
基于RF-DGRU-SA的涡扇发动机剩余寿命预测
2023-02-03 10:14:10马鸣风王力
机床与液压 2023年1期
马鸣风,王力
(1.中国民航大学电子信息与自动化学院,天津 300300;2.中国民航大学职业技术学院,天津 300300)
0 前言
涡扇发动机作为航空飞行器的重要部件,一方面对航空飞行器的正常飞行起着至关重要的作用,另一方面其复杂的内部结构以及对可靠性和安全性的严苛要求使得维护成本高昂。因此,需要对涡扇发动机的健康状态进行实时监控,对其剩余使用寿命(Remaining Useful Life, RUL)进行精准预测,从而做到实时维护,防止故障的发生[1-3]。目前有两大方法可以实现对涡扇发动机RUL的预测:基于物理模型的预测方法和基于数据驱动的预测方法[4]。
由于发动机内部机制复杂,物理模型通常难以建立。随着发动机历史失效数据的大量积累,机器学习和深度学习的快速发展,数据驱动的预测方法已成为时下研究热点。最小二乘支持向量机(Least Squares Support Vector Machine, LS-SVM)[5]、半马尔可夫决策过程框架[6]等机器学习算法被用来解决RUL预测问题。上述方法均没有对数据进行深层次的挖掘,因而预测精度较低。和机器学习相比,深度学习更能充分挖掘数据间复杂关系[7]。长短期记忆(Long Short-Term Memory, LSTM)[8]、循环门控单元(Gated Recurrent Units,GRU)[9]等神经网络模型被用来预测发动机的RUL。上述研究在剩余寿命预测领域取得了一定的成果,但单一神经网络的使用无法优化隐藏信息权重,缺少不同网络的优势互补。文献[10]将自编码(Autoencoder)神经网络和双向长短期记忆(Bidirectional Long Short-Term Memory, BLSTM)相结合;文献[11]将自注意力机制(Self-attention,SA)与LSTM相融合;文献[12]将卷积神经网络(Convolutional Neural Network, CNN)与LSTM相融合。上述研究均采用融合神经网络实现对发动机RUL的预测,虽然取得了一定成果,但是仍存在输入数据维度过高的问题。
本文作者提出了将随机森林(Random Forest, RF)、深度门控循环单元(Deep Gated Recurrent Units,DGRU)和自注意力机制相融合的预测模型来对涡扇发动机RUL进行预测。首先,将数据输入RF模块,通过重要度阈值的设置,剔除无关特征,解决输入数据维数过高的问题;其次,利用DGRU处理此类状态检测数据的优势,挖掘出相关状态特征和剩余使用寿命之间的内在联系,获取更深层次的隐藏信息;最后,利用SA对隐藏信息添加不同大小的权重,进行重要度区分,提高模型的预测精度。
1 理论方法
1.1 基于改进随机森林的特征提取
RF是一个以多个决策树分类器为基础的集成算法,属于自举汇聚法(Bootstrap Aggregating),决策树采用CART(Classification and Regression Tree)算法构建[13]。RF采用有放回的抽样方式在原始数据上进行抽样,抽选出k个数据集作为训练数据集,使用每一个训练集训练出一个决策树即弱分类器,对多个弱分类器预测结果进行组合得到最终集成结果。传统的RF算法采取算术平均法作为集成结果,考虑到不同弱分类器的预测精度不同,本文作者将为不同弱分类器添加误差权重,剔除误差最大的弱分类器,改变其余弱分类器对随机森林集成结果的影响。改进算法具体描述如下。
(1)在原始数据集上进行k次有放回的采样,得到k个采样数据集Di(i=1,2,…,k),其中每个采样数据集都与原始数据集有着相同的大小。
(2)设原始数据具有x个特征,随机挑选m个特征作为单一弱分类器每个节点的分枝变量,根据已有分枝选出最优分枝,采用CART算法构建出没有剪枝的弱分类器。
(3)以弱分类器中最大预测误差为基准将所有弱分类器的预测误差进行归一化,用最大值1减去各个弱分类器的误差归一化结果得到每个弱分类器的误差权重αi。
(1)
(4)将上一步计算出的误差权重αi与各个弱分类器预测结果相乘得到优化后预测结果,将优化后预测结果求和得到最终集成结果r。
(2)
在上述通过有放回的采样方式得到训练数据集训练弱分类器的过程中,大约有1/3的数据未被采样,这些未参与训练弱分类器的数据被称为袋外(Out of Bag,OOB)数据。此类数据常被用于计算不同特征对目标值的重要度,具体思想是对OOB中的单个特征随机添加噪声,分别计算噪声添加前后的预测误差,噪声添加前后的误差变化越大,证明该特征对目标值的重要度越高。
利用改进RF计算特征重要度的步骤:
(1)每个弱分类器都有对应的袋外数据,将袋外数据输入弱分类器,输出预测结果,将预测值与真实值进行比较得到袋外数据误差,记为e1i。
(2)对袋外数据的某一特征Tj(1≤j≤x)进行噪声添加,利用新的袋外数据再次计算袋外数据误差,结果记为e2i。
(3)用误差权重乘以e1i和e2i的差,将二者乘积再除以原数据集中特征Tj的标准误差Tj,std,即得到单一特征Tj对目标值的重要度。重要度的最终结果被限制在[0,1]内。
(3)
(4)

1.2 GRU的结构介绍
GRU作为RNN的一种变体,模拟了人的大脑记忆,通过不同门控的使用将前面有用的时间序列信息进行编码,重新放到模型的参数当中。GRU神经网络模型有两个控制门:控制重置的门控(Reset Gate)和控制更新的门控(Update Gate)。具体网络结构如图1所示。
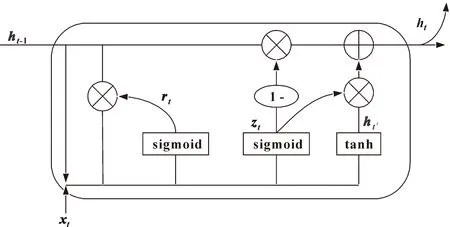
图1 GRU网络结构Fig.1 Network structure of GRU
GRU对上一个时刻传输下来的隐状态ht-1进行保留,再将它与当前节点的输入xt进行向量相连,利用sigmoid函数得到控制重置和更新的两个门控状态rt和zt。然后将rt与ht-1进行矩阵相乘,得到ht-1′,将ht-1′和当前节点的输入xt进行向量拼接,利用tanh激活函数将向量相乘的结果缩放在-1~1之间,经过缩放得到的ht′主要包含的是当前输入数据。最后利用zt对上一时刻的隐状态ht-1和当前时刻的隐状态ht′进行综合运算,确定出传递给下一时刻的隐状态ht。具体过程如下所示:
rt=sigmoid(Wr·[ht-1,xt])
(5)
zt=sigmoid(Wz·[ht-1,xt])
(6)
ht-1′=ht-1×r
(7)
ht′=tanh(Wht′·[ht-1′,xt])
(8)
ht=(1-zt)×ht-1+ht′
(9)
式中:[]表示向量相连;×表示矩阵之间的相乘运算;Wr、Wz、Wht′分别表示不同的权重。
2 RF-DGRU-SA预测模型
2.1 模型构建
文中所提出的RUL预测模型主要分为基于改进随机森林算法的特征提取模块和DGRU-SA寿命预测模块。首先将预处理之后的数据输入到特征提取模块当中,通过设置重要度阈值从中筛选出所需特征,实现特征维度的降低;然后将降维过后的数据输入DGRU-SA模块。DGRU模块由多个GRU层堆叠形成,通过多层网络的构建自适应捕获数据中的潜在特征。单个GRU网络结构数据只在隐藏层之间实现传递,在多个GRU层构造的DGRU模型当中,能完成对输入数据的深层挖掘[11]。在DGRU模块当中,第一层GRU的隐状态只与时刻有关,输出当前时刻下的隐藏信息,其余GRU层与第一层依次相连,实现了数据在空间上的交互,隐藏信息会从上层依次传输入下层神经元,每个GRU层的输出都将作为下一GRU层的输入,同一GRU层下包含多个GRU神经元,各个神经元之间互相交换信息以发掘输入信息的长期依赖性,实现跨时间的自连接。DGRU从输入数据中提取出大量隐藏信息,SA机制自动为隐藏信息添加不同大小的权重,使得重要信息获得更高的关注,最后通过一层全连接层输出预测RUL。图2展示了文中模型的整体架构。

图2 模型整体结构Fig.2 Structure of model
假设输入特征数据X=[x1,x2,x3,…,xN],目标值Y=[y1,y2,y3,…,ym]T。其中xN为m维列向量。输入数据通过特征提取模块,得到各个特征与目标值间的重要度,设置重要度阈值P,当输入特征与目标值间的重要度小于P时,该特征被剔除。设n个特征得到保留,此时X=[x1,x2,x3,…,xn]。
将降维过后的数据输入到DGRU-SA模块,为了满足GRU输入数据尺寸要求,采用滑窗处理的方式对输入数据进行处理。已知输入数据的长度为m,设滑窗窗口长度为s,经RF降维过后的维度为n,DGRU模块的输入(m-s,s,n)的一个三维张量,输出(i,s,e)的一个三维张量,其中i是新样本长度,e为最后一层GRU的隐含层数。
DGRU模块输出的三维张量被传输给SA模块,SA模块包含一个编码器和解码器,编码器和解码器均采用RNN网络实现。当前时刻的每个输入xij通过编码器会得到一个隐层输出hij,将上一时刻隐层Si-1作为参考向量计算出当前时刻每个hij对应的权重αij,根据权重对每个hij进行加权平均得到当前时刻的容量向量ci,最后根据当前容量向量ci、上一时刻隐层Si-1和上一时刻最终输出yi-1计算出当前时刻隐层Si和当前时刻最终输出yi,具体计算过程如下:
eij=F(Si-1,hij)
(10)
(11)
(12)
Si=F(Si-1,yi-1,ci)
(13)
yi=F(yi-1,Si,ci)
(14)
式中:F表示当前神经网络;i表示当前时刻;j表示当前时刻下的单一输入;T表示当前时刻下的总输入数。
2.2 性能评价指标
文中采用3个评价指标来评估不同模型的预测性能,分别是平均绝对误差(Mean Absolute Error,MAE)、均方根误差(Root Mean Square Error,RMSE)和Score评分函数。MAE和RMSE的定义分别如式(15)、式(16)所示。
(15)
(16)
Score评分函数为数据集创建者给出[14],不同于上面两种评价指标,Score评分函数从实际出发,对滞后的预测结果给予更高的惩罚,能反映出预测结果的超前性与滞后性,是更具参考价值的评价指标。Score评分函数的定义如下式:
(17)
3 案例验证
为了研究单一故障对发动机剩余使用寿命的影响,文中使用的数据集是CMAPSS数据集下的子集FD001[15]。FD001数据集记录了100台发动机在高压压气机故障下进行仿真得到的各类数据,包含21个传感器数据、3个运行参数和运行周期。FD001数据集包含1个训练集和1个测试集,其中训练集为20 631行和26列,除去首列发动机号,其余25列作为特征;测试集为13 096行和27列,与训练集相比多出的1列为真实RUL。由于原始训练集没有给出真实RUL,文中将训练集中每台发动机的最大运行周期数作为初始寿命,每运行一个周期寿命自动减1直至为零。对于涡扇发动机,只有在使用末期失效率才随着时间急速增加,而在运行初期,涡扇发动机的失效率随时间变化并不明显,因此文中将根据涡扇发动机的RUL构建分段函数。
(18)
式中:Rp表示修正后RUL;Ro表示原始RUL。
为了加快模型运行速度、提高模型预测精度,首先对训练数据集和测试数据集中的各类特征值进行归一化处理;然后设置模型的各类参数:设置4层GRU,每层GRU神经元数设置为256,步长设置为20,batch size设置为20,随机丢弃层的丢弃率设置为0.3,输出层神经元数设置为1,迭代次数设置为100。选择均方误差(Mean Square Error,MSE)作为损失函数,RMSprop作为损失函数优化器。为了提高训练效率,添加监视器用以监督模型的训练过程,若连续10个时期内验证集的误差都没有发生明显下降,则提前终止训练生成最终模型。
将预处理后的数据输入特征提取模块,输出各个特征对目标RUL的重要度α,结果如图3所示。

图3 各特征重要度αFig.3 Importance of each feature
图中S1~S21表示21个传感器数据,cycle表示已运行周期,Setting1~Setting3分别表示3个运行参数,未列出特征参数的重要度皆为0。特征参数的重要度为0,意味着这类特征在发动机运行过程中没有发生变化。
在特征提取模块中需设定重要度阈值,将重要度低于此阈值的特征剔除,从而实现数据维度的降低,提升后续模块的预测表现。重要度阈值的取值范围设置为[0,0.01,0.02,0.03,0.05],在不同阈值下分别进行实验,评价指标仍为MAE、RMSE和Score函数,实验结果如表1所示。
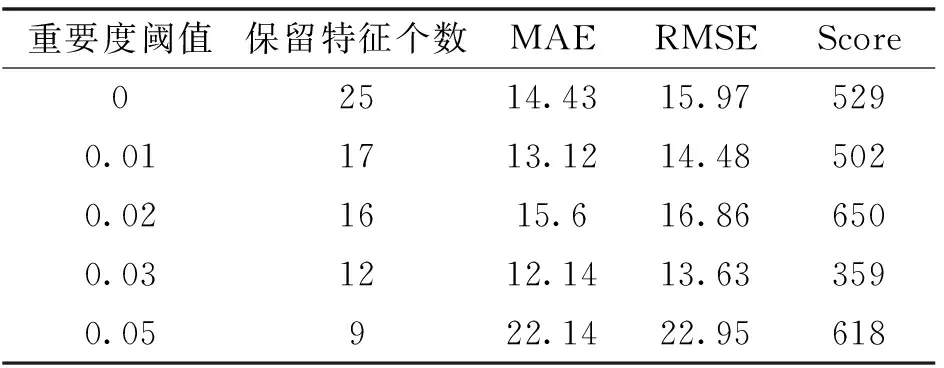
表1 不同阈值下的评价结果Tab.1 Evaluation results of different thresholds
分析实验结果,当重要度阈值为0.05时, RMSE和MAE误差最大,Score得分次大,表明前9个特征不能完全囊括特征与目标值间的隐藏关系,随着重要度阈值的降低,这一现象得到一定程度的改善。但当重要度阈值降为0时,即对数据不做降维处理,预测模型并没有表现出最好的预测效果,表明某些特征对预测结果起到负面影响,干扰模型的预测。当重要度阈值设置为0.03时,实验结果最佳,与未做降维处理的结果相比,MAE下降了15.8%,RMSE下降了14.6%,Score下降了32.1%。综上,通过比较各阈值下模型的预测表现,最终将重要度阈值设置为0.03,即使用重要度排名前12的特征用于后续实验。
为了验证加入SA模块的有效性,将进行消融实验。将原数据分别输入RF-DGRU模型和RF-DGRU-SA模型,特征提取模块中的重要度阈值都设置为0.03,两种模型的对比结果如图4所示。分析图4可知,SA模块的引入有效降低了模型预测的误差,其中Score得分下降趋势最为明显。说明SA模块的引入优化了隐藏信息的权重,提高了模型的整体预测表现。

图4 RF-DGRU和RF-DGRU-SA模型对比
为了更加全面直观地比较上述模型的预测效果,使用上述两种模型对测试集中前50台发动机进行剩余寿命预测,结果如图5所示。比较两种模型的预测曲线,发现RF-DGRU-SA模型的预测曲线更加贴合真实值,说明SA模块的引入有效提高了模型整体预测精度。
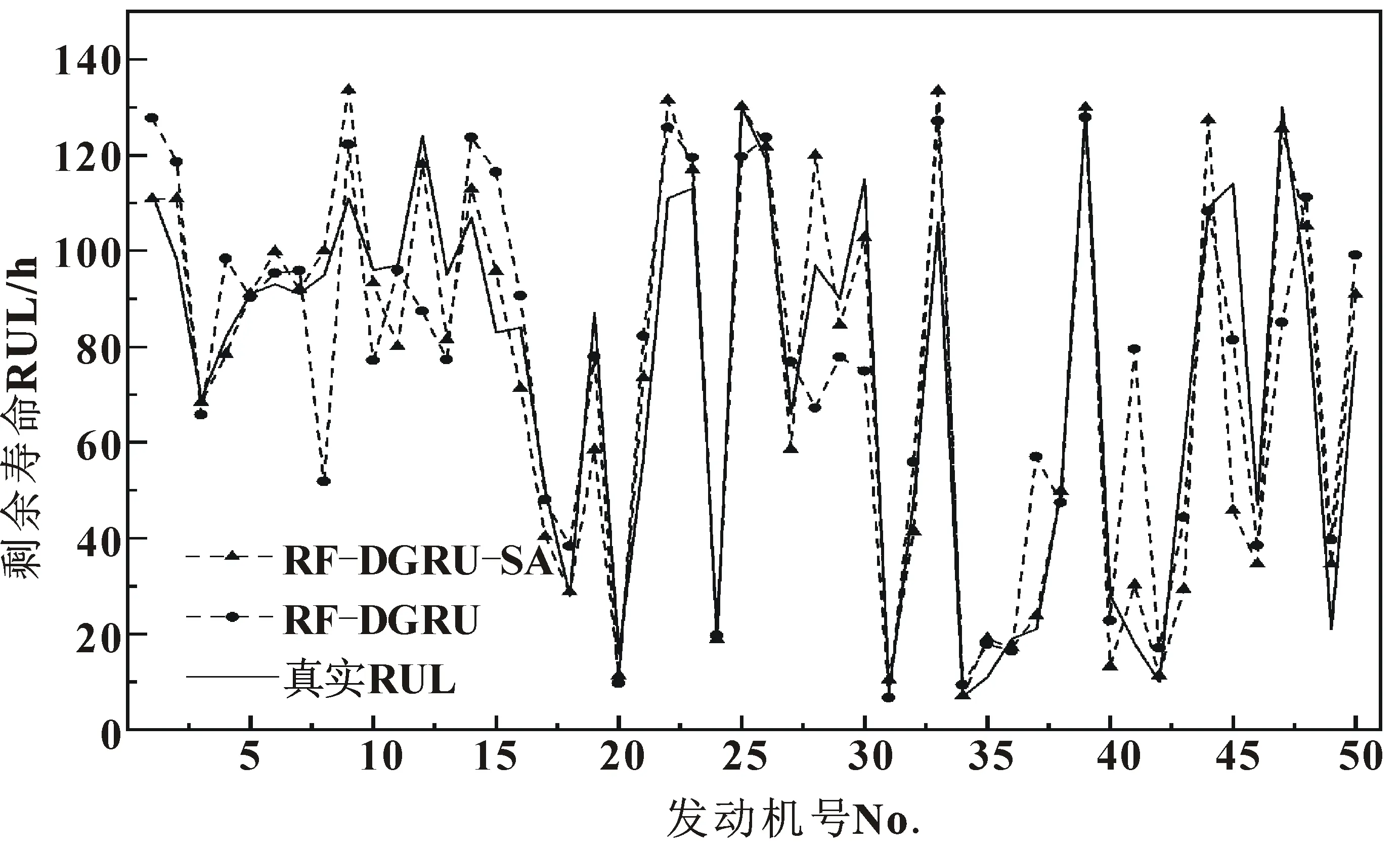
图5 两类模型对前50台发动机剩余寿命预测结果Fig.5 Remaining useful life prediction results of the first 50 engines by two types of models
图6展示了上述两种模型预测的相对误差。可以看出:与RF-DGRU模型相比,RF- DGRU -SA模型预测的误差整体波动较小,误差范围多集中于[-20,20],表明RF-DGRU-SA模型具有更好的预测稳定性。
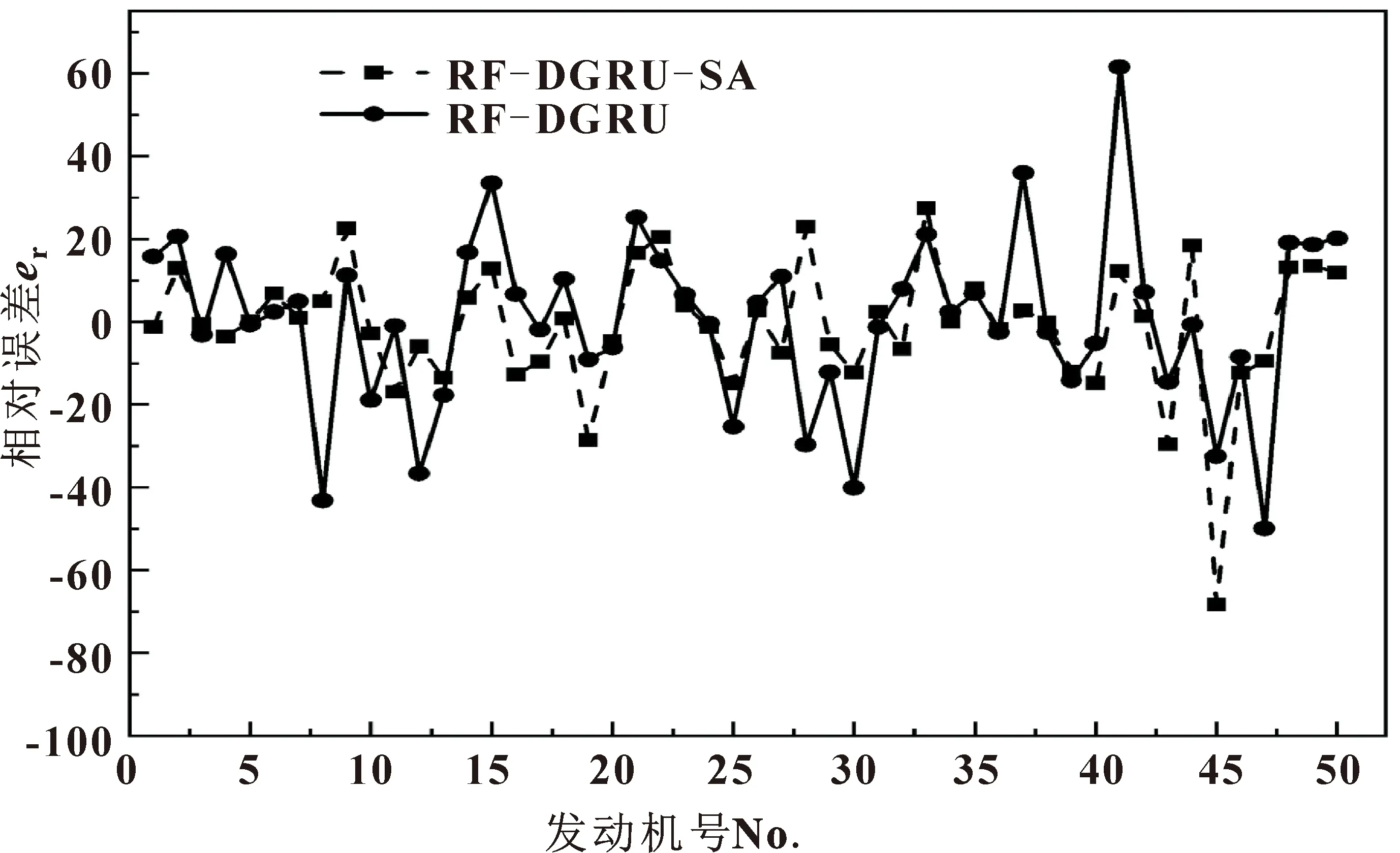
图6 两类模型预测相对误差erFig.6 Predict relative errors of two kinds of models
选取多层感知机(Multi-Layer Perceptron, MLP)模型、卷积神经网络[16](Convolutional Neural Network, CNN)模型、LSTM模型[17-18]、CNN-LSTM模型[12]与文中所提RF-DGRU-SA模型进行比较,具体结果如表2所示。
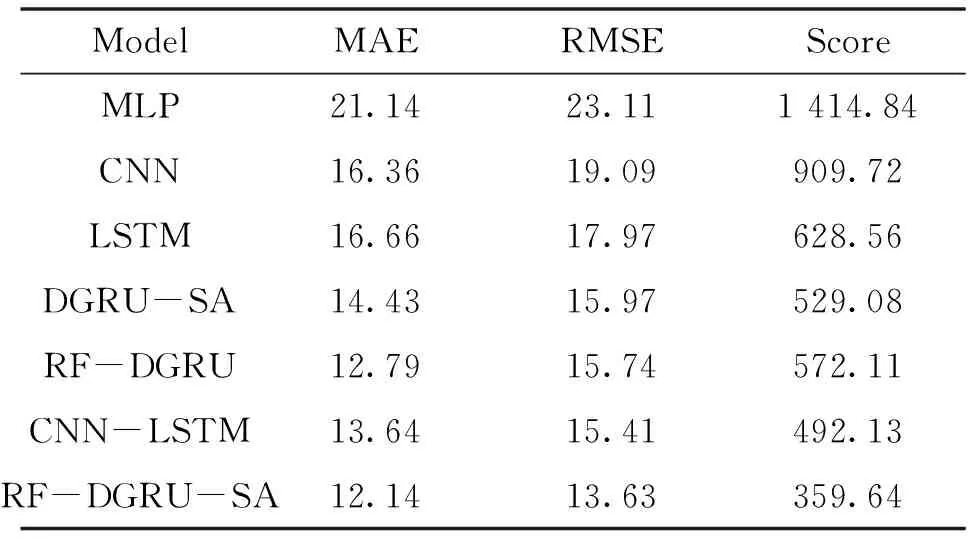
表2 不同预测方法比较结果Tab.2 The results of different forecasting methods
对比结果表明:无论是在MAE和RMSE的评价指标下还是在Score的评价指标下,文中所提方法预测误差都是最低。与其余方法的最优表现相比,文中所提方法预测误差的MAE降低了5.3%,RMSE降低了11.6%,Score得分下降了26.9%,这得益于特征提取模块对特征维数的有效降低,DGRU-SA模块提取出更深层次的隐藏信息,并根据隐藏信息的重要性赋予不同大小的权重重构隐藏信息,有效提高了对涡扇发动机RUL的预测精度。
4 结论
针对涡扇发动机退化过程机制复杂、数据维数过高等问题,提出一种RF-DGRU-SA融合模型实现对涡扇发动机RUL的预测。利用CMAPSS数据集进行实验验证,得到以下结论:
(1)通过改进随机森林算法建立特征提取模块,得到数据样本中各个特征与目标值间的关系,设置合理的重要度阈值,在高维数据中提取出重要特征,实现特征降维。与没有添加此模块,即特征提取模块的重要度阈值为零的DGRU-SA方法相比,MAE下降了15.8%,RMSE下降了14.6%,Score下降了32.1%,表明特征提取模块可以对特征进行有效提取。
(2)RF-DGRU-SA模型与其余模型最优表现相比,MAE、RMSE和Score评分分别下降了5.3%,11.6%和26.9%,并且RUL预测误差幅度变化较小,多集中于[-20,20],表明此模型有效提升了对涡扇发动机RUL预测的精度,并且具有良好的稳定性。
猜你喜欢
制造技术与机床(2019年9期)2019-09-10 07:36:54
民用飞机设计与研究(2019年2期)2019-08-05 01:33:40
西南交通大学学报(2018年6期)2018-12-18 02:22:28
电子测试(2018年1期)2018-04-18 11:52:35
河北遥感(2017年2期)2017-08-07 14:49:00
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
衡阳师范学院学报(2016年3期)2016-07-10 07:16:27
汽车与新动力(2015年1期)2015-02-27 12:11:01
电测与仪表(2014年15期)2014-04-04 12:05:20
