
CoT-TransUNet:轻量化的上下文Transformer医学图像分割网络
2023-02-14 10:31柏正尧
计算机工程与应用 2023年3期
杨 鹤,柏正尧
云南大学 信息学院,昆明 650500
目前,基于CNN的方法在医学图像分割领域取得了优异的成绩。现有的医学图像分割方法主要依赖于U形结构的全卷积神经网络[1-3]。其中最典型的U形结构网络,U-Net[1]由一个带跳跃连接的对称编码器-解码器组成。该网络为了减少下采样过程中造成的空间信息丢失。通过跳跃连接来增强细节保留。并在许多医学图像分割任务中获得了巨大的成功,占据着主导地位。按照这一思想,出现了许多U-Net的变体,如3D UNet[4]、Res-UNet[5]、U-Net++[6]、U-Net3+[7]用于各种医学图像分割。
在上述网络中,由于卷积运算的固有局限性,纯CNN的方法很难学习明确的全局和远程语义信息交互[8]。为了克服这样的局限性,现有研究建议建立基于CNN特征的自注意机制[9-10]。Transformer在建模全局上下文方面功能强大[8]。但是纯Transformer的方法也存在特征丢失的问题。于是,基于CNN架构与Transformer模块相结合的方法得到了越来越广泛的关注。例如,文献[11]利用自注意机制来增强卷积算子,将强调局部性的卷积特征映射与能够对全局进行建模的自注意特征映射连接起来。DETR[12]使用一个传统的CNN骨架网络来学习输入图像的二维表示,编码器和解码器都是由Transformer构成。其中,TransUNet[8]则将这种方法应用到医学图像分割领域,同时具有Transformer和CNN的优点。将Transformer作为医学图像分割任务的强编码器,与CNN相结合,通过恢复局部空间信息来增强更精细的细节[8]。但TransUNet采用传统CNN作为特征提取器和上采样器,在特征提取和上采样阶段,卷积中感受野太小的局限性依然存在。其中,Swin-UNet[13],一种基于纯Transformer的U-Net形的医学图像分割网络。把标记化的图像块通过跳跃连接馈送到基于Transformer的U形En-Decoder架构中,以进行局部和全局语义特征学习。但是纯Transformer的方法,存在特征丢失的问题。ViT[14]可以像Transformer一样直接通过自注意机制处理图像块或CNN输出。此外,文献[15]还提出了一种局部自注意模块,可以完全取代ResNet架构中的3×3卷积。但是这些设计都忽略了相邻keys之间的丰富上下文。于是出现了一种新型的Transformer式模块,CoTNet[16],其充分利用了输入keys之间的上下文信息来指导动态注意矩阵的学习[16]。在传统自注意学习基础上,将局部上下文信息与全局上下文信息融合起来,更好地增强视觉表达能力。
为了解决现有医学图像分割网络中卷积的感受野太小以及对局部上下文信息利用不足的问题。提升现有医学图像分割网络的精度和速度。CoT-TransUNet在编码器部分,采用CoTNet作为特征提取器以提取更丰富特征。并把Transformer的层数增加到了16层。Transformer块把特征图编码为输入序列后送入解码器中进行上采样。在解码器部分,上采样器中采用具有更大感受野的CARAFE算子,在保持轻量化的同时又能基于内容上采样。最后,通过跳跃连接实现编码器和解码器在不同分辨率上的特征聚合。在TransUNet的基础上结合以上改进,更好地提升了网络的性能。在多器官分割任务中,以DSC和HD为评价指标,对8个腹部器官(主动脉、胆囊、脾脏、左肾、右肾、肝、胰腺、脾脏、胃)进行评价,并在可视化结果中用不同的颜色对8个腹部器官进行标注。CoT-TransUNet相对于TransUNet,DSC提升了约0.9%,HD提升了约5.7%。
1 相关工作
1.1 医学图像分割中CNN与Transformer的结合
为了解决卷积运算感受野太小而对全局建模产生的不利影响[8]。Chen等人提出了一种新网络,TransUNet[8]用于代替原有医学图像分割方法中的U-Net[1]和U-Net的一些变体。TransUNet从序列到序列预测的角度建立了自注意机制[8]。但是Transformer也存在特征分辨率损失的问题。于是,TransUNet采用CNN和Transformer相结合的思想,利用来自CNN特征的详细高分辨率空间信息和Transformer编码的全局上下文[8],并采用U形设计。先使用CNN进行特征提取,然后将提取到的特征映射中的标记化图像块编码为用于提取全局上下文的输入序列[8]。再对编码后的特征上采样并与之前高分辨率的CNN特征结合。既在一定程度上解决了卷积的局限性,又防止了特征的丢失。在多器官分割任务中,性能也优于之前的架构。
1.2 基于CNN架构的Transformer风格模块
为了解决Transformer特征丢失的问题,以及更充分地利用局部上下文信息。Li等人提出了一种新的Transformer风格的模块,即上下文Transformer(CoT)块[16]。如图1所示。首先通过k×k卷积对输入K进行上下文编码,从而实现输入的局部(静态)上下文表示。然后将K与Q合并在一起,再通过两个连续的1×1卷积学习动态多头注意矩阵[16]。此矩阵是由Q的信息和局部上下文信息交互得到的,而不只是建模了Q和K之间的关系。也就是说通过局部上下文信息的引导,增强自注意机制。然后再与特征映射后的V相乘,得到输入的全局(动态)上下文表示。最后将静态和动态上下文表示进行线性融合得到输出。使用CoT块替换ResNet结构中的3×3卷积后得到CoTNet,在图像识别,目标检测和实例分割实验中,性能都得到了提升。
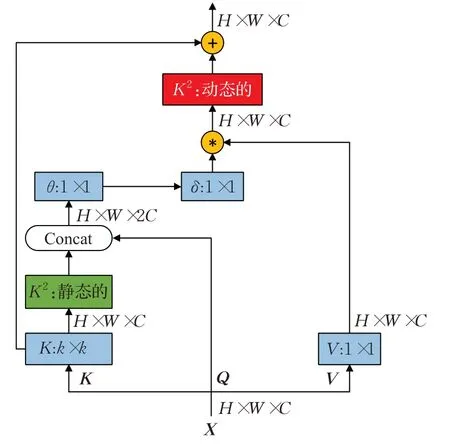
图1 CoT块结构图Fig.1 CoT block structure diagram
1.3 CARAFE上采样算子
针对目前应用最广泛的最近邻插值法和双线性插值法,以及反卷积的上采样方法。前两个主要关注亚像素邻域,无法捕捉丰富语义信息。而反卷积的方法忽略了低层的内容,无法对局部变化有很好的反应能力,并且需要大量参数。Wang等人提出了一种CARAFE[17]上采样算子。其通过加权组合在以每个位置为中心的预定义区域内重组特征,以内容感知的方式生成权重,每个位置都有多组这样的上采样权重。然而,这些权重并不作为网络参数学习,而是使用一个轻量级的,带有softmax激活函数的全卷积模块来实时预测。因此,能在大接收域内聚合信息的同时,又能实时适应特定实例的内容,并能保持计算效率。在不同的任务中,CARAFE上采样算子仅通过一小部分额外参数和计算工作就取得了显着的进步。在CoT-TransUNet中,每个CARAFE上采样块都由一个CARAFE上采样算子、一个3×3卷积、一个ReLU层组成,并级联多个这样的上采样块构成解码器。
2 方法
CoT-TransUNet的总体结构如图2所示。对于一个输入图像,首先将其送入混合编码器模块并由CoTNet提取特征,接着通过Transformer块将特征图编码成用于提取全局上下文的输入序列,然后采用上采样模块对编码后的特征上采样并通过跳跃连接与编码器中的高分辨率特征结合,恢复到原始分辨率,以设计一种轻量化的端到端U形网络结构,从而充分利用特征提取阶段的局部上下文信息,增加上采样阶段的感受野以及增强细节保留。通过这三个模块的结合,并从分割结果可以看出,CoT-TransUNet实现了更好的边缘预测,获得了优于其他网络的分割性能。

图2 CoT-TransUNet的总体框架Fig.2 Overall framework of CoT-TransUNet
2.1 混合编码器
2.1.1 特征提取
CoTNet:如图1所示,对于输入的特征图,keys、queries、values分别定义为K=X、Q=X和V=XWv。其中,Wv是V的权值矩阵。在k×k空间网格内对所有相邻keys进行k×k组卷积,所得到的K1∈RH×W×C代表了相邻keys之间的局部上下文信息,于是将K1作为输入X的静态上下文表示。然后将和Q合并,再通过两个连续的1×1卷积(带ReLU激活函数的和不带激活函数的)获得注意矩阵D[16]:

然后,把获得的注意力矩阵D与V点乘,得到,代表了全部上下文信息,于是将作为输入的动态上下文表示:

最后,将静态上下文表示和动态上下文表示相加,得到输出。

用CoTNet-50作为特征提取器,生成特征图后输入到Transformer块中编码成序列。
2.1.2 图像序列化
Transformer块:对于一张图像X∈ΦH×W×C,其空间分辨率为H×W,通道数为C。将输入X重构为一些2D的,其中每个patch的大小为P×P,,即输入序列的长度。将已经矢量化的XP映射到隐藏的N维空间中[8]。再把特定的位置嵌入添加到patch嵌入中以保留位置信息,patch嵌入表示如下面公式所示:

其中,R∈Φ(P2·C)×N是patch的嵌入投影,Rpos∈ΦM×N是位置嵌入。
Transformer层是由L层的多头自注意(MSA)和多层感知器(MLP)块组成。因此,第λ层的输出表示为:
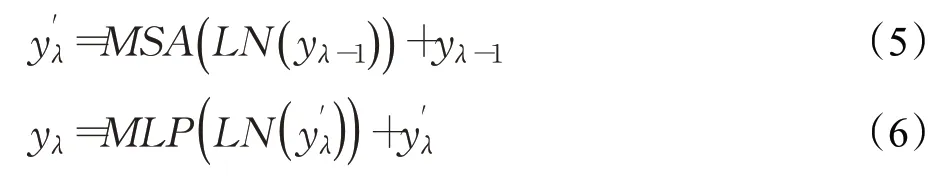
其中,LN(·)为层归一化算子,yL为编码后的图像表示。如图2(1)所示。
通过上述方法便可以得到patch的嵌入。CoTTransUNet使用CoTNet为输入生成特征映射。再对从CNN特征图中提取的1×1个patch进行嵌入,而不是对原始图像进行嵌入[8]。
2.2 解码器
解码器部分是由一个级联上采样器构成的,将从编码器输出的隐藏特征的序列重构为后,通过级联多个CARAFE上采样块将分辨率恢复到H×W的全分辨率。如图2(2)所示。
上采样核预测模块:对于形状为H×W×C的输入特征图,为了减少后续步骤的参数和计算量,首先用一个1×1的卷积将通道数压缩到Cm。然后把第一步中压缩后的特征图,利用一个kencoder×kencoder的卷积层来预测上采样核,上采样核尺寸为kup×kup,输出的通道数为Cup=σ2ku2p。在此过程中,该编码器的参数为kencoder×kencoder×Cm×Cup,可以看出,增加kencoder可以扩大编码器的感受野,并在更大的区域内利用上下文信息,但是,计算复杂度也会随着核大小的平方而增加,而更大的核带来的好处却不会增加。因此,kencoder=kup-2是性能和效率之间的一个很好的权衡[17]。然后把通道维在空间维展开,得到形状为σH×σW×ku2p的上采样核。并利用softmax进行归一化,使得卷积核权重和为1。
特征重组模块:对于输出特征图中的每个位置,将其映射回输入特征图,取出以该位置为中心的kup×kup的区域,并与预测出的该点上采样核作点积,得到输出值。达到相同位置的不同通道共享同一个上采样核的目的。并且,由于内核归一化,CARAFE没有进行任何缩放和改变特征图的均值。因为来自局部区域相关点的信息得到了更多的关注,重组后的特征图拥有更强的语义信息。
2.3 评价指标
对于分割问题,采用Dice相似系数(Dice similariy coefficient,DSC)和Hausdorff距离来评估模型的分割性能。并通过对参数数量、计算复杂度(GFLOPs)和推理时间(ms)的比较来评估模型的轻量化。
2.3.1 Dice系数
Dice系数是衡量两个集合相似度的指标,用于计算两个样本的相似度,取值范围是[0,1],值越大说明分割结果与Ground Truth越接近,分割效果越好。如下所示:
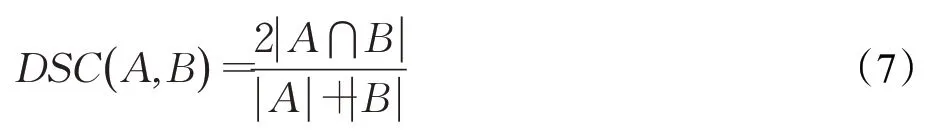
式中,A和B分别表示Ground Truth和预测的结果。
2.3.2 Hausdorff距离
Hausdorff距离是在度量空间中任意两个集合之间定义的一种距离。表示分割结果与Ground Truth两个点集之间最短距离的最大值。如下所示:
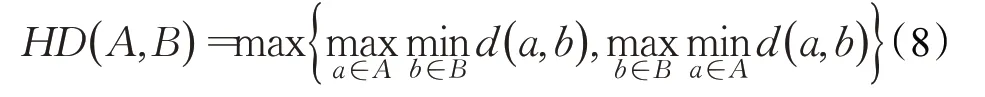
式中,d(a,b)表示a、b两点之间的欧氏距离。
3 实验
3.1 数据集
使用的数据集是MICCAI 2015多图谱腹部标记挑战赛中的Synapse多器官CT数据集。此数据集收集了30例患者,一共3 779张轴向腹部临床CT图像。按照文献[8,18],随机将18个样本(2 211张轴向切片)做为训练集,12个样本做为测试集。测量其DSC(平均Dice相似系数,单位:%)和HD(平均Hausdorff距离,单位:mm)作为最终的评价指标。并采用DSC作为评价指标,分别对8个腹部器官(主动脉、胆囊、左肾、右肾、肝脏、胰腺、脾脏、胃)进行评价。
3.2 实施细节
整个实验是在Python 3.7和Pytorch 1.8.0上实现的。实验开始阶段都对数据进行了随机翻转和旋转的预处理,以增强数据的多样性。输入图像的大小设置为224×224,patch size设置为16,batch size设置为24,在解码器部分连续级联四个CARAFE上采样块以达到完全分辨率。框架采用CoT-TransUNet-50。在编码器设计中,将CoTNet-50、CoTNet-101与ViT[14]组合,记作C50-ViT和C101-ViT,并且都在ImageNet[19]进行了预训练。对于模型,使用交叉熵损失(cross entropy loss,CE)和Dice损失(Dice loss)的组合来训练CoT-TransUNet-50,如下式所示:
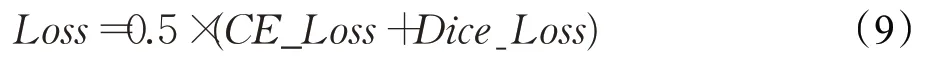
并且采用学习率为0.01,动量为0.9,权重衰减为1E-4的SGD优化器进行训练,迭代的默认次数为14 000次。实验是在单个12 GB内存的Nvidia RTX3060 GPU上进行的。
3.3 实验结果
在Synapse多器官分割数据集上进行实验,并与6个之前的先进技术:U-Net[1]、Swin-UNet[13]、V-Net[20]、Att-UNet[21]、DARR[18]、TransUNet[8]进行了对比结果如表1所示。CoT-TransUNet-50获得了最好的分割性能,分割精度达到了78.24%(DSC)和23.75 mm(HD)。与TransUNet相比DSC评价指标提高了约0.9个百分点,虽然改进不大,但是在HD评价指标上却提高了约5.7 mm。如表2所示,在与目前几种主流的网络进行比较后,相比于其他引入注意力机制的网络,例如Swin-UNet[13]、TransUNet[8]。CoT-TransUNet-50的参数数量更少,推理时间更快,计算复杂度也更低,也更加轻量化。不同框架在Synapse多器官CT数据集的分割结果如图3所示。从图中可以看出,基于纯CNN的方法对边界信息不够敏感,容易出现过度分割的问题。例如,在第一行和第二行中,胃部被TransUNet[8]、Att-UNet[21]、U-Net[1]过度分割。基于纯Transformer的方法虽然对边界信息较为敏感(特别是胃部的分割),但是由于一些特征的丢失,容易出现分割不足的问题。例如,在第二行中,Swin-UNet[13]对胰腺的预测出现缺失,而CoT-TransUNet则正确预测了胰腺,并保留了很好的边界信息。实验结果表明,相比于TransUNet,以及其他基于纯CNN的框架,CoT-TransUNet更加注重边界信息,能实现更好的边缘预测。对于纯Transformer的方法,CoT-TransUNet既保证了对边界信息的敏感度,又防止了特征的丢失。在传统CNN中加入自注意机制[22-23]和Transformer后,将局部上下文信息和全局上下文信息相融合,提高了输出特征的表达能力,再通过Transformer编码以及U形结构的上采样恢复,从而获得更好的分割结果。
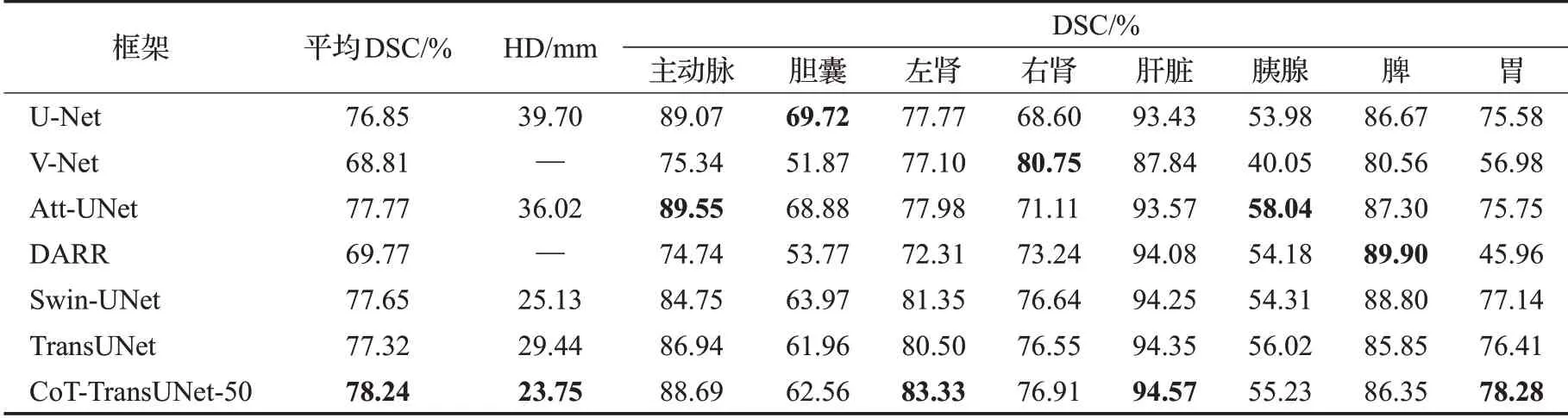
表1 Synapse多器官CT数据集上不同网络的分割精度对比Table 1 Comparison of segmentation accuracy under different networks on Synapse multi-organ CT dataset
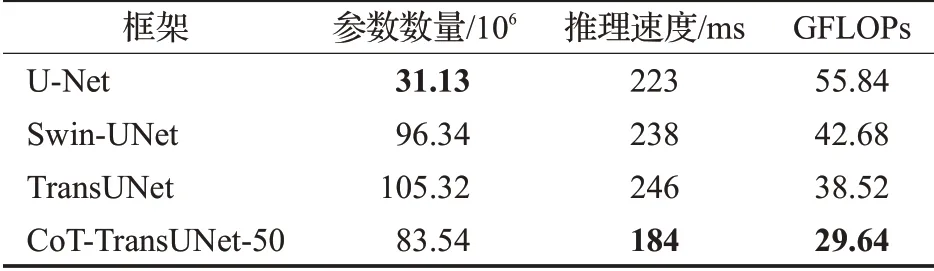
表2 与几种主流网络的对比Table 2 Compares with several major networks
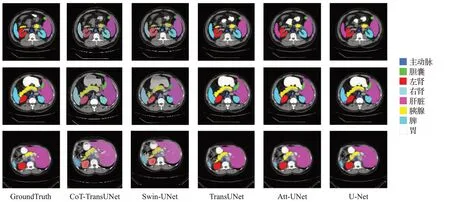
图3 不同框架的分割结果Fig.3 Segmentation results of different frames
3.4 分析研究
为了全面评估CoT-TransUNet框架的性能,并探究不同因素对其性能的影响。于是在Synapse数据集上对CoT-TransUNet进行了各种研究。包括结构的设计、输入图像的分辨率、CNN的深度、patch size的大小、模型的大小。
结构的设计:为了分析CoT块在编码器部分的重要性,通过在编码器、解码器、编-解码器中分别加入CoT块,以及不加入CoT块进行实验。实验结果如表3所示。在编码器中加入CoT块,即原网络中的CoTNet-Transformer混合编码器结构,可以获得更好的分割精度。为了分析CARAFE上采样算子在解码器部分的重要性,在解码器中分别采样CARAFE算子和2×上采样算子进行实验。结果如表4所示。在解码器中采用CARAFE上采样算子相比于2×上采样算子可以获得更好的分割精度。

表3 CoT块替换位置的消融研究Table 3 Ablation study of replacement position of CoT block 单位:%

表4 上采样算子的消融研究Table 4 Ablation study of upsampling operator单位:%
输入图像的分辨率:为了探究更高分辨率对分割性能的影响。在其他参数不变的情况下,对分辨率为512×512的图像进行实验。实验结果如表5所示。在保持patch size不变的情况下,增大分辨率导致Transformer的序列长度增加。文献[24-25]指出,增加有效序列长度体现出对鲁棒的改进。虽然模型的分割精度得到提升,但是计算成本过大。所以所有实验都是在默认分辨率(224×224)下进行。

表5 输入图像分辨率的研究Table 5 Study of input image resolution 单位:%
CNN的深度:由于卷积神经网络的灵活性,为了探究是否能推广到更深的网络层次。于是对CoT-TransUNet-101进行实验并与CoT-TransUNet-50比较。实验结果如表6所示。CoT-TransUNet-101并没有获得优于CoTTransUNet-50的分割精度。

表6 CNN深度的研究Table 6 Study of CNN depth 单位:%
patch size的大小:因为Transformer的序列长度与patch size的平方成反比[26]。patch size越小,序列长度越大。为了探究patch size对分割性能的影响。分别对24、16、8的patch size进行实验。实验结果如表7所示。减小patch size确实可以起到提升分割性能的作用[27-28]。按照TransUNet[8]、ViT[14]中的设置,CoT-TransUNet使用16×16作为默认值。

表7 Patch size大小的研究Table 7 Study of patch size 单位:%
模型的规模:最后,对不同模型大小的CoT-TransUNet进行了消融研究。主要有两种不同的CoT-TransUNet配置。“基础版”和“升级版”,按照TransUNet[8]、ViT[14],对于“基础板”,hidden size为768,Transformer层数为16,MLP size为3 072,注意力头数为12。“升级版”中,hidden size为1 024,Transformer层数为24,MLP size为4 096,注意力头数为16。如表8所示。由结果可知,模型越大,效果越好。但是计算成本的增加过大。所以,所有实验都采用“基础版的模型”。

表8 模型大小的研究Table 8 Study of model size 单位:%
3.5 讨论
在有Transformer参与的模块中,其性能受到预训练模型的严重影响。由于Google和CoTNet[16]都没有提供“CoTNet50/101-ViT”的预训练权重,只有采用退而求其次的方法,把CoTNet[16]在ImageNet上训练后提供的单个CoTNet-50/101的预训练权重和Google提供的ViT[14]预训练权重结合。由于这两个模块的权重不是从端到端的训练生成的,一定程度上影响了CoTTransUNet的性能。其次,实验中所用到的图像都是2D的,然而,医学图像的数据大多数是3D的。在未来的研究中继续探索,将CoT-TransUNet推广到3D医学图像分割中。
4 结论
针对现有医学图像分割网络中卷积运算感受野太小以及对局部上下文信息利用不足,所提出的CoTTransUNet在多器官分割任务中性能优于现有网络。在CoT-TransUNet中,首先,采用更注重局部上下文信息的CoTNet作为特征提取主干,为输入生成更好的特征图。其次,采用感受野更大并基于内容上采样的轻量化CARAFE算子进行上采样。最后,通过跳跃连接将编码器和解码器相连,以增强细节保留。在多器官分割任务的实验中也表现出更好的分割精度和更低的计算复杂度,证明可作为一般医学图像分割的一种替代网络。
由于使用的预训练权重并不是从端到端的训练生成的,一定程度上影响了网络的性能。下一步工作是解决预训练模型的问题,获得更好的预训练权重。其次就是继续优化模型结构,将CoT-TransUNet推广到3D医学图像分割中。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
网络安全与数据管理(2022年1期)2022-08-29
小学生必读(低年级版)(2021年10期)2022-01-18
数学物理学报(2021年2期)2021-06-09
数学物理学报(2021年1期)2021-03-29
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
应用数学(2020年2期)2020-06-24
家庭影院技术(2019年8期)2019-12-04
制造技术与机床(2017年7期)2018-01-19
