
锂离子电池内短路检测算法及其在实际数据中的应用
2023-02-27 07:53:38韩雪冰欧阳明高任华华闫月君
储能科学与技术 2023年1期
潘 岳,韩雪冰,欧阳明高,任华华,刘 巍,闫月君
(1清华大学汽车安全与节能国家重点实验室,北京 100084;2阿里巴巴集团,河南 郑州 450018)
锂离子电池由于具有能量密度高、使用寿命长、无记忆效应等诸多优点[1],目前被广泛应用于电动汽车领域和储能领域。随着锂离子电池的大规模应用,以热失控为特征的锂离子电池系统安全性事故时有发生,对人民群众的生命和财产安全造成威胁[2]。锂离子电池的热失控可能由电池的机械滥用、电滥用或热滥用引发,导致电池内部化学组分及组分间发生一系列产热副反应使温度持续上升,并最终引发电池剧烈的热量释放,表现为电池起火、爆炸等现象[3]。
锂离子电池内短路是机械滥用、电滥用、热滥用导致电池热失控的共性环节。机械滥用破坏电池结构,电池剧烈的形变或者刺入电池的异物导致电池内部正负极之间形成电气连接,引发剧烈的电池内短路;热滥用导致电池隔膜大规模崩溃收缩,崩溃收缩的隔膜导致电池的部分正负极直接接触,引发电池内短路;电滥用使得铜、锂等金属析出并在负极沉积,不断沉积的金属可能穿过隔膜孔隙或者绕过隔膜边缘,从而连通正负极并导致内短路[4-5]。除此之外,在电池生产制造过程引入的金属颗粒杂质、极片毛刺等制造缺陷,也可能导致电池内短路[6]。内短路发生后,内短路电流产生的焦耳热使得电池局部产生热量积聚从而导致电池局部温升,当热量积聚到一定程度就可能触发热失控连锁反应[7]。
根据内短路电池的电压、温度表现,可以将内短路分为突变型和缓变型。突变型内短路表现为短时间内(秒级)的电压突降和温度陡升,普遍原因为机械滥用或者热滥用导致的正负极大规模接触,最近也有研究证明:存在于负极和带正电的壳体之间的金属颗粒杂质也是导致突变型内短路的可能原因[8]。突变型内短路的短路电阻小,持续时间短,放热剧烈且集中。缓变型内短路表现为长时间的缓慢电压下降,在较差的散热条件下也能观察到温度的缓慢上升,其可能的原因为电滥用导致的金属沉积,沉积的金属穿过隔膜引发正极-负极的内短路。缓变型内短路的短路电阻大,持续时间长。有研究指出缓变型内短路存在着短路电阻逐渐减小的发展演化过程,并将缓变型内短路分为初期、中期和末期三个阶段[9]。在初期阶段,内短路阻值很高,内短路产热几乎可以被散热抵消,因此只能观察到自放电导致的电压异常降低;在中期阶段,随着内短路阻值的降低,电池异常产热和自放电现象更为明显;到了末期阶段,电池温度达到隔膜失效温度,隔膜崩溃引发大规模内短路,进而导致电池热失控[9]。因此,内短路检测算法需要在内短路发展到末期之前将内短路检测出来,给后续的处置留出充足的时间,避免内短路发展到末期引起热失控。
本工作首先对目前已有的内短路检测算法进行分类介绍,分析其优点与不足,之后提出一种基于长周期运行数据的内短路检测算法,并利用电池包的实际运行数据对算法有效性和准确率进行评估。
1 锂离子电池内短路检测方法研究进展
为了在内短路导致热失控之前将其检测出来,研究者们从不同角度出发,提出了多种内短路检测方法。现有的内短路检测方法可以分为以下5 类:①基于一致性差异的内短路检测方法;②基于电池模型的内短路检测方法;③基于自放电检测的内短路检测方法;④基于机器学习的内短路检测方法;⑤其他内短路检测方法。下面将分别对这5类算法进行介绍。
1.1 基于一致性差异的内短路检测方法
该类方法基于电池一致性假设,即同一个电池包中的电池单体由于其生产批次接近、工作工况相近,应该具有良好的一致性。当某个电池单体发生内短路后,该电池的电压、温度、SOC 等参数会与电池包中其他电池的对应参数产生差异,这种差异被定义为一致性差异,即内短路发生后,电池某些参数的一致性差异会增大,基于此原理就可以设计开发内短路检测算法。
基于一致性差异的内短路检测算法最早出现于发明专利中,Hermann等[10]提出利用电压一致性差异进行内短路检测,当某电池单体的电压显著低于其他电池单体时,认为该单体发生了内短路。进一步地,Ouyang等[11]提出了一种基于电池组平均-差异模型的内短路检测方法,该方法首先利用电池等效电路模型对电池开路电压OCV(open circuit voltage)、电池内阻进行估计,进而计算电池开路电压的一致性差异ΔE、内阻一致性差异ΔR和内短路一致性差异的波动值fluc(ΔR),通过判断计算的一致性差异值是否大于预设阈值来判断内短路是否发生。类似地,Feng 等[12]基于电池等效电路模型计算电池SOC(state of charge)、基于电池集总热模型计算电池产热功率,进而基于平均-差异模型计算SOC 的一致性差异ΔSOC 和产热功率的一致性差异ΔP,进而与预设阈值相比较来进行内短路的检测。除了基于平均-差异模型量化一致性差异外,Lai 等[13]提出通过计算相关系数来量化参数的一致性差异,某电池单体的一致性差异增大时会导致该电池单体与其相邻电池单体的相关系数降低。
基于一致性差异的内短路检测算法相对简单、计算量相对较低、对数据存储量的要求不高,是应用最广的内短路检测算法。然而该算法存在着很多缺点:①从采集到的信号角度,对于电池包内采用电池单体先并联后串联的构型,其一致性差异在信号上只表现为并联单元的电压一致性差异和温度采样点的温度一致性差异,因此基于一致性差异的内短路检测算法只能定位到发生内短路的并联单元,无法定位到具体单体。②造成电池包内各单体的一致性差异的原因有很多,比如电池老化造成的容量不一致会带来电压一致性差异;电池包内散热条件不一致会带来温度一致性差异。因此一致性差异大并不一定意味着存在内短路。③目前常用的BMS(battery management system)都具备均衡功能,均衡功能会在一定程度上缩小电池组的一致性差异,进而影响这一类算法的有效性。
1.2 基于自放电检测的内短路检测方法
对于缓变型内短路,超出正常范围的自放电是其重要特征之一,因此,通过检测异常的自放电可以有效判断电池是否发生内短路。然而,在缓变型内短路的初期,内短路的程度较低,短路电流较小,因此如何精确地测量短路电流或者放大短路电流的影响是这类检测方法的核心。
Sazhin等[14]提出一种针对电池单体的内短路检测方法,通过在电池两端并联恒压源,平衡状态下流过电池的电流即为内短路电流,该方法本质上是利用了高精度的电流传感实现了短路电流的测量。Schmidt 等[15]提出一种通过施加放电脉冲并监测脉冲后的弛豫电压曲线形状来检测异常自放电的方法,若电池存在异常自放电,则长时间的电压弛豫曲线会出现负斜率。进一步地,Haussmann等[16]基于弛豫电压曲线斜率估算了自放电电阻值,该方法利用放电后长时间的搁置将短路电流的影响通过电压曲线的斜率进行放大。Kong等[17]针对串联电池模组基于充电曲线相似性假设提出了剩余可充电容量RCC(remaining charging capacity)的计算方法,该方法通过计算相邻两次充电的RCC 变化估算短路电流,进一步地,Lai等[18]在该方法的基础上考虑了均衡策略,对均衡的影响进行了补偿,该方法利用较长时间的充放电过程将短路电流的影响通过电压曲线的平移进行放大。
尽管较大的自放电同样不一定是内短路引起的,电池内部的副反应也会导致化学自放电,但是相比一致性差异,自放电仍是内短路更为本质的特征。但是在信号特征上,自放电信号的提取难度更大,且往往需要较长时间的累积才能足够显著,因而在实际使用中,更易受到采样噪声等因素的影响。
1.3 基于电池模型的内短路检测方法
基于电池模型的内短路检测方法的基本思路是借助电池的物理模型将内短路检测问题转化为状态估计或参数辨识问题。Asakura 等[19]提出了一种比较恒流充电工况下的模型输出电压和实测电压来识别内短路的方法。Feng等[20]提出利用等效电路模型进行欧姆内阻和极化内阻等参数的辨识,以正常电池和内短路电池的电压、电流曲线为输入会得到不同的参数辨识结果,基于此进行内短路的检测。除此之外,基于模型得到的参数辨识和状态估计结果也可作为其他算法的输入,比如作为1.1 节介绍的一致性差异算法的输入,或者作为1.4 节将要介绍的聚类等机器学习算法的输入,与其他算法结合进行内短路的检测。
基于电池模型的内短路检测方法的一大优点是利用电池模型建立起的内短路情况下电池电压、电流、温度和电池状态参数(SOC、内阻等)的对应关系,但这类算法最大的问题是模型参数的准确性会影响算法的性能,一方面新鲜电池的模型需要大量实验进行标定,另一方面当电池老化之后模型参数会发生改变,如何更新电池老化后的模型参数是个亟待解决的问题。
1.4 基于机器学习的内短路检测方法
随着电池云端数据量和数据精度的提升,开发数据驱动的内短路检测方法成为可能,目前已有相关研究利用机器学习算法实现内短路的检测并进一步地分析内短路与热失控、内短路与短路触发条件之间的关系。Naha 等[21]利用数据训练随机森林模型并利用内短路实验结果对模型进行验证,证明模型拥有高达97%的准确率。Kriston 等[22]利用主成分分析和聚类算法对780 组不同仿真数据进行分析,利用聚类算法可以对不同热失控类型进行区分。Li等[23]利用随机森林、支持向量机、神经网络等机器学习方法对2500 余组机械滥用导致内短路的仿真数据进行分析,建立了不同机械滥用条件下的安全边界。
可以看到,目前基于机器学习的内短路检测方法仍主要以实验数据或者仿真数据为输入,直接利用车用电池或储能电池的实际运行数据开发的算法较少,因此很难评价这类方法的实际应用效果。一方面由于在实际运行过程中大量的数据都是无标签的数据,有故障标签的数据很少,以内短路为故障标签的数据就更少了,少量的数据无法支持机器学习算法的开发;另一方面根据1.1~1.3 节的分析,内短路在电池信号特征上很难和其他故障类型做完美的区分,因此机器学习类算法更多地用于广义的故障诊断,即只区分故障电池和正常电池。在广义的故障诊断方面,王震坡团队借助新能源汽车国家监测与管理平台的大量故障车数据,提出了一系列数据驱动的故障诊断算法,如基于熵值故障诊断方法[24]、基于多参数聚类的故障诊断方法[25]、基于长短时记忆神经网络的故障诊断方法[26]等。这些算法对于实车故障数据具有较好的检测效果,但并不针对内短路这一具体故障类型。
1.5 其他内短路检测方法
上述方法大多没有对电池单体结构或者电池模组结构进行改变,只是利用电池电压、电流、温度信号进行内短路的检测。而通过改变电池和模组结构,可以获得更丰富的信息,有助于更精确地定位短路单体或者确定短路发生时刻。Zhang 等[27-28]提出了一种对称环形并联电路结构,传统的并联结构导致内短路检测算法只能定位发生短路的并联单元,无法确定并联单元中具体哪个电池单体发生内短路,而对称环形并联电路结构通过在并联环路上布置电流传感器,可以精确定位并联单元中的内短路单体。Wu等[29]将传统的隔膜替换为聚合物层-金属层-聚合物层“三明治”结构的隔膜,中间的金属层充当电极,当枝晶生长穿透聚合物层时,金属层和负极之间的电压会发生下降,基于此信号可以在内短路完全形成之前进行内短路的预警。这类内短路检测方法虽然在一定程度上提高了内短路的检测效果,但是由于其需要对传统的电池单体和电池模组结构做较大的改变,若大规模应用会导致电池系统成本的增加,因此尚无法实际应用。
上述对于内短路检测方法的分类旨在条理清晰地对目前已有的内短路检测算法进行介绍。正如在1.3 节提到的,在实际使用中,一个完整的内短路检测算法不只依靠单一的指标或者模型,而是往往采用多指标[30](一致性差异、自放电)、多模型[31](等效电路模型、热模型)、多策略[24](分级阈值、机器学习找离群点)融合的算法,以提高内短路的检测性能。针对以上对现有内短路检测方法的分析,本工作提出一种基于长周期运行数据的锂离子电池内短路检测算法,利用长周期的数据对微弱的自放电信号进行放大,综合考虑内短路引起的一致性差异、自放电效应和异常产热效应进行指标提取,利用聚类算法对内短路电池进行精准定位,并借助归一化分数进行分级报警,最终采用实际电池包运行数据对算法的准确率和误报率进行评估。
2 基于长周期运行数据的锂离子电池内短路检测算法
2.1 算法提出
本工作提出的基于长周期运行数据的锂离子电池内短路检测算法可以分为以下几部分:数据预处理、指标提取、聚类与结果输出,下面将分别对三部分进行介绍。
2.1.1 数据预处理
本算法针对电池包长周期运行数据开发,将长周期定义为数据时长大于6个月或数据帧数不小于10 万帧的数据。首先对原始数据进行数据清洗以除去无效数据帧,从原始数据中提取时间、电压、电流、温度、充放电标志位等数据项。之后,对数据按照充放电过程进行分段处理,取一个放电加充电过程为一段,以电压为例,第i段电压矩阵如式(1)所示。

其中v ij,k为第i段电压矩阵中第k个电压采样点的第j帧电压,mi为第i段电压矩阵的行数(总帧数),n为电压矩阵的列数(电压采样点个数),p为分段后的电压矩阵数量,全部电压数据可以表示为:Voltage =[V1,V2,…,Vp]。温度、电流等数据项也做同样的处理。
2.1.2 指标提取
利用分段后的电压、温度数据进行内短路相关指标的提取,包括电压一致性差异指标、自放电指标、温度一致性差异指标和异常温升指标,下面分别对各指标的计算方法进行介绍。
(1)电压一致性差异指标计算。首先,基于电池平均-差异模型计算各段电压的电压一致性差异:
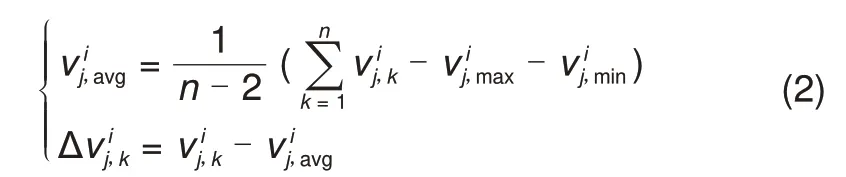

(2)自放电指标计算。利用电压一致性差异指标的计算结果,定义自放电指标为电压一致性差异指标随时间的变化率。在自放电率较低时,电压一致性差异指标往往波动较大,直接差分计算自放电指标也会使自放电指标波动较大,因此采用最小二乘法计算自放电指标,如式(5)所示:

(3)温度一致性差异指标计算。首先,基于电池平均-差异模型计算各段温度的温度一致性差异:

由于电池包运行数据的温度精度较差,一般为1 ℃,且温度的波动频率远低于电压的波动频率,因此数据同步性和采样噪声的影响不明显,所以无须对ΔT i j,k进行滤波,可直接计算ΔT i j,k的平均值ΔT iavg,k作为该段温度曲线的温度一致性差异指标:

(4)异常温升指标计算。电池温度是产热和散热共同作用的结果,对于长周期运行数据而言,电池外部环境温度随昼夜、季节会有明显的变化,内短路的产热在长周期上很难对电池温度表现出持续的影响。因此,将异常温升指标定义为每段温度数据中的温度采样点温度极差,以反映在该段温度数据中的温升情况:

2.1.3 聚类与结果输出
对提取到的指标进行归一化后,采用聚类算法得到内短路单体编号,设定不同阈值并根据归一化指标给出一致性差异、自放电和异常温升的故障等级。
(1)指标归一化。由于各指标具有不同的量纲,难以将其直接进行比较,因此需要对各指标进行归一化以消除量纲的影响,通过计算各指标的归一化分数(Z_score)将各指标进行归一化,如式(9)所示:

(2)聚类算法。采用基于密度的DBSCAN(density-based spatial clustering of applications with noise)聚类算法[32],算法包括两个参数,分别是邻域半径eps和最少点数目minpoints,算法流程描述如下:
①选择数据集中尚未检查过(未被归为某个簇或者标记为噪声)的对象点p,检查其邻域,若邻域内点的数目不少于minpoints,则建立新簇C,将邻域内所有点加入候选集合G;若邻域内点的数目少于minpoints,则将p点标记为噪声;
②对候选集合G中所有未被处理的对象点q,检查其邻域,若邻域内点的数目不少于minpoints,则将这些点加入G;若q未归于任何一个簇,则将q归入簇C;
③重复步骤②,继续检查G中未处理的对象点;
④重复步骤①~③,直到所有对象点都归入某个簇或者标记为噪声。
(3)分级报警。对于归一化指标Z1、Z2,设置三级报警阈值为-3、-5、-7,当归一化指标小于对应报警阈值时给出对应的报警信号;对于归一化指标Z3、Z4,设置三级报警阈值为3、5、7,当归一化指标大于对应报警阈值时给出对应的报警信号。
2.2 数据情况
采用电池包实际运行数据对算法进行有效性验证,共包括10组电池包运行数据,编号1~10。其中数据组1 和数据组2 为最终发生热失控的数据,其故障标签为1;其余8 组为正常的电池包运行数据,故障标签为0。数据详细信息如表1 所示。这10 组数据来自同一款电池包,从数据项中可知,该款电池包由90 个并联单元相互串联连接而成,数据中包括了90 个并联单元的端电压,其中每个并联单元可能由多个单体并联组成,但具体电池单体数量和单体容量未知。数据中共有18 个温度采样点的温度数据,即不是每个并联单元都有温度测点,而是平均5 个并联单元对应1 个温度测点,因此根据温度信息无法直接对应到某个并联单元,在后续的数据处理时会做相应的考虑。
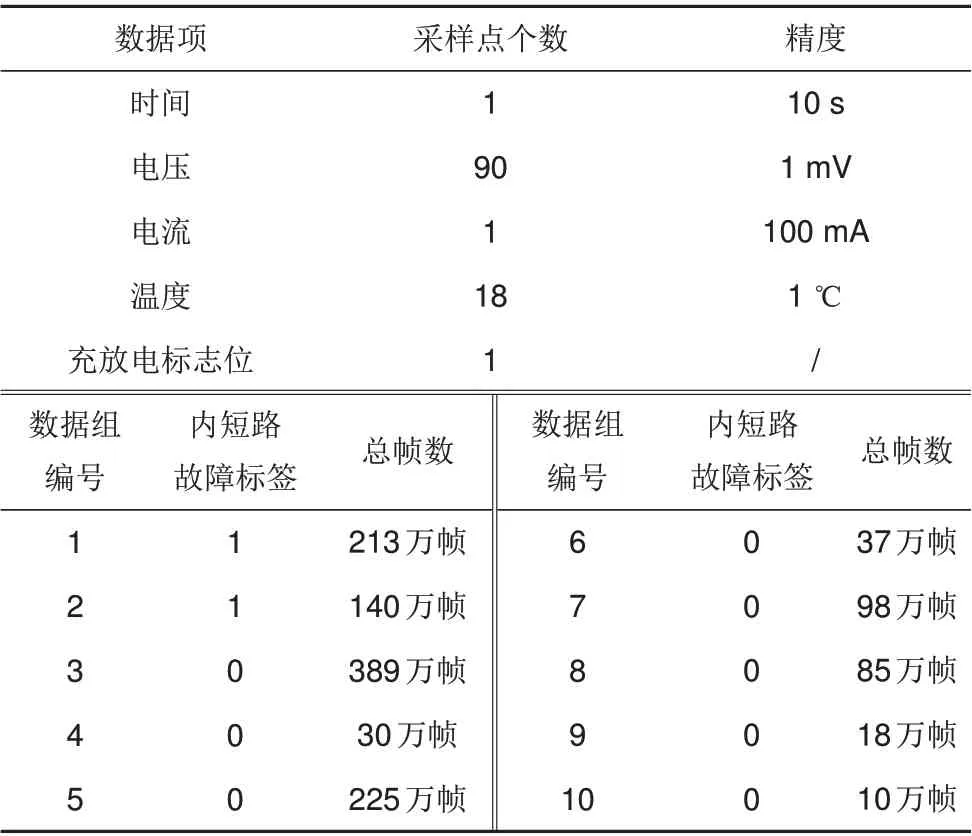
表1 数据详细信息Table 1 Detailed information of data
3 结果与讨论
3.1 故障电池包数据的算法运行结果
数据组1 和2 为故障电池包的运行数据,以数据组1为例展示算法对于故障电池包数据的运行细节,数据组1 共有213 万帧数据,首先对数据组1进行数据清洗和数据分段。数据组1按照一次放电加充电为一段,共分成124段。其中各段数据帧数的分布如图1所示,数据段长度最长不超过6万帧,大部分数据段的长度集中在5 千帧~2.5 万帧之间。

图1 数据组1的数据分段帧数分布Fig. 1 Frame number distribution of the data segments of data group 1
对分段后的数据进行指标提取,首先进行电压一致性差异的计算。以第一段数据为例,根据式(2)计算得到的电压一致性差异见图2(a),由于数据同步性较差,直接计算得到的电压一致性差异波动剧烈,波动幅值±0.2 V,若不进行滤波则会对一致性差异指标的计算造成影响。采用如式(3)所示的EWMA滤波后得到图2(b),波动幅值约为±0.005 V,波动被明显抑制。

图2 数据组1第一段数据的电压一致性差异Fig. 2 Voltage inconsistency of the 1st data segment of data group 1
利用式(4)计算各段数据的电压一致性差异指标,计算结果如图3所示。绝大部分并联单元的电压一致性在±0.005 V内波动,长期来看并没有增大或减小的趋势。只有最下方对应3号并联单元的黄色曲线,由于其存在着微弱的负向增大的趋势(约-10 mV/213万帧),使得电压一致性差异指标逐渐离群。

图3 数据组1的电压一致性差异指标Fig. 3 Voltage inconsistency indicator of data group 1
进一步地,在电压一致性差异指标的基础上,根据式(5)计算电池自放电指标,计算结果如图4所示。在前20 段数据中,由于点数较少导致计算结果有较大波动;在20 段数据之后,计算结果逐渐收敛。除3 号并联单元的自放电率稳定在-4×10-10V/s之外,其余并联单元的自放电率都收敛在0 附近。因此3 号并联单元的自放电指标也逐渐离群。
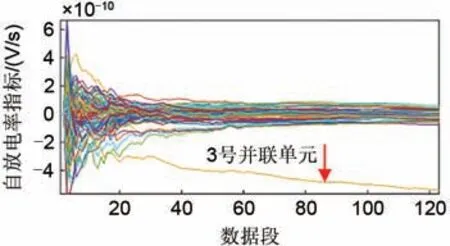
图4 数据组1的自放电指标Fig. 4 Self discharge indicator of data group 1
根据式(6)对分段温度数据计算温度一致性差异,以第一段数据为例,计算结果如图5所示,温度一致性差异在±2 ℃之内。由于温度采样精度为1 ℃,所以没有表现出由于数据同步性差导致的温度一致性差异计算结果的波动,因此无须对温度一致性差异进行滤波处理。
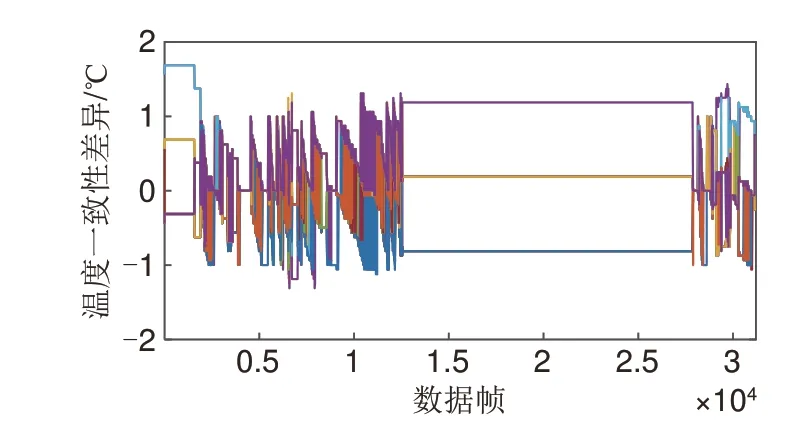
图5 数据组1第一段数据的温度一致性差异Fig. 5 Temperature inconsistency of the 1st data segment of data group 1
进一步地,根据式(7)计算各段数据的温度一致性差异指标,计算结果如图6所示。绝大部分温度采样点的温度一致性在±1 ℃内波动,长期来看并没有增大或减小的趋势;只有最上方对应4号温度采样点的紫色曲线和对应6号温度采样点的蓝色曲线的温度一致性差异偶尔大于1 ℃。总的来看,所有温度采样点的温度一致性差异在[-1 ℃,2 ℃]的范围内,温度一致性较好。

图6 数据组1的温度一致性差异指标Fig. 6 Temperature inconsistency indicator of data group 1
根据式(8)计算各段数据的异常温升指标,计算结果如图7所示。所有温度采样点的异常温升指标都不超过4 ℃,说明温度传感器并没有检测到异常的温度升高,这一方面可能是由于内短路程度不严重,短路电阻较大,因此短路产热较小不足以引起电池的异常温升;另一方面也可能是由于温度采样点布置位置距离内短路单体较远,没有捕捉到由于内短路造成的温度升高。

图7 数据组1的异常温升指标Fig. 7 Abnormal temperature rise indicator of data group 1
指标计算完毕后,利用式(9)对四项指标进行归一化,结果如图8所示。归一化后,各指标变为无量纲数,可以进行相互对比和后续的聚类处理,并按照设定的报警阈值进行报警。从电压相关指标来看(图8),3号并联单元归一化后的电压一致性差异指标和自放电指标对应图中黄色曲线,呈现出明显的离群;而从温度相关指标来看,归一化后的温度一致性差异指标和异常温升指标几乎都不超过报警阈值,也没有某一温度点对应的指标表现出明显离群。

图8 数据组1的指标归一化结果Fig. 8 Normalized indicators of data group 1
考虑到温度采样点的数量远小于电压采样点的数量,也即平均5个并联单元只有1个温度采样点,因此温度采样点测得的温度无法反映每个并联单元的真实温度,而电压采样点的电压包括了每个并联单元的电压。因此在使用聚类算法时,仅将Z1和Z2作为算法的输入,这样算法输出的结果可以直接对应到具体的并联单元。DBSCAN算法的参数eps取2.5,minpoints 取3,算法运行结果如图9 所示。由于数据组1共分成了124段,因此聚类算法会执行124 次,每次运算都会输出对应的离群点编号。图9(a)为数据组1第50段数据指标的散点图和聚类结果,其中红色点是算法输出的离群点,对应3号并联单元,蓝色点是算法输出的正常点。记录下聚类算法各次的输出结果,即离群点对应的并联单元编号,可得到图9(b)。可以看到对于第1~27 段数据,聚类算法没有输出离群点;从第28 段数据开始,3号并联单元为唯一离群点。因此,算法会在第28段数据时给出内短路的报警信号,认为3号并联单元发生内短路。
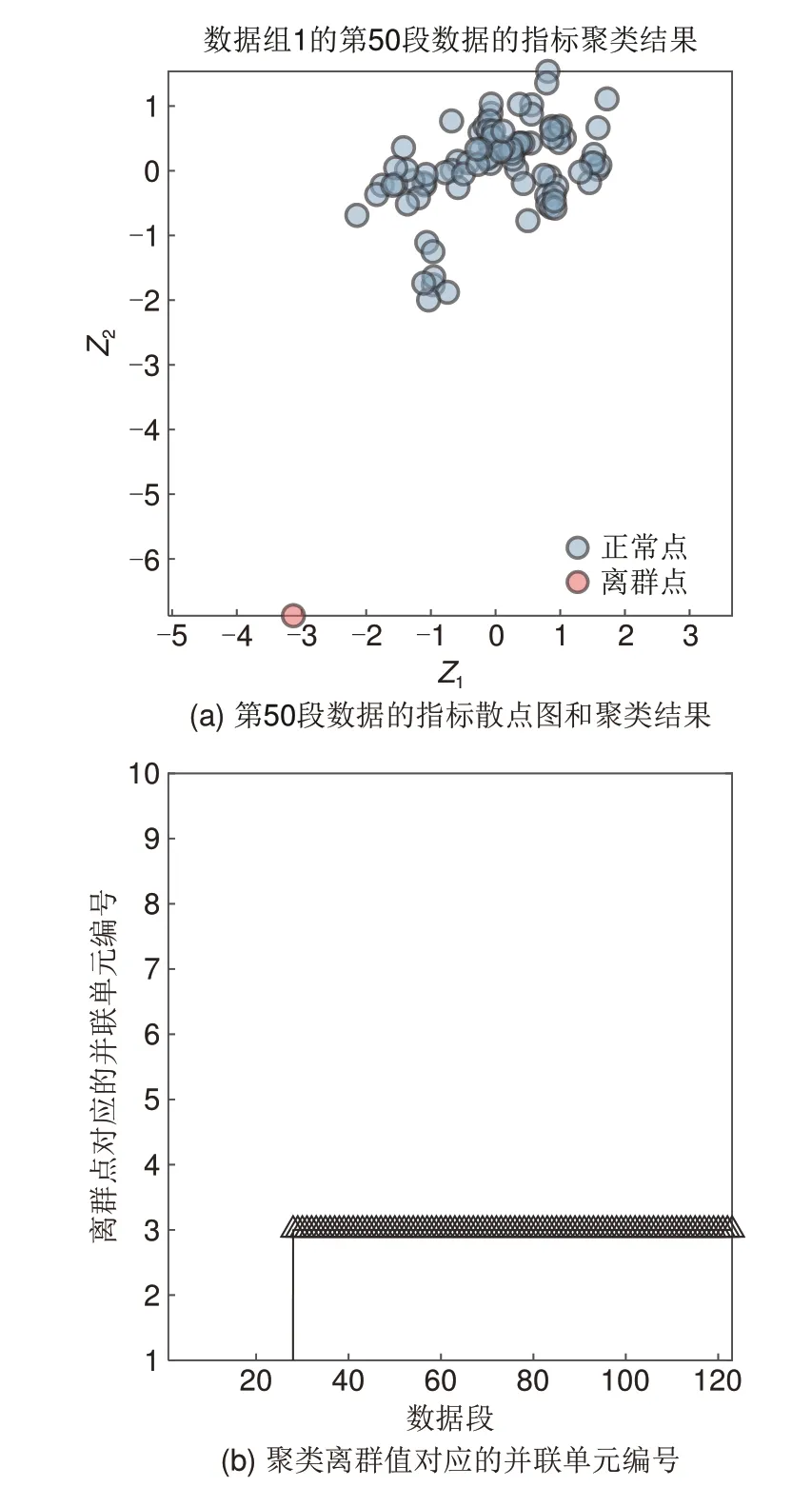
图9 数据组1的聚类结果Fig. 9 Clustering results of data group 1
进一步地,在算法给出内短路报警信号后,计算一致性差异、自放电、异常温升对应的报警等级,得到如图10 所示的数据组1 第28 段数据的各指标散点图。在图10(a)中,归一化的电压一致性差异指标Z1越小,则电压一致性越差;归一化的自放电指标Z2越小,则对应并联单元的自放电率越大,且1~3 级报警阈值分别为-3、-5、-7。图中红色点为并联单元3对应的数据点,蓝色点为其余并联单元的数据点.可见对于并联单元3 而言,其Z1<-3、Z2<-5,因此给出电压一致性1级报警和自放电异常2 级报警。在图10(b)中,归一化的温度一致性差异指标Z3越大,则温度一致性越差;归一化的异常温升指标Z4越大,则异常温升越大,且1~3级报警阈值分别为3、5、7。图中黄色点为所有温度采样点的数据,所有点都处在正常范围内。

图10 数据组1的分级报警结果Fig. 10 Hierarchical alarm results of data group 1
根据以上分析,对于数据组1而言,算法在第28段数据时检测出3号并联单元发生内短路,并给出电压一致性差异1级报警和自放电异常2级报警。第28 段数据对应的时间为2019 年11 月25 日,而数据组1的最后一帧数据时间为2020年4月26日,因此本算法可以对于数据组1的内短路预警提前时间为5个月。数据组2的数据特征和数据组1相似,因此不再赘述其分析细节,算法对于数据组2同样可以实现预警,预警提前时间约2个月。
3.2 正常电池包数据的算法运行结果
数据组3~10为正常电池包的运行数据。对于正常数据而言,由于没有内短路的存在,各电压、温度采样点的一致性差异指标、自放电指标和异常温升指标应该没有离群点。在8组正常数据中,数据组3 的帧数最多,因此以数据组3 为例展示正常数据的算法运行结果。
数据组3 共有389 万帧数据,对数据组3 的数据分段共分成249段。图11为数据组3的指标归一化结果,与内短路故障数据组1 的图8 相比,数据组3的四项归一化指标都没有离群值。

图11 数据组3的指标归一化结果Fig. 11 Normalized indicators of data group 3
数据组3 的聚类算法运行结果如图12 所示,以第100 段数据为例展示聚类算法的运行结果见图12(a),可以看到全部数据点集中分布,聚类算法判定所有点都为正常点。聚类算法对全部249段数据的计算结果见图12(b),对于全部数据段聚类算法都没有数据离群点,证明本算法对于该组正常数据不会误报。
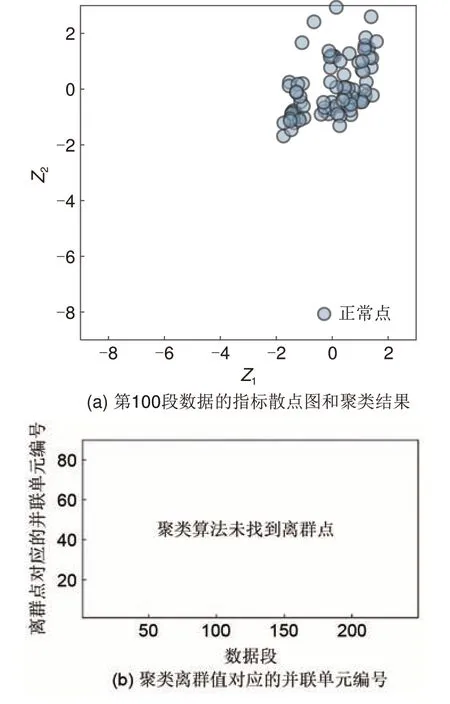
图12 数据组3的聚类结果Fig. 12 Clustering results of data group 3
对其他正常数据组,算法表现出和数据组3类似的运行结果,即算法对于全部的8组正常数据组都不会产生误报。综合算法对于内短路故障数据的表现,可以认为本工作所提出的算法对于这10 组实际运行数据具有较高的检出率和较低的误报率。
4 结 论
本文简要综述了锂离子电池内短路检测问题的研究进展,分类讨论了各类内短路检测方法的优缺点。提出了一种基于长周期运行数据的锂离子电池内短路检测算法,综合考虑内短路引起的一致性差异、自放电效应和异常产热效应并对长周期运行数据进行指标提取,利用聚类算法对内短路电池进行精准定位,并借助归一化分数进行分级报警,最终利用电池包的内短路故障数据和电池包的正常运行数据对本工作所提出的算法进行了检出和误报情况的评估。对于本工作所用的10组电池包运行数据,算法可以实现高检出率和较低误报率;对于2组内短路故障数据,算法可以在内短路引起热失控之前数月给出内短路报警信号。本工作提出的算法具有良好的迁移性,不只适用于车用锂离子电池系统,也可迁移至储能场景,具有实际应用价值,能够切实降低锂离子电池系统的安全隐患。
猜你喜欢
公民与法治(2022年5期)2022-07-29 00:47:28
少年博览·小学高年级(2022年6期)2022-05-30 20:26:20
教学考试(高考物理)(2021年5期)2021-11-08 10:31:22
中医眼耳鼻喉杂志(2021年1期)2021-07-22 07:38:14
作文大王·笑话大王(2016年6期)2016-06-22 11:33:08
作文大王·笑话大王(2016年4期)2016-04-27 11:40:20
电源技术(2016年6期)2016-04-05 08:46:30
作文大王·笑话大王(2016年1期)2016-02-24 11:25:51
燕山大学学报(2015年4期)2015-12-25 02:19:49
电源技术(2015年7期)2015-08-22 08:48:40
