
基于CNN-RF模型的广州地区土壤质地识别方法
2023-02-03 12:52冯文康梁忠伟刘晓初谢鑫成萧金瑞
节水灌溉 2023年1期
冯文康,梁忠伟,刘晓初,谢鑫成,赵 传,萧金瑞
(1.广州大学机械与电气工程学院,广州 510006;2.广州大学广东省太阳能智能灌溉装备科技创新中心,广州 510006;3.广东工业大学机电工程学院,广州 510006)
0 引言
1 材料与方法
1.1 土壤质地数据
1.1.1 土壤样本采样和质地测定
土壤样品采集地点在岭南地区广东省广州市(22°26′~23°56′N,112°57′~114°3′E),地处亚热带沿海,属海洋性亚热带季风气候,是中国光、热和水资源最丰富的地区之一,年平均气温22.3℃,年降雨量约为1 720 mm,雨热同期,气候适宜,土壤肥沃,农产品丰富。广州的番禺区、南沙区、黄埔区等各区的50个采样地点在图1中标记,每个采样点采集20个样品,共1 000个样品,每个样品取250 g±10%,在去除地表存在的所有植被后,使用标准泥铲从休耕农田的土壤表层(0~15 cm)收集样本,保持样品之间距离d(d>200 m),以确保采集样品之间合理的独立性,采样点有水稻田、菜园、旱田、甘蔗地、芭蕉地。样品被收集在有标签的密封袋里,然后运回广州大学-广东省太阳能智能灌溉装备科技创新中心实验室进行处理[18]。在实验分析前,所有样品在光照强度1.5×104Lux,风速16 m/s条件下24 h风干,研磨后通过孔径为2 mm的筛网,得到筛选样本。土壤是砂粒、粉砂和黏粒的混合物,而土壤类型是按照其砂粒(0.05~2 mm)、粉粒(0.002~0.05 mm)和黏粒(<0.002 mm)所占百分比不同而定义的。土壤颗粒采用比重法[19]测定,计算出颗粒在土壤样本的占比。美国农业部土壤质地分类标准[20]采用三角坐标图解法。等边三角形的三条边分别代表黏粒、粉粒及砂粒的含量(%),对土壤质地类型进行分类。如图2中红点A位于粉壤土区域,其中砂粒5%、粉砂70%和黏粒25%。

图1 土壤采样点的地理位置Fig.1 Geographical location of soil sampling points

图2 美国土壤质地分类三角坐标图Fig.2 Triangular coordinates of USDA soil texture classification
1.1.2 土壤图像采样
在土壤图像采集中,照明条件极大影响成像任务的质量,为了减小自然光亮度等其他因素的影响,设计并制作了一体化的图像采集装置[21],如图3所示,具体包括:成像盒(12 cm×8 cm×5 cm)、相机、方形支架(4 cm×4 cm×2 cm)、直流电源适配器、照明LED灯泡(2 W,12 V)以及变光开关控制器;其中,成像盒为长方体,顶部有圆形窗口,圆形窗口用于放置相机,盒体内壁均涂为黑色;所述相机放置在盒体的圆形窗口上,用于为土壤样本进行拍照;方形支架位于盒体底部,用于固定土壤样本;照明LED灯泡位于盒体内部,照明灯由白色LED条组成,LED条水平黏贴于盒体的内壁,用于为土壤样本进行拍照时提供补光;开关控制器位于盒体外侧,与照明LED灯电连,用于控制照明LED灯的亮度,在对土壤样本进行拍照时提供100 lm和200 lm等强度光;直流电源适配器(输出电压12 V,电流500 mA)与LED灯连接,位于盒体外部,用于为照明LED灯供电。

图3 土壤样本图像采集装置Fig.3 Image acquisition device
1.2 CNN-RF模型建立
在本文中,纹理特征和颜色特征作为土壤图像分析的特征[22,23]。纹理是反映土壤图像的一种显著性特征,纹理特征提取由Haralick特征局部二值模式计算得来,采用统计类中的haralick特征和局部二值模式(Local binary pattern,LBP)对土壤图像纹理特征提取。Haralick特征算法被用于纹理量化图像表面结构组织[24]。纹理特征由Haralick特征使用4个灰度共生矩阵[22-25]来计算总共13个纹理特征向量,土壤图像像素之间相邻从左到右h=0°、左对角线h=45°、上到下h=90°和右对角线h=135°计算出4个矩阵,根据4个矩阵计算其13个统计量,可有效消除土壤图片旋转带来的不同结果。
局部二值模式(LBP)算法[25]是计算土壤图像纹理特征的方法,如图4(a)所示土壤照片像素图,本文选用圆形领域的LBP算子,16个像素采样点,每个圆的像素点半径设置为2,图4(b)是土壤图像处理后的纹理效果图。在中心的像素点,与相邻的8个像素进行比较,若周围的像素值大于中心像素标为1,否则标为0;如在3×3领域内的8个点可产生8位二进制,即是该中心像素的LBP值,图4(c)是LBP直方图统计出的26个特征向量。

图4 LBP处理后土壤图像Fig.4 Soil image after LBP treatment
颜色特征是土壤图像的一个重要特征,由颜色直方图[26]和Hu矩[27]特征组合。Hu矩是具有平移、旋转和尺度不变性的土壤图像的颜色特征,利用图像变换的常量中心矩计算出Hu矩,用7维特征向量表示。这组矩的前6个Hu矩特征对平移、缩放、旋转和反射是不变的,而第7个Hu矩的符号因土壤图像反射而改变。
颜色直方图是图像广泛采用的颜色特征,特别适于描述那些难以进行自动分割的图像。因此本文选用HSV直方图作为土壤图像的颜色特征,将图像的RGB颜色空间转换为HSV分量并计算颜色直方图的数值,然后统计H、S、V 3个通道的直方图并进行归一化,归一化后将3个维度的直方图数据进行拼接,每个通道256个维度特征,共256×6组数据,然后缩放到512个维度特征。
脂肪酸(fatty acid)是油脂(甘油三酯)的主要组成单元[1],其结构是末端含有羧基的长碳氢链,一般根据碳链的饱和程度分为饱和脂肪酸和不饱和脂肪酸,极少数特殊油脂的脂肪酸可能含有羟基、环氧基等。是自然界中最常见的有机物之一,广泛存在于动植物或微生物等的油脂中。在日常生活中,脂肪酸产品被广泛用于化妆品、洗涤剂、肥皂、工业脂肪酸盐、涂料、油漆、橡胶等领域,不愧为油脂工业的3大中间体之首[2]。脂肪酸羧基的反应最常见的自然是中和皂化成盐等,在上篇已经讲述[3],这里主要讲述羧酸的酯化、酰卤化、酸酐化、过氧化、脱羧等反应,由于a-H的活性是受到羧酸的影响,故该反应也放在本文中稍加讲解。
图5是基于CNN-RF模型结合3种组合(颜色特征、纹理特征、颜色特征+纹理特征)方法对土壤样本的黏粒、粉粒和砂粒百分比进行回归预测,519个颜色特征和39个纹理特征累积产生总共558个全局特征。这些全局特征与CNN提取的512维特征一起输入RF中,土壤质地类型是由砂粒、粉粒和黏粒的不同含量比例确定。
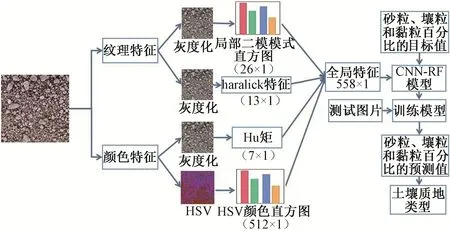
图5 基于CNN-RF模型结合图像特征方法Fig.5 Image feature method based on CNN-RF model
为对土壤质地图像进行可靠识别,考虑到平台计算能力和图像清晰度运算要求准则,图像分辨率采用256×256像素可以有效满足土壤质地图像计算速度和信息表达清晰度等多项要求。因此该研究将采集获得的土壤质地图片调整到256×256像素分辨率,输入到CNN-RF模型中。模型中第一个卷积块和第二个卷积块的卷积层的通道数分别为48和128,第三个卷积层的通道数为192,第三个卷积块中卷积层的通道数为128。除第一个卷积层的卷积核大小为11×11外,其余卷积核大小均为3×3。卷积块处理完后得到输入图像的高维特征,将其展平送入到线性块中得到512维的特征向量。其中线性块中Dropout层的概率参数取0.9,第一个线性层中全连接层为4 608维度,第2个线性层中全连接层为512维度,通过随机森林(500决策树)输出并对土壤样本中的黏粒、粉粒和砂粒百分比含量进行回归预测。
由于传统CNN方法有许多不同的预训练结构,这些结构被标记数据成功训练,如1 000个不同的类组成的Image Net。由于这类网络提取的特征是针对特定数据进行分类的,因此这类网络结构不能直接用于土壤图像的分类。另外,Softmax作为卷积神经网络分类器同时会导致泛化能力不足的问题。综合上述问题,本文结合卷积神经网络与随机森林的算法模型。通过CNN提取512维特征,这些特征要与机器学习提取的特征输入到RF中,在土壤样本图片上,既要预测土壤质地,黏粒、粉粒和砂粒的百分含量,还要根据这些进行土壤质地分类。所以既有回归预测也有分类,故选用RF进行分类[28]。机器学习算法提取出来的558×1与CNN提取出来的特征一起输入到RF模型分类器。算法流程见图6。回归预测图像中砂粒、粉粒和黏粒的百分比进而进行土壤质地分类。得到土壤质地预测混淆矩阵,来验证模型的可靠性、准确性。
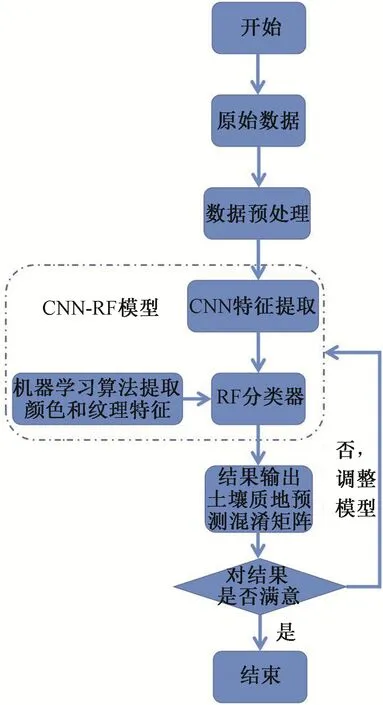
图6 结合机器学习算法的CNN-RF模型Fig.6 CNN-RF model combined with machine learning algorithm
1.3 CNN-RF模型性能评估参数
平均绝对误差(MAE)和均方根误差(RMSE)相当于L1范数和L2范数,评估预测和真实的接近程度,其值越小越好。判定系数(R2),其取值范围[0,1],越接近于1越好。
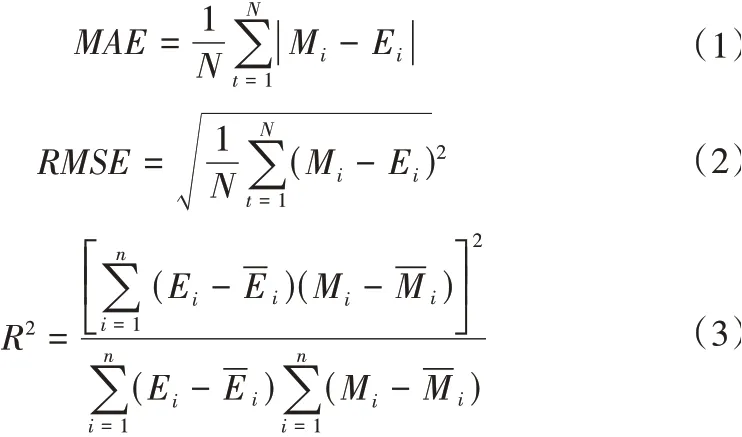
土壤是由黏粒、粉粒和砂粒不同含量比例混合而成,由3个预测值通过土壤质地三角图,得到黏土、粉黏土、壤砂土、砂黏壤土、砂黏土、砂壤土、粉壤土、粉黏壤土、黏壤土、壤土、砂土和粉土等土壤类型。提取混淆矩阵来评估土壤质地识别性能。这个矩阵中的值代表了的提出模型识别的实际土壤种类。主对角线上的数值表明样品的分类正确,而非对角元素上的数值表明样品的分类错误。通过使用混淆矩阵推导出几个统计指标如下所示。
准确度(Accuracy)是表示所有样本中完全预测对的占比,精密度(Precision)是所有预测为正确的样本中,实际为正确的样本的占比,灵敏度(Sensitivity)是所有正确例中预测为正确例占比,特异性(Specificity)是所有不正确类中预测为不正确类占比,AUC(Area Under Curve)曲线(AUC curves)是灵敏度与特异性和的一半,用来评估给定算法的性能,AUC的值接近于1越好。灵敏度参数表示模型如何检测正确样本,特异性参数表示模型如何检测不正确样本,准确性参数定义了如何同时识别不正确和正确样本。当前两个参数增大时,模型精度提高,当前两个参数减小时,精度减小。


式中:TP表示样本为正确并正确预测;FP表明样本呈正确,但预测错误;TN代表的是错误样本,但分类正确;FN描述的样本是不正确的,但不正确的预测。
2 实验数据结果
2.1 CNN-RF模型训练过程
本文实验采用70%的土壤质地识别模型数据作为测试集训练,另外30%的数据作为训练集测试。该模型采用端对端的方式进行训练和测试,使用Adam优化器,学习率为0.001。具体的训练步骤为:①初始化模型参数;②将训练数据输入到模型中并得到512维的输出结果;③512维数据输入到随机森林中得到预测的损失;④通过优化器反向传播更新模型的参数;⑤重复上述②~④的步骤,直到第200轮结束。图7为CNN-RF模型对土壤图像的训练和测试的损失函数,损失值显示了在训练过程中为每个图像所做的误差的总和,以找到最佳的权值作为模型参数。从图7可以看出,由于该函数在训练集和测试集上都呈下降趋势,CNN-RF模型经过了良好的训练,并收敛为正确的聚类分类。这个模型是收敛的,这对于CNN-RF土壤质地识别模型来说是符合逻辑的,当这个代价函数最小化到其最小值时,就可以实现准确的分类。

图7 CNN-RF土壤质地识别模型进行训练和测试数据的损失函数Fig.7 Loss function of CNN-RF soil texture recognition model training and test data
2.2 CNN-RF模型性能评估
CNN-RF模型预测黏粒、粉粒和砂粒的土壤识别验证数据统计,该模型依然使用的3种组合特征(颜色特征、纹理特征、颜色特征+纹理特征),如表1所示。预测砂粒MAE值为3.39,RMSE值为3.73,R2值为0.99;粉粒MAE值为3.51,RMSE值为3.81,R2值为0.98;黏粒MAE值为3.41,RMSE值为3.77,R2值为0.99。MAE值和RMSE值越小,R2越接近于1,模型性能更优。从结果可知,MAE值和RMSE值更小,R2更接近于1,CNN-RF模型(颜色+纹理特征模型)性能更好。

表1 不同图像特征的CNN-RF模型Tab.1 CNN-RF models with different image features
图8是CNN-RF土壤质地识别模型的判定系数R2图;预测黏粒、粉粒和砂粒的R2分别是0.99、0.98和0.99。由此可知,CNN-RF模型的R2接近于1,性能优良。

图8 CNN-RF模型预测性能对比Fig.8 Comparison of prediction performance between RF and CNN-RF models
土壤的黏粒、粉粒和砂粒的真实值和预测值对比图,由图9可知,CNN-RF模型的预测值与真实值存在差异性较小,如序号10~50的样品之间,进一步说明CNN-RF模型性能优良。

图9 CNN-RF模型的预测土壤黏粒、粉粒和砂粒含量Fig.9 Prediction of soil clay,silt and sand content by CNN-RF model
2.3 CNN-RF模型预测土壤质地的混淆矩阵
图10是CNN-RF模型得出的结果。混淆矩阵显示土壤图像的预测分布。图中矩阵的主对角线上颜色加深的元素表示预测值与实际值相等。混淆矩阵作为一种结果可视化工具,可以得到更高级的分类指标:Accuracy(精确度),Precision(精密度),Specificity(特异性),Sensitivity(灵敏度),AUC曲线。以上指标可以用来验证CNN-RF算法性能。

图10 CNN-RF土壤质地预测混淆矩阵Fig.10 CNN-RF soil texture prediction confusion matrix
表2是CNN-RF模型对土壤图像识别的各种性能统计结果。可知CNN-RF模型识别准确度为99.43%,精密度为96.66%,灵敏度为96.78%,特异性为99.69%,AUC曲线为98.23%。结果表明,这些参数都接近100%,该CNN-RF土壤质地识别模型性能较优。
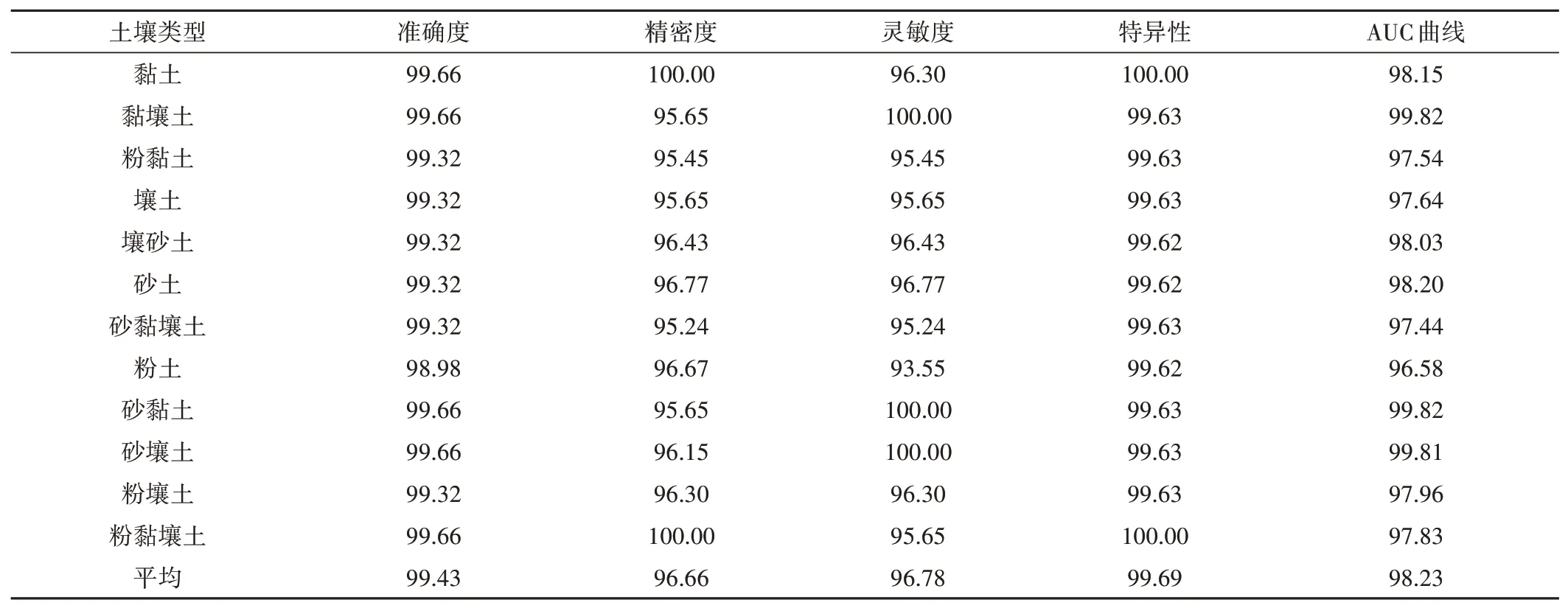
表2 CNN-RF模型预测土壤质地类型的性能结果 %Tab.2 Performance results of CNN-RF model for predicting soil texture types
3 数据分析
土壤是由黏粒、粉粒和砂粒组成。对采集的土壤图像进行灰度化、去噪处理。面向土壤图像中提取其颜色特征和纹理特征。通过土壤图像中局部二值模式(LBP)与Haralick特征计算出土壤图像的纹理特征;并将图像的RGB颜色空间转换为HSV分量计算出土壤的颜色特征;卷积神经网络(CNN)和随机森林(RF)算法相结合为CNN-RF模型,基于CNNRF模型结合3种组合(颜色特征、纹理特征、颗粒特征+颜色特征)方法对土壤样本中的黏粒、粉粒和砂粒百分含量进行回归预测。
CNN-RF模型与其他传统机器学习性能对比,VGG16-RF模型预测砂粒的MAE值为3.37,RMSE值为3.87,R2值为0.96,粉粒的MAE值为3.58,RMSE值为3.98,R2值为0.96,黏粒的MAE值为3.57,RMSE值为3.81,R2值为0.97(见表3)。VGG16的网络相对于本研究的网络更深,能够容纳的特征量更多,本应该具有更良好的性能,但在测试时指标却低于简单的网络。是因为VGG网络由于参数量更多,导致在训练集出现了过拟合的现象,从而影响了测试集的指标结果;RF模型预测砂粒的MAE值为3.58,RMSE值为4.35,R2值为0.96,预 测粉 粒 的MAE值 为3.73,RMSE值 为4.40,R2值 为0.85,预 测黏 粒 的MAE值 为3.63,RMSE值 为4.61,R2值 为0.97;KNN模型预测砂粒的MAE值为3.76,RMSE值为4.61,R2值为0.94,预测粉粒的MAE值为3.79,RMSE值为4.63,R2值为0.84,预测砂粒的MAE值为4.06,RMSE值为4.62,R2值为0.94。而CNN-RF土壤质地识别模型(颜色特征+纹理特征)的性能是最优,预测砂粒MAE值为3.39,RMSE值为3.73,R2值为0.99;粉粒MAE值为3.51,RMSE值为3.81,R2值为0.98;黏粒MAE值为3.41,RMSE值为3.77,R2值为0.99。与传统的机器学习算法相比,CNN之所以能有更好的表现,是因为它可以从更深层次上得到由各种边、线、角组成的图像,并捕捉图像的内容。可知CNN-RF模型(颜色+纹理特征)性能更好。
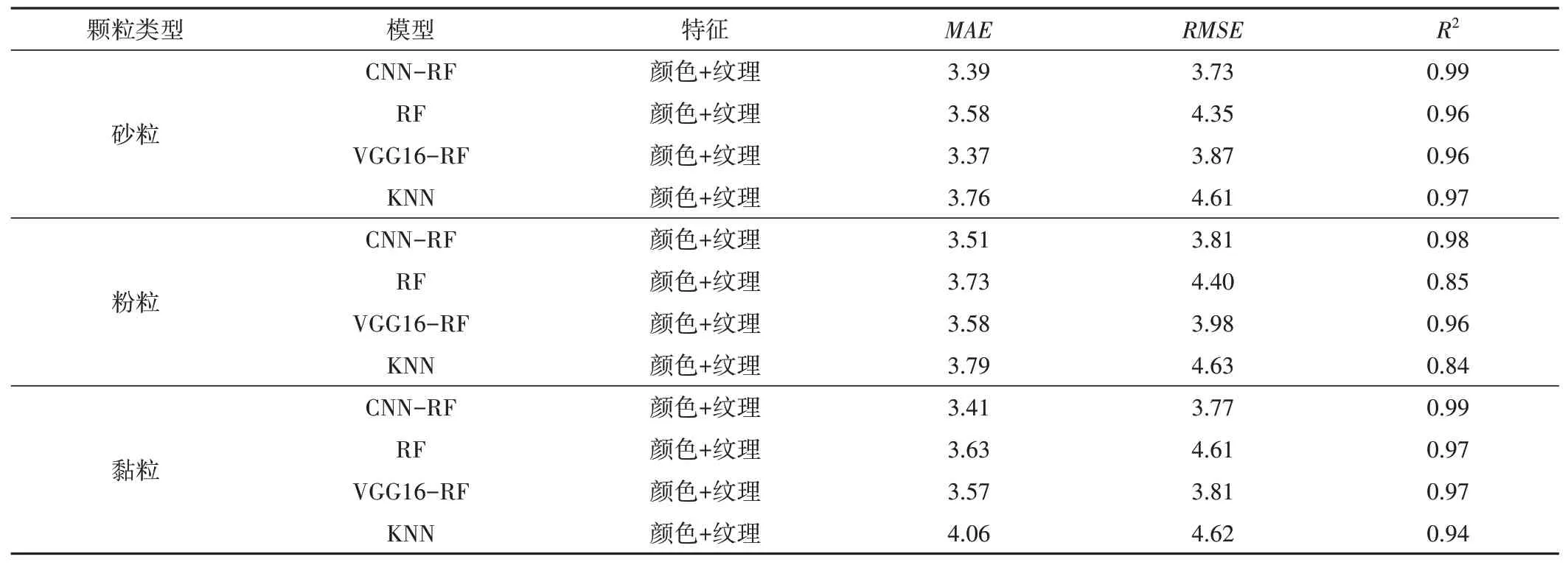
表3 CNN-RF模型性能与其他模型性能的对比Tab.3 Performance comparison between CNN-RF model and other models
4 结论
本文对广州的番禺区、增城区、黄埔区等不同区域进行1 000个土壤样本采样,提取土壤图像中的颜色特征和纹理特征,通过CNN-RF模型进行土壤黏粒、粉粒和砂粒含量预测,根据土壤质地三角图实现了土壤质地的高效精准识别。通过该模型采集总数据中700个数据用于训练,另外300个用于土壤质地识别模型测试,每个训练过程使用200个训练周期。CNN-RF模型预测黏粒、粉粒和砂粒的土壤识别验证数据统计,该模型模型使用3种组合(颜色特征、纹理特征、颜色特征+纹理特征),获得准确度、精密度、灵敏度、特异性、AUC曲线下面积等重要统计参数分别为99.43%、96.66%、96.78%、99.69%、98.23%。通过与类似算法进行比较,可看出本文提出的CNN-RF土壤质地识别模型(颜色特征+纹理特征)在关键性能指标上最优,为广州岭南丘陵土壤的耕作和农作物质量提升提供可靠技术支撑。
猜你喜欢
中国农业科学(2022年15期)2022-08-09
专用汽车(2021年11期)2021-11-18
安全与环境工程(2021年2期)2021-04-02
建材与装饰(2020年18期)2020-06-24
中华建设(2019年12期)2019-12-31
西南交通大学学报(2019年3期)2019-07-11
煤田地质与勘探(2019年3期)2019-07-02
中国地质灾害与防治学报(2018年3期)2018-07-26
浙江工业大学学报(2016年3期)2016-06-29
女友·家园(2016年2期)2016-02-29
