
融合常识库和语法特征的数学应用题题意理解
2023-02-24 05:00:50刘清堂马鑫倩吴林静周鹏霄
计算机应用 2023年2期
刘清堂,马鑫倩,周 洁,吴林静,周鹏霄
(华中师范大学 人工智能教育学部,武汉 430079)
0 引言
数学题自动求解的难点在于数学问题的题意理解。从Bobrow 等[1]开发出最早的STUDENT 数学问题理解系统开始,越来越多的学者投入到题意理解的研究中来,但现有研究中大多围绕计算步骤简单的数学计算题或者题意清晰的应用题开展。在早期基于规则的逻辑关系模型基础上,不同学者将其创新性地转化为分类、实体识别等问题,通过引入机器学习方法实现数学问题的题意理解,常见的方法有最大熵模型(Maximum Entropy Model,MaxEnt)[2]、支持向量机(Support Vector Machine,SVM)[3-4]和条件随机场(Conditional Random Field,CRF)[5-6]等;但在对语义表述多变、求解规则复杂的应用题的题意理解方面的研究仍然存在方法不多、准确率低的问题,尤其是以古典概型题为代表的概率与统计问题是中高考的热点题型,它研究的是生活中的随机现象,与实际情境联系紧密,可作为突破机器题意理解的极佳的研究对象,且由于其情境复杂、参数较多等特征,很难利用已有方法自动抽取解题所需的信息来实现题意的较高准确率理解。
本文选择了初等数学古典概型应用题作为复杂语境的数学应用题题意理解的突破点,通过分析其文本特征和结构特征,构建了面向自动解题的古典概型应用题意表征模型;并根据古典概型应用题命题特点,提出了融合常识库和语法特征题意理解方法。首先通过两层语法特征识别层获得语法特征表示,然后将识别结果输入到CRF 层进行参数识别,最后通过常识参数补全模块得到最终的题意理解表征。本文中的语法特征是指词法特征、句法特征和边界特征的总称,常识库是指面向数学解题领域构建的情景和数学类常识库。以新东方在线网站和21 世纪教育在线题库中的948 道古典概型应用题为实验语料进行实验,实验结果表明,所提方法对古典概型类应用题题意理解具有显著成效。
1 相关研究
1.1 题意理解
人通过语言将其所要表述的“意思”传达出来,计算机通过理解语言中的问题所蕴含的“参数”实现人机的自动交互。当前自然语言处理领域题意理解的研究主要基于三种方法来开展:基于规则的方法[7]、基于统计的方法[8-9]和基于神经网络的方法[10-11]。题意理解是数学问题自动求解所面临的第一个问题,主要目标就是让计算机具有类人思维,从复杂的数学文本中提取出与解题相关的信息。对数学问题的题意理解方法研究,最早是Bobrow[1]开发的STUDENT 数学问题理解系统,基于关键词和句式匹配的方式建立逻辑关系模型,实现英文代数问题的题意理解。基于此,有学者探索并实现了对面向微积分应用题的CARPS(CAlculus Rate Problem Solve)题意理解系统[12]和面向基本概率问题的HAPPINESS 题意理解程序[13],此外还有文献[14-15]等。随着机器学习技术的发展,不同学者将题意理解创新性地转化为子模块优化、分类问题及实体识别问题等,通过引入不同的机器学习方法实现数学问题的题意理解。吴林静等[16]针对初等数学分层抽样问题提出了包含五种语义角色的题意表征框架,将题意理解问题转化为句子分类问题,设计了分层抽样问题的题意理解框架,此外还有部分学者[17-18]采用分类方法实现题意理解。吴宣乐[19]将句模理论和命名实体识别相结合构建了题意理解系统,实现了初等数学问题的题意理解。当前命名实体识别领域应用较为广泛的有MaxEnt[2]、隐马尔可夫模型(Hidden Markov Model,HMM)[20]、SVM[3-4]、CRF[21]等,其中CRF 因其能灵活引入多种特征、充分利用上下文信息,得到了学者的广泛关注,在军事[22]、医疗[23]、食品安全[24]、不同语言[25-27]等领域均取得了很好的效果。此外,对于复杂多变的数学问题也有学者尝试引入知识库以提升数学题意理解的效果:Wong 等[28]通过构建InfoMap 本体知识库设计了一个基于认知知识的数学应用题题意理解系统(Learner-initiating instruction model of geometry word problems,LIM-G);刘清堂等[29]通过构建常识库系统辅助题意理解。
综上所述,基于机器学习技术的题意理解方法逐渐成为主流,但通过对文献的深入分析,发现大部分研究都围绕计算步骤简单的数学计算题或者题意清晰的应用题开展,在对语义表述多变、求解规则复杂的应用题的题意理解方面的研究较少。有研究指出使用机器学习方法进行实体识别进行建模,若单纯考虑字词级别层面的特征可能会导致模型与数据产生过拟合的问题[30]。在词法特征的基础上增加句法特征分析可以增加词语间的长距离依赖能力[31-32],促进对复杂情景信息的理解。因此,本文拟探索引入词法特征、句法特征和边界特征等多种语法特征,引入机器学习模型,探索适合数学领域的题意理解方法。
1.2 常识库及应用
古典概型应用题是概率与统计领域的基本题型,命题信息大多来源于人们日常的生产实践活动以及生活经验等,题意表达涉及丰富的情境信息、数学专业知识等常识信息。人进行题意理解时,往往可根据所具备的日常经验对常识信息进行补全;但计算机在进行题意理解时,不具备这些对情境和数学知识具有完善作用的信息。因此,如何解决计算机对常识信息的自动识别与补全成为题意理解的重要研究问题。常识是一种来源于生活实际的重要的人类知识[33]。常识研究是自然语言处理领域的重要组成部分,Smith[39]将人们与常识世界的交互称之为自然认知,而在自然认知过程中使用的就是自然语言,因此,通过自然语言处理去进行常识的相关研究,不仅能促进常识的获取,也有助于自然语言理解和常识特点与结构的相关研究。
对常识的相关研究主要分为常识表示和常识库的构建两个方面,应用比较广泛的常识表示法有谓词逻辑表示法、产生式表示法、语义网络表示法以及框架表示法。围绕常识库的构建,国内外众多学者开展了相关研究,常见的常识库有Foxvog 等1984 年开始的构建以知识工程为基础的Cyc 常识库[40],该常识库采用人工方式通过谓词逻辑表示法表示常识知识;Liu 等在OMCS(Open Mind Common Sense)语料[34]基础上利用“常识抽取规则”自动构建的Concept Net 常识库[35]、普林斯顿大学Miller 等[41]基于同近义词词汇映射设计开发的WordNet 常识库。在中文领域应用最为广泛的是HowNet 常识库以及盘古常识库,其中盘古常识库采用基于本体的常识表征方式;HowNet 通过义原来表示词语之间的关系[36],即是采用框架表示法将词按照“词-义项-义原”三层结构来形式化表示。在本文中,初等数学古典概型应用题的常识被定义为常用于古典概型应用题中的、具有不确定性的、包含解题关键信息的隐性知识。根据解题的需要,在借鉴现有常识相关研究的基础上选择框架表示法的常识库构建方法辅助古典概型应用题题意理解。
2 古典概型应用题题意理解分析
2.1 文本特征分析
古典概型应用题是数学领域的一种重要题型,其题意表述具有数学语言的一般特征,同时也具有独特的特性。从题意信息的载体上来看,古典概型应用题的题意信息蕴含在一个个实体之中,想要完整准确地理解题意信息,只需将蕴含解题关键信息的实体信息抽取出来,利用各个实体之间的相互关系进行组合,即可实现古典概型应用题的题意表示与理解,如表1 所示为对古典概型应用题两种典型实例的分析。

表1 古典概型应用题典型实例Tab.1 Typical examples of classical probability word problem
要实现对上述应用题的问题求解,无论是计算机还是学习者都必须先识别题目中的关键信息。学习者求解上述应用题的难点在于选择合适的方法进行推理计算,对题目中已知信息的识别和常识信息的抽取则相对容易;而对于计算机则刚好相反,实现上述应用题自动求解的关键是实现题意的正确理解。面向计算机自动解题而言,古典概型应用题题意理解的难点主要有以下几个方面:
1)命名实体表现为典型长序列。相较于英文以空格作为分词界限,以大写字母作为人名、地名等命名实体的开头,中文文本没有显性的边界特征,而古典概型应用题文本更是存在典型的长序列特征,其中的实体可能由一个或多个词语共同组成,更是增加了其实体识别的难度。例如,“正四面体骰子”这一实体,其中“正四面体”“骰子”均为生活中常见的词语,但一般的骰子有6 个面,在这道题中将骰子限定为4 个面,因此,需要将“正四面体骰子”作为一个实体看待。
2)情景信息复杂。情境性较强是大部分数学问题所具有的特征,但古典概型应用题中除了干扰信息以外,其题干中的情境信息也隐含着有助于解题的信息,且存在明显的上下文情景依赖。例如,有一短句“现有一副扑克牌”,仅仅从字面表述上看,这一短句属于情境信息,与解题无关,但若后面紧接着“从中抽取一张牌,抽到红桃的概率”这一句话,则可以看出该情景信息中存在与解题相关的必要实体——“扑克牌”。因此在对古典概型应用题进行命名实体识别时,既要识别直观呈现的与解题相关的实体,又要排除干扰项,识别蕴含解题信息的情景实体。
3)蕴含大量常识信息。古典概型应用题来源于生活中的随机现象,题意表达蕴含着大量的常识知识,如“骰子、硬币”等,但其隐含的数据信息却不会呈现出来。因此如何实现计算机对常识知识的自动识别与补全是实现其题意理解的重要部分。
2.2 题意表征模型
本文提出的题意理解以自动解题为目的,即是从古典概型应用题文本中,识别并形成一个计算机能够理解的包含解题相关的关键参数及其数值信息的集合,这个集合中不仅要形式化地呈现古典概型题目的结构特征,同时也要包括各类结构中涉及的题意表述的关键参数。因此,根据古典概型应用题的文本及结构特征建模出其题意表征模型是研究的基础。
在对大量的古典概型应用题进行处理和分析的基础上,从解题的角度对古典概型应用题的结构特征进行分析,该题型具有两个鲜明特点:有限性和等可能性,即在古典概型中,所有可能出现的基本事件总数是有限的,并且每个事件出现的概率是相同的。根据古典概型求解规则进行反向思考,若要求解古典概型,需要识别并挖掘出整个实验中的基本事件参数及实验事件参数等信息。
1)基本事件描述,主要指定位基本事件的主体以及挖掘对应的数值信息,同时描述主体的属性,如“小球”是事件实体,“5”则是事件的数值信息,而“白色”“红色”则是主体的属性。一般而言,题目所求事件A 发生的概率都由主体属性引申而来,因此,事件主体的属性及其数量是问题求解的关键信息。
2)实验事件描述包括事件排序、抽取方式、抽取数量以及抽取次数等信息。在古典概型题目中,事件是否有序、有放回抽取还是无放回抽取、一次抽取多个还是多次抽取都会对事件A 发生的概率产生影响,从而影响最终题目求解的准确率。综上所述,本文设计了包含7 个关键解题参数的古典概型应用题意表征模型,如表2 所示。

表2 古典概型应用题意表征模型Tab.2 Representation model of classical probability word problem
如表2 所示如果能够识别基本事件及实验事件中的所有参数,然后将相关参数代入古典概型题的相关计算规则进行计算,可以实现从题意理解服务于自动解题。
3 融合常识库和语法特征的应用题题意理解
3.1 融合多维语法特征的CRF题意参数识别方法
通过对古典概型应用题的文本特征分析发现,其题意表述具有较强的上下文关联性和情景复杂性。因此,在对其进行题意参数识别时,需要采用能适应文本关联性和情景复杂性的机器学习模型。CRF 是由Lafferty 等[37]提出的一种无向图模型,能够灵活地引入多种特征,充分利用文本中的上下文信息获取标签序列,对整个观测序列进行全局归一化,求得全局最优解,符合古典概型应用题参数识别的需求。然而,有研究发现使用机器学习方法对数学领域实体识别进行建模,若单纯考虑字词级别层面的特征可能会导致模型与数据产生过拟合的问题[30]。在词法特征的基础上增加句法特征分析,可以增加词语间的长距离依赖能力[31-32],促进对复杂情景信息的理解。因此本研究设计了融合多维语法特征的CRF 参数识别方法,其中语法特征包含词法特征、句法特征和边界特征三个维度的特征。算法实现过程如图1 所示。

图1 融合多维语法特征的CRF题意参数识别模型Fig.1 CRF problem meaning parameter identification model integrating multi-dimensional grammatical features
在该模型中,首先通过分词工具确定分词和边界特征,通过词性特征表示层和句法分析层进行题目的词法特征识别和依存句法分析,以获得其词法和句法特征的识别和标注;然后将词法和句法特征识别结果输入到包含特征模板的CRF 模型中进行参数识别模型训练,通过不断调整特征模板及其窗口大小,训练出最佳的解题参数识别模型,实现古典概型题意参数识别。
3.1.1 特征选择
为保证对长序列及复杂情景信息的识别效果,本文提出的多维语法特征主要包含词法特征、句法特征和边界特征3个维度的6 个特征以辅助题意参数识别,具体如表3 所示。其中,词法特征4 类,除词特征、词法特征基础特征外,还引入数量词特征、专有名词特征增强对实体名称参数及数量参数的识别效果。句法特征采用依存句法对句子结构进行分析,通过分析句子所包含的句法单位和这些句法单位之间的依存关系来揭示其句法结构。边界特征使用常用的BMES标记模式对语料进行标记,以此作为边界特征,其中:标记B表示Begin,即当前词是某个实体的起始词;M 表示Middle,即识别出实体的中间名;E 表示End,即实体名的结束词;S指Single 表示独立成词。将6 种特征的识别序列作为输入,通过遍历组合特征选择方法选取最优的特征组合,进而完成题意参数识别。
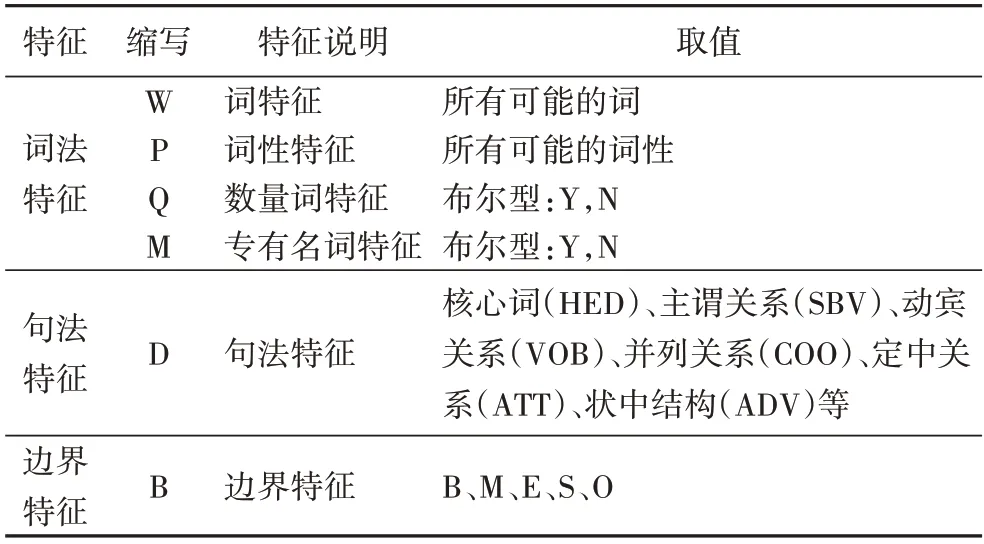
表3 古典概型题意参数识别的多维语法特征Tab.3 Multi-dimensional grammatical features of classical probability word problem meaning parameter identification
3.1.2 特征模板设计
相较于其他实体识别模型,CRF 模型的最大优势在于它可以有效利用上下文信息。对于古典概型应用题的关键参数识别,特征模板设计的关键在于对上下文信息的合理利用:过长使得数据会产生大量冗余,模型的可扩展性降低;过短则无法充分提取上下文信息,模型的识别精度降低。上下文信息的利用效率由窗口大小以及内部组合共同决定,常用的特征窗口大小为3 和5,常用的特征模板有原子特征模板和混合特征模板两类。
在上述6 种词句法特征的基础上,为保证CRF 模型对上下文信息的充分利用,本文分别为每一个特征构建了窗口大小为3 和5 的特征模板,并在每个模板中又分别进行了一元、二元、三元、四元以及五元特征的内部组合实验,以便为每个特征项选择最适合的窗口大小以及内部组合特征模板,特征模板设计如表4 所示,特征模板以%x[Row,Col]形式化表示,其中:%x 表示当前位置;Row 表示相对于当前位置的行偏移量,即字词的偏移量;Col 则表示列偏移量,即特征项的偏移量。如,%x[0,0]表示当前字词的第一个特征项,%x[-1,1]则表示当前词的上一个字词的第二个特征项。

表4 特征模板设计Tab.4 Design of feature template
在为每个特征选择最佳窗口及特征模板后,采用贪婪式特征选择方法选取最优的特征组合方案。为了对比不同的特征组合对各个标签中实体识别的贡献,本文以词特征(W)为基准线,在此基础上分别引入不同的特征及组合,通过比较分析实验结果,选取最优的特征组合,以提高古典概型题意参数识别的精度。
3.2 融合常识库和语法特征的应用题题意理解方法
上述融合多维语法特征的CRF 题意参数识别方法,虽然可以较好地识别题目中的显性参数,但是对于“掷骰子、抛硬币”和计算“点数为偶数”这类包含隐性的常识知识的题目,却无法准确识别其中隐含的关键常识参数信息。为完善对古典概型应用题中隐性参数的识别效果,本文进一步提出了融合常识库和语法特征的数学应用题题意理解方法。该方法在3.1 节融合多维语法特征的CRF 题意参数识别方法的基础上增加了参数补全模块,在引入构建的数学和情景类常识库基础上,通过常识识别和常识参数补全实现对隐性常识参数的补全,完善古典概型应用题题意参数识别。
3.2.1 常识库构建
通过对古典概型的文本分析发现,其包含的隐性常识信息可分为情景类常识和数学类常识两类,为保证常识库构建的质量,本文采用框架表示法将常识知识按照“词-义项-义原”三层结构来形式化表示,以XML(Extensible Markup Language)结构存储。对全部的古典概型应用题语料信息进行常识抽取,经过去重处理,共获得61 个常识;通过对涉及解题信息且文本中未对该信息进行描述的常识属性进行分析,根据题意理解需求,对获取的61 个常识分别进行描述,共获得28 条情景类常识和33 条数学类常识,其中情景类常识库和数学类常识库的部分信息,分别如表5、6 所示。

表5 面向古典概型应用题题意理解的情景类常识库(节选)Tab.5 Commonsense knowledge base of situation for understanding of classical probability word problems(part)

表6 面向古典概型应用题题意理解的数学类常识库(节选)Tab.6 Commonsense knowledge base of math for understanding of classical probability word problems(part)
3.2.2 题意识别方法改进
融合常识库和语法特征的数学应用题题意理解方法是对上述融合多维语法特征的CRF 题意参数识别方法的优化,将上述方法作为参数识别模块,并在此基础上增加“常识参数补全模块”优化并完善上述方法对隐性解题参数的识别。具体实现步骤如图2 所示。

图2 融合常识库和语法特征的古典概型应用题题意理解方法Fig.2 Classical probability word problem understanding method integrating commonsense knowledge base and grammatical features
在参数识别模块主要通过融合词句法特征的CRF 算法进行参数识别,然后对题意参数的识别结果进行判断,是否存在常识实体且常识参数缺失?若存在则检索构建的常识库,对缺失的常识参数进行补全,然后输出识别结果并将结果转化为XML 题意表征文本,为下一步的自动解题的实现提供解题数据。为了更直观地展现引入常识库的改进前后的题意参数识别结果的变化,以题目“同时抛掷两枚骰子,求点数之和为3 的概率”为例,改进前后的识别结果如图3 所示,从识别结果中明显可以看出,相较于融合多维语法特征的CRF 参数识别方法(如图3(a)所示),融合常识库和多维语法特征的改进CRF 题意参数识别方法(如图3(b)所示)通过引入常识库的参数补全模块,实现了对“骰子”隐性常识参数的识别与补全,如骰子的基本事物属性Inf 和属性事物数量Inf_num;并且调取数学类常识,修正了因“之和”这类数学类常识的缺失而导致的错误,显著提升题意理解的效果。
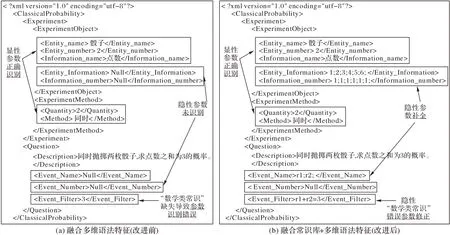
图3 改进前后的应用题题意理解结果对比Fig.3 Comparison of word problem understanding results before and after improvement
4 实验与分析
4.1 语料概述与评价指标
为验证方法的有效性,本文以新东方在线网站和21 世纪教育在线题库中的古典概型应用题为实验语料,删除含图表、题干不完整、重复以及无关题型后,最终得到948 道古典概型应用题。将实验语料按照7∶3 的比例划分为训练集和测试集,667 道作为训练数据,281 道作为测试数据。
实验采用CRF++0.58 工具包作为CRF 的实现工具,以HanLP 工具作为分词、词性标注及依存句法分析工具。对题意参数识别结果的评测借鉴了MUC 会议中信息抽取系统的相关测评标准,使用正确率(P)、召回率(R)和F1 值进行测评[38]。此外,本文中题意理解是为后续的自动解题服务的,单个的参数识别精度并不能完全说明题意理解的准确性,因此本文还引入了题意理解准确率(Val)[17]作为整题题意理解有效性的评价指标,其计算公式如下:
其中:N表示全部题目的个数,NR表示题意表征正确的题目个数。即通过分析题意识别的XML 表征结果,若XML 结构中能够完整而准确地呈现出解题所需要的关键参数,则认为该道古典概型应用题题意表征正确;若XML 结构中未将解题信息完整地表征出来,或者是将与解题无关的错误信息也进行了表征,造成题意表述的混乱,则认为题意表征错误。
每个题目的题意表征正确与否是通过人机协同的方式判断的,分为两个步骤:1)首先通过编程判断,排除核心参数如基本事物数量(Num)、基本事物属性名(Inf)、属性事物数量(Inf_num)、发生次数(Quan)、发生方式(Meth)识别不正确的题目。2)对于剩余题目的XML 表征结果进行人工判断,若XML 结构中能够完整而准确地呈现出解题所需要的关键参数,则认为该道古典概型应用题题意表征正确;若XML 结构中未将解题信息完整地表征出来,或者是将与解题无关的错误信息也进行了表征,造成题意表述的混乱,则认为题意表征错误。最后得出题意表征正确的题目个数NR。
4.2 实验结果与分析
4.2.1 题意参数识别
为保证在CRF 模型训练中可以最大限度地有效利用上下文信息,本文对选定词特征(W)、词性特征(P)、数量词特征(Q)、专有名词特征(M)、句法特征(D)和边界特征(B)这6个特征项(详见表3)分别进行了最优窗口大小及特征模板测试,其中词特征(W)是命名实体识别任务中最基本的特征,任何特征都需要与词特征进行组合以此实现实体识别任务。6 个特征项的最优窗口大小及特征模板测试结果的F1值如表7 所示,其中加粗的数据为该特征项所对应的最优窗口大小及特征模板,如词特征,当其特征模板是窗口大小为5 的一元模板时,取得最优识别结果,F1 值为0.894 3,其他特征项依此类推确定最优窗口大小及特征模板。

表7 词特征与其他特征组合的识别结果的F1值Tab.7 F1-scores of recognition results of combinations of word feature and other features
在确定了每个特征项的最优窗口大小和特征模板的基础上,本文对选定的6 个特征项(详见表3)的不同特征组合进行了CRF 模型训练。首先使用词特征(W)做基准实验,在此基础上使用贪婪式特征选择方法进行特征选择,即在上次特征基础上,与词性特征(P)、数量词特征(Q)、专有名词特征(M)、句法特征(D)、边界特征(B)5 个剩余特征进行组合,每次选择对评测结果提升贡献最大的特征,直到完成所有的特征组合为止。表8 为采用贪婪式特征选择方法时n个最优特征组合的实验结果。
表8 展示了不同特征组合对古典概型应用题意表征模型中的7 个核心参数的识别结果数据(具体参数标签对应的含义详见表2),可以看出,随着特征项的依次增加,该模型对题意参数的识别效果呈上升态势,且融合六种特征的W+P+B+Q+M+D 复合特征组合方案取得了最优识别结果,其平均7 个核心参数的平均F1 值为0.935 6。这也从侧面验证了本文提出的多维语法特征对古典概型题意参数识别的有效性。

表8 不同特征组合的识别结果的F1值Tab.8 F1-scores of recognition results of different feature combinations
为进一步验证融合多维语法特征的CRF 题意参数识别方法的有效性,本文选取了MaxEnt 模型、双向长短期记忆网络-条件随机场(Bidirectional Long Short-Term Memory-Conditional Random Field,BiLSTM-CRF)模型和传统CRF 模型作为基线方法,进行对比实验。其中MaxEnt模型并不做独立性假设且能够容纳较多的特征,在对上下文关系密切的古典概型应用题文本中比HMM 模型更为适用;BiLSTM-CRF 模型是命名实体识别领域中常用的神经网络模型,通过双向长短时记忆神经网络进行大规模语料的训练。在此使用题意表征模型中的各个题意参数(具体参数标签对应的含义详见表2)识别上的F1值作为模型评价指标,实验结果如表9所示。

表9 与基线方法识别结果的F1值对比Tab.9 Comparison of F1-score with baseline methods
从实验结果可以看出,融合多维语法特征的CRF 题意参数识别方法的平均F1 值比MaxEnt 模型高出23.97 个百分点,比BiLSTM-CRF 模型高出6.40 个百分点,比传统CRF 模型高出1.8 个百分点。分析其原因在于,MaxEnt 模型仅对语料中的每个词进行单独识别,上下文信息利用不充分;BiLSTM-CRF 模型未能从小规模语料库的训练中学习到充分的上下文信息,容易产生过拟合的问题;而融合多维语法特征的CRF 题意参数识别方法能够对计算语料序列化后的联合概率分布,充分地利用应用题文本中所提供的上下文信息,相较于神经网络模型,其在特定领域的较小语料库数据中依然能取得较好的题意参数识别效果,弥补了传统CRF 模型对句法上下文信息学习的不足。
4.2.2 题意理解
在面向自动解题的题意理解任务中,除各核心参数的独立识别率外,整题的题意表征正确率也是判断其题意理解效果的重要标准[17]。题意表征正确率用于衡量以整题为单位判断识别结果将解题信息完整的表征出来的概率。表10 是五种方法的题意理解准确率识别结果的对比,其中NR表示题意表征正确的题目个数,NW表示题意表征不正确的题目个数,Val表示题意理解准确率,根据式(1)计算得到。
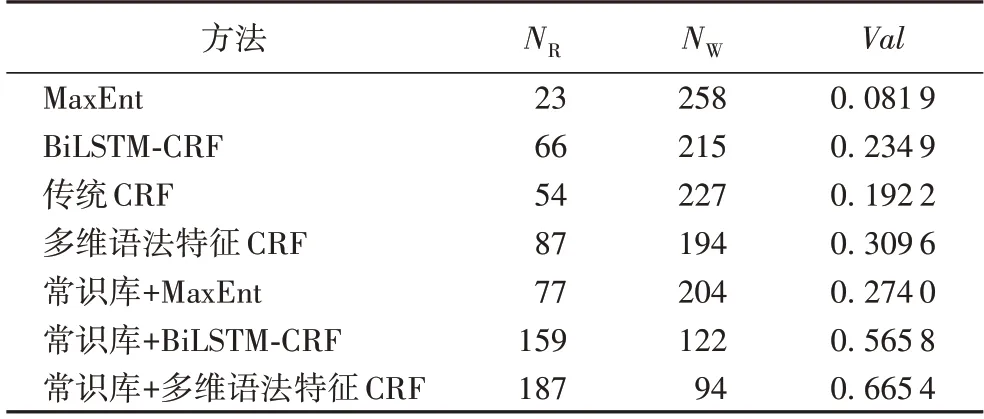
表10 与其他方法的应用题题意理解准确率对比Tab.10 Comparison of accuracy of word problem understanding with other methods
从实验结果来看,本文提出的融合常识库和语法特征的题意理解方法的整题题意表征正确率显著高于MaxEnt、BiLSTM-CRF、传统CRF 等方法。更有趣的是,本文发现传统CRF 模型虽然在单个参数的识别结果表现较好(F1 值为0.917 6),但是对于整题题意理解准确率却仅为0.199 2,整题的题意识别效果明显较低。分别对其表征结果XML 分析发现,传统CRF 明显存在参数缺失和参数混淆的问题,而多维语法特征CRF 模型在传统CRF 的基础上整合词法和句特征,显著改善了这类问题。这也进一步证明了本文提出的融合多维语法特征的CRF 题意参数识别方法的有效性。
对比融合多维语法特征CRF 方法在引入常识库补全模块前后的题意表征效果,可以发现题意理解准确率从30.96%上升到了66.54%,可以看出在融合多维语法特征的CRF 模型的基础上引入常识库,可以显著提升古典概型应用题的题意理解效果。除此之外,为了证明引入常识补全模块的有效性,本文还在MaxEnt、BiLSTM-CRF 两个基线方法的基础上,分别加入常识补全模块,发现引入常识库补全模块能显著提升题意理解准确率,其中,MaxEnt 模型题意理解准确 率Val值从8.19% 提升到了27.4%,BiLSTM-CRF 从23.49%提升到了56.58%。通过对题意理解XML 表征结果进行分析发现,大多数的古典概型题目均包含隐性的常识信息,仅采用融合多维语法特征的CRF 题意参数识别方法会造成隐性关键参数的缺失,造成题意表征不准确。而融合常识库和语法特征的题意理解方法可以在有效识别显性实体及属性参数的同时,对隐性参数进行补全,能够实现对复杂类数学问题的自动题意理解。
4.2.3 错误分析
虽然融合常识库和多维语法特征的题意理解方法可以实现对66.54%的题目的有效题意理解,但是仍有33.45%的题意理解出现问题。通过对未实现正确题意表征的题目分析发现,对于特殊的具有复杂关系的古典概型应用题仍存在题意理解困难。例如,“甲盒中有3 个红球,2 个黄球,乙盒中有2 个红球,4 个黄球。现从甲盒中取出1 个红球放入乙盒中,再从乙盒中抽取2 个小球,求抽得2 个黄球的概率”,在对这道题目进行题意表征时,只会对“甲盒”“乙盒”这一类实体的属性、数量等固定信息进行表征,并不能对“从甲盒中取出1 个红球放入乙盒中”这种动作信息进行表征,由此造成题意表征错误的情况。在后续的题意理解研究中针对这类问题可考虑引入知识图谱建模、探究其他特征选择等方法进行针对性的解决。
5 结语
本文以概率统计中的典型题型——古典概型应用题作为复杂语境的数学应用题题意理解的突破点,结合其命题和解题特征,构建了面向自动解题的古典概型应用题意表征模型。针对其存在的典型长序列、无明显边界特征、情景信息复杂、蕴含大量常识信息的特征,本文提出融合多维语法特征的题意理解方法,通过与MaxEnt 模型、BiLSTM-CRF 模型以及传统CRF 模型的对比,验证了该方法在题意参数识别中的有效性。在此基础上针对隐性常识参数缺失的问题,提出了融合常识库和多维语法特征的CRF 题意理解方法,将整道题的题意理解准确率从30.96%提升到了66.54%,并且显著高于MaxEnt 模型、BiLSTM-CRF 模型以及传统CRF 模型的整题题意表征效果,在面向自动解题的古典概型应用题题意理解效果中取得了明显成效,为后续复杂数学问题的题意理解研究提供借鉴。但是现有研究中针对特殊的具有复杂关系的古典概型应用题的题意理解仍存在题意理解困难,未来研究中可考虑采用知识图谱等方法进行针对性的解决。
猜你喜欢
中学生数理化·七年级数学人教版(2023年11期)2023-12-26 08:05:02
小学生学习指导(低年级)(2023年10期)2023-10-28 06:34:46
中学生数理化·高三版(2023年3期)2023-03-17 16:14:51
中学生数理化·高一版(2021年3期)2021-06-09 06:10:12
数学小灵通(1-2年级)(2020年11期)2020-12-28 00:41:30
文苑(2020年11期)2020-11-19 11:45:11
中学生数理化·高一版(2019年3期)2019-04-15 00:30:40
中学生数理化(高中版.高考数学)(2018年12期)2019-01-17 01:32:04
新世纪智能(数学备考)(2018年9期)2018-11-08 11:07:34
中国眼镜科技杂志(2017年10期)2017-07-10 09:17:56
