
基于改进编解码器和情感词典的对话生成模型
2023-02-21 12:54张顺香朱广丽李晓庆魏苏波
计算机工程与设计 2023年2期
张顺香,李 健,朱广丽,李晓庆,魏苏波
(1.安徽理工大学 计算机科学与工程学院,安徽 淮南 232001; 2.合肥综合性国家科学中心 人工智能研究院,安徽 合肥 230000)
0 引 言
情感对话模型是人工智能领域的一个重要研究方向,可以在各种社交场景下进行不限定主题的人机交互,通过主动识别用户情绪,生成符合逻辑和语境的人性化回复。现有的对话生成模型主要是结合深度学习技术,实现符合上下文逻辑的人机对话过程。这种数据驱动的对话系统着重关注建立查询和回复之间的语义对应关系,生成的回复语句缺乏情感共鸣,拟人效果不够理想,不能很好地适应和模拟真实的对话场景,构建情感拟人程度更高的对话模型已经成为一种趋势[1]。文本情感分析是机器主动识别用户情绪的重要途径,基于规则的方法利用词汇字典来判断句子的情感,利用设定的规则对语句进行分词和情感值计算,内容丰富的情感词典可以获得较好的情感分析效果[2,3]。而情感的表征和生成对语句所蕴含的意义是至关重要的,也是保证情感对话过程一致性和相容性的基础。
基于上述问题,本文提出一种基于改进编解码器和情感词典的对话生成模型,可以根据不同的情感特征生成相应的拟人回复。相对于传统的对话生成模型,其创新之处在于构建AgSeq2Seq模型和情感词典,能更好地识别情感语句和自然语句,并结合情绪对比机制和目标语句概率生成回复。识别输入语句的情绪特征并计算回复语句的情感值,使得对话过程产生的情绪信息进行了有效对比,从而实现了拟人程度更高的情感对话过程。
1 相关工作
Mikio Nakano等[4]构建了一种封闭域聊天对话系统的框架HRIChat,可以很好地处理特定领域的话语。Kengo Ohta等[5]提出了一种基于LSTM的响应类型选择器,并结合多个解码器进行多任务学习,使回复语句更加自然,有效避免了枯燥对话。曹东岩[6]通过定义对话的奖励函数,提出了一种基于强化学习的对话生成算法,在回复多样性和对话轮数上相比传统Seq2Seq模型均有所提升。Ling Yanxiang等[7]提出了一种上下文控制的主题感知神经响应生成模型(CCTA),有效地利用了相关话题信息来提高回答信息量,同时通过语境控制过滤干扰话题词中的噪声,进一步保证了回答的连贯性和恰当性。吴威震[8]提出了一种由注意力机制、集束搜索算法、BiLSTM与传统Seq2Seq模型相结合得到的聊天机器人对话模型,其效果优于传统Seq2Seq模型。Wang Hao等[9]利用知识增强型神经模型建立信息丰富的逻辑对话系统,可以深入理解对话背景,从而产生更多信息和逻辑反应。
栗梦媛[10]提出了一种基于情感的端到端对话生成模型,添加情感分类器生成对应情绪的回答,并在预测阶段结合多样化集束搜索方法,使生成的回复更加生动合理。Liu Mengjuan等[11]在CVAE模型的基础上提出了改进,使对话系统能产生更多情绪化、情境化和多样性反应。蒋承霖[12]提出了一种基于深度学习的情感对话生成系统,对对话中的情感关系进行学习和建模,使其具备自适应的情绪感知和表达能力。杨丰瑞等[13]提出了一种融合主题信息和情感因素的主题扩展情感对话生成模型,能生成内容丰富且情感相关的回答。Zhang Shunxiang等[14]提出了一种基于情感词典的中文文本情感分析方法,通过构建6种情感词典并提供了情感值的计算方式,能够准确、有效分析文本情感。刘婷婷等[15]对人机交互过程中用户情绪的识别方法进行了梳理,通过用户输入的文本和语音信息来感知、分析用户的情绪状态,归纳了情绪识别中的一些机器学习方法。Zhang Shunxiang等[16]提出了一种基于关键句的情感分类模型SC-CMC-KS,通过设计多个规则获得句子级的情感值,对情感倾向的判断准确率显著提高。
综上所述,本文提出一种基于改进编解码器、情感词典及情绪对比机制的对话生成模型。利用一个嵌入关注门控的AgSeq2Seq模型训练语料数据集,这里是实现高质量人机交互的关键步骤。关注门控通过特征提取方式,一方面增强对情感语句的关注,另一方面限制自然语句带来的噪音等不利因素。利用情感词典获得的情绪注意值可以与解码器生成的目标语句相结合,以拼接方式生成情绪回复。
2 本文模型
提出的基于改进编解码器和情感词典的对话生成模型,其底层的AgSeq2Seq模型由编码器、解码器和关注门控组成。考虑到对话数据集中大量的自然语句容易训练出“无情绪回复”,同时统计机器学习方法的性质也决定了解码器在生成响应时,训练集中的高频词、高频搭配更容易被选择,所以本文在Attention机制的基础上增加了一个关注门控,负责情绪特征和全局特征的提取,在训练过程中对自然语句进行权重限制,从而有效降低其产生的噪音影响,同时从情感语句中获得一个情绪注意值,可以与解码器生成的目标输出进行拼接后生成情绪回复。另外,构建多样化的情感词典分析对话过程中产生的情绪特征,同时结合语义规则对所有可能的回复语句进行情感值计算,最后与输入语句进行情绪对比,生成符合当前语境的拟人回复。基于改进编解码器和情感词典的对话生成模型框架如图1所示。
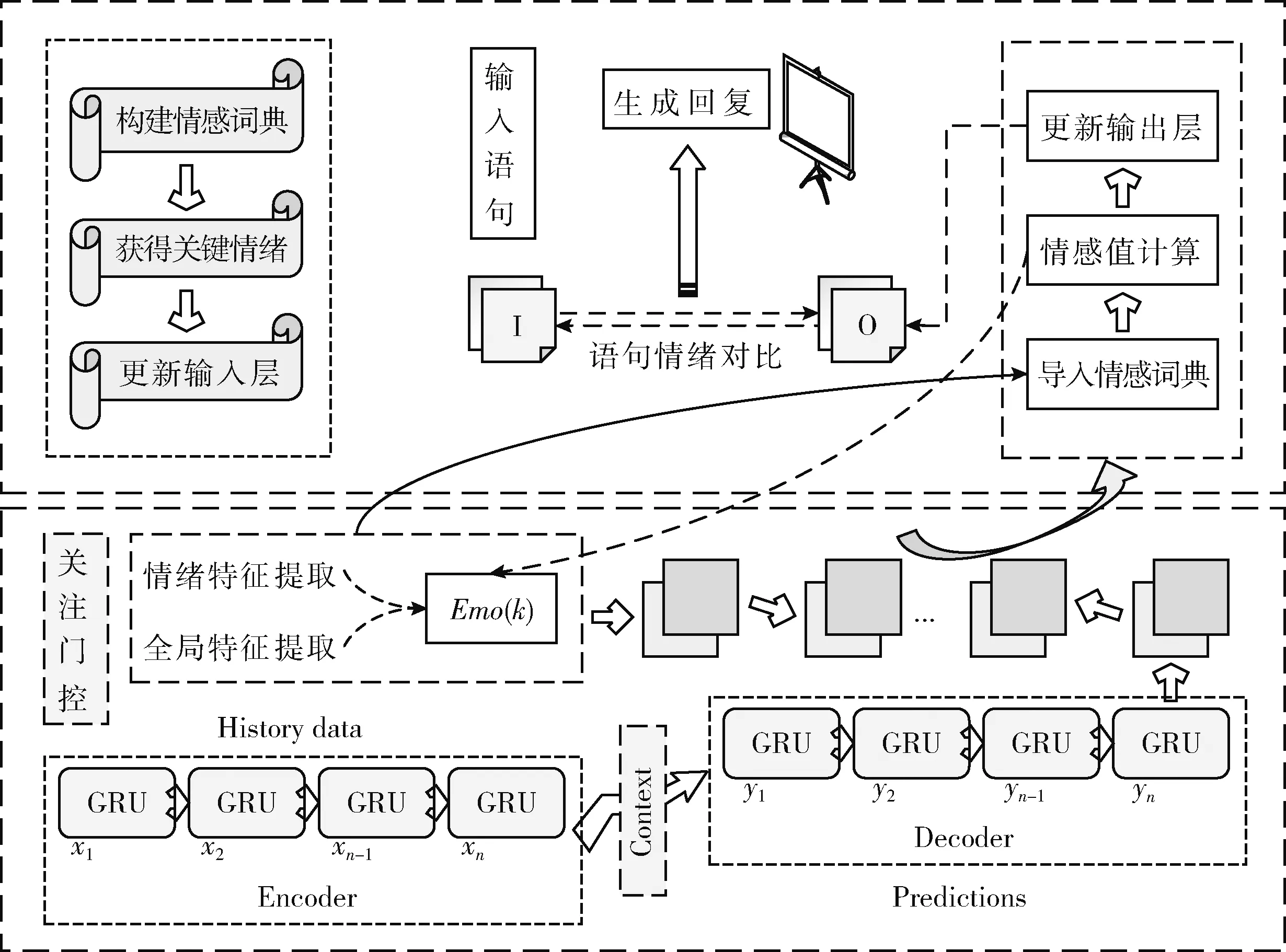
图1 基于改进编解码器和情感词典的对话生成模型框架
2.1 AgSeq2Seq模型
AgSeq2Seq模型由编码器、解码器和关注门控3个模块组成,在基于Attention机制的Seq2Seq模型基础之上,增加一个关注门控提取情绪特征和全局特征,在训练过程中对非情感语句进行权重限制,降低了数据集中诸多自然语句带来的噪音影响,增强了基准数据的情绪特征。同时利用情感词典计算语句的情感权重值,并结合情感词嵌入的概率向量和一般词嵌入的均值向量获得一个情绪注意值,与目标输出进行拼接后生成情绪回复。相比于传统的Encoder-Decoder结构,这种方法有利于构建出质量更高的对话生成系统。AgSeq2Seq模型的基本结构如图2所示。
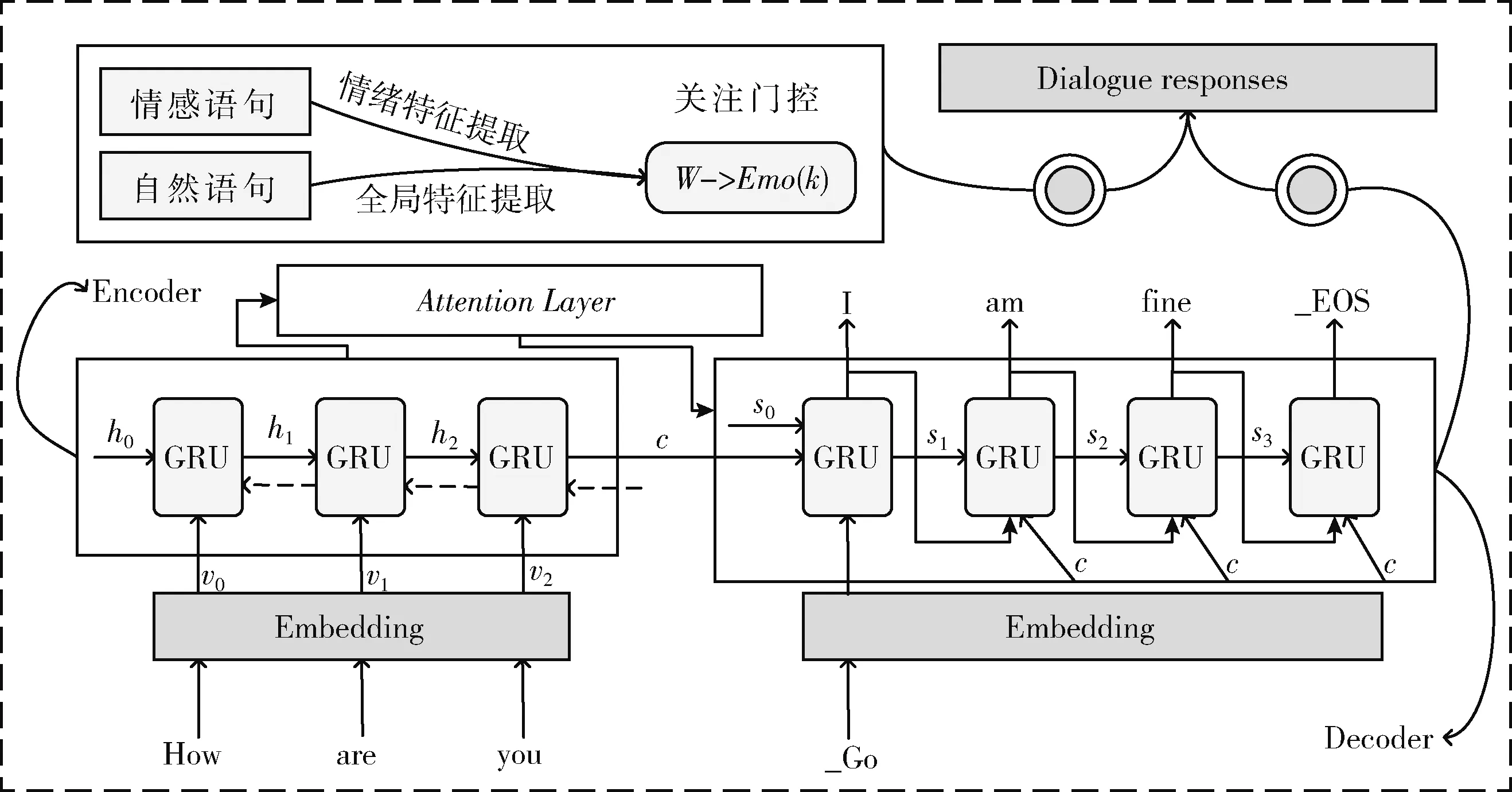
图2 AgSeq2Seq模型基本结构
在AgSeq2Seq模型中,给定查询序列X=(x1,x2,…,xM) 和目标序列Y=(y1,y2,…,yN), 得出以X为条件的Y的生成概率的最大值。在基于Attention机制的编码器和解码器模块,为了增强对上下文语义信息的表示,编码器通过双向GRU将输入序列转换成指定长度的上下文向量c,解码器利用单向GRU以c为输入对Y的生成概率进行估计,并结合注意力机制生成目标语句。另外,关注门控通过特征提取方式获得情绪注意值,更新目标语句并生成情绪回复。AgSeq2Seq的目标函数如下
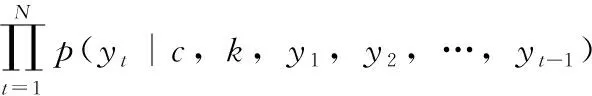
(1)
为了兼顾训练过程中的效率和梯度问题,本文使用两个GRU分别作为编码器和解码器,其中编码器采用双向GRU结构。另外,在经典注意力机制的基础上,增加一个关注门控,对自然语句进行全局特征提取并给予相应的权重限制,对情感语句进行情绪特征提取并获得相应的情绪注意值,最后与解码器生成的目标语句相结合,进行拼接后生成回复语句。为避免注意力分散,语义向量c在每一个时刻都会发生变化。这就导致每一个时刻的权重向量都要重新计算,所以解码器在t时刻的隐藏状态st和上下文信息的权重向量ct的计算公式分别如下
(2)
式中:yt-1是上一时刻的输出词;αit是注意力概率分布(即权重向量),它通过softmax函数对一个注意力打分函数进行转换后得到;hi是编码器的输出向量。解码器生成目标语句序列的计算公式如下
p(yt|w,y1,y2,…,yt-1)=g(yt-1,st,ct)
(3)
式中:w是目标输出层的参数。对话数据集一般来源于各种社交环境,不可避免地存在大量自然语句,高质量的情感对话数据相对缺乏,从而给训练过程带来一定的噪音影响,故对基准数据集中的情感语句给予更多的关注显得极为重要。自然语句与情感语句在对话中一般交织出现,关注门控根据当前对话以及上下文输入,结合情感词典判别语句属性,对自然语句进行全局特征提取,并给予相应的权重限制;对情感语句进行情绪特征提取,生成情感词向量并获得相应的情绪注意值,并与目标输出进行拼接。生成情绪响应序列的条件概率计算公式如
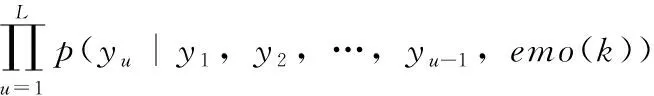
(4)
式中:emo(k) 是关注门控利用情感词典得到的情绪注意值,L是情绪响应序列词的数量。关注门控的情绪注意值计算公式如下
emo(k)=β|(αk1-(1-α)k2)|
(5)
式中:α表示数值介于0到1之间的语句情感权重值,β表示预先定义的超参数,k1表示情感词嵌入的概率向量,k2表示一般词嵌入的均值向量。生成情绪响应Lout的拼接方法如下
Lout=max(k1L1,k2L2,…,knLn)
(6)
式中:Ln表示第n次解码所对应的目标输出的概率得分,kn表示关注门控在第n次解码过程中同步生成的门控参数,若为情感语句则对应情绪注意值emo(k),若是自然语句则对应限制权重。
2.2 构建情感词典
本文所使用的情感词典由基本情感词典、程度副词词典、否定词词典、感叹词词典以及关系连接词词典构成,并可以根据实际对话场景进行拓展。将目标语句导入情感词典,结合语义规则对分割后的情感词设置恰当的权重并计算情感值,从而判断输入语句和回复语句的情感极性相似度,并给出最合乎当前对话情境的拟人回复。结合情感词典的情绪特征识别流程如图3所示。
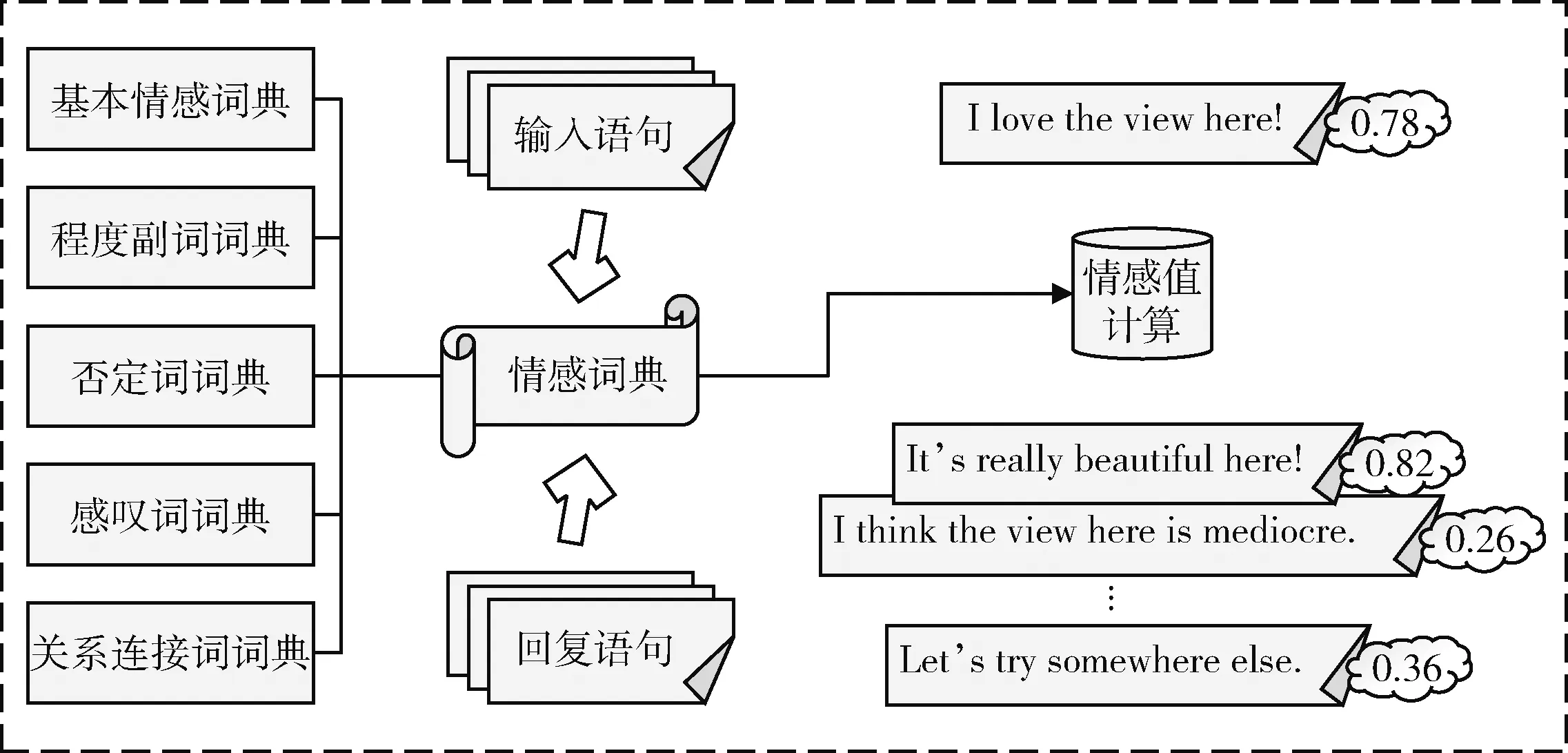
图3 结合情感词典的情绪特征识别流程
VoS表示语句情感值,VoC表示以情感词为中心的关联部分情感值。W表示基本情感词的权重,D表示程度副词的权重,N表示感叹词的权重。程度副词的作用一般是对情感词的限定或修饰,故存在程度副词时,可以将其与情感词相结合得到一个新的权重。出现在情感词前面的否定词个数决定了情感偏向性,若是奇数会发生情感翻转,若是偶数则保持原来的情感特征(否定之否定)。另外,感叹词的权重可以根据其出现的个数累加计算。修辞性反问词也会大大影响语句的情绪特征,但在一条语句中通常最多出现一次。在情感词前面同时出现程度副词和否定词/前缀的情况下,考虑到否定词+程度副词+情感词(This car is not very attractive)对语句本身情绪的影响较弱,而程度副词+否定前缀+情感词(This car is very unattractive)对语句本身情绪的影响较强,所以构建以下系数公式加以区别
VoC=D*W*0.5*P+D*W*2*Q
(7)
式中:P表示程度副词在否定词之前,这时P取值为-1,Q取值为0;Q表示否定词在程度副词之前,这时P取值为0,Q取值为-1。输入语句和回复语句的情感值计算公式如下
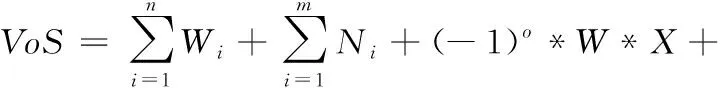
(8)
式中:n表示基本情感词的个数,m表示感叹词的个数,o表示否定词的个数。X作为否定词门控,若出现否定词取值1,否则取值0;Y作为修辞性反问词门控,若出现修辞性反问词取值1,否则取值0。如果一条语句中间存在关系连接词,那么根据语义理解,若出现这种情形,只关注后半部分的情感值即可(I want to play football, but it’s raining outside.)。
2.3 情绪对比机制
针对现有模型生成的回复语句缺乏情感共鸣,拟人效果不够理想的问题,将AgSeq2Seq模块和情感词典模块通过情绪对比机制结合起来,有效识别了输入输出语句的情绪特征并实现了拟人程度更高的情感对话过程。其中,构建的情感词典一方面为输入语句和生成回复计算情感值,另一方面也为关注门控的特征提取任务提供计算途经。情绪对比机制算法如下:
算法: Contrast mechanism of emotion
输入: A sequence of query statements
输出: An emotional response sequence
(1)Decoder_EOS=Seq2Seq+Attention(Input)
(2)Emo(k)=AgSeq2Seq(Input)
(3)Sentence[n]=Combine(Emo(k),Decoder_EOS)
(4)Value=Sentiment Dictionary(Input)
(5)Score[n]=Sentiment Dictionary(Sentence[n])
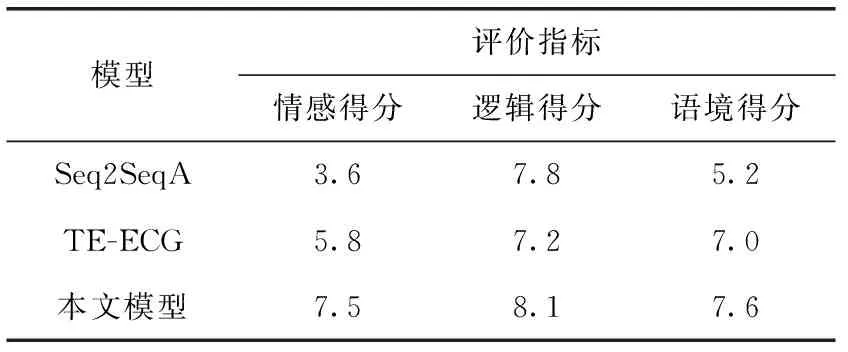
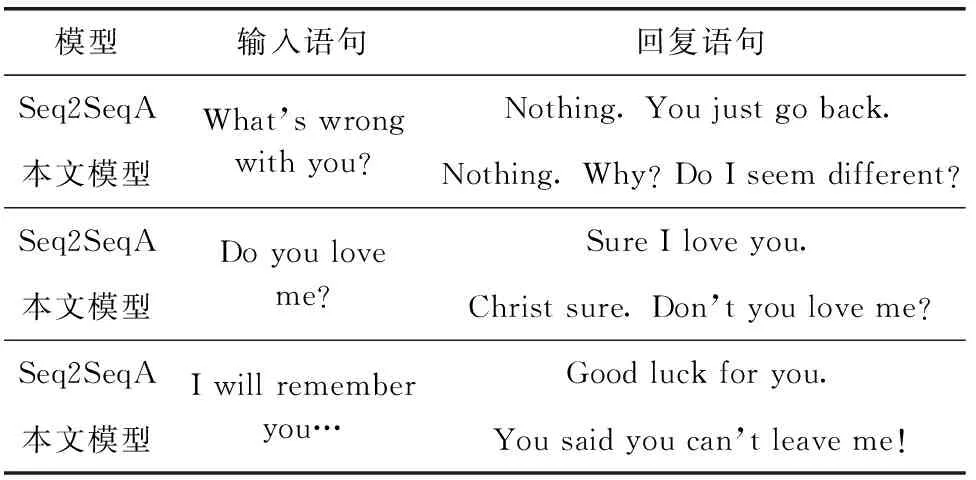
(6)for(i=0;i (7) if(abs(Score[i]-Value)==min): (8) Output=Sentence[i] (9)return Output 情绪对比机制算法分析:输入一条查询语句序列,AgSeq2Seq模型的解码器模块结合注意力机制输出目标语句序列,同时关注门控利用情感词典获得这条语句的情绪注意值,然后与目标语句进行拼接(若是自然语句则给予相应的权重限制,增强对话数据的情绪特征)。在生成情绪回复后计算情感得分,并与输入语句的情感值进行对比,当对比语句情绪之差的绝对值最小时退出循环,最后在生成回复层实现当前语境下拟人程度最高的情感对话过程。 本文使用Cornell Movie-Dialogs Corpus作为实验数据集,包括10 292对电影角色之间的220 579次对话。提出的模型是在PyTorch框架下实现的,编码器和解码器由两层GRU组成,其中编码器采用双向GRU结构。隐藏节点数均设置为256,并将词嵌入大小设置为100,最后将批次大小和学习率分别设置为128和0.001。为了更好地适应稀疏梯度,本文使用Adam优化目标函数。 选取两个基线模型作为本文的对比方案:一个是基于注意力机制的序列到序列模型(sequence to sequence model with attention,Seq2SeqA);另一个是TE-ECG模型,这个模型在对话中融入了主题信息和情感因素,能生成主题相关和富有情感的回复。 本文采用人工评价和自动评估两种方式,对提出的模型效果进行检测。采用Perplexity、BLEU和Distinct1/2等指标对所提模型和基线模型进行自动评估。Perplexity可以根据语句复杂度来判断语法的正确程度,两者呈负相关。BLUE值用于衡量生成回复和参考语句之间的相似性,可以很好地反映人机互动过程中情绪的一致性。Distinct1/2则可以通过较小的计算代价,评估回复语句形式上的多样性。本文模型与基线模型的自动评估结果比较见表1。 表1 本文模型与基线模型的自动评估结果比较 可以看出,相对于Seq2SeqA模型和TE-ECG模型,本文模型的Perplexity指标分别降低了1.08%和1.98%,BLUE值分别提高了16.67%和7.06%,验证本文模型生成的回复语句在语法和相似性上均获得了良好的效果。另外,本文模型相对于Seq2SeqA模型和TE-ECG模型,其Distinct-1指标分别提高了56.52%和24.14%,Distinct-2指标分别提高了20.31%和13.24%,验证本文模型生成的回复语句在形式上的多样性也获得了一定程度的提升。 为了弥补自动评估在衡量上下文语义和情绪适宜性时的不足,采用人工评价的方式,分别从情感、逻辑和语境3个方面对模型进行打分,来检测回复语句的情感拟人程度、上下文的逻辑关系和语境相符程度。本文模型与基线模型的人工评价结果比较见表2。 表2 本文模型与基线模型的人工评价结果比较 可以看出,与基线模型相比,本文模型在人工视角下的各项评价指标均得到了较大提升,说明结合情绪对比机制和目标语句概率生成的回复语句既保证了上下文的逻辑关系,又在情感和语境上获得了一定进步,有效增强了交互过程中的情绪体验。 此外,提出的模型在语境感知和对话节奏的把握上亦能获得不错的效果,可以有效地对话题进行扩展。本文模型与基线模型的生成回复样例见表3,各模型基于同一输入语句下生成的回复在逻辑结构上均没有问题,但在情绪释放上有着较为显著的差别,可以看出本文模型能对交互话题起到一定的延伸作用,同时在各种情绪语句下生成的回复均能体现出情感上的共鸣。 表3 本文模型与基线模型的生成回复样例 关于人工评价的声明:我们确保参与评价的人员均接受过良好的高等教育,并严格依据客观事实独立完成各项指标的打分,最后结合统计学规则得出模型的平均分。 本文提出了一种基于改进编解码器和情感词典的对话生成模型,旨在利用AgSeq2Seq模型构建高质量对话系统的前提下,结合情感词典并利用情绪对比机制实现更加优质的情感对话模型。实验结果表明,相对于传统的对话生成模型,提出的模型能生成更加合乎逻辑、适应语境的回复,并实现拟人程度更高的情感对话过程。同时我们也注意到,人机交互的情感表达方式呈现出混合型、多样性等特征,通常不再局限在文本领域。在未来的工作中,我们将考虑构建多模态的情感对话模型,以期实现语音、图像和文本的混合情感交互过程。3 实验与结果分析
3.1 实验设计
3.2 实验结果与分析

4 结束语
猜你喜欢
小学生必读(低年级版)(2021年10期)2022-01-18
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
快乐语文(2020年15期)2020-07-06
文苑(2019年24期)2020-01-06
文苑(2019年24期)2020-01-06
家庭影院技术(2019年8期)2019-12-04
快乐语文(2019年12期)2019-06-12
快乐语文(2018年27期)2018-10-20
小学生学习指导(低年级)(2018年6期)2018-05-25
