
自学考试“脏数据”问题研究和应对策略
2023-02-17 06:09:20林华
考试研究 2023年1期
林华
高等教育自学考试制度以其开放、灵活的特点成为构建高等教育立交桥的重要组成部分。数据作为信息化的基础,是自学考试最核心的部分之一,它能为用户提供业务申请、存储、检索服务,使其方便、准确、及时地从数据中获得所需的信息,更可以为管理者提供决策依据。完整、准确的数据是保证自学考试业务正常运转的重要因素。但随着自学考试数据不断积累且日益庞大,海量数据中不可避免的产生并积累了不同程度冗余的、失准的、无效的甚至是错误的数据,形成所谓“脏数据”[1],给自学考试信息系统运行与维护都带来了困扰,也直接影响到各项管理工作的效率,长此以往,甚至会造成自学考试政策制定的偏差。因此,清洗“脏数据”已成为亟待解决的问题。
一、自学考试“脏数据”的概念与种类
(一)“脏数据”的概念
“脏数据”(Dirty Data),又称“坏数据”(Bad Data),其概念最初源于西方,是指源系统中的数据不在给定的范围内或对于实际业务毫无意义,或是数据格式非法,以及在源系统中存在不规范的编码和含糊的业务逻辑[2]。
这个概念引申到自学考试中,是指随着几十年自学考试的发展沉积下来的,在目前或以后的数据使用过程中和数据管理中冗余的、失准的、无效的,甚至是错误的数据。这些数据不仅不能为系统的正常运行带来价值,反而会随时间推移逐渐占据存储空间,浪费软硬件资源,如不能得到及时的清理,而参与到正常的运算和检索中,会出现严重的错误,影响数据库的可信度。数据分析的最终目的是驱动决策,一旦“脏数据”使整个数据都不再可靠和准确的时候,那将会直接影响决策的质量。
(二)“脏数据”的分类与成因
根据“脏数据”形成的主要原因,大致可将其分为以下四类。
1.重复冗余数据
随着我国社会经济的高速发展,新的行业不断涌现,相应的,自学考试新专业也应运而生。与此同时,不再适应社会人才需求的自学考试相关专业的生源则在逐渐萎缩。目前,全国自学考试的专业及课程体系又进入了一个调整期,随着部分专业的关停并转,考生专业转考的规模也将持续增加。
图1、图2、图3展示了在某个时间点,停考专业转考的三种基本形式,在几十年专业的不断调整过程中,这三种简单形式交错演变形成图4或图5的复杂形式。
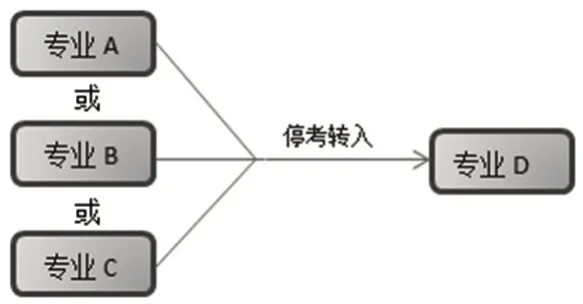
图1 停考专业“多对一转考”示例
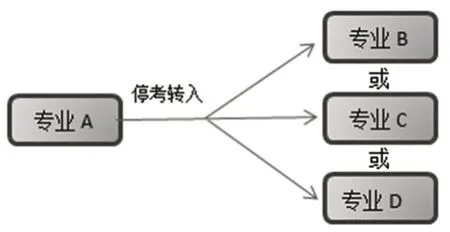
图2 停考专业“一对多转考”示例

图3 停考专业“一对一转考”示例

图4 停考专业链状继承图
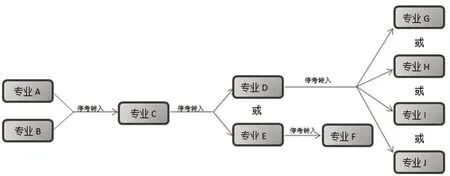
图5 停考专业网状继承图
例如,从图4上看,一个A专业的考生,多年来一直参加自学考试但仍未毕业,始终处在持合格成绩转考的过程中,其所在专业先后经过了三次停、转。由于自学考试是按照专业管理,考生报考任何专业均要申请该专业的准考证号,所以这个考生虽然目前留在专业D里继续参加考试直至毕业,但他此时会持有专业A、专业B、专业C以及专业D的四个准考证号。从专业管理的层面看,根据准考证号的不同,系统将会把该考生认作四个独立的个体;而从身份管理的层面看,根据身份证号等个人信息,他又被系统视为同一个人。数据库中每一位考生的信息是由多个具有不同属性的字段组成的,当两个考生记录的大多数属性字段值相同或绝大程度相似时,就将这两条记录判定为相似重复记录[3]。从这个角度看,专业发展必定带来停考专业考生集体的迁移,而考生的集体迁移便会在数据库中形成大量人员的相似数据重复记录。
同样,考生报考的多个专业之间的课程又存在向下可顶替的继承关系,从图5中可以看出,这个继承关系可以是链状继承,也可以是树状甚至是网状继承,那么如果要使符合政策的考生的合格成绩在申请毕业时生效,记录成绩数据中课程间的相互关系的过程,也是产生冗余数据的一个重要环节。如果能将这类重复冗余的数据加以“瘦身”,将大大简化数据间的复杂结构,有效提升数据的检索速度,降低系统运转压力。
2.多重标准数据
自学考试制度建立40多年来,从最初的全手工管理到20世纪90年代的信息系统管理,再从C/S模式升级到B/S模式,各项信息数据项采集标准在不断提高,对数据内容的校准也日趋完善。但数据标准的每一次提升,都成为那个阶段新老数据的分水岭,于是多重数据标准慢慢成型。
如表1所示,以准考证号字段为例。通过比较发现数据标准的变化十分明显。
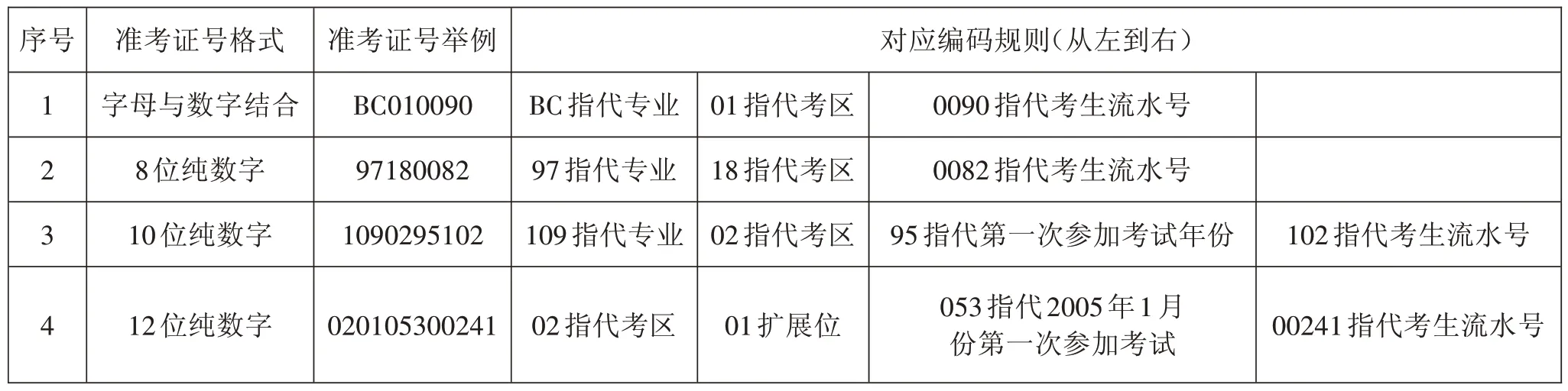
表1 准考证号编码规则演变示例
内容变化:在前三个阶段的准考证号的编制中都含有了考生的专业信息,其中第一个阶段的专业代码用两位的英文字母表示,第二个阶段的专业代码为两位的纯数字,而第三个阶段为三位的纯数字专业代码,在第四个阶段中准考证编号中不再体现考生的专业信息。
位数变化:准考证的位数先后经历了四个阶段,即字母与数字结合的8位字符串、8位纯数字字符串、10位纯数字字符串、12位纯数字字符串。
位置变化:在四个阶段的准考证号中都含有了考生所属考区的信息,但不同之处在于前三个阶段,考区的标志位,在第三、第四两位体现,而在第四个阶段中考区标志位被提到了前两位。
从上面的分析可以看出,虽然字段表达内容相同,但不同数据标准同时在系统中运转,加大了系统源代码辨析的难度以及系统运行时对数据的兼容性要求,也势必会提高系统运转的错误率。同时,在上报国家考试中心相关数据时,还要额外增加字段转换和补位工作,也增加了报送出错的风险。
此外,如表2所示,考生头像照片的数据标准也是在不断改进中。为使对考生身份的管理更加严谨,自从建立管理信息系统后,头像照片的尺寸(由180×240提高到480×640)、分辨率(由96dpi提高到300dpi)和背景色(由多色统一为浅蓝色)几个维度都在不断地提高照片的精准度。因此,多规格的照片在数据库中在读取和使用时,相对低像素的照片会出现模糊不清,为日后的入场考试身份验证环节和毕业生学历认证带来不必要的麻烦。
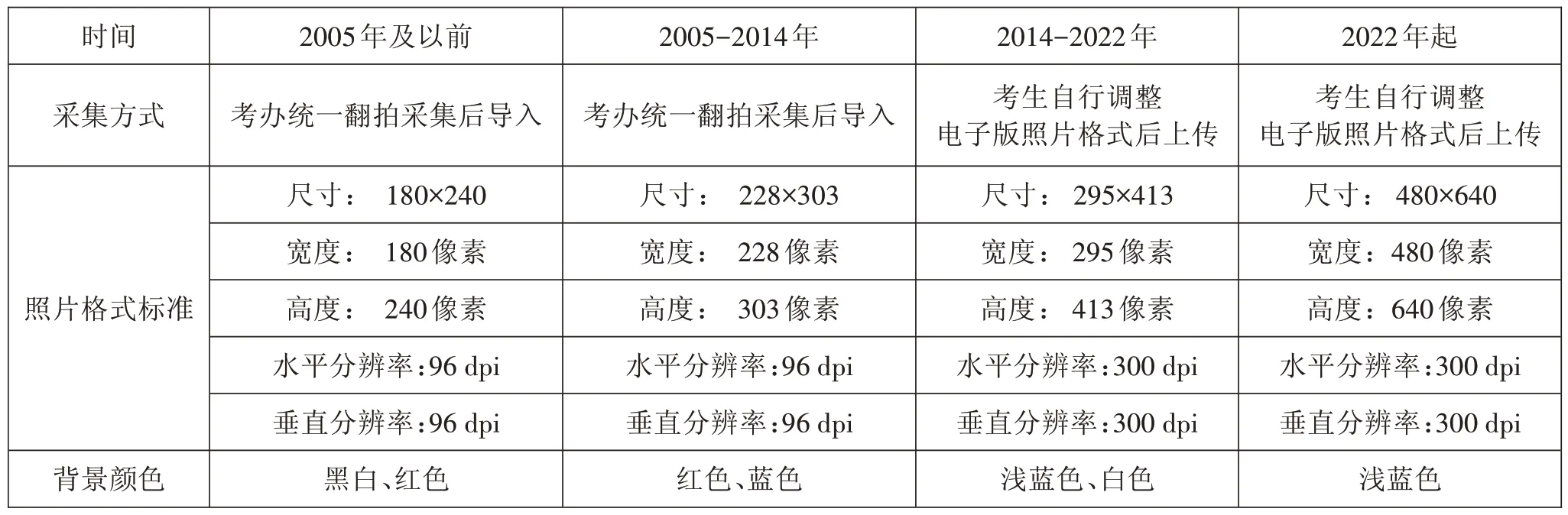
表2 考生头像照片格式标准演变示例
3.过时无效数据
数据时效性是与时间相关的,表示数据是最新有效的,可以描述客观实体。反之,过时无效数据是指由于其时间久远,已不再准确、不应参与到正常处理的、已经失去使用价值的数据。自考中的过时无效数据指数据本身是真实的,但随着时间的推移,其有效性在不断降低。主要有以下几类:
(1)过时的考生头像数据。由于考生参加考试数年,其容貌变化较大,无论是继续考试还是申请毕业,该头像照片均已无法成为核验其身份真实性的有效依据。
(2)不再活跃的“僵尸”数据。例如,某些院校将自考本科段的英语(二)科目合格成绩作为学士学位申请的必要条件之一,因此出现有考生注册准考证号后,仅报考英语(二)这一个科目,便不再参加该专业内的其他课程考试,成为“一次性考生”,这类考生本不应属于自考的在籍考生范畴,因此,这些数据不应出现在各项各类统计中。
(3)陈旧的联系方式。20世纪八九十年代初期固定电话还不普及,移动通讯的手段更是少之又少,于是在自考刚开考的相当长的一段时间内并未采集联系电话这一数据项。在后期开发系统开始采集之后,考生提供的联系方式多数为座机,但由于电话的升位、手机的普及,凡未及时更正的,也都成为了过时无效数据。通讯地址信息的数据变更存储也有类似的情况。
4.缺失完整性数据
缺失完整性数据是指数据集合中的数据不能全面地、较完整地描述客观事实,不能支持某种统计查询、关联计算和决策分析等应用。在自学考试制度建立初期,受当时技术手段的限制,考生从初次报考到申请毕业中间各个环节的信息采集均为手工填表、纸质管理,但因采集源不完整,又因缺乏完备的筛查手段而未得到及时更正,故而成为如今难以追溯的缺失数据。随信息技术的不断发展,考试的管理工作逐步由人工向计算机信息系统过渡,管理者做了大量的整理工作,尝试将各种各类纸介质档案转为数字化档案录入系统,但在这个过程中,又会因为各种各样的原因再次造成漏缺的数据。以考生身份证号为例,目前,考生一代、二代身份证号并存。截至2021年底,在籍考生中身份证号位数不满18位的考生占到考生比例的36.33%,其中一大部分是因为开考初期的老考生自始至终未采集,另一部分是因为不再参加考试且没有申请身份证号正常升位造成的。此外,早期毕业证书上均采用手贴照片的形式,而在实际系统中并未采集数字化信息,从而造成毕业生的照片信息缺失,进而导致毕业生身份认证时被质疑。随着信息时代的发展以及信息技术在社会各行各业工作中的全面应用,这一问题也日益凸显。
二、自学考试数据清洗的途径与办法
数据清洗(Data Cleaning)就是把“脏”的“洗掉”,发现并纠正数据文件中可识别错误的一道程序,是对数据进行重新审查和校验的过程,是按照一定的规则删除重复信息,纠正存在的错误,处理无效值和缺失值,以提高数据一致性、准确性[4]。自学考试的数据清洗,必须要从自学考试自身特点入手,采用技术层面的数据清洗,以及与考试管理方式改革紧密结合的政策调整等方法,对脏数据进行清理并防止“脏数据”的进一步累积。
(一)技术层面的数据清洁
1.重复冗余数据清洗
如上文所述,目前的自学考试按照专业管理的方式,一旦专业发生关停时,持有两个或以上不同专业的准考证号的考生便会重新注册新号。为避免重复的考生数据再次积累,可尝试借鉴其他省市“一号通”概念,即一名考生自始至终仅有一个准考证号。对于这样的考生可以采用机器自动合并、手工确认的方式,将每个考生现有的多个准考证号进行并档操作。把多个准考证号归并到其中一个准考证号下,并将此准考证号作为唯一准考证号在今后的考试中使用。自动合并就是机器通过分析考生姓名、身份证号和头像照片等信息将确属同一个考生的不同准考证号归并到最新的一个号上,经考办专家审核后,提交给考生端,待考生本人确认无误,并档正式生效。对于姓名、身份证号不能完全匹配为同一考生的,可由考生自行补充相关准考证号信息,考办专家审核通过后并档生效。从而,完成多号归一的去重工作。
2.多重标准数据清洁
多重数据标准在清洗前首先要做的是统一标准,在唯一的标准下,才能有针对性地对不符合标准的数据进行过滤筛查,并制定清洗方案。根据教育部教育考试院2020年发布的《关于开展高等教育自学考试考籍管理基础信息归集工作的通知》中的要求,统一准考证号采集标准,报考期间凡不符合标准的考生在登录系统时,会自动赋予新的准考证号,老准考证号下的考生个人以及成绩的各项信息经过一系列审核通过后,归并到新准考证号下,供日后使用。根据教育部教育考试院2021年发布《关于做好高等教育自学考试毕业证书电子注册图像采集工作的通知》中的要求,统一照片格式标准,在办理毕业期间,凡老考生成功申请并由考区、市考办审核通过的,须上传符合标准的近期头像,经过系统人像对比和人工专家审核,确属一人的方可准予毕业,图像被记录到毕业生库。新考生在注册准考证号时,即按照此文件标准上传图像。对于已经毕业的考生采用按照标准扫描其毕业生登记表上的照片信息、上传至毕业生库中的方法,进一步完善毕业生核验信息,为学历认证提供基础。
3.无效、缺失数据清洗
对于过时的无效数据,最重要的是保持数据的时效性,数据的时效性提高之后,缺失数据也会及时得到补充。为此,在考生服务系统中增加了信息更正环节。考生每次登录时,系统都自动弹出对话框,引导考生核对、更新对时效性要求比较高的相关信息。例如,考生需要将15位身份证号升至18位时,除填写相关信息外,还须上传佐证材料,之后考生服务系统会向公安部门身份证认证系统申请核验,最后通过考区和市考办的审核合格的方为更正成功。如考生修改联系电话,那么系统会向其手机号发送验证信息,确保其提交信息的准确性。通过长期的、反复的、大量的更正操作,无效或缺失数据的比例会逐渐减少,在一定时间内都未申请修改的,将被其定义为“僵尸数据”,并转移至不活跃数据表中,待日后激活使用,以提高系统运行效率。
(二)政策层面的数据清洗
1.转变专业管理模式
自学考试多年来一直采取专业管理的模式,考生的报考信息管理是按照从专业到课程的二维结构实施的。若出现上述关、转的专业,为了从根本上改变数据冗余,要将原来的专业管理模式调整为课程管理模式,由原来的一考生一专业一准考证号,改为一考生一准考证号多专业,即考生用唯一的准考证号选择不同专业的课程参加考试。最后,将已取得合格成绩的历史课程与现行某专业计划找出对应替代关系,按照该专业要求筛选合格课程申请毕业。已毕业考生所有个人及成绩信息归档到毕业生信息中。从源头杜绝一人多号的重复数据和冗余数据产生。
2.统一数据标准体系
在规范数据标准问题上,首先要加强数据标准的顶层设计,尽量满足唯一性、稳定性、可拓展性、前瞻性和共享性标准规范要求。所有的业务系统均应建设在统一数据平台基础之上。逐步统一数字化基础管理和安全的数据标准体系,统一与国家考办间的标准资源,完善跨省数据标准体系。通过建立统一的数据标准体系将为自考业务的创新和事业发展营造有利的环境。
3.保障数据内容真实
从技术上增加校验维度,提高数据标准的精度,可保证数据格式属性的准确性。但对于数据本身的真伪,需要在其他单位或部门的配合下,才能保障其内容的真实性。因此,首先需要使用身份证识别设备或人脸识别设备等,核实新进入系统的考生身份号以及姓名的真伪,防止冒名顶替考试的事件发生。其次,需要联合学信网,在考生毕业申请前,先确认该考生前置学历的真伪,杜绝假冒前置学历的现象。最后,为保证所采集数据真实有效,增加考生到考区提交佐证材料的环节。
三、结语
本文对自学考试现有“脏数据”的类型进行分析,分别从技术和政策修订的角度初步构建了数据清洗策略,设计了数据清洗流程。在自学考试不断发展的进程中,应当从提高清洗精准度、清洗效率和调整相关政策等方面入手,建立更加完善的脏数据发现举证机制、审核认定机制以及纠错更新机制等[5],以进一步提高自考数据质量,让清洁的数据始终作为信息管理的优质基础,为决策的制定提供有力保障。
猜你喜欢
城市道桥与防洪(2022年4期)2022-07-01 06:04:12
小学生学习指导(当代教科研)(2021年6期)2021-05-23 13:24:54
开放教育研究(2021年2期)2021-03-31 03:59:20
甘肃教育(2020年2期)2020-09-11 08:00:46
艺术品鉴(2020年6期)2020-08-11 09:36:46
当代陕西(2019年8期)2019-05-09 02:22:48
动漫星空(兴趣百科)(2019年3期)2019-03-07 07:23:10
中学科技(2017年5期)2017-06-07 13:01:01
专用汽车(2016年4期)2016-03-01 04:13:43
中学科技(2015年6期)2015-08-08 05:35:38
