
一种面向生态环境领域的知识图谱构建方法
2023-02-07 03:09王天一孟小亮
地理空间信息 2023年1期
王天一,孟小亮*,张 华
(1.武汉大学 遥感信息工程学院,湖北 武汉 430079)
知识图谱是通过节点和有向边的方式来表达实体、概念及其相互之间关系的大型语义网络,是大数据时代背景下从数据互联迈向知识互联服务的基础[1-2]。目前,知识图谱在很多领域发挥作用,而应用知识图谱的前提是构建知识图谱。地学领域已有学者探究面向灾害应急响应的地质灾害链知识图谱的构建方法,但所用方法未充分利用丰富的文献文本资源[3];部分信息管理领域学者对从文献等文本资源中提取的知识进行了研究,但通用方法对专业领域知识图谱构建具有局限性[4-5]。生态环境是人类赖以生存和发展的重要基础,人类社会的建设对生态环境安全造成了难以估量的影响,为了人类的可持续发展,生态环境的治理保护显得尤为重要[6]。生态环境领域期刊文献中的文本具有形式简洁、知识集中、现势性好等特点。本文选择生态环境领域文献作为数据源研究领域知识图谱的构建方法具有典型性。
本文设计的文献驱动的领域知识图谱构建方法如图1所示,包括数据获取与存储、领域知识图谱模式层构建、语料库语义标注、知识自动抽取与知识验证等部分。输入数据源可以是文献数据库、行业标准等,步骤①通过自动抓取程序、OCR文本识别以及PDF文本抽取等方式获取领域文献文本数据;步骤②将数据存储到原始语料数据库中;步骤③~④通过统计和机器学习方法,如TextRank、TF-IDF利用无监督关系抽取模型OPENIE抽取领域中关键的实体概念以及实体间的相关关系;步骤⑤利用领域知识和建模系统人工总结归纳、提炼得到领域知识图谱的模式层,并将其作为语义标注平台的标注依据;步骤⑥将模式层导入语义标注工具中;步骤⑦通过语义标注平台从原始语料库获取未标注的文本;步骤⑧人工参与标注领域实体和关系组建语义丰富的领域实体关系语料库;完成标注的语料库作为训练样本,通过步骤⑨对领域知识自动抽取算法进行训练;训练完成后,将未标注的大量文本数据通过步骤⑩输入领域知识抽取算法;经算法处理后,步骤○1得到抽取的知识三元组;步骤○12对抽取的知识三元组进行验证;步骤○13将符合规定条件的知识三元组存储到领域知识图谱中。
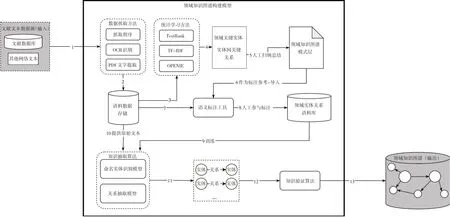
图1 文献驱动的领域知识图谱构建方法技术流程图
1 自动化语料内容数据获取
数据源的质量将对研究结果造成很大影响,文献文本数据规范、客观、可信。本文选取的数据来源于《生态学报》《环境科学》等专业生态环境领域中文期刊,均从收录期刊的文献数据库或期刊官网中获取。由于这些文本数据具有较规则的数据形式和特定的Dom结构,因此可通过分析页面要素的特点和规律,编写抓取程序对文章的标题、作者、关键词、摘要以及全文内容等信息进行自动获取。本文共获取2014—2020年见刊的5 000多篇文献约2 000万字的语料内容数据。
2 利用机器学习的图谱模式层构建
模式层构建是构建知识图谱的核心内容[7],模式层构建即构建本体模型。本体模型的构建包括手工构建和自动构建等方法[8],首先需明确概念、关系等内容,然后便可在某种本体语言的基础上进行本体建模[9]。传统构建方法几乎完全需要领域专家从语料文献中人工提炼,而自动构建方法可快速建立本体模型,但与人们的认知习惯有所差距[10]。因此,本文首先利用机器学习技术从大量生态环境领域文献文本中自动抽取领域关键词和领域关系,再人工从语义层面分析抽取结果,然后通过建模语言归纳出领域知识图谱的模式层,最终以构建的模式层为指导建立领域语料库。
2.1 领域关键词和领域关系抽取
关键词可集中反映相关领域的特征,本文利用TF-IDF与TextRank算法,并融合词频统计的方式自动挖掘生态环境领域关键词。TF-IDF算法兼顾了词频特征和逆文本频率指数,TextRank算法利用图的思想在提取时顾及了语义信息。在使用Python中文分词库jieba的基础上,利用各方法抽取领域关键词。为保证领域关键词抽取结果的可靠性,根据各方法的提取能力定权,加权计算综合重要性指标。I综合为综合重要性指标,I词频、ITF-IDF、ITextRank分别为归一化后的词频、TF-IDF值和TextRank值。利用式(1)得到1 500个关键词语及其重要级。为了可视化分析和直观展示抽取结果,本文制作了领域关键词云图(图2),可以看出,“污染”、“群落”、“生物”、“环境”等词语是生态环境领域中的关键概念,但“土壤”、“碳”等一些词语是要素实例,还存在一些高频词汇与生态环境领域相关性不高,如“评价”、“可能”、“说明”等。

图2 生态环境领域关键词云图
I综合=0.2I词频+0.4ITF-IDF+0.4ITextRank(1)
关系是指实体或概念间的联系,是知识图谱模式层的核心要素。本文首先对文本数据进行分句处理,然后通过OPENIE工具(来源于Stanford CoreNLP自然语言处理工具包)进行无监督开放信息抽取,最终提炼出135 971条关系三元组。人工筛除含义不明的关系后,统计关系出现的频次,归纳得到具有生态环境领域含义的关系,如表1所示。
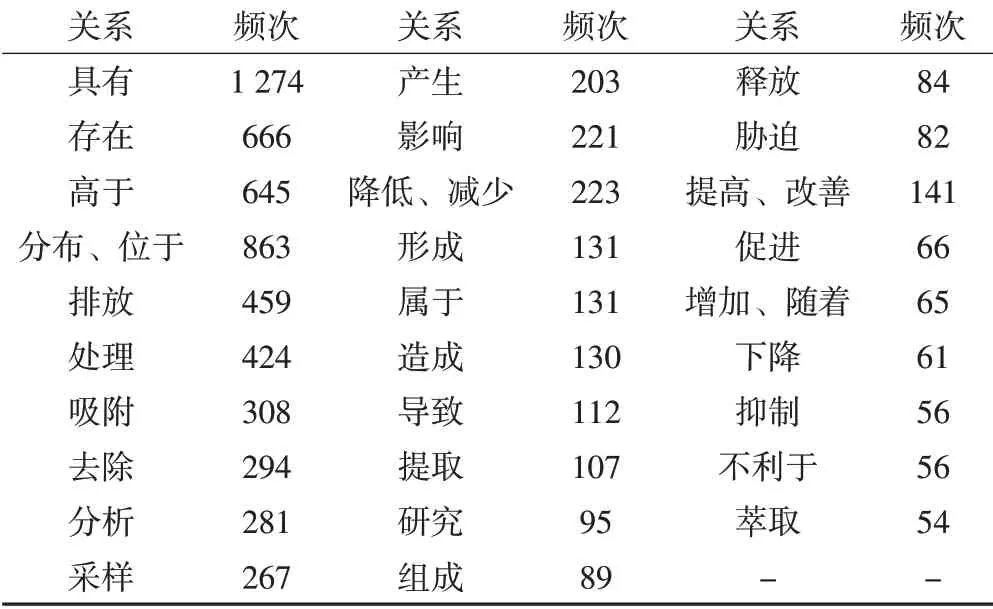
表1 生态环境领域关系抽取与筛选结果
2.2 领域知识图谱模式层建立
UMLS是一种工具化、集成化、跨领域的语言系统[11]。本文将UMLS的顶层概念(图3)与提取的领域关键词和关系相结合,构建生态环境领域知识图谱的模式层。
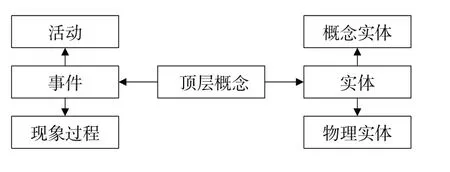
图3 UMLS顶层概念
参照UMLS体系,将领域知识体系在顶层概念中分为概念实体、物理实体、现象过程和活动4个实体,含义分别为人类主观认知的实体,客观存在的实体,唯物的、无意识的自然现象,计划性的、可归因的人类行为。通过对生态环境领域关键词和关系的归类,归纳得到生态环境实体列表与关系列表(表2、3)。

表2 生态环境领域实体列表
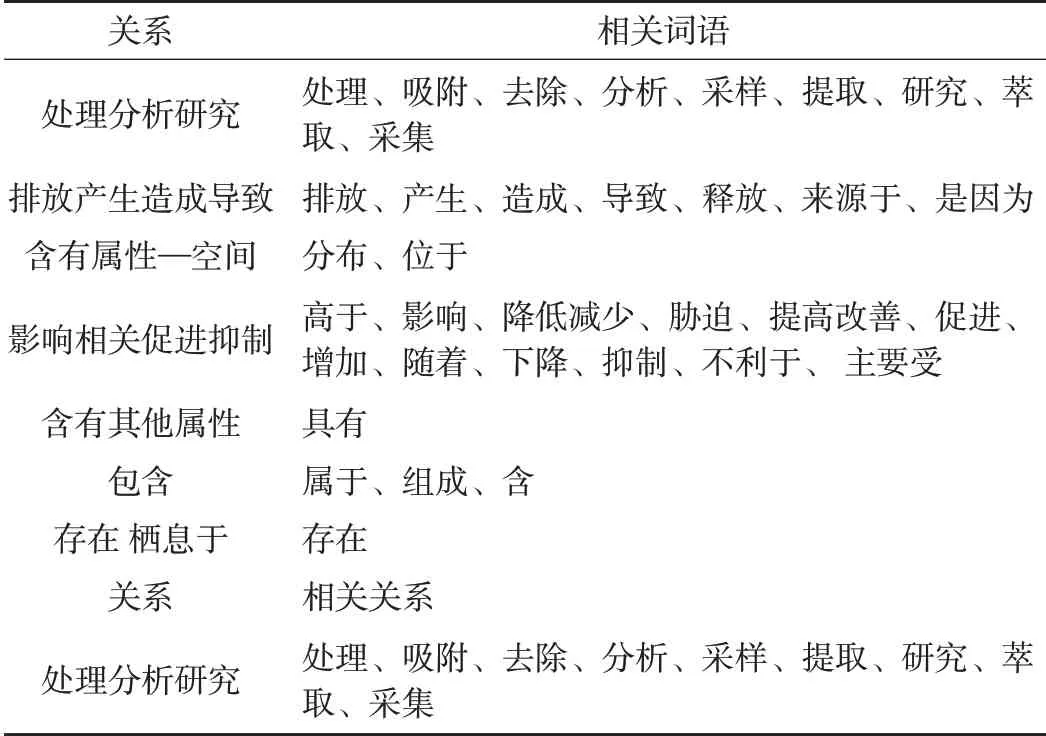
表3 生态环境领域关系列表
生态环境的核心是环境要素和生物体。人类活动造成的损害与生态治理过程中的分析都不断影响着生态环境[12]。沿此思路,本文将知识图谱模式层归纳为生态环境风险、生态环境主体、生态功能现象过程、人类活动、分析方法五大要素。UMLS顶层概念将实体间关系分为上下位关系和相关关系,其中相关关系涵盖环境实体间、属性实体间、环境与属性实体间的关系,环境实体间的关系又包含相关关系、概念关系、等价关系等。整合上述生态环境实体与关系,得到生态环境领域知识图谱模式层,如图4所示。
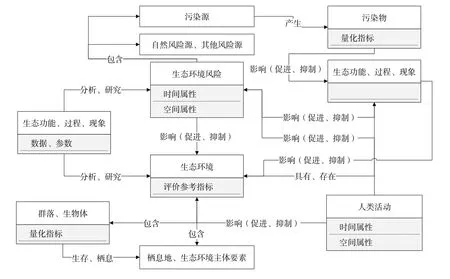
图4 生态环境领域知识图谱模式层
2.3 领域语料库建立
建立语料库是自动抽取知识的先决条件。目前生态环境领域还没有公开可查询的语义标注集,且诸多语义标注软件在用户体验上不能满足需求。语义标注应从知识图谱的模式层出发,包含实体和关系的标注。关系表达为三元组(E1,R,E2),R表征实体E1和E2的关系。本文设计和开发了语义标注软件工具,主界面如图5所示。语义标注流程为:①标注实体,标注人员在选定文字后,选择实体类型与空间信息,点击标注按钮即可完成实体标注;②标注关系,先在实体列表上设置头实体和尾实体,再设置关系类型点击标注关系按钮即可标注一条关系。本文共标注了40万字的语料,其中实体类别标签2.2万条,关系类别标签1.1万条。
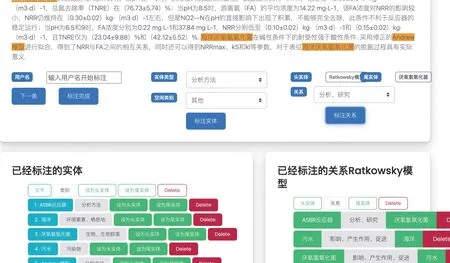
图5 设计实现的语义标注软件工具
3 领域知识图谱自动化构建
在生态环境领域,已有学者针对生态环境领域命名实体识别进行了研究,如蒋翔[13]等基于BiLSTM-IDCNN-CRF模型进行了生态治理技术领域命名实体识别。本文采用BERT-BiGRU-CRF模型进行生态环境领域实体提取,并讨论了最佳的实验参数;采用Transformer[14]特征提取网络对生态环境领域实体之间的关系进行抽取;利用校验次数和来源指数对抽取的知识进行质量验证,从而自动构建生态环境领域知识图谱。
3.1 实体信息自动抽取
在构建的语料库的基础上,通过程序生成训练样本,实体利用程序转换并输出参考BIO方案的标注结果,标记数据以60%、20%、20%的比例随机用于训练、验证和最终测试。BERT[15]是应用广泛的词向量编码模型,几乎替代了以Word2vec[16]为主流的词向量编码模型,在许多自然语言处理任务中精度更高;对于长序列文本处理,GRU[17]比LSTM[18]模型所需的训练样本更少,CRF[19](条件随机场)是序列化标注算法。本文利用样本训练BERT-BiGRU-CRF模型并测试,相关文献指出模型学习率与BatchSize比值越大泛化性越好[20],以此为指导权衡训练时间,最终调整Batch-Size为4、学习率为1e-5时,平均准确率为88.64%、平均召回率为88.90%,各类的识别准确率在85%~99%之间。
3.2 实体概念间关系自动抽取
本文利用Transformer网络进行关系抽取。基于该网络的编码器组件,将数据输入到Transformer网络的Encoder中,多头注意力机制将从语句中提取重要信息,然后将注意力层的输出与输入进行合并和正则化。为充分抽取不同特征等级的句子信息,此处借鉴ResNet网络的方法,将Transformer的结果拼接并传送给全连接层输出分类结果。经试验得到,学习率为1e-4、BatchSize为16时,取得最优的平均准确率(97.25%)。
3.3 知识验证与知识图谱存储
生态环境领域实体和关系自动抽取完毕后,得到了数目庞大的领域实体和关系构成的三元组,即知识图谱的知识单元。这些通过深度学习算法抽取的知识单元并非完全可靠,不能直接构建知识图谱,需先将其暂存在Elasticsearch数据库中,再利用知识质量验证算法过滤筛选得到可靠的知识,最终将验证后的知识数据同步到Neo4j数据库。
知识来源是衡量知识置信度的重要指标。本文设置Q为来源指数(指数越高表明知识越可信),图谱知识来源包括人工标注文献文本、模型识别文献文本、模型识别其他文本等,模型的训练样本是经人工标注的文献文本,且基于最大似然的思想,认为文献文本数据、人工标注数据相对于其他来源的数据可信度更高,综上得出式(2)。

T为校验次数,是指同一个知识三元组被尝试插入知识图谱多次,其中来源指数不小于现有图谱中该三元组来源指数的次数。当某知识校验次数大于阈值,可将该知识视为正确。知识三元组需经过Q、T指数的考核才能录入图谱数据库,知识更新的流程为:当知识图谱中插入新的知识三元组时,首先从知识图谱中查询是否具有头尾实体相似的三元组,若无,则该三元组是新知识,设置知识来源后插入知识图谱;若有,如果关系相同,判断来源是否更加权威,更新现有相似知识三元组的来源指数和校验次数,如果关系不同,则比较知识三元组置信水平,倘若图谱中知识三元组校验次数超过阈值,则认为知识正确,倘若校验次数不及阈值,则比较知识来源的权威性,新增知识权威性较高则插入,反之则丢弃,否则比较模型识别的置信度,新知识置信度较高则插入知识,随后更新Q、T指数,如图6所示。
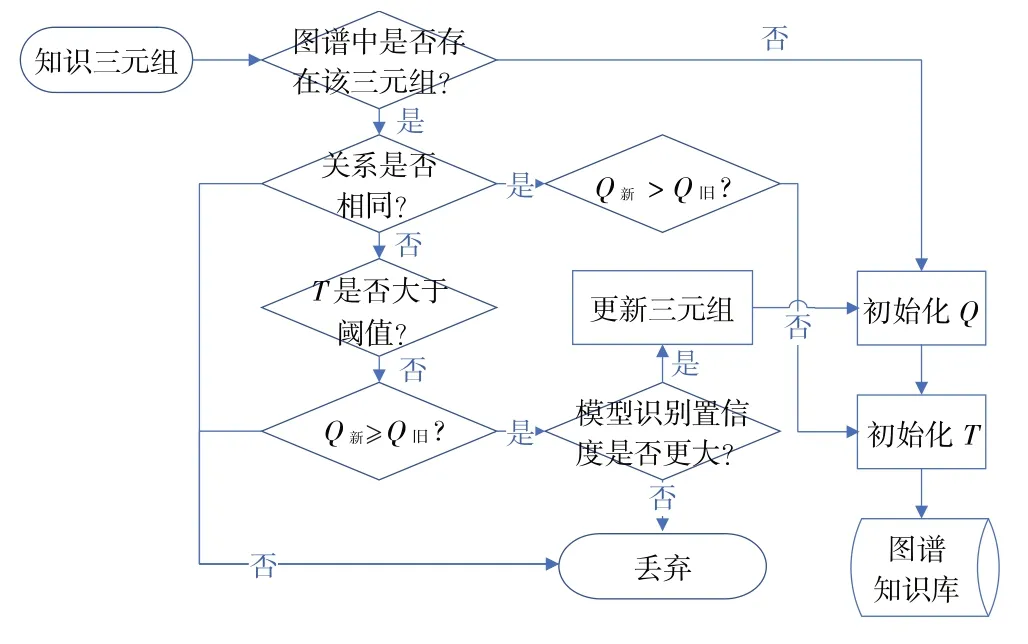
图6 知识验证流程图
本文通过上述步骤自动构建知识图谱,并将部分结果做可视化处理,结果如图7所示,通过认证次数确定知识节点的符号大小,不同节点颜色表示不同类别的知识节点,知识节点的名称通过文本显示。
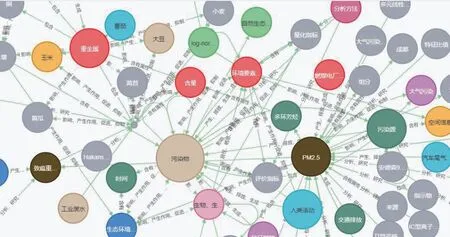
图7 部分知识图谱可视化
4 结语
当前海量生态环境文献文本中蕴含了丰富的非结构化领域专业知识,这些数据可被用于构建知识图谱。本文提出了一种生态环境文献文本驱动的自动化领域知识图谱构建方法。该方法以生态环境类期刊文献文本为数据源,通过构建生态环境领域知识模型,标注生态环境领域语料库,并基于深度学习方法抽取生态环境领域信息,实现生态环境领域知识图谱的自动化构建。
1)本文共获取5 000余篇生态环境领域文献,共计2 000万余字,采用机器学习方法抽取保留了重要性指数前1 000的词组和关系,再从抽取结果中总结归纳构建生态环境领域知识图谱模式层。
2)从领域知识图谱模式层出发,分析了标注过程的需求,自主开发了语义标注工具,并利用该工具识别语料40万字,完成了2.2万条实体与1.1万条关系的语义标注工作。
3)本文进行了生态环境领域信息抽取算法的训练与调优。实验结果表明,BERT-BiLSTM-CRF模 型 在BatchSize(4)、Learningrate(3e-5)时效 果 较好、效率较高,抽取总体精度为89.09%,召回率为88.60%,F1值为88.85;Transformer模型在Batch-Size(16)、Learningrate(1e-4)时效果最好,抽取总体精度为96.27%,召回率为97.33%,F1值为96.80%。抽取数据经过本文提出的知识验证算法筛选后存储到知识图谱数据库中,最终得到29 490条知识三元组。
本文还可在以下两个方面进一步开展工作:①语义标注时,在选取文本契合度方面可进一步利用专家知识,并研究提高标注效率的方法;②本文使用的实体提取和关系提取模型仍为通用模型,可进一步对生态环境领域实体提取和关系提取的网络结构进行优化。
猜你喜欢
山西大学学报(自然科学版)(2021年1期)2021-04-21
少先队活动(2020年12期)2021-01-14
天津外国语大学学报(2020年1期)2020-03-25
五邑大学学报(自然科学版)(2019年3期)2019-09-06
计算机技术与发展(2018年12期)2018-12-20
中成药(2017年3期)2017-05-17
领导科学论坛(2016年9期)2016-06-05
语言与翻译(2015年4期)2015-07-18
外语教学理论与实践(2014年4期)2014-06-13
现代防御技术(2014年6期)2014-02-28
