
资源管理驾驶舱的设计与实现
2023-02-18 13:11王旭
铁路计算机应用 2023年1期
王旭
(中国铁路设计集团有限公司 土建院,天津 300308)
随着云计算、物联网等技术的发展,大数据对各个行业的影响越来越深[1-3]。数据的深入发掘利用给企业带来了新的机遇。同时,海量数据处理也给企业带来了一定的挑战。数据可视化是大数据分析的重要手段[4],数据可视化技术综合运用计算机图形学、数据挖掘、可视化、人机交互等技术,将海量、高维复杂数据变换为容易区分和理解的图形符号、图像、视频或动画,并以此挖掘对用户有价值的信息,洞察数据内部的规律[5]。
管理驾驶舱利用了数据可视化技术,直观地显示各类数据,支持下钻查询方式,可实现对各类指标的精细化管理和深层次分析,以形象化、直观化、具体化的数据展现形式反映企业核心业务的运行状态,是一个为企业或部门领导层提供一站式决策支持的系统[6],已在各行业得到了广泛的应用。如电力企业使用管理驾驶舱结合数据挖掘技术将业务数据和绩效管理指标进行直观的图形化展示[7-8];高等院校通过将战略管理指标体系引入管理驾驶舱实现了高校战略管理的信息化[9];资产管理公司利用管理驾驶舱理念搭建了管理会计信息化系统[10];医疗机构利用管理驾驶舱实现了门诊的实时监控管理[11]。而勘察设计企业对驾驶舱的应用还不够深入。
中国铁路设计集团有限公司既有的设计资源管理信息系统(简称:既有系统)是用于生产组织安排和人力资源规划的工具,经过几年的运行,该系统积累了大量的数据。为了使这些数据更好地应用于管理决策,发挥更好的支撑作用,本文设计并实现了一个资源管理驾驶舱,将既有系统中的数据经过一系列统计分析,形成不同维度的管理指标并呈现给各级管理者,为科学决策提供依据。
1 现状及存在的问题
1.1 既有系统现状
既有系统是参考企业资源计划(ERP,Enterprise Resource Planning)和制造执行系统(MES,Manufacturing Execution System)的理念,结合铁路勘察设计的业务特点和自身管理习惯而研发的。该系统将土建专业勘察设计的作业流程进行了标准化,制定了标准的作业单元。在实际应用中,将项目各个阶段的勘察设计任务用这些标准作业单元进行工作分解结构(WBS,Work Breakdown Structure)分解,一直分解到一系列可由一个人完成的工作,然后将每项工作以工单的形式下发给设计者,通过工单在流转过程中产生的各种数据来统计项目的进展和人力资源分布情况。该系统的应用提高了生产组织的效率和信息化水平,上线2 年多来积累了大量的生产活动数据。
1.2 存在的问题
既有系统是一款B/S 架构的应用,采用了前后端分离的模式,后台服务提供数据层状态转化(REST,Representational State Transfer)数据接口,前端网页通过HTTP 协议调用接口获取数据后渲染页面。这种基于“请求–响应”模型的方式给数据分析和展现带来了一定的限制,主要有以下2 点。
(1)前端展示的数据是静态的,除非用户主动刷新页面,否则数据不会自动更新。如果采用自动定时刷新方案,对于更新频率低的指标会造成大量无用的刷新,给前台渲染和后台服务带来负担;而对于频繁更新的指标,定时刷新往往无法满足时效性的要求。
(2)很多指标都是在请求到达服务器之后才开始计算并返回给前端,受制于请求响应时间的限制,计算必须足够快,因此复杂度不能太高,导致很多耗时的数据分析只能离线进行,无法随时查看。
为了解决这些限制,需要引入资源管理驾驶舱的理念对既有系统进行改造升级。
2 资源管理驾驶舱的设计
2.1 设计目标
资源管理驾驶舱的开发目标是提升数据分析和数据呈现能力。具体为:
(1)对于数据分析,在保证计算时效性的前提下增加指标的深度和广度,即对数据进行深入挖掘的同时开发出更多对管理决策有参考意义的指标;
(2)对于数据呈现,针对不同管理角色和场景将所需指标用直观的图表展示在一块屏幕上,当某个指标有更新,前端相关图表会及时刷新,而与此指标无关的图表不会触发更新。
2.2 总体架构
资源管理驾驶舱使用了事件驱动模型来实现更新的实效性和经济性。为了尽量避免对既有系统进行侵入式修改,在数据库和接口调用的地方增加了消息埋点,并用Kafka 消息队列将资源管理驾驶舱和既有系统桥接起来。资源管理驾驶舱的总体架构如图1 所示。

图1 资源管理驾驶舱总体架构
(1)既有系统。通过在线填报的方式进行数据采集,前端有浏览器、桌面客户端和手机客户端3种形式,后台服务通过HTTP 协议为3 种客户端提供统一的编程接口。在后台服务的相关接口中进行了消息埋点,当接口被调用时,调用参数和接口的名称就会被投递到桥接层的消息中间件,从而实现了对既有系统的最小化改动。
(2)桥接层。核心是一个Kafka 消息队列,为既有系统上传的每一类数据建立一个主题(Topic)。该层采用“发布–订阅”的模式将这些数据与资源管理驾驶舱的指标计算服务连接起来,降低了开发耦合性的同时也充分利用了消息队列的异步处理优势,提高了数据处理性能。
(3)驾驶舱。分为指标计算服务、指标持久化服务、前端消息订阅服务和前端数据展示4 个模块。每一个指标计算服务都监听消息队列里相关的一个或多个Topic,每当收到新的消息,就会触发指标的增量更新计算,计算过程结束后,结果会保存到指标持久化服务的Redis 数据库中,并通过前端消息订阅服务通知相关图表刷新数据。在前端数据展示模块,每一个图表只对应一类指标,针对不同的管理角色和场景将图表组合起来形成面板,即最终展示给用户的资源管理驾驶舱页面。
3 资源管理驾驶舱的主要功能
3.1 人员状态概览
人员状态概览功能以图形的方式动态展示了每一名员工多个维度的信息。该功能可使管理者快速了解职工当前的状态,降低沟通成本。每个员工的信息都用一个图标来集成展示,如图2 所示。
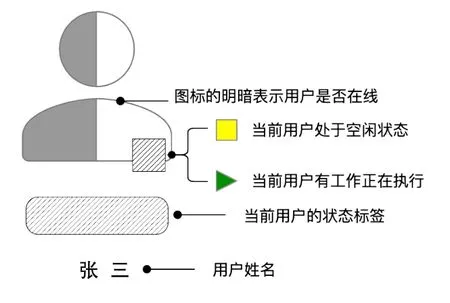
图2 人员状态概览示例
每个图标展示了3 个维度的信息:图标的明暗用来表示用户当前是否在线;图标右下角的位置用正方形和三角形来表示用户当前是否有正在执行的工作;下方的矩形标签里注明了用户当前的状态,如“出差”“休假”等。
3.2 工作安排热力
工作安排热力通过图表的形式展示所有员工未来30 天内每天的工作量。该功能可使管理人员直观地看到每个人的工作量,以便合理地调配工作负载。工作安排热力图的样式如图3 所示。
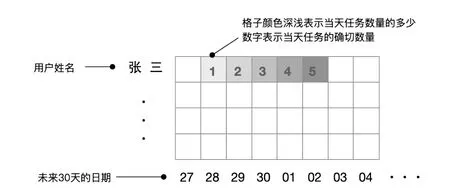
图3 工作安排热力图示例
图的横轴为未来30 天的日期,纵轴是每位职工的姓名,每一个格子即表示该名职工在这一天工作数量的多少,工作越多格子的颜色就越深,反之格子的颜色就越浅。
3.3 项目人力分布概览
项目人力分布概览以南丁格尔玫瑰图的形式展示了当前投入人力最多的10 个项目。管理者通过该功能可实时掌握人力资源在各项目的分布情况,优化资源配置。项目人力分布图示例,如图4 所示。
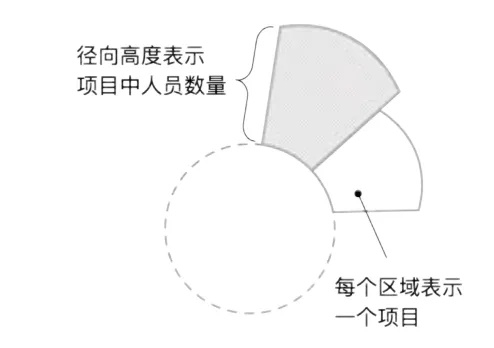
图4 项目人力分布图示例
图4 中,每一块区域表示一个项目,半径方向的高度表示项目投入的人员数量,由于半径和面积是平方的关系,所以南丁格尔玫瑰图会使数据之间的差异更加突显,适合用于对比大小相差不大的数值。图上始终显示10 个投入人力最多的项目,随着工作的启动和完成,这10 个项目和人员投入数量是动态变化的。
3.4 项目进展跟踪
项目进展追踪功能以进度条的形式实时展示了项目当前的进度与计划之间的关系。管理者通过该功能可关注项目的实时进展情况,及时调整项目进度。项目进展跟踪图的样式如图5所示。
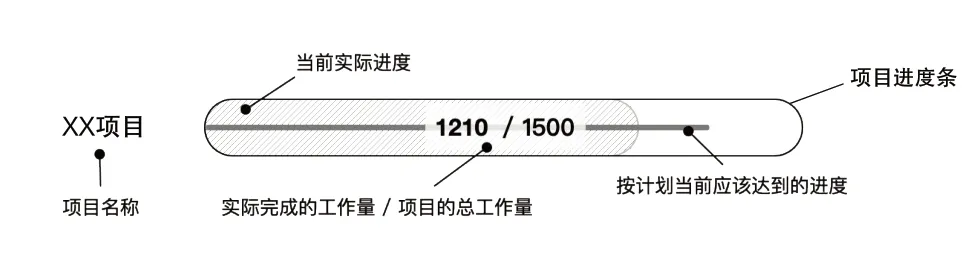
图5 项目进展跟踪图示例
项目进度条组成:水平的一道横线表示按照计划当前应该达到的进度;填充颜色的区域表示当前实际完成的进度,如果当前进度比计划超前则填充绿色,落后于计划则填充红色;进度条中间的2 个数字表示当前完成的工作量和此项目的总工作量,这些工作量都是从既有系统中提取出的量化数据。
4 关键技术
4.1 事件驱动的数据增量更新技术
管资源理驾驶舱的各类指标采用了事件驱动的更新方式,从事件发生到驾驶舱前端页面更新的整个流程如图6 所示。
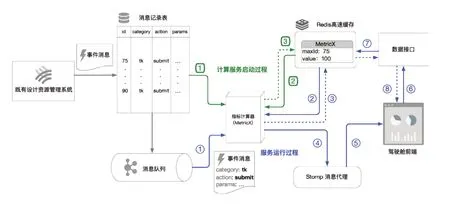
图6 事件驱动的数据指标更新流程
事件源来自于既有系统中的消息埋点,当用户在操作中调用了某个埋点的接口,就会产生一个事件消息,消息产生后,会持久化到关系型数据库中,然后被投递到消息队列。每条消息都会被分配一个自增的ID,标记事件产生的先后顺序。
4.1.1 指标计算器启动时的更新
服务在冷启动时,会根据消息的ID 判断是否要运行全量更新,其过程如图7 所示。

图7 指标计算器启动时的更新流程
假设有一个指标,其代码为MetricX,只有工单的提交事件(category="tk";action="submit")会影响这个指标的数值。当计算服务冷启动时,数据更新的过程如下。
(1)从关系型数据库的消息记录表中查询category="tk"并且action="submit"的消息最大的ID;
(2)从Redis缓存中查询MetricX指标的maxId 即已处理过的最大的消息ID;
(3)将这2 个ID 进行比较,若两个ID 一致证明Redis 缓存的指标无需更新,如果不一致则说明在计算服务停止的这段时间里,系统又发生了和这个指标相关的事件,此时MetricX 的指标计算器会运行一次全量的更新,并将更新之后的maxId 和指标数值写入到Redis 中。
4.1.2 指标计算器在运行过程中的增量更新
在指标计算服务启动成功后,指标计算器会进行增量更新,其过程如图8 所示。

图8 指标计算器在运行过程中增量更新流程
(1)指标计算器监听消息队列,根据新事件的category 和action 判断是否和自身相关;
(2)当相关事件发生时,指标计算器从Redis中取到maxId 和value 值,如果新事件的ID 小于当前maxId 说明事件已被处理过,消息被丢弃;
(3)如果新事件的ID 大于maxid,指标计算器会根据事件消息中携带的参数计算出指标的增量叠加到之前的value 值之后回写到Redis 缓存中;
(4)指标计算器通知Stomp 消息代理MetricX指标已经发生了变化;
(5)驾驶舱前端页面通过Stomp 消息代理获知MetricX 发生了更新;
(6)驾驶舱前端页面通过ajax 请求向数据接口查询MetricX 的最新数值;
(7)数据接口服务从Redis 缓存中获取MetricX的最新值并返回给驾驶舱前端页面;
(8)驾驶舱前端页面使用MetricX 指标的最新值更新相关图表。
4.2 组件化的前端图形展示技术
组件化是目前Web 前端领域一种流行的开发方式,它的核心思想是按照单一功能原则将应用划分为若干独立、可复用的模块。组件内部利用数据模型驱动视图的渲染,对外则提供了函数和配置项供使用者来控制组件的行为和样式。通过组件的嵌套和组合可以很大程度上提高模块的复用性和扩展性。
在资源管理驾驶舱前端展示页面中,有2 个重要组成部分,即数据和图表。图表的形式往往是有限的,一般常用的有折线图、饼图和柱状图等10 余种,而数据指标类型却是多种多样的,而且在使用过程中还会不断有新的指标出现。如果在开发中将数据处理的逻辑与图表展示的逻辑耦合在一起,会造成视图部分的代码出现大量的重复冗余,而且数据格式或图表样式任何一方发生变化,整个页面的代码都需要重写。本文提供一种组件化思路,可以将数据处理与数据展示功能正交化,以克服上述耦合开发带来的弊端,如图9 所示。

图9 前端组件化示意
资源管理驾驶舱将数据可视化过程分为数据处理和数据展示2 个维度。在数据处理维度上,各个组件只负责监听指标的变化及获取指标的最新数值;在数据展示维度上,组件负责页面的整体布局及每一个显示区域尺寸和位置的计算。通过参数注入,2个维度的组件不断将参数传递到下一层组件,最终在图表内核组件中将2 个维度参数结合起来完成图表的绘制。图9 中5 个组件的具体功能如下。
(1)布局(Layout):将整个页面分隔成不同的区域,每个区域显示一个图表。
(2)视图容器(View Container):根据其在布局组件中的位置,计算显示区域的尺寸和其他显示参数,并将这些参数注入到子组件中。
(3)全局数据分发(Global Data Dispatcher):统一订阅Stomp 消息代理,当收到指标变更的通知时重新获取数据并分发给相关的图表,其作用相当于整个前端页面的数据总线。采用这种消息分发机制,可以让所有图表组件都复用一个网络连接,减小了服务器资源开销,也提高了客户端的性能。
(4)数据容器(Data Container):向Global Data Dispatcher 注册指标类型,当该类指标发生更新时,Data Container 会收到Global Data Dispatcher 的数据推送,并将这些数据转换为图表显示所需的格式。
(5)图表内核(Chart Core):根据View Container提供的显示参数和Data Container 提供的数据模型将可视化图表渲染出来。页面尺寸的变化和指标数据的变化都会触发图表的重新渲染,实现了数据的即时刷新和自适应显示。
5 资源管理驾驶舱的应用
资源管理驾驶舱的上线应用解决了企业管理指标的实时计算和展示的难题,不但提升了管理效率,也为管理者的科学决策提供了数据支持。各类反映不同管理指标的图表可以根据用户的管理角色和管理场景组合成不同的面板,用户也可以根据实际需求,灵活设置面板的参数,实现个性化的展示。资源管理驾驶舱实际展示效果如图10 所示。
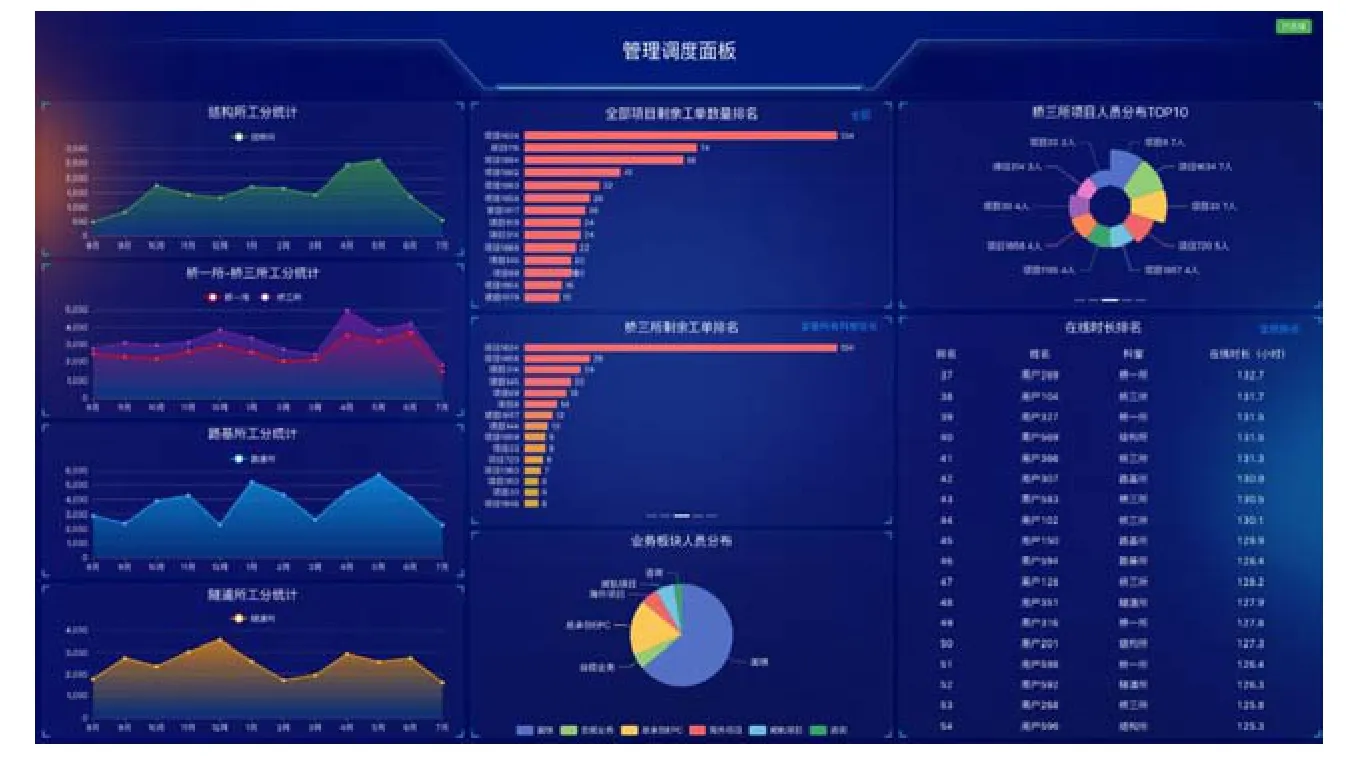
图10 资源管理驾驶舱应用实例
6 结束语
本文在既有的设计资源管理信息系统基础上,研发了一个资源管理驾驶舱,实现了人员状态概览、工作安排热力图显示、项目人力分布概览、项目进展跟踪等多种功能。该驾驶舱用关键指标实时反映了企业运行的状态,为企业各层级管理人员科学决策提供了有力的支撑。
猜你喜欢
保健医苑(2022年1期)2022-08-30
时代英语·高一(2018年4期)2018-09-14
百科探秘·航空航天(2016年9期)2016-12-01
足球周刊(2016年14期)2016-11-02
足球周刊(2016年15期)2016-11-02
足球周刊(2016年10期)2016-10-08
世界博览(2016年16期)2016-09-27
时代英语·高一(2016年4期)2016-09-21
汽车零部件(2014年4期)2014-06-23
通信技术(2012年4期)2012-02-15
