
融合改进FPN和注意力机制的规范穿戴工作服识别方法
2023-02-14 06:01翟永杰张祯琪陈年昊
电力科学与工程 2023年1期
翟永杰,张祯琪,陈年昊
(华北电力大学 自动化系,河北 保定 071003)
0 引言
实现智能化的规范穿戴工作服识别对于电力生产安全的保障具有重要意义。将深度学习技术应用于作业人员规范穿戴工作服的识别,可以减少人工成本的投入,提高工作效率。
受监控图像像素较低、图像失真、目标被遮挡等情况影响,一些不规范穿戴情况难以被智能算法准确识别。所以,目前基于图像识别算法的研究基本都是针对安全帽佩戴[1,2]和输电线路[3,4],而在作业人员着装规范性的识别方面尚未有显著的成果。
文献[5]提出了基于HOG和HOC提取形状、颜色特征并结合 SVM 分类器的变电站作业人员服装规范性识别方法,该方法实现了复杂背景下的着装规范性识别。相比传统目标检测算法,该方法具有较高的识别精度,但依旧有提升空间。
文献[6]提出了一种基于样本Q邻域敏感度的径向基神经网络的着装识别算法。通过优化参数改进传统的RBFNN,该算法在提高模型的检测精度和鲁棒性能的同时降低其漏警率;但是,该算法的检测速度较慢。
文献[7]提出了一种基于Faster R-CNN[8]的穿戴识别方法:采用多特征层融合结合多尺度检测的改进方法,提高了模型的识别精度和鲁棒性能。但是,该算法检测实时性较低,不适用于实际应用。
文献[9]提出了一种基于Faster R-CNN的规范穿戴工作服的检测算法:将L2正则项引入损失函数中,提高了模型的训练收敛速度。该模型有较好的泛化能力和鲁棒性能,准确率和实时性相较于基线模型都有所提高。
文献[10]提出了一种基于 YOLOv5的工作服规范穿戴识别检测算法。该算法的思想是:修改YOLOv5中检测模块输出层的维度;以算法在公开数据集上得到的预训练模型作为基础,将实际监控图像作为训练集进行训练,并对数据集进行数据增广;通过调整模型的超参数,使得最终得到的算法模型有较好的查准率和查全率。但是,该模型无法检测出工作服的材质是否符合要求,并且角度和视线遮盖的问题对检测的准确度有较大的影响。
综上所述,目前基于深度学习的工作服规范穿戴识别方法仍存在一些问题,例如对小目标的识别精度不高、模型鲁棒性能和泛化能力较低、实时性不强等。本文通过在基础的Faster R-CNN模型中加入改进特征图金字塔网络(Feature pyramid networks,FPN)[11]模块和注意力机制[12]模块,从不同的方面提高算法模型对目标的识别精度。
1 改进的Faster R-CNN算法
针对当前基于Faster R-CNN的规范穿戴工作服识别算法在目标较小、目标被遮挡时识别效果较差的问题,本文提出了一种融合改进FPN和注意力机制的目标检测算法。
如图2所示,本文模型分为3部分:特征提取部分,候选区域选取部分,回归分类部分。图1中:ResNet50为一类卷积神经网络;fc为全连接层;区域候选网络(Region proposal network,RPN)结构和Two MLPHead结构是Faster R-CNN网络的组成部分。

图1 融合改进FPN和注意力机制的目标检测算法模型Fig. 1 An object detection algorithm model combining improved FPN and attention mechanism

图2 改进的特征图金字塔网络Fig. 2 Improved feature pyramid networks
本文模型以ResNet50网络为基础网络,在其中加入了注意力模块。输入图片经ResNet50网络和注意力模块后,传入改进的FPN结构中;将得到的融合后的特征图作为特征提取部分的输出,传入候选区域选取部分中。将特征图与RPN选出的候选框一起送入RoI align结构[13]中,得到固定大小的特征矩阵;再通过Two MLPHead结构进行展平,通过全连接层,得到了候选区域选取部分的输出。最后将候选区域选取部分的输出内容分别传入2个全连接层,得到了模型识别出的目标类别参数和边界框回归参数。
本文算法的核心,是将基础Faster R-CNN算法中的RoI pooling层[14]更换为RoI align层,并加入了改进的FPN结构和注意力模块,进而实现模型识别精度的提高。
1.1 Faster R-CNN算法
Faster R-CNN算法是基于 Fast R-CNN和R-CNN进行改进得到的双阶段目标检测算法。
Fast R-CNN虽然实现了在R-CNN的基础上大幅度提升检测速度,但是由于其依旧采用SS算法[15]生成候选区域,所以模型的检测耗时仍旧较长,无法满足实时检测的需求。Faster R-CNN算法通过RPN结构生成候选框,减少了冗余,实现了模型训练速度的进一步提升。
Faster R-CNN算法的步骤为:首先将图像输入卷积神经网络中,得到相应的特征图;然后使用RPN结构生成候选框并将其投影到先前生成的特征图上,从而获得相应的特征矩阵;最后将生成的特征矩阵通过RoI pooling层和一系列全连接层运算得到预测结果。
1.2 改进的FPN
在Faster R-CNN网络模型中,输入图像通过基础卷积神经网络进行特征提取,从而得到单尺度特征图,然后将得到的特征图传入模型中的RPN结构和RoI pooling层进行预测。
通过神经网络提取单一深层特征图进行网络训练,可以使网络得到较强的特征表达能力。这种方法对于较大目标的分类和定位精度较高,但无法准确识别小目标。这是因为在图像经过深层卷积神经网络进行大量卷积运算和池化运算的过程中,网络特征层的感受野会逐渐增大、分辨率逐渐降低,容易造成小目标的漏检。
与深层特征不同,浅层神经网络中得到的低层特征分辨率高且包含信息多,其有利于小目标的检测。因此,将不同尺度的特征进行融合,可以在维持对大目标识别精度的基础上,提高模型对小目标的识别精度。
为提高模型算法对小目标的检测精度,本文在Faster R-CNN的基础上加入改进的FPN。基础的FPN结构通过将高层特征与低层特征进行自上而下的的融合,提高了输出的低层特征的语义性。本文改进的FPN结构如图2所示。从图2可以看出,模型对基础FPN输出的P2、P3、P4、P5进行了自下而上的融合,从而提高了高层特征的分辨率。
1.3 注意力机制
通过现场监控拍摄得到的数据图像,其像素通常较低,存在目标被遮挡、光线不好等问题。为减轻上述影响因素对模型识别的干扰,本节引入了注意力机制,通过降低背景权重、提高目标部分的权重,实现模型识别精度的进一步提高。
在Faster R-CNN模型中,输入特征图中的所有通道权重都相同,即每个通道对于模型而言重要程度相同;这会使得模型使用大量算力对背景部分进行运算,而对目标部分的运算不足。
压缩和激励网络(Squeeze-and-excitation networks,SENet)模块[16]通过赋予特征图中各个通道不同的权重,令包含目标的通道权重增高、背景相关通道权重降低,使得模型能够增加对目标相关通道的运算,从而提高模型的特征表达能力。
在SENet的结构中,输入的特征图首先通过自适应平均池化层,得到全局感受野,其中包含了特征在通道维度上的全局信息。然后,将全局感受野通过2个全连接层和ReLU激活函数,使得模型能自动学习通道特征。最后,通过sigmoid函数将所得值转换到[0,1]范围内,作为最终权重;将最终权重与最初的输入特征相乘,结果即为经过SENet处理后的特征。
2 仿真性能测试
2.1 实验参数与评价指标
实验计算硬件条件:操作系统为Ubuntn 16.4;GPU为Geforce RTX 1080Ti显卡;CUDA版本为11.3。
实验计算软件条件:以Python3.7为程序开发语言;以Pytorch中的Faster R-CNN代码框架为基线模型代码,对其中的代码进行修改。
实验中,主要调整的超参数有学习率[17]和一次传入图像数量[18]。
学习率可以理解为每一次迭代时参数更新的幅度。学习率过小会导致模型收敛速度过慢,造成模型梯度下降至局部最小点;而学习率过大会导致模型难以收敛,出现震荡。通过不断调整学习率,得到本文模型在实验中的最优学习率为0.016。
一次传入图像数量是指模型一次处理的图像数量。一次传入图像数量过少,会导致模型梯度变化的准确性过低,使得模型的收敛速度过慢;而一次传入图像数量过多,会导致模型占用内存空间过大,对硬件要求高。通过不断调整一次传入图像的数量,最终确定该参数的最优取值为4,即模型一次同时处理4张传入图像。
其他实验参数设置如下:动量,0.9;权重衰减值,0.000 5。
本文模型选取的评价指标为:当候选框和真实框的交并比取值为0.5时,各个类别的精度均值(Average precison,AP)以及所有类别的平均精度均值(Mean average precision,mAP),即AP50和mAP。
2.2 数据集与数据增强
实验使用的数据集中共有2 645张图像,包含了不同的场景、不同目标大小、不同亮度的样本。
将数据集内标注分为4类,分别为:佩戴红袖章的监护人员(badge),正确穿戴工作服的人员(clothes),不规范穿戴工作服的人员(wrong clothes),在场人员(person)。
在原有图像中,wrong clothes类别的目标图像仅占总量的 11%。考虑数据集长尾分布会导致模型训练时过拟合,从而使识别精度过低;因此,将数据集中的部分图像进行数据增强[19]。本文通过对图像进行翻转、旋转、裁剪、移位、模糊、色彩转换、添加噪声等操作,对有限的数据进行扩充。通过对图像进行数据增强,将图像增广至4 740张,实现了数据集中各类别目标数量的均衡分布。
数据增强后,将数据集中的图像划分为 80%训练集,10%验证集和10%测试集。
2.3 实验验证
2.3.1 对比实验
用 YOLOv3-SPP 算法[20]、SSD 算法[21]、Retina Net算法[22]、基础的Faster R-CNN算法以及本文模型分别进行训练和测试。
实验得到4个目标类别的识别精度AP50和所有类别的平均精度均值mAP如表1所示。

表1 不同模型的对比实验结果Tab. 1 Comparative experimental results between different models
由表1可知,YOLOv3-SPP算法对小目标的识别精度较高,但整体的检测精度较低;SSD算法整体识别精度较低;RetinaNet算法整体识别精度都较高,但仍有提升空间;基础的Faster R-CNN算法对各类别目标的识别效果都较差;相比之下,本文提出的识别模型的精度明显优于上述各类算法,检测漏检、误检的情况较少。
2.3.2 消融实验
本文通过数据增强来平衡数据集中各类别目标的数量,并通过在基线模型中加入改进的 FPN结构、SENet模块等方法,实现了模型对规范穿戴工作服的识别精度的提升。
表2展示了本文模型消融实验的结果,由表2可以看出,在Faster R-CNN中加入FPN结构后,各类别的平均精度均值从原先的76.2%提升至92.4%。

表2 不同模块的消融实验对比Tab. 2 Comparison of ablation experiments of different modules
以加入FPN的Faster R-CNN模型为基线模型。在基线模型中加入改进的FPN结构后,各类别的平均精度均值从原先的92.4%提升至93.9%。在基线模型中加入SENet模块后,各类别的平均精度均值从原先的92.4%提升至94.2%。
在基线模型中加入改进的FPN结构和SENet模块后,各类别的平均精度均值从原先的 92.4%提升至94.5%。
与基础Faster R-CNN模型相比,本文提出的融合改进FPN和注意力机制的目标检测算法模型各类别的平均精度均值从原先的 76.2%提升至94.5%,其中,badge一类的AP50提升了14.9%,clothes一类的AP50提升了10.5%,wrong clothes一类的AP50提升了38.9%,person一类的AP50提升了9.0%。
图3中展示了本文提出模型的检测效果。由图3中可以看出,在加入改进的FPN结构和注意力机制后,模型在大目标无遮挡、小目标无遮挡、大目标被遮挡、小目标被遮挡、目标背景复杂等情况下的识别效果都较好。
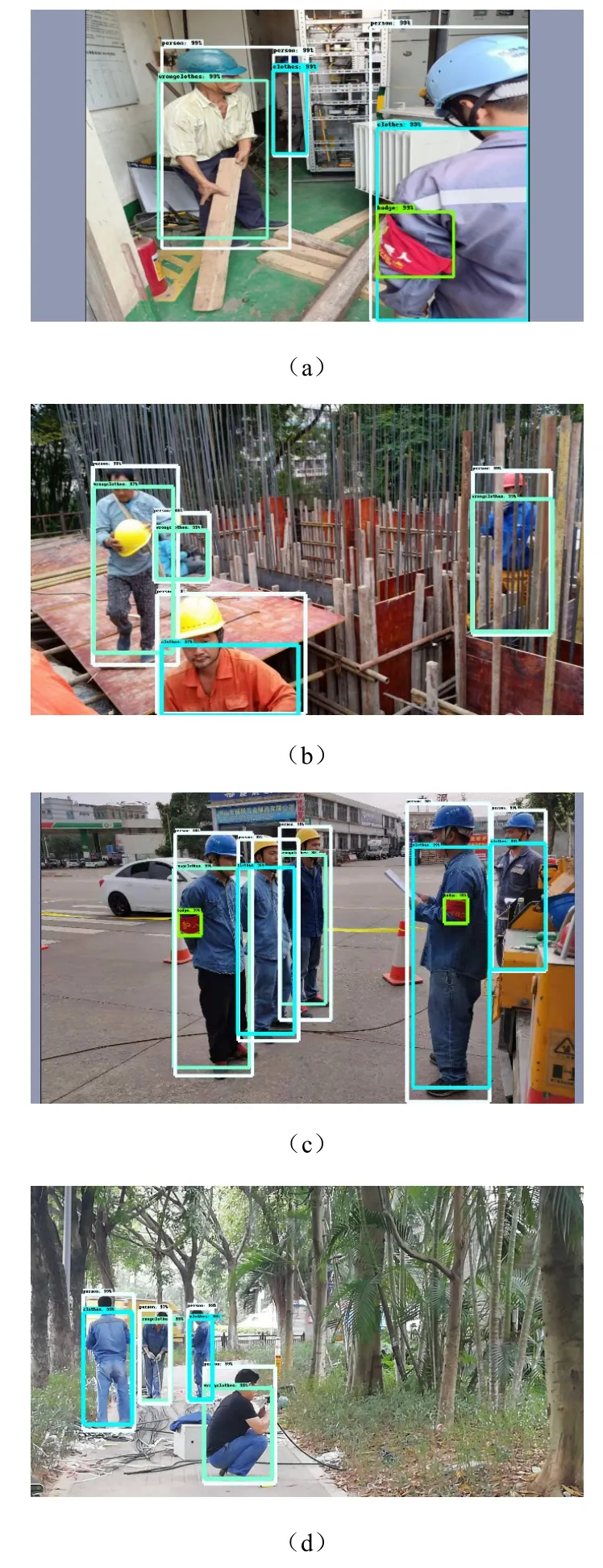
图3 模型实际检测效果:(a)—(c)各类目标被遮挡情况,(d)各类目标无被遮挡情况Fig. 3 Detection effects of the model: (a) — (c) the situation that different targets are obscured, (d) the situation that different targets are not obscured
3 结论
本文基于Faster R-CNN算法,设计了一种融合改进FPN和注意力机制的规范穿戴工作服识别方法。
通过在 Faster R-CNN的基础上加入改进的FPN结构,将ResNet50网络的输出特征传入改进的FPN结构中进行双向融合,使得模型对小目标的识别精度有一定程度的提高。通过在 Faster R-CNN中加入SENet注意力模块,降低背景权重、提高目标部分的权重,实现模型对复杂背景下目标识别精度的提高。
通过在包含4个类别的数据集上进行实验,本文模型较基础的Faster R-CNN模型有了18.3%的检测准确率提升。本文模型具有较好的鲁棒性能和泛化能力。
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
小雪花·成长指南(2022年1期)2022-04-09
一重技术(2021年5期)2022-01-18
中学生数理化·八年级物理人教版(2019年9期)2019-11-25
当代陕西(2019年10期)2019-06-03
中学生数理化·八年级物理人教版(2019年12期)2019-05-21
电子制作(2018年11期)2018-08-04
数学小灵通·3-4年级(2017年9期)2017-10-13
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
