
ISMB:多核系统中利用Bank分区实现共享库隔离
2023-03-04 06:42:50杨虎斌李嘉翔陈玉聪张红涛周庆国
计算机技术与发展 2023年2期
杨虎斌,李嘉翔,陈玉聪,刘 刚,张红涛,周 睿,周庆国
(兰州大学 信息科学与工程学院,甘肃 兰州 730000)
0 引 言
动态随机存取存储器(Dynamic Random Access Memory, DRAM)被广泛地应用于嵌入式设备、个人电脑和服务器[1]。在现代计算机内存体系结构中,当处理器核(Core)通过内存控制器访问DRAM中的数据时,需要将线性的物理地址转换为由通道(Channel)、DIMM、Rank、Bank、行(Row)和列(Column)组成的多维的DRAM地址[2]。为了提高访问内存的速度,在每个Bank中都有一个行缓冲区(Row Buffer)[3-4],它一次可以存储Bank中的一行数据。特别地,应用程序的局部性越好,行缓冲区起到的效果就越好。
在多核平台上,DRAM由系统中所有的Core共享,因此,只有在不同Core上运行的进程并发访问同一个Bank中的同一行数据,或者并发访问不同Bank中的数据时,才不会发生行缓冲区冲突。但是,当不同Core上运行的进程并发访问同一个Bank中不同行中的数据时,会引发行缓冲区冲突,从而导致该行缓冲区的频繁刷新。因此,行缓冲区冲突导致的内存访问延迟使整个系统的性能下降。
目前已有一些解决方案利用DRAM Bank分区技术缓解这个问题[5-13]。这些解决方案的主要设计思想是利用Bank分区技术将DRAM中指定的Bank分配给指定的进程,因此,不同的进程只能访问位于自己的Bank中的物理内存,从而可以有效地缓解Bank行缓冲区冲突。然而,由于共享库是一种进程间的共享资源,它们被加载到内存后,通常随机地分布在不同的DRAM Bank中。因此,虽然基于DRAM Bank分区技术的解决方案可以有效地缓解由进程访问私有内存导致的Bank行缓冲区冲突问题,但是,无法解决访问共享库引起的Bank行缓冲区冲突问题。
该文提出了一种在多核系统中利用DRAM Bank分区技术实现共享库隔离的方案(Isolation of Shared Libraries in MultiCore Systems via Bank Partitioning,ISMB)。ISMB为每个Core提供了一个共享库的副本,并使运行在相同Core上的所有进程共享只属于该Core的共享库的副本。
具体地,ISMB首先将共享库的副本分别加载到位于对应的Core的Bank中的物理页面中,然后利用Bank分区技术使运行在同一个Core上的所有进程只能访问属于该Core的共享库的副本。因此,ISMB消除了共享库导致的Bank行缓冲区冲突问题,从而提升了系统整体的性能。
从表1中可以看出,与其他没有考虑共享库的Bank分区方案相比,ISMB的创新性在于:在涉及共享库的两种情况下,ISMB都可以提供有效的隔离。例如,在情况2下,假设为Core 0和Core 1分别分配的是Bank 0和Bank 1,则运行在Core 0上的应用程序的二进制可执行代码被加载到Bank 0中,而运行在Core1上的共享库的代码被加载到Bank 1中,因此,当Core 0和Core 1并发访问内存时,不会导致Bank行缓存区冲突。
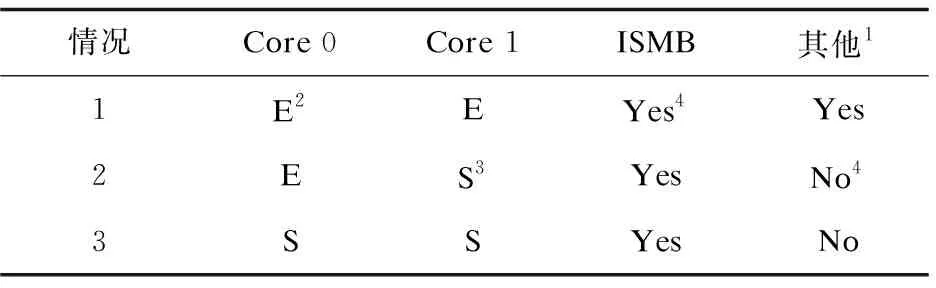
表1 ISMB与其他不考虑共享库的Bank分区机制在共享库隔离方面的对比
对比实验结果表明,ISMB能够有效地提升系统隔离性能。与未使用ISMB的Linux相比,在高负载的情况下,所有SPEC CPU2006基准测试程序的减速率平均降低了3.9%,最大降低了26.3%。在混合负载的情况下,减速率平均降低了6%,最大降低了15.7%。
1 相关工作
1.1 DRAM控制器调度算法
目前已有一些研究[14-16]通过优化DRAM控制器调度算法来解决多核平台上Bank行缓冲区冲突问题,从而实现提高系统吞吐量或公平性的目的。虽然DRAM控制器调度算法优化方案可以提高系统吞吐量或公平性,但是这些方案有以下三个缺点:第一,涉及到内存控制器硬件的修改;第二,这些方案的有效性受到诸多因素的限制,例如调度算法缓冲区的大小等等;第三,当运行在不同Core上的多个进程共享DRAM时,优化后的DRAM控制器调度算法可能会导致饥饿现象的产生[11]。因此,利用优化DRAM控制器调度算法来解决多核平台上DRAM Bank行缓冲区冲突问题,所能达到的效果有限。
1.2 DRAM Bank分区技术
DRAM Bank分区技术是通过软件的方式缓解多核平台上Bank行缓冲区冲突问题的机制。基于DRAM Bank分区的方案[5-13]主要分为静态分区和动态分区两类。其中,Bank静态分区技术对DRAM中的Bank进行静态分区,并将指定的Bank分配给指定的进程,以减少Bank的行缓冲区冲突,从而提高系统性能。Bank动态分区技术首先会根据进程对Bank数量的需求,动态地对DRAM中的Bank进行分区,然后在进程运行的不同阶段,为其分配数量不等的Bank。
1.3 共享库隔离机制
目前已有一些为共享库提供隔离机制的解决方案,这些解决方案通常是将共享库独立地运行在隔离环境中,例如不同的上下文环境[17]或独立的虚拟机[18-19]中。在这些解决方案中,调用共享库中函数需要进行上下文环境或虚拟机的切换,因此,在函数调用很频繁的情况下,这会造成很大的系统开销。除此之外,Kim等人提出了一种称为选择性共享的策略[20]。该策略首先为每个共享库创建n+2个副本,其中n表示系统中Core的数量;然后将n个副本分别由运行在n个Core上的高优先级实时任务共享访问;其次,将另外2个副本分别由运行在所有Core上的低优先级实时任务和非实时任务共享访问。由于低优先级实时任务和非实时任务分别共享的2个共享库仍然可以导致Bank行缓冲区冲突问题,因此,该策略没有彻底地解决共享库引发的Bank行缓冲区冲突问题。
2 设计与实现
ISMB的核心设计思想是:首先,为每个Core创建一个共享库的副本;然后,利用Bank分区技术使运行在某Core上的所有进程只能访问该Core对应的共享库副本。
如图1所示,假设为Core 0和Core 1分别分配的是Bank 0和Bank 1,则运行在Core 0上的进程只能访问Bank 0中的进程的私有内存和Core 0的共享库副本的共享内存。因此,ISMB可以同时消除进程访问私有内存和共享库导致的Bank行缓冲区冲突问题,从而提升系统的整体性能。

图1 ISMB的共享库隔离示意图
2.1 为Core分配DRAM Bank
在Linux内核中,ISMB为系统中所有的Core维护了一个空闲物理页面链表数组pcpu_list,数组中链表的数量等于系统中Core的数量。除此之外,ISMB将系统中的所有DRAM Bank进行分区,并为每个Core分配了一组固定的Bank,因此,pcpu_list数组中每个链表存放的空闲物理页面位于该链表对应的Core的Bank中。例如,为Core 0分配的是Bank 0,则pcpu_list[0]链表中存放的空闲物理页面都位于Bank 0中。当运行在Core 0上的进程在运行过程中发生缺页异常,进入异常处理程序后,ISMB通过修改Linux内核函数_rmqueue,实现了直接从pcpu_list[0]链表而不是Linux伙伴系统中为进程申请空闲物理页面的操作。
图2是从pcpu_list[0]链表中为运行在Core 0上的进程申请空闲物理页面的流程。如果pcpu_list[0]链表不为空,那么ISMB直接从pcpu_list[0]链表中取出第一个空闲物理页面后,返回该物理页面。否则,ISMB首先从Linux伙伴系统中申请一个空闲物理页面,然后将其插入pcpu_list[0]链表。最后,从pcpu_list[0]链表中取出空闲物理页面后,返回该物理页面。在这个过程中,若从Linux伙伴系统申请的空闲物理页面不位于Bank 0中,则把这些物理页面分别插入适当的pcpu_list链表,从而可以减少在将来申请空闲物理页面的时间开销。

图2 从pcpu_list[0]链表中申请空闲物理页面的流程
2.2 DRAM Bank映射
为了把从Linux伙伴系统中申请的空闲页面插入适当的pcpu_list链表,需要知道将物理地址转换为DRAM地址的映射信息,从而确定一个物理页面位于哪个DRAM Bank。对于没有公开地址映射信息的体系结构(例如Intel),可以利用逆向技术获取这些地址映射信息[21-27]。目前已有的逆向技术主要分为两类:基于软件的方法和基于硬件的方法。
由于文中的实验平台基于AMD架构,并且该架构在其架构手册中明确地公开了DRAM地址映射信息,因此,通过查询AMD架构手册可知:物理地址中的Rank和Bank位的信息分别存放在“F2x[1,0][6C:60] DRAM CS Mask Registers”和“F2x[1,0]80 DRAM Bank Address Mapping Register”两个寄存器中[28-29]。如表2所示,文中使用的实验平台有1个通道,每个通道有2个DIMM,每个DIMM有2个Rank,每个Rank有8个Bank,因此,系统中总共有32个Bank,即在物理地址中,总共有5个比特位用来表示Bank的编号。
图3显示了文中使用的实验平台的DRAM Bank映射信息。由图可知,比特位16~17用于表示Rank的编号,比特位13~15用于表示Bank的编号。综上,ISMB使用物理页面的起始地址中的比特位13~17,来确定物理页面所在的Bank的编号。例如,一个物理页面的起始地址中的比特位13~17全为0,表示该物理页面位于Bank 0中。

图3 文中实验平台的DRAM Bank映射信息
2.3 共享库隔离
在已经对DRAM Bank进行分区,并将指定的Bank分配给指定Core的情况下,为了使进程只能访问属于运行该进程的Core的共享库的副本,ISMB需要将属于某个Core的共享库的副本加载到位于该Core的Bank的物理页面。
ISMB使用了一种简单有效的方法[20]对共享库进行Core间的隔离。首先,在磁盘上为每个Core创建一个用于存放共享库副本的目录,并将共享库分别复制到每个目录中。然后,在运行绑定在指定Core上的应用程序前,将该Core对应的存放共享库副本的目录添加到环境变量LD_LIBRARY_PATH。故该应用程序在运行过程中,只能使用该Core对应目录中的共享库副本。因此,在已经将指定Bank分配给指定Core的情况下,属于某Core的共享库副本只能被加载到位于该Core的Bank的物理页面,并被该Core上运行的所有进程共享。
3 实验与评估
3.1 实验环境
文中使用的实验平台的参数如表2所示,如2.2节所述,实验平台上总共有32个Bank。由于物理内存的总大小为16 GB,因此,每个Bank的大小为512 MB。在所有实验中,为每个Core静态地分配8个Bank。操作系统使用Ubuntu 18.04,其中Linux内核版本为5.3。此外,在所有实验过程中,通过禁用不相关的服务(桌面服务和网络服务)以提高实验精度。

表2 实验平台参数
在文中实验中,使用SPEC CPU2006[30]作为实验基准测试程序,表3对每个SPEC CPU2006基准测试程序使用的共享库进行了全面的统计。使用减速率(slowdown ratio)作为评估ISMB实现的性能隔离程度的指标[12],其定义如下:

表3 SPEC CPU2006基准测试程序的共享库使用统计信息

其中,IPCalone表示在无负载的情况下,SPEC CPU2006基准测试程序运行时,每个时钟周期执行的指令条数(Instructions Per Clock,IPC);IPCshared表示在有负载的情况下的IPC。减速率的值越小,说明隔离性能越好。
3.2 高负载的隔离性评估
实验中将SPEC CPU2006基准测试程序中的访存密集型(Memory intensive)程序470.lbm作为负载[12],来评估ISMB实现的性能隔离程度。实验过程如下:首先,在没有负载的情况下,在Core 0上运行所有SPEC CPU2006基准测试程序,并获取它们的IPC作为IPCalone;然后,在Core 1~3上分别运行三个470.lbm基准测试程序作为负载,在Core 0上运行所有SPEC CPU2006基准测试程序,并获取它们的IPC作为IPCshared;最后,利用公式(1)计算出SPEC CPU2006基准测试程序的减速率。
图4显示了将470.lbm作为负载的情况下,所有SPEC CPU2006基准测试程序的规范化减速率。从图中可以看出,在使用ISMB时,大部分基准测试程序的性能较好,除了如471.omnetpp之类的少数基准测试程序,这些基准测试程序的性能下降的原因主要是Bank数量减少导致的性能下降抵消了Bank分区技术带来的性能提升。实验结果表明,在使用ISMB的情况下,SPEC CPU2006基准测试程序的减速率平均降低了3.9%,最大降低了26.3%(470.lbm基准测试程序,规范化减速率为0.737)。

图4 以470.lbm作为负载的SPEC CPU2006基准测试程序的规范化减速率
3.3 混合负载的隔离性评估
为了模拟更加真实的运行环境,如表4所示,从所有SPEC CPU2006基准测试程序中随机选择10组基准测试程序,每个测试组包含4个基准测试程序。每个测试组的实验过程如下:首先,将测试组中的4个基准测试程序分别同时运行在4个Core上,并获取各自的IPCshared;然后,结合上一小节实验中获取的IPCalone,计算出每个SPEC CPU2006基准测试程序的减速率;最后,计算出这4个基准测试程序的平均减速率,作为测试组的减速率。

表4 SPEC CPU2006基准测试程序组
图5显示了10个测试组在使用ISMB的情况下,每个测试组的规范化减速率。实验结果表明,在混合负载的情况下,ISMB的使用使SPEC CPU2006基准测试程序的减速率平均降低了6%,最大降低了15.7%(Mix8测试组,规范化减速率为0.843)。因此,与未使用ISMB相比,ISMB可以有效地提升系统的隔离性能。

图5 SPEC CPU2006基准测试程序组的规范化减速率
4 结束语
该文提出的在多核系统中利用DRAM Bank分区技术实现共享库隔离的方案(ISMB)消除了共享库导致的Bank行缓冲区冲突问题,从而有效地提升了系统的整体性能。对比实验结果表明,与未使用ISMB的Linux相比,ISMB能够有效地提高系统隔离性能。特别地,在高负载的情况下,SPEC CPU2006基准测试程序的减速率最大降低了26.3%,在混合负载的情况下减速率最大降低了15.7%。提出的ISMB机制是基于静态Bank分区技术实现的,在未来的研究工作中,计划采用动态Bank分区技术来实现ISMB机制。从而在保证ISMB隔离性的同时,进一步提升系统的整体性能。
猜你喜欢
成都信息工程大学学报(2019年2期)2019-08-28 10:00:46
计算机系统应用(2019年2期)2019-04-10 05:08:46
第二课堂(课外活动版)(2019年12期)2019-02-10 03:59:37
数字技术与应用(2018年4期)2018-08-18 08:23:26
成都信息工程大学学报(2018年1期)2018-05-31 08:40:25
电脑知识与技术(2017年5期)2017-04-08 19:29:29
数字通信世界(2016年11期)2016-11-29 13:27:32
计算机与生活(2016年11期)2016-11-22 02:07:32
中国高新技术企业(2015年24期)2015-06-25 00:15:18
计算机工程与科学(2015年3期)2015-03-27 07:46:15
