
基于改进YOLOv4的轻量级车辆检测方法
2023-02-05 11:30李奇武杨小军
计算机技术与发展 2023年1期
李奇武,杨小军
(长安大学 信息工程学院,陕西 西安 710064)
0 引 言
在交通监控场景下,对道路车辆目标进行准确快速地检测,对缓解交通压力、应对交通安全问题具有积极意义。由于智能交通监控摄像头等边缘设备往往性能有限,设计一款轻量级的道路车辆目标检测模型很有必要。
对目标检测来说,一个重要的任务就是定位、分类视频图像当中的那些关注的目标[1]。传统的目标检测算法通常都是用滑动窗口进行区域的选择,这种策略存在着耗时多、冗余窗口多、检测效率低下、对资源的需求较高等缺点,同时人工设计的特征难以适应恶劣环境下的检测任务,鲁棒性低,其泛化性也较差,对目标的误检和漏检比较多[2-3]。在复杂的应用场景下,传统目标检测算法往往难以满足需求,而基于深度学习的目标检测算法逐渐成为大家研究的重点。现阶段基于深度学习的进行目标检测的算法有很多,大致可分为两类:一类是基于候选区域的两阶段算法,一类是基于回归的单阶段算法[4]。前一类算法通常精度比较高,但因为这类算法需要先找到候选区,之后才进行分类,速度较后一种算法慢,代表算法有R-CNN[5]等;后一类算法通常速度非常快,但检测的准确度比前一类算法略低,常见的有SSD[6]和YOLO[7]等[8]。近些年来,许多学者都在将目标检测的方法应用到车辆检测上来,同时也在研究将其应用到嵌入式平台中。杜金航等[9]将YOLOv3的骨干网Darknet53改进为有30个卷积层的卷积神经网络,同时使用K-means聚类方法预测锚框,提高了车辆检测的性能。鲁博等[10]在YOLOv3-tiny网络上引入BiFPN特征金字塔结构,检测的准确度得到大幅提高,同时检测速度也很快。孙皓泽等[11]以MobileNet作为骨干网构建了一个轻量级的检测网络,将残差模块与网络中的检测单元融合,提高对小目标的检测性能,在小型移动侦查平台能够很好适用。李国进等[12]提出一种基于改进SSD的算法,通过用改进后的Inception模块替换SSD网络中的部分卷积层以及引入SENet注意力模块,有效提高了对目标车辆的特征提取能力,提高了精度,但模型较为复杂,参数量大。张宝朋等[13]把YOLOv4的骨干网替换为改进的ShuffleNetV2,显著降低了模型容量,但损失了检测精度。
针对智能交通监控场景中,常见车辆检测模型结构复杂,参数量大,难以在计算和存储能力有限的边缘设备中部署等问题,该文主要在YOLOv4网络的基础上做了两点改进,用来构建轻量级的车辆检测方法MC-YOLO。首先,将YOLOv4中负责初步提取特征的主干部分替换为MobileNetV3;然后,在主干部分和加强特征提取部分之间引入了有效的注意力模块CBAM,它能够筛选重要特征,弥补将主干网络轻量化而引起的精度上的损失,提高模型的检测能力。
1 MobileNetV3算法
1.1 深度可分离卷积
MobileNet系列算法为了减少模型参数同时提升运算速度,都采取了将传统的标准卷积替换为深度可分离卷积的方式[17]。如图1所示,深度可分离卷积是由两层组成的,分别是深度卷积(Depthwise Convolution)和1×1的逐点卷积(Pointwise Convolution)[18],它们的作用分别是进行滤波和线性组合,这样操作有效减少了参数量和计算量[19]。

图1 标准卷积与深度可分离卷积比较
假设输入时的特征图F的大小为DF×DF×M,在经过一系列卷积操作后输出时的特征图G的大小为DF×DF×N,其中DF用来表示特征图的宽和高,M为输入通道数,N为输出通道数,DK代表卷积核的高与宽,对于标准卷积,它的计算量是:
DK·DK·M·N·DF·DF
(1)
而对于深度可分离卷积,它的计算量为:
DK·DK·M·DF·DF+M·N·DF·DF
(2)
将两种卷积操作的计算量进行比较:
(3)
由式(3)可知,采用深度可分离卷积可大量减少计算量。
1.2 倒残差结构
在MobileNetV1基础上,为了提高网络的表征能力,MobileNetV2引入了倒残差结构[20],一方面压缩了网络规模,一方面提高了检测性能。为了解决在训练网络的时候,由于网络深度逐渐增加而出现的梯度消失的问题,ResNet中提出了残差结构,类似的残差结构在MobileNetV2中也存在,但是不同的是,在MobileNetv2中,在通过深度卷积DW进行特征提取之前,先进行了逐点卷积PW的升维操作,然后再一次使用逐点卷积PW进行降维操作[21-22]。倒残差结构如图2所示。
您好!我是一个快上初三的大男孩。我知道自己已经步入青春期了,最明显的表现就是不愿意搭理父母,我也不知道为什么,但这就是我发自内心的感受,我觉得他们都不懂我,他们的关心让我感到烦躁。另一方面,我又略感自责,但我只要放学回到家,就无法克制自己。父母应该感觉到了我的疏远,我很苦恼。
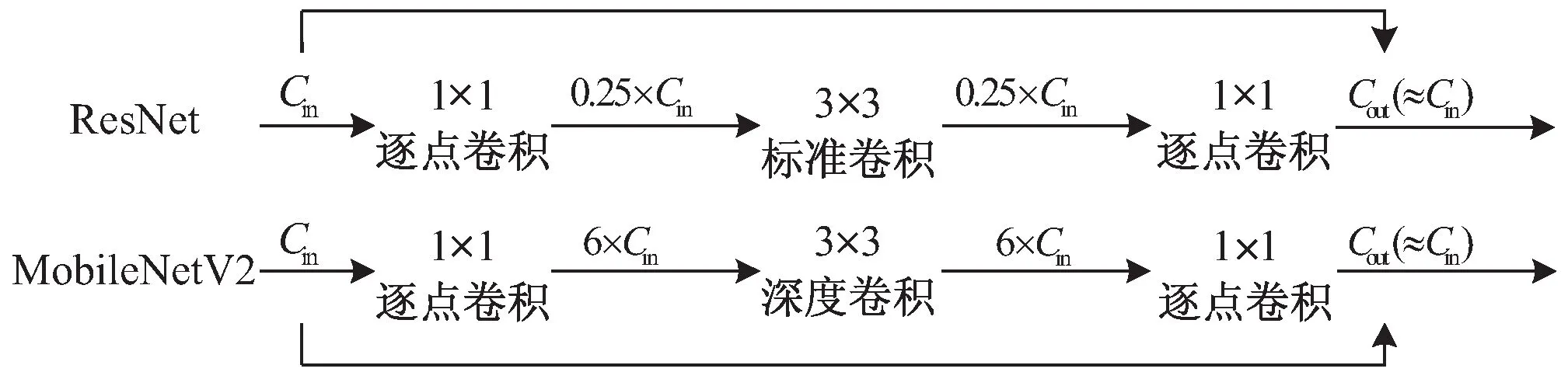
图2 MobileNetV2中的倒残差结构
1.3 MobileNetV3
MobileNetV3的网络结构中,一方面融合了深度可分离卷积、线性瓶颈结构,一方面引入了SE(Squeeze and Excitation)注意力模块和h-swish函数等,速度和性能有了很大提升[23-24]。MobileNetV3的基础模块bneck结构如图3所示。可以看到,它先通过1×1的卷积将维度升高,目的是对在高维空间得到的特征数据进行分析;再进行深度可分离卷积操作,同时,在这个结构里还嵌入了SE模块,用来对不同通道的权重进行相应的调整;最后再通过1×1的卷积将维度降低,若步长为1,输出与输入进行残差操作[24]。
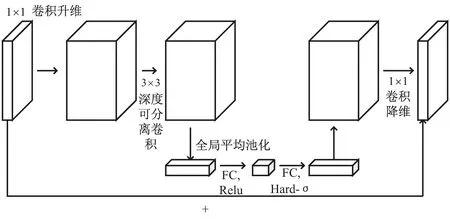
图3 bneck结构
MobileNetV3有large和small两个版本,两种模型的区别主要在于通道数的变化以及网络中bneck的次数。该文采用MobileNetV3-large模型。
2 YOLOv4模型改进
2.1 YOLOv4简介
YOLOv4是在YOLOv3的基础上发展而来的,如图4所示,可以将网络划分为三个部分,分别是主干特征提取网络CSPDarknet53、加强特征提取网络以及预测网络YOLO Head[25]。主干网络CSPDarknet53借鉴了CSPNet的优点,提高了网络的推理速度和准确性,可以看到输入的图像在主干网经过特征提取,得到三种不同尺度的特征层[26]。加强特征提取网络主要是由SPP(空间金字塔池化)模块和PANet(路径聚合网络)组成的,从图中可以看到,SPP模块将从主干网得到的最小尺寸的特征层利用四个不同尺度的最大池化进行处理,然后再传入PANet与另外两个特征层进行自上而下和自下而上的双向特征融合,进一步加深了特征提取,最后由YOLO Head输出预测结果[26-27]。
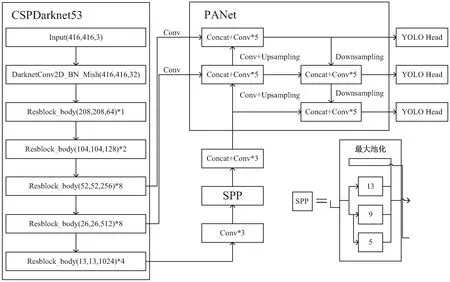
图4 YOLOv4网络结构
该文采用YOLOv4原有的损失函数。YOLOv4是在YOLOv3的基础上发展而来,相较于YOLOv3,其在边界框回归损失部分进行了改进,将YOLOv3中的均方误差损失函数替换为CIoU,在置信度损失和类别损失两个方面与YOLOv3相同。由于IoU存在着只有在边界框重叠的情况下才有效果的缺陷,YOLOv4采用CIoU,同时考虑了重叠面积、中心点距离以及长宽比三种因素,它的计算方式为:
(4)
(5)
(6)
其中,b和bgt代表预测框以及真实框的中心的位置,ωgt、hgt和ω、h则分别代表真实框和预测框的宽和高。
2.2 卷积注意力模块CBAM
注意力机制是模仿人的神经系统提出的概念,在某个特定的场景中,不同物体对人的吸引力是不同的,对吸引力较强的物体,人往往会投入更多的注意力去关注它,这种情况也可以扩展到神经网络中来,一般来说更重要的特征也应该被赋予更高的权重,以提升主干网络对重要特征的关注度。该文结合轻量级注意力模块CBAM(Convolutional Block Attention Module)对网络进行优化,CBAM是一种即插即用的注意力模块,能够嵌入到网络中的卷积层之间,虽然增加了较少的计算量,但能够显著提升检测的准确度。CBAM同时关注了通道注意力信息和空间注意力信息,如图5所示,它有通道注意力模块CAM(Channel Attention Module)以及空间注意力模块SAM(Spatial Attention Module)两个子模块,把这两者结合起来,能够让网络关注到更多的重要信息,起到提升模型的检测性能的作用[28]。CBAM将某一层的特征图抽取出来,接着进行通道维度与空间维度的提取后,与原特征图进行结合作为下一层卷积层的输入,强调重要特征,抑制一般特征。
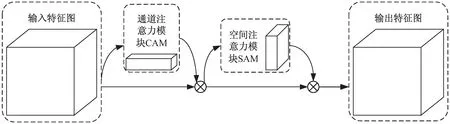
图5 CBAM结构
2.3 总体改进思路
YOLOv4算法性能优异,但是其网络结构复杂,参数量很大,难以应用于算力资源和内存资源有限的边缘设备。如图6所示,该文主要通过两个方面对原YOLOv4算法进行改进:一方面,为了减少网络的参数量,压缩模型大小,通过替换骨干特征提取网络来实现,将YOLOv4的主干网CSPDarknet53替换为MobileNetV3;另一方面,为了保证优化后的模型在轻量化的同时,使其检测精度尽可能符合预期要求,在SPP模块之后和PANet模块之间以及主干和PANet模块之间均嵌入了卷积注意力模块CBAM,用以弥补模型轻量化导致的精度损失。

图6 MC-YOLO网络结构
3 实验结果与分析
3.1 实验准备
实验的环境配置:CPU为Intel Core i7-10875H CPU @2.30 GHz;内存16G;显卡为NVIDA GeForce RTX 2060。在Windows 10系统上进行车辆检测模型的开发,开发环境为Python 3.7,CUDA10.0,深度学习框架为PyTorch。
实验数据集:针对该文研究的路侧交通监控场景的车辆检测,由于UA-DETRAC[29]数据集的拍摄角度与监控摄像头相近,因此采用该数据集作为实验的数据集。
UA-DETRAC数据集包括100个从现实世界交通场景中拍摄的视频,有超过14万帧的视频图像,人工标注了8 250个车辆目标,有121万目标检测框被标注,它考虑了四种照明条件,即多云、夜间、晴天和雨天;UA-DETRAC数据集将车辆分为四类:car、bus、van和others[30],由于该文主要讨论的是车辆检测,故不再区分车辆类型,以car作为唯一的类型。同时,为了检验该模型的检测效果,作为UA-DETRAC数据集测试集的补充,通过模拟交通监控拍摄角度,分别在白天和夜晚车流量较多的时段于西安市二环南路东段立交桥采集了两段视频,视频分辨率为1 280×720,FPS为30,每段时长均为5分钟。
评价指标:使用精确度(Precision)、平均精度(AP)、参数量、模型大小和FPS作为评价指标。
3.2 模型训练
在训练之前,把实验所用到的UA-DETRAC数据集中的图像随机划分为两份,其中训练集用到的图像占80%,剩余的则是测试集的图像。将原尺寸的图像输入网络,在网络输入端进行图片的调整,将原图像的大小调整为416×416再输入网络。该文对模型的训练主要分成两步,在第一个阶段只训练MC-YOLO网络的主干,这个阶段只训练50个Epoch,它的学习率lr设为0.001,此阶段每次迭代的batch_size为16;第二个阶段则是对整个MC-YOLO网络进行训练,将lr调整为0.000 1,训练的次数则设置为100个Epoch,此阶段将batch_size调整为8。在整个训练过程中,均采用Adam优化器,将其权重衰减设置为0.000 5,而且采用了标签平滑策略,设置为0.005。MC-YOLO模型和YOLOv4模型的训练集Loss变化曲线和测试集Loss变化曲线的对比如图7所示。可以看到,当训练次数超过100个Epoch时,MC-YOLO的Loss曲线已经开始趋于稳定,相较于YOLOv4收敛更快。

图7 MC-YOLO与YOLOv4的Loss曲线对比
3.3 结果分析
为验证该算法的可行性,以及改进模块对交通监控场景下的车辆检测模型的影响,将YOLOv4分别与替换主干网后的模型MobileNetV3-YOLOv4以及该文提出的MC-YOLO进行比较,将改进的方法与原YOLOv4在相同的环境下进行训练,在模型大小、平均精度AP、参数量以及FPS四方面进行比较,结果如表1所示。

表1 实验结果对比
由表1可看出,在将YOLOv4的主干网用MobileNetV3替换YOLOv4的主干特征提取网络可以显著压缩模型大小,将模型大小从245.5 MB压缩到44.7 MB,但同时也造成了一部分精度的损失,在加入CBAM注意力模块后,对检测效果的提升较为明显,模型大小虽然比MobileNetV3-YOLOv4模型略大,但与原YOLOv4模型相比,减少了约190 MB,参数量也降低了约77%,同时保证了较好的检测精度,在相同的硬件条件下,MC-YOLO模型的速度比YOLOv4提升了约21%,能够满足实时性检测的需求。
为更直观体现MC-YOLO车辆检测方法的性能,验证其在不同天气情况下的检测效果,在UA-DETRAC数据集中选取了雨天、夜晚两种天气条件下的图像,图像中包含部分遮挡的目标以及小目标,将MC-YOLO与YOLOv4两者进行比较,结果如图8所示。

图8 UA-DETRAC数据集测试结果对比
从图8中可以看出,无论在雨天还是夜晚,改进后的车辆检测算法都保持着较好的检测精度,对部分遮挡的车辆和远处的车辆也能较为准确地识别,证明了算法的鲁棒性。为了检验该模型的泛化能力,在人工采集的西安市二环南路东段立交桥监控视频图像上进行测试,得到MC-YOLO和YOLOv4的检测结果对比如图9所示,体现了较好的泛化性。

图9 实际应用场景测试结果对比
4 结束语
为模拟现实交通监控场景下的车辆检测,选择UA-DETRAC数据集进行训练和评估,在YOLOv4的基础上通过替换主干网以及引入注意力模块提出了轻量级车辆检测方法MC-YOLO。实验结果表明,MC-YOLO模型的AP与YOLOv4相近,但有效降低了模型的大小和复杂度,在不同的天气状况下对车辆进行检测的效果较为理想,体现了较好的鲁棒性,同时泛化性较好,能够满足交通监控场景下的车辆检测任务。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
电子制作(2019年15期)2019-08-27
电子制作(2019年11期)2019-07-04
电子制作(2018年19期)2018-11-14
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
自动化学报(2017年11期)2017-04-04
第二课堂(课外活动版)(2016年2期)2016-10-21
