
基于深度残差网络模型压缩的局部遮挡人脸识别
2023-02-28 16:10刘瑞明徐春融陈伦奥
智能计算机与应用 2023年11期
刘瑞明,徐春融,周 韬,陈伦奥
(江苏海洋大学电子工程学院,江苏 连云港 222005)
0 引 言
卷积神经网络的成熟让人脸识别技术取得了突破性的进展,而人脸识别也被广泛应用在日常生活中的各个领域。 但是在现实环境中,人脸识别往往会受到各种因素的影响或限制,如光照、遮挡及面部姿态和表情等,其中遮挡人脸识别问题仍是当前所面临的一大挑战[1]。 特别是在疫情影响下,人们在公共场所必须佩戴口罩,因此,简单、高效的遮挡人脸识别方法的研究显得尤为重要。
在深度学习之前,遮挡人脸识别主要停留在人脸“浅层”特征的提取,主要分为2 个方面:未遮挡特征鲁棒提取和遮挡区域的修复。 第一种方法主要是利用未遮挡区域的局部特征进行识别,如HOG、SIFT、LBP 等,He 等学者[2]受到相关熵的启示,提出基于最大相关熵准则的鲁棒人脸识别方法,让训练样本遮挡部分离群值相对应的像素对相关熵的贡献很少,遮挡像素赋予的权重很小,对未遮挡区域赋予较大的权重。 对于第二种方法,Wright 等学者[3]首次将稀疏表示分类(Sparse Representation based Classification,SRC)算法应用到遮挡人脸识别中,利用稀疏表示的区别性对有遮挡的人脸图像进行分类,随后,为了解决真实环境下人脸遮挡的对齐和光照问题,应用类内变异字典表示测试样本与训练样本间的变化,利用稀疏系数对人脸进行重构,提出鲁棒SRC 和扩展SRC 方法。 这些方法需要大量的同类图像,然而协同表示把待识别图像看作是所有训练数据的线性组合,基于正则最小二乘的协同表示分类(CR based classification with regularized least square,CRC_RLS)算法,采用最小L2 范数回归代替了SRC 中的L1 范数,大大降低了算法的复杂度。
随着深度学习的快速发展,在人脸识别领域取得一系列可观的成果,主要体现在深度神经网络结构的设计[4-9]、损失函数的改进[10-13]以及人脸数据增强[14-15]三个方面。 Sun 等学者[16]首先提出DeepID2神经网络并在此基础上增加隐藏层的表示维数和卷积层的监督,进一步提出了DeepID2+网络结构,提取的人脸特征具有较强的鲁棒性。 随后,由于卷积神经网络的盛行,基于卷积神经网络的Deep-Face[17]、Google-Net[18]以及Face-Net[19]等模型被相继提出。为了缓解遮挡对脸部特征的影响,Li 等学者[20]以GAN 为基础提出了一种遮挡人脸修复的深度生成网络,针对人脸图像的遮挡区域,该网络可以从随机噪声中合成面部关键部位,并对恢复后的人脸进行识别,但是却只限于原始人脸图像的修复,特定妆容的随机遮挡则会影响修复效果。 除了对遮挡人脸进行修复,还有另一种方法是忽略被遮挡破坏的元素,利用未遮挡特征进行识别。 Song 等学者[21]采用一个掩膜学习策略并忽略被遮挡区域的特征进行人脸识别,利用遮挡图像和无遮挡图像对应特征间的差异获取掩码特征来建立掩膜字典,在识别过程中对遮挡导致特征信息有偏差的部分进行消除,该方法需要大量的图片训练多个模型建立掩膜字典,占用空间较大,在测试时进行特征提取和掩膜字典对比,大大增加了时间成本。
总之,传统方法对有遮挡人脸图像的识别有一定的效果,但是都停留在人脸的“浅层”特征上,这些特征在处理过程中容易丢失人脸的细节信息,特别是出现混合遮挡时,人脸识别的效果会大大降低。深度学习有自主学习的优点,能够获得更具有表达性的高阶特征,提高人脸识别的准确率,但为了学习人脸图像中的被遮挡区域和未遮挡时的对应关系,使得深度卷积神经网络的结构更加复杂,在不同的通道特征和滤波器之间存在冗余造成很大的计算量。 因此,本文提出一种基于深度残差网络模型压缩的遮挡人脸识别方法,对复杂的网络结构中卷积层滤波器进行修剪,实现网络结构的稀疏表达,大大降低了网络的计算成本。 与以上方法相比,本文的方法将有效提高遮挡人脸识别的速度。
1 相关工作
目前遮挡人脸识别算法中能取得较好识别效果的网络模型,其网络参数计算量大,结构一般比较复杂。 为简化网络结构提高人脸识别速度,本文采用包含50 层网络的ResNet-50 模型作为主干网络,以残差块中的卷积层为基本单位,对每一层中的滤波器进行修剪,然后将部分无需配对的遮挡和无遮挡的人脸图像输入到稀疏化的神经网络结构中获取特征掩码,利用掩码将遮挡人脸图像的损坏特征清除以实现最终的人脸识别,其总体流程如图1 所示。

图1 人脸识别流程图Fig. 1 Flow chart of face recognition
1.1 残差网络基本原理
深度卷积网络被广泛应用于人脸识别领域并取得突破性成果,但随着识别准确率的提高,网络层数不断增加,而过深的网络会出现梯度爆炸或消失和识别性能退化的问题,因此He 等学者[4]提出残差学习的思想,在传统的卷积网络中引入残差单元能够很好地避免网络退化问题。 残差是指输入与输出之间的差异,残差单元则采用跳跃连接的方式在输入和输出之间增加了一条快捷通道,实现输出与输入相同的恒等映射层。 残差网络结构如图2 所示。图2 中,X为卷积神经网络上一层的输入,通过快捷通道将参数传递到下一层的同时保留原来的输入信息,假设期望得到的结果为H(X),让堆叠的非线性层来拟合另一个映射F(X)=H(X)- X。 那么原来的映射可以转化为F(X)+X,使每层的输出为映射和输入的叠加,其中F(X)表示残差函数,当F(X)=0 时,则表示网络训练为最佳状态,需要建立恒等映射即H(X)=X。
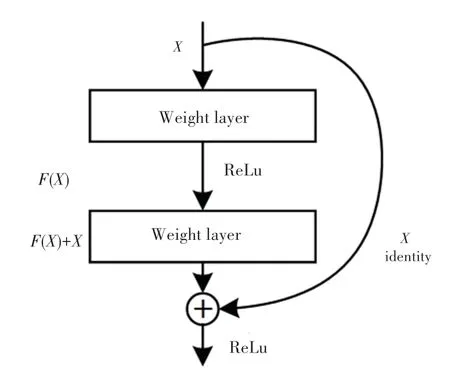
图2 残差网络结构Fig. 2 Residual network structure
残差网络包含一系列不同层数的网络结构模型,目前常见的有:ResNet-18,ResNet-34,ResNet-50,ResNet-101,ResNet-152,其后数字代表不同模型的网络层数。 本文采用残差网络ResNet-50 模型,该模型总共有50 层网络,其中包含1 个单独的卷积层、1 个全连接层和4 组不同的残差块,每组残差块包含不同数量的卷积层,网络中每个模块的具体卷积层参数见表1。

表1 网络模型参数Tab. 1 The parameters of network model
1.2 深度残差网络模型压缩
随着网络深度的增加,模型性能也不断提升,残差网络不仅解决了准确率饱和后的退化问题,还在一定程度上提高了图像特征的提取能力。 但复杂的残差网络也会存在不足,在追求网络性能的同时,模型参数量增加,训练时间变长。 因此,本文在改进的ResNet50 基础上进行结构化剪枝实现网络模型的压缩,简化网络结构复杂度的同时提高人脸识别速度。 对于一些结构简单的CNN,如VGGNet、AlexNet等,可以对任何卷积层中的滤波器进行修剪,而残差网络中的跳跃连接要保证其输入和输出的尺寸相同才能相加限制了剪枝的规则。 文中根据卷积层中滤波器的敏感程度给每一个残差块设置特定的剪枝比例对卷积层中的滤波器进行结构化剪枝,并且选用与快捷连接相同的剪枝标准如图3 所示。
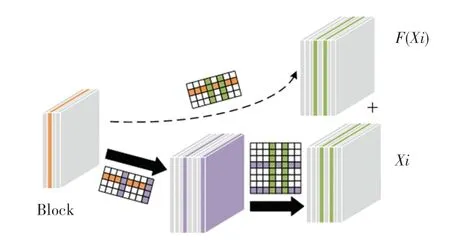
图3 ResNet50 网络剪枝原理Fig. 3 The pruning principle of ResNet50
遮挡人脸识别不仅需要设计深度卷积神经网络,为了提高学习特征的区分能力,损失函数的改进也是必不可少的,虽然Softmax被广泛应用于分类任务中,但是人脸特征存在类间距离小、类内距离大的特点对人脸识别准确率有很大的影响。 基于最大化类间方差和最小化类内方差,主流的SphereFace、CosFace 和ArcFace 中的损失函数有了很大的改进。其中,SphereFace 首次将人脸识别的特征空间转换到超球面角度特征空间。 CosFace 将Softmax损失重新表述为余弦损失,进一步最大化决策余量。ArcFace 提出一种加性角边距损失,与超球面上的测地距离对应,直接在角度空间中对分类边界进行惩罚约束,并给出了清晰的几何解释。 以上3 种方法分别加入了不同的超参数m1、m2、m3并且可以用统一的公式表达见式(1):
而SphereFace、ArcFace 和CosFace,分别表示为(m1,0,0)、(0,m2,0)和(0,0,m3)。 在本文中,采用CosFace 作为研究的训练人脸识别损失函数。
2 实验及分析
2.1 实验环境
本文中所有实验均在Ubuntu20.04 操作系统、1 块NVIDIA GTX1060 显卡、显存为4 GB 的笔记本上进行。在Visual Studio Code 上使用Python3.8.3和Pytorch1.6.0深度学习框架进行网络模型的训练和测试。
2.2 数据集介绍
(1)CASIA-Webface: CASIA-Webface 数据集由中科院自动化研究所李子青团队于2014年创建,采用半自动的方式从互联网上搜集而得来,包含了10 575个人的494 414 张图像。
(2)LFW: LFW(Labled Faces in the Wild)人脸数据集中提供的人脸图片均来源于生活中的自然场景,包含了不同姿态、表情、光照、年龄以及遮挡等因素影响的人脸图像。 该数据集共有13 233 张人脸图像,每张图像均给出对应的人名,共有5 749 人,且绝大部分人仅有一张图片,每张图片的尺寸为250×250。
(3)RMFD:由于疫情的影响,在公共场所必须佩戴口罩。 武汉大学国家多媒体软件工程技术研究中心创建口罩遮挡人脸数据集(Real-World Masked Face Dataset),其中包括真实口罩和模拟口罩两种类型,给公开数据集中的人脸佩戴口罩,包含10 000人的50 000 张人脸模拟口罩数据集。
(4)动态遮挡人脸数据集:采用文献[22]中的方法选择CASIA-Webface 数据集和LFW 人脸数据集与遮挡物合成遮挡人脸图像,遮挡物包括太阳镜、围巾、杯子和书等日常生活中经常出现在脸上的物品如图4 所示。 遮挡人脸图像是把遮挡物随机地遮挡在干净的人脸图像上,遮挡位置的大小可以按照一定的比例调节。

图4 常见遮挡面部物体Fig. 4 Common occlusion of facial objects
文中使用CASIA-Webface 和CASIA-Webface 遮挡人脸数据集作为实验的训练数据集,选用LFW、LFW 遮挡人脸数据集和RMFD 这3 个数据集作为测试数据集,部分人脸图像如图5 所示。 由于数据集中每类的样本数量有差别,先对样本数量进行统一的处理以减少训练样本不平衡问题对网络的影响。 然后,采用MTCNN[23]对人脸进行检测并提取人脸标志位,通过检测到的5 个关键点(左眼、右眼、鼻子、左右嘴角)进行相应的相似度变换,得到对齐的人脸图像。最后,将对齐的人脸图像进行剪裁,得到尺寸大小为112×96 的人脸图像。 在训练和测试时,图像的像素值均归一化为[-1.0,1.0]。

图5 人脸数据集图像Fig. 5 Face dataset images
2.3 模型训练
训练过程可以分为3 个阶段,首先,对改进ResNet50 中的残差块进行结构化剪枝,每个残差块按照一定的比例修剪其卷积层滤波器;然后,把剪枝后的网络结构在CASIA-Webface 数据集上进行周期为40 的训练;最后,将之前训练的剪枝模型作为预训练模型在CASIA-Webface 数据集和CASIAWebface 遮挡数据集按1 ∶2 的比例混合组成的训练数据集上进行再训练以减少识别误差,并生成特征掩码清除损坏特征,利用CosFace 损失函数进行遮挡人脸分类识别。 在模型训练过程中使用随机梯度下降优化,初始学习率为0.1,动量为0.9,权重衰减为0.000 5,批的大小为8。
文中考虑了2 个基准模型。 第一个是只用改进ResNet50 网络模型在CASIA-Webface 数据集上进行周期为40 的训练,称为基准1。 第二个基准选择CASIA-Webface 数据集和CASIA-Webface 遮挡数据集按1 ∶2 的比例混合组成的训练数据集,把第一个准则作为预训练模型,同样进行40 个周期的训练,称为基准2。
2.4 实验结果分析
为了研究不同的剪枝比例对该网络模型性能的影响,考虑设计5 组不同剪枝率、即R∈(0.1,0.2,0.3,0.4,0.5)的对比实验,其实验结果分别与未修剪的网络模型进行比较。 不同修剪比例下模型参数的趋势如图6 所示,实验结果表明,使用文中方法对选用的2 个基准网络结构进行训练,其模型的参数呈显著下降的趋势。 为了分析在不同修剪比率下训练的网络模型对人脸识别鲁棒性的影响,选择使用LFW 数据集和LFW 模拟口罩数据集作为测试集对网络模型的性能进行验证。 表2 中给出了不同剪枝比例的人脸识别准确率。 通过对比结果可知,随着修剪比率的增加,人脸识别准确度有所降低,但是在简化网络参数的情况下对识别性能的影响是微不足道的。

表2 不同剪枝比例的人脸识别准确率Tab. 2 Face recognition accuracy under different pruning ratios

图6 模型参数变化趋势Fig. 6 Trend of the model parameters
为了进一步评估所提出的方法在遮挡人脸识别方面的性能,采用2.2 节中描述的遮挡人脸数据集作为测试集,其中“Occ-LFW”表示LFW 数据集上40%的区域被随机遮挡,“Mask-LFW”表明将模拟口罩自动地添加到LFW 数据集。 文中方法与2 个基准模型在3 个不同数据集上的识别准确率和速度的对比结果见表3。 实验结果表明,文中的压缩模型在测试集上的识别速度均有很大提升,虽然识别精度有所损失,但是识别速度提升和模型参数减少的优势远超于误差增长。 尤其是在原始LFW 数据集上有较好的效果,在准确率下降0.76 个百分点的情况下,识别速度提升了43.54%。
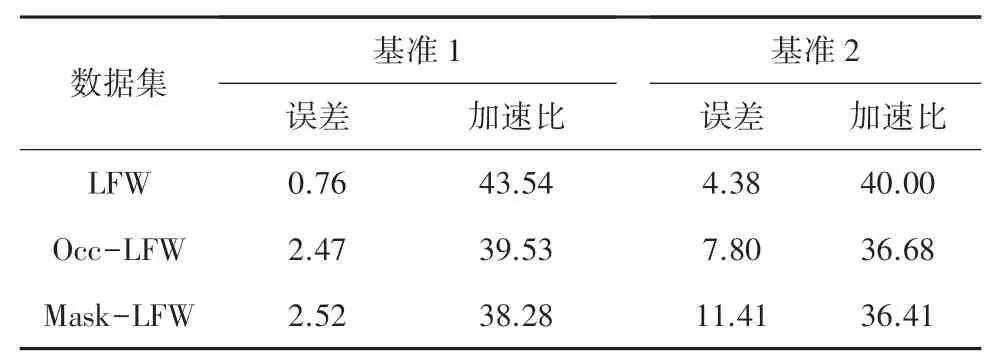
表3 不同模型实验结果对比Tab. 3 Experimental results comparison of different models %
此外,基于模型的性能和网络参数,对遮挡人脸识别误差增长和识别速度增长比做进一步分析,实验均是在相同的配置下进行,以不同修剪比例对网络模型进行训练,实验结果如图7 所示。 本文提出的压缩模型在确保识别精度受影响最小的基础上,提高了遮挡人脸的识别速度,对网络规模进行精简优化的同时,大大提高了人脸识别的时效性,使网络的复杂度和识别速度得以平衡。
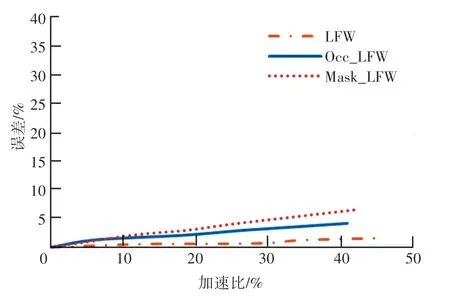
图7 人脸识别性能比较Fig. 7 Comparison of face recognition performance
3 结束语
本文提出了一种基于深度残差网络模型压缩的遮挡人脸识别方法,该方法将改进后的残差网络作为主干网络,采用结构化剪枝策略缩减模型中卷积层的冗余滤波器,实现模型的压缩,提高识别效率。在原始LFW 和遮挡人脸数据集上的综合实验表明,该模型在显著减少人脸识别时间的同时,保证了识别精度降低的最小限度。 此外,文中提出的方法在一般人脸识别上具有很好的广泛性。
猜你喜欢
保健医苑(2022年5期)2022-06-10
作文中学版(2022年1期)2022-04-14
少儿美术·书法版(2021年9期)2021-10-20
成都信息工程大学学报(2021年6期)2021-02-12
学生天地(2020年31期)2020-06-01
动漫星空(2018年9期)2018-10-26
天津诗人(2017年2期)2017-03-16
计算机工程(2015年8期)2015-07-03
发明与创新(2015年33期)2015-02-27
奇闻怪事(2014年5期)2014-05-13
