
基于BERT文本分类模型的APP隐私政策完整性评价研究
2023-03-01 01:33:06吴子帅韦秉东
现代情报 2023年3期
朱 侯 吴子帅 韦秉东
(中山大学信息管理学院,广东 广州 510006)
信息技术在人们的生活中逐渐渗透,与人们日常生活紧密融为难以分割的整体。然而,大多数用户并不太关心工具、设备背后的技术细节,尤其是当前日渐普遍的大数据技术与个性化服务,使得人们在互联网上留下的每一步足迹都为个人信息的泄露埋下隐患。生活的便利可能同时伴随着个人隐私的牺牲。在第44次《中国互联网络发展状况统计报告》[1]对2019年上半年网络安全问题的统计中,有24%是个人信息泄露问题。互联网时代隐私泄露事件多发的一大原因在于,APP平台方常以个性化推荐或提供服务为由,过度收集和利用用户的隐私信息,大大增加了其被泄露的可能;更有甚者直接非法倒卖用户隐私信息以谋利。隐私政策的出现则是对平台保护用户隐私的一个规则限制,是平台对用户信息合法收集和利用等处理行为的宣告。用户隐私政策既是政府对互联网企业发展的限制与规范,更是互联网企业与用户之间关于信息使用的契约。
隐私政策是用户隐私保护的一道防线。但是,由于隐私政策篇幅较长,用户常常不会仔细查看隐私政策,对其是否符合法律法规要求不够在意。一些企业可能利用这点,使用冗长的隐私政策提高用户的阅读成本。这样用户在可能出现的法律纠纷中就会落于下风。因此,平台对用户个人隐私的保护,首先就体现在对平台制定的隐私政策是否合乎法规,是否囊括应说明的内容,以及是否予以落实。
APP隐私政策是平台方对用户隐私信息处理举措的明细直观体现,判断隐私政策文本内容是否阐明完整则是评判APP隐私政策是否合法的方向之一。通过对隐私政策的自动分类对隐私政策进行评价,能够为用户选择对隐私保护更具力度的平台提供辅助,也可以让监管人员和机构更快速地了解该隐私政策是否囊括了法律规定应在隐私政策中包含的内容,减轻工作人员负担。当前并没有通用的APP隐私政策完整性评判标准,但我国《信息安全技术 个人信息安全规范》[50]和欧盟《通用数据保护条例》[49](General Data Protection Regulation,GDPR)等法律条例都对隐私政策中应包含的内容给出了相关规定,可以认为更完整和广泛地覆盖这些法律条例要求的隐私政策有着更高的完整性[48]。因此,本文引入融合上下文语义的文本分类方法,以相关法规中要求的隐私使用或保护措施为标签,对隐私政策文本进行自动分类检测,并根据分类结果利用L2归一化[54]的方法计算得到隐私政策的完整性得分,对不同APP隐私政策进行量化比较分析,以期规避传统隐私政策评价方法的主观性和局限性,推动隐私政策评价研究向自动化和智能化方向发展。
1 相关研究
1.1 隐私保护总体研究现状
隐私泄露是近几年社会关注的热点问题,不少学者都针对提升国内用户隐私保护水平的方向进行探索研究。陆雪梅等[2]在通过典型案例、统计分析和系统分析等手段分析用户隐私信息泄露的成因后,提出若要保护用户隐私,则需要政府方对隐私保护进行立法,且企业方需从技术层面上加强前沿信息技术的应用,建立行业自律规范等。徐艺心[3]详细分析了互联网生态环境的特点以及可能会对用户隐私保护造成的影响,提出了用户隐私保护的制度模式,除了政府需要监管平台外,也需要明确平台方在保护用户隐私信息上的义务与责任。谢珍等[4]提出,用户画像的建设必定需要用户数据,但平台方必须要从安全性、匿名性、用户同意、服务内容与数据提供对等四大原则来平衡数据应用与隐私保护之间的平衡方案,确保用户的信息安全。以往研究中提出的优化隐私保护建议常与推动完善隐私保护政策内容和措施相关,用户隐私信息的安全性离不开法律规范和平台方对隐私的保护。
1.2 隐私政策与隐私条款相关研究
用户隐私信息的安全性离不开法律规范和平台方对隐私的保护,而隐私政策是运营商和用户就隐私收集和保护问题达成一致的重要契约。李卓卓等[5]利用内容分析法调研我国APP隐私政策中保护用户隐私信息的实际表现,发现APP运营平台方在数据利用相关内容上的说明存在漏洞,如部分APP未告知平台方将如何进行隐私数据处理,对信息的使用是否存在风险,未声明具体权限等。陆康等[6]建议图书馆应以法律规范为标准,构建符合图书馆发展方向的隐私条款,制定具有行业特色的隐私保护制度。徐磊等[7]以图书类APP隐私政策为研究对象,认为当前隐私政策存在重点不明、规定模糊等问题,认为可以通过提升用户在修订隐私政策过程中的参与度,夯实隐私政策法律基础等方法,提高隐私政策质量。郭清玥等[8]采用文献调研法、内容分析法和LDA主题建模法,收集约200款APP隐私政策文本进行分析,获得国内常用APP隐私政策的通用内容框架,在经过与国内外法律政策文件的对比后,认为国内APP隐私政策在个人信息主体权利和个人信息安全保护体系等方面内容的介绍还有所欠缺,提出对我国APP隐私政策内容框架的优化方向。当前APP隐私政策的内容可能存在一定安全隐患,而隐私政策需要做到合理、合规、合法才能实质性保护用户隐私信息。
当前部分隐私政策研究聚焦在不同隐私政策的对比方面,比如:不同国家(地区)隐私政策的对比、不同网站隐私政策的对比和不同APP隐私政策的对比。有的学者选择的是分类型收集不同平台的隐私政策进行对比[9-11];有的学者则会专注某一领域的平台,如图书馆与档案[12-14]、电商[15-17]、政府平台[18-21]和健康领域。不同领域内又有不同功能平台主题的具体细分,比如在健康类APP方向,马骋宇等选择的主题是不细分功能的多种健康类APP[22],O’Loughlin K等则专注于心理抑郁类的健康APP[23],而Benjumea J等选择了健康APP中的癌症类APP作为研究对象,从欧盟的GDPR法规(通用数据保护条例)出发,改进了隐私政策评价量表[24]。
1.3 隐私政策完整合法性相关研究
优化隐私政策是提升用户隐私保护力度的重要建议方向,国内外学者常将隐私政策的完整性作为评估隐私政策是否符合法律规范的一大落脚点。国内外对隐私政策完整性的评价研究常使用内容分析、层次分析、文本编码[25]等方法来观察平台的隐私政策有没有涉及法律条款规定应当涉及的方面,并根据隐私政策中提到的对法律法规的遵守情况给出分数评价。常见的完整性评价体系包含个人信息收集、个人信息使用、Cookie技术、信息披露条件、数据保护、用户权利、未成年人隐私保护等几个方面[26]。朱颖还对APP是否有专门隐私政策、隐私保护政策名称规范性、获取隐私政策的便捷性、用户接受政策的权利性、更新时间的标注和企业是否提供联系方式6种表现进行了分析[27]。徐雷等使用内容分析法,评价国内热门APP隐私条款的获取途径、可读性和文本内容,既统计了APP在不同内容类别表述上的整体表现,也从70余款APP中选取了表现突出的几款进行具体说明[28]。
除了通过完整性来对隐私政策的合法性进行评价的常规分析,一些学者另辟蹊径,使用其他方法来评估隐私政策。Mamakou X J等[29]关注的是如何评估网站遵守法律和道德准则的情况,提出了基于模糊数理论和模糊德尔菲法的法律合规指数FLECI,对100个网站的合规程度进行了评分。Reidenberg J R等[30]专注于评价隐私政策的语义模糊性,他以隐私政策文本中的“May”“Will”“Generally”等词作为模糊语义的标志,对网站隐私政策的模糊性进行打分。邵国松等[31]除了从隐私政策的发布、个人信息收集的目的、信息保密性与安全保障、删除权与更正权以及隐私政策的可见性5个角度对隐私政策进行完整性审核以外,还用技术手段监测敏感信息类网站使用的追踪Cookies、数据安全漏洞和侵入数据库的可能性,来检测这些网站是否兑现了隐私政策中所做的规定。姚胜译等[32]从用户视角来考虑对隐私政策的评价,认为隐私政策的友好度能够提高用户的阅读意愿,从内容可读性和交互友好性来构建APP隐私政策用户友好度评价指标,在选取样本后,运用问卷调查法和层次分析法进行评价分析,并对我国APP隐私政策的编写提出优化建议。
1.4 使用自然语言技术的隐私政策研究
为实现对隐私政策自动分析和评估,一些学者借助自然语言处理技术对隐私政策进行研究,例如隐私政策自动摘要提取[33]、建立隐私政策本体[34]、针对隐私政策的语义框架[35]、隐私政策的自动生成36]等。其中,基于文本分类技术是实现隐私政策完整性评价的重要方向。Liu F等[37]使用隐马尔可夫模型,试图对解决相同隐私问题的段落进行识别与分类。Boldt M等[38]选用15种分类算法,对合法公司与违法公司的隐私政策进行分类,其中朴素贝叶斯算法的表现最好,研究发现,违法公司的隐私政策覆盖面比合法公司要低很多。Wilson S等[39]基于网站隐私政策的OPP115语料库,应用逻辑回归的文本分类方法,实验首先将注释进行粗分类,再对每个粗粒度类别训练二元逻辑回归分类器,实现了粗粒度与细粒度结合的文本分类方法。Zimmeck S等[40]基于GDPR框架构建了移动APP的隐私政策语料库App-350,并在此基础上训练模型对大量Google应用商店的APP进行了测评。
已有研究表明,隐私政策作为平台使用和保护用户个人信息的重要契约,其完整性、合法性及其评价问题已经受到学界的广泛关注。但已有研究大多基于内容分析、质性分析、调查研究等方法对其完整性、模糊性和合法性等进行评价。为推动隐私政策自动化评价,国外部分学者通过自然语言处理技术对隐私政策进行挖掘分析,但主要基于GDPR等法律框架和OPP115等国外隐私政策语料库进行研究,缺乏对国内隐私保护法律框架的研究和中文隐私政策文本的自动评价。
2 实验设计
隐私政策完整合规的前提是其符合且满足相关法规的要求。目前,欧盟GDRR、美国《联邦贸易委员会法》[51](FTC Act)和日本《个人信息保护法》[52]等各国(地区)法律法规均对个人信息的保护和使用方式给出了相应规定。我国信息安全标准化技术委员会制定的《信息安全技术 个人信息安全规范》(GB/T 35273-2020)(以下简称《规范》)也规定了个人信息的收集、存储和使用等活动应遵循的原则和安全要求,并规定了互联网制定和应用隐私政策的方式,即隐私政策应清晰完整地罗列出互联网企业平台方将如何处理用户个人信息,并给出了隐私政策编写范本与要求,是目前我国针对维护互联网个人信息安全最权威的规定。
针对APP隐私政策的完整性,本研究首先根据《规范》的隐私政策要求,考虑信息的流转生命周期[53],结合隐私政策主要内容,提炼出信息收集、信息保存、信息使用和用户权利4个大类和12个隐私文本分类类别,作为隐私政策文本数据集标注的标签,如图1所示。随后利用神经网络构造APP隐私政策分类模型对其进行分类实验,实现隐私政策条款的自动分类识别,并在对分类结果进行评估后,利用L2归一化对待测试APP的完整性得分进行量化计算。
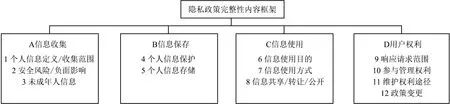
图1 隐私政策完整性内容框架
2.1 文本分类实验设计
分类实验流程分为3个步骤:首先,收集并标注APP隐私政策,作为实验输入数据集;其次,分别构建一次性多分类法和双层级联分类法,用多个模型对隐私文本数据集进行训练与预测分类;最后,比对分类结果,选出效果最佳的分类模型,作为隐私政策自动分类评价的实证工具。
在模型选择上,一次性多分类法和双层级联分类法都采用了word2vec[42]和Bert[41]两种融合了语义的文本表示模型,并组合CNN[43]、LSTM[44]和BiLSTM[45]3种深度神经网络分类模型,进行隐私政策分类。Word2vec模型是谷歌开源的词向量工具,是一种浅层神经网络模型,其利用词语的上下文使得向量表示的语义含义更加丰富。其基本原理如图2所示。

图2 Word2vec算法原理
Bert是谷歌在大量文本资料上训练起来的预训练模型,其核心编码器层是由多层Transformers编码器组成的,如图3所示。由于在直接用于下游任务前已经获得了对大量自然语言的了解,Bert模型进行训练时仅需要对其参数进行微调,再添加上输出层,就已经可以获得比以往传统模型更好的结果。使用Bert模型可以直接获得文本分类结果,也可以作为词嵌入层获取高维词向量。
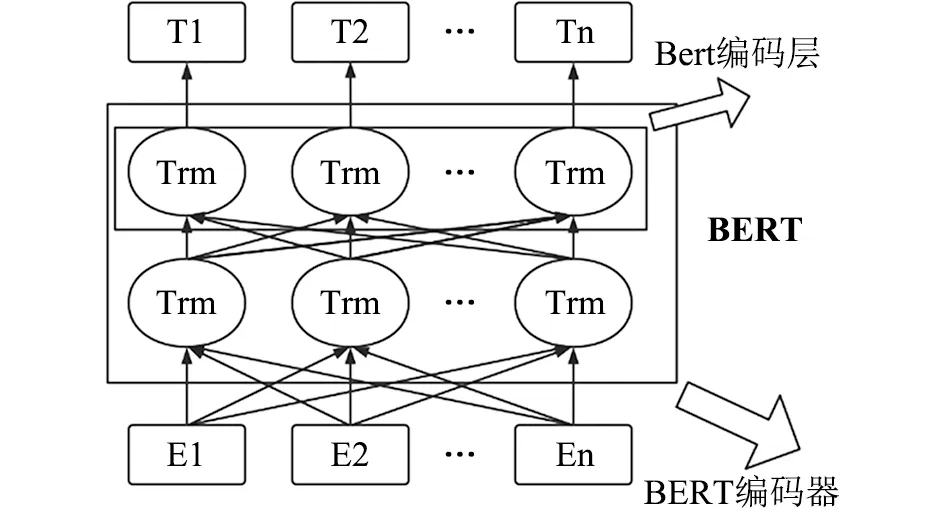
图3 Bert模型结构
CNN文本分类模型包含输入层、卷积层、池化层、全连接层和Softmax输出层。
长短时神经记忆网络(LSTM)和双向长短记忆网络(BiLSTM)可以将上一时刻的输出信息和当前数据的输入作为当前时刻的输入信息,经过处理,将当前时刻的输出信息再作为下一时刻的输入信息,达成选择性地记忆或遗忘信息的目的。
如图4所示,一次性分类法分别使用Word2vec和Bert对隐私政策文本进行向量化表示,并后接3种分类模型进行隐私政策文本一次性十二分类。需要指出,Bert模型既可以作为文本表示方法输出多维词向量,也可以单独作为文本分类方法实现多分类。

图4 一次性多分类法
如图5所示,双层级联分类法同样分别采用Word2vec和Bert作为文本向量表示方法,依托于可分成两层树状结构的数据集,首层先将文本分为差异明显的大类别,第二层中再将每个大类别下都细分小类。在模型设计中,先对首层的大类别实现文本粗分类,再对每个大类别下的细分类分别训练小分类器,最终获得文本多分类的结果。

图5 级联多分类法
2.2 隐私政策完整性评价方法设计
《规范》中提炼出的隐私政策内容框架代表着一篇完整的隐私政策应当包含的内容,完整合规的隐私政策应当在覆盖《规范》要求的同时,尽可能详细地陈述对用户各项隐私信息收集和使用的方式,即各个分类标签下条款数目相对较多的隐私政策完整性更高。因此,本文将隐私政策完整性的评价量化为不同内容类别数量的比较,即从不同APP隐私政策内容出发,将隐私政策文本各个类别的文本内容相对含量作为APP隐私政策评价的判断依据。研究利用L2范式归一化(式(1))的思想,将对应APP类型中不同标签的APP的隐私条款数进行归一化处理后映射到(0,10)区间内并求和,得到APP隐私政策完整性得分。
(1)
式中,xi,j表示同一分类下APPi(如18*邮箱)在隐私类别j(如未成年人信息)下的隐私政策条数;Scorei表示APPi最终的完整性得分。
3 隐私政策文本分类实验
3.1 数据采集、标注与预处理
本文计划选择艾瑞数据APP应用独立设备排行榜下与用户隐私强相关的8种类别中排名前列的APP,如表1所示,采用人工录入的方式对隐私政策条款进行采集,共收集得到80个APP隐私政策的14 000余条政策条款。
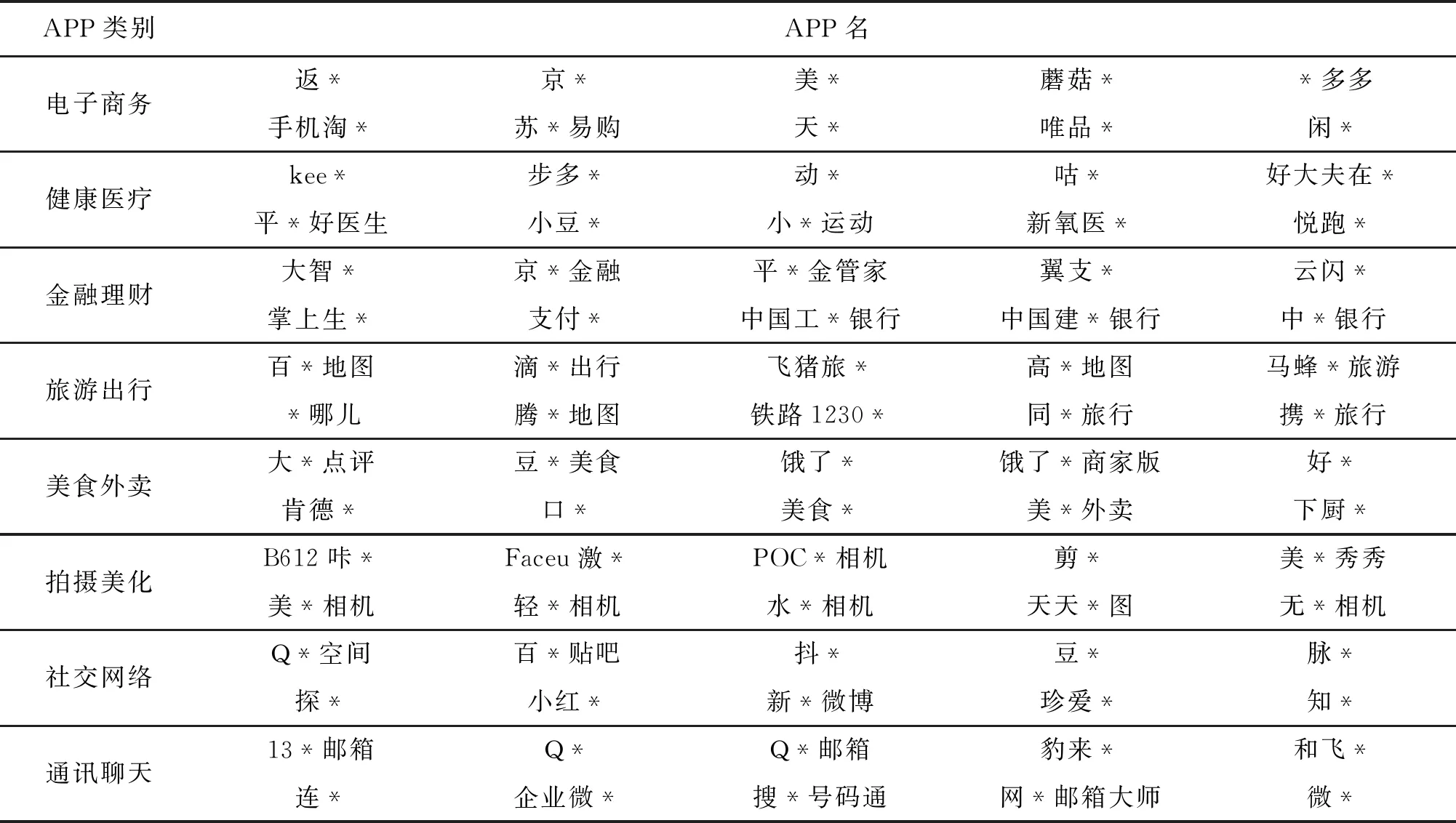
表1 实验收集隐私政策文本来源APP
在根据图1隐私政策完整性内容框架中的12种类别和4种大类作为分类标签,对采集到的APP隐私条款进行人工标注和格式处理后,共获得约14 000条无重复有标签文本作为初始数据集,如表2所示。
考虑到数据不平衡的问题,在进行过采样处理后得到了以下包括约30 000条带标签隐私政策条款的数据集,如表2所示。
对数据集的格式与分布进行基本处理后,为了进行词嵌入,还需要对数据集进行文本预处理。由于Bert模型自带文本预处理的特性,输入Bert的数据集不需要预先进行太多调整。但Word2vec模型仍需要通过NLTK工具包[47]进行去停用词、标注词性和分词3个预处理步骤,才能获得用于分类训练的词向量。
3.2 隐私政策文本分类模型效果对比分析
实验采用Python语言,主要使用Keras[46]深度学习框架,将预处理后的文本数据分别输入一次性多分类模型和双层级联分类模型进行训练。在对模型结构和参数进行多轮优化调整后,得到不同模型的分类结果如表3、表4所示。

表3 一次性多分类法模型最佳结果
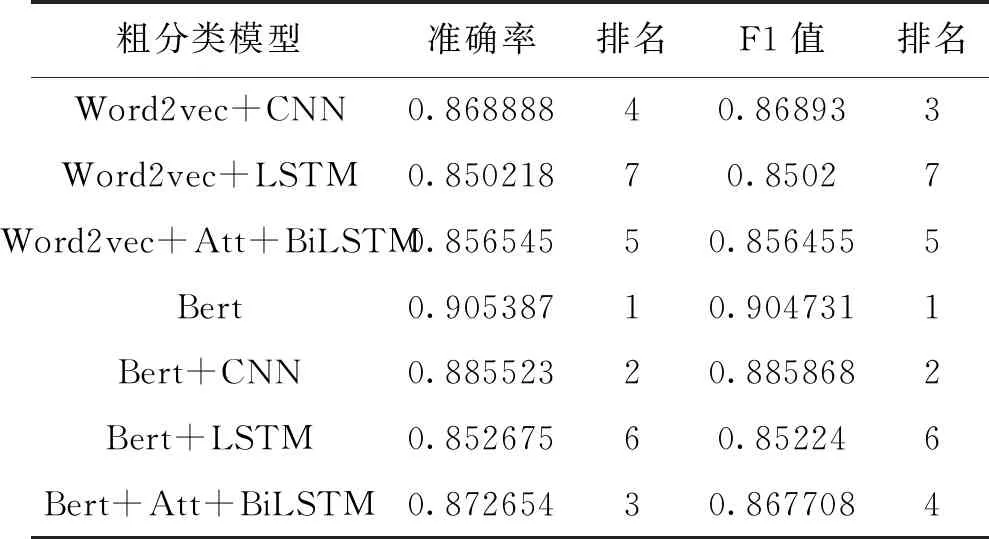
表4 双层级联分类法粗分类最佳结果
一次性多分类模型中,Bert作为文本向量表示模型的效果均优于Word2vec,此外,单独的Bert、Bert+CNN和Bert+att+BiLSTM 3种模型均能取得较高得分。
如表4所示,在级联分类的第一层粗分类中,Bert的准确率和F1值均最高,因此将Bert模型作为细分类文本向量表示的基础。
基于粗分类的最佳模型结果,在细分类中,选择CNN、LSTM和BiLSTM 3个模型来承接Bert模型输出的向量,对4个粗分类下的子类别分别训练小分类器。最终细分类的准确率与F1值由4个小分类器按类别权重合并计算得出,如表5、表6所示。
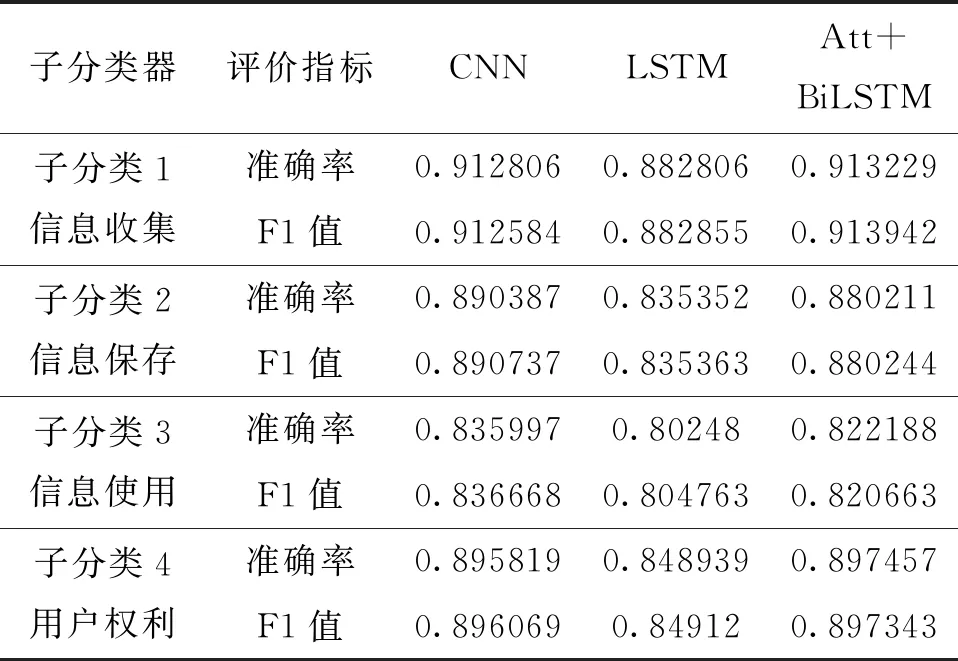
表5 双层级联分类法细分类中子分类器的最佳实验结果
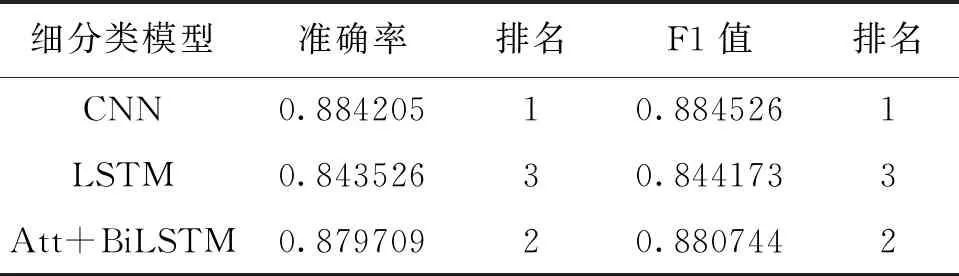
表6 双层级联分类法细分类最佳实验结果
将粗分类和细分类的实验评价指标分别相乘,即可得到级联分类的准确率与F1值结果,如表7所示。

表7 双层级联分类法最佳实验结果
可以看出,粗分类和细分类准确率均较低,粗分类的准确率最高仅有90%,除“信息使用”子分类器的分类准确率在84%左右外,其他子分类器准确率也均在90%左右。在本实验中,无论是十二分类还是四分类,用Bert和Bert+CNN进行十二分类的实验效果明显比其他方法都好。在十二分类实验中,Bert模型的准确率比Bert+CNN稍低,但F1值比Bert+CNN略高。一次性进行十二多分类的实验的效果远好于双层级联分类,推测其原因是数据集标注质量的限制,导致首层粗分类的准确率不及预期,对接下来的模型衔接产生了较大的负面影响。基于上文中提到的准确率可能存在的弊端,并且以四分类中Bert的准确率与F1值都比Bert+CNN更高作为侧面依据,认为使用Bert进行一次性十二分类是在本次实验中效果表现最佳的隐私文本分类方法。
4 基于文本分类结果的隐私政策完整性评价
基于之前分类模型的效果,实验将选择使用Bert模型从8种分类中分别选择一个对应的APP,如表8所示,用前文收集的共80个APP隐私政策文本作为训练集,对这8个APP的隐私政策文本进行分类预测并评价其隐私政策完整性。

表8 用于评价的隐私政策文本来源APP
利用Bert对待测APP进行分类后结果如表9所示。

表9 APP隐私政策文本分类结果
4.1 隐私政策纵向对比评价
纵向对比是指分别对8个APP在其所属APP分类中的内容含量水平对比。从标注结果推测,不
同类别的APP隐私政策表现存在较大差异,因此实验比较同类型的APP隐私政策文本相对数量,利用式(1)计算得到待测APP的完整性得分,如表10、图6所示。

图6 8个APP隐私政策完整性对比

表10 8个APP隐私政策完整性得分
可以看出,与同类型的APP进行比较,转*的隐私政策所包含的内容详细且完整;18*邮箱和智*火车票在同类型APP中也处于领先地位,但少数内容仍有一定欠缺;随手*表现平平,能够对《规范》中提出的大部分隐私政策内容进行详细描述;而蜗*睡眠、天*社区、简*和星巴*表现很差,部分条款大量缺失,亟需补充完善隐私政策。
4.2 不同类别APP隐私政策完整性评价
本部分旨在对不同类别的APP隐私政策完整性进行比较分析。与纵向对比类似,实验对不同类型的APP隐私政策文本数量平均值进行L2范式归一化(式(1))后映射到(0,10)区间内并求和,得到不同类别APP隐私政策完整性得分。结果如表11、图7所示。

图7 不同类别APP隐私政策完整性对比

表11 各类别APP隐私政策完整性得分
可以看出,不同类型的APP在隐私政策文本的完整性评价上,呈现出不同的特点。电子商务类APP呈现领跑局面,除了对个人信息收集的描述略有不足;同样涉及金钱的金融理财类APP则同样在安全风险上表现十分突出;旅游出行、美食外卖、社交网络三类APP在隐私政策内容对比中处于中游水平;健康医疗类APP仅着重介绍了信息使用方面的条款,而忽视了用户对隐私保护与维护权益的需求;通讯聊天类APP仅在“个人信息存储”与“参与管理权利”两种类别上得分较高,需要进行大范围改动优化;拍摄美化类APP的表现尤为不足,各项得分均较低,对《规范》中隐私政策范例的实践普遍表现不佳,需要行业整体对隐私政策进行整改。
4.3 隐私政策与法律条款人工对比核验
为了验证基于文本分类方法完整性评价的结果,研究分别纵向对比中完整性得分最高和最低的转*和星巴*APP隐私政策,直接对照《规范》中给出的隐私政策编写要求进行人工复核,二次验证分类和完整性得分计算方法的有效性。
经过人工比对,转*的隐私政策内容基本符合要求,仅有一些细节有所遗漏,如未描述提供个人信息后可能存在的安全风险,未表明在发生个人信息安全后平台方将承担法律责任。此外,转*在隐私政策中指出其隐私政策所涉及的个人信息与个人敏感信息内容参考自《规范》,与本文中的完整性评价使用了同一参考法规。对比结果与通过文本分类获得的评价结果相符。
星巴*的隐私政策在各个内容类别都缺漏较多,隐私政策文本撰写得比较简单。在信息收集方面,除了未对“安全风险/负面影响”进行说明外并没有明显不足。在信息存储方面,星巴*没有详细说明平台方对个人信息保护的措施,未如编写要求中所述列举出遵循的个人信息安全协议和取得的认证,也没有注明个人信息的存储时间,说辞含糊不清。对于较为细节的信息安全事件发生后平台方的担责与对用户的告知方式,也只字未提。在信息使用方面,星巴*未提及关于响应用户请求的部分。虽然在隐私政策中说明了对用户的个人信息可能会存在跨境传送和访问的情况,但并未按要求详细说明需要跨境传输的数据类型以及将遵循的跨境规范,仅说明了会有跨境动作,未介绍详情。在用户权利方面,星巴*仅给出了平台方的联系方式,但没有给出对出现无法轻易和解的争端时的解决方法,如申请外部争议解决机构审议等。总体来看,其隐私政策的特点是仅有大框架,而重要细节模糊不清。在政策中常使用“适当”“合理”等词汇来概括性说明,对具体情形没有详细列举。体现在上文的横向比较与纵向比较结果中,即可以看到不同类别的文本内容数量均较低,导致评分极低。星巴*隐私政策的人工比对结果同样与基于文本分类的完整性评价得分结果基本吻合。
5 结论与展望
本文基于体现上下文语义的BERT模型应用于APP隐私政策完整性评价中,在能够保证文本分类效果的前提下,提出准确高效的隐私政策完整性评价体系和方法。以上分析结果表明,首先,使用文本分类方法对隐私政策文本进行完整性评价,能够得出与人工比对法律规范近似的结论,基本能够体现出不同APP隐私政策的完整性表现,文章提出的基于BERT文本分类和L2范式归一化的完整性得分计算方法基本有效。在8个用于隐私政策评价的APP中,隐私政策完整性的得分表现可以分为4个梯队。不同类别APP隐私政策文本在编写上各有特点,如电子商务类APP隐私政策的内容更为完善,但同样与用户财产挂钩的金融理财类型APP在完整性上则有所差距,拍摄美化类APP则对隐私政策的编写要求不够重视,不能达到《规范》中的隐私政策内容标准。其次,基于BERT的文本分类模型能够在隐私政策完整性研究中取得很好的效果,其十二分类的F1值达到0.8489,证明利用BERT模型的文本分类方法来进行隐私政策完整性评价研究有其合理性和准确性。
此外,本研究将在以下方面进一步探索。首先,实验样本数据量不够大,不足以发挥预训练模型的特点,同时CNN等传统神经网络需要多次Epoch训练才能收敛,对于部分数据可能存在方差较高的问题。未来可以收集更多APP的隐私政策文本作为训练集,让模型能够学习到更多隐私政策文本特征,提升模型效果。其次,分类实验中文本粒度较大,仅对隐私政策条款进行了分类研究,体现隐私政策文本的语义特征不充分。可以通过命名实体识别和知识抽取等方法获取隐私政策中涉及到的具体隐私保护规则和信息,进一步判断其隐私保护力度和合法性。
猜你喜欢
工会博览(2022年16期)2022-07-16 05:53:54
今日农业(2022年1期)2022-06-01 06:17:42
云南化工(2021年9期)2021-12-21 07:44:00
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
绿色中国(2019年14期)2019-11-26 07:11:44
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
中国音乐教育(2017年4期)2017-05-20 09:21:06
中国男科学杂志(2016年9期)2016-03-20 15:00:13
