
铁路客运车站客流监测与预警系统
2023-02-18 13:11李永孟歌廖凤华张军锋周星
铁路计算机应用 2023年1期
李永,孟歌,廖凤华,张军锋,周星
(1.中国铁道科学研究院集团有限公司 电子计算技术研究所,北京 100081;2.中国铁路济南局集团有限公司 客运部,济南 250001)
铁路客运车站是旅客出行重要集散场地,目前车站进站验证、安检、候车等客运组织工作所需的设备、人员等资源主要依靠经验进行调配,缺乏准确的实时数据支持。近年来,随着新一代客票系统[1]的建设,车站实现了实名制验证和电子客票[2]进出站,能够准确地实时采集旅客进出站数据。另一方面,大数据、机器学习等技术在铁路客运系统得到成功应用[3-4],为客运车站客流预测提供了技术支撑。
为此,通过获取铁路客票预售数据[5]、车站历史客流数据、旅客进出站实时数据、列车正晚点数据等相关信息,建立基于K 均值聚类(K-Means)的支持向量回归(SVR,Support Vector Regression)客流预测模型,实现车站每日进站客流和分时段进站客流及候车室客流的监测、预测及超限预警,帮助车站工作人员及时掌握客流变化,高效地组织、引导和疏散客流,为旅客提供更加优质的服务,提升旅客出行体验。
1 系统架构
1.1 总体架构
铁路客运车站客流监测与预警系统利用Kafka、数据传输中间件等技术[5],自动从中国铁路客票发售和预订系统(简称:客票系统,含12306 互联网售票系统)、铁路客运营销辅助决策系统(简称:客运营销系统)、铁路旅客实名制进站验证检票系统(简称:实名制验证系统)[6-7]、铁路旅客自动检票系统(简称:检票系统)、铁路列车调度指挥系统(简称:列车调度系统)[8]等系统获取所需数据,对这些数据进行必要的转换和融合处理,获得较为全面的客流数据;利用车站历史客流数据,建立基于K均值聚类的支持向量回归机客流预测模型,实现分时段客流预测和候车室客流预测,当预测客流超出预警阈值时及时告警,为车站客运组织工作提供准确的实时客流信息。
铁路客运车站客流监测与预警系统采用集中部署方案,系统架构划分为数据接入层、业务处理层和数据展示层,如图1 所示。
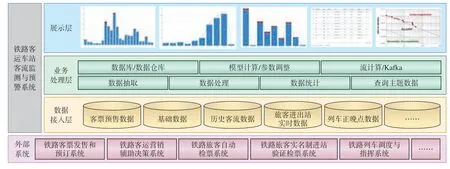
图1 铁路客运车站客流监测与预警系统架构示意
(1)数据接入层:通过数据采集程序自动获取相关数据,主要包括客票系统的客票预售数据以及列车时刻表、车站字典、车次候车室安排等基础数据,客运营销系统的历史客流数据,检票系统和实名制验证系统的旅客进出站实时数据,列车调度系统的列车正晚点数据。
(2)业务处理层:根据实际业务需求,对数据接入层所获取的数据进行清洗、转换和融合处理,生成不同业务场景下的客流监测数据;利用车站历史客流数据建立客流预测模型,完成每日进站客流、分时段客流和候车室客流预测,并将客流监测数据和预测数据存储在数据库或数据仓库中。
(3)展示层:为用户提供内容丰富的实时客流展示图表及数据查询功能,并提供用户管理、预警管理、阈值设置、模型参数设置等系统维护功能。
2 系统功能
铁路客运车站客流监测与预警系统功能如图2所示,主要面向车站用户,提供客流流向、客流监测与预测、客流统计、预警管理、系统监控、系统设置等功能,同时也为铁路局和站段用户提供全局和所辖各站段客流数据。
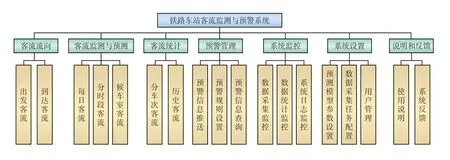
图2 铁路客运车站客流监测与预警系统功能构成示意
2.1 客流流向
通过对铁路客票预售数据的统计分析,提供车站出发和到达客流的城市分布情况,帮助车站工作人员提前对重点方向旅客做好车站引导服务。
(1)出发客流:以迁徙图的形式,展示从车站出发的客流主要去往的城市,并以不同颜色标识客流量的大小。
(2)到达客流:以迁徙图的形式,展示到达车站的客流主要来自于哪些城市,并以不同颜色标识客流量的大小。
2.2 客流监测与预测
提供分时段和分场地的车站客流量监测与预测,帮助车站工作人员及时掌握和预知客流变化,提前设置好进站闸机和安检通道开启数量,安排好现场客服人员。
(1)每日客流:利用客票系统的预售数据,统计生成车站每日客流的监测数据;应用客流预测模型,预测车站每日客流;利用Echarts 技术,实现每日客流监测与预测数据可视化展示;当预测客流量超过警阈值时,自动改变图形显示颜色,并显示推送的预警信息。
(2)分时段客流:基于旅客进站实时统计数据,动态展示各时段进站客流及各时段内具体车次的客流,准确反映旅客进站时间分布和进站高峰时段;结合车站列车时刻表数据,应用客流预测模型预测车站分时段客流;利用Echarts 技术,实现实现分时段客流监测与预测数据可视化展示;当预测客流量超过预警阈值时,自动改变图形显示颜色,并显示推送的预警信息。
(3)候车室客流:基于旅客实时进站统计数据,确定各车次进站客流;根据车站候车室车次安排和列车正晚点数据,监测车站各候车室客流;应用客流预测模型,预测车站各候车室客流;当预测客流量超过预警阈值时,自动改变图形显示颜色,并显示推送的预警信息。
2.3 客流统计
通过对铁路客票预售数据和客运营销历史客流数据的融合分析,提供车站停靠列车的分车次客流数据统计和车站历史发送量数据统计,帮助车站工作人员预知客流分布情况,提前做好客运组织准备工作。
(1)分车次客流:利用客票系统的客票预售数据,统计出停靠车站的各次列车的乘车和到达客流,方便车站工作人员根据列车时刻表,提前做好组织引导旅客乘车和出站的具体工作安排。
(2)历史客流:基于客运营销系统的历史客流数据,提供车站历史发送客流和到达客流的统计分析,统计车站某段时间或者某天的发送和到达客流;通过对客流的钻取,进一步分析分时段或者分车次的客流,方便车站工作人员掌握本站客流规律,做好应对客流高峰期的准备工作。
2.4 预警管理
当车站的客流量达到设定的预警阈值时,针对不同业务场景自动生成预警消息,并按照设置的预警消息推送方式,及时将预警消息发送给相关的车站工作人员。
(1)预警信息推送:根据不同业务场景下触发预警的级别,自动生成相应的预警消息,按照设定的业务职责和工作流程,将预警消息分别推送给具体工作人员,提醒其对客流预警予以关注,以便车站工作人员采取不同预警级别的针对性措施。
(2)预警规则设置:提供预警规则编辑和预警消息提示方式设置功能,车站管理员可根据车站技术条件和人员配备等实际情况,合理调整车站不同业务场景下客流预警阈值及预警消息提示方式,如弹出窗口、播放声音、推送至企业微信或钉钉工作群等。
(3)预警信息查询:按车站、时间段和不同业务场景,提供预警消分类汇总和条件查询。
2.5 系统监控
记录数据采集和处理程序模块的运行状态,生成用户登录和操作日志,帮助系统管理员全面掌握系统运行情况和用户使用情况,支持故障诊断、性能调优和系统安全审计。
(1)数据采集监控:数据采集任务在执行过程中自动记录日志,在数据采集监控页面上可查看数据采集情况,包括采集时间、任务执行状态、数据记录数等。
(2)数据统计监控:针对不同业务场景定期自动执行数据统计任务并记录日志,可在数据统计监控页面上查看数据采统计任务的执行情况。
(3)系统日志监控:提供用户登录和操作日志,记录用户登录时间、登录地址、登录方式、登录次数及操作活动等,提供用户行为审计。
2.6 系统设置
完成预测模型参数、数据采集任务时间和频率的设置,提供系统用户管理功能。
(1)预测模型参数设置:对客流预测模型进行离线训练,对模型的精度进行验证,当客流预测模型满足要求时,在系统中对客流预测模型参数进行设置,以便将该模型应用于客流预测。
(2)数据采集任务配置:对于不同的数据采集任务,按需指定其自动执行的时间、次数及频率。
(3)用户管理:管理人员添加和删除用户,给不同的用户进行不同的权限或修改用户操作权限,重置用户密码;验证登录用户身份合法性,仅允许用户访问被授权的功能。
2.7 说明和反馈
介绍系统的使用说明和用户对系统使用的反馈情况。
(1)使用说明:提供系统使用说明页面,介绍系统的操作和使用方式,不同功能中一些指标的简介和使用场景。
(2)系统反馈:提供用户反馈使用建议或报告使用系统的过程中所欲遇到问题或故障的信息交流窗口,以帮助不断完善系统。
3 关键技术
3.1 数据采集、转换、融合与存储
系统从多个外部系统自动获取数据,考虑到所采集数据的更新频度及不同系统提供数据的接口方式,采用多种技术完成数据采集,并对采集到的数据进行必要的转换和融合处理后,提供客流监测和预测功能。系统数据采集、转换与融合处理流程,如图3 所示。

图3 数据抽取、转换、融合与存储流程
(1)数据抽取:目前,客票系统实现了核心交易数据的集中管理,相关应用均可通过连接交易管理服务器(CTMS,Connection and Transaction Management Server)请求访问客票业务数据;鉴于电子客票数据量大,数据更新频繁,为减少对客票系统的影响,利用Kafka 消息中间件实时接收客票预售数据;同时,利用Sybase 数据库复制技术,直接从客票系统获取列车时刻表、车站字典、车次候车室安排等静态基础数据,当基础数据变化(如调图后)时,可手动触发数据复制;使用Java 数据库连接(JDBC,Java Database Connectivity)开发数据抽取程序,分别接入实名制验证系统和检票系统获取旅客实时进出站数据;利用数据库通信服务器(DBCS,Database Communication Server),每天从客运营销系统获取一次历史客流数据;数据抽取程序通过Web Service 接口,每隔30 min 自动从列车调度系统获取最近的车站列车正晚点数据,也可根据实际情况手动调用数据抽取程序获取数据。
(2)数据转换与融合:根据不同的业务场景,对数据进行必要的类型和格式转换,并通过建立关联进行数据融合,生成满足不同业务场景的数据表;进站验证和进站闸机数据中包含个人姓名、身份证号等敏感信息,需要对其进行加密来脱敏。
(3)数据存储:系统采用2 级数据存储模式,将采集到的、经过转换和融合处理的实时客流数据以及客流预测结果数据存储在数据库中,并定期将历史数据归档转储至数据仓库中,以提高数据查询性能;将车站历史客流数据等存储在数据仓库中,便于数据统计分析处理。
3.2 客流预测模型
常用的客流预测方法主要有聚类分析、时间序列[9]、灰色预测法[10]、SVR[11]、神经网络[12]等。其中,SVR 以预测误差最小化为目标,寻求一个能较好的接近数据点的估计函数f,再利用非线性映射函数 φ,将输入空间的数据xi映射至高维空间Rn中进行线性回归,可得到在原低维空间中非线性回归的效果,对于非线性环境下小样本数据集具有较好性能。K-Means 算法根据数据间相似度,将特征类似的样本自动归为一类,实现数据聚类划分[13]。
铁路客流受多种因素影响,直接对车站客流数据进行预测可能存在较大误差,先利用K-Means 方法对车站停靠列车进行聚类,再将聚类后的数据作为SVR 输入样本,构建基于K-Means 的SVR 客流预测模型。
设聚类后的数据训练样本集为(x1,y1),(x2,y2),···,(xN,yN),其中xi∈Rn,yi∈{-1,1},N为客流样本数,n为客流特征向量的维数。在SVR 中,求最优超平面可转化为求解二次规划问题:
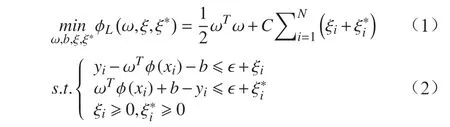
其中,ω为法向量;C为惩罚参数;ξi和为松弛因子;ε为不敏感函数。
利用二次规划方法可以得到SVR 的估计式为
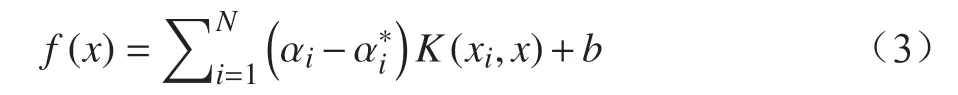
其中,阈值b通过下式求解:
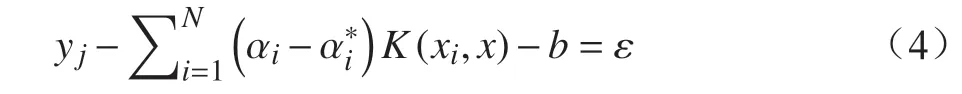
其中,ε取常用值0.1。
利用车站历史客流数据进行模型训练,采用均方根误差(RMSE)对模型进行验证,满足要求的模型即可用于预测客流,具体流程如图4 所示。
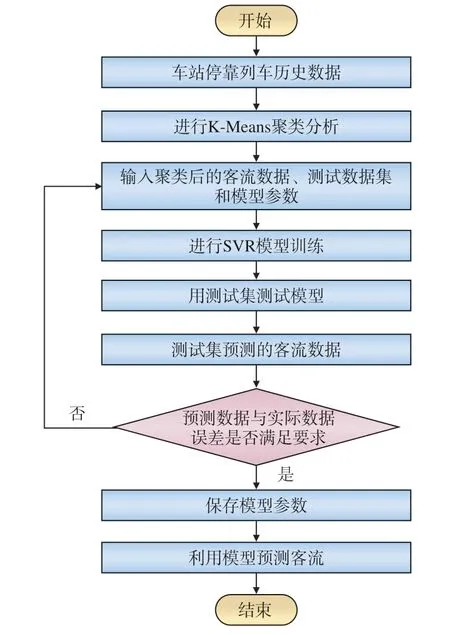
图4 客流预测模型处理流程
3.3 客流预警阈值计算与预警分级规则
客流预警阈值包括进站口客流预警阈值和候车室客流预警阈值。
(1)影响进站口客流聚集的因素较多,本文暂时主要关注车站进站闸机数量配置,依据车站历史最大旅客发送量S与进站闸机配置数量G,计算进站口客流预警阈值 α为

(2)候车室客流预警阈值 β主要依据车站候车室的面积和历史最大客流量计算得到,即有

其中,Q为车站候车室的有效使用面积,J为车站候车室历史最大客流量。
根据车站规模和历史客流,可将客流预警级别划分为4 个级别:Ⅳ(一般)—蓝色,Ⅲ(较重)—黄色,Ⅱ(严重)—橙色,Ⅰ(特别严重)—红色。以济南站为例,客流预警级别划分标准如表1 所示。
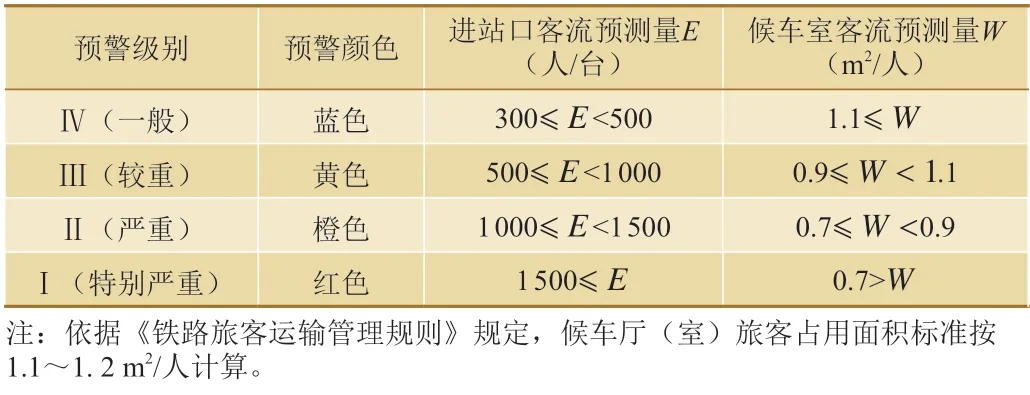
表1 济南站客流预警级别划分标准
系统计算出车站每日客流和候车室客流的预测量后,自动检测是否超过设定的客流预警阈值。触发预警后,客流监控窗口中展示客流信息的各种图表会立即自动改变显示颜色;同时,系统还会根据告警信息设置,向相关人员主动推送预警信息,提醒车站工作人员注意客流疏散组织。
4 结束语
铁路客运车站客流监测与预警系统自动采集铁路客票预售数据、客运营销历史客流数据、旅客进出站实时数据、列车正晚点等相关数据,提供直观明了的车站出发、到达客流迁徙图,基于车站历史客流数据建立客流预测模型,实现车站每日客流、分时段客流、候车室客流的监测及预测,可根据历史客流数据合理设置客流预警阈值,自动推送预警信息,方便车站工作人员随时掌握客流动态,及时根据客流变化动态调配设备和人员,确保精准、高效、安全、有序地开展车站客运组织工作。
目前,该系统已在济南站试运行,系统运行稳定,有助于改善车站客运服务水平,提升旅客出行体验,具有较强的推广使用价值。
猜你喜欢
减速顶与调速技术(2020年4期)2020-11-22
铁道通信信号(2019年9期)2019-11-25
铁道通信信号(2019年5期)2019-10-10
运输经理世界(2019年3期)2019-08-15
祖国(2018年6期)2018-06-27
阅读(科学探秘)(2018年8期)2018-05-14
汽车与安全(2016年5期)2016-12-01
中国市场(2016年45期)2016-05-17
海峡科技与产业(2016年3期)2016-05-17
铁路通信信号工程技术(2014年6期)2014-02-28
