
基于混合注意力Seq2seq模型的选项多标签分类
2023-02-28 09:19王素格
计算机工程与应用 2023年4期
陈 千,韩 林,王素格,郭 鑫
1.山西大学 计算机与信息技术学院,太原 030006
2.山西大学 计算智能与中文信息处理教育部重点实验室,太原 030006
高考文学类阅读理解的研究多是针对简单事实类问题,本文聚焦高考语文中的文学类阅读理解选择题,其题干绝大多数为“根据文章内容,下列选项正确(或错误)的是:”,题干只能得到正误判定。选择题的选项不是简单事实性表述,更多的是从文章的组织结构、全文主旨等不同角度进行的语义方面的理解和概括。同时,不同类别的选项,其特征与潜在错误也不同,需要对选项采用不同的策略进行分析。每个选项不只属于一个类型,从而将其视作多标签分类而非多分类。因此,选项多标签分类是高考文学类阅读理解选择题解答任务中的重要一环,其类型决定了后续解题策略的不同。针对不同类型的选项,使用相应的答案生成方法。
文本多标签学习[1-2]是自然语言处理领域一项十分重要且具有挑战的任务,旨在为数据集中每一样本分配相应的多个标签,广泛应用于文本分类[3]、信息检索[4]等多个研究领域。选项的标签有助于提高高考文学类阅读理解选择题的答题准确率,如对词句理解类选项,思路是根据选项出现的原文表述,回到文章进行定位,将定位处语义与选项匹配,判断正误;分析综合类选项无法在文章中准确定位,因而须调用全局分析模块进行解答。
通过对大量文本数据和现有方法的观察与研究发现,在多标签文本分类中,有三种相关性对分类结果具有重要影响,分别是标签内部相关性、文本与标签间相关性及文本内部相关性。现有方法并未全面考虑上述三种相关性。BR(binary relevance)[5]是最早提出的方法之一,该方法将多标签分类任务建模为多个单标签问题的组合,通过忽略标签内部相关性来达到理想的性能。为了获得标签内部相关性,CC(classifier chain)[6]将任务转换为一系列的二分类问题并对标签内部相关性建模。对标签内部相关性进行建模的方法还有CRF(conditional random fields)和CBM(conditional Bernoulli mixtures)。然而上述方法仅适用于中小型数据集,在大型数据集上的表现欠佳。随着深度学习技术的发展,神经网络模型也被应用于多标签文本分类任务。文献[7]提出的模型利用词嵌入和卷积神经网络(convolutional neural network,CNN)来捕捉标签内部相关性。文献[8]提出一种基于深度神经网络的模型CCAE(canonical correlated autoencoder)。然而这些方法并没有从文本中提取有效信息。
文献[9]使用序列到序列(Seq2seq)模型,将标签预测视为序列生成任务。Seq2seq模型可以对给定的源文本进行编码,并将编码生成的对应表示进行解码,形成近似标签序列的新序列。随着长短期记忆模型(long short-term memory,LSTM)被广泛应用,文献[10]提出了一种带有注意力机制LSTM的Seq2seq模型。利用注意力机制,解码器能够有效地从文本中提取对标签预测有重要作用的信息,利用文本与标签间相关性,从而提高标签预测的精确度。文献[11]提出一种处理多标签文本分类的模型。然而这些方法与模型都忽略了文本内部相关性。
对于高考文学类阅读理解选择题选项的多标签分类任务,文本内部相关性即选项内部相关性。例如,历年高考文学类阅读理解选择题的选项可划分为五类,分别为写作技巧类、思想情感类、词句理解类、分析综合类和因果推理类。具体样例见表1,如2015-北京-20-D 即2015年北京高考真题20题D选项,该选项中,“渗入”和“生活”以及“象征”和“民族精神”这两组词内部存在明显的语义关联,而这两组词可对应于标签“思想情感类”;2014-北京-18-C选项中,“往往”和“从而”两个词间存在的语义关联对应标签“因果推理类”,“心灵”“震撼”和“共鸣”三者存在的相关性对应标签“思想情感类”,因此该选项同时属于“因果推理类”及“思想情感类”;2017-河北省唐山市模拟题-1-B 选项,“形成”和“对比”两词间相关性对应“写作技巧类”,“表达”和“思考”对应标签“思想情感类”。据此,可以根据选项所属类别调用不同的答题引擎,从而提高答题准确率。

表1 高考文学类阅读理解选择题选项样例Table 1 Examples of multiple-choice questions for RCL-CEE
根据以上分析可知,选项内部相关性是对选项文本进行分类和分配合适标签的关键。本文提出了基于混合注意力的Seq2seq 模型(hybrid attention of Seq2seq model,HASM),该模型利用双向长短时记忆(bi-directional long short-term memory,Bi-LSTM),获得选项与标签间相关性作为全局信息,通过多头自注意力(multi-head self-attention,MHA),获得选项内部相关性作为局部信息。使用标签嵌入隐式融合标签内部相关性。
本文的主要贡献如下:
(1)提出了混合注意力机制,利用多头自注意力获得选项内部关联语义;通过Bi-LSTM 获得选项与标签间相关性;使用标签嵌入方法,隐式融合标签内部相关性。充分对分类过程中的标签内部相关性、文本与标签间相关性及文本内部相关性建模,大大提升了模型的预测效果。
(2)提出的HASM模型在高考文学类阅读理解选择题数据集上的实验结果表明,算法性能优于前沿多标签文本分类方法。
1 相关工作
目前,多标签文本分类模型主要分为三类:问题转换法、算法适应法和神经网络模型。
问题转换法的主要思想是将多标签文本分类任务转换为多个单标签学习任务来处理。BR[5]是一个典型的问题转换方法,它直接忽略标签内部相关性,并为每个标签构建一个单独的分类器。但实验表明,忽略标签之间的相关性会导致预测性能的降低。为了获得标签内部相关性,LP[2]通过对每个标签组合使用唯一的二元分类器,将该任务转化为标签组合的多分类问题。CC[6]主要是针对BR方法中未考虑标签内部相关性而导致信息损失的缺点的一种改进方法,该算法的基本思想是将任务转化为一系列二元分类问题即二元分类问题链,链中后续分类器的建立基于先前的标签预测。上述方法的计算效率和性能都面临着标签空间和样本空间过大的挑战。
算法适应法通过修改和扩展传统的单标签算法,或对单标签算法进行相应的改进来处理多标签数据。ML-DT(multi-label decision tree)[12]通过构建基于熵的信息增益的决策树进行多标签分类;文献[13]提出的ML-KNN(multi-labelk-nearest neighbor)方法使用k近邻算法和最大后验概率来确定每个样本的标签集;文献[14]使用CBM 简化任务,将其转换为多个标准的二元多类问题,用于分类预测。
近年来,随着神经网络的广泛应用与深入研究,其在许多重要的自然语言处理任务上都表现出了优越的性能,研究者也提出了各种基于神经网络的多标签文本分类模型。文献[15]提出了一种基于标签的预训练方法来获得具有标签感知信息的文档表示。文献[16]研究了不同信息来源的有效性,例如标记的训练数据、类的文本标记和类的分类关系。更具体地说,首先,对于每个文档-类对,使用不同的信息源提取不同的特征,然后,将多标签文本分类看作一个排序问题,采用学习排序(learning to rank,LTR)方法对文档类进行排序,并选择文档标签。文献[17]提出了一种结合动态语义表示模型和深度神经网络的多标签文本分类方法。然而,先前的模型都存在两个问题:第一,由于窗口大小的限制,模型无法获得文本间长距离的依赖关系;第二,当模型预测时,文章文本中不同的词对标签预测的贡献程度不同,但模型并没有重点关注那些对标签预测贡献大的词语。基于上述的想法,文献[11]提出将Seq2seq模型应用于多标签分类任务中,利用注意力机制得到每个词语的重要性权重用于标签的预测。MDC(multi-level dilated convolution)[18]以Seq2seq 模型为基础,使用具有混合注意力的附加语义单元,用于创建信息增强的表示。在现实应用中,多标签文本分类任务的标签具有语义信息,但在部分方法中将标签仅看成是原子符号,忽略了标签文本内容的潜在知识。在多标签文本分类中,标签是文本形式,由词语组成,词嵌入作为自然语言处理的基础模块,能够获得词语之间的相似性和规律性,因此可以用词嵌入来隐式地融合标签信息。
为了进一步提升多标签文本分类的性能,本文提出混合注意力机制,同时建模三种相关性,从而得到更全面的全局和局部信息。
2 基于混合注意力的Seq2seq模型
2.1 问题描述
模型的任务是将一组标签Y分配给选项文本序列Wi,标签序列生成任务可以专门建模,以找到最大化条件概率p(Y|X)的最优标签序列,计算见式(1)、(2)。
2.2 模型框架
模型总体架构如图1所示。受自注意力机制启发,同时考虑选项内部相关性对于标签预测的影响,提出了混合注意力机制,通过Bi-LSTM 获得选项与标签间相互信息hG,利用MHA获得选项内部关联语义信息hL,同时标签嵌入层模块(label-embedding,L-E)对标签进行隐式融合,作为解码器的输入。解码器由LSTM单元组成,最终得到预测标签。掩码模块(masked softmax,MS)使用掩码向量避免预测重复标签。
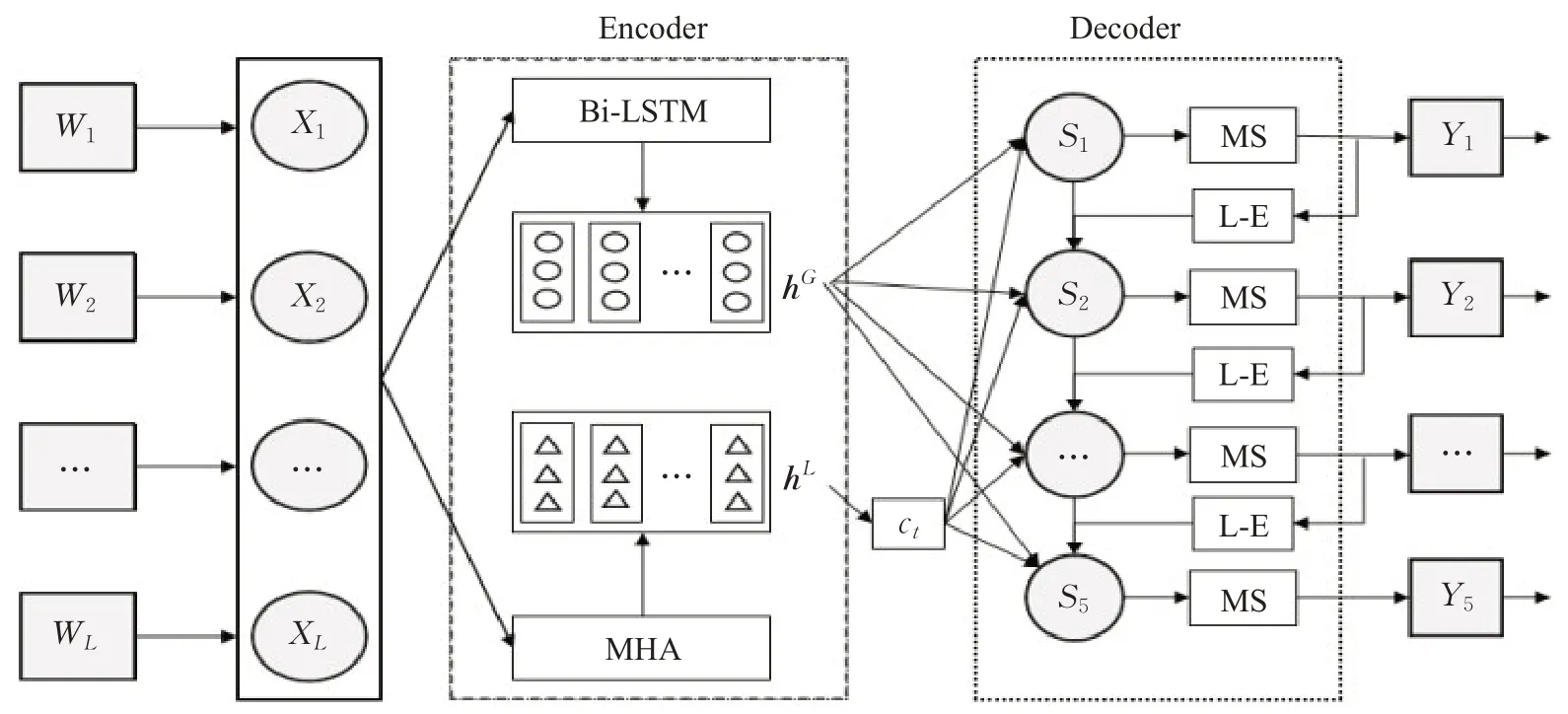
图1 模型框架Fig.1 Framework of model
2.3 基于混合注意力的编码器
2.3.1 Bi-LSTM层
LSTM在序列建模问题上具有长时记忆优势,实现简单,同时解决了长序列训练过程中存在的梯度消失和梯度爆炸问题。而单向LSTM 只关注前向信息是不够的,因此应用Bi-LSTM 获得选项到标签的相关性作为全局信息。给定输入X={X1,X2,…,Xi,…,XL},每个单词的隐层状态由式(3)、(4)得到:
第i个词的上下文嵌入表示为,式(5)hG表示选项和标签之间的互注意力信息,即全局信息。
2.3.2 多头自注意力层
注意力机制可以宏观上理解为一个查询(Query)到一系列键-值(Key-Value)对的映射。将源(Source)中的构成元素想象成是由一系列的
文中dv、dk、dq分别对应于values、keys和queries的深度。进一步,以表示第m个head上的values、keys和queries的深度。对于给定的输入序列X∈RL×d,MHA输出计算如式(6)、(7)、(8)所示。hL代表从选项内部得到的自注意力信息,即局部信息。
2.3.3 混合注意力
对局部信息hL分配权重参数。第i个单词在t时刻的权重αti由式(9)、(10)计算。
其中,VT、W、Z、U均为权重参数。St-1表示上一时刻的隐状态,是第i个单词的自注意力信息,g(yt-1)是经过L-E层的上一时刻的预测标签。
最终在t时刻的局部自注意力信息ct由式(11)计算。
2.4 标签嵌入(L-E)层
对于标签集Y,任一标签的文本内容表示为y={N1,N2,…,Np},即每个标签由p个词组成。为了得到每一标签的隐表示e,将标签文本作为输入,使用词向量平均函数进行计算,如式(12):
其中,e∈Rk,k为文档中单词的嵌入维度。
2.5 预测标签
解码器在t时刻的隐状态St由式(13)计算得到:
其中,[g(yt-1);hG;ct]由向量g(yt-1)、hG和ct拼接得到。hG是全局的互注意力信息,ct为局部的自注意力。g(yt-1) 是在分布下具有最高概率的标签的嵌入,而yt-1是在t-1 时刻标签空间Y的概率分布,其计算如式(14)、(15)。
其中Wo、Vo和Zo是权重参数。f是非线性激活函数。
模型的MS 模块即掩码模块,其中It∈R5,是防止解码器预测重复标签的掩码向量,如式(16):
针对标签序列,在序列的头部和尾部添加bos和eos符号。利用束搜索算法[20]找到最优预测序列。在训练过程中,使用二元交叉熵损失(binary cross entropy loss)[21]作为损失函数,其计算如式(17):
其中,T为选项样本的数量,,分别为第i个实例的第j个标签的真实标签和预测标签。
3 实验设计与结果分析
3.1 数据集及评测指标
本文在高考文学类阅读理解选择题数据集上进行测试。该数据集包含各省和全国的高考文学类阅读理解真题与模拟题共计3 209 篇文章,13 827 条选项。训练集共计10 056条选项数据,验证集和测试集分别包括1 850 条数据和1 921 条数据。对每条选项数据进行人工标注,由于每个人对选项类别的判断标准不一致,很容易出现不同的标注结果。因此,在标注数据过程中,采用多人独立标注、协同交叉验证的方式,即每个人先独立标注一部分语料,之后随机从标注人员的标注语料中抽取相同数目的选项文本,交叉进行评估。若准确率在80%以上,则此次抽取的选项标注结果有效。将选项分为5类标签,分别为写作技巧类、思想情感类、词句理解类、分析综合类和因果推理类,分别用0,1,2,3,4 数字表示。
为了评估模型的标签预测性能,采用汉明损失(Hamming loss,HL)、Micro-F1作为性能比较的主要评价指标,同时结合Micro-Precision 和Micro-Recall 指标进行评测。
HL[22]衡量标签被错分的次数,即属于某个样本的标签没有被预测,不属于该样本的标签被预测属于该样本,如式(18)。
其中,N为样本数,L为标签数。Yij是第i个预测中第j个分量的真实值,Pij是第i个预测中第j个分量的预测值。XOR()表示异或关系。
Micro-F1[23]可解释为精确度和召回率的加权平均值,不需区分类别,直接使用总体样本的精确度和召回率计算,如式(19)。
其中,Precisionmicro和Recallmicro表示所有类别的平均精确度和召回率。
3.2 实验设置
文本预处理主要包括文本标准化和分词。标准化包括通过正则去噪,将繁体转化成简体等操作。分词则通过结巴分词包对标注后的高考文学类阅读理解选择题数据集进行分词处理。
对于数据集,本文设置嵌入维度d和隐层大小h均为512,epoch 为30,batch-size 为128,使用Adam 优化算法[24],初始学习率是0.000 3,编码器和解码器的神经网络层数均为3,且编码器使用Bi-LSTM。束搜索大小设置为9。多头自注意力中M=3。另外,使用dropout正则化来避免过度拟合。对比算法中的参数按照对应的原始论文[11,25-28]进行设置。
本文使用以下基线模型来比较在高考文学类阅读理解选择题数据集上的性能表现。
CNN[25]使用深度卷积网络提取文本特征,然后将它们输入到线性变换层,然后使用sigmoid 函数输出标签空间上的概率分布。
CNN-RNN[26]利用CNN 和RNN 捕捉全局和局部的文本语义信息,并对标签之间的依赖关系进行建模。
SGM(sequence generation model)[11]将多标签分类任务看作一个序列生成问题,输入文档内容,生成预测的标签序列。
LSAN(label-specific attention network)[27]利用标签和文档间的语义联系,以及文档中特定的表示,设计了一种自适应融合策略,可以有效地输出综合文档表示来构建多标签文本分类器。
Seq2set[28]为了减少模型对标签顺序的依赖,以及捕捉标签之间的相关性,提出通过强化学习进行训练,其中奖励反馈设计为独立于标签顺序的模式。
FSL-MLC(few-shot learning for multi-label classification)[29]提出了带有核回归和Logits Adapting的元刻度阈值(meta calibrated threshold,MCT)机制,利用先验的领域经验和新的领域知识以估计阈值。同时引入了锚标签表示以得到分离得比较好的标签表示,以实现更好的label-instance相关性分值计算。
3.3 整体性能比较
HASM 模型同以上对比模型在高考文学类阅读理解选择题数据集上的评价指标对比得分情况见表2,最佳结果用粗体表示。
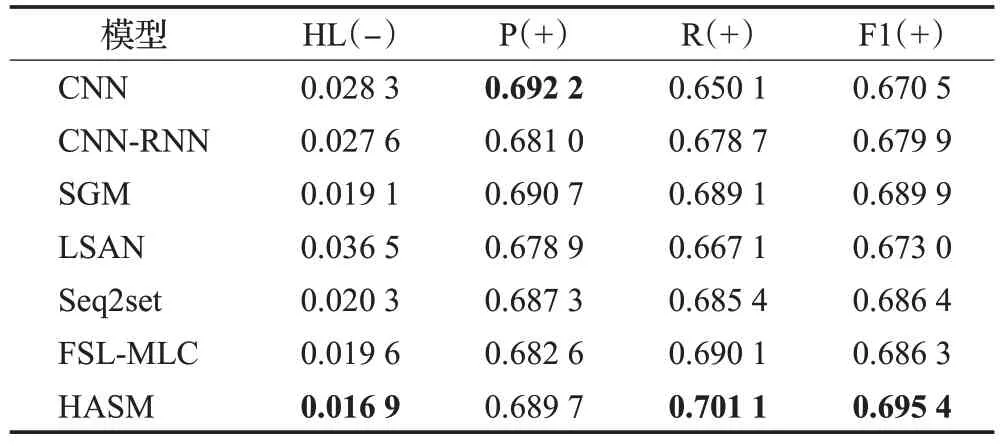
表2 不同模型实验结果Table 2 Experimental results of different models
表2中,HL代表汉明损失,F1代表Micro-F1,(-)代表值越小分类效果越好,(+)代表值越大分类效果越好。可以看出,在测试集上,使用Seq2seq架构并结合注意力机制进行多标签分类的方法效果总体要优于CNN,HL 提高了近1 个百分点。但基于深度学习的经典模型CNN,即使不使用Seq2seq 结构,在精确度上仍具有一定的优势。LSAN的准确率要低于SGM和Seq2set,达到约67%。而本文方法HASM 充分利用了标签内部相关性、文本与标签间相关性以及文本内部相关性,能够略微提升Micro-F1 指标,最终F1 指标达到近70%。SGM和经典模型Seq2set相比实现了一些改进,SGM和Seq2set 模型的F1 值相对于CNN 和CNN-RNN 的F1 值更高,说明序列到序列模型对于多标签分类任务是有效的。传统的CNN 在Micro-Precision 上的值领先于所有基线模型(包括HASM)。同时,可以看到SGM的F1值比Seq2set的F1值略高,因数据集中标签空间并不是很大,标签顺序的影响较小。FSL-MLC 在各指标上的成绩都与SGM相接近,但略逊一筹,总体表现不如SGM,可见Seq2seq架构更适用于高考文学类阅读理解选择题数据集。与六种基线模型相比,HASM在总体指标上明显优于前六种模型,处于领先地位,说明HASM 模型对三种相关性的建模是有效的。与基线模型中表现最好的SGM 相比,HASM 将汉明损失在数值上降低了0.002 2,并将F1值提高了5.5个百分点。
为了更全面地分析HASM 模型的性能,计算得到HASM模型在每个选项类别上的指标,结果如表3所示。
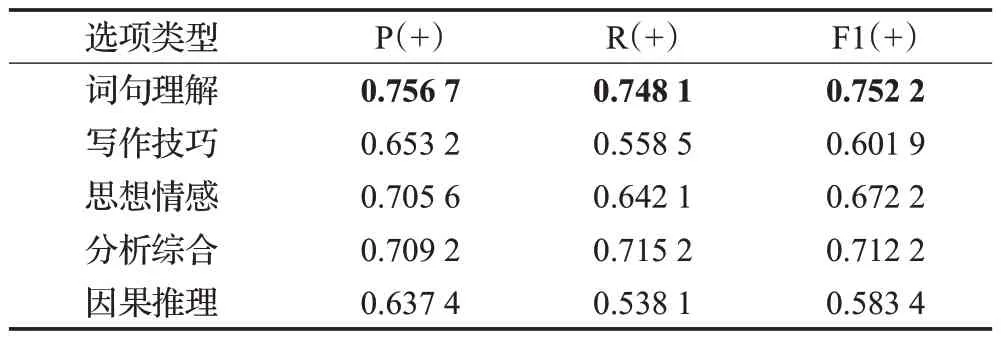
表3 HASM模型在不同选项类别上的指标Table 3 Indicators of HASM model in different option categories
根据表3,HASM 模型对词句理解类选项的分类效果最佳,该类选项对文章有着明显的引用,HASM 模型更易识别该类选项。相较于词句理解类,模型对因果推理类、写作技巧类的识别则更为模糊,在指标上有所欠缺,但通过对这两类选项的分析,发现这两类选项都有明显的关键词可对其进行区分,如选项包含“记叙”“比喻”“拟人”“写作手法”等词语时,明显可划分为写作技巧类,据此分别构建了两类选项的关键词词典,下一步拟将关键词词典作为模型先验知识,以进一步提高模型性能。同时,通过对这两类选项指标的分析,发现精确率和召回率间存在较大差异,原因可能是这两类选项数据的label数量不均衡,需要对数据进一步处理。
3.4 MHA模块与标签嵌入消融实验
为了进一步证明HASM 模型中MHA 模块和标签嵌入(L-E)模块对提升模型性能的作用,也为了更充分评估HASM模型的效果,进行了一系列消融实验。通过从HASM模型中移除一些模块来控制变量,以便能够比较它们的效果。实验结果如表4所示。

表4 消融实验结果Table 4 Results of ablation experiment
表4 展示了MHA 模块和L-E 层对模型的贡献。对比表2、表4发现,不包含MHA模块的模型在HL指标和F1 指标上分别下降了0.003 1 和3.51 个百分点,不包含L-E 模块的模型在HL 指标和F1 指标上分别下降了0.002 6 和3.07 个百分点。模型通过MHA 模块获得选项内部相关性,利用L-E 层得到标签内部相关性,对上述相关性的建模大大提升了HASM 模型的性能。从表4可以看出,选项内部相关性和标签内部相关性对于选项多标签分类任务准确度的提升有着重要作用。HASM 模型能够利用多头自注意力获取局部选项内关联信息,标签嵌入能够建模标签内部语义关联。同时已有模型均没有考虑到文本内部相关性,而HASM模型能够将三种相关性的充分结合,具有较好的多标签分类效果,实验结果也进一步证明HASM模型从选项中提取有关标签分类信息的能力。
3.5 重要词汇的捕捉
在对同一选项预测不同的标签时,选项中每个单词的重要性权重是不同的,为了证明HASM模型在预测不同标签时能够捕获不同单词的权重,本文从高考文学类阅读理解选择题数据集中取出几个例子,对同一选项中不同标签对应的单词权重进行展现。如图2、图3所示,模型在预测两个不同的标签时,对选项中单词的关注度是不一样的,单词颜色越深,对当前词汇关注越大。可以看出,标签“写作技巧类”更关注选项中如“描写”“写作风格”“修辞手法”等关键词,而标签“思想情感类”则更关注“表现”“追怀”等关键词,从而证明不同标签关注选项的不同部分。

图2 “写作技巧类”捕捉的重要词汇Fig.2 Important words captured by“writing skills”

图3 “思想情感类”捕捉的重要词汇Fig.3 Important words captured by“thoughts and emotions”
图4 展现了选项内部存在的语义相关性。如图所示,两个词之间的语义相关性越强则表格中所示颜色越深,表格中的颜色深浅代表两个词之间的语义关联程度。如“类似”和“于”,“本文”和“的”,这两组词内部即存在语义关联,在表格中表示为较深的灰色。而“行文”“呈现”和“写作风格”三者之间存在的语义关联,对选项标签“写作技巧类”的预测起着重要作用。
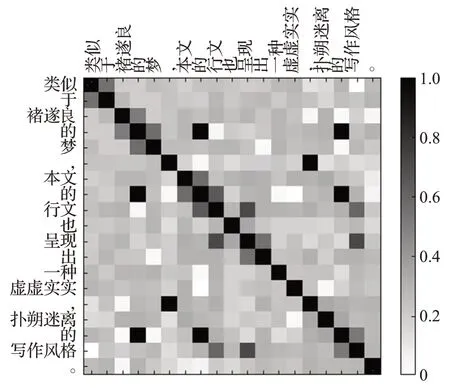
图4 选项内部相关性Fig.4 Option internal correlation
不同标签关注选项的不同部分,同时选项内部不同的语义关联对不同标签的预测有着影响,这些都证明了本文提出的模型的亮点,将选项内部相关性(自注意力信息)、选项与标签间相关性(互注意力信息)及标签间相关性三者相结合是符合实际问题的。
4 结论与展望
本文主要针对选项内部相关性提出混合注意力机制,并基于该机制设计一种序列到序列模型HASM。该模型提取选项内部相关性和选项到标签间相关性,并对其分配参数进行使用,同时模型利用标签间相关性,对三种相关性进行建模。实验结果表明,提出的HASM模型能够有效地捕捉三种相关性。进一步的分析表明,HASM 模型在高考文学类阅读理解选择题数据集上更具优势。虽然HASM模型有着最好的表现,但所有模型在高考文学类阅读理解选择题数据集上的F1数值都不够高。下一步,将加入先验知识,考虑更多粒度的信息,期望通过不同粒度的信息学习更丰富的文本语义内容,从而更高效、更准确地预测标签。
猜你喜欢
新世纪智能(数学备考)(2021年5期)2021-07-28
中学生数理化(高中版.高二数学)(2020年11期)2020-12-14
新世纪智能(高一语文)(2020年5期)2020-07-24
新世纪智能(高一语文)(2020年5期)2020-07-24
中学生数理化(高中版.高考数学)(2020年5期)2020-06-02
时代英语·高一(2017年5期)2017-11-14
时代英语·高三(2017年4期)2017-08-11
时代英语·高一(2017年4期)2017-08-09
西部大开发(2017年8期)2017-06-26
试题与研究·中考英语(2016年3期)2017-01-05
