
特征分离编码的景区短期客流量预测模型
2023-01-31 03:56:58邹开欣佃松宜王茂宁
计算机工程与设计 2023年1期
邹开欣,佃松宜,王茂宁,2+
(1.四川大学 电气工程学院,四川 成都 610065;2.四川大学 计算机学院,四川 成都 610065)
0 引 言
随着经济的快速发展,旅游人数的增加,准确预测景区客流量成为难题。景区管理者掌握到未来客流量,有利于对未来的工作、人员安排做出科学、合理的决策,解决景区交通拥堵、景点人员拥挤等问题,排除安全隐患。景区客流量随着时间呈现出周期性规律的变化,是一种典型的时间序列,因此建立一个能够准确预测景区未来客流量的时间序列模型具有重要意义。
预测时间序列的方法有基于经典的统计学方法。Aasim等[1]提出基于自回归积分滑动平均(autoregressive integrated moving average,ARIMA)和小波变换的混合模型预测短时和超短时风速。Ilie等[2]使用ARIMA方法预测新型冠状病毒肺炎流行趋势并在多个国家得到验证。Li等[3]提出先使用灰度模型计算再使用ARIMA残差对模型进行修正和验证的方式预测能源需求的增长。此类方法比较适合于处理平稳时间序列,但是对于处理景区客流量非平稳变化的时间序列有很大的局限性。
最近几年,由于大量数据的出现和计算能力的提高,对时间序列的研究从传统的分析方法转向了机器学习和深度学习方法。机器学习方法能够较好处理非线性变化的时间序列,得到了广泛的应用。Sun等[4]将短时交通流时间序列进行相空间重构,使用支持向量机(support vector machine,SVM)对短时交通流量预测,并利用模拟退火算法对花授粉进行优化用以优化SVM的参数。Jia等[5]提出了多任务的最小二乘支持向量机,利用相邻时间点之间的相关性,构造多个相邻时间点的学习任务,并在多个时间序列数据集上验证了方法的有效性。Deng等[6]采用模糊集理论将灌溉功率时序分解成信息粒表征原始数值点集,使用SVM预测信息粒并利用灰狼优化算法调整SVM参数。Hu等[7]整合极度随机树、随机森林(random forest,RF)、极限梯度提升(extreme gradient boosting,XGBoost)、多元线性回归方法预测船舶燃料消耗,采用贝叶斯超参数优化方法设置模型的超参数值。但是相比于传统机器学习,循环神经网络(recurrent neural network,RNN)能够使用其内部状态处理输入序列,更好捕捉输入序列中的时间依赖,特别是其变体长短期记忆(long short-term memory,LSTM)神经网络,可以学习到输入序列中的长时间依赖关系。Yan等[8]将CNN挖掘到的相邻路口交通流量的空间相关性特征与LSTM挖掘到的交通流量时序特征相结合预测短时交通流量。Zheng等[9]根据交通系统中的时空关系选择LSTM模型。Xu等[10]提出基于LSTM神经网络的模型解决无站式共享单车的动态需求问题。Jia等[11]考虑到降雨对交通流量的影响,结合深度信念网络和LSTM神经网络学习各种降雨情况下的交通特征预测交通流量。
当使用LSTM做多步预测时,特别是使用单向LSTM,除最后一个LSTM单元以外,中间的LSTM单元并没有学习到整个输入序列的信息。此外,虽然LSTM能够很好学习到输入序列中的长时间依赖关系,但是当随着输入序列的增长,其性能表现也将不可避免的受到影响。近几年出现的Seq2Seq结构以及注意力机制很好解决了上述问题,为序列建模的问题探索了新的方向。Han等[12]将变道车辆以及周围车辆视作整体状态单元,并为状态单元内的所有车辆加入时空状态特征来刻画车辆间的动态行为,采用基于LSTM的编码器-解码器结构以及注意力机制预测车辆的变道轨迹。You等[13]对船舶的轨迹和位置特征进行优化,使用基于Seq2Seq结构的模型预测短期船舶轨迹。Zhang等[14]使用t-SNE算法将特征向量降维后再使用K-means算法聚类,采用为每个簇构建带注意力机制的Seq2Seq模型对功率输出进行预测。以上方法都取得了不错的效果,然而很少研究者在景区客流量预测的领域中使用注意力机制和Seq2Seq结构的模型。
本文提出了一种基于特征分离编码和注意力机制的景区短期客流量预测模型FSEANet,该模型为Seq2Seq结构,不同分布规律的特征拥有各自独立的编码器,这些独立的编码器对不同类型分布规律的特征信息编码,然后融合成最终的编码向量序列。注意力机制帮助解码器在每一个解码时刻关注到编码向量序列中不同重要程度的信息,将编码向量序列重新组合成一个上下文向量。最终解码器对上下文向量进行解码,得到未来的游客数量。
1 特征选择
景区的客流量与众多因素有关。节假日时有更多的游客出行游玩,并且游客会根据节假日的长短做出行计划。此外,游客也会关注景区的天气情况,选择在比较适合游玩的天气时出行。因此,本文选择日期、天气、假期信息和游客数量等作为特征并使用Spearman rank相关系数给出各个特征与客流量之间的相关性,见表1。Spearman rank相关系数公式如下[15]
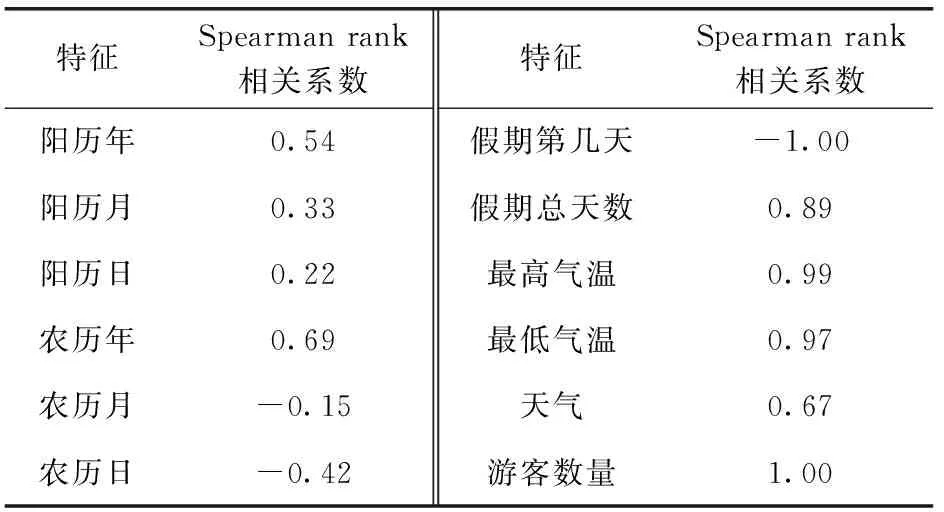
表1 特征与客流量相关性
(1)
其中,ρ代表Spearman rank相关系数, cov(rgx,rgy) 为协方差,σrgx和σrgy为秩变量的标准差。若秩变量是不相同的整数,则可用式(2)
(2)
其中,di=rg(x(i))-rg(y(i)),m为元素个数。Spearman rank相关系数的取值范围为[-1,1],相关系数大于0代表客流量随特征值单调增加,小于0代表随特征值单调减少,绝对值越接近1代表越接近完全单调相关,越接近0代表相关度越低。从表中可知,年份特征的相关系数大于0,说明客流量呈现出逐年增加的趋势。此外假期天数与气温的Spearman rank相关系数非常接近1,代表这些特征与客流量密切相关,客流量会随着假期总天数的增加和气温的提升而增多,随着剩余假期的减少而下降。
2 网络模型与算法
2.1 网络模型的整体架构
本文提出的FSEAMNet模型如图1所示。本文网络主体为Seq2Seq结构[16]。景区数据库的原始数据进行归一化处理

图1 模型框架
(3)
其中,xr代表原始特征,xr min代表原始特征中的最小值,xr max代表原始特征中的最大值,xs代表归一化后的特征。将具有相同分布规律的特征分离,根据特征的分布规律,采用均匀分布特征编码器,泊松分布特征编码器以及非均匀分布特征编码器对特征编码。3个编码器相互独立,减少了干扰分布规律的影响,提高了编码器对相同分布特征的编码能力。编码器均采用LSTM神经网络,由于不同特征在时间方向上具有不同的相关性,因此均匀分布特征编码器与非均匀分布特征编码器采用单向LSTM神经网络,泊松分布特征编码器采用双向LSTM(Bi-LSTM)。注意力机制提升解码器对编码向量的聚焦能力,在不同的解码时刻为每个编码时刻的编码向量分配权重,从而得到关键的包含各个分布规律特征的编码向量表示——上下文向量。解码器采用同样的LSTM神经网络将上下文向量中的信息解码成游客数量信息。
2.2 特征编码器

X′p=fc256(Xp)
(4)
X′u=fc256(Xu)
(5)
X′n=fc256(Xn)
(6)
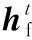
2.3 解码器与注意力机制

(7)

(8)
(9)
(10)

(11)

3 实验结果与分析
3.1 景区游客数据及实验建立
本文选取的数据集是从景区数据库中获取的真实数据。该数据集中包含了从阳历2011-01-02~2017-07-05的数据,包括阳历年、阳历月、阳历日、农历年、农历月、农历日、假期第几天、假期总天数、气温上限、气温下限、天气和游客数量。阴历考虑到有闰月的情况,本文把闰月定义为闰的月份加0.5,即如果是闰4月,用4.5表示。另外天气是非数值型数据,因此需要将天气数据编码,按照天气的恶劣程度将天气编码。1到6的整数分别代表雪、雨、雾、阴、多云和晴。小数代表天气的转变,如5.6代表多云转晴。
以时间步长为1,滑动窗口为30提取样本,同时将窗口后预测天数内的游客数量作为该样本的预测真值,随机选择80%的样本作为训练集,20%的样本作为测试集。使用Pytorch v1.6.0在NVIDIA GeForce GTX 1660Ti GPU上训练模型,训练的epoch设置为1000,并且在测试集上引入early-stopping机制,避免模型过拟合。使用均方误差(mean squared error,MSE)为模型损失函数
(12)
此外,使用Adam优化器优化损失函数,学习率设置为0.0002,第一和第二矩估计的指数衰减率指数下降率和分别设置为0.5和0.999。
3.2 评价标准
本文的评价标准从两个方面考虑,一是从模型的拟合能力方面,考虑均方根误差(root mean squard error,RMSE)以及平均绝对误差(mean absolute error,MAE)作为评价标准。二是从实际工程应用方面,使用平均绝对百分比误差(mean absolute percentage error,MAPE)作为评价标准
(13)
(14)
(15)
3.3 模块重要性分析
3.3.1 注意力机制的影响
图2说明了注意力机制对FSEAMNet预测误差的影响。本文模型在图中集中于左下角,相比于特征分离编码的网络模型(feature separation encoding network,FSENet)各种层数的编码器和解码器组合中的预测误差都有明显的下降。尤其是在最简单的编码器和解码器层数的组合中,即一层编码器和一层解码器,误差最多下降了65.38%。误差下降最少也有26.89%,当组合为3层编码器,两层解码器时。图3展示了不同输入输出对的注意力矩阵,行代表输入时间步长,列代表输出时间步长。可以看到,不同时间步的输出对输入序列的关注部分并不一样,从图中可以观察到输出序列随时间步长向后的推移,对输入序列的关注重点也在向后推移,使得不同时间步的输出序列能够捕捉到输入序列中对当前时刻更有价值的信息。注意力机制的引入使得解码器获得了聚焦功能,增强了模型对具有长时间依赖的序列的学习能力。
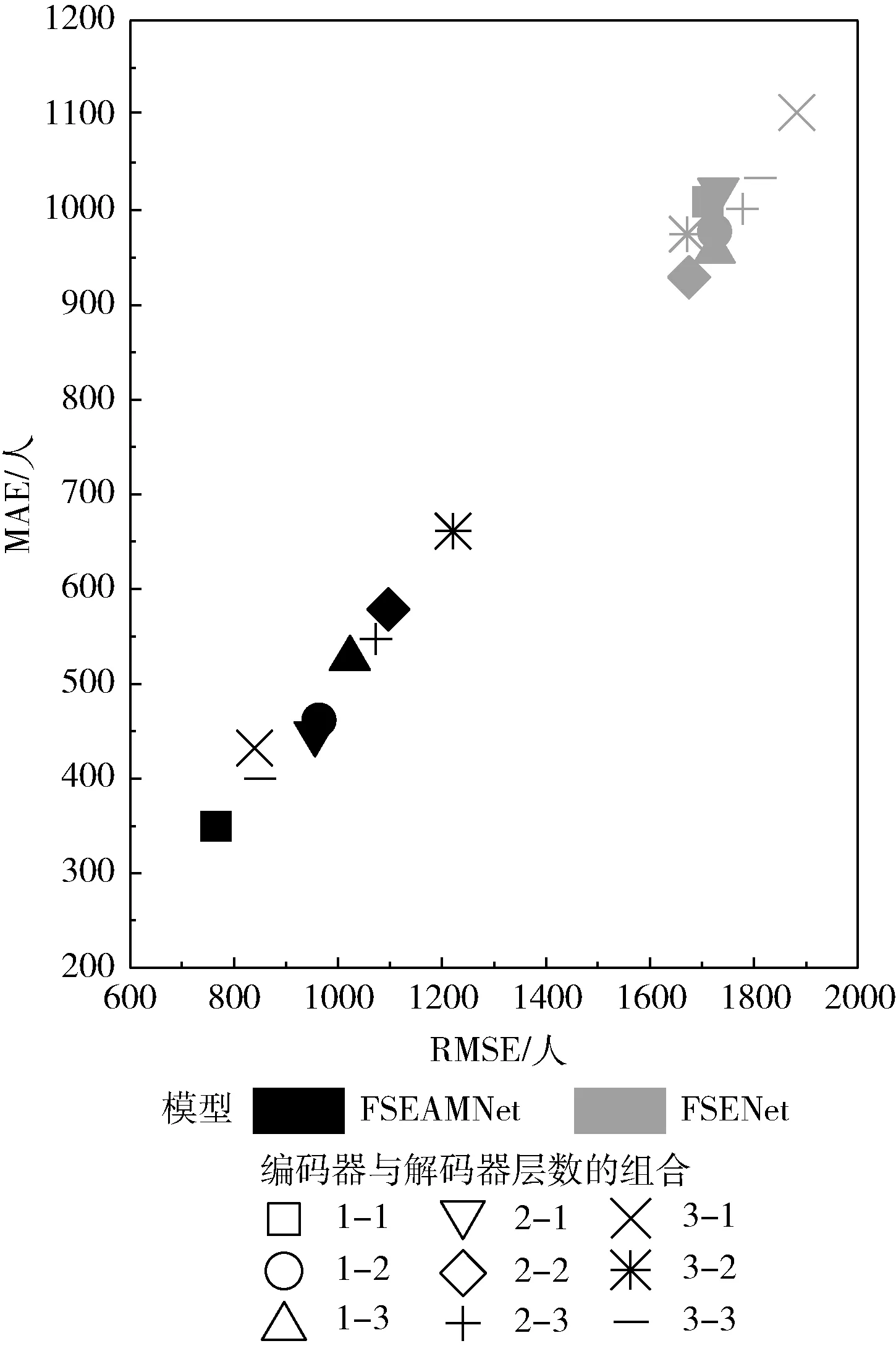
图2 注意力机制的影响
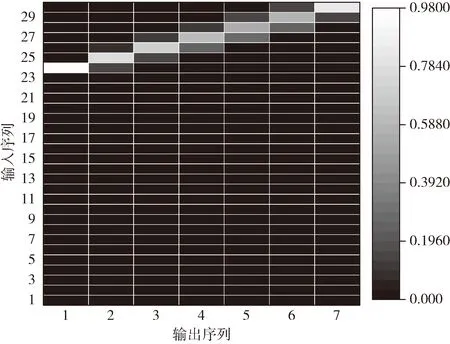
图3 注意力矩阵的可视化
3.3.2 特征分离的影响
图4说明了特征分离对FSEAMNet预测误差的影响。与统一编码的FSEAMNet(FSEAMNet in unified encoding,FUE)相比,所提模型在图中位置更加靠近左下方,表明模型的预测误差有了显著的下降。其中在一层编码器和一层解码器的组合中减少最多,误差最多减少了50.84%。当组合为3层编码器和两层解码器时误差最少减少有2.57%。结果验证使用独立的编码器对具有不同分布规律的特征分别进行编码,能够使编码器专注于学习和理解具有相似类型的分布特征规律,避免了信息杂乱,让编码效果更加出色,预测误差有效减少。
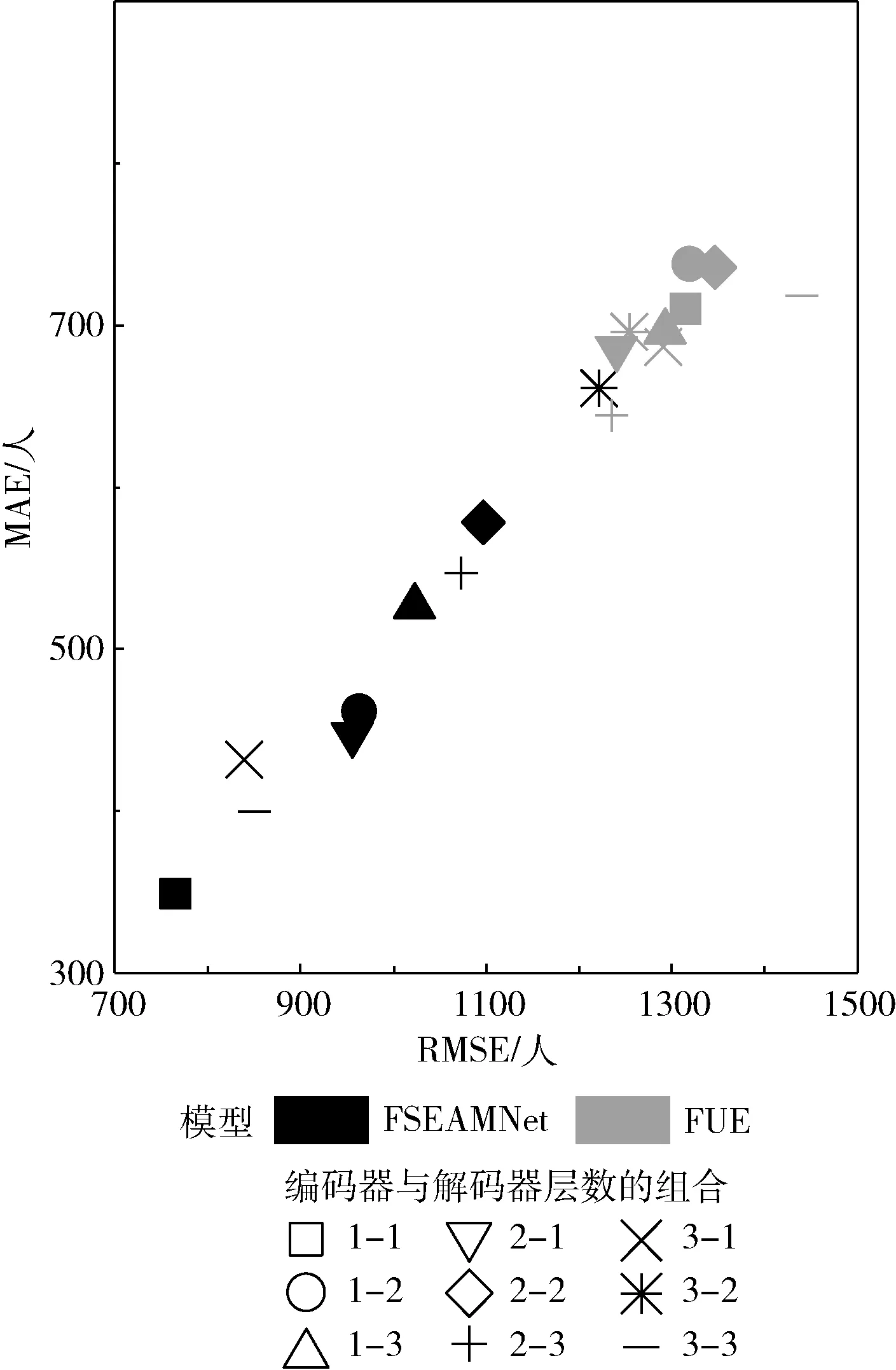
图4 特征分离的影响
3.4 景区客流量预测性能比较
本文将FSEAMNet与其它方法作了对比,如RF、XGBoost、LSTM、Bi-LSTM、FSENet以及FUE。表2展示了不同历史时间窗口各个模型预测性能的细节对比,每个时间窗口最好的结果都加粗显示。对于传统方法RF和XGBoost,与更加适合时序问题建模的基于LSTM的模型比较,它们的预测误差都排在靠前的位置。对于LSTM模型,Bi-LSTM的性能表现略好于单向的LSTM。对于拥有基于LSTM的Seq2Seq结构的FSEAMNet,本文对比了将特征分离编码但无注意力机制的FSENet,以及不区分特征分布规律但拥有注意力机制的FUE。在所有的历史时间窗口中,基于Seq2Seq结构的模型的预测结果更加准确,特别是本文提出的FSEAMNet模型,在所有历史时间窗口中的表现都是最好的。从表中可知,在历史时间窗口为30时,本文模型在各项性能指标中的表现均为最优,展现了所提模型对于长时间序列优秀的建模能力。在各指标中,最多比RF下降82.80%,比XGBoost下降80.50%,比LSTM下降75.34%,比Bi-LSTM下降73.14%,比FSENet下降65.38%,比FUE下降51.82%。
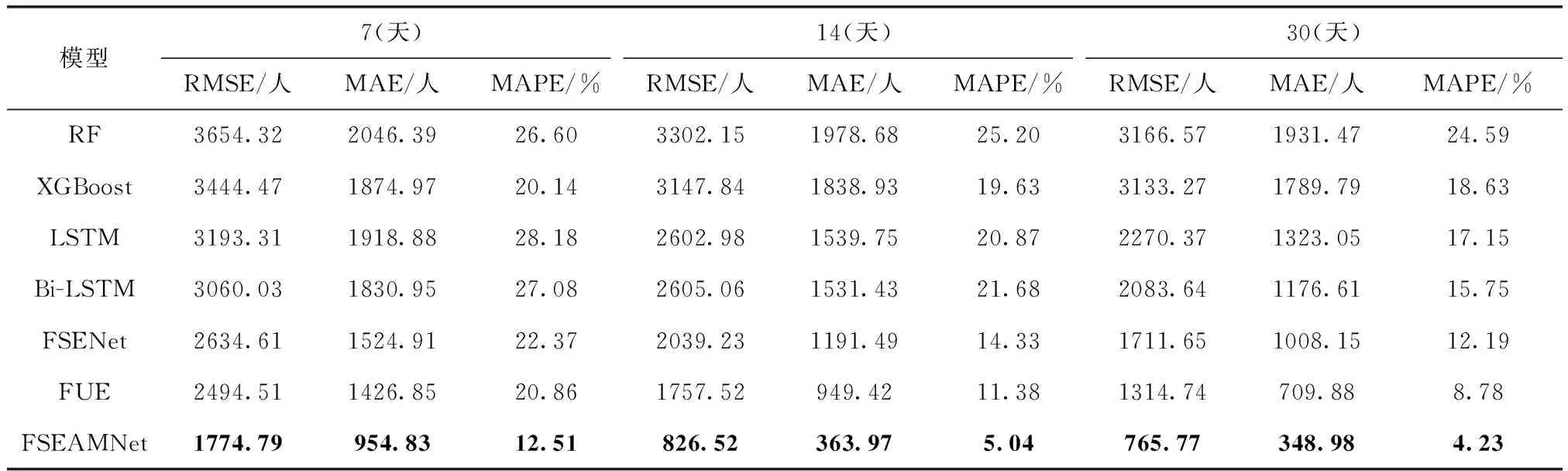
表2 各模型性能表现对比
3.5 景区客流量预测案例分析
在实际工程应用中,景区会利用所有的历史数据作为模型的训练数据,然后用训练好的模型预测未来一周的客流量,根据预测的客流量做出相应的一系列管理措施。本节模拟了10次独立的工程应用,即不是对同一周的客流量做重复预测。每一天预测客流量的MAPE如图5所示。从结果上看,FSEAMNet对未来一周客流量预测的MAPE均小于10%,完全能够满足工程上的应用要求。
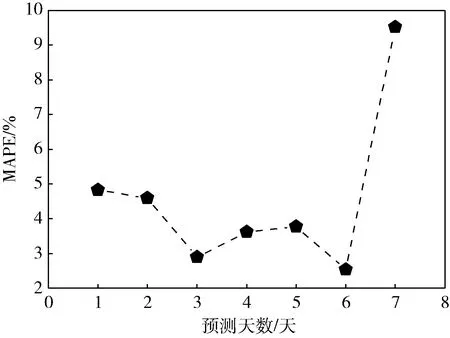
图5 预测客流量的MAPE
此外预测时可以大致分为两种情况,一种情况是未来一周没有包含节日,另一种情况是未来一周包含了节日的特殊情况。因此,针对这种特殊情况下模型的表现,本文也对FSEAMNet性能表现进行了比较,如图6所示。在图6(a)的实验中,所要预测客流量的日期中没有包含节日,而在图6(b)的实验中,所要预测客流量的日期中第2天到第4天是劳动节。从图6(c)中可以看到,两种情况下所提模型的每日MAPE都保持在10%以下,说明模型具有一定的鲁棒性,但在无节日的情况时MAPE波动较小,在有节日的情况时,MAPE在节日附近两天有一定的波动。

图6 特殊案例
4 结束语
本文提出了适用于真实景区客流量预测的模型FSEAMNet。该模型根据特征的分布规律将特征分离并独立编码,泊松分布规律特征采用Bi-LSTM特征编码器编码,均匀分布和非均匀分布规律特征采用单向LSTM特征编码器编码,解码器基于单向LSTM,并在加入注意力机制后得到聚焦编码信息的能力,最后在解码器的解码信息中提取到未来客流量信息。在真实的景区客流量数据中对FSEAMNet进行了验证。所提模型最小RMSE、MAE和MAPE分别为765.77、348.98和4.23,与其它模型相比误差下降最多达82.80%。在工程案例分析中,每日MAPE均小于10%。实验结果表明,所提模型能够较准确的预测景区未来短期客流量,为景区管理者掌握未来客流量变化提供了一种可行的方法。
猜你喜欢
小学生必读(低年级版)(2021年10期)2022-01-18 15:10:46
小学生必读(低年级版)(2021年11期)2021-03-09 06:14:46
小学生必读(低年级版)(2021年12期)2021-03-04 07:18:44
家庭影院技术(2019年8期)2019-12-04 14:43:19
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
精密制造与自动化(2018年1期)2018-04-12 07:42:49
电子设计工程(2017年20期)2017-02-10 03:39:29
电子器件(2015年5期)2015-12-29 08:42:24
中国铁道科学(2015年1期)2015-06-26 08:33:56
电测与仪表(2014年13期)2014-04-04 12:04:18
