
基于对话者语句交互图神经网络的对话情感分析
2023-02-28 16:09:58杨璐娴
智能计算机与应用 2023年11期
杨璐娴,何 庆
(贵州大学大数据与信息工程学院,贵阳 550025)
0 引 言
随着大数据时代的到来,以互联网为基础的智能化设备逐渐进入人类日常生活中的各个领域,用户对于人机交互的需求日益增多,解决人机交互困境成为研究热点。 同时,互联网的发展极大地提高了人类通信交流的效率,降低了沟通成本,丰富了互联网用户通信方式和沟通渠道。 人类社交方式逐渐多元化,社交平台的迅速崛起为人类提供便利,也为人工智能技术的发展提供了海量的研究数据,对话场景下的情感分析研究应运而生[1]。
对话情感分析作为自然语言处理的新研究方向[2],由于其广泛的应用场景而受到研究人员的广泛关注,该任务旨在通过理解人类在对话中表达情绪的方式,结合对话内容及对话者信息,识别对话中的每一个语句的情感分类[3],对提升人机交互系统的用户体验具有重要的研究意义,也是人工智能领域的一个重要研究方向。 对话情感分析不仅在各种社交媒体上具有极高的应用价值,在舆情分析[4]、虚假信息检测[5]、对话系统[6]和智能客服[7]等领域也得到了广泛的应用。 对话是人类最基本的交流方式,具有明显的不连贯性和弱逻辑性,区别于篇章级的文本情感分析,对话文本的信息往往语言不连续且存在较大的跳跃性。 对话情感分析与其余的文本情感分析任务本质上的区别在于信息的交互性。 对话信息的获取依赖于对话语句发生的时序性、对话中的历史信息,对于多方多轮次的对话文本,对话信息还依赖于对话者信息及其对应语句发生的轮次等。 因此,在对话的交互过程中,需要建模对话中的语句上下文语境,改变了情感分析模型的基本建模框架,给情感分析任务带来了极大的挑战[8]。
对话场景下的语句情感判定具有复杂性。 对话示例如图1 所示,该对话是在2019年公开的数据集MELD[9]中选取的一个3 方6 轮对话文本。 对话者Chandler 的第二句话“真孩子气”在一般情况下会被判定为“愤怒”,但是在该场景中这句话实际上表达了对话者“悲伤”的情绪。 由此可见,在不同对话场景下语句所表达的情感是复杂且多样的,与对话内容的历史信息、上下文语境、对话者情感状态及情绪变化等信息有极高的关联度。 因此,如何准确地捕捉对话过程中的上下文信息、语句情感信息以及与之相关联的对话者信息是本文的研究重点。

图1 对话示例Fig. 1 Examples of conversation
在目前的对话情感分析任务模型中,主流研究模型几乎都需要对对话的上下文依赖信息进行建模,之前的工作已经提出了许多模型用于对上下文依赖信息建模,包括记忆网络[10]、递归神经网络[11]等模型,这些实验都取得了令人满意的效果,但是由于受到网络存储容量限制,导致远距离上下文信息丢失,难以有效传入当前对话中。 此外,人类情绪具有惰性和干扰性两种特性。 其中,情绪惰性是指在没有外界干扰的情况下,对话者自身的情绪会长期保持在同一个状态下;情绪的干扰性是指对话者保持在一个情绪状态时,由于其他对话人的话语刺激,激发了对话者的情绪变化。 因此,还需要充分考虑对话者信息以便建模对话者之间的情绪交互。
针对上述问题,本文提出了一种基于对话者语句交互图神经网络的对话情感分析模型。
(1)通过微调RoBERTa 预训练语言模型提取语句特征,引入Bi-GRU 建模对话文本序列上下文特征。
(2)通过图神经网络建模对话上下文,并引入不同类型的有向边和对话者节点建模对话者及其语句交互信息。
(3)在MELD 公开数据集上进行大量实验,验证了本文方法的有效性。
1 相关工作
对话场景下的文本情感分析作为一个具体问题场景,其研究历史较之其他文本情感分析问题的研究较短。 目前,对话情感分析的方法主要采用基于深度学习和基于图神经网络的方法。 对话情感分析任务在前期侧重于先建模对话中语句的上下文依赖关系,Poria 等学者[12]提出了一种基于LSTM 的上下文信息提取模型,用于视频模态的情感识别任务。Zahiri 等学者[13]提出一种用于对话文本的序列的卷积神经网络模型。 Hazarika 等学者[10]引入对话记忆网络,将每一位对话者的历史语句信息融入记忆网络,建模对话者之间的交互关系。 Majumder 等学者[14]利用GRU 建模对话序列信息、对话者和倾听者的情绪交互状态,再引入注意力机制捕捉长距离历史信息。 由于近几年图神经网络方法在建模结构化数据中取得的巨大进展,将图神经网络方法应用于对话场景下的情感分析任务也逐渐成为研究热点。 Zhang 等学者[15]通过连接语句节点之间无向边和对话者语句间的无向边建模上下文依赖和对话者情感依赖信息,提出多方对话中的情感分析方法。Hu 等学者[16]利用图卷积神经网络融合对话者内部信息和多模态对话数据,并取得较好的效果。
综上,虽然基于深度学习方法在对于对话语言顺序建模上有较好的适应能力。 但是,对于参与者较多、对话篇幅较长的多方多轮对话中,深度学习方法的网络结构变得复杂,难以保留远距离历史信息。利用图神经网络对多轮对话进行建模具有更强的可解释性,可以更好地解决这一问题。
2 基于对话者语句交互图神经网络的对话情感分析模型
一个完整的对话由多个语句组成,在对话情感分析任务中,给定的对话文本U =u1,u2,…,un,其中ui表示对话U中的第i句话,n表示语句个数。 对于多方对话文本,每个语句所对应的说话人表示为p(ui) ∈P,P =p1,p2,…,pm,m表示说话人个数。对话文本的情感分析任务目的在于预测对话中每个独立语句ui的情绪标签。 参见图1 的简单对话示例,对话中的第6 句话:“真是胆小鬼!”,仅关注句子本身很难识别说话人真实的情绪,对话情感分析依赖于对话发生的顺序、对话上下文语境以及对话者人信息等。 本文模型框架如图2 所示。
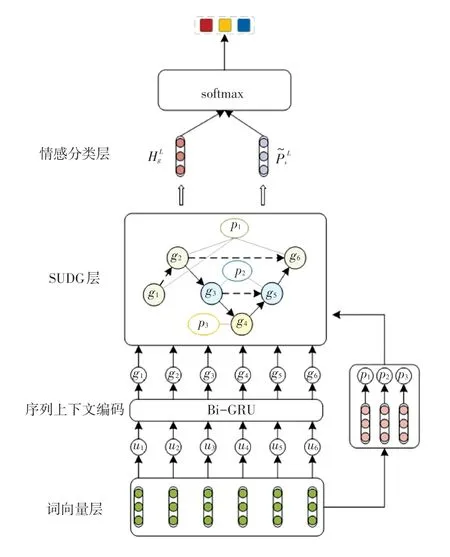
图2 模型框架Fig. 2 Framework of the model
2.1 对话特征提取
对于对话语句的特征表示,本文通过微调RoBERTa 预训练语言模型将对话文本序列转换为词向量形式。 为便于训练和微调,本文将对话语句ui定义为“[CLS],”作为模型中对话语句的输入。 数学表达式如下所示:
对于对话者特征表示,本文将训练集中一个对话者所说的所有语句特征的平均值设为该对话者的特征表示。 在进行实验时,若某对话者只出现在测试集中,则将测试集中该对话者所说的所有语句特征平均值设置为该对话者特征表示。
2.2 序列上下文层级编码
对话的进行是连续且有序的,上下文信息会根据对话顺序流动,所以对话的语句顺序上下文信息是对话中的重要特征。 GRU 是RNN 的一种变体,相较于RNN,保留了长期序列信息,并且减少了梯度消失的问题,但由于GRU 无法编码从后往前的依赖信息,造成对话信息缺失,因此引入Bi-GRU 来生成文本的序列上下文特征,其数学模型如下:
2.3 对话者语句交互有向图模型SUDG
2.3.1 对话图构建
本文,将对话图定义为G ={Vg,Vs,ε,R},其中Vg ={g1,g2,…,gn} 表示对话中的语句节点,Vs ={p1,p2,…,pm} 表示对话者节点,ε表示连接这些节点和边的信息集合,R ={r1,r2,r3} 表示边的关系类型。 考虑到多方对话中多名不同对话者之间的情绪交互影响,本文将边关系类型定为3 种:
(1)同一对话者说出的不同语句节点间的边为r1;
(2)不同对话者说出的语句节点之间的边为r2;
(3)每个语句节点与其对应的对话者节点之间的边为r3。
由于对话的进行具有时序性,对话中已发生的语句可以对对话者的情绪产生影响,继而影响即将发生的语句情感,反之,未发生的语句却不能影响已发生的语句情感。 因此,r1和r2是有向边,根据对话发生顺序模拟对话中的时间关系。r3为无向边,用于传递整个对话中语句与其对应的对话者信息。
图3 是根据图1 构建的对话者语句交互图示例。对话中有6 个语句{g1,g2,…,g6},3 个对话者{p1,p2,p3},其中g1、g2、g6来自对话者p1,g3、g5来自对话者p2,g4来自对话者p3。 图3 中的有向虚线、即r1,有向实线、即r2,无向实线、即r3。
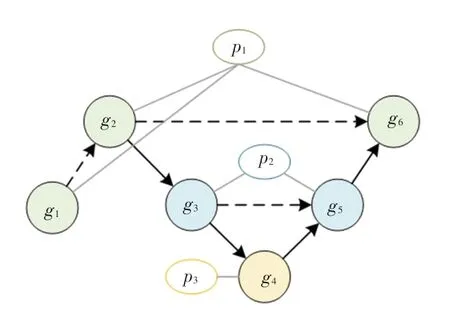
图3 对话者语句交互图示例Fig. 3 Sample of Speaker utterance interaction graph
2.3.2 SUDG 层
SUDG 模型是一个异构有向图神经网络,有2种不同的节点,因此需要2 种不同的信息传播方法。对于语句节点Vg需要考虑对话序列上下文信息和对话者信息,而对于对话者节点Vs只需要考虑其对应的语句。 因此邻接矩阵A也需要分为不同模块:
其中,A∈R(n+m)∗(n+m);Ag表示语句之间的边;As表示对话者节点与其语句之间的边;O是0 矩阵。 同时,定义语句节点的特征矩阵为,对话者节点的特征矩阵为。
对话信息根据语句顺序传递,语句节点要聚合相邻节点信息和边关系类型信息,而SUDG 构建的对话图是多关系图,语句节点间的边关系类型有r1和r2两种,因此本文引入基于不同关系的图注意力机制计算注意力权重。 对于节点Vgi通过节点在l层的隐层特征和边关系特征计算得到注意力权重,数学模型如下:
语句节点在l +1 层的最终表示如式(8)所示:
给定对话者的所有语句的聚合特征可以通过邻接矩阵As计算:
融合对话者信息的对话语句的特征表示如下:
2.3.3 情感分类
本文将所有图网络层的对话语句隐藏层状态拼接作为对话语句的最终表示,通过一个全连接层和softmax层即可预测对话语句的情绪标签,数学模型如下:
其中,S表示情绪标签合集。
本文使用标准交叉熵作为损失函数:
3 实验与结果分析
3.1 实验数据集
本文使用的是2019年公开的英文数据集MELD[9]。 MELD 来自于美剧《老友记》部分内容片段,包含1 433 段对话,超过13 000 句话,每句话都被标注了情绪标签,标签分为中性、愤怒、厌恶、高兴、恐惧、悲伤和惊讶7 种情绪分类。 MELD 是一个包含多名对话者的多模态数据集,本文只关注于文本模态数据,数据集具体内容见表1。

表1 数据集参数Tab. 1 Parameters of datasets
在验证实验中,为了衡量模型对所有标签的分类精确度和有效性,本文使用宏平均F1分数作为评价指标。
3.2 实验设置
本文实验在型号为NVIDA GTX 3090 的GPU服务器上进行,使用Intel(R) Core(TM) i5-7500 处理器,内存大小为8 GB,选用版本号为Ubuntu 18.04.3 LTS 的Linux 操作系统,模型是基于PyTorch 深度学习框架搭建。 模型在训练的过程中采用Adam优化器来优化模型参数,通过验证集调整超参数,学习率为1×10-5,丢失率为0.3,批量大小为32。
3.3 与基准模型比较
本文选用以下模型进行对比分析:
(1)KET[17]:使用一个外部知识网络增强语句信息,再结合上下文感知情感图注意力机制动态的增强上下文信息,以增强情感分类的性能。
(2)DialogueRNN[14]:使用GRU 建模对话者状态和全局上下文信息,聚合对话者的情绪状态,建模对话者间的关系,可应用于多方对话场景。
(3)DialogueGCN[18]:使用GCN 增强上下文信息,以句子为节点,对话图中基于固定上下文窗口连接不同关系节点,提出句子和对话者之间的有8 种关系类型,同时考虑历史信息和未来信息。
(4)DAG-ERC[19]:通过有向无环图建模对话上下文,对话图以边关系类型建模对话者与句子关系,只关注历史信息。
(5)RGAT[20]:对不同对话者关系位置编码建模对话结构,使用图注意力网络更新节点,同时考虑历史信息和未来信息。
(6)ICON[21]:使用记忆网络储存对话者情感信息和全局状态信息,是一个多模态情感检测框架。
在MELD 数据集上的情感分析实验结果见表2。

表2 不同模型结果对比Tab. 2 Comparison with others model
根据表2 可知,在MELD 数据集上,SUDG 与ICON 模型相比F1值提高了10.11%,提升效果最佳,说明SUDG 更适用于文本特征任务。 与使用RNN 和GCN 的模型相比F1值分别提高了7.73%和6.66%,说明在多方多轮对话语境中,过于复杂的模型反而会因为计算量庞大,导致上下文信息部分丢失,影响分类效果。 与KET 模型和RGAT 模型相比,F1值提高了6.58%和3.85%,说明基于图网络的方法能更好地建模对话上下文信息,高效的传递对话历史信息。 与DAG-ERC 模型相比,F1值提高了1.11%,说明加入语句对话者信息能丰富对话中的上下文语境信息,同时证明了本文在图网络中加入语句对话者节点构图策略的有效性。
3.4 消融实验
为了验证各个组件对模型的影响,本文进行了消融实验,具体内容如下:
(1)SUDG/R:移除序列上下文编码部分和对话者交互有向图模型。
(2)SUDG/C:仅移除序列上下文编码部分,其他层保持不变。
(3)SUDG/H:仅移除对话者交互有向图模型,其他层保持不变。
(4)SUDG/S:移除对话者交互有向图模型中所有的对话者节点,引入一个随机初始化的全局节点代替原始对话者节点的位置,同时全局节点连接所有语句节点,用以验证融合对话者与对应语句关系信息的有效性,其他层保持不变。
消融实验结果对比见表3。 根据表3 可知,相比于只使用了RoBERTa 语言模型的SUDG /R 而言,SUDG /H 和SUDG /C 的F1值分别提高了5.89%和11.55%,说明在多轮对话中语句情感对上下文信息依赖性强,将对话上下文信息进行顺序建模可以大幅度提高模型情感分类效果,并且基于图神经网络的方法能更有效地传递对话历史信息。 相比于将对话者节点全部替换为全局节点的SUDG/S模型,SUDG 的F1值提高了1.60%,说明对话者节点与其对应语句连接可以有效提升模型对语句信息的提取,降低引入冗余信息的概率,提高模型情感分类准确率。 SUDG 整体性能表现最佳,表现出全方位性能的显著提升,展示不同模型间的协同互补。

表3 消融实验结果对比Tab. 3 Results of ablation experiments
4 结束语
本文提出一种基于对话者交互图神经网络的对话情感分析模型(SUDG)。 利用RoBERTa 预训练语言模型提取文本特征;针对多轮多方对话文本中语句情感对语句序列的高依赖性,结合Bi-GRU 将对话语句进行序列上下文编码;通过图结构建模对话上下文依赖关系,引入对话者信息节点,连接对话者节点及其对应语句,以提高对话情感分析中的上下文信息理解能力,传递远距离历史信息,减少冗余信息的引入,提高模型情感分类准确率。 实验结果表明了SUDG 模型的有效性,在MELD 数据集上与其他模型相比,该模型在对话情感分析中表现出良好的分类效果。 本文关注了对话者信息对语句情感的增强作用,未来将探索如何引入外部知识库增强语句情感信息。
猜你喜欢
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14 07:36:02
新世纪智能(语文备考)(2020年4期)2020-07-25 02:28:50
电子制作(2018年17期)2018-09-28 01:56:44
通信电源技术(2018年5期)2018-08-23 01:15:36
新课程研究·上旬(2018年3期)2018-06-30 06:26:16
环球时报(2018-06-04)2018-06-04 06:16:06
作文评点报·低幼版(2017年44期)2017-11-16 08:24:58
教育界·下旬(2016年4期)2016-11-19 21:19:13
文史博览(2016年2期)2016-03-23 09:11:55
语文知识(2014年4期)2014-02-28 21:59:52
