
交互式机器翻译综述
2023-02-24 05:00廖兴滨秦小林张思齐钱杨舸
计算机应用 2023年2期
廖兴滨,秦小林*,张思齐,钱杨舸
(1.中国科学院 成都计算机应用研究所,成都 610213;2.中国科学院大学 计算机科学与技术学院,北京 101408)
0 引言
交互式机器翻译(Interactive Machine Translation,IMT)也被称为交互式机器预测或目标文本介导的交互式机器翻译,是一种人工翻译人员或者用户与机器翻译系统输出互动的翻译模式[1]。交互式机器翻译的出现主要原因包括:1)当前最先进的SOTA(State Of The Art)的机器翻译(Machine Transaction,MT)技术仍然无法实现任何两种语言间的高质量翻译,必须要对机器翻译系统的输出进行人工后期编辑(Post-Editing),而IMT 是一种可行的解决方案;2)交互式模式识别(Interactive Pattern Recognition,IPR)框架很容易和机器翻译系统结合,机器翻译系统可以预测给定源句子的翻译,用户可以接受该翻译或进行修正以产生反馈;3)交互式机器翻译可以在迭代交互过程中提出新的改进译文,直到整个输出被用户接受,而在该过程中产生的反馈信号可以用于训练。
在这种模式下,机器翻译系统根据源句子和当前时刻已经产生的部分译文给出建议,而用户要么接受翻译系统输出的候选译文,要么给出针对当前候选译文的反馈。当用户对给出的建议翻译不满意时,机器翻译系统会根据用户的反馈信号,重新更新模型以完成对新的候选翻译的预测,并将更正后的版本呈现给用户。这种方法与Post-Editing 机器翻译输出的常见做法形成对比,区别在于该方法在训练过程中即引入人工影响,模型可以得到更多的反馈信号,从而可以获得更好的性能,而在Post-Editing 方式中,用户仅根据机器翻译系统输出的完整译文进行修改,直到译文能满足特定的要求。
伴随着机器翻译的发展,IPR 框架可以和不同时期的机器翻译模型相结合,从而产生不同的研究方法,正是出于这一点考虑,本文根据交互式机器翻译形式的不同,从交互式统计机器翻译(Interactive Statistical Machine Translation,ISMT)、交互式神经机器翻译(Interactive Neural Machine Translation,INMT)和结合强化学习(Reinforcement Learning,RL)方法的交互式机器翻译(Interactive Reinforcement Learning based Machine Translation,IRMT)这三方面对交互式机器翻译的历史发展过程及主要技术展开介绍,早期的相关综述可以参考文献[2]。
1 机器翻译背景
机器翻译是在计算机程序的帮助下将一种自然语言(简称源语言)映射成另一种自然语言(简称目标语言)的过程。这一简单直观的想法经历了机译系统、统计机器翻译和神经机器翻译三个阶段的发展,再结合强化学习技术,已日渐成熟。互联网上有很多翻译应用,可以应用于日常工作和学习,部分应用已经开始商用,但是目前机器翻译的效果在很多特定场景下仍然难以令人满意,因此机器翻译研究还需要结合IPR,作进一步的探索。
1.1 统计机器翻译
给定一个源句子x,SMT 系统试图找到一个目标语言句子,使得这个句子是源句子x的翻译的后验概率最大:
根据贝叶斯公式,可以将P(h|x)写成如下形式:
其中:P(h)表示语言模型,重点是求翻译概率P(x|h),IBM Model 1~IBM Model 5 以及基于短语的翻译模型等都给出了相应的求解方法。
1.2 神经机器翻译
得益于深度学习的飞速发展,自然语言处理(Natural Language Processing,NLP)领域也进行了大量的学术研究,端到端(End-to-End)的神经翻译模型(图1)和基于编码器解码器(Encoder-Decoder)架构的模型(图2)成为神经机器翻译着重考虑的两个模式。
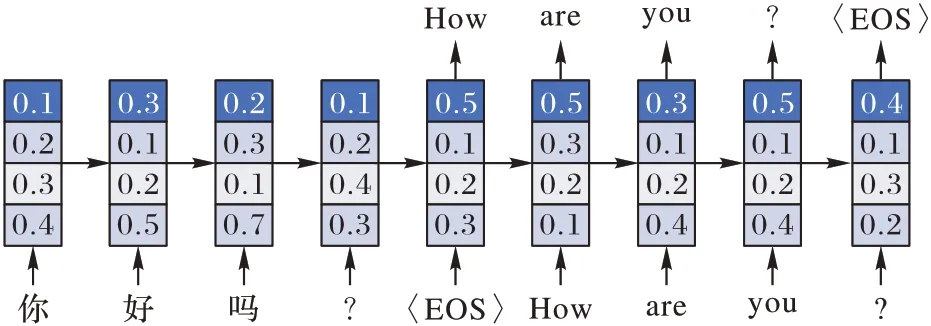
图1 端到端模型Fig.1 End-to-end model

图2 Encoder-Decoder模型Fig.2 Encoder-Decoder model
这两种主流的架构多采用擅长处理长序列数据的循环神经网络(Recurrent Neural Network,RNN),如长短期记忆(Long Short-Term Memory,LSTM)网络或者门控循环单元(Gate Recurrent Unit,GRU),而引入注意力机制[3]可以针对长序列句子以获得更好的翻译性能,解决机器翻译的长距离依赖关系。Transformer[4]是一种只采用Attention 机制和线性层的 Encoder-Decoder 模型,文献[5]中使用BERT(Bidirectional Encoder Representations from Transformers)[6]预训练模型最后一层输出的基于上下文的Embedding 信息,融入机器翻译模型中,进一步提升了翻译的性能。
1.3 结合强化学习方法的交互式机器翻译
将强化学习引入机器翻译系统中,一方面强化学习可以作为一种优化方法,文献[7]中指出,一些网络的前向运算中包含随机采样操作,这种操作会造成梯度回传中断,因此需要用随机采样的方式估计梯度;另一方面强化学习可以为一系列序列到序列(Sequence to Sequence,Seq2Seq)任务和序列生成任务建模,优化一系列与任务相关的目标函数,如在机器翻译任务中,文献[8]中采用强化学习方法对NMT 模型进行训练,文献[9]中则是对翻译模型进行优化。
2 交互式统计机器翻译
交互式统计机器翻译的核心思想是:先由机器翻译系统翻译出部分(或者完整的)目标语言翻译,然后由人工手动标注或修改,这种行为可以获得一些用户反馈,用户反馈进而又可以指导机器翻译的提升。在传统的统计机器翻译系统中,对于一个源语言句子x和一个由翻译系统预测的前缀q,统计机器翻译的优化问题可以简化为一个搜索问题,即寻找一个后缀s,使得这个后缀与前缀结合可以作为源语言句子的翻译[10]:
因为前缀和后缀的结合就是目标语言句子,因此式(3)可以重写成:
交互式统计机器翻译基于当前翻译,在系统产生候选翻译后,与用户进行交互,文献[11]中提出并评估三种计算效率高的在线方法,用于更新IMT 系统。文献[12]中研究了基于统计机器翻译方法的新型人工翻译辅助,开发了计算机辅助工具Caitra,为句子的候选翻译提供建议,显示单词和短语的翻译选项,同时允许对机器翻译输出进行后期编辑,在辅助工具的帮助下,明显加快了翻译人员的翻译速度。文献[13]中把在线学习范式应用于IMT 框架中,在系统和用户交互的过程中会产生很多用户反馈,这些用户反馈可以用来扩展模型,而在非在线学习MT中则无法使用这种用户反馈。
文献[14]中分析了判别岭回归在交互式机器翻译框架下学习SOTA 的机器翻译系统的对数线性权值的适用性。文献[15]中将用户与IMT 系统交互过程中的鼠标点击操作提取成中间译文的词对齐信息,可以实现对译文的动态词对齐标注,在词对齐和参考译文的约束下提高了IMT 的准确率。文献[16]中则是从翻译人员的角度采集用户的反馈数据,并研究了翻译系统对用户反馈的依赖程度,然后进一步改进模型,以提高翻译系统的性能。
为了减少用户和系统交互的工作量,IMT 系统向用户提供评价系统输出的候选翻译的置信度信息(Confidence Measures,CMs)。在文献[17]中,CMs 用于IMT 系统以提高翻译预测的准确性。在文献[18-19]中提到,CMs 也可以用于减少用户与IMT 系统交互的次数,从而减少了用户的工作量,只有那些根据置信度评估为不正确的候选翻译才由参与交互的用户提供反馈。在计算置信度评分时,文献[20]提出一种具有不依赖系统输出的置信度计算方法,称为词后验概率的向后最大估计,适用于所有类型的机器翻译系统,优于传统的置信度估计,计算方式为:
其中:fi是原始句子的第i个单词,规定f0为空句子;e表示目标语言中的单词。式(5)的目的在于最大化给定源语言句子后目标语言句子的后验概率。
文献[21]中利用句法层面的子树信息来指导候选译文的产生,能显著减少人机交互次数。文献[22]中一方面提出了基于短语表的多样性排序算法,根据用户对翻译过程的认知,设计了便于用户交互的界面,让用户从候选翻译列表中选择正确的翻译选项,改善了用户体验,并减少了用户的工作量;另一方面在解码阶段,利用双语数据和前缀来指导解码过程以提高翻译性能。
文献[23]中证明,用户能通过微弱的反馈来纠正模型,提出了对潜在变量模型的推广,给出了基于反馈的潜在感知器在线学习的遗憾界和推广边界,并证明了弱反馈学习仍会收敛。文献[24]中描述了一种新的交互式机器翻译方法,它能够使用基于短语和层次翻译模型,并在统一的统计框架中集成错误校正。
另外,为了保证用户的交互体验,实时用户交互系统应当具有高效的搜索技术,如Word-graph 表示和维特比算法。为了获得快速的响应,文献[25]中使用单词假设图作为一种有效的搜索空间表示,对当前的翻译前缀进行扩展。文献[26]中允许翻译人员提供除前缀外的多个正确片段(cf),这些片段作为解码的正约束,同时为了适应这种新的交互模式,提出了相应的改进方法。
交互式统计机器翻译方法在很大程度上促进了机器翻译领域的发展,进一步提升了交互式机器翻译方法的性能,而随着深度学习和神经机器翻译的发展,INMT便自然产生了。
3 交互式神经机器翻译
神经机器翻译模型的解码过程是通过在每个时间步生成一个标记(Token),直到遇到句子结束符“〈EOS〉”标记为止,每个标记都以之前生成的标记作为历史信息,进而指导下一个标记的生成。在这个过程中,交互式预测非常容易集成到标准的机器翻译中:在下一个标记生成的上下文语境中,可以不使用翻译模型给出的预测,而是使用专业译者提供的前缀中的标记,或者使用用户给出的反馈来指导模型的更新。
注意力机制作为一种解决信息过载的手段,提出不久就在包括自然语言处理、图像处理领域的多项任务上得到了大量应用,并取得了非常好的性能提升。文献[27]中提出了一种新的注意力机制,称为“交互式注意力”,它通过读写操作来模拟翻译过程中解码器和源句表示之间的互动,作者对NMT 系统的Decoder 部分进行了改进:引入一个表示t时刻源句子的词嵌入表示和t时刻Decoder 状态的中间状态,同时Decoder 在时刻t的状态计算也有了改进,另外引入Attentive read 和Attentive write 操作,以便进行交互,Decoder可以根据这种机制自动区分哪些部分已翻译以及哪些部分未翻译。在NIST 汉英翻译任务上的实验表明,交互式注意力比早先提出的基于注意力的NMT baseline 和一些SOTA 的基于注意力的NMT 变体有明显的性能提升。
因为当时的机器翻译系统不能给出令人满意的翻译结果,而交互式翻译系统训练中需要人工参与,提升用户的交互体验和简化交互协议是提高训练效率的有效手段,因此文献[28]中将神经机器翻译任务整合到互动机器翻译框架中以提升人机协作,对NMT 的Decoder 进行了简化,使得提出新的交互协议变得更加简单,以便为用户提供更好的体验,同时系统将获得更高的生产力,在采用交互式预测机器翻译后,可以显著改善经典的基于短语的方法。文献[29]中则是引入额外的翻译人员的先验知识对INMT 系统进行训练,并且在解码阶段把用户的纠正信息融入INMT 的Decoder,同时保持当前信息不变,重新解码操作。
主动学习经常被用于降低数据标注的成本,并且主动学习需要人工交互来对难以划分的样本进行标注,因此主动学习非常容易与交互式框架结合。文献[30]中研究了主动学习技术在交互式神经机器翻译的无界数据流翻译中的应用,即从大量的质量不等的源句子流中挑选出值得由交互式神经机器翻译系统与用户交互的句子,对模型进行更新。将主动学习技术纳入该领域可以减少学习过程中所需要的用户工作量,同时提高翻译系统的质量。此外,采用主动学习的交互式神经机器翻译系统的性能在很大程度上超过了传统的SOTA 方法。
文献[31]研究了在后期编辑或互动翻译过程中NMT 系统的增量更新问题,并指出在在线学习框架下,不论是在训练阶段还是在预测阶段,用户在交互过程中会产生反馈信号,可以收集新的数据以进行训练,通过在线学习技术,对INMT 模型的更新是即时进行的,这是在线学习的重要优势。另外,该方法通过一个字符级交互式自适应系统减少获得高质量翻译所需的人力成本,这些自适应系统在资源匮乏的情况下也表现良好,INMT 系统可以迅速适应特定的领域。
文献[32]中探讨了在不同翻译指标上交互式机器翻译和后期编辑对翻译系统产生效果的比较。对具有底层神经翻译系统(NITP)的翻译生产力的实证研究结果显示,在一些研究任务中,超过一半的专业译员选择使用NITP,与后期编辑相比,翻译速度更快。
通过改进系统与用户交互的方式也可以显著减少用户的工作量。文献[33]中,作者介绍了一个交互式机器翻译界面,该界面通过即时提示和建议来协助用户的翻译,用户仅需要通过键盘按键(如方向键上、下,Tab 键,Enter 键等)来提供反馈,必要时可以输入系统提供的候选翻译的首字母进行交互,这大幅减少了用户的工作量,也使端到端的翻译过程更快、更有效,并易于产生高质量的翻译。图3 是Microsoft开发的交互式神经机器翻译系统的用户交互界面。
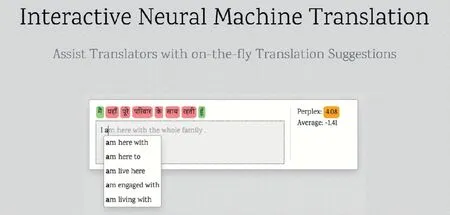
图3 Microsoft开发的INMT系统界面Fig.3 Interface of INMT system developed by Microsoft
CMs 是改进交互方式的一种实现方式,为了保证用户与机器之间交互的良好体验和效率,翻译系统所用的CMs 必须在计算上足够快,文献[34]介绍了几种用于交互式预测神经机器翻译的快速CMs,这些估计器让系统通过获得质量较差的翻译来实现减少输入单词数的目的,在获得高质量翻译的同时,需要纠正的单词数量减少。
文献[35]介绍的TranSmart 是一个实用的人机互动翻译系统,它能够在翻译质量和效率之间进行权衡。TranSmart还可以通过使用历史上的翻译句子作为其记忆来避免类似的翻译错误,该系统支持词级自动补全、句级自动补全和翻译记忆三个重要功能,而传统的交互式翻译系统只提供单词级补全,使用更丰富的自动补全和记忆功能可以更有效地帮助用户提高交互速度。
在交互式神经机器翻译系统的发展过程中,得益于深度学习在强化学习领域的发展,交互式强化机器翻译充分结合了IPR、深度学习和强化学习的优点,作为一类重要的方法,与交互式神经机器翻译一起,促进了机器翻译领域的发展。
4 交互式强化机器翻译
机器翻译任务是一个Seq2Seq 任务,而序列相关的任务可以建模成一个贯序决策问题:给出一个源句子,然后逐词依次给出翻译结果,而下一个待预测的词往往对历史信息(即上文已经翻译出来的词)产生依赖,因此可以把机器翻译问题建模成马尔可夫决策过程。文献[36]中指出,机器翻译任务是一个从人类反馈中进行强化学习的自然替代问题:用户对候选翻译提供快速、低质的评分,以指导系统进行改进。
文献[8]中指出,传统的端到端的神经机器翻译根据历史输出来指导当前候选翻译的生成,将问题简化成最大化“正确”标记的对数似然,模型最终学到的分布很可能是一个错误的分布,在评估时,模型根据自己学到的知识预测可能的候选翻译,这可能导致模型本身不正确且预测更不准确的现象,文献[37-38]的研究表明,最大似然训练可能是次优的。
强化学习近年来逐渐应用于交互式机器翻译中,而且强化学习天然地易于集成到交互式机器翻译过程中。强化学习和用户交互的结合也出现在其他领域,如在图像分割的模型训练任务IteR-MRL[39]中,作者引入用户交互来给分割模型较差的输出,指出有问题的点,然后将用户反馈用于更新模型参数。
文献[8]中提出了一种范式以结合神经机器翻译和强化学习,训练模式如图4 所示,作者使用Actor-Critic 算法来处理序列生成问题,给定一个Actor 网络的策略,Critic 网络用于根据历史输出的候选翻译生成一个新的候选翻译。这样就得到了一个更接近测试阶段的训练模型,并可以直接优化特定任务的得分,如 BLEU(BiLingual Evaluation Understudy)[40]。Critic 网络先通过监督学习方法进行预训练,随后在强化学习环境下作进一步训练,经过预训练的Critic 网络知道什么样的输出是好的输出,可以更好地指导Actor 的训练。这种先经过预训练再使用强化学习进一步训练的方法随后也在其他领域得到应用,文献[9]也是随后一些工作的基础,为强化学习与IMT 的结合提供了灵感。Actor网络的梯度为:

图4 将INMT建模成强化学习问题Fig.4 Modeling INMT to RL problem
考虑到获取翻译质量的评分比获取待翻译文本的目标翻译要更加容易,但由于评分者的评价标准各异、用户对翻译质量评价的任意性,往往导致翻译系统难以获取充足的反馈信号,文献[41]研究了不同类型的用户Bandit 反馈对使用强化学习进行训练的NMT 系统的可靠性等因素的影响,并探究了奖励反馈信号的质量对整个强化学习训练任务的影响。作者发现,通过精心选择反馈信号的形式,可以从非专业用户那里获得既快速又低成本的反馈信号,并且强化学习方法可以从少量可信度高的人类Bandit 反馈中进行学习,获得了非常可观的性能提升。文献[36]中提出了一种结合了Bandit 结构化预测的强化学习算法,它可以在INMT 系统中模拟人类用户对翻译质量的反馈,考虑到人类反馈信号的偏差、高方差、颗粒化差异等特点,通过对人类的反馈行为进行建模,并将该反馈信号作为系统奖励以训练翻译模型,进一步降低了训练翻译系统的成本。该算法结合了异步优势动作评价(Advantage Actor-Critic,A2C)算法[42]和基于注意力的神经Encoder-Decoder 架构,与文献[8]采用的方法类似,将NMT 系统建模成Actor 模型。
有些交互式机器翻译系统要求用户选择、纠正或删除候选翻译片段,以提供足够的反馈信号来进行模型训练,文献[43]中提出了一种交互式预测神经机器翻译的方法,在一个模拟环境中进行了实验,使用参考译文模仿翻译者,并通过在整个训练过程仅使用代理对部分翻译质量进行判断、设置反馈请求阈值(当候选翻译的熵达到该阈值后,触发反馈请求)以及每次交互后模型参数在线更新来减少用户的参与。模拟实验表明,与仅对完整翻译的反馈相比,对部分翻译的奖励信号明显提高了翻译性能,并且明显减少了用户代理的工作量。图5 为NMT 系统与用户的交互过程。

图5 NMT系统与用户的交互过程Fig.5 Interaction process between NMT system and user
文献[44]中通过减少反馈请求的数量和频繁的模型参数更新来减少用户的参与,利用强化学习和模仿学习进行训练,用户在交互式NMT 训练过程中,利用“保留”和“删除”等形式的弱反馈(用于强化学习训练),以及有限的以“替代”编辑形式的专家示范(用于模仿学习)形式反馈信息,NMT 系统通过限制集束搜索以得到可替代的翻译。
文献[45]中认为,不同类型的反馈对学习有不同的成本和影响,因此不同的监督信号的重要性也不同。在交互式神经机器翻译的实验中,自我调节器(Self-regulators)通过将各种不同的反馈信号混合到一起,包括纠正、错误标记和自我监督(对应了完全监督、弱监督和自监督学习),并将梯度形式统一化,根据不同的反馈类型计算对应的梯度,学习到了一个在成本和质量间进行折中的最佳策略,比从单一反馈类型学习的模型和基于不确定性的主动学习模型性价比更高,因为更多的反馈类型提高了模型的泛化能力。
文献[46]中提出,机器翻译等Seq2Seq 学习任务可以采用根据弱反馈进行训练的强化学习,作者提出的算法对TED演讲的英‒德翻译进行错误标注,可以实现精确的信用分配(Cridit Assignment),同时所需的人力明显少于纠正或者后期编辑,并且NMT 模型的微调都通过从错误修正和标记中学习提升了模型性能,但是错误标记所需的人工注释工作量则少了几个数量级。
基于置信度的交互式机器翻译可以有效地减少人工参与,在前人的工作中对CMs 进行了大量的研究,但仍只对翻译质量进行优化。针对这些缺陷,文献[47]中提出了一种新型的交互式机器翻译方法,使用Transformer 构建NMT 模型并进行预训练,通过使用改进的Actor-Critic 方法对NMT 系统进行训练,模型学会了预测何时应向用户请求反馈,同时对翻译质量和用户参与的成本进行了优化。该方法可以使用类似或更少的人工参与,在翻译质量上优于置信度基线。但与标准的NMT 模型相比,该方法的训练效率相对较低,因此改进训练效率需要进一步研究。
利用离线强化学习(Offline RL)使用静态的交互日志来学习一些帮助决策的策略是近年来新兴的领域,大量日志数据非常适于离线训练。用户与NLP 系统互动的大量日志中可能会隐含很多有用信息,文献[48]中将离线强化学习引入NLP 任务中,研究这些日志是否可以帮助改进NMT 系统的性能,结果发现NLP 任务在利用用户交互日志进行系统改进方面有很大的潜力,同时强化学习范式非常容易和交互式学习相结合。作者探讨了由于NLP 任务的性质和生产系统的限制出现的一系列的挑战,对这些挑战做了一个简明的概述,并讨论了可能的解决方案,为今后研究提供了思路。
结合强化学习的交互式神经机器翻译方法从另一个角度来看待翻译问题,利用了强化学习天然适合进行序贯决策问题从而尤其适合机器翻译的优点,而交互式学习协议在模型训练过程中引入了用户反馈,降低了强化学习训练的难度,大幅促进了交互式机器翻译的发展。
5 发展趋势和研究难点
相较于流行的端到端的机器翻译系统,交互式机器翻译的优点在于将Post-Editing 整合到翻译模型训练的过程中,可以结合部分的人工交互,达到较为满意的效果。交互式学习方式同时支持在用户使用翻译工具的过程中,收集用户反馈用于进一步提升模型的性能。交互式学习协议易于整合到机器翻译模型中,并容易和多种先进的技术相结合,从而使机器翻译模型达到非常好的性能,该领域具有广阔的应用前景;难点在于如何进一步降低人工交互的工作量,设计出更接近人类行为的用户代理,将用户代理作为人类反馈信号的替代,使整个交互过程尽可能高效,以及如何更好地利用人类译者的先验知识,使交互式机器翻译系统在真实世界中可以更好地利用反馈信号进行学习。
猜你喜欢
实用手外科杂志(2022年2期)2022-08-31
现代临床医学(2022年1期)2022-02-12
速读·下旬(2021年11期)2021-10-12
大东方(2019年12期)2019-10-20
科学与财富(2017年22期)2017-09-10
商情(2017年1期)2017-03-22
商用汽车(2016年11期)2016-12-19
商用汽车(2016年6期)2016-06-29
商用汽车(2016年4期)2016-05-09
Coco薇(2015年5期)2016-03-29
