
一种基于地形预分类的渐进加密点云滤波方法
2023-02-07 03:09原瀚杰董丽梦黄达文陈泽佳
地理空间信息 2023年1期
谭 麒,原瀚杰,陈 亮,张 雨,何 勇,董丽梦,黄达文,陈泽佳
(1.广东电网有限责任公司肇庆供电局,广东 肇庆 526000)
点云滤波技术是机载激光雷达(LiDAR)数据预处理的重要环节之一,也是基于LiDAR数据生成和制作数字高程模型(DEM)的重要方法。点云滤波的核心功能是区分离散点云中的地面点和非地面点。目前国内外已有众多学者针对该问题开展了大量研究工作,主要可分为基于形态学、曲面拟合、图像分割、不规则三角网(TIN)和深度学习等技术的滤波方法。基于形态学的方法将点云转换为栅格化高程数据,根据局部区域内真实地形的几何特征,利用相应的图像处理方法进行滤波,具体包括渐进形态学[1]、多尺度表示[2]、图像补全[3]、Hermite变换[4]、顶帽变换[5]等。基于曲面拟合的方法利用一个连续的参数表面对真实地形进行逼近,通过测量点与拟合曲面的接近程度确定该点的类别,根据函数模型的不同可分为线性预测[6]、薄板样条[7]、二次曲面[8]等方法。基于图像分割的方法同样将点云进行栅格化处理,采用先聚类再判断分割块属性的策略进行分类[9-10],该过程中除直接利用高程值外,还可能采用回波数量[11]、最大回波高差[12]等信息作为额外判据。基于TIN的方法通常利用局部最低点构建初始TIN,然后通过逐步优化TIN实现滤波,其中具有代表性的是Axelsson P[13]提出的渐进加密三角网(PTD)算法;在此基础上,一系列改进的PTD算法得到发展,具体改进策略包括引入平滑约束[14]、增加山脊点以保留山体特征[15-16]、增加种子点[17]、引入支持向量机[18]或布料模拟技术[19]等。基于深度学习的方法主要通过近年来计算机视觉领域发展迅速的卷积神经网络等技术实现滤波[20-22],但该类方法通常对训练样本的标注质量和数量有较高要求。
作为目前生产实践中应用最广泛的滤波方法之一,经典PTD算法通常能在预先知晓数据地形类别、进而更改对应参数配置的前提下发挥良好性能;但对于平地/山区混合出现、地形类别难以明确定义的场景,利用同一套参数的适应性将可能下降,导致滤波结果存在山脊特征缺失或平坦地区凸起等问题。鉴于此,本文提出了一种基于地形预分类的改进PTD算法,通过二次滤波的思想,实现对混合地形点云数据的自适应高精度滤波。首先采用统一参数进行初次滤波,并利用滤波得到的地面点构建DEM,以DEM中的高程信息为引导进行地形预分类,得到平地和山区的地理范围;然后针对不同地形区域的点云数据,分别采用不同的参数配置进行二次滤波;最后对不同地形下的二次滤波结果进行合并,得到最终滤波结果。
1 研究原理与方法
1.1 经典PTD算法存在的问题
经典PTD算法通过迭代加密三角网的方式,在地面点密度足够的情况下,可保留地形的细节特征,在一定程度上能适应地形的复杂变化,但仍存在局限性。对于包含地势起伏较大的山区和含有大型建筑物的平地区域等混合地形只使用一套阈值参数难以取得较好的结果,植被覆盖的斜坡地形中一些小的起伏都可能导致地面点与非地面点的混淆,选取宽松的阈值可能导致山区无法检测出完整的地形特征,而选取保守的阈值又可能使平地区域的建筑物被误分为地面点。
1.2 基于地形预分类的改进PTD算法
针对经典PTD算法的上述问题,本文提出了一种基于地形预分类的改进PTD算法。具体算法流程如图1所示。
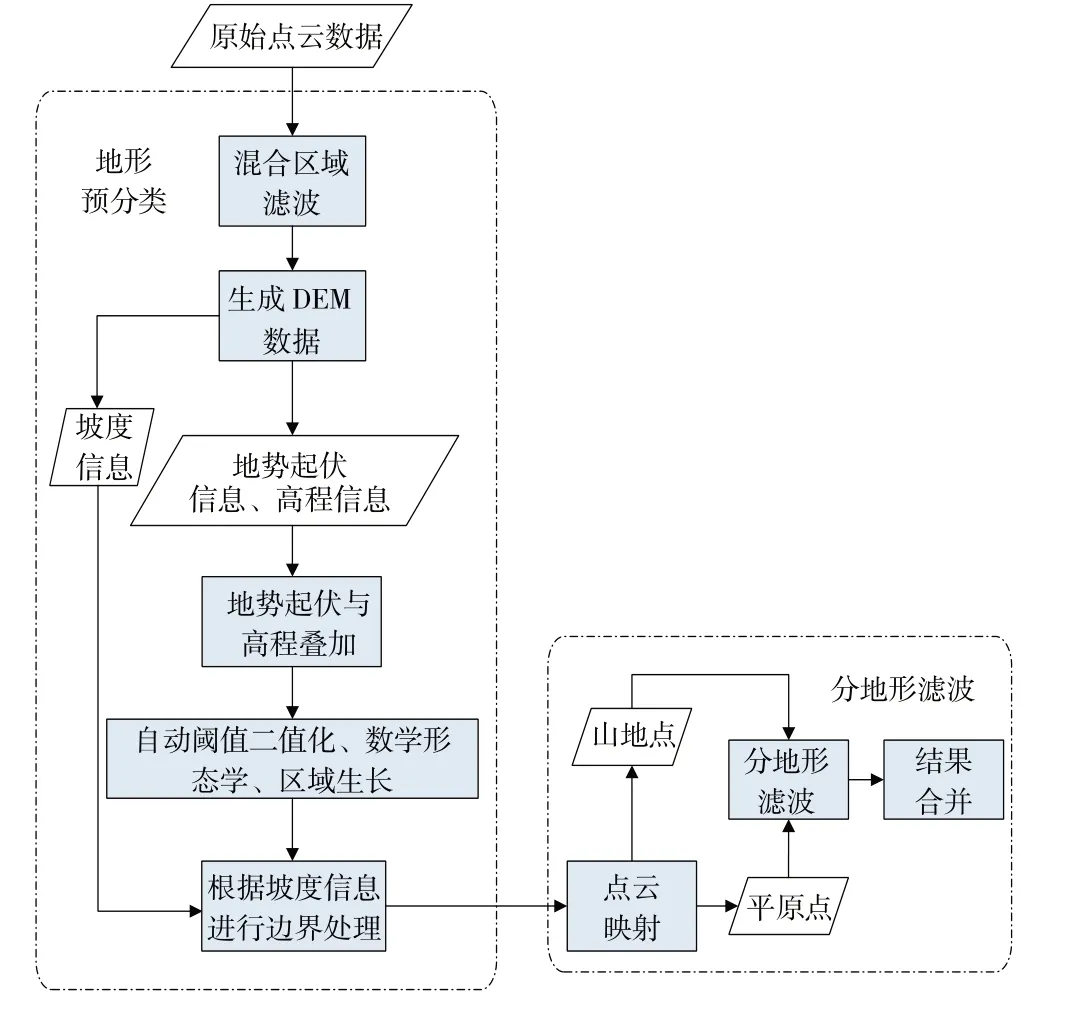
图1 技术流程图
1.2.1 地形预分类
本文将地形分为平地和山区,二者最显著的区别是地势起伏度、高程信息和坡度信息,因此以地势起伏和高程信息为主,坡度信息为辅,对整体区域进行地形分类。地形预分类的具体步骤为:
1)初次滤波。首先利用适中的滤波阈值进行初次滤波,得到初始DEM;再根据DEM计算每个点的地势起伏信息。地势起伏可表示为在某点的一定范围内,高程最大值与最小值的差值。由于山区地势起伏度大、高程大;平地区域地势起伏度小、高程小,因此利用高程和地势起伏信息点位相加后的数据可显著区分因特征丢失而平整的山脊区域和平地区域。对于叠加后的数据,计算统计直方图,遍历整个直方图,寻找两个峰值之间的最低点获取最优阈值,并进行二值化。
2)数学形态学和区域生长。若仅根据上述数据进行分类,无法很好地区分平地和山区,且分类区域破碎,综合利用数学形态学的腐蚀和膨胀可有效解决该问题。首先利用腐蚀形态学减缓边界的扩张,有利于后期边界处理;然后利用闭运算形态学填充物体内的细小空洞,连接邻近的物体,该过程中可调整窗口大小,以达到除去大块区域中破碎分类区域的目的,有效解决大块区域中的空洞问题。在山区的山谷部分,因其地势平坦,会被误分为平地,于是利用区域生长,对区域内的小块区域进行面积统计,小于阈值且其周围存在大量不同类别数据的,则改变其类别,从而实现山区和平地的分类。
3)坡度数据辅助边界处理。经过上述流程,在平地与山区的交界处,仍存在严重的误分现象。地形交界处坡度会急剧变化且山区坡度较大,因此可利用坡度数据减少这种误分现象。坡度较大的点可认为是山区地形。
1.2.2 不同地形的滤波参数选择
针对地形预分类后的点云,本文根据地形类型进行阈值设置:
1)平地区域。地面点选择窗口大小不能太小,否则无法避免较大人工建筑物的影响;角度与距离阈值不能太大,对于平地而言,初始TIN就能较完整的表达,若角度与距离阈值过大会使原本平坦的地面出现凹陷与凸起现象,将误分一些低矮地物,这些误分点在平地上更为明显。
2)山地区域。地面点选择窗口大小不能太大,否则地面点密度不足,难以完整表达地形;角度与距离阈值不能太小,山区地形崎岖,原本相邻地面点的高程就相差较大,若阈值太小会使最终地面点密度过低,尤其是在大面积植被覆盖的山区。
1.2.3 不同地形滤波结果的合成
分地形完成滤波后,需对滤波后的结果进行合并。由于分区域的点云是从同一个点云数据集中分离出来的,因此它们拥有相同维度,且不存在重叠区域,点云合并只是点云数量上的合并,且保留其地面点和非地面点属性,也可只保留地面点的点云,便于后续DEM的生成。
2 实验结果与分析
2.1 实验数据与参数选择
本文选取安徽省黄山市休宁县的一个山地/居住地混合地区作为实验区域,采集的LiDAR点云数据覆盖面积约为1 km2,平均点密度约为2.0点/m2,高程区间为204~430 m。实验区地势起伏大、山脊陡而窄、植被覆盖度高,植被下方地面点相较于裸露地表更稀疏;中间地带地势相对平坦,存在集中的居民地和河流,建筑密集但无单个超大面积建筑物。实验数据的整体情况如图2所示,图2a中白色矩形内为实验区可见光遥感影像;图2b为点云数据,激光点的高程由蓝至红逐渐升高,红框内为包含多个建筑物的居民区。本文对实验数据进行人工编辑,生成了1 m分辨率的DEM,作为参考数据用于实验的定量评价。

图2 实验数据
实验数据的地形预分类结果如图3所示,图3b中白色区域表示山区、黑色区域表示平地。通过与图2的比较发现,本文的预分类算法整体上取得了较好的地形区分效果。
图3 去噪前后残差值对比图
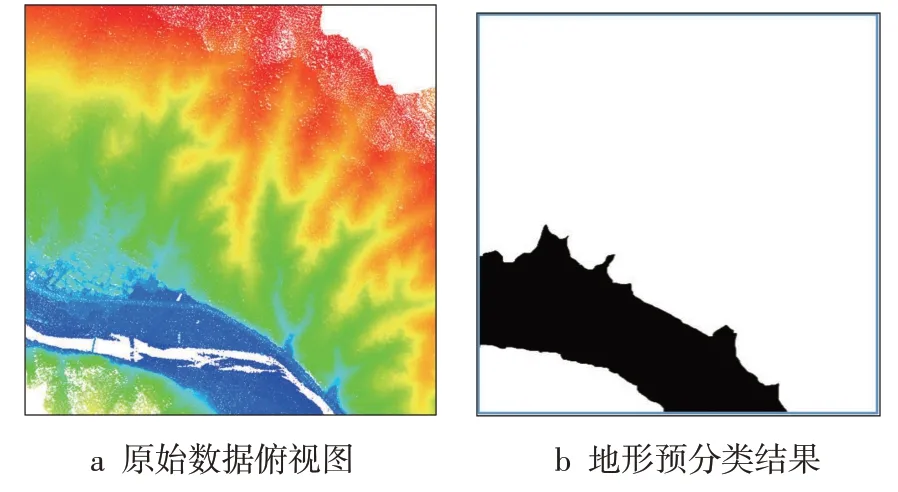
图3 原始数据与预分类结果
本文设置了3组对比实验参数:经典PTD平地参数、经典PTD山地参数、本文方法。对平地和山区分别采用平地参数和山地参数,不同方案的参数设计如表1所示。

表1 不同方案的参数设置
2.2 滤波结果与分析
利用表1中的参数分别进行3次试验,并利用滤波后的结果生成1 m分辨率的DEM,计算其与参考DEM之间的高程差异;再利用均方根误差(RMSE)对结果进行评价。评价结果如表2所示,可以看出,采用本文方法的滤波精度比经典PTD平地参数方法提升了0.551 m,而仅比经典PTD山地参数方法提升了0.129 m,较小的提升很大程度上与试验数据有关,该数据大部分区域为山区,因此利用本文方法精度提升不显著。

表2 RMSE评价结果
3种滤波方法结果的TIN渲染图如图4所示,可以看出,在经典PTD平地参数下,平地区域的滤波结果达到较好效果,但山地部分特征缺失严重,尤其是山脊部分缺失严重,导致山脊平整;在经典PTD山地参数下,更好地保留了山地部分特征,但平地区域凸起现象明显,尤其是建筑物区域;本文方法既保留了完整的山地特征,又兼顾了平地区域,达到了最好的效果。
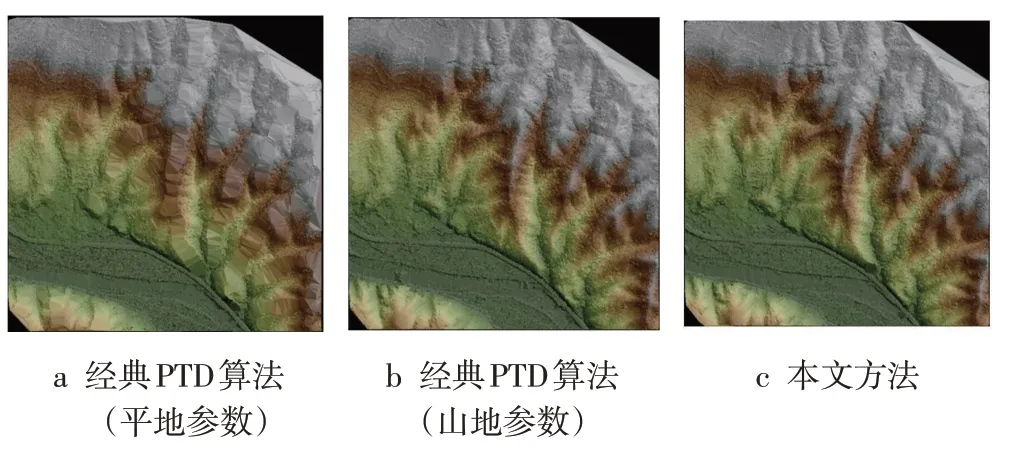
图4 滤波结果TIN渲染全局对比
3种滤波方法结果的局部TIN渲染结果对比如图5所示,分别选取山区和平地区域进行对比,可以看出,经典PTD山地参数方法和本文方法在山地区域的效果较好,山脊特征完整,而经典PTD平地参数方法的山脊特征严重缺失,如图5中红框所示;经典PTD平地参数方法和本文方法在平地区域相对平滑,没有明显的突起或凹陷,而经典PTD山地参数方法存在明显的突起现象,如图5中蓝框所示。

图5 滤波结果TIN渲染局部对比
高程差值分布如图6所示,可以看出,采用本文方法获得的结果在平地区域和山地区域的滤波精度均有明显提升,提高了PTD滤波的整体精度。
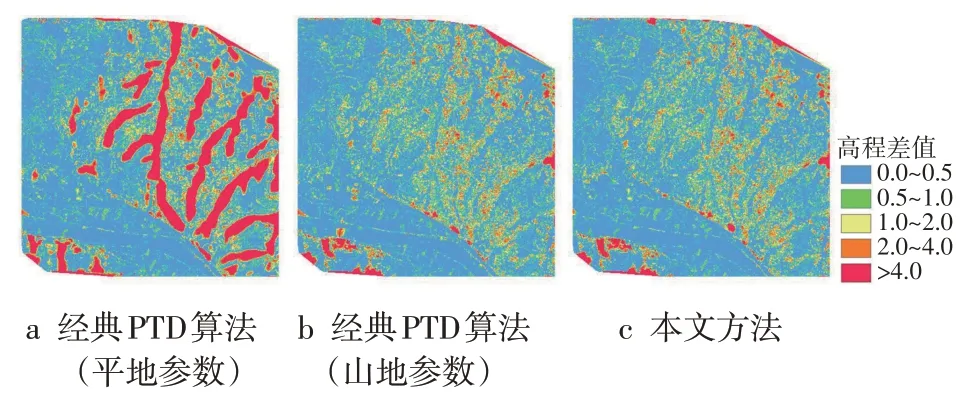
图6 滤波结果高程差值图
3 结语
本文在经典PTD算法的基础上,提出了一种基于地形预分类的改进PTD算法,通过利用和提取初次滤波结果中包含的高程信息实现地形预分类,进而有针对性地应用不同参数配置对不同地形进行滤波处理,以提高经典PTD算法处理混合地形数据的能力。实验结果表明,对于平地/山区混合地形数据,本文方法能较完整地保留不同地形的地表特征,所生成DEM的精度显著优于经典PTD算法。
猜你喜欢
黄河之声(2021年6期)2021-06-18
当代陕西(2020年23期)2021-01-07
当代陕西(2020年17期)2020-10-28
艺术品鉴(2019年12期)2020-01-18
小太阳画报(2018年7期)2018-05-14
当代工人(2018年21期)2018-03-06
文学港(2018年1期)2018-01-25
消费导刊(2017年8期)2018-01-18
全球定位系统(2015年4期)2015-02-28
浙江国土资源(2014年5期)2014-04-28
