
位置感知注意力及其在行人重识别中的应用
2023-02-05 11:31陈江萍张索非吴晓富
计算机技术与发展 2023年1期
陈江萍,张索非,宋 越,吴晓富,林 嘉
(1.南京邮电大学 通信与信息工程学院,江苏 南京 210003;2.南京邮电大学 物联网学院,江苏 南京 210003;3.95958部队,上海 200120)
0 引 言
行人重识别是在不同背景和视角的摄像头中匹配输入特定人的图像[1],其在大规模人员追踪和智能视频监控相关场景中得到了广泛应用。近年来,行人重识别取得了显著进展,但仍存在一些具有挑战性的问题,如局部遮挡、背景扰动、姿态变化等[2]。
最近,多尺度特征提取技术以及多分支神经网络结构已经被证明能提高行人重识别的性能,可以解决上述部分问题,如最近提出的特征金字塔分支(Feature Pyramid Branch,FPB)网络[3]。FPB网络采用了一个双层特征金字塔分支,可以直接插入到骨干网中,形成一个不对称的多分支结构,同时该网络的特征金字塔分支可以从不同尺度的特征图中提取不同的特征,实验结果验证了该结构的有效性。
为了进一步提高模型的性能,各种注意力模块被用于提高主干网的特征提取能力,如位置注意力模块(Position Attention Module,PAM)[4]。PAM可以看作自然语言处理中多头注意力机制[5]的简化版本,利用特征间的相对位置关系输出更需要关注的行人可区分特征。文献[6]中提出的非局部注意力模块(Non-Local Block)通过自相关矩阵计算图片特征之间的相似性,从而输出特征之间的相关性信息。这些注意力模块可以通过特征之间的依赖关系获取行人可判别性特征,但是缺乏对特征绝对位置信息的挖掘。当行人特征间相似度较高时,仅通过特征间的相对关系无法准确识别行人。
该文在特征金字塔分支网络的框架下对比分析了PAM和非局部注意力模块的结构和性能,通过合理使用位置编码特征的绝对位置信息,使注意力模块可以通过特征的相对位置和绝对位置关系来区分特征,显著提升了系统的识别准确率。
主要贡献包括:
(1)在多尺度特征金字塔分支网络框架下,分析了不同结构注意力模块实现的效率和性能;
(2)提出了一种融合位置编码和非局部注意力机制的位置感知注意力模块,该模块具有即插即用的优点,能有效提升行人重识别网络的性能;
(3)在多个流行行人重识别标准数据集上的实验表明,所提出的位置感知注意力模块能提升FPB网络的行人识别准确率,而增加的可学习参数量仅为0.29 M。
1 面向行人重识别的位置感知注意力机制设计
1.1 特征金字塔分支(FPB)网络模型
采用特征金字塔分支(FPB)网络作为行人重识别模型的基础网络架构,该架构由全局分支和特征金字塔分支组成,如图1所示。
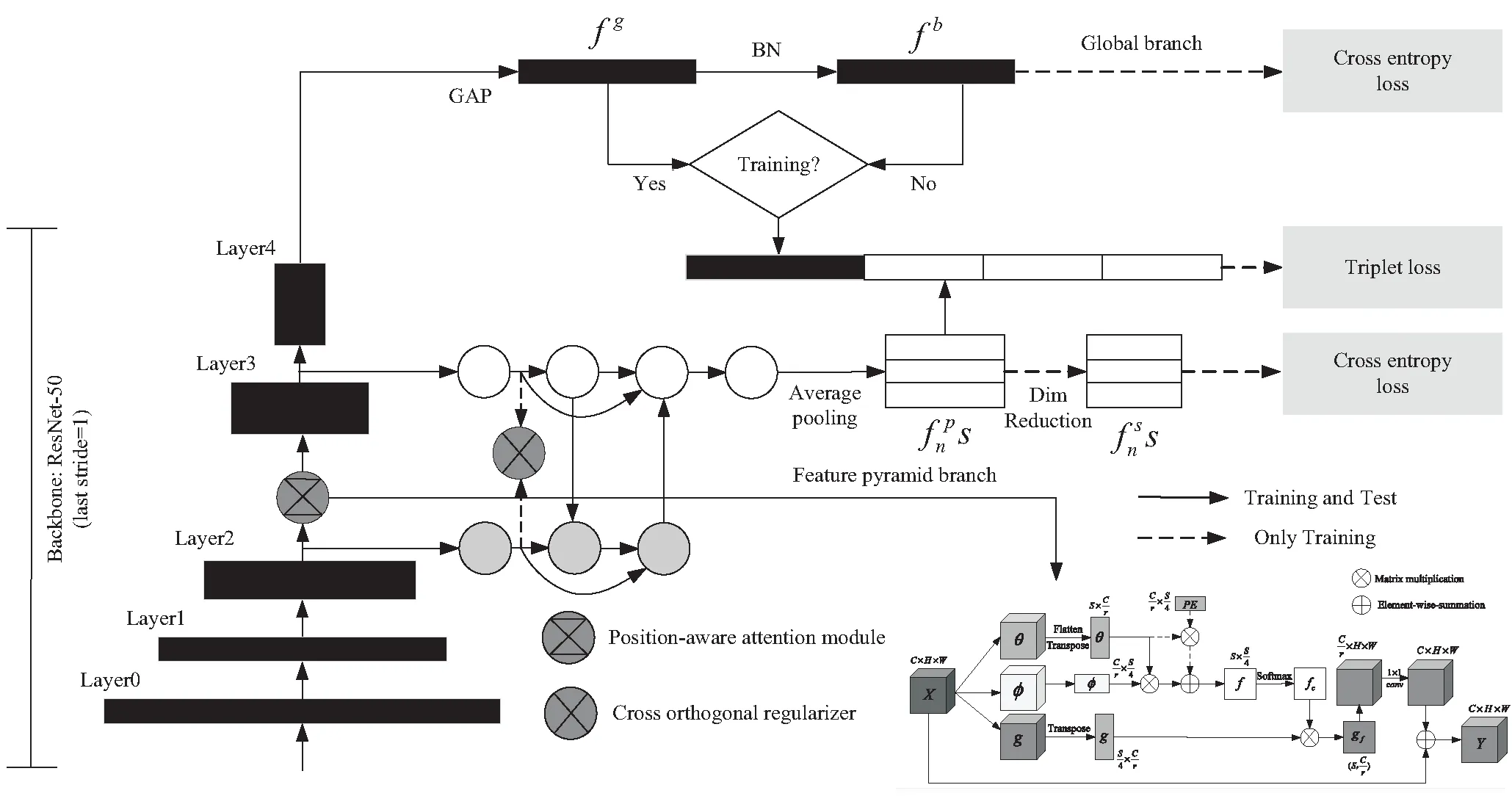
图1 融入位置感知注意力模块的金字塔特征行人重识别模型的总体架构
全局分支主要基于Bag-Of-Tricks方法[7],以修正的ResNet50作为骨干网。与标准的ResNet50[8]不同的是,这里去掉了ResNet50第四层的最后一个下采样操作,以增加输出特征图的尺寸。对主干网第四层的输出进行全局平均池化(Global Average Pooling,GAP)操作,再使用BNNeck(BN),输出一个2 048维向量作为全局特征向量。
除了全局分支,FPB网络引入了一种轻量级的特征金字塔分支,用来丰富特征的多样性。这个分支的结构是受到文献[9]的启发,将输出特征图划分为局部特征来强调局部信息。不同之处在于,特征金字塔分支是从主干网的第2层和第3层取特征(相比文献[9],所取特征层更浅),这些浅层特征可以保留图像更多的局部细节。同时,浅层的低维特征可以减少分支中可学习参数的数量。
除此之外,FPB网络还在骨干网第二层的输出位置插入了一个位置注意力模块,用于提取与任务有关的不同位置特征之间的相关性信息。在位置注意力模块的基础上,通过在特征金字塔分支上加入正交正则化来进一步强化特征的多样性。如文献[3]所述,正交正则化的目的是通过降低不同通道间的特征相关性来提高特征的代表效率,对注意力模块输出特征的影响尤其明显。

1.2 PAM与非局部注意力模块的比较
注意力模块在各种深度学习场景中被证明是一种有效的机制,通过注意力模块能实现任务相关特征的有效提取。对于行人重识别任务,注意力模块的使用有助于模型学习跟行人辨识相关的典型特征,通过让模型关注特征之间的关系,能有效提高模型的泛化能力。该文考虑以下两种注意力模块:

attentionp(X)=V·Softmax(Ap)=
V·Softmax(QTK)
(1)
如果忽略所有的可学习参数,位置相似度矩阵Ap可以简化为一个格拉姆矩阵,可以测量X不同位置特征之间的相关性。从这个角度看,位置注意力的本质是通过每个特征与其他特征之间的相关性来重新加权特征。结构如图2所示,PAM中还采用了残差结构和可学习参数γ来调节注意力的影响。

图2 位置注意力模块

(2)

通过将Non-Local Block与PAM进行对比,可知有如下区别:
(1)Non-Local Block中使用1×1卷积对原始图像进行特征提取时,对g分支上的特征图也进行了通道数的降维操作,并在输出前加入1×1卷积进行升维到原始输入维度大小,而PAM中V分支没有相应的降维和升维操作;
(2)Non-Local Block中的φ和g分支对应的特征图需要进行池化操作,特征图大小缩小了4倍,而PAM中Q和V分支没有池化操作;
(3)Non-Local Block可以通过调整超参数,变种很多种形式的注意力模块,而PAM只是在输入特征空间(单空间)上做的attention。
因此,可得出结论:PAM是Non-Local Block的一个特例,在特征空间上注意力机制的原理基本相同,详细的实验结果对比将在2.3节表1中详细阐述。根据实验结果,选择性能更优的Non-Local Block作为模型的基础注意力模块。

图3 注意力模块
1.3 位置感知注意力模块设计
为了更加充分利用特征出现的位置作为先验知识提升特征的代表性,可以在模型中加入一些特征的位置信息。
该文考虑两种方法将位置信息融入非局部注意力模块,一种是三角函数式常数位置编码(Sinusoidal Position Encoding,SPE)[10],另一种是可学习的位置编码(Learned Positional Embedding,LPE)[11]。融合位置编码的非局部注意力模块—位置感知注意力模块如图3所示,在图中PE处引入位置信息,PE指使用的是LPE或SPE。
三角函数式常数位置编码:利用正余弦函数的周期性进行位置编码,即通过正余弦函数相乘得到相对位置关系。不同位置不同维度的编码公式如下:
(3)
(4)
其中,p代表特征位置,i代表位置向量的维度,dspe是位置向量的长度。位置向量是指图片中每个特征位置对应的dspe维向量。位置编码的每一个维度对应于一个正弦或余弦信号。使用三角函数设计的好处是位置p+k处单词的位置编码可以被位置p处单词的位置编码线性表示,反映两处单词的相对位置关系。
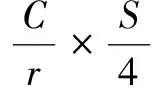
Rθ,φ=θ×φ
(5)
特征与位置之间的关系可由公式(6)计算得出:
Rθ,PE=θ×PE
(6)

f=Rθ,φ+Rθ,PE=θ×φ+θ×PE
(7)
通过实验比较了两种不同方式的位置编码融入非局部注意力模块后的性能区别,以数据集Market1501为例,加入可学习的位置编码的mAP和rank-1分别比加入三角函数式常数位置编码高0.2%和0.5%,其他数据集上的对比将在2.4节表2中详细阐述,最终选择可学习的位置编码将位置信息融入到非局部注意力模块中,形成位置感知注意力模块。同时,也将可学习的位置编码以同样的方式应用于PAM中,在Market1501上的实验结果将在2.4节表3中详细阐述。
1.4 损失函数
(8)
其中,i是训练样本(xi,yi)的索引。triplet(·)是在一个批次内样本i和另外一个样本j之间的困难样本三元组损失[12]。⊙表示fg和所有向量的拼接操作。ce(·)是交叉熵损失[12],Wb和分别为fb和之后的全连接层。cor是or的交叉正交正则化版本。采用超参数α平衡不同的损失。ce(·)的使用遵循了行人重识别模型的传统框架,而triplet(·)通过确保不同身份样本的输出特征之间的距离大于相同身份样本的输出特征之间的距离,提高模型的泛化能力。
如公式(8)所示,损失函数包含全局分支上的特征fg和经过BNNeck的特征fb。BNNeck部署了一个BN层,通过让特征fg经过BNNeck,得到归一化版本fb。fb在训练时用于全局分支上ce(·)的优化,在推理时用于最终特征的一部分。而原始的fg作为输出特征的一部分,在训练过程中对triplet(·)进行优化。实验结果表明,仅仅在全局分支上部署BNNeck而不是在两个分支上部署BNNeck可以获得最优的性能,原因在于它会使输出的结构不对称,从而确保不同路径的特征多样性。
2 实 验
2.1 数据集
该文开展了一系列的实验来分析嵌入注意力模块的性能影响,实验主要考虑了三种常用的行人重识别数据集:Market1501[13]、DukeMTMC[14]、CUHK03[15]。
Market1501包含32 668张图片,由6个摄像头拍摄到的1 501个行人图片组成,每个行人都至少被两个摄像头捕获到,且在同一个摄像头中可能具有多张图片。训练集考虑了来自751个行人的12 936张图片,平均每个人有17.2个训练样本,测试集考虑了来自750个行人的19 732张图片。
DukeMTMC包含36 411张图片,由至少两个摄像头拍摄到的1 404个行人图片组成,并且将仅由一个摄像头捕获到的408个行人的图片作为干扰物。训练集采用了702个行人的16 522张图片,测试集选用了702个行人的17 661张图片。
CUHK03由5个摄像头拍摄到的1 467个行人的图片组成,其中767个行人的图片用作训练集,剩下700个行人的图片用作测试集。数据集包含两项:用于行人重识别的人工标注行人框图片和机器标注行人框图片。人工标注行人框的数据集有7 368张图片用于训练,6 728张图片用于测试。机器标注行人框的数据集有7 365张图片用于训练,7 732张图片用于测试。
2.2 实现细节
骨干网络采用了在ImageNet上预训练过的ResNet50,特征金字塔分支初始化选用了He[16]方法。训练期间采用的数据增强方法有random horizontal flip[17],random crop[17],random erasing[17]和random patch[3]。用Adam优化器对模型进行了160轮的微调。采用线性预热策略,初始学习率设置为3.5×10-5,经过20个epoch学习率达到3.5×10-4。在第60和90个epoch,学习率分别以0.1的速率衰减。将Market1501、DukeMTMC和CUHK03数据集的图像大小调整为384×128。实验是在Intel E5-2680CPU 2.4 GHz和NVidia Tesla P100 GPU的硬件环境下进行的。
为了对不同方法进行定量比较,以mAP和rank-1作为标准指标。行人重识别的平均精确率AP(Average Precision)是指在单个行人类别上多次检索结果的平均准确率(Precision),mAP(mean Average Precision)是指在所有行人类别检索下中的平均AP值;rank-1是指搜索结果中第一张图就是正确结果的概率。所有的结果都没有使用任何重新排序或多查询融合技术。
2.3 PAM与非局部注意力模块的性能对比
首先,针对PAM与Non-Local Block应用在不同的数据集上进行实验对比。在表1中,列出了在Market1501,DukeMTMC,CUHK03(Labeled)和CUHK03(Detected)上的表现。实验表明:两者在CUHK03-Detected上性能差别最大,mAP和rank-1分别相差0.8%和0.6%;在DukeMTMC上性能差别最小,mAP仅相差0.2%,rank-1相差0.6%;Non-Local Block在所有数据集上的性能都优于PAM;如果不加注意力模块,在所有的数据集上性能都将变差,在CUHK03表现得最明显,mAP和rank-1最高分别能下降2.7百分点和2.1百分点。

表1 不同注意力模块的对比 %
2.4 不同位置编码方法的对比
记baseline+FPB+Non-Local Block为FPB*。将三角函数式常数位置编码和可学习的位置编码分别加入表1中的Non-Local Block,在表2中列出了这两种方法的性能比较。实验表明:两者在CUHK03-Labeled上性能差别最大,mAP和rank-1分别相差1%和0.4%;在Market1501上性能差别最小,mAP和rank-1分别仅相差0.2%和0.5%;可学习的位置编码在所有数据集上的性能都优于三角函数式常数位置编码;如果不加可学习的位置编码,在所有数据集上的性能都会有所下降,在CUHK03-Labeled上表现得最明显,mAP最高下降0.9百分点,rank-1下降0.6百分点。因此认为:在行人重识别中,编码特征的绝对位置比编码特征的相对位置更有效。

表2 不同位置编码方法的对比 %
2.5 注意力机制和位置编码方法的消融对比
以FPB网络为框架,嵌入位置感知注意力模块,构造了最终的模型。表3列出了在Market1501数据集上每次尝试的影响。首先,列出了骨干网ResNet50结合文献[7]中技巧的性能,记为baseline,证明了特征金字塔分支(FPB)的有效性。然后,分别加入不同的注意力模块PAM和Non-Local Block进行对比。最后,将可学习的位置编码分别融合到PAM和Non-Local Block中。
从表3中可以看到,加入注意力模块PAM或者Non-Local Block性能都得到了提升,但加入Non-Local Block性能更好,mAP和rank-1比加入PAM高0.3%和0.4%;最后分别在PAM和Non-Local Block中加上可学习的位置编码,性能进一步提升,但性能最好的还是在Non-Local Block中加入可学习位置编码。

表3 注意力机制和位置编码方法的消融对比
2.6 与其他算法的横向比较
下面给出所提出的融入位置感知注意力模块的FPB网络和其他算法在不同数据库的性能比较。在表4中,列出了在Market1501,DukeMTMC,CUHK03(Labeled)和CUHK03(Detected)这四个任务中的表现。从表4中可以看到,将位置感知注意力模块嵌入到FPB网络后,性能得到显著提高,与表中的其他算法相比,在上述几个数据集上性能都是较高的。

表4 与其他算法的横向比较 %
3 结束语
该文提出了一种新的位置感知注意力模块,该模块使用可学习的位置编码学习特征图中子特征间的位置关系,提升了特征的代表性。同时该模块具有即插即用的优点,能方便融入到行人重识别主干网。实验结果表明:在FPB网络中嵌入位置感知注意力模块,增加的计算量小,但能显著提高模型的识别能力。
猜你喜欢
环球时报(2022-09-19)2022-09-19
黑龙江大学自然科学学报(2022年1期)2022-03-29
数学物理学报(2021年4期)2021-08-30
考试与评价·七年级版(2020年4期)2020-10-23
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
井冈山大学学报(自然科学版)(2019年4期)2019-09-09
学生天地(2019年28期)2019-08-25
少儿美术(快乐历史地理)(2019年2期)2019-06-12
小学教学研究·新小读者(2017年9期)2017-10-25
