
融合情感轮注意力的情感分布学习
2023-02-28 09:19陈启凡曾雪强左家莉万中英王明文
计算机工程与应用 2023年4期
陈启凡,曾雪强,左家莉,万中英,王明文
江西师范大学 计算机信息工程学院,南昌 330022
情感分析的任务目标是挖掘出数据中蕴含的人们的情感倾向[1-2],在个性化推荐[3]和智能客服系统[4]等多个新兴的人工智能场景具有重要的应用价值。情感分析主要包括3 个子任务,即情感信息抽取、情感信息分类和情感信息检索与归纳[2]。本文的研究聚焦于情感信息分类,目标是提升情绪识别模型的泛化性能。
传统的情绪识别模型,大部分基于单标记学习(single label learning)或多标记学习(multi-label learning),为示例关联一个或多个情绪标签,不能定量地分析具有不同表达强度的多种情绪[5]。为了解决这一问题,Zhou等人于2015年在面部表情识别任务中首次提出情感分布学习(emotion distribution learning,EDL)[6]。EDL 借鉴标记分布学习(label distribution learning,LDL)[5,7]的研究思路,认为文本和图像等媒介表达的情感是多种基本情绪的混合,各种基本情绪在同一示例上具有不同的表达强度。示例的各个基本情绪的表达强度介于0和1之间,所有基本情绪的表达程度之和为1。所有基本情绪在某个示例上的表达程度共同构成一个情感分布(emotion distribution)[6]。在文本情绪识别任务中,一个句子同时表达多种强度不同的基本情绪是一种常见的现象。如图1所示,SemEval文本情感数据集[8]对每个句子在6 种基本情绪上的表达程度都给出了具体评分。EDL通过情感分布对多种情绪同时进行表示,可以较好地处理存在情绪模糊性的情绪识别任务。
人类情感是一个复杂的现象,各种基本情绪之间高度相互关联,呈现出正相关性或负相关性。正相关的情绪更有可能同时发生,负相关的情绪则很少一起出现[9]。例如,图1中的例句1标注了悲伤和恐惧两种基本情绪,其中悲伤是主导情绪。通过对文本内容进行人工分析,发现例句1还应该蕴含有惊讶情绪(在图1中用虚框标出)。进一步分析会发现,惊讶与悲伤是在心理学上高度正相关的两种情绪。例句2 的情况与例句1 相似,通过人工分析可以发现该句子蕴含未标注的与悲伤情绪高度相关的厌恶情绪。如何在情感分析模型中有效地考虑情绪之间的相关性,是各种情绪识别模型的一个常见的研究思路。
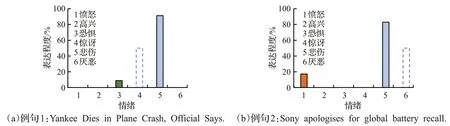
图1 SemEval文本情感数据集的两个例句(虚框标识的情绪是通过人工分析新发现但数据集未标注的情绪)Fig.1 Two example sentences from SemEval text sentiment dataset
近年来,EDL 是机器学习领域的一个研究热点,国内外许多学者在国际顶级会议和期刊上发表了多个EDL 有关的研究工作[10-14]。从已有的研究工作看,在EDL 模型中考虑情绪标签之间的相关性是一个重要的研究方向。比如,Jia 等人[10]于2019 年利用局部低秩结构捕捉标签局部相关性,提出了一种基于标签局部相关性的面部情感分布学习方法;Xu和Wang[11]于2021年提出一种基于注意力机制的情感分布学习方法,取得图像的各个区域与情感分布之间的关系。以上这些工作的基本思路是在EDL模型中增加考虑从训练数据中挖掘出的情绪相关性,并取得了一定的效果。然而,目前在EDL 模型中引入基于心理学先验知识的情绪相关性的工作还比较少。
普鲁契克情感轮是心理学家罗伯特·普鲁契克于1980年提出的一种经典的心理学情感模型,用于描述人类基本情绪之间的相关性[15]。普鲁契克认为人类情感是由8种基本情绪(愤怒、期待、高兴、信任、恐惧、惊讶、悲伤和厌恶)构成的混合表达。这8种基本情绪共同构成一个情感轮,相邻位置的两个情绪具有正相关性,相对位置的两个情绪为负相关。两种基本情绪的间隔角度越小,其情绪正相关性越高;基本情绪的间隔角度越大,其情绪负相关性越高。总体上,情感轮上的间隔角度代表对应情绪间的心理学相关程度。He 和Jin 于2019 年在图像情绪识别任务上提出考虑心理学先验知识的基于图卷积神经网络的EDL 方法,取得了不错的效果[12]。但是该工作的模型结构相对较为简单,包含先验知识的图卷积网络的训练相对独立。到目前为止,还没有EDL工作采用注意力机制将基于情感轮的心理学先验知识直接融合到深度学习网络中。
为了在EDL模型中有效地引入心理学先验知识以提升情感分析性能,本文提出了一种基于情感轮注意力的情感分布学习(emotion wheel attention based emotion distribution learning,EWA-EDL)模型。EWA-EDL模型在经典的文本卷积神经网络的基础上,通过注意力机制将基于心理学的情绪相关性先验知识引入神经网络,再采用多任务损失函数同时学习情感分布预测和情绪分类任务。EWA-EDL 模型主要由5 部分构成,分别为输入层、卷积层、池化层、注意力层和多任务损失层。输入的句子在输入层表示为词嵌入向量的矩阵,再使用卷积层的多个不同宽度的滤波器生成新的输出特征,随后在池化层中基于标准的最大池化操作获取特征中的最大值。在注意力层,EWA-EDL 模型为每个基本情绪构建一个基于普鲁契克情感轮的先验情感分布,并通过注意力机制将各个情绪的先验情感分布融合为一个最终的情感分布输出。在最后的多任务损失层中,EWAEDL模型将KL损失和交叉熵损失结合,同时学习情感分布预测和情绪分类两个任务。本文在英文情感分布数据集(SemEval 2007 Task14[8])、4 个英文单标签数据集(CBET[16]、ISEAR[17]、TEC[18]和Fairy Tales[19])和3 个中文单标签数据集(NLP&CC 2013、NLP&&CC 2014[20]和WEC[21])上进行对比实验。实验结果表明,EWA-EDL模型在情感分布预测和情绪分类任务上的性能均优于对比的EDL模型。
1 相关工作
传统的文本情感分析主要是对句子进行情感极性分类,即判别情感的正面、负面或中性极性[2]。然而,情感极性识别模型无法捕捉细粒度情绪,只适用于简单的情感分析任务。与传统的情感极性分析不同,细粒度情感分析的目标是识别文本中的细粒度情绪[6],即愤怒、期待和高兴等具体情绪。经典的细粒度情绪识别模型一般基于单标记学习或多标记学习进行建模,为示例关联一个或多个情绪标签[5]。
细粒度情绪识别模型能够处理很多情感分析任务,但是其建模能力仍有不足,无法定量表示示例蕴含的表达程度不同的多种情绪[13]。在实际应用中,很多句子存在同时表达多个程度不同的情绪的情况。例如,常用的SemEval文本情感数据集对句子的6种细粒度情绪的表达程度都进行了标注[8]。如图1所示,悲伤是例句1的主要情绪,表达程度达91.10%;作为次要情绪的恐惧的表达程度为8.82%。例句2的主要情绪(悲伤)的表达程度是82.85%,次要情绪(愤怒)的表达程度为17.14%。
为了定量地处理一个示例同时表达多种强度不同的情绪的情况,Zhou 等人[6]借鉴标记分布学习(LDL)[5]的研究思路,于2015 年提出情感分布学习(EDL)。此后,Zhou 等人[13]于2016 年提出面向文本的EDL 方法。一个句子可能表达一种或多种情绪,每种情绪的表达强度不同。本文使用表示句子x中情绪y的表达强度。各种情绪在每个句子上的表达强度得分构成一个情感分布,通过向量归一化保证。需要注意的是,不是概率,而是情绪y在情感分布中所占的比例。如果认为是概率,则意味着一个句子只有一个情绪标签是正确的,而EDL 认为一个示例同时包含多种情绪。EDL 的建模目标是学习一个从句子空间X=ℝm到情感分布空间Y={y1,y2,…,yc}的映射,每个标签yi代表一种基本情绪。
情感分布学习可以有效地处理一个示例同时表达多种情绪的问题,适用于存在情绪模糊性的任务[6]。近年来,许多学者在EDL 领域提出了多个有效的研究工作[10-14]。按照是否考虑情绪标签间相关性的角度划分,现有的EDL工作可以分为如下三大类:
不考虑情绪标签相关性的方法。早期的大部分EDL 工作不考虑情绪标签间的相关性,例如Zhou 等人[13]使用最大熵模型从句子文本直接预测情感分布,没有考虑情绪的相关性;Zhang 等人[22]提出基于多任务卷积神经网络(multi-task convolutional neural network,MT-CNN)的EDL 模型,同时优化情感分布预测和情绪分类任务;Li等人[23]将单词与具有定量强度的细粒度情感标签联系起来,提出了一种结合领域知识和维度词典来生成词级情感分布向量的新方法。
从训练数据学习标签相关性的方法。此类方法是当前EDL方法的一个热门研究方向。Jia等人[10]在人脸表情识别任务上挖掘数据中的局部标签相关性进行情感分布学习;Fei 等人[14]提出一种潜在情感记忆网络学习数据中潜在的情感分布,并将其有效地利用到分类网络中;Xu 和Wang[11]提出一种基于注意力机制的情感分布学习方法,取得图像的各个区域与情感分布之间的关系。
通过引入外部先验知识考虑标签相关性的方法。此类方法利用心理学情感先验知识,考虑情绪标签间的相关性,以提升情绪识别模型的泛化性能。目前考虑情感先验知识的EDL 工作还比较少,He 和Jin[12]提出一种基于情感轮心理学模型的情绪图卷积网络的EDL方法(EmotionGCN)。EmotionGCN 主要由两部分组成:用于提取图像特征的CNN 模块和考虑先验知识的基于GCN 的权重生成器。实验结果表明EmotionGCN 在图像EDL 任务上具有较好的性能。但是EmotionGCN 的模型结构较为简单,学习情绪标签相关性的GCN 模块和基于图像的CNN 模块相对独立,仅采用矩阵相乘将两个模块的输出直接合并在一起。研究者们需要提出更有效地将心理学先验知识直接融合到深度学习网络中的EDL工作。与MT-CNN和EmotionGCN相比,本文提出的EWA-EDL 模型基于情感轮心理学模型定义各个基本情绪之间的距离并生成相应的先验情感分布,通过注意力机制将各个情绪的先验情感分布融合于卷积神经网络模型,再采用多任务损失函数以端到端的方式同时学习情感分布预测和情感分类任务。
2 基于情感轮注意力的情感分布学习
2.1 普鲁契克情感轮
根据心理学的研究,人类的情绪之间具有明确的相互关联[15]。某些情绪经常会同时出现,即表现出很高的正相关性;而另外一些情绪则相反。罗伯特·普鲁契克于1980 年提出的情感轮理论,是一种从心理学角度描述人类情绪间相互关系的经典模型[15]。普鲁契克情感轮(Plutchik’s wheel of emotions)包含愤怒(anger)、厌恶(disgust)、悲伤(sadness)、惊讶(surprise)、恐惧(fear)、信任(trust)、高兴(joy)和期待(expect)8 种基本情绪。如图2所示,8种基本情绪在情感轮中分为4组对立的情绪,对角位置的情绪具有负相关性,位置相邻的情绪具有正相关性。
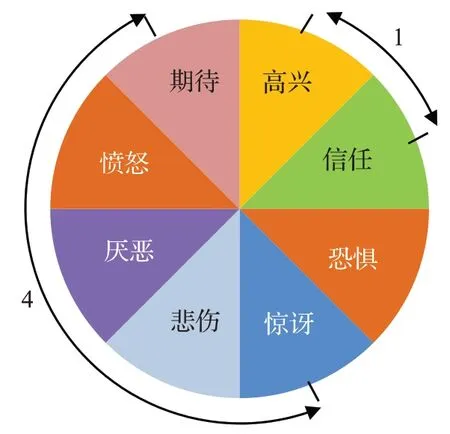
图2 普鲁契克情感轮Fig.2 Plutchik’s wheel of emotions
按照情绪在情感轮中的间隔角度的大小,定义情绪之间的心理学距离。两种情绪每间隔45°,距离定义为1。两种情绪的间隔角度越小,其心理学距离越小,情绪相似性越高。如图2 所示,高兴和信任是相邻情绪,间隔角度为45°,距离定义为1;期待和惊讶是对立情绪,间隔角度为180°,距离设定为4。
在EDL 领域,已有一些研究工作将情感轮作为先验知识使用[12-13]。例如,Zhou 等人[13]在基于最大熵模型的EDL方法的优化目标中引入基于普鲁契克情感轮的情绪约束条件,取得了不错的效果。He 和Jin[12]提出一种基于图卷积神经网络和情感轮的EDL 方法,表现出了不错的性能。但是总体而言,基于情感轮的EDL 工作还比较少。目前,还没有EDL 工作采用注意力机制将基于情感轮的心理学先验知识直接融合到深度学习网络中。
2.2 基于普鲁契克情感轮注意力的情感分布学习
本研究将注意力机制引入基于普鲁契克情感轮的心理学先验知识,采用多任务深度卷积神经网络,提出基于情感轮注意力的情感分布学习(EWA-EDL)模型。EWA-EDL模型的构架如图3所示。
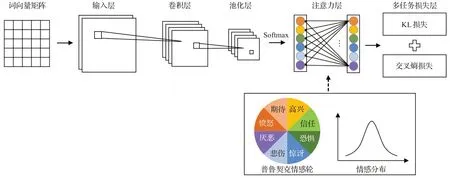
图3 基于情感轮注意力的情感分布学习模型构架图Fig.3 Overall framework of emotion wheel attention based emotion distribution learning model
给定一个由N条句子构成的文本训练集S=,其中是句子si对应的情感分布,表示第j种情绪在句子si上的表达程度,∈[0,1]且。EWA-EDL 的建模目标是学习到一个从句子si到情感分布di的映射。EWA-EDL 同时优化两个训练任务,分别为情感分布预测和情绪分类。EWA-EDL的模型构架由5部分组成,分别为输入层、卷积层、池化层、注意力层和多任务损失层。
输入层:EWA-EDL模型的输入是由M个单词构成的句子。将第m个单词wm表示为一个k维的词嵌入向量xm∈ℝk。然后,将该句中所有的词向量连接在一起,组成词向量矩阵:
如果句子文本的长度未达到M,在词向量的最后用0 补齐,将每条句子表示为一个维度为k×M的词向量矩阵。
卷积层:卷积层包含多个滤波器ω∈ℝh×k,其中h为窗口宽度,每个滤波器产生一个新的特征表示。设xp:p+h-1表示词xp,xp+1,…,xp+h-1的连接,则特征vp是采用滤波器ω在一组词xp:p+h-1上计算得到,公式如下:
其中,f(·)是一个非线性激活函数,比如Sigmoid 或ReLu 函数,b是偏差值。滤波器窗口覆盖到句子中的所有词x1:h,x2:h+1,…,xM-h+1:M,可以产生一组特征图v:
池化层:一系列标准的最大池化操作运用到特征图v上,用来获取特征中最大值作为重要特征:
注意力层:注意力机制最初在计算机视觉领域被提出,主要目的是让神经网络根据需要将注意力集中于图像的特定部分,而不是整体图像[24]。Bahdana 等人[25]于2014 年将注意力机制成功应用于自然语言处理领域。鉴于注意力机制在自然语言处理任务上表现优秀,本文采用注意力机制在基于深度网络的EDL模型中引入情感心理学先验知识。首先为每种基本情绪生成一个描述情绪间相关度的先验情感分布,再通过注意力机制加权,预测最终的情感分布。
依据各种情绪在情感轮模型中的心理学距离,为每个情绪α,α∈{1,2,…,C},生成一个先验情感分布fα。在先验情感分布fα中,情绪标签α的值应该最大,表达程度最高,其他情绪的值随着离情绪标签α在情感轮中的距离增大而减小。总体而言,先验情感分布fα应该是一个以情绪标签α为中心,左右对称递减的分布。根据Geng 等人[26]的基于LDL 的人脸年龄预测工作的结论,假设先验情感分布服从高斯分布。给定情绪标签α,基于高斯分布生成先验情感分布fα,计算公式如下:
其中,σ是先验情感分布的标准差,Z是归一化因子,使得是情绪a与真实情绪α之间的情感轮距离。例如,高兴和惊讶的先验情感分布分别为[4.03×10-2,9.17×10-1,4.03×10-2,8.12×10-4,3.42×10-6,8.12×10-4]和[4.51×10-4,4.51×10-4,2.33×10-1,5.09×10-1,2.33×10-1,2.24×10-2]。
其中,fj是第j个情绪αj的先验情感分布。
具体而言,EWA-EDL 模型的注意力层的计算过程如图4所示。以初步预测的情感分布g=[0,0.7,0,0.3,0,0]为例,对各个基本情绪的先验情感分布进行注意力加权。加权后,只有高兴和惊讶两个情绪的输出不为0,对应的加权先验情感分布分别为[2.82×10-2,6.42×10-1,2.82×10-2,5.68×10-4,2.39×10-6,5.68×10-4]和[1.35×10-4,1.35×10-4,7.00×10-2,1.52×10-1,7.00×10-2,6.72×10-3]。最后,对加权的情感分布进行融合,得到注意力层最终的预测情感分布[2.83×10-2,6.42×10-1,9.82×10-2,1.53×10-1,7.00×10-2,7.28×10-3]。
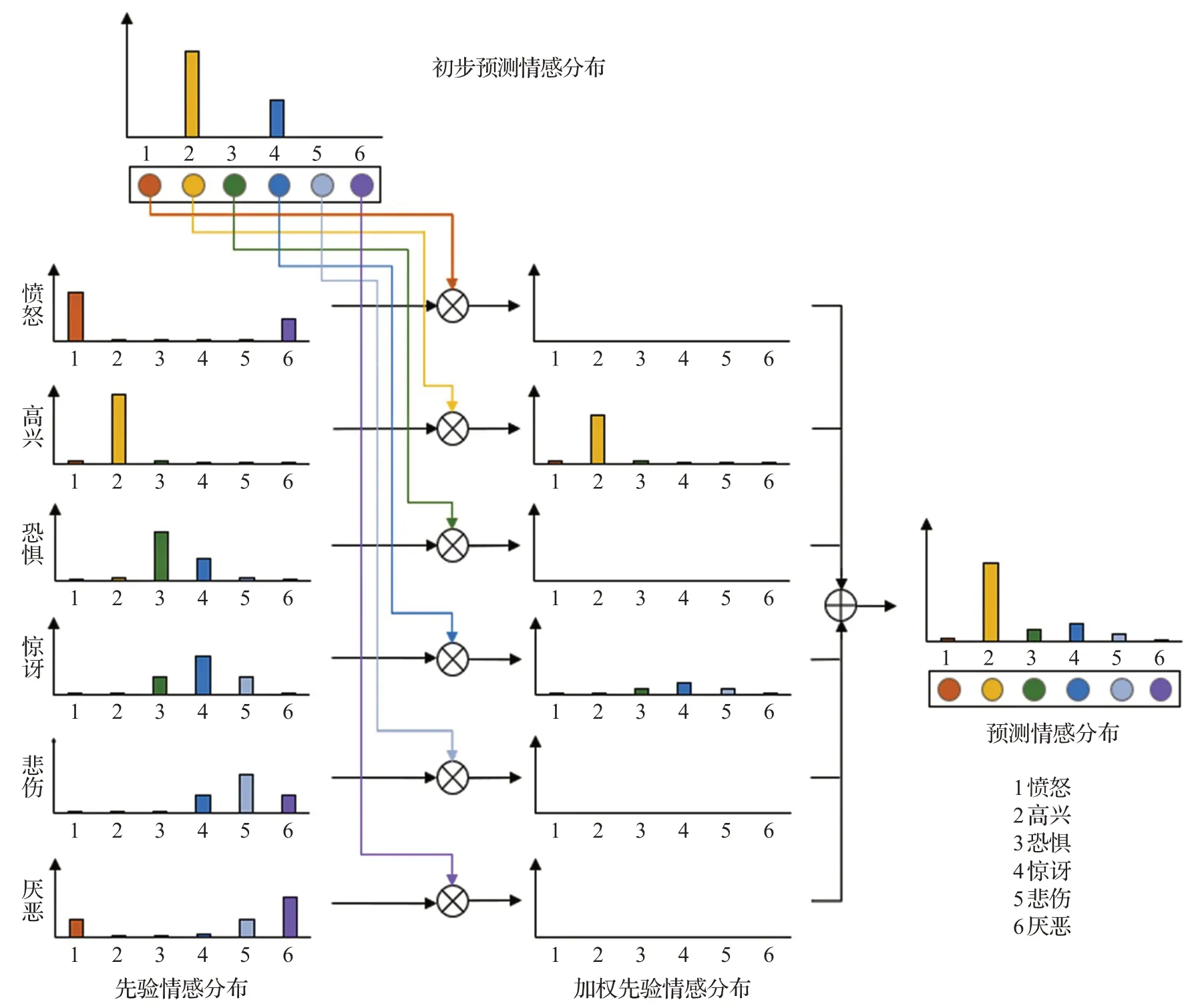
图4 EWA-EDL模型的注意力层示意图Fig.4 Schematic diagram of attention layer of EWA-EDL model
多任务损失层:EWA-EDL 模型将交叉熵损失函数和KL 损失函数结合,采用端到端的方式同时训练情感分布预测和情绪分类任务。两个同时训练的学习任务可以相互促进,学习得到更鲁棒的神经网络模型。对于已标注情感分布的数据集,情感分布di中表达程度最高的情绪作为句子si的真实情绪标签,用于情绪分类。对于没有标注情感分布的单标签数据集,采用标记增强技术(label enhancement)[27]将真实情绪标签扩展为情感分布。
EWA-EDL 的目标损失函数是交叉熵损失和KL 损失的加权组合,计算公式如下:
其中,Ecls代表用于情绪分类任务的交叉熵损失,Eedl是情感分布预测任务的KL 损失,λ是权重参数。根据前人的研究工作[22],λ设置为0.7。
交叉熵损失最大化目标标签的概率,是一种常用于分类任务的目标函数,定义为:
其中,1(δ)是指标函数,当δ为真时1(δ)=1,否则为0,yi是句子si的真实情绪标签,表示句子si在最后一层的输出值。
对于情感分布预测,KL 损失度量预测分布和真实分布之间的差异,具体定义如下:
Zhang 等人提出的基于多任务卷积神经网络(MTCNN)的EDL 模型[22],以端到端的方式同时训练情感分布预测和情绪分类任务,取得了不错的效果,但是MTCNN模型没有考虑心理学先验知识。本研究将在实验部分对EWA-EDL和MT-CNN模型的性能进行对比。
3 实验结果与分析
为了考察本文提出的EWA-EDL 模型的性能,进行了3 组实验,分别是分析先验情感分布的参数σ对EWA-EDL模型性能的影响,对比多种EDL方法在中英文数据集上的情绪预测性能和比较3 种基于深度网络的EDL模型在7个单标签数据集上的情绪分类性能。
3.1 实验设置
本文实验采用了8 个文本情感数据集,分别是SemEval情感分布数据集(SemEval 2007 Task14[8])、4个单标签英文数据集(CBET[16]、ISEAR[17]、TEC[18]和Fairy Tales[19])和3 个单标签中文数据集(NLP&CC 2013[20]、NLP&&CC 2014[20]和WEC[21])。表1列出了所有中英文实验数据集的详细信息,包括各个情绪的句子数量、全部句子数量和每个句子的平均单词数量。
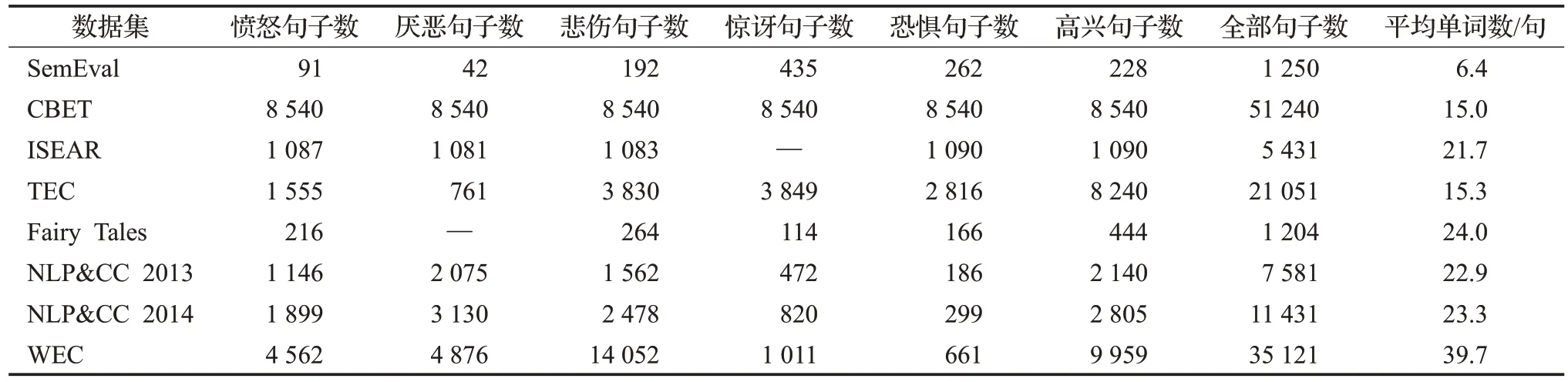
表1 中英文实验数据集Table 1 Chinese and English experimental datasets
本文采用的5 个英文文本数据集的基本情况如下。SemEval数据集[8]是标注了多种情绪表达强度的情感分布数据集,包含1 250条新闻标题,每个新闻标题有6个情绪标签及其对应的表达强度,即愤怒、高兴、恐惧、惊讶、悲伤和厌恶。SemEval 数据集主要从New York Times、CNN、BBC 和Google 新闻等主流英文报纸收集新闻标题。CBET 数据集[16]由76 860 条推特文本组成,包含9种情绪,每种情绪有8 540条推文。从CBET数据集选用了普鲁契克情感轮包括的6种情绪(愤怒、高兴、恐惧、惊讶、悲伤和厌恶)共51 240条推文。ISEAR数据集[17]包含7 666 条句子和7 种情绪标签。句子的内容是人们描述他们经历某种情绪(愤怒、高兴、恐惧、悲伤、厌恶、羞耻和内疚)时的现场情况和经验。本文实验选用ISEAR 数据集中的5 种情绪(愤怒、高兴、恐惧、悲伤和厌恶)和5 431 条句子。TEC 数据集[18]包括21 051 条情绪推文,每条推文均标注了6 种情绪之一,即愤怒、高兴、恐惧、喜悦、惊讶和悲伤。Fairy Tales 数据集[19]从185个童话故事中摘抄1 204条英文句子,共有5种情绪(愤怒、高兴、恐惧、惊讶和悲伤),每条句子标注1 个情绪标签。
在中文数据集方面,NLP&CC 2013 和NLP&CC 2014 单标签中文数据集[20]分别包含从新浪微博采集的32 185 条句子(10 552 条情绪句和21 633 条无情绪句)和45 421 条句子(15 690 条情绪句和29 731 条无情绪句)。NLP&CC 2013和NLP&CC 2014数据集包含7种情绪,即愤怒、高兴、恐惧、惊讶、悲伤、厌恶和喜欢。本文保留了其中的6种情绪(愤怒、高兴、恐惧、惊讶、悲伤和厌恶),并从这两个数据集分别选取了7 581和11 431条情绪句。WEC(Weibo emotion corpus)数据集[21]是香港理工大学于2016 年基于微博文章构建的情感语料库,共包含7种情绪(愤怒、高兴、恐惧、惊讶、悲伤、厌恶和喜欢)。本文选用WEC 数据集中的6 种情绪(愤怒、高兴、恐惧、惊讶、悲伤和厌恶)共35 121条句子进行实验。
英文数据集的文本预处理步骤如下:首先,去除标点符号等特殊字符,仅保留英文字母和数字。然后,将所有英文字母转为小写,并对单词进行词干化处理。最后,采用开源的预训练word2vec词嵌入模型[28]将每个单词表示为300 维的向量。word2vec 模型在GoogleNews数据集的大约1 000 亿个词上训练得到,词典包含大约300万个词。对于中文文本的预处理步骤如下:首先,去除标点符号等特殊字符,仅保留中文和数字。然后,采用Jieba 分词工具(https://github.com/fxsjy/jieba)进行中文分词。最后,采用中文预训练词向量模型Chinese Word Vector[29]将每个单词表示为300维的向量。Chinese Word Vector模型包括85 万个词,在百度百科等中文语料库上的大约1.36 亿个词上训练得到。对于词嵌入模型的未登录词,采用均匀分布U(-ε,ε) 进行随机初始化,其中ε设置为0.01。作为神经网络模型的输入,每个句子均通过预处理转换为一个300 维的词嵌入矩阵。句子最大的单词数设为每个数据集中最长句子的单词数。预训练的词嵌入向量在神经网络的训练过程中保持固定。
为了合理评估模型的性能,实验设置采用标准的分层十折交叉验证(stratified 10-fold cross-validation)。具体步骤是,在保持类别比例的前提下,将数据集平均分成10 份,每份作为测试集使用1 次,对应的剩余数据合并为训练集,如此重复10 次。交叉验证中的每一折都是一次独立的EDL 情绪预测任务,在每一折的实验中随机抽取训练集的1/10 作为验证集。为了使实验结果具有可比性,参与对比的模型均采用一致的数据划分。各个评价指标在10 次交叉验证上的平均值,用于评价EDL模型的最终性能。
对于情感分布预测任务,采用6种常用的EDL指标来评价预测的情感分布的质量,包括Euclidean、Sφrensen、Squaredχ²、KL Divergence、Cosine 和Intersection[13]。对于情绪分类任务,采用4 种分类评价指标,分别是精确率(Precision)、召回率(Recall)、F1 分数(F1-score)和准确率(Accuracy)。另外,EWA-EDL 模型的参数设置如表2所示。
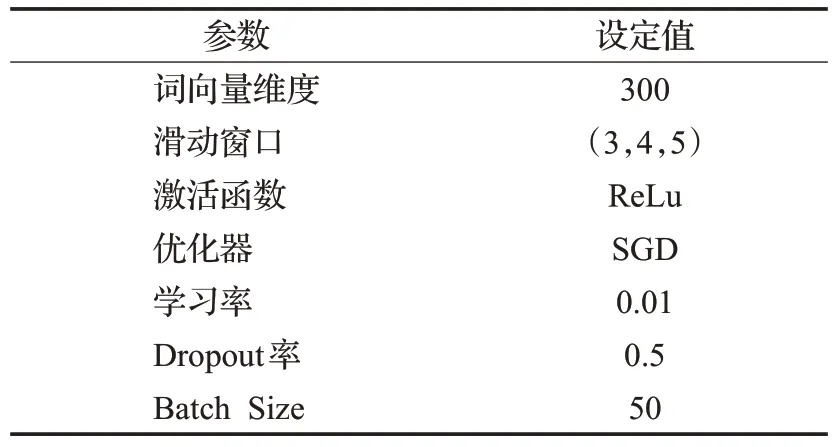
表2 EWA-EDL模型参数设置Table 2 EWA-EDL model parameter settings
本文的实验在1 台联想工作站上运行,主要硬件配置为Intel 酷睿i9-10900X 3.70 GHz 10 核CPU 和128 GB内存。操作系统为Ubuntu 18.04,深度学习框架采用Pytorch 1.5.0。
3.2 先验情感分布参数σ 对EWA-EDL 模型性能的影响
先验情感分布的标准差参数σ用于控制由真实情绪标签生成的情感分布的离散程度,是影响EWA-EDL模型性能的一个重要参数。当σ越大时,情感分布越分散,高斯分布曲线越扁平;当σ越小时,情感分布越集中,情感分布曲线越瘦高。为了分析标准差参数σ对EWA-EDL 模型性能的影响,将参数σ从0 到1 取值,每间隔0.1 取值一次,记录对应的Accuracy 和Cosine 指标的变化情况。在SemEval数据集上先验情感分布参数σ对EWA-EDL模型性能的影响实验结果如图5所示。
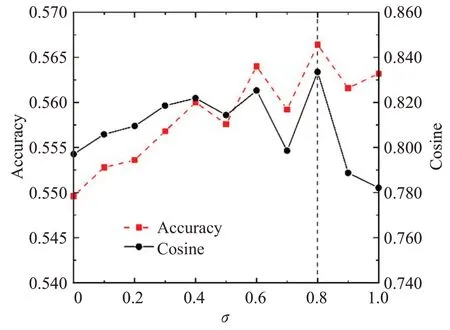
图5 先验情感分布参数σ 对EWA-EDL模型性能的影响Fig.5 Effect of prior emotion distribution parameter σ on performance of EWA-EDL model
如图5 所示,EWA-EDL 模型在SemEval 数据集的情绪预测任务上,评价指标Accuracy 和Cosine 均在σ=0.8 时达到最高。当σ 取值在0 到0.7 之间时,Accuracy和Cosine基本上呈现逐步上升的趋势,说明将单个情绪标签扩展为情感分布时,适当增加情感分布的离散程度有益于提升EDL 模型的性能。当σ=0.8 时,Cosine 和Accuracy达到最高值,说明此时生成的情感分布的离散程度最优。以惊讶情绪为例,σ=0.8 时的先验情感分布为[4.51×10-4,4.51×10-4,2.33×10-1,5.09×10-1,2.33×10-1,2.24×10-2]。当σ取值增加到0.8与1.0之间时,评价指标Cosine和Accuracy出现明显下降,说明此时真实情绪在情感分布中的得分过低,生成情感分布的离散程度过大。以上实验结果表明,在保持真实情绪的主导地位同时,适当增加先验情感分布的离散程度有助于提升EDL模型的性能。
3.3 多种学习模型的情感分布预测和情绪分类性能对比
为了评估本文提出的EWA-EDL 模型在情感分布数据集上的情感分布预测和情绪分类性能,将EWAEDL与常用的EDL和LDL方法进行对比,包括AA-BP、SA-BFGS、SA-IIS、SA-LDSVR、AA-KNN、SA-CPNN[5]、TextCNN[30]和MT-CNN[22]。AA-KNN 和AA-BP 是经典的KNN 算法和BP(back propagation)神经网络的扩展版本,以解决LDL 任务[5]。SA-LDSVR、SA-IIS、SABFGS 和SA-CPNN 是为LDL 任务专门设计的算法[5]。TextCNN[30]是用于文本情感分类的卷积神经网络模型。MT-CNN[22]是Zhang 等人提出的用于文本EDL 的多任务卷积神经网络模型。8 种情感分布学习方法在SemEval 数据集上的情感分布预测和情绪分类的具体实验结果如表3 所示(表3 中每种指标的最优结果用加粗标出,↑表示该指标越大越好,↓表示该指标越小越好)。
由表3可见,本文提出的EWA-EDL模型在SemEval数据集上总体表现出比其他LDL方法和EDL模型更好的性能。在情感分布预测和情绪分类任务的所有10个指标上,EWA-EDL 模型均优于SA-CPNN、AA-KNN、SA-LDSVR、SA-IIS、SA-BFGS 和AA-BP 模型。在情感分布预测任务上,EWA-EDL模型除了在KL Divergence指标上略低于MT-CNN 模型0.25%外,在其他5 项指标上均表现出最优结果。例如在Cosine 指标上,EWAEDL比次优的MT-CNN模型提升了0.9%。在情绪分类任务上,EWA-EDL 模型同样表现出优秀的性能。例如在Accuracy 指标上,EWA-EDL 模型比次优的MT-CNN模型高出1.68个百分点。在Recall、F1和Accuracy这3个情绪分类指标上,EWA-EDL 模型均取得了最优得分。以上实验结果表明,EWA-EDL 模型具有比对比的EDL模型更为优秀的情绪预测性能。普鲁契克情感轮可以较好地描述基本情绪之间的相关性,通过注意力机制引入基于情感轮的心理学先验知识对提升EDL模型的性能具有明显的效果。
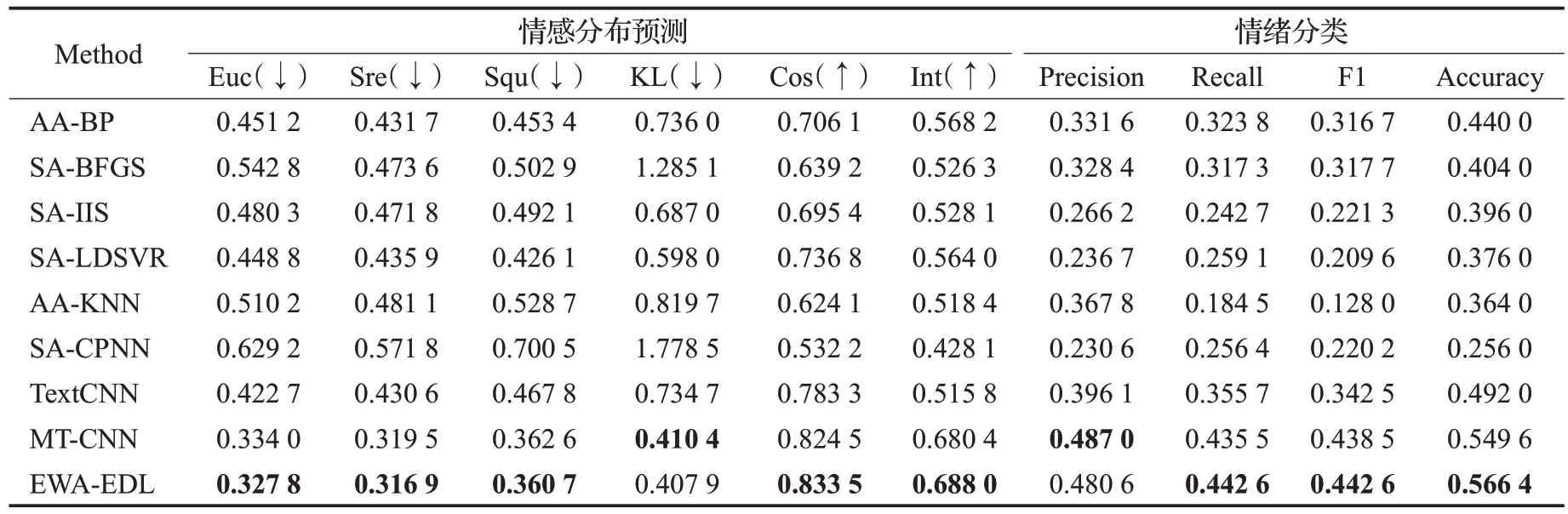
表3 在SemEval数据集上8种EDL方法的性能对比Table 3 Performance comparison of 8 emotion distribution learning methods on SemEval dataset
3.4 基于深度网络的情感分布学习模型的情绪分类性能对比
为了评估EWA-EDL 模型在传统的单标签情感数据集上的性能,在4个英文单标签数据集(CBET、ISEAR、TEC和Fairy Tales)和3个中文单标签数据集(NLP&CC 2013、NLP&&CC 2014 和WEC)上进行了情绪分类性能对比实验。在单标签数据集上,使用LLE(lexicon based emotion distribution label enhancement)标记增强方法[22,31]将示例的情绪标签增强为情感分布。标记增强方法生成的情感分布作为训练样本的监督信息使用。LLE方法在句子的真实情绪标签之外,引入文本中的情感词信息生成情感分布,具有较好的性能[22]。将EWA-EDL 模型与基于深度神经网络的TextCNN[30]和MT-CNN 模型[22]进行对比实验,具体的实验结果如表4所示(表4中每种指标的最优结果用加粗标出)。
由表4 的结果可以看出,本文提出的EWA-EDL 模型在7 个单标签数据集上总体表现出比TextCNN 和MT-CNN模型更优的性能。以F1分数和准确率指标为例,EWA-EDL模型在7个数据集上均取得了最优的得分。具体而言,在CBET、ISEAR、TEC、Fairy Tales、NLP&&CC 2013、NLP&&CC 2014和WEC数据集上,EWA-EDL模型的F1 得分比MT-CNN 模型分别高出1.25 个百分点、1.12 个百分点、1.07 个百分点、3.62 个百分点、0.49 个百分点、0.31 个百分点和0.17 个百分点,比TextCNN 模型分别高出1.49个百分点、2.82个百分点、3.57个百分点、4.87个百分点、2.74个百分点、6.58个百分点和1.61个百分点。在所有7 个数据集的平均准确率上,EWA-EDL模型比MT-CNN 和TextCNN 模型分别高1.04 个百分点和3.27 个百分点。实验结果说明,在基于深度网络的EDL 模型中引入心理学先验知识有助于提高情绪分类任务的性能。本文提出的EWA-EDL 模型有效地利用了心理学知识,比TextCNN 和MT-CNN 模型具有更好的情绪分类性能。
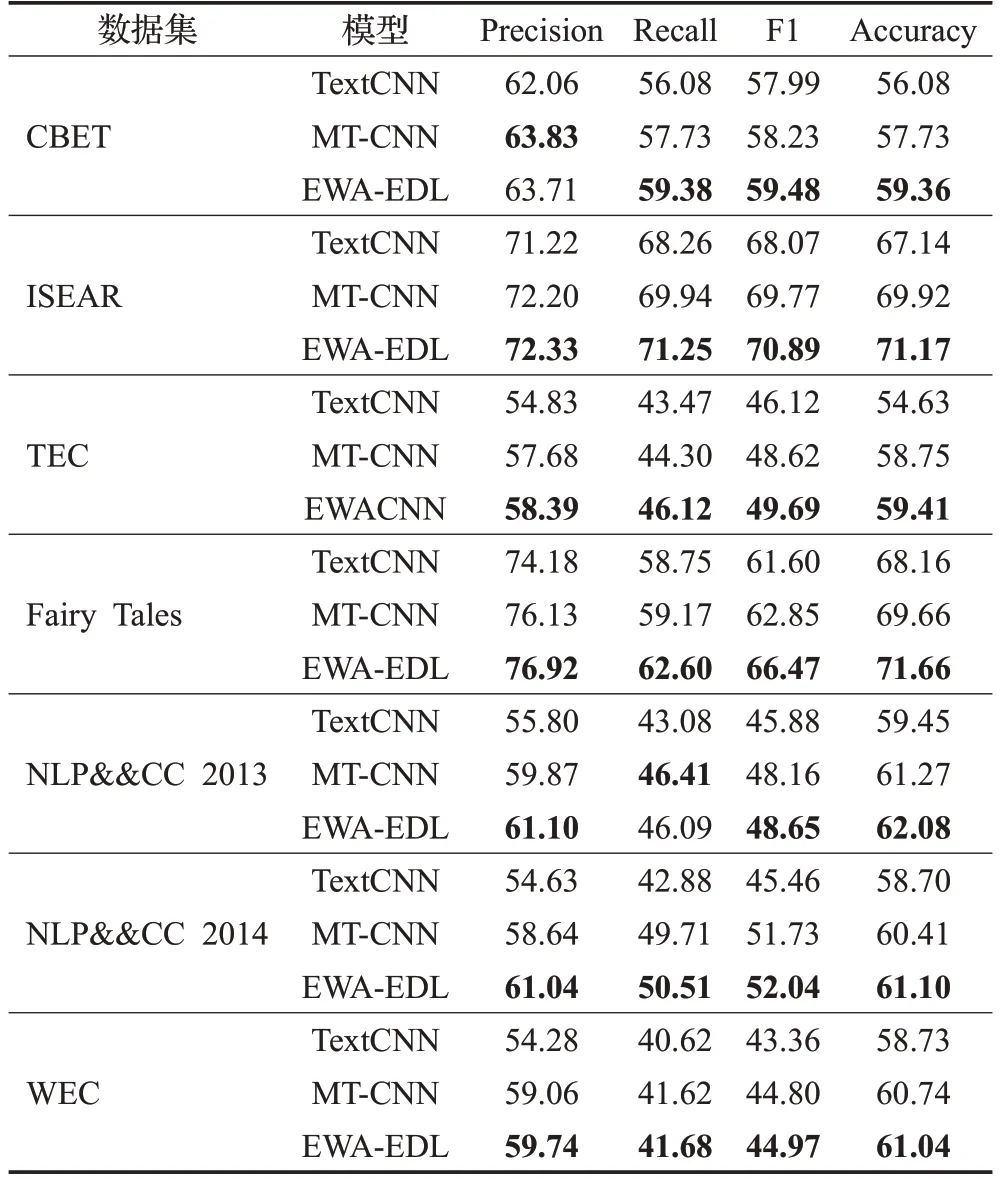
表4 单标签数据集上3种EDL模型的性能对比Table 4 Performance comparison of 3 EDL models on single-label datasets 单位:%
另外,与Zhang等人的实验结果一致[22],MT-CNN模型在7 个数据集上的所有指标上均高于TextCNN 模型。这一实验结果表明,使用交叉熵损失和KL 损失组合训练的多任务神经网络模型比传统的卷积神经网络模型更适用于情绪分类任务。
4 结束语
通过采用注意力机制引入心理学先验知识,本文提出了一个基于情感轮注意力机制的情感分布学习(EWA-EDL)模型。EWA-EDL 模型基于普鲁契克情感轮心理学模型计算基本情绪间的相关性,以注意力机制将心理学先验知识融合到多任务卷积神经网络中。EWA-EDL 模型由5 部分组成,分别是输入层、卷积层、池化层、注意力层和多任务损失层。在8个中英文文本情感数据集上的对比实验结果表明,EWA-EDL 模型在情感分布预测和情绪分类任务上具有比现有EDL方法更优的性能。
在未来的工作中,将考虑以更加有效的方式利用先验知识,对注意力机制进行改进,提升情感分布学习模型的性能。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
成都信息工程大学学报(2019年3期)2019-09-25
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
传媒评论(2017年3期)2017-06-13
自动化学报(2017年5期)2017-05-14
光学精密工程(2016年4期)2016-11-07
第二课堂(课外活动版)(2016年2期)2016-10-21
公民与法治(2016年10期)2016-05-17
探测与控制学报(2015年4期)2015-12-15
