
词素位置概率在中文阅读中的作用:词汇判断和眼动研究*
2023-02-13 02:12曹海波兰泽波于海涛王敬欣
心理学报 2023年2期
曹海波 兰泽波 高 峰 于海涛 李 鹏 王敬欣
(1 天津师范大学心理学部,天津 300387) (2 河北北方学院艺术学院,张家口 075000)(3 福建医科大学健康学院,福州 350122) (4 燕山大学心理健康教育服务中心,河北 秦皇岛 066000)
1 引言
阅读过程中读者对词素位置信息的加工是词汇识别不可或缺的步骤,一般而言,词汇识别包含两类编码,即身份信息编码和位置信息编码。身份信息编码是指哪些字符构成了词汇,而位置信息编码是指字符在词汇中的相对顺序(滑慧敏 等,2017)。字符的位置信息在词汇识别中有重要作用,英文中读者区分相同字母组成的单词时便依据字母的位置差异,如causal 和casual。同样,中文读者也由词素位置信息识别变位词,譬如“上海”和“海上”,二者身份信息相同,通过词素位置区分语义。若词素位置判断能力不足则会干扰正常阅读,一部分阅读障碍儿童对汉字位置出现判断困难,测试成绩显著低于控制组儿童(田晓梅 等,2006)。词素位置信息的加工是通往词汇识别和更高语言水平加工的重要途径,离不开视觉和认知加工系统的相互作用。据此,研究者对拼音文字的字母位置信息进行了深入探究,发现了字母的换位效应(transposition-letter effect,TL effect),即人们在阅读一个内有字母换位的非词时,倾向于将其识别为与之对应的真词,并且这种倾向比将内有替换字母的非词当作真词的概率要高(Perea & Carreiras,2006)。后续研究更进一步,探究了词首与词尾位置之于词汇识别的重要程度,研究认为比起词内部的换位,发生在词首、词尾的换位会对词汇识别起到更大的破坏作用(Yakup et al.,2014)。Schotter 等人(2012)发现词首的字母或者词首的字更重要。综上所述,词素位置信息的加工是词汇识别的重要环节,且词素处于不同的位置对词汇识别所起的作用不同。对词素位置与整词词汇识别关系的深入思考,将有助于我们认识汉字水平自下而上的加工对词切分及阅读认知机制的理解。
中文阅读同样重视词素位置的作用,也发现了字母转置效应(Gu et al.,2015),且发现词边界信息影响汉字位置的加工(顾俊娟 等,2020)。彭聃龄等人(1999)发现词素换位也能达到正常语义启动的效果,卞迁等人(2010)应用眼动技术探究词素换位对词素识别的影响,发现含高频词素换位的词汇识别要快于低频词素换位的词汇。需指出的是,中文的字序编码区别于位置编码,字形编码发生在阅读的早期阶段,而位置信息的编码则具有一定灵活性(Gu et al.,2015)。徐迩嘉和隋雪(2018)应用启动范式,比较了不同启动时间下首字替换词与尾字替换词的启动条件,发现首字替换词对目标词的启动效果最小,说明首字的替换对词汇识别的破坏性更大,证实了词首在词汇加工中的重要性。总体来看,词素位置信息的加工是词汇加工的重要环节,且值得思考的是,词素的特定位置(如词首)能影响词汇加工,那么词素位置概率又是怎样作用于词汇识别的呢?具体而言,词素位置概率指的是汉字出现在词首或词尾时双字词的次数占该汉字组成的所有双字词(无论出现在首字还是尾字)的比重(Yen et al.,2012)。例如,在语料库中“消”可组成39 个双字词,其出现在词首可组成33 个词,如“消炎”、“消息”、“消失”等,为此,其词首词素位置概率为0.85。可见,“消”常居于双字词词首,这为读者提供了较清晰的词边界信息。连坤予等人(2021)发现被试在低词素位置概率条件下的凝视时间显著长于高概率条件,表现出明显的词素位置概率效应。而且读者对词素位置概率的利用表现出发展上的差异性,即大学生运用词素位置概率帮助词切分的能力强于小学生(Liang et al.,2015)。
词素位置概率现象是中文词汇的显著特点,中文以汉字为书写单元,汉字携带一定意义且是汉语最小的语言单位,而词素是指具有独立形态和意义的最小语言单位(张玲燕 等,2013),同时,汉语书写系统中大多数词是双字词,词素位置信息相对明确(赵思敏 等,2017)。据统计,约20%的汉字出现在多字词的固定位置,其中 8.2%惯常居于词首,7.5%惯常居于词尾,2.1%以单字词形式呈现(白学军,闫国利,2017),词素位置的这一特性为中文读者提供了词与词之间隐含的边界,为中文词汇的切分提供了可用线索。因为中文词汇的识别与切分区别于拼音文字,拼音文字中的空格为读者提供了明确的单词首尾部分的物理空间边界信息,帮助计划下一次眼跳,促进单词的识别(Perea & Acha,2009;Rayner,1998)。而中文无词间空格标示词边界,邻近的汉字可组成双字词、三字词及四字词,并且中文组词的模糊性也加大了词切分难度(Gao et al.,2005),但中文读者并未遭遇特殊阅读困难,其阅读速度可与拼音文字读者保持一致(Liversedge et al.,2016),那么中文读者如何进行词切分就成为汉语阅读的一个独特问题,其必定借助某些隐含线索协助词切分。此时,词素位置概率信息可作为一种隐含的语言线索帮助词切分,由于词素经常出现在双字词的某一特定位置(词首或词尾),一定程度上标示出了词与词之间的隐藏边界,据此,研究者们开展了一系列研究。梁菲菲(2013)用新词习得的方式探讨了中文读者对词素位置概率线索的使用,研究操纵首、尾词素的位置概率,创设三种类型的假词作为新词,发现在词素位置概率一致条件下的注视时间和注视次数显著低于不一致条件。Yen 等人(2012)采用边界范式的研究表明,中文读者能够利用词尾词素位置概率指导词汇识别和眼跳控制。高淇(2018)以儿童和成人为研究对象,对词首、尾词素位置概率的关系进行了推论,即词首词素位置概率的高低对儿童和成人的阅读行为没有影响,但词尾词素位置概率显著影响了儿童和成人的阅读表现,研究结果进一步肯定了词尾词素位置概率的词切分作用。然而一项后续研究提供了不同的实验证据,即儿童和成人均能利用词首和词尾词素位置概率指导阅读活动(连坤予 等,2021)。可见,词首与词尾词素位置概率在阅读过程中的作用还未取得较为统一的观点,是词尾词素位置概率发挥了主要作用,还是词首与词尾同等重要?这一问题的解决有待开展后续研究深入考察与澄清。
值得一提的是,有研究指出低频词倾向于词素通达,而高频词可能经由整词路径通达(高淇,2018)。换言之,在心理词典中低频词倾向于以单个字的形式进行表征,而高频词常以整体形式表征(白学军 等,2015)。事实上,中文复合词的表征方式一直存有争议,在识别复合词时,是通过整词表征亦或经由分解的词素表征,以及二者发挥作用的程度如何,一直是心理语言学研究的热点问题。研究者基于不同的研究材料、范式及技术手段给予了不同程度的回答,既往研究证据提示词频会影响词汇加工,高频词的注视时间显著低于低频词(Wei et al.,2013),从高频中央凹词到副中央凹词的眼跳长度显著长于从低频词跳出的眼跳长度(王永胜 等,2018),对不同词频的使用会影响真词与换位假词的判断(Vergara-Martínez et al.,2013)。相关研究指出词素特征是词汇识别的重要影响因素,并且在低频词加工中表现的更加明显(彭聃龄 等,1999)。与词素位置颠倒的高频词相比,读者对词素位置颠倒的低频词识别较慢(卞迁 等,2010)。可见,整词的词频对词汇的加工具有潜在影响。
研究者还关注到,在中文的词汇识别过程中,首词素与尾词素对整词识别的贡献不同,且词频的变化会带来阅读行为的改变,这使得词频对词素位置概率线索的作用成为一个新问题。不同词频条件下词素位置概率还能否发挥作用,词首与词尾词素位置概率的作用差异如何?探查既往研究发现其未对词频做出具体区分,这是否成为词首与词尾词素位置概率作用不同的潜在影响因素?另外,根据经典的词汇识别模型,如McClelland 和Rumelhart(1981)的交互激活模型、Davis (2001)的自我组织词汇习得与识别模型、Taft(2004)的多层激活模型,词频是进入词汇通达的重要因素,其可能会影响到汉语词素位置概率对词汇识别的加工呈现出不同的模式。Li 和Pollatsek (2020)提出的中文阅读的整合模型也指出词频是影响词汇识别的重要因素,词频直接影响词汇节点的输入,并成功预测了词频对眼跳长度的影响。鉴于此,有必要在探究首、尾词素位置概率认知机制的基础上,进一步明确整词词频的内在影响,探究中文复合词的加工方式,即复合词的表征究竟是基于词素、整词,亦或是混合通达?据此,对上述问题的考察便体现出一定的新意和价值。第一,对复合词认知加工的组件词素作用的研究,可加深对复合词通达表征网络的理解。第二,当前汉语词素位置信息加工机制的研究尚浅,持续探讨词素位置概率之于词切分的作用,有助于回答中文读者如何确定词边界的问题,为仍处于探索中的汉字位置编码机制提供新视角。
研究设计了4 个实验,实验1a 和1b 采用词汇判断任务,创设不同的首、尾词素位置概率条件,同时操纵目标词词频。另外,由于汉语中高、低频词汇难以平衡词首和词尾的词素位置概率,故未采用2 (词频:高、低) × 2(词首词素位置概率:高、低) × 2(词尾词素位置概率:高、低)的实验设计,而是采用2(词首词素位置概率: 高、低) × 2 (词尾词素位置概率: 高、低)的两因素被试内重复测量实验设计,分开考察词频因素的影响便于更清晰地考察不同词频条件下词素位置概率的重要程度。词素位置信息的加工是词汇加工的重要阶段,词首与词尾在词汇识别过程中发挥着不同作用,词首作用较为积极,研究假设: 词素位置概率信息是中文词汇识别的语言线索,且与词尾词素位置概率相比,词首词素位置概率在词汇识别中的促进作用更大。实验2a 和2b 采用句子阅读任务,记录被试在句子阅读过程中的眼动特征,进一步考察处于生态效度更高的自然阅读情景下词素位置概率效应是否存在,以及作用发挥在加工的哪一阶段。研究假设: 读者能利用词素位置概率线索帮助词切分,词首词素位置概率的优势更为明显,同时词频会影响这一作用的发挥,即低频词条件下读者能够运用词素位置概率线索助力词切分,高频词条件下这种促进作用会减弱。依据Li 等人(2009)提出的词切分与词汇识别模型,中文词汇识别是一个交互激活的过程,字水平的激活前馈到词水平,反过来词单元的激活也反馈到组成该词的字水平。字词层面的信息交互激活并相互影响,属于该词的字比其它字激活更快,同时属于该字的位置比其它字的位置激活更快。如果在高频词中未发现词素位置概率效应,说明词汇识别是经由整词表征的,输入刺激直接激活了心理词典的整词词条。如果在低频词中观察到词素位置概率效应,则表明词汇识别过程中发生了分解的词素表征,词素激活后影响到整词识别。鉴于此,复合词的加工既存在整词表征又存在词素表征,研究结果倾向于支持复合词加工的混合通达表征观点。
2 实验1a: 词素位置概率在高频词词汇识别中的作用
2.1 实验目的
采用词汇判断任务,操纵词首和词尾词素位置概率,以高频目标词为研究对象,探讨词素位置概率是否影响被试的词汇识别。
2.2 实验方法
2.2.1 被试
60 名天津师范大学在校学生,其中女生40 名,男生20 名,年龄在18~22 岁之间(M=19.70,SD=1.94)。被试均为汉语母语者,视力或矫正视力正常,均不知实验目的,实验结束可获得一定报酬。为保证较高的统计效能(Faul et al.,2007),在实验实施前采用G*power 分析方法对样本量进行估算。根据中等效应量水平(f=0.25)及0.01 的α 水平,G*power分析结果建议实验需要48 名被试可使统计效能达到0.95。考虑到可能有无效被试,实际取样60 名。
2.2.2 实验设计
采用2 (词首词素位置概率: 高、低) × 2 (词尾词素位置概率: 高、低)的两因素被试内重复测量设计。
2.2.3 实验材料
参照中国电视电影旁白的汉语词汇和笔画频率语料库(Cai & Brysbaert,2010),为保证词素位置概率条件的区分度,将词素位置概率高于0.7 定义为高概率,低于0.3 定义为低概率。词素位置概率计算方法: 汉字出现在词首或词尾时双字词的数量除以汉字所能组成的所有双字词(无论出现在首字还是尾字)的数量。操纵词素位置概率的高低,共选取80 个双字词,将其分为4 种条件(每种条件下20个双字词): (1)高词首词素位置概率、高词尾词素位置概率;(2)高词首词素位置概率、低词尾词素位置概率;(3)低词首词素位置概率、高词尾词素位置概率;(4)低词首词素位置概率、低词尾词素位置概率。控制4 种条件下双字词的词频差异不显著(F(3,124)=0.15,p=0.92)、词首笔画数差异不显著(F(3,124)=2.19,p=0.09)、词尾笔画数差异不显著(F(3,124)=1.24,p=0.21)、词首字频(F(3,124)=0.98,p=0.40)和词尾字频(F(3,124)=0.42,p=0.73)的差异不显著。考虑到词素结构可能对词汇认知加工造成影响,材料选取时尽可能避免选取偏正复合词和含有词缀的双字词。同时,对双字词词首和词尾的构词能力进行了控制,构词能力是指词素所能构成双字词的数量(冯丽萍,宋志明,2004),例如,在语料库中“透”字可以组成“透明”、“透彻”、“看透”等20个词,那么其构词能力即为20。4 种条件词首和词尾的构词能力之间差异不显著,ts 〈 1,ps 〉 0.05。此外,请15 名不参加实验的同学对目标词的熟悉度和语义透明度进行评定,其中1 代表“非常不熟悉”,5 代表“非常熟悉”,1~5 的变化代表词语熟悉性的增强,目标词的熟悉度为M=4.18 (SD=0.17);语义透明度指的是复合词的语义能从其各个组成词素的语义推知的程度。其中1 代表“完全不透明词”,5代表“完全透明词”,1~5 的变化代表语义透明度的增强,目标词的语义透明度为M=4.24 (SD=0.15)。实验材料的基本参数情况见表1。

表1 实验材料基本参数情况
为平衡词汇判断的对错项目数,在材料中加入填充词构成“否”反应。填充词是由真字构成的假词,其中假词中字的笔画与真词中字的笔画差异不显著,t〈 1,p〉 0.05;假词中的字频与真词中的字频差异不显著,t〈 1,p〉 0.05。
2.2.4 实验仪器
实验采用联想ThinkPad T-14 笔记本电脑,屏幕为14 英寸,分辨率为1024×728 像素,刺激为32号宋体,每个汉字大小约为41×41 像素,以白底黑字方式呈现。被试眼睛与屏幕之间的距离为75 cm,每个汉字约为1.1°视角。
2.2.5 实验程序
实验使用E-prime 2.0 编程。首先,被试阅读指导语理解实验程序。实验开始时,屏幕中央呈现“+”注视点,800 ms 后注视点消失,接着呈现一个词语,被试需快而准地进行真假词判断,若是真词按“F”键,若是假词按“J”键。目标词在被试做出反应或3000 ms 后消失。反应后空屏600 ms 进入下一试次。实验材料随机呈现,为避免练习效应按键反应在左右手间平衡。实验前是10 个试次的练习,正确率达90%以上开始正式实验,实验需15 分钟。实验流程见图1。
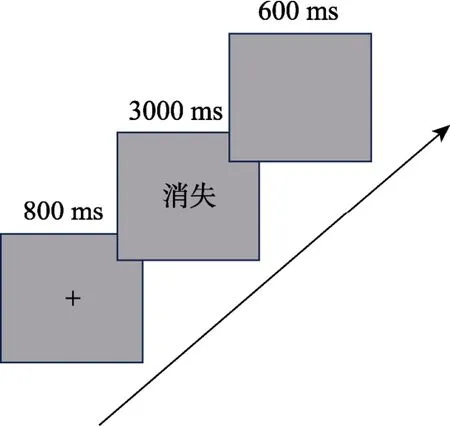
图1 实验1 流程图
2.3 实验结果
数据分析时,填充材料不参与分析。数据分析过程中删除了错误反应的反应时数据以及大于或小于3 个标准差的极端值,占有效被试数据的1.2%。
注: 例词“消失”表示高词首词素位置概率、低词尾词素位置概率条件,即“消”词首词素位置概率0.85,“失”词尾词素位置概率0.24。
2.3.1 错误率
被试在不同词素位置概率条件下的平均错误率如表2 所示。

表2 不同词素位置概率条件下的平均错误率
使用R 统计软件(R Development Core Team,2016)以及lme4 工具包(Bates et al.,2017),采用广义线性混合模型(Generalized Linear Mixed-effects Models,GLMMs)对错误率数据进行分析。对比传统的方差分析(ANOVA),线性混合模型将全部原始数据纳入模型,数据利用率更高,在计算数据时采用最大随机效应结构,将被试和项目定义为交叉随机效应(crossed random effects)同时纳入模型,可有效规避被试分析(F1 检验)和项目分析(F2 检验)检验结果不一致的情况,使计算结果更加统一和稳定。统计结果见表3。
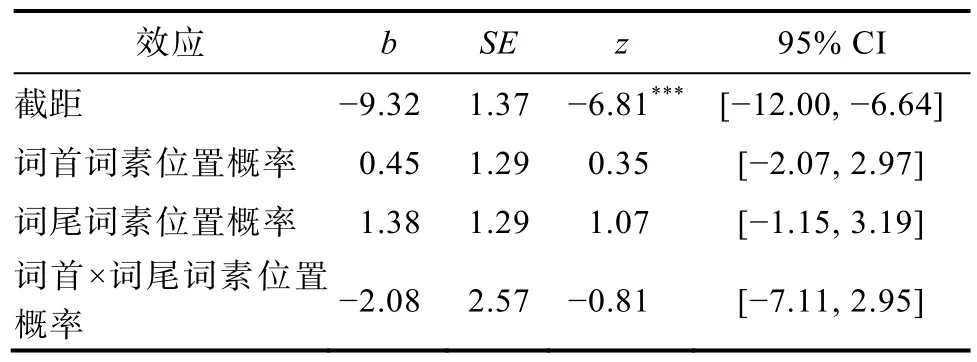
表3 不同词素位置概率条件下错误率的线性混合模型统计结果
结果显示,词首词素位置概率(z=0.35,p=0.73)和词尾词素位置概率(z=1.07,p=0.29)的主效应均不显著;二者交互作用不显著(z=-0.81,p=0.42)。结果表明高频词条件下词素位置概率不影响被试的错误率。
2.3.2 反应时
被试在不同词素位置概率条件下的平均反应时如表4 所示。

表4 不同词素位置概率条件下的平均反应时(ms)
使用R 统计软件(R Development Core Team,2016)以及lme4 工具包(Bates et al.,2017),采用线性混合模型(Linear Mixed-effects Models,LMMs)对反应时数据进行分析,统计结果见表5。
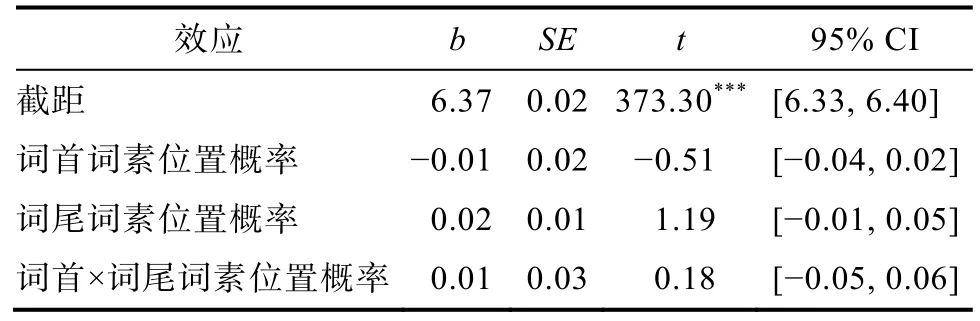
表5 不同词素位置概率条件下反应时的线性混合模型统计结果
结果显示,词首词素位置概率(t=-0.51,p=0.62)和词尾词素位置概率(t=1.19,p=0.24)的主效应均不显著;二者交互作用不显著(t=0.18,p=0.86)。结果说明高频词条件下首、尾词素位置概率不影响词汇识别。
2.4 讨论
实验1a 结果表明,加工高频词时词首与词尾词素位置概率的高低不影响被试反应时。一些研究提示词频可影响单词的表征,高频词由于常一起呈现,在通达表征层逐渐形成独立表征;而低频词可能依赖分解的途径通过词素进行通达(彭聃龄 等,1999)。有研究指出低频双字词识别过程中存在词素语义激活,词素意义和整词意义之间相互作用,当二者意义相近时相互促进,而且高频双字词词素语义激活不明显,整词语义的激活并不慢于词素,词素通达并不是整词通达的必经阶段(俞林鑫,2006)。另有实验证据表明,双字词的词频高时,词素频率效应不显著,即词频与词素频率的作用是竞争的,但词频发挥了更强的作用,高词频抑制了词素频率的效应(王德强,2013)。可见,词素的特性受到整词属性的制约。
总结以往研究可知,与高频预测性目标词相比,读者在加工低频预测目标词时耗费的资源更多,词汇加工的层次也更深(吴琼,2013)。来自拼音文字的研究显示,当复合词为长词(平均12~13 个字符)时,如breastbone,词素breast 和bone 的词频会影响注视词的加工时间(Hyönä et al.,2004);当复合词变成短词(平均7~9 个字符)时,词素词频的作用有限,而是整词词频影响目标词的注视时间。Li 和Pollatsek (2020)认为词汇识别是从视觉信息开始,之后是字层面的加工,最后是词层面的加工。因此,字层面的词素位置概率的加工水平是低于词汇层面的,词素位置概率信息没有词汇层面信息的丰富性。如在高频或高预测性条件下,读者可能更依赖整词词频或整体语境去识别词汇。对比而言,低频词条件由于缺少了整词提供的丰富的词汇信息,词素特性得以展现,此时词素位置概率信息可能会发挥作用。为此,当目标词变为低频条件时,是否存在词素位置概率效应?首、尾词素位置概率信息对视觉词汇加工的重要程度如何?实验1b 将探究在低频词条件下词素位置概率在词汇识别中的作用,以期全面考察整词词频对词素位置概率效应的影响。
3 实验1b: 词素位置概率在低频词词汇识别中的作用
3.1 实验目的
采用词汇判断任务,操纵词首和词尾词素位置概率,考察在低频词条件下被试词汇判断的成绩差异,探究词素位置概率线索在词汇识别中的作用。
3.2 实验方法
3.2.1 被试
同实验1a。
3.2.2 实验设计
同实验1a。
3.2.3 实验材料
参照中国电视电影旁白的汉语词汇和笔画频率语料库(Cai & Brysbaert,2010),为保证词素位置概率条件的区分度,将词素位置概率高于0.7 定义为高概率,低于0.3 定义为低概率。操纵词素位置概率的高低,共选取120 个双字词,将其分为4 种条件(每种条件下30 个双字词): (1)高词首词素位置概率、高词尾词素位置概率;(2)高词首词素位置概率、低词尾词素位置概率;(3)低词首词素位置概率、高词尾词素位置概率;(4)低词首词素位置概率、低词尾词素位置概率。控制4 种条件下双字词的词频(F(3,116)=0.62,p=0.60)、词首笔画数(F(3,116)=1.28,p=0.12)、词尾笔画数(F(3,116)=0.74,p=0.52)、词首字频(F(3,116)=1.49,p=0.09)和词尾字频(F(3,116)=1.58,p=0.08)的差异不显著。考虑到词素结构可能对词汇认知加工造成影响,材料选取时尽可能避免选取偏正复合词和含有词缀的双字词。同时,控制4 种条件词首和词尾的构词能力之间差异不显著,ts 〈 1,ps 〉 0.05。此外,请15 名不参加实验的同学对目标词的熟悉度和语义透明度进行评定,其中1 代表“非常不熟悉”,5 代表“非常熟悉”,1~5 的变化代表词语熟悉性的增强,目标词的熟悉度为M=3.98 (SD=0.22);语义透明度指的是复合词的语义能从其各个组成词素的语义推知的程度。其中1 代表“完全不透明词”,5 代表“完全透明词”,1~5 的变化代表语义透明度的增强,目标词的语义透明度为M=4.13 (SD=0.35)。其中,目标词的词频显著低于实验1a 中目标词的词频(t=-9.84,p〈 0.001)。实验材料的基本参数情况见表6。

表6 实验材料的基本参数情况
为平衡词汇判断的对错项目数,在实验材料中加入了填充词,构成了“否”反应。填充词是由真字构成的假词,其中假词中字的笔画与真词中字的笔画差异不显著,t〈 1,p〉 0.05;假词中的字频与真词中的字频差异不显著,t=1.70,p〉 0.05。
3.2.4 实验仪器
同实验1a。
3.2.5 实验程序
同实验1a。
3.3 实验结果
数据分析时,填充材料不参与分析。数据分析过程中删除了错误反应的反应时数据以及大于或小于 3 个标准差的极端值,占有效被试数据的1.6%。
3.3.1 错误率
被试在不同词素位置概率条件下的平均错误率如表7 所示。使用R 统计软件(R Development Core Team,2016)以及lme4 工具包(Bates et al.,2017),采用广义线性混合模型(Generalized Linear Mixed-effects Models,GLMMs)对错误率数据进行分析。将词首、词尾词素位置概率以及它们之间的交互作用作为固定因素纳入模型进行分析,统计结果见表8。

表7 不同词素位置概率条件下的平均错误率
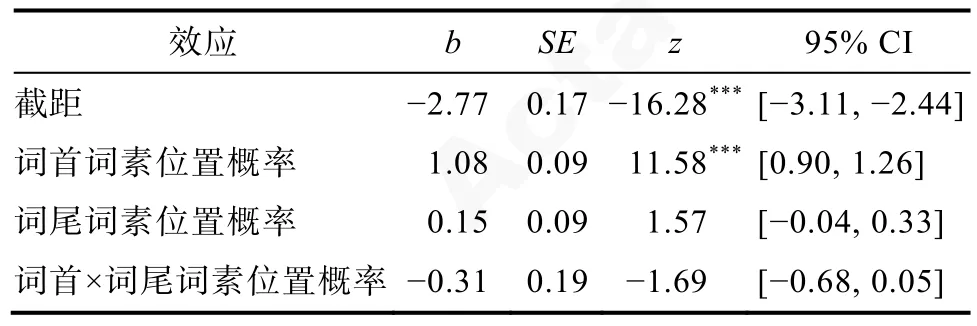
表8 不同词素位置概率条件下错误率的线性混合模型统计结果
由统计结果可见,词首词素位置概率的主效应显著(z=11.58,p〈 0.001),词尾词素位置概率的主效应不显著(z=1.57,p=0.11),二者的交互作用不显著(z=-1.69,p=0.09)。结果表明,词首词素位置概率在词汇识别中起了显著作用。
3.3.2 反应时
被试在不同词素位置概率条件下的平均反应时如表9 所示。

表9 不同词素位置概率条件下的平均反应时
使用R 统计软件(R Development Core Team,2016)以及lme4 工具包(Bates et al.,2017),采用线性混合模型(Linear Mixed-effects Models,LMMs)对反应时数据进行分析。统计结果见表10。
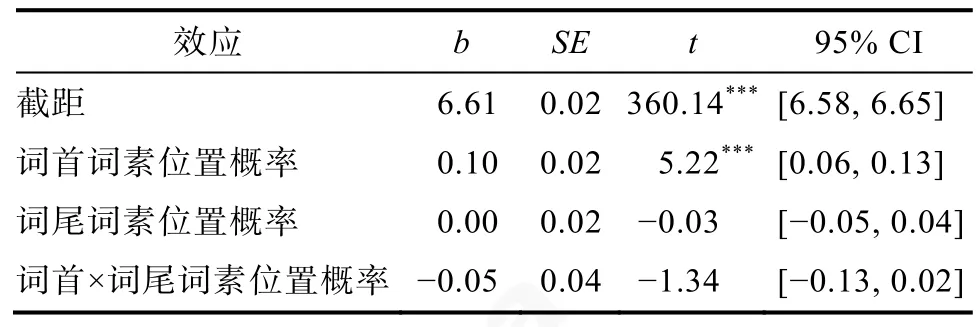
表10 不同词素位置概率条件下反应时的线性混合模型统计结果
由统计结果可见,词首词素位置概率的主效应显著(t=5.22,p〈 0.001),词尾词素位置概率的主效应不显著(t=-0.03,p=0.97),二者的交互作用不显著(t=-1.34,p=0.19)。结果表明,与词尾词素位置概率相比,词首词素位置概率对词汇识别的作用更大。
3.3.3 词首词素位置概率和反应时的简单线性回归模型
实验1b 的结果显示,被试的反应时随词首词素位置概率的升降而变化,二者之间呈现出一定程度的相关关系。为了检验这种相关关系的确切程度及方向性,尝试根据词素位置概率建立读者词汇判断反应时的最优回归模型,以期从更直观的线性模型视角描述词素位置概率与词汇加工的关系。
(1)建立简单线性回归模型
运用最小二乘法建立简单线性回归的数学模型:
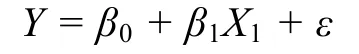
公式中以反应时为因变量,词首词素位置概率为自变量,β0为常数项,表示截距项参数;β1为回归系数,表示自变量X每变化1 个单位时,其单独引起因变量Y的平均变化量;ε为随机误差项,表示除影响因素X以外,其他所有影响Y的因素。借助R 统计软件(R Development Core Team,2016)以及ggpubr 工具包对数据进行简单线性回归分析,计算词首词素位置概率和词汇判断反应时的相关性,结果显示,反应时与词首词素位置概率呈显著负相关(r=-0.38,p〈 0.001)。
(2)整体回归模型的显著性检验
对回归模型的整体做显著性检验,结果显示回归方程高度显著,F(1,118)=19.93,p〈 0.001。这说明反应时与词首词素位置概率间的线性回归关系密切。
(3)回归系数的显著性检验
对回归系数进行显著性检验,即变量系数的t检验。以反应时为因变量,以词首词素位置概率为自变量,经由R 数据软件建立简单线性回归方程,统计结果见表11 和图2。

表11 词首词素位置概率对反应时的简单线性回归结果
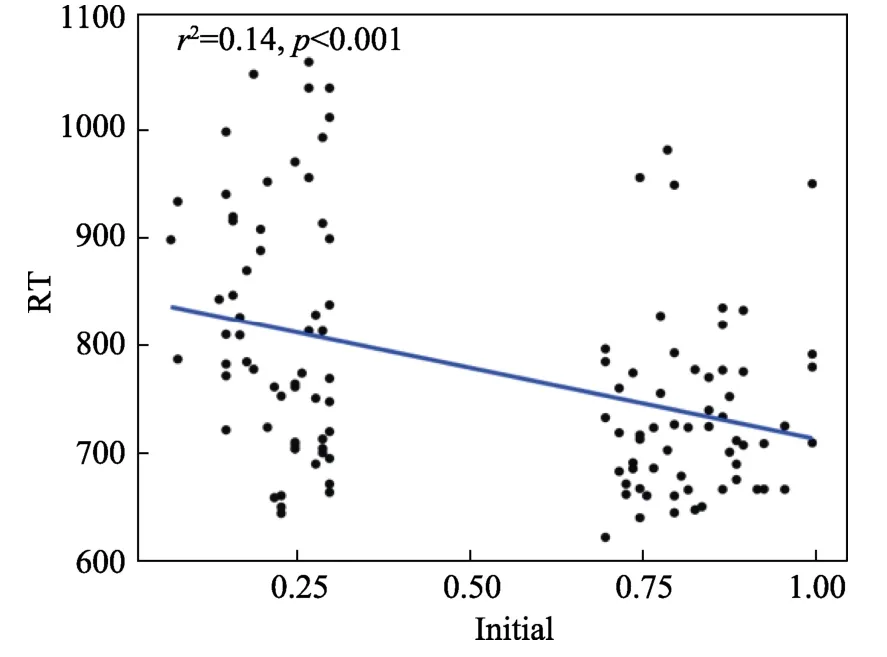
图2 词首词素位置概率对反应时的简单线性回归图
由表11 和图2 的结果可见,模型的回归系数显著,为此得出估计的回归方程:
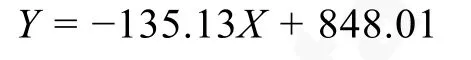
由回归方程可知,词首词素位置概率与反应时呈显著负相关关系,即词首词素位置概率每增加1个单位,读者反应时减少135.13 ms,可见词首词素位置概率显著影响读者的词汇加工。这启示我们可根据词素位置概率来预测读者的反应时,这对中文读者阅读行为的探究具有现实指导意义。
3.4 讨论
实验1b 反应时数据提示,词首词素位置概率的主效应显著而词尾不显著,即不论双字词词尾词素位置概率高低与否,只要词首词素位置概率高时,词汇判断时间便显著减少。错误率数据进一步肯定了词首的加工优势。同时,观察反应时的线性回归模型发现,被试词汇判断的反应时与词首词素位置概率呈现显著的负相关关系,词首词素位置概率增加,词汇判断反应时减少。Cui 等人(2014)应用边界范式发现,词首词素字频的识别制约着词尾词素的识别,且词尾词素语义的获得还受到了词首词素字频的调节。Bertram 等人(2004)发现与词首词素字频较低的条件相比,词首词素字频较高时复合词的注视时间显著降低。后续研究进一步巩固了词首词素的主体地位,长复合词中读者首先加工词首,然后加工词尾,最后加工整词(Hyönä et al.,2004;Pollatsek&Hyönä,2005)。
中文阅读研究认为词汇加工早期阶段是词素层次的通达,词素身份信息起主要作用,晚期是整词的检验,词素位置信息开始起作用(彭聃龄 等,1999),词素身份信息确定后读者开始加工词素的位置信息,而单独呈现双字词时,词素位置信息的重要性在早期阶段表现明显(吴琼,2013),当词素经常出现在某一位置时,则对词素位置产生了期待。例如,“批”字组成的复合词中其常出现在词首,如“批改”、“批评”,读者在学习和阅读过程中常接受这一讯息,加深了心理词典中“批”居于词首的印象,对“批”位于词首也产生更多期待。当看到“批改”时,词首“批”被激活的同时所携带的高词素位置概率特征亦被激活。此时,如果被试觉察到当前汉字实际位置与期望位置相符,词的激活水平比较高,词汇识别时间较短。一旦读者发现当前汉字实际位置与期望位置相矛盾,如“批”字出现在不常出现的词尾位置,组成“分批”一词,被试需花费额外的认知资源处理这一冲突,词汇识别时间延长。综上,低频词条件下词素特征信息得以表达,而加工高频词的词素位置概率信息时,其词素语义激活相对较弱,以整词形式完成了词汇识别,为此词素提供的位置概率信息被掩盖。两个实验以词汇判断的方式独立呈现双字词的词素位置,一般而言读者是在句子中理解词汇,那么,在贴近自然阅读的句子中,词素位置概率是否还会发生作用?首、尾词素位置概率作用的发挥是否一致?实验2a 将探索处于生态效度更高的自然阅读中词素位置概率的现实效用。
4 实验2a: 高频词条件下词素位置概率在句子阅读中的作用
4.1 实验目的
通过操纵词首和词尾的词素位置概率的高低,进一步考察在自然阅读过程中词素位置概率线索是否会影响被试的词汇识别与切分。
4.2 实验方法
4.2.1 被试
60 名天津师范大学在校学生,其中女生42 名,男生18 名,年龄在18~24 岁之间(M=19.33,SD=1.54)。被试均为汉语母语者,视力或矫正视力正常,均不知实验目的,实验结束可获得一定报酬。
4.2.2 实验设计
采用2 (词首词素位置概率: 高、低) × 2 (词尾词素位置概率: 高、低)的两因素被试内重复测量设计。
4.2.3 实验材料
参照中国电视电影旁白的汉语词汇和笔画频率语料库(Cai & Brysbaert,2010),为保证词素位置概率条件的区分度,将词素位置概率高于0.7 定义为高概率,低于0.3 定义为低概率。操纵词素位置概率的高低,共选取96 个双字词,将其分为4 种条件(每种条件下24 个双字词): (1)高词首词素位置概率、高词尾词素位置概率;(2)高词首词素位置概率、低词尾词素位置概率;(3)低词首词素位置概率、高词尾词素位置概率;(4)低词首词素位置概率、低词尾词素位置概率。控制4 种条件下双字词的词频差异不显著(F(3,92)=0.23,p=0.87)、词首笔画数差异不显著(F(3,92)=1.43,p=0.23)、词尾笔画数差异不显著(F(3,92)=1.11,p=0.35)、词首字频(F(3,92)=0.89,p=0.44)和词尾字频(F(3,92)=0.18,p=0.90)的差异不显著。考虑到词素结构可能对词汇认知加工造成影响,材料选取时尽可能避免选取偏正复合词和含有词缀的双字词。同时,控制4 种条件词首和词尾的构词能力之间差异不显著,ts 〈 1,ps 〉 0.05。请15 名不参加实验的同学评定目标词的熟悉度和语义透明度,其中1 代表“非常不熟悉”,5代表“非常熟悉”,1~5 的变化代表词语熟悉性的增强,目标词的熟悉度为M=4.31 (SD=0.12);语义透明度指的是复合词的语义能从其各个组成词素的语义推知的程度。其中1 代表“完全不透明词”,5代表“完全透明词”,1~5 的变化代表语义透明度的增强,目标词的语义透明度为M=4.24 (SD=0.35)。实验材料的基本情况见表12。

表12 实验材料的基本情况
依据目标词编制句子,目标词出现在句子中间位置,句子长度在18~20 个汉字之间。请15 名不参加正式实验的大学生评定句子的通顺性,从1“非常不通顺”到5“非常通顺”,平均通顺性为M=4.22 (SD=0.28)。选取15 名不参加正式实验的大学生对句子的难度进行 5 级评定,从1“非常简单”到5“非常难”,平均难度为M=1.86 (SD=0.21)。同时,对双字词词首和词尾的构词能力进行控制,4种条件首、尾的构词能力差异不显著,ts 〈 1,ps 〉0.05。另选取15 名不参加正式实验的大学生对句子的预测性进行评定。预测性评定采用补充句子的方式,即将实验句中目标词及以后的内容删除,让被试依据所剩的部分将句子补充完整。如果被试所填内容与目标词一致,则表明预测成功,计1 分;否则表明预测失败,计0 分。经计算,句子的平均预测性为:M=0.012 (SD=0.42),说明目标词的可预测性非常低。为了避免被试对实验句形成反应定势,在阅读材料中随机插入填充句。采用拉丁方平衡设计将实验材料分为4 个Block,每一个Block 包含4个练习句、24 个实验句和24 个填充句。实验材料举例如表13。

表13 实验材料举例
4.2.4 实验仪器
采用Eyelink 1000 plus 眼动仪,采样频率1000 Hz。显示器分辨率为1920×1080,刷新率140 Hz。被试与屏幕相距75 cm。实验材料的汉字为32 号宋体,汉字为41×41 像素,约呈0.75°视角。
4.2.5 实验程序
每个被试单独施测。首先,主试讲解指导语确保被试理解实验过程。开始前对眼动仪进行三点校准,平均误差小于0.3。之后被试阅读屏幕上的句子,句子呈现前屏幕左侧出现注视点“+”,要求盯住“+”触发句子阅读。实验包括4 个练习句,24 个实验句,24 个填充句,其中14 个句子后面有简单的“是”或“否”的判断题,“是”或“否”的判断各占一半,以确保被试认真阅读句子。实验材料逐屏呈现,被试阅读完一屏后按空格键进入下一个句子。实验过程中每读完5 个句子做一次三点校准,其他每个句子做一点校准。主试实时监视眼动仪器必要时进行重新校准,整个实验大约15 分钟。
4.2.6 分析指标
参照以往研究(Liang et al.,2015),选取首次注视时间、凝视时间、回视路径时间和总注视时间进行分析。首次注视时间是指首次通过兴趣区的首个注视点的注视时间,与兴趣区内有多少注视点无关;凝视时间是指从首次注视开始到注视点第一次离开所在兴趣区之间的持续时间;回视路径时间是指从首次注视开始,到注视点落到所注视兴趣区的右侧区域为止(不包括右侧区域这一注视点),之间所有注视点持续时间的总和;总注视时间是指落在兴趣区内所有注视点的持续时间的总和。其中,首次注视时间和凝视时间是反映词汇通达早期阶段特征的有效指标,回视路径时间既能反映词汇通达的过程,还可反映词汇后期加工和语义的整合过程,总注视时间反映的是词汇加工的总体过程(闫国利 等,2013)。
4.3 实验结果
被试正确率在85%以上(SD=4.2%),说明其认真阅读了句子。参考以往研究的数据删除标准(Rayner,2009): (1)删除注视点持续时间小于80 ms 或大于1200 ms 的注视点(1.9%)。(2)删除单个句子注视点少于5 个的试次或追踪丢失的数据(0.42%)。基于R语言环境(R Development Core Team,2016)下的线性混合模型(Linear Mixed-effects Models,LMMs)和lme4 数据包统计数据(Bates et al.,2017)。分析时对注视时间进行了log 转换,将首、尾词素位置概率及其交互作用作为固定效应纳入模型,被试和项目作为交叉随机效应。首先从最大效应模型开始,若模型无法拟合则依次简化最大模型直至拟合。不同词素位置概率条件下眼动指标的描述统计结果见表14,线性混合模型统计结果见表15。

表14 不同词素位置概率条件下眼动指标的描述统计结果
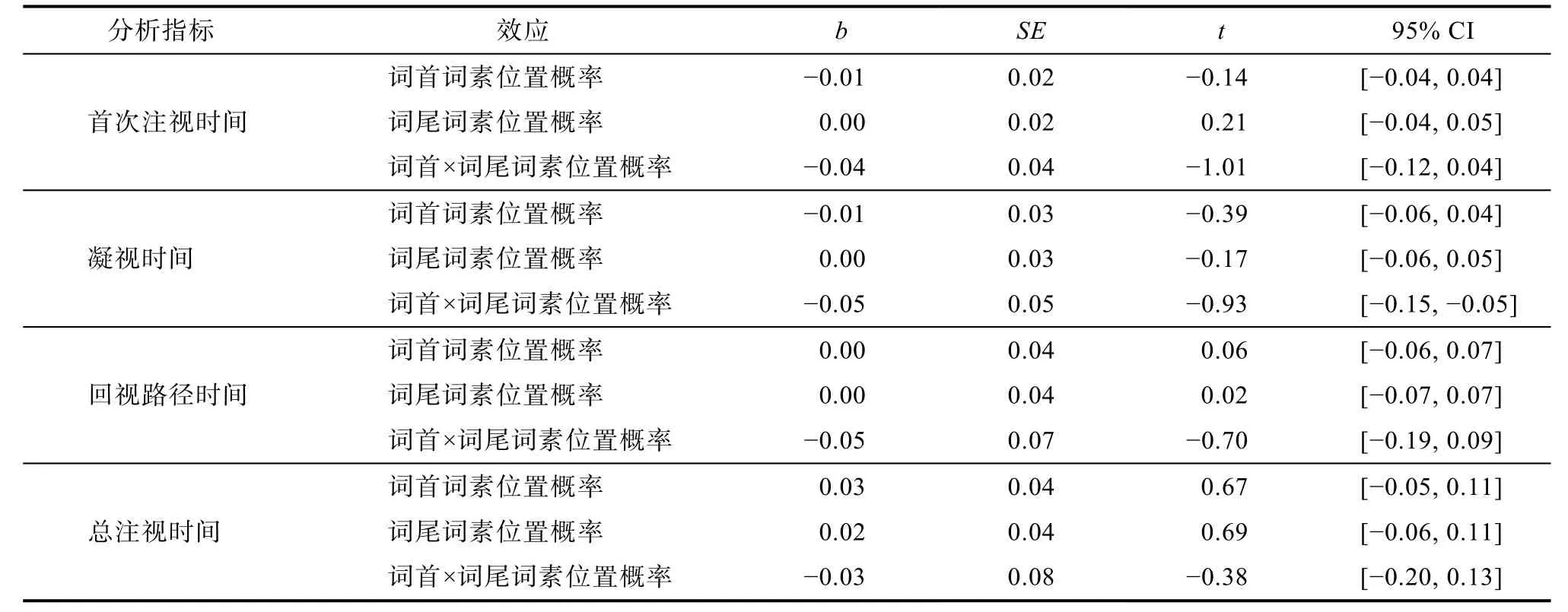
表15 不同词素位置概率条件下线性混合模型的统计结果
根据线性混合模型的统计结果,词首词素位置概率在首次注视时间(t=-0.14,p=0.89)、凝视时间(t=-0.39,p=0.70)、回视路径时间(t=0.06,p=0.95)以及总注视时间(t=0.67,p=0.51)上的主效应不显著;词尾词素位置概率在首次注视时间(t=0.21,p=0.84)、凝视时间(t=-0.17,p=0.86)、回视路径时间(t=0.02,p=0.99)及总注视时间(t=0.69,p=0.50)上的主效应不显著;首、尾词素位置概率在首次注视时间(t=-1.01,p=0.32)、凝视时间(t=-0.93,p=0.36)、回视路径时间(t=-0.70,p=0.49)及总注视时间(t=-0.38,p=0.71)的交互作用不显著。研究结果表明,高频词条件下词素位置概率未影响读者的阅读行为。
4.4 讨论
实验2a 结果表明,当目标词为高频词时,词首与词尾不同词素位置概率水平下的注视时间没有显著差异。同时,综合实验1a 和1b 的结果发现,当目标词为低频时,读者能利用词首词素位置概率线索指导阅读,而目标词变为高频时,词首词素位置概率不再显著影响阅读进程,这个结果与复合词混合通达表征模型的观点较为吻合。Caramazza 等人(1988)提出的混合通达表征模型(Augment Addressed Morphology)认为,词汇识别时既存在单独的词素表征,也存在整词表征,词汇识别是词素与整词激活并相互作用的结果。例如,加工“walked”可激活“walked”、“talked”等整词,也可激活“walk”、“ed”这样的词素,整词与词素谁先达到激活阈限谁便在竞争中胜出。为此,对于新词或低频词,由于在通达表征中没有相对应的整词表征,而是相应的词素被激活,词素单元在竞争中更易胜出,而后词素所携带的位置概率特征可能被激活;而对于熟悉的高频词,其组成成分经常同时出现,倾向形成独立的识别单元,由此整词更易被激活继而通达了语义,这样的话,可能会减少词素位置概率提取或使用的机会,词素携带的位置概率信息未得到充分表达。为此,实验2b 将探究含词素位置概率信息的低频目标词置于句子中的眼动规律,进一步厘清首、尾词素位置概率在词汇加工中的重要性。
5 实验2b: 低频词条件下词素位置概率在句子阅读中的作用
5.1 实验目的和假设
通过操纵词首和词尾的词素位置概率的高低,考察在低频词条件下词素位置概率线索是否会影响被试的词汇识别与切分。
5.2 实验方法
5.2.1 被试
同实验2a。
5.2.2 实验设计
同实验2a。
5.2.3 实验材料
参照中国电视电影旁白的汉语词汇和笔画频率语料库(Cai & Brysbaert,2010),为保证词素位置概率条件的区分度,将词素位置概率高于0.7 定义为高概率,低于0.3 定义为低概率。操纵词首与词尾词素位置概率的高低,将128 个双字词分为4 种条件(每种条件下32 个双字词): (1)高词首词素位置概率、高词尾词素位置概率;(2)高词首词素位置概率、低词尾词素位置概率;(3)低词首词素位置概率、高词尾词素位置概率;(4)低词首词素位置概率、低词尾词素位置概率。控制每一种条件下双字词的词首笔画数与词尾笔画数、词首字频与词尾字频的差异不显著(t(62) 〈 1,p〉 0.05)。控制4 种条件下双字词的词频差异不显著(F(3,124)=0.75,p=0.52)、词首笔画数差异不显著(F(3,124)=0.83,p=0.47)、词尾笔画数差异不显著(F(3,124)=0.94,p=0.42)、词首字频(F(3,124)=0.92,p=0.43)和词尾字频(F(3,124)=1.88,p=0.10)的差异不显著。考虑到词素结构可能对词汇认知加工造成影响,材料选取时尽可能避免选取偏正复合词和含有词缀的双字词。同时,控制4 种条件词首和词尾的构词能力之间差异不显著,ts 〈 1,ps 〉 0.05。此外,请15 名不参加实验的同学对目标词的熟悉度和语义透明度进行评定,其中1 代表“非常不熟悉”,5 代表“非常熟悉”,1~5 的变化代表词语熟悉性的增强,目标词的熟悉度为M=4.06 (SD=0.19);语义透明度指的是复合词的语义能从其各个组成词素的语 义推知的程度。其中1代表“完全不透明词”,5 代表“完全透明词”,1~5 的变化代表语义透明度的增强,目标词的语义透明度为M=4.15 (SD=0.11)。其中,目标词的词频显著低于实验 2a 中目标词的词频(t=-10.49,p〈0.001)。实验材料的基本情况见表16。

表16 实验材料基本情况
依据目标词编制句子,目标词出现在句子的中间位置,句子长度在18~20 个汉字之间。选取15名不参加正式实验的大学生对句子的通顺性进行5级评定,从1“非常不通顺”到5“非常通顺”,平均通顺性为M=4.01 (SD=0.32)。选取15 名不参加正式实验的大学生对句子的难度进行5 级评定,从1“非常简单”到5“非常难”,平均难度为M=1.89(SD=0.21)。考虑到词素结构可能对词汇认知加工造成影响,保证实验选取的词汇材料词素与整词语义关联程度相同,并避免选取偏正复合词和含有词缀的双字词。另外,选取15 名不参加正式实验的大学生对句子的预测性进行评定。预测性评定采用补充句子的方式,即将实验句中目标词及以后的内容删除,让被试依据所剩的部分将句子补充完整。如果被试所填内容与目标词一致,则表明预测成功,计1 分;否则表明预测失败,计0 分。经计算,句子的平均预测性为:M=0.009 (SD=0.38),说明目标词的可预测性非常低。为了避免被试对实验句形成反应定势,在阅读材料中随机插入填充句。采用拉丁方平衡设计将实验材料分为4 个Block,每一个Block 包含4 个练习句、32 个实验句和32 个填充句。实验材料举例如表17。
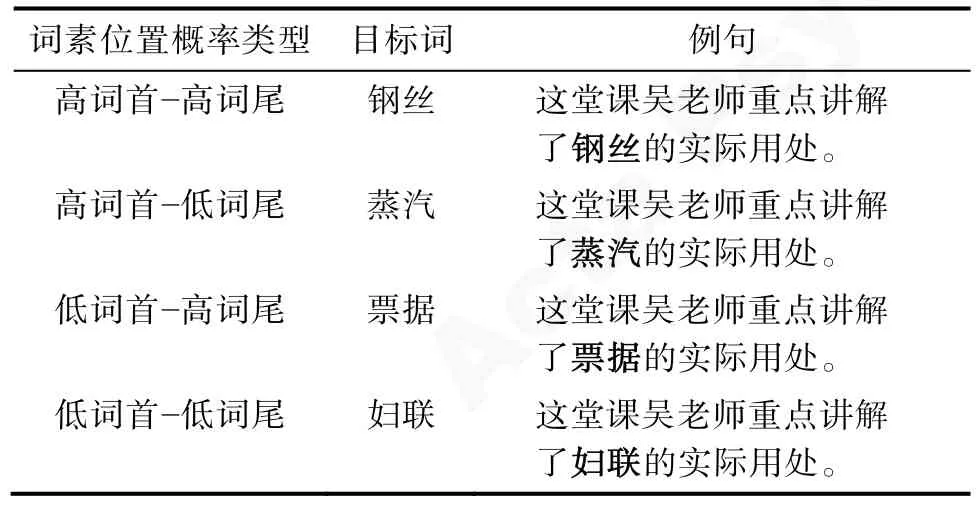
表17 实验材料举例
5.2.4 实验仪器
同实验2a。
5.2.5 实验程序
同实验2a。
5.2.6 分析指标
同实验2a。
5.3 实验结果
所有被试正确率均在85%以上(SD=5.9%),说明被试都认真阅读了实验材料并且理解了句子的内容。参考以往研究的数据删除标准(Rayner,2009)对眼动数据进行整理: (1)删除注视点持续时间小于80 ms 或大于1200 ms 的注视点(2.1%)。(2)删除单个句子上的注视点总数少于5 个的试次或者追踪丢失的数据(0.68%)。眼动数据基于 R 语言环境(R Development Core Team,2016)下的线性混合模型(Linear Mixed-effects Models,LMMs)和lme4 数据包进行统计(Bates et al.,2017)。数据分析时对注视时间指标的数据进行了log 转换,将词首与词尾词素位置概率以及它们之间的交互作用作为固定效应纳入模型,对于因变量指标,模型的建立以被试和项目作为交叉随机效应。应用马尔可夫链蒙特卡罗(Markov-Chain Monte Carlo) 的算法得出事后分布的模型参数来作为显著性的估计值,这一统计算法的优势是可以同时反映来自被试和项目的变异(Baayen et al.,2008)。模型拟合时首先从最大效应模型开始,若复杂模型无法拟合则依次简化最大模型直至模型能够拟合。不同条件下眼动指标的描述性统计结果见表18,线性混合模型统计结果见表19。

表18 不同词素位置概率条件下眼动指标的描述统计结果
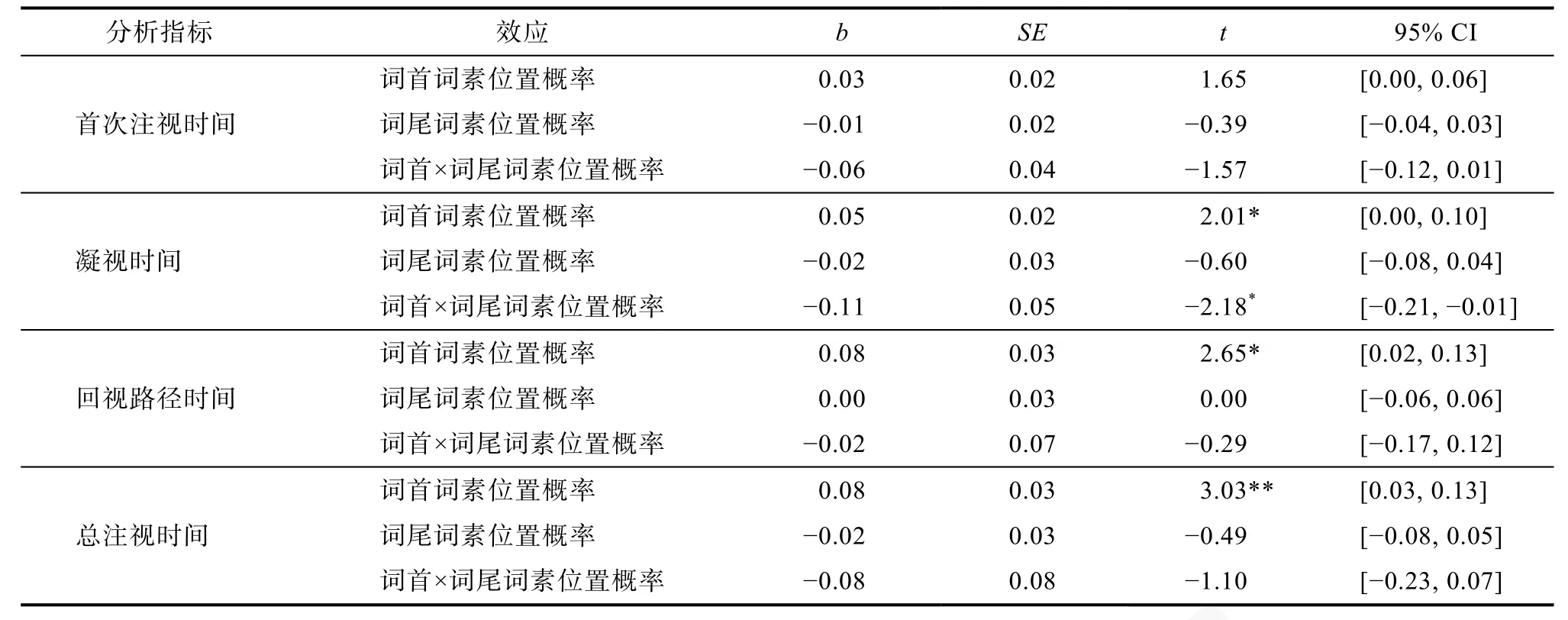
表19 不同词素位置概率条件下线性混合模型的统计结果
根据线性混合模型的统计结果,词首词素位置概率在凝视时间(t=2.01,p=0.05)、回视路径时间(t=2.65,p=0.01)、总注视时间(t=3.03,p=0.004)上的主效应显著。词尾词素位置概率在首次注视时间(t=-0.39,p=0.69)、凝视时间(t=-0.60,p=0.55)、回视路径时间(t=0.00,p=0.99)、总注视时间(t=-0.49,p=0.63)上的主效应均不显著。词首与词尾词素位置概率交互作用在凝视时间上显著(t=-2.18,p=0.03),在首次注视时间(t=-1.57,p=0.12)、回视路径时间(t=-0.29,p=0.77)、总注视时间(t=-1.10,p=0.28)上的交互作用均不显著。
针对词首与词尾词素位置概率在首次注视时间、回视路径时间、总注视时间上均不存在交互效应,通过贝叶斯因子(Bayes Factor)进一步检验首、尾词素位置概率交互作用不显著的可靠性。应用Bayes Factor 数据处理包,分别对首次注视时间、回视路径时间、总注视时间进行线性混合模型的贝叶斯分析(Morey et al.,2018)。分析将既包含两因素主效应也包含两因素交互作用的全模型(BFFull),与包含两因素的主效应模型(BFMain)相比较,即BF=BFFull/ BFMain。若BF值小于1,表示支持虚无假设,即两因素交互作用不显著;若BF值大于1,则支持备择假设,即两因素交互作用显著存在。在分析过程中,选取默认的先验概率值0.5,设定蒙特卡罗迭代次数(Monte Carlo iterations)为100000。贝叶斯分析结果显示所有指标BF值均小于1 (首次注视时间: 1 : 3.03;回视路径时间: 1 : 6.41;总注视时间:1 : 11.56),分析结果更加支持词首与词尾词素位置概率之间不存在交互作用。
5.4 讨论
实验2b 结果表明,与词尾词素位置概率相比,词首词素位置概率对词汇识别与切分占首要地位。在反映词汇早期加工指标的凝视时间上,词首词素位置概率主效应显著;在反映词汇后期语义整合的眼动指标回视路径时间、总注视时间上主效应亦显著,这意味着词首词素位置概率的作用近乎贯穿了词汇加工的整个过程。大量实证研究肯定了词首的加工优势,拼音文字的研究指出词首字母与高级认知功能高相关,尾字母与低水平的视知觉有关(Johnson&Eisler,2012)。White 等人(2008)通过变换词首与词尾字母的位置区分首、尾字母之于词汇识别的重要性,发现变换词首字母的注视时间显著高于词尾变换,词首字母在词汇识别中发挥了关键作用。相关中文研究认为词首字频在一定程度上调节尾字信息的获得和加工(Yan et al.,2006)。吴琼(2013)通过对目标词设置4 种条件(原词、换位、首字掩蔽、尾字掩蔽,如“精力”、“力精”、“吅力”、“精吅”)考察词素位置信息的重要性,研究发现当双字词词首被掩蔽时(如“吅力”)加工难度最大,进一步印证词首在词汇加工过程中的重要性。
此外,自我组织词汇习得与识别模型(selforganizing lexical acquisition and recognition,SOLAR)指出,字母位置的激活程度从词的左侧到右侧是递减的,词首字母获得了加工优势(Davis,2001)。Whitney (2001)提出的SERIOL (sequential encoding regulated by inputs to oscillations within letter units)模型也指出,字母的兴奋性输出在整词上呈梯度变化,变化方向是从词首向词尾逐渐减弱。Zhou 和Marslen-Wilson (1999)认为首词素的加工会激活整词的语义表征,继而影响尾词素识别。综上,词首词素位置在词汇识别与加工过程中具有一定优势。依据汉语阅读的词切分和识别模式(Li et al.,2009),知觉广度范围内的字均被激活,字所携带的位置信息亦被激活。当词首词素位置概率较高时,词首携带的词素位置概率信息容易被激活,例如“钢”字位于词首的词素位置概率为0.87,那么“钢”居于词首的信息被预先激活,当阅读“钢丝”一词时,被试发现当前汉字的实际位置与惯常位置相契合,于是词汇加工较快,反之亦然。
6 综合讨论
本研究通过词汇判断和眼动实验,探讨了词素位置概率信息与中文词汇识别与切分之间的关系。综合分析4 个实验发现词素位置概率能有效引导读者的阅读行为,且作用发挥受整词词频影响,读者在低频双字词识别中更依赖词素位置概率信息。值得一提的是,研究结果显示词首词素位置概率的影响甚于词尾词素位置概率,且眼动实验发现词素位置概率效应持续发生在词汇加工的早、晚期阶段。在单词独立识别及句子语境中均发现了较为稳健的词素位置概率效应,下面分别讨论词素位置概率在中文词汇识别与切分中的作用及影响因素。
6.1 词素位置概率在中文词汇识别与切分中的作用
本研究发现词素位置概率能够促进词汇的识别与切分,词素位置概率越高注视时间越短,且简单线性回归模型说明了这一注视事件的规律。这与连坤予等人(2021)的研究结果具有较强一致性。基于Li 和Pollatsek (2020)提出的中文阅读整合模型,知觉广度范围内的汉字被平行激活,汉字所组成的词相应被激活。当注视目标词时,目标词的汉字被激活,字所携带的位置信息亦被激活,词素位置信息的激活强度与其所处位置的使用频率关系密切。换言之,某一词素位置的使用频率越高,词素被激活的水平越高。在中文词汇的学习和使用过程中读者的阅读经验不断增加,逐渐意识到一些字常出现在词首,而另一些字常居于词尾,词素与词素位置的联系得到强化。鉴于此,若词素实际位置与预期位置相符,词切分较容易;若词素实际位置与预期位置不符,需启动词素位置的再分析,对词素出现的实际位置与惯常位置进行核证,为解决这一位置冲突,读者不得不对有限的认知资源进行二次分配,致使注视时间增多。同时,依据激活扩散模型(Collins & Loftus,1975)和交互激活模型(McClelland&Rumelhart,1981),中文词汇识别是一个交互激活的过程,字特征信息的激活前馈到词水平激活相应词单元。词的激活反馈到组成该词的字水平,组成优势词的字的识别更快。当加工双字词的首字时,其所携带的高词素位置概率信息被激活,以该字开头的候选双字词更易激活,被激发的候选双字词反过来促进词首位置的识别,词素位置的使用频率越高激活越快,最终使词汇识别速度加快。
需关注的是,当前研究发现词首词素位置概率的作用更为关键,且观察到首、尾词素位置概率的交互作用不显著,这说明词首词素位置概率对词汇识别的促进作用具有独立性,不受词尾词素位置概率影响。大量实证研究支持了词首位置的重要性,Taft(2004)认为在双词素词通达过程中,首词素是主要搜索对象,尾词素的作用相对较小。词汇开始部分所携带的信息量(如语义或词频)要大于结尾部分的信息量(Shillcock et al.,2000)。字母换位效应的研究认为含有字母换位单词的句子会造成读者认知资源的额外损耗,其损耗程度与单词字母的换位位置相关,换位发生在单词开头时认知资源损耗最大,词尾次之(Perea & Lupker,2003)。注意资源的分配受字复杂性的影响,这种影响显著体现在复合词的词首位置,词尾则没有(Ma & Li,2015)。Davis(2001)提出的自我组织词汇习得与识别模型指出,每个字母的识别与自身的激活水平有关,首字母激活水平最高,随后激活水平递减,最后一个字母激活水平最低。
来自汉语表意文字的研究也印证了首词素的激活优势,徐迩嘉和隋雪(2018)发现目标词的首字身份信息一旦破坏,词汇的注视时间将显著增加。陈曦等人(2006)采用语义启动和色词干扰范式发现,首词素在三种不同的刺激间隔条件下激活都达到较高水平。同时,结合Inhoff 和Wu (2005)提出的中文词汇识别的单向切分假设(un-directional parsing hypothesis),汉语是从左至右逐词展开的,词切分遵循着从左向右的序列,受注意梯度的影响左侧汉字得到的注意资源较多,且资源从左至右传递,左侧汉字的激活早于右侧汉字,词首信息激活的同时词素携带的位置信息亦被激活。若词素在词首位置的使用频次较高时,对词素位置的敏感性提升,当词首词素的实际位置与固有位置契合时,高词首词素位置概率向整词释放兴奋,加快了词汇的识别速度。
6.2 词频对词素位置概率发挥词切分作用的影响
本研究发现词频调节了词素位置概率对词汇识别与切分的影响,当目标词为高频时,词首词素位置概率对阅读行为的影响较弱,而加工低频词时词首词素位置概率发挥了显著作用。有研究指出低频词在识别过程中存在词素的语义激活,而高频词词素的语义激活不明显,低频词更易被分解表征,高频词则倾向于整词表征(俞林鑫,2006)。既往研究指出不同词频条件下读者耗费的心理资源不同,低频词的加工负荷高于高频词(高晓雷 等,2020;Rayner,2009;Vorstius et al.,2014),即当中文读者在句子阅读过程中遭遇低频词时,需要投入更多的认知资源来加工低频词汇,而词素特征在低频词条件下更易显现(白学军 等,2015;Liversedge et al.,2014),此时固有的词素位置概率信息为读者提供了隐含的词边界。当目标词转为高频条件时,由于人们常能听到、见到或书写高频词,刺激材料的加工难度降低,倾向以整词形式表征,导致激活水平较高,在来自词素水平的前馈激活到来之前很可能已经被识别了,因此使读者不能充分提取词素位置概率的特征信息,这在很大程度上弱化了词素位置冲突的潜在干扰,继而掩盖了词素位置概率的作用。Chu 和Leung (2005)的研究指出高频词倾向自上而下的整体加工,重视整体时局部的特征易忽略,此时难以析出词素,而低频词更倾向自下而上的局部加工,使局部的词素位置概率特征得到关注。
结合以往研究,词频在复合词表征中扮演了重要角色。我们都明白“海象”、“海马”这类词语表达的意义,读到这些词时可能头脑中还会闪现其视觉形象,然而我们不会把这些形象分解为海中的象、海中的马,可见一定存在与其相对应的整体单元。相对而言,如果看到“海兔”这个词,由于很少遇到“海兔”一词,心理词典中不大可能存在它的独立表征单元,整词通达受阻,那么就要通过词素通达。依据复合词的混合通达表征模型,心理词典中既存在词素表征,也存在整词表征,词汇识别是词素激活和整词激活相互作用的结果。低频词在日常阅读中不常见,以词素形式存于心理词典,且深受词素特征影响,使得词素位置概率的特征信息得以表征。在低频词的加工中激活了词素位置概率线索,助力词汇的识别与切分。反观高频词,日常阅读中出现的频率较高,激活阈限较低,通过整词的形式存储在心理词典中,对词素特征信息不够敏感,词素位置概率信息作用有限。
综合地看,词素位置概率在中文动态的词切分过程中发挥了作用,反映出汉语读者在长期接触汉字位置信息过程中所形成的心理倾向。而这种词素位置的识别能力是否具有发展性,还需后续研究进一步揭示,比如探查发展中的儿童、语言发展受阻的阅读障碍儿童,以及阅读经验相对丰富的老年人对词素位置概率的运用或保留情况。综上,读者在阅读过程中抽取了词素位置概率这项特征,这也意味着词素作为一个独立的语言单元得到了加工,说明中文复合词加工过程中存在词素通达。而目标词转为高频词后词素位置概率的特性表现的不明显,说明复合词加工过程中也存在整词通达。综合而言,研究结果支持了中文复合词加工的混合通达表征模型。
7 结论
中文阅读中词素位置概率信息是读者重要的语言词切分线索,且与词尾词素位置概率相比,词首词素位置概率在词汇识别与切分过程中发挥的作用更大。同时,读者对词素位置概率信息的加工优势受整词词频的影响,研究结果支持复合词识别加工的混合通达表征模型。
猜你喜欢
考试与评价·八年级版(2020年5期)2020-10-29
学校教育研究(2019年1期)2019-12-08
鸭绿江·下半月(2019年7期)2019-11-05
亚太教育(2018年5期)2018-12-01
辞书研究(2017年3期)2017-05-22
中国修辞(2017年0期)2017-01-31
现代语文(2015年8期)2015-08-15
读者·校园版(2015年7期)2015-05-14
图书馆论坛(2014年8期)2014-03-11
心理学报(2014年4期)2014-02-02
