
改进YOLOv5的光伏组件热斑及遮挡物检测
2023-02-13 03:31魏卓航林培杰陈志聪吴丽君卢箫扬程树英
福州大学学报(自然科学版) 2023年1期
魏卓航,林培杰,陈志聪,吴丽君,卢箫扬,程树英
(福州大学物理与信息工程学院,微纳器件与太阳能电池研究所,福建 福州 350108)
0 引言
光伏组件由于工作需要长时间暴露在无遮挡的自然环境中,如果不能及时进行有效维护,将产生各种故障,热斑就是其中一种典型故障[1]. 当光伏组件受到遮挡后,遮挡部分的电池片流过的电流变小,在其他串联电池片的影响下成为负载,并将其他电池片产生的能量以热量的形式消耗掉,导致遮挡部分的电池片温度升高而产生热斑效应[2]. 单体电池片的不匹配、 短路、 裂缝、 组件表面局部脏污或遮挡都会引起光伏组件产生热斑. 热斑问题不仅影响光伏组件的发电效益, 甚至可以引发火灾,严重影响光伏系统的性能和寿命,因此,对热斑的实时检测和定位, 对光伏电站的维护工作有着重要价值.
由于热斑效应会引起电池片局部温度上升,故可使用红外热成像图像进行判断. 文献[3]采用Canny边缘检测算子检测红外图像下的热斑模块及其相关故障. 文献[4]采用光伏组件红外热图像的HOG特征和纹理特征进行分类,通过朴素贝叶斯分类器检测热斑. 文献[5]提出一种基于混合特征的光伏面板热斑检测和分类的支持向量机模型,采用数据融合的方法构造一种新的混合特征向量,取得了更好的检测效果. 近年来,深度学习在解决图像识别、 目标检测等问题上成效突出,学者们也将其应用于光伏故障检测和热斑识别上. 文献[6]提出改进Faster R-CNN的红外图像检测方法,将SpotFPN多尺度特征学习模块应用在二阶段目标检测网络中,提高了模型的检测精度. 文献[7]提出一种基于多尺度残差和注意力机制相结合的新型卷积神经网络 AMSRnet,训练识别自制的光伏组件红外图像热斑状态数据集,准确率高达 95%. 文献[8]提出直接利用相机拍摄可见光图片, 对光伏面板上的遮挡物进行检测,以便及时排除产生热斑效应的隐患,在检测准确率上也取得了不错的效果.
然而,红外热成像主要反映的是温度信息,无法正确体现物体的边缘、 纹理等细节信息,所以基本只能运用于热斑的检测与定位. 若结合可见光图片的信息,则可以在进行热斑检测与定位的同时, 对光伏面板上的遮挡物进行检测,进而对热斑形成的原因进行初步的判断. 随着红外热成像仪器的发展和进步,许多型号的红外成像仪已具备同时拍摄同位置下的红外和可见光图片的功能,为推动图像融合在光伏热斑检测方面的研究提供了便利.
综上所述,本研究提出一种基于深度学习的光伏组件热斑及遮挡物的检测方法,采用像素加权平均法融合红外和可见光图像,使用YOLOv5深度学习目标检测算法实现不同成因的热斑和遮盖物的检测与定位. 同时,针对多分类数据集训练中负样本量过多的情况,在算法中引入变焦距损失函数,达到突出正例的效果. 为了减小算法生成anchor box目标框的误差,改进模型目标框生成算法,使用IOU得分代替欧式距离作为聚类算法评判标准. 此外,对YOLOv5的网络结构进行轻量化改进,设计了融合坐标注意力机制的MobileNetCA特征提取网络,并将其应用到模型中,在降低模型体积的同时力求提升模型检测效果.
1 实验数据采集与处理
1.1 数据采集
实验数据集的拍摄仪器为FLIR T420,该仪器在拍摄时可同时输出同一位置的红外和可见光图像,输出分辨率均为320 px × 240 px,故在红外可见光图像融合时无需配准. 采集地点为福建省某大学微纳器件与太阳能电池研究所的光伏实验平台,采集时间选在晴朗天气上午9时至下午3时之间,拍摄时用树叶、 细沙、 硬纸片、 彩旗的倒影模拟实际情况中发生的遮挡与阴影,热斑主要由物体或阴影的遮挡和光伏面板间串内短路等原因产生. 拍摄共采集到红外和可见光图片各622张,并进行人工标注,按照热斑与遮挡物情况将数据集标签分为5类,具体如下: 1) 类型一, 有热斑产生但无遮挡物. 2) 类型二,有片状(如树叶,纸片)遮挡物,尚未产生热斑. 3) 类型三,有片状(如树叶,纸片)遮挡物并已产生热斑. 4) 类型四,有细沙遮挡并已经产生热斑. 5) 类型五,有细沙遮挡,尚未产生热斑.
标注共获得1 654个标签,分别为类型一389个,类型二353个,类型三301个,类型四215个,类型五396个. 其中类型一在实验中主要由组件短路或组件表面细小灰尘产生. 通过以上分类,模型可同时检测是否有热斑和遮挡物,以及遮挡物的形态,还可以凭借检测的信息进一步分析热斑产生的原因,为故障处理提供参考. 为了得到更准确的结果,具体拍摄实验中,需要不断对遮挡物的数量、 种类和位置进行变换,拍摄位置在距离光伏组件正前方2~8 m处,拍摄时随机变换角度. 拍摄效果如图1所示. 图中,红色数值表示最高温,蓝色数值表示最低温.

图1 拍摄所得的红外与可见光图片示例
1.2 红外可见光融合方法
选用像素加权平均法作为红外可见光图片融合方法,其原理是: 对红外图像的像素取相应权值a(a<1),则可见光图像的像素权值为1-a,然后加权平均得到融合图像的像素值. 比如,有需要融合的可见光图像的像素值为A,红外图像的像素值为B,则融合后图像的像素值就是A×a+B×(1-a). 该方法具有运算速度快、 融合图像之间权重易于调节的特点,缺点是削弱了图像中的细节信息,不适用于图像清晰度不足的场景. 由于光伏组件的工作特性,热斑检测都是在白天进行,拍摄的照片光线充足,检测目标边缘轮廓清晰,同时基于减少计算成本与合成时间的考量,选择像素加权平均法实现图像融合.
为了排除颜色对目标检测和定位的干扰,增强模型鲁棒性,选取可见光图像的灰度图作为融合素材,图2展示的是a取不同值时的合成效果. 经对比发现,a取值过小会导致红外图像信息消失,过大会导致合成图像过于模糊,最终选取权值a=0.5进行融合. 5种类别的目标在融合后的图片效果如图3.

图2 相同图片不同权值的融合效果

图3 不同实验类型融合后的图片效果
2 基于YOLOv5的光伏组件热斑及遮挡物检测定位模型
2.1 YOLOv5算法框架
YOLOv5是一种单阶段目标检测算法,其网络结构分为: 输入端、 backbone、 neck和prediction四部分. 模型分为 YOLOv5s、 YOLOv5m、 YOLOv5l和YOLOv5x四个版本,它们的网络结构完全相同,仅在深度和宽度上有差异,因此,选用复杂度最小的YOLOv5s版本作为基础研究模型[9].
输入端主要包括Mosaic数据增强与图片尺寸变换. Mosaic数据增强算法主要思想是将4张图片进行随机缩放、 裁剪、 翻转等变换,再拼接成一张图作为训练数据[10],在丰富图片背景的同时变相提高了批量尺寸. 图片尺寸变换则是对不同长宽的原始图像自适应地添加最少的黑边,统一变换为标准尺寸[11].
图4为YOLOv5网络结构. 在Backbone中,Focus模块通过切片运算把特征图转化为多个低分辨率的特征映射. CBS模块表示卷积+批量归一化+Silu激活函数,是一个卷积模块. C3结构由若干个Bottleneck模块组成,可以减少卷积神经网络训练中的梯度信息重复. SPP模块主要作用是增加网络的感受域,并获得不同尺度的特征.
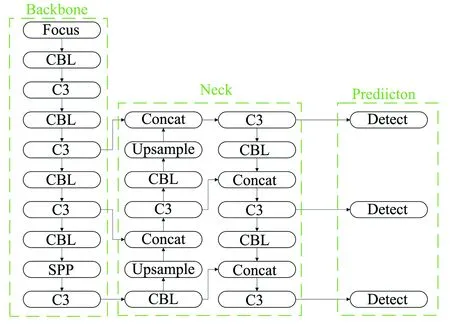
图4 YOLOv5模型框架
YOLOv5还在neck部分增加了一个自下而上的特征金字塔结构. 先从上到下传递语义特征,再通过特征金字塔从下到上传递定位特征,提高了网络检测不同尺度目标的能力. 在Prediction部分,YOLOv5 将3种不同大小的特征输入 Detect 模块,分别针对大、 中、 小体型的目标识别.
2.2 改进的YOLOv5s模型
2.2.1Backbone替换为MobileNetCA
原YOLOv5s网络backbone部分是基于C3和SPP模块的特征提取网络,整体模型参数量较大,对硬件要求较高. 因此,基于轻量化思想,并为未来植入移动端做准备,将特征提取网络替换为融合MobileNetV3网络和坐标注意力机制的MobileNetCA网络,在保证模型检测性能的同时显著减少模型参数量.
轻量级网络MobileNetV3包含MobileNetV3-large和MobileNetV3-small两个版本,分别适用于对资源不同要求的情况[12]. 此外,MobileNetV3网络中还引入了类似MobileNetV2中的α参数作为宽度缩放因子,其作用是对网络的每一个Bneck层的维度(特征数量)进行瘦身. 研究中选取α=0.35[13]的MobileNetV3-large(下文称MNV3)作为实验对象. 由于MNV3原网络最后4层用于分类,对于特征提取是无用的,将其舍弃. 为了对应YOLOv5s原特征提取网络,选取第15层,第13层和第6层作为backbone的输出输入到neck部分中,输入尺寸根据实际情况改为320 px × 320 px × 3.
此外,MobileNetV3系列网络中的SEnet通道注意力模块通过2D全局池化来计算通道注意力,在较低的计算成本下实现性能提升. 然而,它仅仅考虑建模通道间的关系来对每个通道加权,而在文献[14]中提出一种专门为轻量级网络设计的注意力模块(CoordAttention, CA),如图5所示.

图5 CA模型框架
由图5可见,CA模块利用两个一维全局池化(x方向池化和y方向池化)操作分别将垂直和水平方向的输入特征聚合为两个独立的方向感知特征图,用来缓解2D全局池化造成的位置信息丢失,帮助网络更准确地定位感兴趣的目标. 因此,本研究进一步在MNV3网络部分Bneck层中嵌入CA模块,在深度可分离卷积后进行CA操作,并移除原SEnet模块,设计了MobileNetCA网络作为YOLOv5s的backbone特征提取网络,该网络结构如表1.
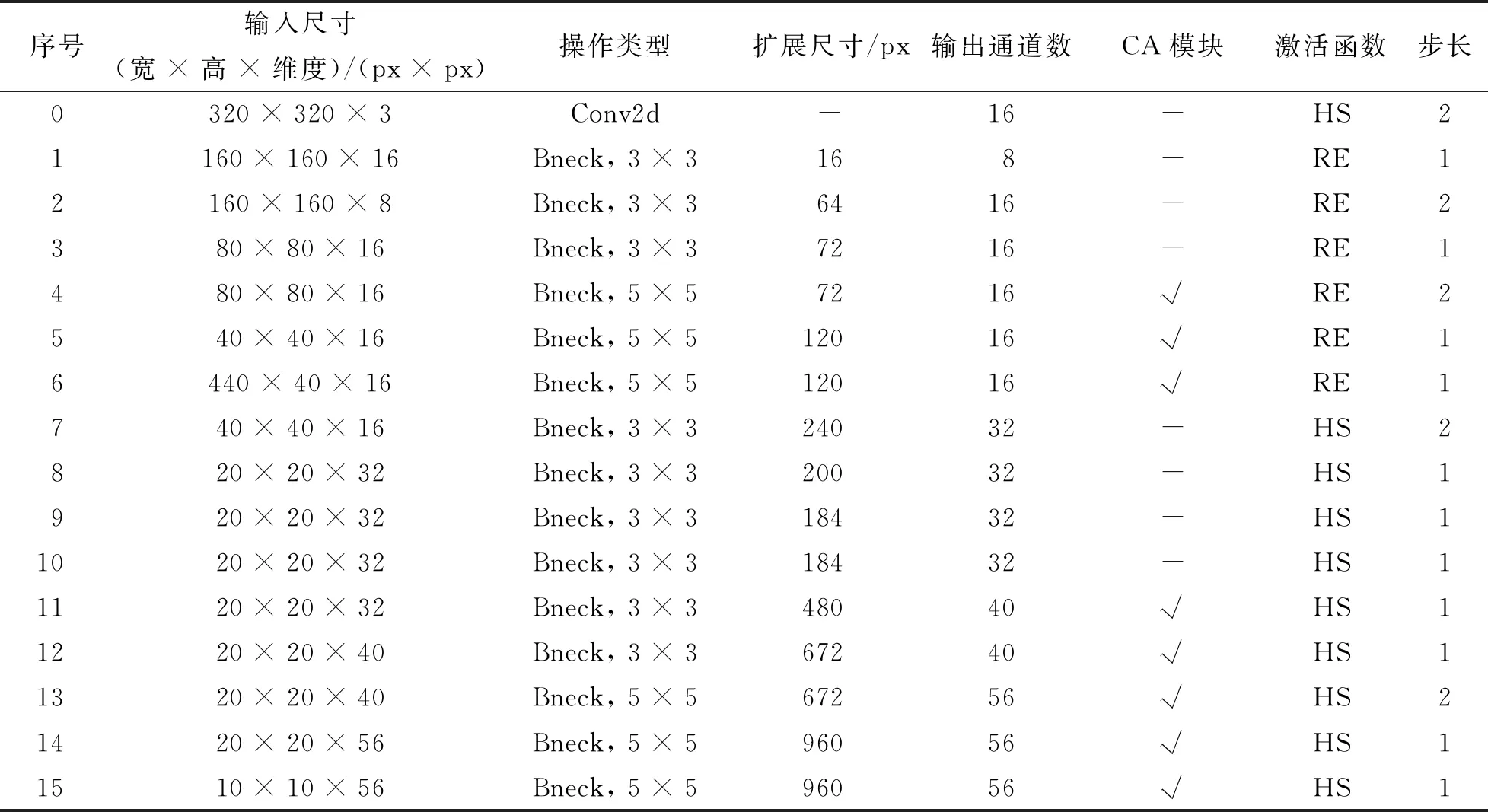
表1 MobileNetCA网络结构
2.2.2损失函数改进
YOLOv5网络训练过程中,程序会将每一轮次模型训练输出的结果与真实值进行损失函数的计算,YOLOv5原网络使用的二元交叉熵损失函数对正负样本都进行同样的计算. 而文献[15]提出一种新的损失函数(varifocal loss, VFL). VFL主要针对正负样本存在不平衡和正样本同时存在不等权的问题,不对称地处理正负样本,具体函数为

(1)
式中:p为YOLOv5网络的输出预测值;q为真实值;γ和α分别取值1.5和0.25. VFL通过用γ因子将负例(q=0)的损耗按比例缩小,而不以同样方式缩小正例(q>0)的损耗贡献.
本研究中,为了避免对光伏阵列本身造成不可逆的损坏,热斑形成一定时间后需要及时处理,这导致热斑样本的获取较为困难. 在所采集的数据中,平均每张图片仅有2.7个目标,且目标又分为5个类别,所以模型训练时正样本相对负样本少得多,存在不平衡,而VFL损失函数通过γ因子将负例缩小,保留正例珍贵的学习信号. 因此,将YOLOv5网络损失函数的分类损失和置信度损失由原来的二元交叉熵损失函数替换为VFL.
2.2.3目标框生成算法的优化
YOLOv5官方代码库中有利用k-means聚类和遗传算法生成新的目标聚类框,但其中的k-means聚类是基于欧氏距离聚类,而使用欧氏距离会让大的边界框比小的边界框产生更多的误差[16],聚类结果可能会偏离. 文献[16]提出采用IOU得分(boxes之间的交集除以并集)作为评判标准距离函数, 很好改善了这些误差,使生成的目标框与实际标注框更一致. 其具体公式为:
d(box, anchors)=1-IOU(box, anchors)
(2)
式中: box为标注框; anchors是k-means算法生成的聚类框.
因此,采用1-IOU(box, anchors)作为目标框生成算法中k-means聚类的评判标准,生成新的聚类框. 改进后算法(下文称IOUscore)生成的目标框宽和高分别为(13, 7)、 (16, 12)、 (23, 10)、 (18, 12)、 (25, 14)、 (35, 13)、 (32, 18)、 (48, 15)、 (51, 27)px.
3 实验结果与分析
3.1 性能评价指标
性能指标的计算依赖于模型预测结果形成的混淆矩阵,混淆矩阵把预测的结果分为: TP预测对的正类; TN预测对的负类; FP预测错的正类; FN预测错的负类.
选用准确率(precision,P)、 召回率 (recall,R)、 平均准确率(average precision,Pav)和主要平均准确率(main average precision,Pm, av)[17]4 项性能指标作为网络性能评价,其计算公式如下:
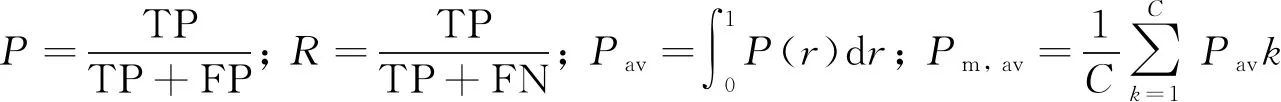
(3)
模型参数量是指该模型中总共含有多少参数,直接决定模型文件的大小,影响模型推断时对内存的占用量,本实验用模型参数量表示模型的计算量和复杂度.
3.2 模型训练过程
实验计算机平台为AMD R5 3600 CPU,GeForce RTX 3060 12 G GPU,内存为16 G. Python版本为3.8,使用Pytorch 1.8.1深度学习框架,GPU CUDA版本为11.1.
选择466张样本组成训练集,余下156张作为测试集. 为提高模型训练效果,增强模型鲁棒性,训练前使用图像处理方法对训练集数据进行扩充,使模型学习更多的信息. 具体操作是: 对训练集中任意图片的亮度和噪声进行随机调整,同时随机对图片进行平移、 翻转、 遮挡等变换,最终将训练集扩充为1 398张,训练集标签数量也从1 223变为3 669.
实验设定模型训练初始学习率为0.01,动量为0.937,衰减系数为 0.000 5,使用 SGD 梯度优化算法,训练批次大小设为 64,设置训练轮数为600次,非极大值抑制阶段中的IOU阈值为0.3,置信度阈值为0.4. 检测效果示例如图6所示.
图6 检测效果示例
3.3 改进后网络模型的效能评估和分析
各项算法改进与基础YOLOv5s算法精度与参数量对比详见表2. 由表中结果可知,使用IOUscore算法的模型Pm, av较原模型提升1.5%,达到86.6%,说明改进后的算法生成的目标框更适合该数据集和模型. Backbone改为MNV3后,模型参数量下降的同时,其Pm, av也降到85.5%. 而更换为MobileNetCA网络后,模型Pm, av提升1.9%达到87.4%,也优于backbone尚未更换的YOLOv5s,而参数量却较MNV3进一步下降,说明相比MNV3,MobileNetCA是更高效、 更轻量化的特征提取网络. 将损失函数更改为Varifocal Loss后,训练后模型Pm, av相比之前进一步提升至88.9%,说明将YOLOv5s模型中的交叉熵损失函数替换为Varifocal Loss以达到突出正例的效果,确实能改善模型的检测性能,同时,本研究算法参数量仅为原YOLOv5s的48.6%. 各目标类型细分Pav指标对比详见表3. 从表中可以看出,相比原YOLOv5s,改进模型对类型一和类型五目标的检测效果提升最为明显.

表2 各项算法改进与基础算法指标对比

表3 细分各类指标对比
为了进一步验证模型的性能,选择7种算法进行检测,得到不同算法性能指标如表4所示. 从表中可以看出, 本算法在R、Pm, av和模型参数量上均获得更好的结果.
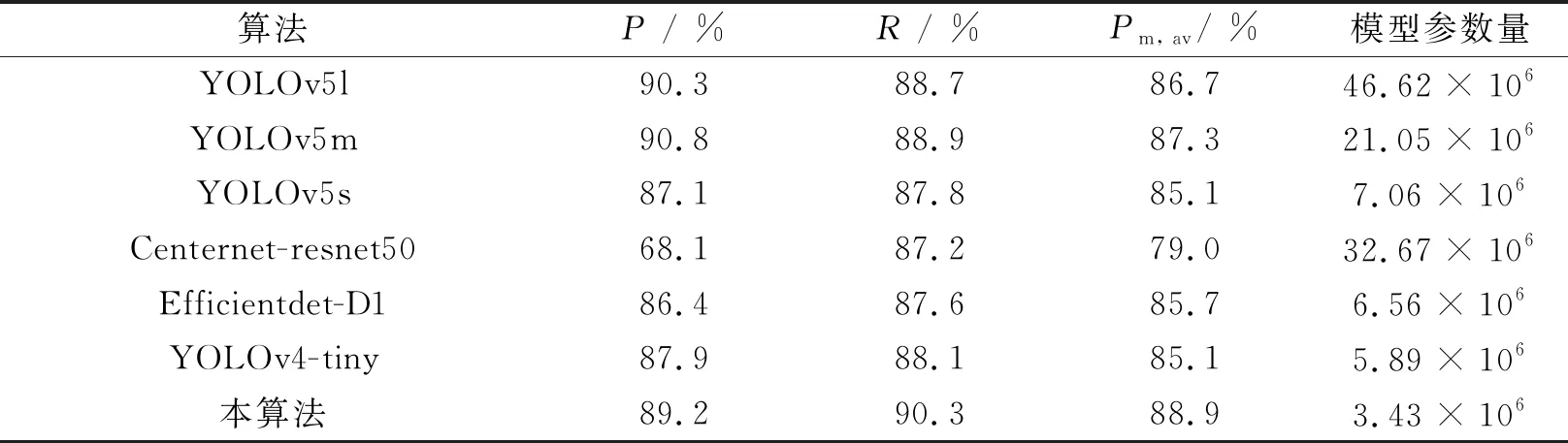
表4 不同算法性能对比
4 结语
提出一种基于YOLOv5框架的光伏组件热斑故障和遮挡物检测定位方法,运用像素加权平均法融合可见光和红外图像,使模型可同时对遮挡物和热斑进行检测. 使用改进目标框生成算法的方法减小生成目标框的误差,提升检测效果. 为了降低模型的体积,原YOLOv5s的backbone部分被替换为融合了坐标注意力机制的MobileNetCA网络. 其次,针对训练中正样本数量过少的问题,引入Varifocal Loss损失函数替换YOLOv5网络的分类和置信度损失函数. 实验结果表明,相比于YOLOv5s模型,改进后的模型不但检测性能得到提升,模型的参数量也有所下降. 下一阶段的研究目标,是将模型移植入算力有限的小型移动设备中,对在移动设备中的实时检测性能进行测试和改进.
猜你喜欢
黑龙江大学自然科学学报(2022年4期)2022-11-17
能源工程(2022年2期)2022-05-23
环球时报(2022-05-23)2022-05-23
金桥(2021年4期)2021-05-21
作文小学中年级(2020年6期)2020-07-24
重型机械(2020年2期)2020-07-24
装备制造技术(2019年12期)2019-12-25
电子制作(2019年7期)2019-04-25
光学精密工程(2016年3期)2016-11-07
太阳能(2015年11期)2015-04-10
