
异源虹膜块状特征相似性统计
2023-02-21 13:17张翌阳唐云祁陈子龙
刑事技术 2023年1期
张翌阳,唐云祁,陈子龙,苗 迪
(1.中国人民公安大学侦查学院,北京 100038;2.公安部鉴定中心,北京 100038;3.北京中科虹霸科技有限公司,北京 100190)
近年来,虹膜识别在国内外公共安全领域应用广泛。由于虹膜表面纹理特征丰富,且这些纹理特征终生不变,人各不同,同时虹膜位于人眼内部的特殊位置也很难伪造,所以虹膜已经成为继指纹、人脸、DNA后又一广泛应用于公安机关核验人员身份的生物识别技术[1]。虹膜识别的精度高,比对速度快,非接触式采集并且不易伪造,同时也特别适合用于大规模人群的身份识别[2]。在虹膜识别技术成熟应用于身份识别后,随之而来的问题是虹膜识别的结果无法直接作为证据应用于司法审判。虹膜从最基础的用于身份识别到作为证据应用于司法审判,两者之间仍然缺少虹膜鉴定这一重要环节。
目前,公安机关使用各种人体生物特征进行身份识别,而对于指纹、DNA、人脸等生物特征的检验鉴定也已取得了一定成果。其中指纹是在已有的人工鉴定方法[3-5]基础上,研究开发出了指纹自动识别系统,而虹膜则是自动识别技术发展在前,鉴定方法的研究相对滞后。虹膜识别技术与虹膜鉴定研究是两个不同的问题,虹膜识别技术是典型的模式识别和计算机视觉问题,识别过程中将虹膜特征以编码形式进行匹配,这种特征编码不需要具备实际的物理意义,因此尽管虹膜识别的精度非常高,但得到的结果无法直接用作鉴定结论,难以在法庭审判过程中发挥作用。虹膜鉴定是通过对两幅虹膜图像进行鉴别,寻找其中能够被人们所认识的特征,最后通过综合分析,判断两幅虹膜图片是否来源同一。虽然全国各地公安机关现已开始了虹膜采集工作,虹膜识别在公安领域的应用也越来越广泛,但虹膜鉴定的方法研究还相对滞后。相比于指纹和DNA成熟、系统的鉴定方法,虹膜的鉴定方法还有待进一步完善。
虹膜鉴定方法研究的难点有两个:第一是选择什么特征作为虹膜鉴定的依据,这个问题是虹膜鉴定的基础,需要对虹膜上所有纹理有总体的认识,从而将不同特征按照各自的特点进行分类;第二是虹膜鉴定特征数量的确定,当前法庭科学领域的发展趋势,对于检验鉴定的要求愈发严格,特征数量问题不能仅凭经验找到一定数量符合的特征点即可认定同一,而是要在此基础之上从客观角度出发,给出相应的统计概率作为证据解释。目前在虹膜鉴定方法的研究中围绕这两个难点,将虹膜上的特征分为了块状特征、线状特征和环状特征三类[6]。受限于当前标准下虹膜图像清晰度的限制,线状特征和块状特征会更加清晰和稳定,本文对类间虹膜块状特征相似性进行统计,首先利用Tophat算法提取虹膜上的块状特征, 然后用Hu矩特征和位置坐标信息两个参数描述块状特征的相似度,最后使用计算机算法对不同虹膜上提取到的块状特征进行两两比较,统计异源虹膜上块状特征的相似情况。本文希望找到一种方法,能从概率论的角度解释虹膜鉴定过程中多少个特征点相吻合即可认定同一。
1 研究现状
虹膜识别从上世纪90年代就已经开始兴起,1993年,Daugman博士[7]研究出基于Gabor变换的虹膜识别算法,使虹膜识别技术有了突破性的进展。在国内,1998年底中科院自动化所谭铁牛博士[8]开始进行虹膜识别方面的研究,2000年成功开发出具有我国自主知识产权的虹膜识别系统,填补了国内空白。目前虹膜识别技术的发展已经非常成熟,虹膜识别技术在世界上已有很多成功的应用案例,如印度的Aadhaar计划和阿联酋的出入境虹膜识别系统等[9-10]。
对于虹膜鉴定方法的研究,公安部鉴定中心以国家重点研发项目为依托,以理论研究和计算机辅助软件两方面研究作为切入点,在该领域开展了深入的研究。在理论研究方面,结合眼解剖学和虹膜基础理论,将虹膜特征分为放射状沟线、向心沟、卷缩轮、隐窝和色素点五大类型[11],并对虹膜图像特征的提取和分析方法进行了研究,解决了虹膜图像的人工特征选取和标注问题。但对于特征点数量问题方面的研究仍有待进一步推进。若要从概率论的角度来解释特征点数量问题,需要统计大量的虹膜上各种特征出现情况,通过人工统计的方式工作量太过庞大,而且由于虹膜纹理特征形状的随机性,肉眼观察也会产生很大误差,这就需要用到计算机算法来自动提取虹膜特征并进行自动统计。
首先要解决的问题是如何从大量虹膜图像中有效、准确提取到纹理特征。Shen等[12-14]通过实验证实了虹膜隐窝特征作为虹膜识别特征的有效性,并设计了基于虹膜隐窝特征的虹膜识别算法,算法中使用Tophat对隐窝特征进行处理后,能够自动勾画虹膜隐窝轮廓,准确地将虹膜隐窝特征提取出来。Tophat算法经常被用来分离比邻近点亮的一些斑块,在一幅图像具有大幅背景,而微小物体比较有规律的情况下可以使用。彭博等[15]利用Tophat算法来增强医学超声图像的局部对比度,在保证特征细节不丢失的情况下有效抑制了背景噪声。虹膜图像和医学超声图像都是灰度图像,在特征细节上虹膜块状特征和超声图像上的特征也有着相似之处。朱成军等[16]使用Tophat滤波对车牌进行处理,将车牌号码突出出来,有效提高车牌的识别率。段建民等[17]则利用Tophat滤波处理的方式,抑制路面上车道线以外的大多数背景物体,大大提高车道检测的准确程度。根据Tophat算法的特点,刚好可以用来对虹膜上的背景噪声进行抑制,突出虹膜块状特征并进行分割。
其次要解决的问题是虹膜块状特征的形状用什么方式描述。Hu矩一般用来识别图像中大的物体,能较好地描述物体的形状,但图像的纹理特征不能太过复杂。商立丽等[18]提出了一种基于全局Hu矩和局部TF-KSURF特征的青铜器铭文相似性度量方法,用Hu矩特征准确地描述了青铜器上铭文的形状,提高了铭文的检索性能。曹鹏辉等[19]提出了一种基于光谱降维与Hu矩的壁画颜料层脱落区域的提取方法,文中使用了Hu矩特征对壁画中颜料脱落区域的形状进行描述并二次分类,提高了壁画颜料层脱落区域的提取精度。可以看到,Hu矩特征经常用于描述青铜器铭文和壁画颜料脱落区域这种小斑块的形状。因此本文选择使用Hu矩特征值对经过Tophat处理过的虹膜块状特征进行描述,以实现对虹膜图像中的块状特征进行自动提取和自动统计。
2 异源虹膜块状特征相似性统计方法
由于虹膜的生理结构,可以将其近似看成同心的圆环,随着瞳孔的放大和缩小,虹膜上的各种特征也随之变化,因此需要将虹膜图像进行归一化处理后再进行后续的实验。得到归一化图像后首先对图像进行Tophat处理,再通过计算连通域的方式将虹膜图像上的块状特征提取出来,然后记录每个特征的位置信息和Hu矩特征,最后把所有虹膜图像上的块状特征进行两两比较,统计不同虹膜上出现位置相同且形状相似的块状特征的情况。本文提出的异源虹膜块状特征相似性统计方法示意图如图1。

图1 统计方法示意图Fig.1 Schematic for statistical method utilized with this paper
2.1 块状特征的自动提取算法
2.1.1 虹膜图像预处理
一张虹膜原始图像中除了有用的虹膜纹理信息外,还包含瞳孔、巩膜、睫毛以及上下眼皮等无用信息。另外,由于瞳孔在不同光照条件下的缩放,虹膜的各类纹理特征也会随之产生变化。因此在提取块状特征前需要对虹膜原始图像进行预处理,本文的预处理过程包括虹膜图像归一化处理、直方图均衡化及反色操作。
虹膜归一化操作是以瞳孔中心为基准点,沿虹膜内外边界同心圆的径向方向,将圆环状虹膜纹理区域展开成矩形的归一化区域。虹膜内外边界均为圆形,以瞳孔圆心为起点,与虹膜内外边界的交点坐 标 分别 为(xi(θ),yi(θ))和(xo(θ),yo(θ)),则 利 用下式可将虹膜原图像中的每一个点一一映射到极坐标(r,θ)中[20-21]。
虹膜归一化能够很好地将每幅虹膜图像调整为同一尺寸,在最大程度上去除无用信息的干扰,从而消除平移、缩放、旋转对虹膜纹理的影响。现行公安标准虹膜原图分辨率为640×480像素,在进行归一化操作后,得到虹膜归一化图分辨率为540×70像素,如图2。
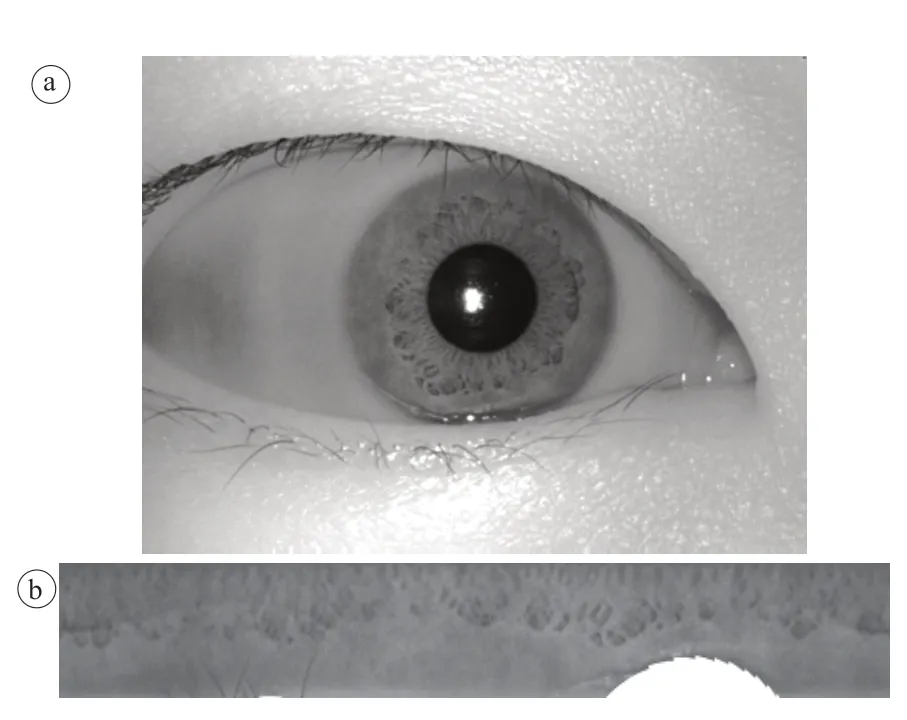
图2 虹膜原图(a)和归一化图(b)Fig.2 Original iris image (a) and its normalized version (b)
对虹膜归一化图进行直方图均衡化操作,以消除光照等因素对虹膜块状特征分割的影响,进而保障了虹膜块状特征分割结果的稳定。直方图均衡化是一种易于操作且效果明显的图像增强方法,通过改变图像的直方图来调整图像中各像素的灰度,能够有效增强图像的对比度。
直方图均衡化的基本原理就是将图像中对画面起主要作用的灰度值进行展宽,对画面不起主要作用的灰度值进行归并,增大图像对比度,使图像更加清晰。虹膜归一化图像由于其灰度分布集中在较窄的区间,图像不够清晰,直方图均衡化能把归一化图像的直方图变换为均匀分布的形式,从而增强图像整体对比度,更加突出虹膜块状特征,如图3。

图3 直方图均衡化效果图Fig.3 The effect image after histogram equalization
虹膜原图经过归一化和直方图均衡化处理后,还需要进行反色处理,如图4。这是由于在归一化图像中,块状特征的颜色深于虹膜的背景,经过反色处理后,虹膜块状特征的灰度会明显高于其邻域,以便后续使用Tophat算法对块状特征进行提取。

图4 反色效果图Fig.4 Reverse color handling into the effect image from histogram equalization
2.1.2 基于Tophat算法的块状特征分割
Tophat算法[17]实际上是原图像与开运算的结果图之差,开运算就是先腐蚀后膨胀的过程。设输入图像为f(x,y),内核为b(x,y),则Tophat算法表达式为
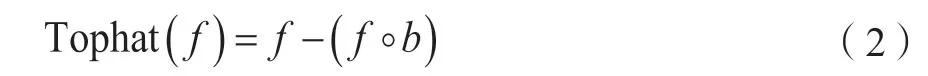
式中符号“。”表示内核b(x,y)对图像f(x,y)的开运算,将该运算继续展开

式中符号“ ”表示结构元素b(x,y)对图像f(x,y)的腐蚀;符号“”表示b(x,y)对图像f(x,y)的膨胀。其中,腐蚀和膨胀运算定义如下:

式中符号“”与“”分别为逻辑与、或运算。实际上,膨胀操作就是将图像f(x,y)与核b(x,y)进行卷积,腐蚀是膨胀的逆运算。
对虹膜归一化图进行开运算可以将归一化图中的纹理放大,从原图中减去开运算后的图像,此过程突出了虹膜归一化图上的纹理特征,最后通过简单的连通域计算,将面积与形状符合条件的块状特征分割出来。
2.2 块状特征相似度计算方法
在虹膜鉴定过程中,对两个特征相似的界定有两个方面:一是特征的位置相同,二是特征的形状相似。
2.2.1 虹膜块状特征的位置
同一虹膜两次采集的图像在进行归一化处理后,块状特征的绝对位置信息可能会发生改变。这是由于在采集虹膜图像的过程中头部发生了旋转,这种变化会使采集到的虹膜旋转3°左右,块状特征在归一化图上的位置也会发生相应变化,如图5。在实验过程中,每个块状特征的位置信息以质心坐标(x,y)的形式记录下来,采用欧氏距离来计算两个特征位置之间的相似程度。

图5 采集时头部旋转对虹膜归一化图上虹膜位置的影响(a:同一虹膜两次采集的图像;b:因头部旋转虹膜上的特征位置发生偏移)Fig.5 Effect of head turning on iris positioning into its normalization map during acquisition (a: two images collected of the same iris; b:iris feature position offset from head turning)
2.2.2 基于Hu矩的块状特征形状信息
虹膜鉴定过程中,虹膜特征的形状如何去定义是一个很重要的问题。经过Tophat处理后的虹膜归一化图,将虹膜块状特征提取出来,仅保留了轮廓形状,这样更有利于后续对特征形状的描述。Hu矩算法是由Hu于1962年提出并证明它们具有旋转、缩放和平移不变性,能够较好描述目标的整体轮廓结构特征,被广泛应用于图像识别领域[22]。
在空间坐标系(x,y)中,设一幅虹膜块状特征图像f(x,y),其(p+q)阶矩定义为:
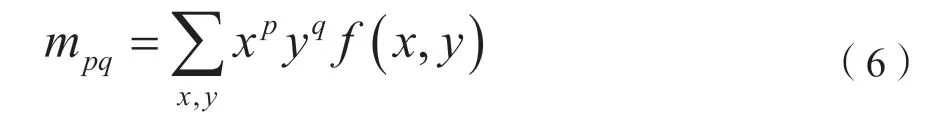
中心距定义为:

式中,p,q=0, 1, 2, 3…,N和M分别是图像的高度和宽度;中心距μpq保持位移不变性,矩心(x,y,代表质心位置,矩心计算公式为

由此得到虹膜块状特征的Hu矩特征向量为

将所有块状特征的Hu矩值计算出来后,发现Hu矩值的范围很大,有些无法直接进行比较,因此需要先进行式(10)中的对数变换再进行比较。
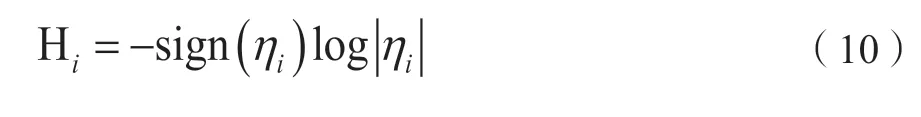
通过式(11)来计算两个特征之间形状的相似程度。

2.3 块状特征相似阈值的调整方法
虹膜鉴定过程当中,由于虹膜纹理特征完全是随机出现,形状也是随机形成的,所以两个块状特征的相似认定实际上是非常复杂的。在从位置和形状两个角度对块状特征之间相似的定义过程中,对认定相似的参数需要进行调整,以达到最接近实际情况的效果。以下两个实验可以对参数的调整提供参考。对于块状特征的位置特征,由于块状特征位置会因为图像采集过程中头部的旋转而产生横向偏差,在归一化操作时也会因为内外圆自动提取的不准确而产生纵向偏差。头部旋转导致的虹膜图像旋转在3°左右,因此结合虹膜图像归一化过程的特点,在分辨率为540×70像素的归一化图像上,只要两个特征之间的欧氏距离小于等于3×540÷360,即小于等于4.5,就认为两个特征的位置相同。此距离大小的选择在不同分辨率的归一化图像上略有不同。对于块状特征的形状特征,需要经过多次的实验,选取同一只眼睛多次拍摄的虹膜图像上的同一块状特征,计算并比较它们的Hu矩特征值,找到类内块状特征Hu矩值之间的差距。本文通过选取4个来自于同一虹膜4次采集的4张虹膜图像上同一个清晰稳定的块状特征A、B、C、D(图6),比较它们的Hu矩值(表1~2),以此作为参考,调整本文实验中认定类间块状特征形状相似的阈值。

表1 类内块状特征Hu矩特征值对比Table 1 Comparison among the intra-class block-shaped characteristic Hu-moment values

图6 类内块状特征示例Fig.6 Examples of the intra-class block-shaped features
从表1和表2明显可以看到,类内块状特征之间Hu矩特征值相似度d差距均小于7,越小说明特征之间的形状越接近。根据经验,类间虹膜块状特征的Hu矩特征值差距明显大于类内的差距。

表2 各块状特征之间Hu矩相似度d的值Table 2 The d values of Hu-moment similarity between blockshaped features
3 实验与结果分析
实验的操作系统是Windows 10(64位),CPU为英特尔Corei7-10750H,内存16 GB,GPU为GTX1660Ti,软件平台采用MATLAB2018b。依据现在公安实战中对虹膜图像的规格要求,共选取来自全国不同地区的952枚分辨率为640×480像素的清晰虹膜图像。本实验所用虹膜数据库由公安部鉴定中心和北京中科虹霸科技有限公司提供。
3.1 不同内核对块状特征提取结果的影响
本文针对虹膜块状特征进行分割,为了更准确地分割块状特征,尽可能多地消除块状特征以外的信息,结合以前对块状特征的研究,对内核的形状和大小进行反复实验。图7为不同形状和大小的内核对Tophat处理虹膜归一化图的效果。发现当使用矩形内核时,块状特征的边缘会损失掉一部分;使用圆盘形内核时如果半径过小,有一些形状复杂的块状特征会被拆成多个小的斑块,而半径过大则不能很好地过滤背景噪声,相邻很近的几个块状特征可能会被融合为一个块状特征。最终经过多次尝试,当使用半径大小为9的圆盘形核时,对于虹膜上的块状特征的腐蚀最为准确。这主要是由于块状特征的形状多为类椭圆形,在分辨率为540×70像素的归一化图中,块状特征的大小为50~500像素不等。这样经过与内核卷积,虹膜上的块状特征被较为完整地保留下来,而一些线状特征则被很好地过滤掉,最后再通过面积和形状的限定,将符合条件的块状特征分割出来。

图7 不同形状内核提取的效果对比(a:虹膜归一化图;b:边长为9的矩形核处理效果图;c:半径大小为3的圆盘形核处理效果图;d:半径大小为9的圆盘形核处理效果图;e:半径大小为15的圆盘形核处理效果图)Fig.7 Extraction effects of shape-different cores (a: normalized iris image; b: effect from processing with side-length-of-9 rectangular core;c: effect from processing with radius-of-3 disc-form core; d: effect from processing with radius-of-9 disc-form core; e: effect from processing with radius-of-15 disc-form core)
3.2 不同阈值对实验结果的影响
实验过程中虹膜块状特征相似需要调整两个阈值,一个是位置相同的阈值,另一个是形状相似的阈值。本文中使用欧式距离对块状特征的位置相似进行度量,但实际实验过程中发现并不是两个斑块位置坐标的欧氏距离越小,得到的实验结果越接近实际。认定两个块状特征位置相同时,它们位置坐标的欧氏距离需要考虑到归一化图的分辨率大小,由此设定一个合适的值,本文实验中设置的值为4.5。如果这个值设置得过小,将会漏掉一些采集虹膜过程中产生偏差的块状特征,使得最后得到的统计结果小于实际值。
块状特征形状相似的阈值本文实验设置为7,因为在实验过程中发现类内块状特征之间的相似程度d都在7左右。理论上,d的值越小,块状特征之间的相似程度便越接近,但由于采集虹膜时的光照、角度等外界因素的影响,同一虹膜上的同一块状特征,在多次采集的虹膜图像上也会呈现出不完全一致的形状。如果阈值设置过小,将会人为过滤掉一部分形状相似的块状特征,也会使统计结果小于实际值。
3.3 关于虹膜块状特征相似性统计结果的分析
本文实验从952枚虹膜图像中提取出7 041个块状特征,不同虹膜图像上的每个块状特征之间两两比对,记录每一对相似的块状特征,再计算得出不同虹膜上相同位置出现相似虹膜块状特征的频率。在952枚的虹膜库中,实验得出满足位置和Hu矩特征值均相似的块状特征22 443对。
经计算,952枚异源虹膜之间进行两两比对,共比对452 676次,其中两枚不同虹膜上出现1个块状特征相似的情况19 811次,出现2个块状特征相似的情况2 418次,出现3个块状特征相似的情况198次,出现4个块状特征相似的情况16次。此时两枚不同虹膜上出现1个块状特征相似的比率为4.38%,2个块状特征相似的比率为0.534%,3个块状特征相似的比率为0.043 7%,4个块状特征相似的比率为0.003 53%。如表3,出现比率=出现次数÷452 676。

表3 虹膜块状特征相似性实验统计结果Table 3 Statistics about appearing similar block-shaped iris feature on two different irises
根据大数定律,在试验不变的条件下,重复试验多次,随机事件的频率近似于它的概率。由于本实验中数据库的大小有限,实验结果中没有出现5个以上块状特征相似的情况,并且以上几种情况的频率还并不能准确接近于它的概率。但当数据库达到一定规模后,其频率就将近似等于它的概率。在今后继续扩充数据库的过程中,可能还会有5个、6个甚至更多块状特征相似的情况,所对应的概率也可以据此方法计算出来。
4 结论
本文对异源虹膜块状特征相似性进行统计,提出利用Tophat算法对虹膜图像进行处理。根据块状特征的特点优化内核的形状,减少背景噪声,并成功提取到了虹膜块状特征;在统计不同虹膜上相同位置出现的形状相似的块状特征时,采用Hu矩特征来对块状特征的形状进行描述,通过实验探究了块状特征相似的阈值调整方法。本文使用计算机算法对异源虹膜块状特征相似性进行统计,得到了两枚不同虹膜上出现1~4个相似的块状特征时各自所对应的频率,在今后的研究中,还可以针对虹膜上其他特征进行类似的统计。
解决鉴定过程中认定同一的特征数量问题,不能仅凭经验,人为地通过设置阈值制定鉴定标准,要以科学的方法为依据,给出客观、可信的标准。本文运用算法自动提取块状特征,在提出虹膜块状特征相似性度量方法的基础上,统计块状特征的出现情况,计算出两枚虹膜上出现不同数量相似的块状特征时对应的频率,运用科学统计的方法给出设置不同数量的块状特征作为同一认定标准时所对应的概率。该方法可用于计算大规模虹膜数据集下异源虹膜间出现不同数量相似块状特征的概率,为解决鉴定过程中需要多少个特征相同才能认定同一的问题奠定基础,对虹膜鉴定的研究具有重要的意义。
猜你喜欢
中学生天地(A版)(2022年11期)2022-11-25
中国典型病例大全(2022年11期)2022-05-13
新世纪智能(英语备考)(2018年11期)2018-12-29
文萃报·周二版(2018年51期)2018-08-04
中国神经再生研究(英文版)(2017年4期)2017-01-12
小学生学习指导(低年级)(2016年10期)2016-12-01
当代化工研究(2016年7期)2016-03-20
电子设计工程(2015年8期)2015-02-27
电视技术(2014年19期)2014-03-11
无机化学学报(2014年4期)2014-02-28
