判断是否包含物体,并对检测到的物体进行分类和定位,在该目标周围绘制边界框和标示出每个目标的位置,在众多的实际应用场景中拥有很高的应用价值[7]。未来研究将完善深度学习的图像数据训练集和验证集,以进一步提高图像目标检测与识别的准确率。
猜你喜欢
软件(2016年4期)2017-01-20
科教导刊·电子版(2016年28期)2017-01-10
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
科学与财富(2016年28期)2016-10-14
科技视界(2016年4期)2016-02-22
