
一种基于奇偶相关性网络的基音周期隐写分析方法
2023-02-28 09:46王嘉伟楼芊驿戴望宇杨洁
现代信息科技 2023年20期
王嘉伟 楼芊驿 戴望宇 杨洁

摘 要:由于基音周期参数在语音编码过程中具有不可预测性,因此,很多隐写算法都将隐藏信息嵌入到基音周期中。目前已有多种基于基音周期的检测方法,但是如何准确的做到信息隐藏检测仍是一项挑战。文章提出了一种基于奇偶相关性网络的基因周期隐写分析方法。实验结果表明,该方法可以有效地检测基于基音周期的隐写术。实验结果表明,提出的方法可以有效地检测基于基音周期的隐写术,具有良好的实时性和健壮性。
关键词:信息隐藏检测;SVM;语音码流
中图分类号:TP309.7 文献标识码:A 文章编号:2096-4706(2023)20-0092-05
A Steganographic Analysis Method for Fundamental Tone Period Based on
Parity Correlation Networks
WANG Jiawei, LOU Qianyi, DAI Wangyu, YANG Jie
(College of Engineering and Technology, Jiyang College of Zhejiang A&F University, Shaoxing 311800, China)
Abstract: Due to the unpredictability of fundamental tone period parameters during the speech coding process, many steganographic algorithms embed hidden information into fundamental tone period. At present, there are many detection methods based on fundamental tone period, but how to accurately detect information hiding is still a challenge. In this paper, a steganographic analysis method for fundamental tone period based on parity correlation network is proposed. Experimental results show that the proposed method can effectively detect steganography based on fundamental tone period, and has good real-time performance and robustness.
Keywords: information hiding detection; SVM; speech coding flow
0 引 言
信息隐藏,亦称为隐写术,是一种利用数字文件或网络协议嵌入秘密信息的安全技术。一般情况下,秘密信息都是被隐藏在公开的媒体信息中,诸如互联网协议(文本、图像、语音、视频)等网络。相对于传统的保密技术,隐写技术的优势在于其不易被攻击者所察觉。因此,隐写术可以应用于隐蔽通信。
近年来,随着移动网络和智能手机的发展,VoIP(Voice over IP, IP语音)通信中的语音码流已经成为当今信息隐藏技术最受欢迎的载体,与其他秘密通信载体相比,VoIP具有明显的优势。例如,其大容量的数据嵌入可以提供高隐蔽带宽,其即時性可以提供实时通信环境。因此,在网络电话、即时消息等移动通信中得到广泛应用,基于语音的信息隐藏及信息隐藏检测技术也成为近年来的研究,而且目前基于VoIP的隐写技术也已经做了很多工作。
在国内外,G.723.1等语音编码技术广泛应用于流媒体语音通信中,这使得低速速率语音成为更好地隐藏载体。为适应语音实时传输的需要,LSB替换算法成为许多针对低速率语音的隐写算法的借鉴首选。Huang等人[1]尝试在VoIP语音中引入LSB(Least Significant Byte,最低有效位)匹配隐写。Liu等人[2]在LSB算法上做了一些改进,并给出了LSD隐藏算法。Huang等人[3]对活动帧的提取检测方法进行了改良,并构建了一种以语音非活动帧为媒介的信息隐藏算法,不过其仍然采用LSB替代方法,因此语音品质有很大的细节损失。另外一种改进隐写算法实时性的方法是把语音压缩和信息隐藏结合起来,并将其嵌入到低速率语音编码当中。Xiao等人[4]提出了一种基于量化索引调制(Quantization index modulation, QIM)的用于低速率语音编码的新算法。这种方法虽然提高感知透明度,但也降低了其隐藏容量。刘程浩等人[5]利用基音闭环搜索的编码区域,对隐藏信息进行了有效的隐藏。该方法在提高了隐藏容量的同时,也降低了嵌入的速度,导致了对信息的透明感知性的降低。对于G.723.1基音周期,Huang等人[6]提出一种隐写方法。该方法通过限定每帧里的四个子帧的基音周期值,然后设计出了15种不同的隐写方法。这种方法具有很好的实时性,但是在很高的嵌入速率下,隐藏的失真情况非常严重。严书凡等人[7]对G.723.1的基频周期进行了分析,并以此为基础,提出了基于基音周期的双层隐写算法。
与隐写术相比,隐写分析的发展过程总是相对滞后的。然而,现仍然有大量有效的方法被提出。针对LPC,Li等人[8]发现,在QIM隐写后,线性预测编码滤波器系数的分割矢量量化码本的相关特性发生了变化。基于这一观察结果,他们构建了定量码本相关网络模型,并在量化修剪网络的定点相关特征后获得特征向量。实验表明,该方法在隐写检测中取得了较好的效果。此外,对于新的基音延迟隐写术也提出了一些有效的检测方法来应对。Li等人[9]提出了一种在G.723.1比特流中检测QIM隐写术的方法。他们根据量化索引序列中每个量化索引分布的相关性和不平衡性提取这些特征向量。基于量化索引序列中每个量化索引分布的相关性和不平衡性,提取一种新的特征向量,用于检测G.723.1编码流中的QIM隐写术。实验表明,该方法在隐写术检测中取得了良好的结果。然而,Ren等人[10]提出了一种新的方法来分析自适应多速率(Adaptive Multi-Rate, AMR)语音隐写,并获得了较好的效果。基于AMR原音与隐写语音邻接基音周期连续性的差异,他们计算了二阶马尔可夫转移概率特征矩阵(Second-Order Markov Transition Probability, MSDPD),然后通过校正后减去MSDPD得到C-MSDPD。随后Liu等人提出了一种奇偶贝叶斯概率(PBP)特征[11],该方法维度低,且PBP的检测效果优于C-MSDPD,是目前最有效的基音延迟隐写检测方法。
基音延迟是语音编解码器中最重要的参数之一。Hess等人指出,基音周期具有相当大的冗余性,无法做到准确预测,所以这意味着它是一个可行的隐写位置。通过T0和T2搜索T1和T3的闭环基音可以由基音周期搜索原理分析结果得出。根据编码原理的分析,通过改变闭环基音来嵌入秘密信息的隐写方法会扭曲子帧之间的连接。在确定当前子帧之后,下一个子帧的基音延迟范围已经缩小,奇偶校验改变的可能性也相应地缩小。但在现有隐写术的条件下,基音延迟值的分布趋于集中,因此可以推断,现有的隐写术破坏了闭环的奇偶相关性,并对基音周期延迟分布的稳定性产生了负面影响。随后,本文应用帧内奇偶分布的概率分布来说明隐写术在基音延迟中的效果。在没有隐写的情况下,奇偶分布在一帧内的分布是不均匀的,而隐写后每一帧内的奇偶分布会变得更均匀。因此,本文选择差异的奇偶性来描述这种变化。然而,现有结论中并没有证明帧内每个子帧的具有某种相关性。因此,Liu等人采用当前子帧和下一子帧的奇偶相关性定理来描述它们的相关性。本文提出了一种新方法,贡献如下:
1)提出帧间子帧相关性的概念,提出一种基音周期奇偶相关性网络算法。
2)将条件概率作为分类特征,最后利用支持向量机进行分类,以判断样本是否为隐写样本。
1 基于奇偶相关性网络的基因周期隐写分析方法
1.1 特征提取过程
LPC线性预测的基本功能是获得10阶LPC滤波器的10个系数,并将其转换为线谱以量化参数LSF。在G.723(6.3 kbit/s)语音编码器中,使用7比特编码的为ACL0和ACL2,用2比特编码的为ACL1和ACL3。根据Liu等人描述,原始样本和隐写样本中的基音延迟奇偶校验贝叶斯概率之间存在明显差异。他们将基音延迟的贝叶斯公式作为特征(PBP)。本文提出了基音周期奇偶相关性网络(PDPCN)。由于基音延迟状态为奇数或偶数,且这是两个相互排斥的事件,因此只需将其中一个记录为特征。本文在此做简单介绍。
第一种特征是第1子帧和第2子帧之间的关系,包括两种情况:P1和P2。P1是在第二个子帧出现奇数的条件下,第一个子帧出现奇数的条件概率。P2是在第二个子帧出现偶数的条件下第一个子帧出现奇数的条件概率,如式(2)所示:
同樣,第二种特征是第1子帧、第2子帧和第3子帧之间的关系。这些特征包括四个情况,分别是P3~P6,如式(3)所示:
第三种特征是在确定第1子帧、第2子帧和第3子帧的情况下,第4子帧是奇数的条件概率。这些特征包括八种情况,分别为P7~P14,如式(4)所示:
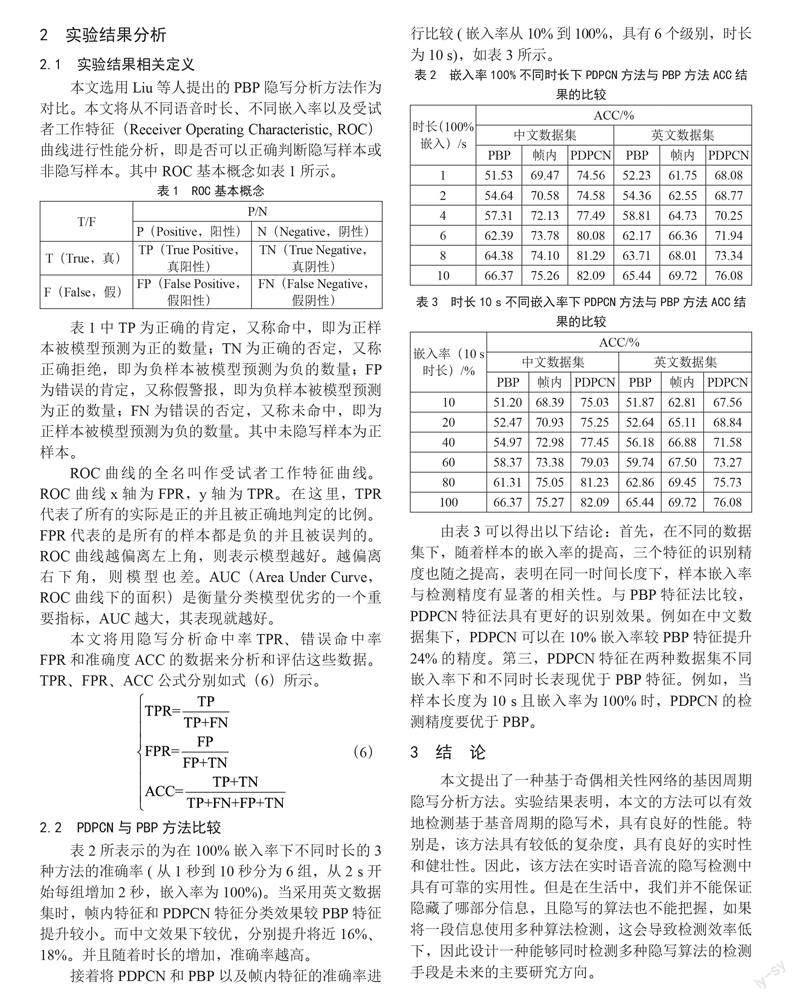
上述特征提取的全部过程都是基于帧内之间的相关性,具体特征之间的相关性如图1所示。
由此,本文构建帧间网络,将每帧的每个子帧和下一帧的各个子帧分别融合,如图2所示。
融合后共有24个帧间系数Ck,其中k ∈ {0,1,2,3},融合公式如式(5)所示。其中i ∈ {1,2,3,4},j ∈ {1,2,3,4}。再将C4k+1~C4(k+1)为一组分为四组分别做P1~P14的条件概率公式的特征提取,共得到56个特征值。最后,将所有这些70维特征组合到PDPCN特征中。
1.2 SVM训练流程
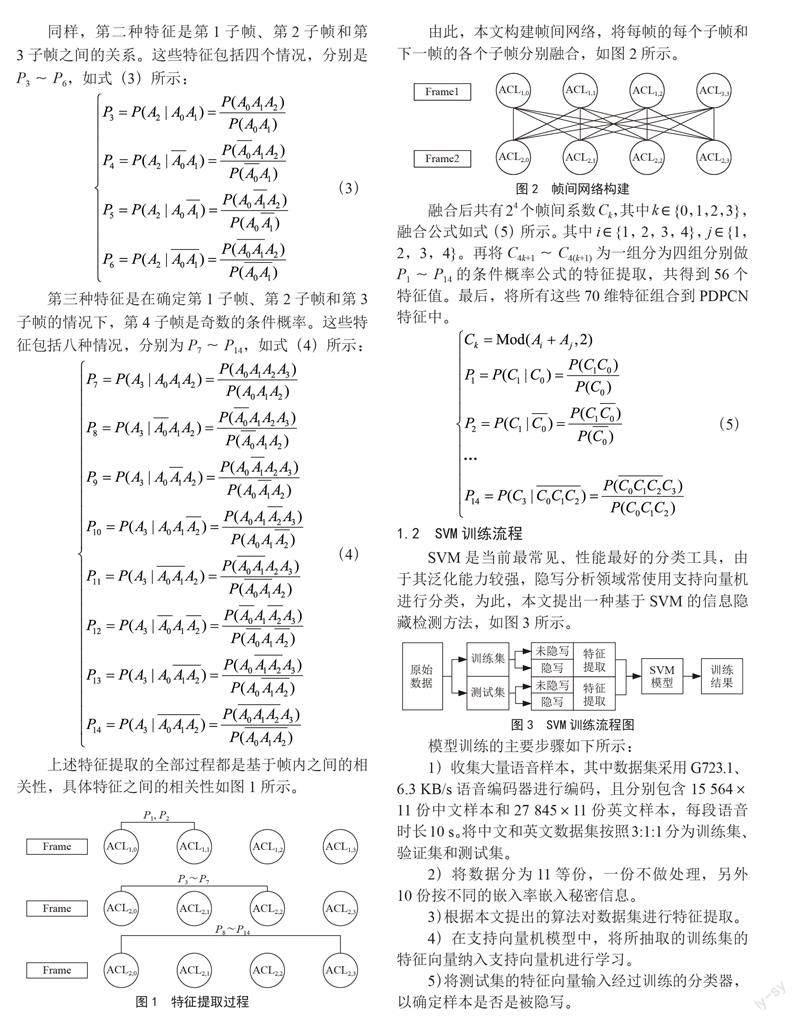
SVM是当前最常见、性能最好的分类工具,由于其泛化能力较强,隐写分析领域常使用支持向量机进行分类,为此,本文提出一种基于SVM的信息隐藏检测方法,如图3所示。
模型训练的主要步骤如下所示:
1)收集大量语音样本,其中数据集采用G723.1、
6.3 KB/s语音编码器进行编码,且分别包含15 564×
11份中文样本和27 845×11份英文样本,每段语音时长10 s。将中文和英文数据集按照3:1:1分为训练集、验证集和测试集。
2)将数据分为11等份,一份不做处理,另外10份按不同的嵌入率嵌入秘密信息。
3)根据本文提出的算法对数据集进行特征提取。
4)在支持向量机模型中,将所抽取的训练集的特征向量纳入支持向量机进行学习。
5)将测试集的特征向量输入经过训练的分类器,以确定样本是否是被隐写。
2 实验结果分析
2.1 实验结果相关定义
本文选用Liu等人提出的PBP隐写分析方法作为对比。本文将从不同语音时长、不同嵌入率以及受试者工作特征(Receiver Operating Characteristic, ROC)曲线进行性能分析,即是否可以正确判断隐写样本或非隐写样本。其中ROC基本概念如表1所示。
表1中TP为正确的肯定,又称命中,即为正样本被模型预测为正的数量;TN为正确的否定,又称正确拒绝,即为负样本被模型预测为负的数量;FP为错误的肯定,又称假警报,即为负样本被模型预测为正的数量;FN为错误的否定,又称未命中,即为正样本被模型预测为负的数量。其中未隐写样本为正样本。
ROC曲线的全名叫作受试者工作特征曲线。ROC曲线x轴为FPR,y轴为TPR。在这里,TPR代表了所有的实际是正的并且被正确地判定的比例。FPR代表的是所有的样本都是负的并且被误判的。ROC曲线越偏离左上角,则表示模型越好。越偏离右下角,则模型也差。AUC(Area Under Curve,ROC曲线下的面积)是衡量分类模型优劣的一个重要指标,AUC越大,其表现就越好。
本文将用隐写分析命中率TPR、错误命中率FPR和准确度ACC的数据来分析和评估这些数据。TPR、FPR、ACC公式分别如式(6)所示。
2.2 PDPCN与PBP方法比较
表2所表示的为在100%嵌入率下不同时长的3种方法的准确率(从1秒到10秒分为6组,从2 s开始每组增加2秒,嵌入率为100%)。当采用英文数据集时,帧内特征和PDPCN特征分类效果较PBP特征提升较小。而中文效果下较优,分别提升将近16%、18%。并且随着时长的增加,准确率越高。
接着将PDPCN和PBP以及帧内特征的准确率进行比较(嵌入率从10%到100%,具有6个级别,时长为10 s),如表3所示。
由表3可以得出以下结论:首先,在不同的数据集下,随着样本的嵌入率的提高,三个特征的识别精度也随之提高,表明在同一时间长度下,样本嵌入率与检测精度有显著的相关性。与PBP特征法比较,PDPCN特征法具有更好的识别效果。例如在中文数据集下,PDPCN可以在10%嵌入率较PBP特征提升24%的精度。第三,PDPCN特征在两种数据集不同嵌入率下和不同时长表现优于PBP特征。例如,当样本长度为10 s且嵌入率为100%时,PDPCN的检测精度要优于PBP。
3 结 论
本文提出了一种基于奇偶相关性网络的基因周期隐写分析方法。实验结果表明,本文的方法可以有效地检测基于基音周期的隐写术,具有良好的性能。特别是,该方法具有较低的复杂度,具有良好的实时性和健壮性。因此,该方法在实时语音流的隐写检测中具有可靠的实用性。但是在生活中,我们并不能保证隐藏了哪部分信息,且隐写的算法也不能把握,如果将一段信息使用多种算法检测,这会导致检测效率低下,因此设计一种能够同时检测多种隐写算法的检测手段是未来的主要研究方向。
参考文献:
[1] HUANG Y,BO X,XIAO H. Implementation of Covert Communication Based on Steganography [C]//4th International Conference on Intelligent Information Hiding and Multimedia Signal Processing.Harbin:IEEE,2008:1512-1515.
[2] LIU J,KE Z,HUI T. Least-significant-digit steganography in low bitrate speech [C]//IEEE International Conference on Communications.Ottawa:IEEE,2012:1133-1137.
[3] HUANG Y F,TANG S,YUAN J. Steganography in Inactive Frames of VoIP Streams Encoded by Source Codec [J].IEEE Transactions on Information Forensics and Security,2011,6(2):296-306.
[4] XIAO B,HUANG Y F,TANG S Y. An Approach to Information Hiding in Low Bit-Rate Speech Stream [C]//Global Telecommunications Conference.New Orleans:IEEE,2008:1-5.
[5] 刘程浩,柏森,黄永峰,等.一种基于基音预测的信息隐藏算法 [J].计算机工程,2013,39(2):137-140.
[6] HUANG Y F,LIU C H,TANG S Y,et al. Steganography Integration Into a Low-Bit Rate Speech Codec [J].IEEE transactions on information forensics and security,2012,7(6):1865-1875.
[7] 严书凡,汤光明,孙怡峰.基于基音周期预测的低速率语音隐写 [J].计算机应用研究,2015,32(6):1774-1777.
[8] LI S,JIA Y,KUO C. Steganalysis of QIM Steganography in Low-Bit-Rate Speech Signals [J].IEEE/ACM Transactions on Audio,Speech,and Language Processing,2017,25(5):1011-1022.
[9] LI S,TAO H,HUANG Y. Detection of quantization index modulation steganography in G.723.1 bit stream based on quantization index sequence analysis [J].Journal of Zhejiang University SCIENCE C,2012,13:624-634.
[10] REN Y,YANG J,WANG J,et al. AMR Steganalysis Based on Second-Order Difference of Pitch Delay [J].IEEE Transactions on Information Forensics and Security,2017,12(6):1345-1357.
[11] LIU X,TIAN H,LIU J,et al. Steganalysis of Adaptive Multiple-Rate Speech Using Parity of Pitch-Delay Value [M].[S.I.]:Springer,2019:288-289.
作者簡介:王嘉伟(2000—),男,汉族,浙江温州人,本科在读,主要研究方向:信息隐藏、深度学习;楼芊驿(2003—),女,汉族,浙江杭州人,本科在读,主要研究方向:信息隐藏、深度学习;戴望宇(1999—),男,汉族,浙江台州人,学士,主要研究方向:信息隐藏、机器学习;通讯作者:杨洁(1989—),男,汉族,重庆开州人,副教授,博士,主要研究方向:信息安全、多媒体信息处理。
收稿日期:2023-04-17
基金项目:国家级大学生创新创业训练计划项目(202213283001);浙江农林大学暨阳学院科研训练计划资助项目(JYKC2205)
