
基于深度学习的EKF 和C-BMIoU 目标跟踪方法
2023-02-27 05:49翁培欣吴林煌
电视技术 2023年12期
翁培欣,吴林煌,苏 喆
(福州大学 先进制造学院,福建 泉州 362200)
0 引言
多目标跟踪技术[1]涉及检测和估计视频流中多个目标的时空轨迹,是许多应用的基本问题。目前,检测跟踪已经成为多目标跟踪(Multiple Object Tracking,MOT)任务中最有效的范例。这种技术模型包含目标检测和跟踪两个步骤。跟踪步骤通常包含两个主要部分:一是使用运动模型和状态估计预测后续帧中轨迹的边界框,二是将新的帧检测与当前一组轨道相关联。
随着人工智能和计算机硬件性能的提升,基于卷积神经网络的深度学习在计算机视觉[2]领域显著成功,尤其在多目标跟踪方面。多目标跟踪任务致力于在给定视频中同时检测和定位多个目标,并维持目标标识的稳定性和轨迹记录。对于车辆跟踪,在视频监控、智能交通和军事制导等领域具有重要的应用。
在深度学习兴起之前,目标跟踪领域主要集中于单目标跟踪,多目标跟踪研究较为有限。传统的多目标跟踪算法包括联合概率数据关联滤波、多假设跟踪和条件随机场等方法。这些算法在一定程度上解决了多目标跟踪问题,但在目标数量较多时会面临多目标跟踪失败的挑战。
近年来,基于卷积神经网络[3]的目标检测器准确性和效率不断提高,直接推动多目标跟踪取得重大突破。一些跟踪算法如SORT[4](Simple Online and Realtime Tracking,SORT)、DeepSort[5]和OCSORT[6]在多目标跟踪领域取得显著成果。这些算法利用卷积神经网络检测目标,并采用不同策略如卡尔曼滤波、重识别特征[7]和分层数据关联等进行目标关联,从而提高多目标跟踪的准确性和健壮性。然而,目前这些算法存在一些局限,如恒速模型假设下的卡尔曼滤波器[8]的使用、无法准确预测边界框形状和目标相互遮挡所导致的目标丢失等问题。
为了解决这些问题,本文提出一种新的跟踪器,首先针对卡尔曼滤波预测的目标边界框与实际对象的边界框存在较大偏差以及目标在长期遮挡下导致行人目标跟踪丢失的问题,采用扩展卡尔曼滤波[9]替换ByteTrack 算法中的卡尔曼滤波,并直接将目标边界框的宽度和高度作为扩展卡尔曼滤波器的待预测状态。其次,使用C-BMIoU 作为跟踪器的匹配规则,从而改进被遮挡目标的跟踪效果。
1 ByteTrack 的基本框架
目标跟踪任务中,通常使用检测器来定位和识别目标。然而,传统的多目标跟踪算法通常关注高分数的检测结果,而忽略了一些低分数的检测框,导致目标丢失和轨迹碎片化的问题出现。为了解决这个问题,ByteTrack[10]算法利用了所有的检测框,并通过多次匹配来提高跟踪的精度。
ByteTrack 算法首先根据检测器的输出得到一系列的边界框和相应的检测分数。然后,算法利用卡尔曼滤波来预测目标的位置和速度。通过匈牙利算法[11]优先匹配高分数的检测框和已有的轨迹,再匹配低分数的检测框和剩余的轨迹。匹配过程中,ByteTrack 算法还使用了与之前轨迹的相似度比较来恢复真实目标并过滤掉背景干扰,具体流程如图1 所示。
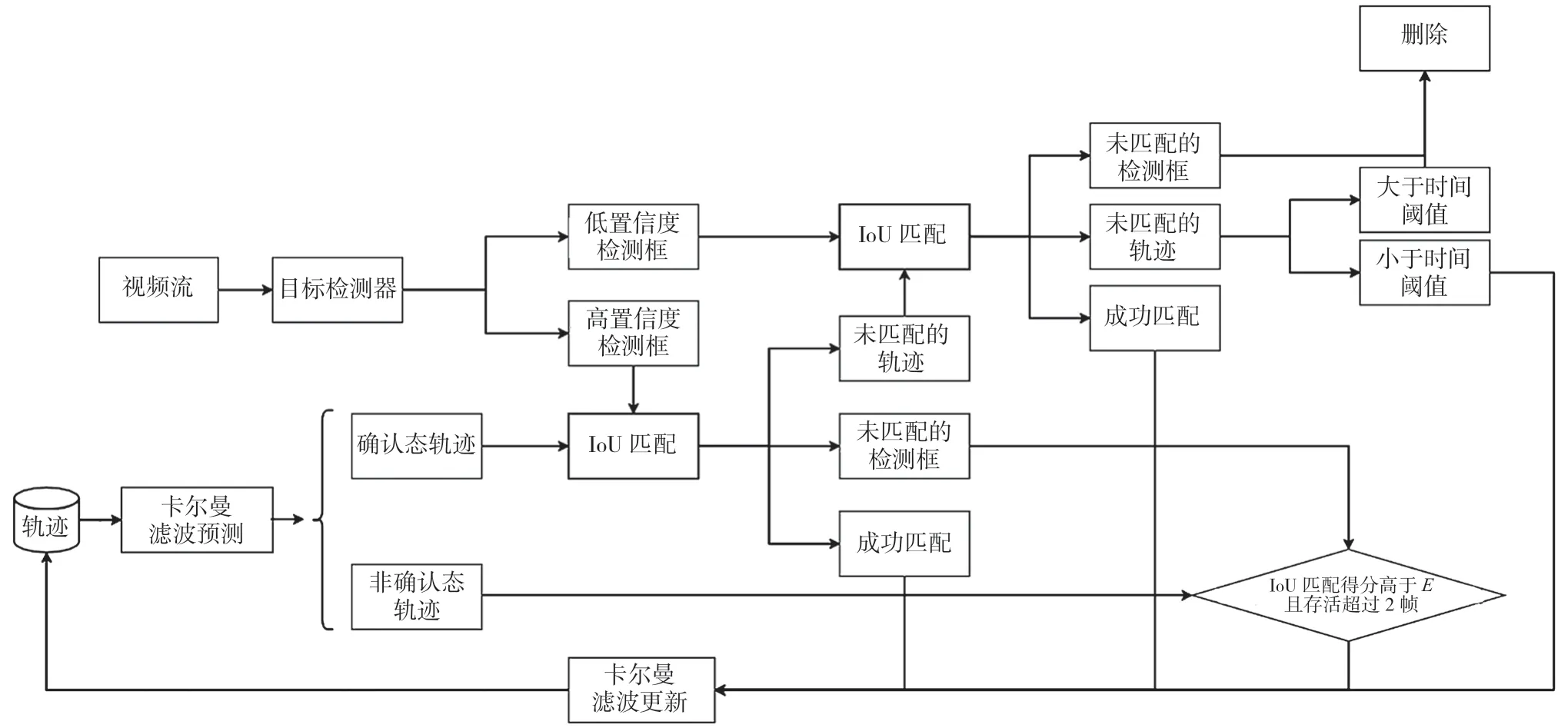
图1 ByteTrack 算法的流程图
1.1 高性能检测器YOLOv8
本文采用的目标检测器是YOLOv8。YOLOv8[12]是一个全新的SOTA(State-of-the-Art)模型,结合了目标检测和实例分割。模型提供了P5 640 和P6 1280 分辨率的目标检测网络,并基于YOLACT 实现了实例分割功能。与YOLOv5 相似,YOLOv8 还提供了不同尺度(N/S/M/L/X)的模型,以适应不同场景。在网络结构方面,YOLOv8 采用了YOLOv7 ELAN 的设计思想,采用C2f 结构替代了YOLOv5的C3 结构,提升了梯度流的丰富度。同时,解耦头结构将分类和检测头分离,并使用无Anchor 的方式进行检测。在损失函数方面,YOLOv8 引入了Task-Aligned Assigner 正负样本匹配方式,并应用DFL(Distribution Focal Loss)行优化。这些改进使得模型的性能得到了提升。此外,在训练过程中,YOLOv8 采用了YOLOX 的策略,通过关闭Mosiac增强来提高精度。总之,它可以满足不同场景的需求,并具备更高的准确性。
1.2 关联方法BYTE
BYTE[10]的输入有视频片段V、检测器D、卡尔曼滤波器KF,设置Thigh、Tlow、E共3 个阈值。前两个为检测分数阈值,后一个为跟踪分数阈值。BYTE的输出为视频的轨迹T,每个轨迹包含目标的检测框和ID。对于视频中的每一帧图像,使用检测器预测其检测框和分数。然后把所得到的检测框按照置信度阈值分成高分检测框Dhigh和低分检测框Dlow,利用KF 预测计算轨迹的包围框。使用高分检测框Dhigh和轨迹进行第一次交并比(Intersection over Union,IoU)匹配,保留未匹配的检测框Dremain和未匹配的高分轨迹Tremain。使用低分检测框Dlow和继续进行第二次IoU 匹配,继续保留未匹配上的轨迹Tre-remain,删除未匹配的低分检测框。该操作可以过滤误检的背景,同时恢复被遮挡的目标。对于未匹配的轨迹Tre-remain,保留30 帧时间周期。该期间内如果没有匹配到检测框,则放入Tlost。对于上一次未匹配到轨迹的高分框的Dremain,如果检测框得分高于E,且存活超过2 帧,则初始化为新的轨迹。
2 基于ByteTrack 的改进
2.1 EKF 扩展卡尔曼滤波算法
卡尔曼滤波(Kalman Filter,KF)算法是首先构建目标状态的线性系统空间方程,通过预测和校正实现状态的最小均方误差估计。算法的优势在于能够在噪声干扰下获得最优的状态估计值,从而提高估计精度;能够实时更新状态估计值,使得其具有实时性和追踪能力。此外,该算法可以通过组合不同的状态和观测量,实现多维度的状态估计和预测。
尽管KF 算法有诸多优点,但其只适用于线性系统,对于非线性系统则无法直接应用。同时,KF算法由于遮挡导致的目标信息不完整,其线性化模型不够准确,导致产生错误的状态估计结果。于是NASA Ames 等机构对卡尔曼滤波理论进行拓展,并应用于非线性系统中,提出了扩展卡尔曼滤波(Extended Kalman Filter,EKF)算法。
EKF 算法流程主要分为预测和更新2 个步骤。预测是基于上一个时刻状态估计当前时刻状态,更新则是综合当前时刻的估计状态与观测状态,估计出最优的状态。预测的过程可表示为
式中:xk为k时刻的状态向量,uk更为控制向量,f(·)为系统非线性状态函数,Ak为状态转移矩阵,Pk为状态向量的协方差矩阵,Q为预测状态的高斯噪声的协方差矩阵,xk-1|k-1为k-1 时刻对k时刻的转台预测,xk|k-1为k-1 时刻对k时刻的状态预测,Pk-1|k-1为k-1 时刻的后验估计误差协方差矩阵,Pk|k-1为k-1 时刻到k时刻的估计误差协方差矩阵。
更新的过程可表示为
式中:Pk为状态向量的协方差矩阵,Ck为转换矩阵,Rk为测量值的高斯噪声的协方差矩阵,yk为传感器测量值的状态向量,h(·)为测量函数,Kk为卡尔曼增益。
式(1)是状态预测,式(2)是误差矩阵预测,式(3)是卡尔曼增益计算;式(4)是状态更新,其输出即最终的卡尔曼滤波结果;式(5)是误差矩阵更新。
目前,大多数跟踪方法都使用经典跟踪器DeepSORT 中提出的KF 的状态特征。它试图估计框的长宽比而不是宽度,这将导致在预测下一帧的轨道边界框时,使用KF 状态估计作为跟踪器的输出会导致一个次优的边界框形状。本文提出改进的扩展卡尔曼滤波直接估计包围框的宽度和高度,可以处理非线性系统和非高斯噪声,具有更好的健壮性和准确性,并对遮挡的影响更小。
2.2 C-BMIoU
C-BMIoU(Cascaded Intersection over Union with Minimum Points Distance and buffer zone)方法是通过将缓冲区和MPDIoU(Minimum Point Distance Intersection over Union)进行结合来实现的。其中,缓冲区通过扩展检测和跟踪的匹配空间,可以直接匹配相邻帧中相同但不重叠的检测框和轨迹框,并且能补偿匹配空间中的运动估计偏差。而MPDIoU[13]是针对大多数损失函数在不同预测结果下具有相同的值会使得边界框回归的收敛速度和准确性降低的问题提出的,能够改善边界框回归的训练效果,提高收敛速度和回归精度。
2.2.1 缓冲区
缓冲区与原始检测框和轨迹成正比,不会改变它们的位置中心、比例和形状,而是扩展它们的匹配空间。缓存区权重计算如图2 所示。

图2 缓存区权重计算公式
与MOT 中的搜索窗口将扩展边界框作为空间约束不同,本文是将扩展边界框作为MPDIoU 的匹配特征。该方法可以解决跟踪模型不能进一步优化的问题和针对检测框、预测框之间的重叠面积为零问题。比如它们在缓存区范围内,缓冲区会为最初不重叠的检测和轨迹构建时空相似性。
2.2.2 MPDIoU
MPDIoU 是在这些现有度量方法的基础上发展起来的,针对传统的边界框回归损失函数难以优化预测框和真实框在宽高比相同但具体尺寸不同时的问题提出,旨在通过直接最小化预测框和真实框之间的关键点距离,提供一种易于实现的解决方案,用于计算两个轴对齐矩形之间的MPDIoU。MPDIoU的计算如图3 所示。
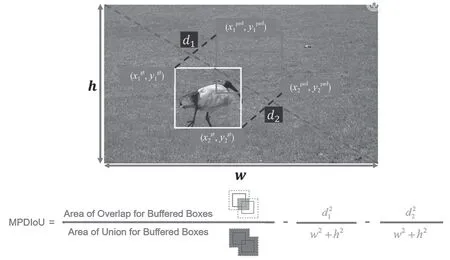
图3 MPDIoU 计算公式
3 实验
3.1 实验设置
3.1.1 数据集
本实验采用MOT17 数据集。该数据集由KITTI 研究组和CVPR2017 MOT Challenge 主办方共同提供。MOT17 数据集包含14 个视频序列,序列由单双目摄像头采集。这些视频序列涵盖不同的场景,包括商场、街道、交通路口和室内走廊等。每个视频序列中都包含多个移动物体,这些物体在不同的帧中出现、消失、移动和交互。MOT17 数据集为每个物体提供了精确的边界框注释,以及每个物体的唯一ID 号。在MOT17 数据集上利用TrackEval评测工具对算法进行评估。
3.1.2 评估指标
为了评价多目标跟踪算法的性能,需要使用一系列评价指标来进行定量评价。常见的多目标跟踪评价指标包括MOTA(评价多目标跟踪算法性能的综合指标)、HOTA(综合考虑目标跟踪器的准确性和稳定性的指标)、IDF1(评价多目标跟踪算法的准确率的指标)、MT(衡量了跟踪算法成功跟踪目标的帧数占测试序列总帧数的比例,从而反映算法的跟踪成功率)和ML(衡量跟踪算法的误报率,即跟踪算法将背景或者非目标物体错误地标记为目标的情况)。MOTA、MOTP 和IDF1 指标计算公式为
式中:NFN为未被成功匹配的真实轨迹,NFP表示生成的轨迹没有被匹配成功,NGT表示视频序列中真实的轨迹数量,NTP是成功匹配的真实轨迹。
式中:NIDTP、NIDFP和NIDFN分别表示目标标识真正例、假正例和假反例的数量。
3.1.3 实验平台
本文的实验平台环境是ubuntu7.5.0 系统,配置4 张NVIDIA GeForce RTX 2080Ti 显卡。实验的输入大小设置为(1 440,800),batchsize 设置为48,初始学习率为0.001,迭代次数设置为300 次。
3.2 实验结果分析
将本文改进的ByteTrack 算法与另外两个性能优异的跟踪算法ByteTrack、OC-SORT 进行性能对比,结果如表1 所示。
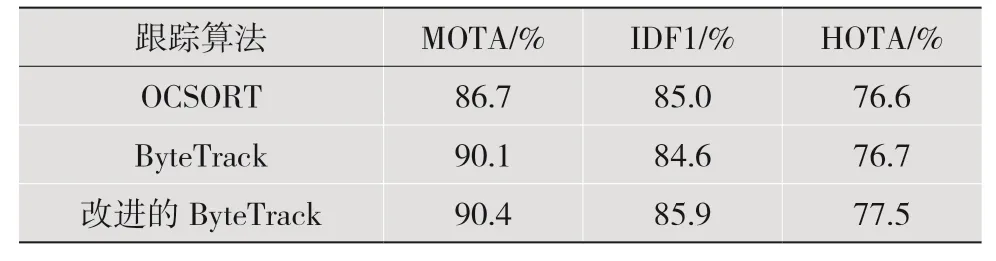
表1 性能对比结果
从表1 的测评结果可以看出,将改进的EKF 算法与C-BMIoU 算法相结合,可以有效地提高目标跟踪过程的准确度。本文算法在3 种算法中各项指标都取得了相对较好的结果。与原ByteTrack 算法框架相比,MOTA、IDF1 和HOTA 分别提高了0.3%、1.5%和1.0%。针对边界框宽度与对象的拟合度问题,通过改进的EKF 作为轨迹状态的预测和更新,大大提高了边界框宽度与对象的拟合度,并且在目标长期遮挡情况下能连续帧跟踪多目标。使用C-BMIoU损失函数作为匹配规则,有效缓解了模型存在的不能进一步优化的问题,也能有效缓解由不规则运动引起的不匹配并提高跟踪性能。该改进的算法模型有效减少了因目标遮挡造成的身份频繁交换问题。
4 结语
本文针对行人多目标跟踪场景中存在的多目标遮挡干扰、目标多尺度变化等复杂场景所造成的跟踪精度降低和目标边界框与实际对象的边界框存在较大偏差等问题,提出了一种基于改进ByteTrack算法的多目标跟踪方法。实验结果表明,改进算法有效地提高了多目标跟踪的跟踪精度,有针对性地提高了整体跟踪算法的准确性和可靠度,实现了复杂场景下持续稳定的多目标跟踪。但由于没有考虑行人外观特征,如果在长时间跟踪中,行人从摄像头视野中消失一段时间然后再次出现,那么该方法就不能将其视为新的目标,因此未来的研究方向是如何更好地做跨摄像头跟踪目标,以保证后续多目标跨摄像头能够持续稳定地跟踪。
猜你喜欢
儿童时代·幸福宝宝(2021年11期)2021-12-21
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
证券法律评论(2018年0期)2018-08-31
现代装饰(2018年5期)2018-05-26
北京航空航天大学学报(2017年9期)2017-12-18
中国三峡(2017年2期)2017-06-09
电源技术(2016年9期)2016-02-27
电源技术(2015年1期)2015-08-22
外语学刊(2014年6期)2014-04-18
