
基于深度可分离的多尺度Lw-YOLO轻量化人脸检测网络
2023-01-31 08:55陈伟民于津强
计算机应用与软件 2022年12期
陈伟民 段 锦 于津强 吴 杰 陈 宇
(长春理工大学电子信息工程学院 吉林 长春 130022)
0 引 言
近些年来,随着深度学习的飞速发展,越来越多的卷积神经网络相继诞生,与此同时,相关的改进网络也是层出不穷。但是绝大多数网络都是适用于带有GPU的PC机。目前所谓的“实时”性,验证的模型都是建立在TitanX[1]或者Tesla这类强大独立显卡的基础上,而在实际的应用场景中,例如超市的人脸识别、自动售货机的人脸识别等,并不能配备这些装备。所以这类模型一旦移植到计算和内存相对不足的嵌入式平台时,检测的速度就非常不理想,达不到实时的要求。
因此,实时性高的检测网络进入到了人们的视野。例如,Redmon等[2]提出的YOLO和Liu等[3]提出的SSD等网络都是旨在提高目标检测的速度。其中,YOLO-LITE[4]是致力于CPU和嵌入式检测的网络模型,其有效地加快了检测速度,但是带来了检测精度的损失。本文设计一种计算参数量小、人脸检测精度高的轻量化网络Lw-YOLO。该网络以YOLO-LITE为基础,由深度可分离卷积(depthwise separable convolution)[5]替代传统卷积,以减少参数量;同时利用多个1×1的点卷积提升网络深度,获得更多的特征;采用改进的多尺度预测方法,将浅层的特征充分地提取与深层的特征结合[6],提高了人脸检测的精度。将该网络应用到本文的树莓派人脸检测系统中,可以达到较高的检测精度和速度,基本满足实际应用场景,具有较好的市场前景。
本文从Lw-YOLO人脸检测网络原理出发,通过深度可分离卷积的方法减少网络的参数量及改进的多尺度预测方法提高网络的精度,达到速度和精度的双平衡。最后,在WiderFace和Extended Yale B数据集上通过多组的实验比较,验证Lw-YOLO网络的实用性、合理性,为无GPU嵌入式平台的轻量化网络设计提供一条新的思路。
1 基于Lw-YOLO的目标检测原理
本文提出的Lw-YOLO轻量化网络是基于无GPU嵌入式平台设计的网络架构,对输入图像提取特征,通过逻辑回归预测每个边界框分数,筛选得到每个类别的预测结果,实现端到端[7]的快速目标检测。
图1为整个网络的原理图,网络首先将一幅未知分辨率图片的输入分辨率重置为224×224,并等分成S×S个栅格,如果目标中心落在某个栅格内,就由该栅格负责此目标的检测任务。然后网络通过目标中心、栅格宽高和预设边界框(anchor box)进行目标边界框的预测。每个人脸得出三个预测的边界框,每个边界框输出5个参数,分别是预测边界框的中心坐标(Bx,By)、预测边界框的宽高(Bw,Bh)和最终的预测置信值C,最后筛选出置信值最高的边界框,加上标签。
边界框预测过程如图1中间的大图所示,虚线矩形框为预设边界框,实线边界框为通过网络预测的偏移量计算得到的预测边界框。其中:(Cx,Cy)表示栅格的边距;(Pw,Ph)为预设边界框的宽和高;(Tx,Ty)和(Tw,Th)分别为网络预测的边界框中心偏移量以及宽高缩放比。从预设边界框到预测边界框的转换公式为:
Bx=σ(Tx)+Cx
(1)
By=σ(Ty)+Cy
(2)
Bw=PweTw
(3)
Bh=PheTh
(4)
Pr(obj)×IOU(box,obj)=σ(To)
(5)
C=max(σ(To))
(6)
式中:(Tx,Ty)用Sigmoid函数归一化处理,使取值在0~1之间;σ函数表示归一化值转化为真实值;Pr(obj)为目标属于某一类的概率;IOU(Intersection over Union)是预测的边界框和真实标定框之间的交并比[8];σ(To)表示预测边界框的置信值。
网络根据维度聚类(dimension clusters)[9]的方法对人脸数据集聚集6组预设边界框的宽高(即anchors值),一次预测选定三个预设边界框,依照不同大小的人脸尺寸,分别进行两次不同尺度的独立预测。维度聚类方法可以自适应地找到更好的边界框宽高尺寸,有利于提升速率和网络收敛程度。而传统网络的距离指标使用的是欧氏距离函数,这意味着较大的边框会比较小的边框产生更多的错误,聚类结果可能会偏移。为此,网络采用IOU得分的评判标准,削减了边框产生错误的概率,最终的距离函数表达式为:
d(box,obj)=1-IOU(box,obj)
(7)
在训练过程中,网络用二元交叉熵损失来预测类别。二元交叉熵损失公式为:
(8)
(9)
当且仅当yi和yj相等时,Loss为0;否则,Loss为一个正数。
2 Lw-YOLO轻量化网络模型
2.1 Lw-YOLO网络架构
针对YOLO-LITE在嵌入式设备检测精度较低的问题,本文设计一种计算参数量小、人脸检测精度高的轻量化网络Lw-YOLO,通过深度可分离卷积的方法减少网络的参数量及改进的多尺度预测方法,添加多个1×1卷积提高网络的精度,达到速度和精度的双平衡。
Lw-YOLO轻量化网络相比较于图2 YOLO-LITE网络,具有网络更深、精度更高的优势。如图3所示,首先,网络以YOLO-LITE为基础架构,选取224×224的图片输入,增加网络层数至20层,将除第一层卷积外的所有是3×3卷积核的传统卷积都替换成更高效的深度可分离卷积,减少计算量,提升网络深度。增加滤波器个数至512个,以获得更多的特征。其次,改进多尺度预测,同时利用低层特征和高层特征,将7×7×128特征图(feature-maps)[10]经过上采样2倍后得到14×14×128特征图,再与之前14×14×256特征图叠加融合,形成14×14×384的特征图,最后分别在YOLO1(7×7×18)和YOLO2(14×14×18)两个尺度做独立检测。
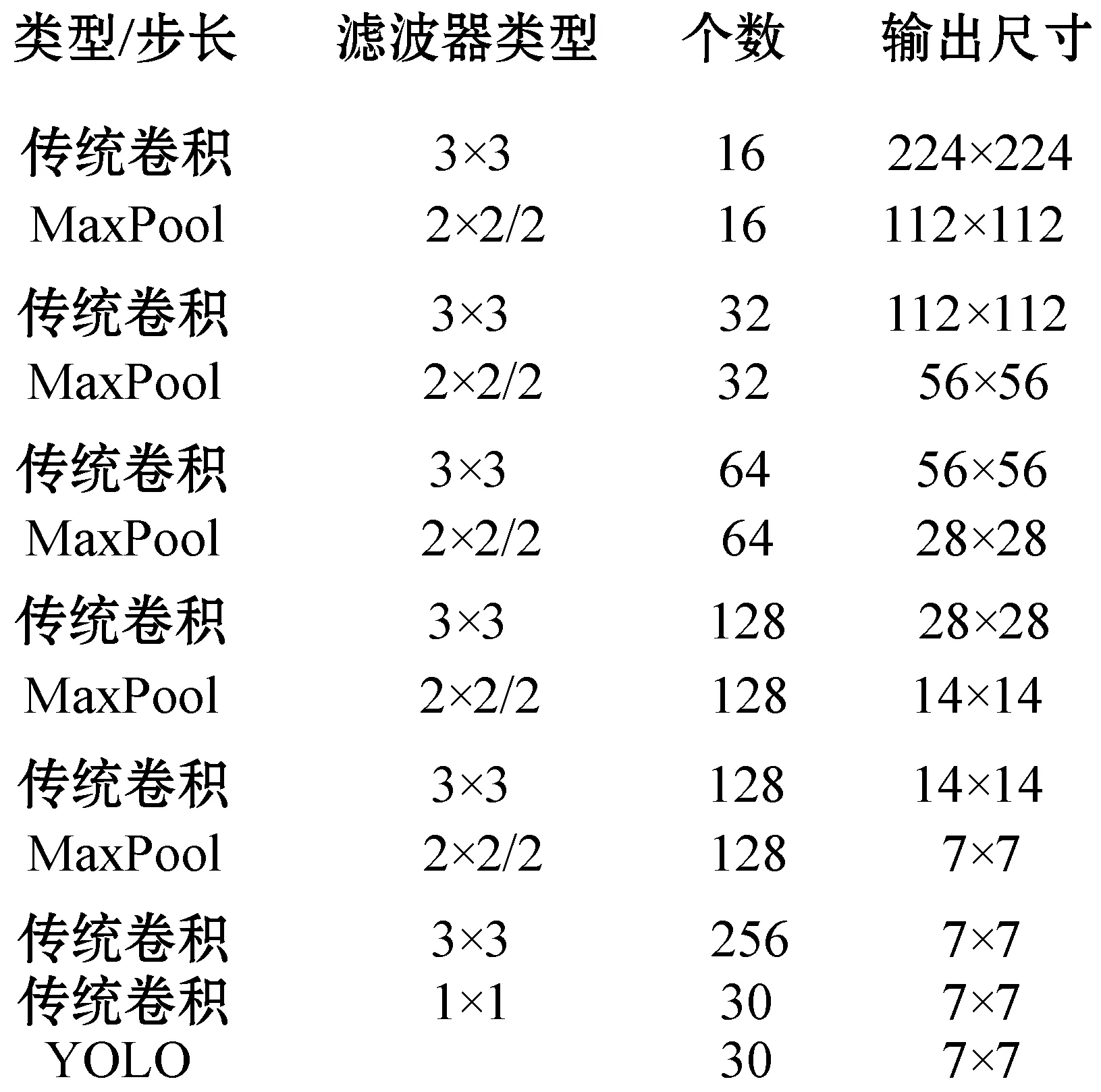
图2 YOLO-LITE网络架构
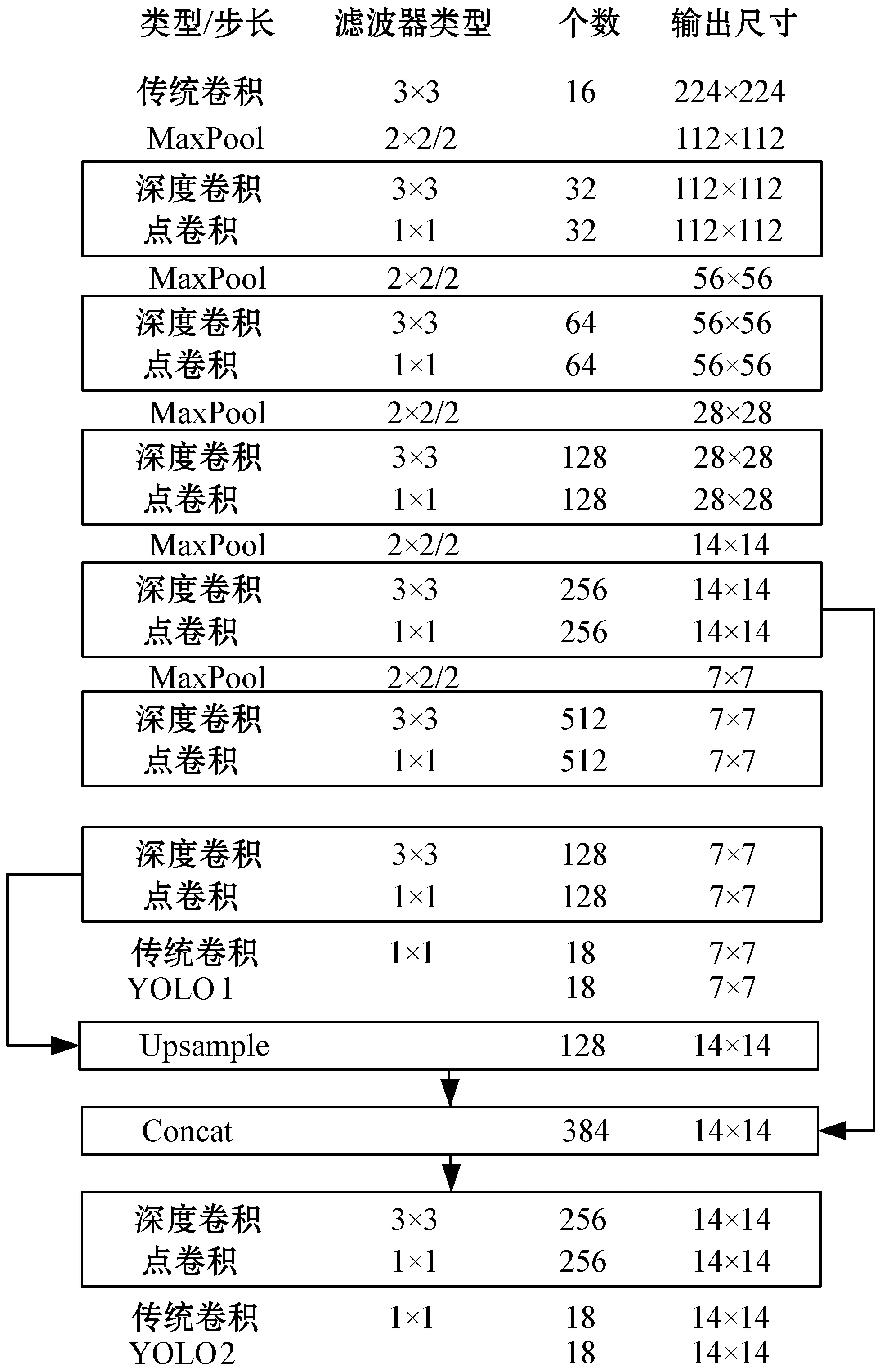
图3 Lw-YOLO网络架构
YOLO-LITE为每个特征图的每个栅格设置5个预设边界框,所以每个栅格的张量(tensor)为5×(4+1+1)=30,其中:4表示(Tx,Ty,Tw,Th)4个坐标偏移;前一个1表示包含目标得分;后一个1表示1个类别,因此得到总输出张量为7×7×30=420。而Lw-YOLO网络为每个栅格设置3个预设边界框,每个栅格的张量为3×(4+1+1)=18,总输出张量为7×7×18+14×14×18=4 410。
2.2 深度可分离卷积
Lw-YOLO轻量化网络模型将传统卷积替换成深度可分离卷积提高网络的计算效率,大大减少了计算的参数量。多个1×1点卷积的引入增加网络模型的深度,保证网络的精度。
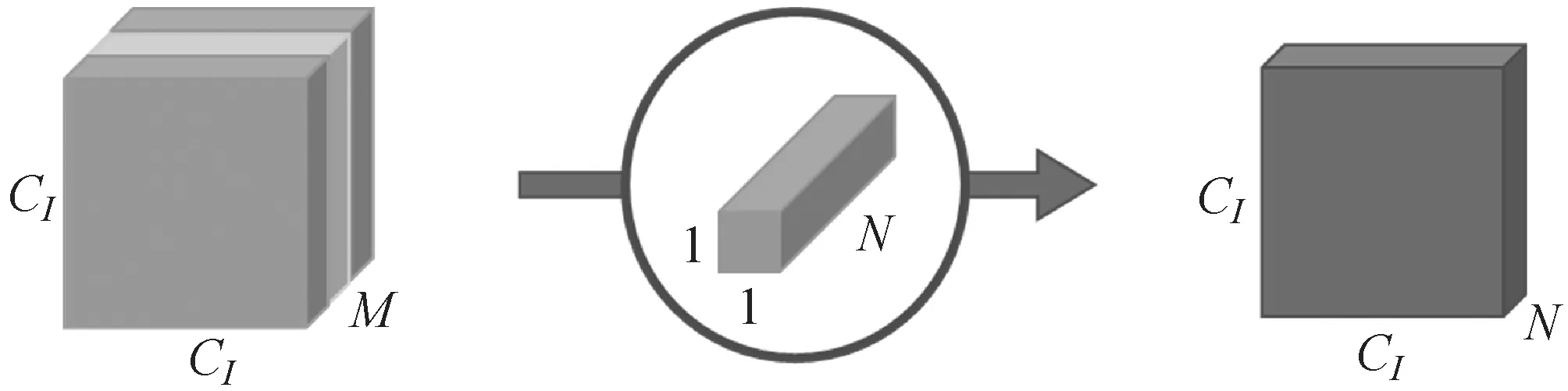
如图4所示,若原始图像是二维的,大小是CI×CI,有M个通道,相当于是一个三维的图片。其输入图片格式是CI×CI×M。卷积核大小是Dk×Dk。输入图片被M个不同Dk×Dk大小的卷积核遍历N次,产生M×N个特征图谱,进而通过叠加M个输入通道对应的特征图谱融合得到1个特征图谱,最后产生的输出图像大小是CI×CI×N。则传统卷积计算的参数量为:
C=Dk×Dk×M×N×CI×CI
(10)
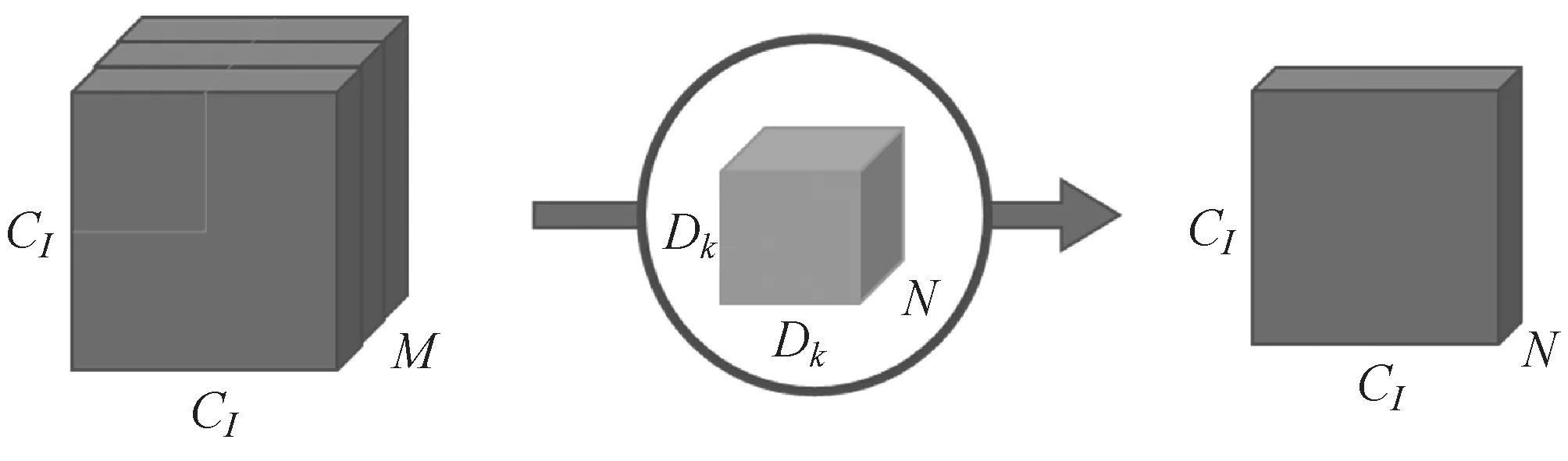
图4 传统卷积
如图5所示,深度可分离卷积是通过两次卷积实现的,即将传统的卷积分解为一个深度卷积(depthwise convolution)和一个1×1的点卷积(pointwise convolution)[5,11]。第一步,用M个Dk×Dk的卷积分别对输入图片的M个通道做一次卷积,生成M个特征图谱。第二步,M个特征图谱中分别通过N个1×1的卷积核,生成M×N个特征图谱。最终叠加M个输入通道对应的特征图谱后融合得到1个特征图谱。深度可分离卷积计算的参数量为深度卷积和1×1点卷积的参数量[12]之和为:
D=Dk×Dk×M×CI×CI+M×N×CI×CI
(11)
忽略N,当Dk=3时,深度可分离卷积和传统卷积分别计算的参数量之比为:
(12)
由式(12)可见,深度可分离卷积的参数量缩减为传统卷积的1/9左右。
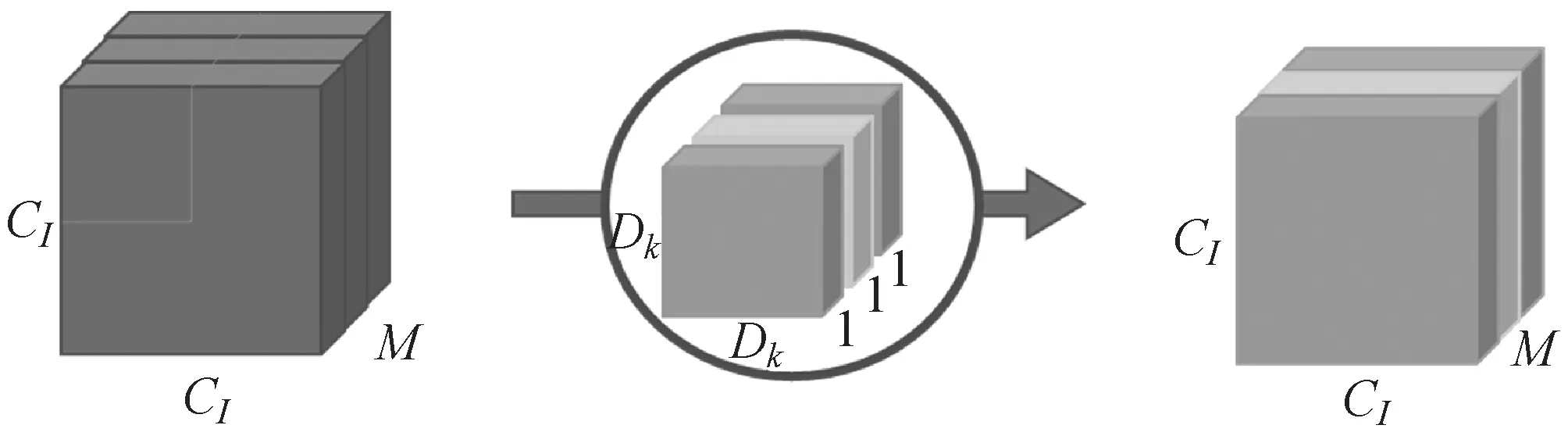
(a) 深度卷积
(b) 点卷积图5 深度可分离卷积
2.3 改进的多尺度预测
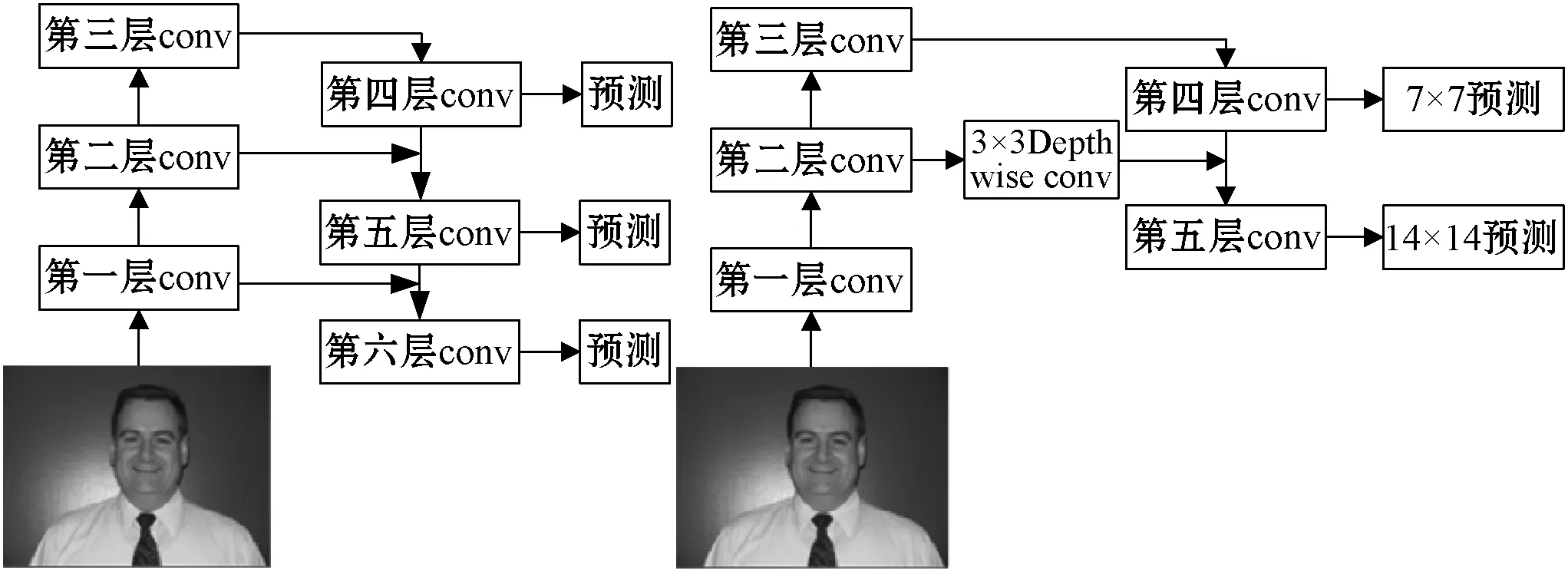
由于一幅图片中可能具有多个不同大小的目标,对于简单的目标仅仅需要浅层的特征就可以检测到它;而对于复杂的目标,就需要利用复杂的特征来检测它。因此,区分不同大小的目标需要不同尺度的特征。本文借鉴FPN[13]网络的思想,采用改进的多尺度预测方法预测目标,7×7尺度特征图采用(10,24)、(11,15)、(41,54)三个预设边界框预测较大简单的目标。14×14尺度特征图同时利用低层特征和高层特征,采用(4,5)、(6,7)、(8,10)三个预设边界框预测较小复杂的目标,所以能在较小的计算开销下产生不同尺度的独立预测。它的优点是在不同尺度的层上负责输出不同大小的目标,在有不同大小的目标时,较大的目标直接由7×7预测层输出,不需要进行下面的卷积操作,而14×14预测层不需要再一次经过第三层卷积就能输出对应的小目标(即对于有些目标来说,不需要进行多余的前向卷积操作),这样可以在一定程度上对网络进行加速操作,同时可以提高算法的检测性能。
整个过程如图6(b)所示,首先网络对输入的图片进行深度卷积,在基础网络之后对第二个卷积层上的特征进行降维操作(即添加一层1×1的卷积层),在第四个卷积层输出第一个尺度7×7的特征图;对第四个卷积层上的特征进行上采样操作(×2),使得它的尺寸扩大两倍,即与第二个卷积层的尺寸相同,然后对经过深度卷积处理后的第二个卷积层和处理后的第四个卷积层执行加法操作(即对应元素相加),将获得的结果输入到第五个卷积层中去,这样做能找到早期特征映射的上采样特征和细粒度特征[14],并获得更有意义的语义信息。之后,网络添加多个卷积层来处理这个特征映射组合,得到相比第一个尺度变大两倍的第二个尺度14×14特征图。
(a) FPN的多尺度金字塔 (b) 轻量化的多尺度金字塔图6 多尺度金字塔结构
本文从两种不同尺度的特征图谱上进行预测任务,网络用相似的概念提取这些尺度的特征,以形成特征金字塔网络。这次本文使用了轻量化的深度可分离卷积层来构造特征金字塔,提高网络的计算效率;相比较图6(a),网络只进行两次预测,即将处理过的低层特征和处理过的高层特征进行累加,这样做的目的是因为低层特征可以提供更加准确的位置信息,而多次的降采样和上采样操作使得深层网络的定位信息存在误差;因此,我们将其结合起来使用,这样就构建了一个更浅更轻量化的多尺度特征金字塔,融合了两层特征信息,并在不同的尺度进行独立预测输出。
3 实验结果分析
3.1 实验环境与数据集
模型训练环节的实验是在较高配置的PC端进行的,具体硬件环境为:处理器:Intel Core i7- 6700 3.4 GHz处理器;显卡:GeForce GTX 1060显卡,显存为6 GB。实验的软件平台环境为:训练框架:DarkNet;开源库:OpenCV;界面设计:PyQt4。
测试使用树莓派3B+作为嵌入式平台,树莓派软件配置树莓派Respbian系统、OpenCV3.4.4、Python3.5编程语言。
本文使用WiderFace和Extended Yale B人脸数据集作为人脸检测的训练数据集和测试数据集。WiderFace包含32 203幅图像和393 703幅人脸图像,在尺度、姿势、闭塞、表达、装扮、关照等方面表现出了大的变化。Wider Face是基于61个事件类别组织的,本文对于每一个事件类别,选取其中的50%作为训练集,10%作为验证集,40%作为测试集。
扩展Yale人脸数据库B中包含28个人16 128幅图像,包括9种姿态、64种光照条件下的图像。本文将它用作模型对不同光照、角度人脸检测的测试集。
根据维度聚类方法对WiderFace人脸数据集进行聚类,得出6组anchor值。anchor box为特征图上的点预测的宽高比例不同的预设边界框,anchor值表示预设边界框的宽高尺寸,用相对于原图的大小来定义,大小范围为(0×0,224×224)。网络对于输入图像考虑6个预设边界框,结果如表1所示。

表1 WiderFace人脸数据集6组anchor值
3.2 Lw-YOLO网络训练结果分析
网络在3.1节实验环境中,初始学习率learning-rate为0.001,衰减系数decay为0.000 5,动量参数momentum为0.9,每10 000次迭代保存一次此时的网络权重,在训练迭代次数为40 000和60 000时,分别将学习率降低至0.000 1,总训练迭代次数为100 000。为了证明所设计的网络可以完成对数据集的学习,将训练中的Loss数据收集起来,并利用matlabplot库将数据可视化,最终得到如图7所示的Loss变化曲线。
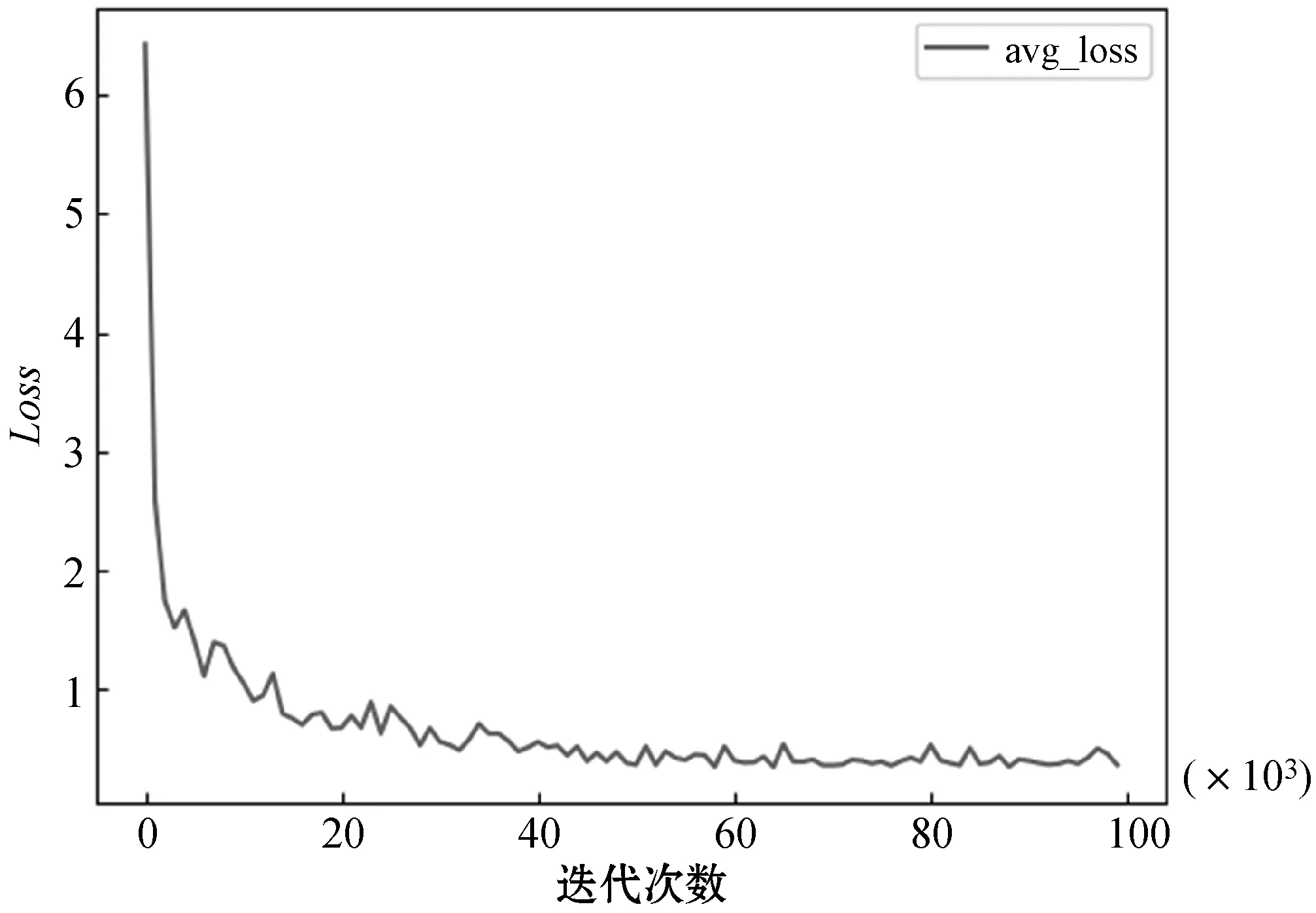
图7 Lw-YOLO网络训练中Loss变化曲线
可以看出,Lw-YOLO网络在训练过程中可以快速收敛,在40 000次后曲线趋于平稳,Loss曲线变化趋势正常,最后的Loss值下降到0.4左右。这说明优化得到的Lw-YOLO网络可以学习到数据集中的内容,训练结果比较理想。接下来要对训练过程中产生的多个权重进行选择,选出其中最好的权重文件完成下文的网络对比,因此本文选择的权重为迭代40 000次的权重。
3.3 Lw-YOLO网络测试结果分析
实验一:选取WiderFace的测试集对三种人脸检测模型进行测试,测试结果如表2、表3所示。
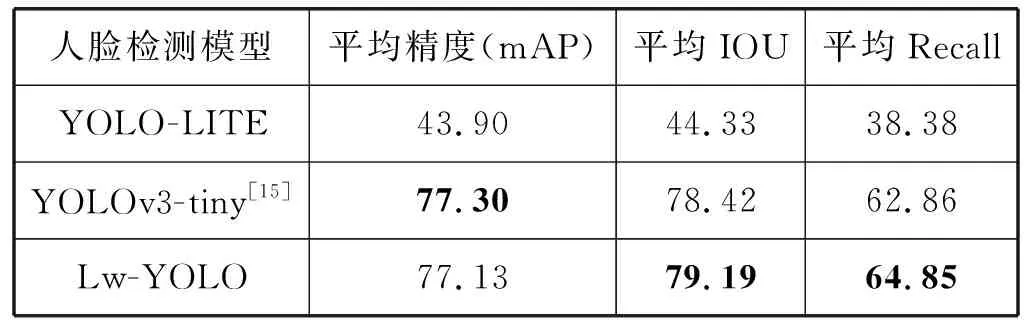
表2 三种人脸检测模型在WiderFace精度测试结果(%)
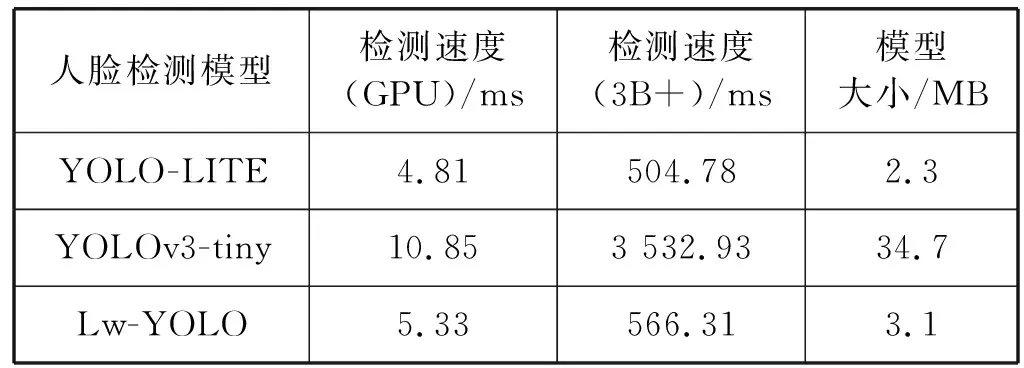
表3 三种人脸检测模型在WiderFace速度测试结果
由表2知,Lw-YOLO人脸检测模型的平均精度与YOLOv3-tiny基本持平,比YOLO-LITE模型高23.22百分点,平均IOU是三者中最高的,同样平均Recall是三者之中最优,说明Lw-YOLO模型检测结果与预设边界框最接近,漏检的概率最小。
在表3中,Lw-YOLO模型较小,只比YOLO-LITE模型大0.8 MB,在GPU和树莓派3B+上的检测速度也与YOLO-LITE模型相近,YOLOv3-tiny模型大小最大,检测速度也最慢。虽然在GPU上三个模型耗时差距并不明显,但是在计算能力有限且无GPU的树莓派3B+上测试时,可以发现Lw-YOLO检测速度几乎是YOLOv3-tiny的1/7。
根据表2、表3可知,改进后的Lw-YOLO人脸检测模型在树莓派3B+上保持检测速度与YOLO-LITE模型相近,而检测精度有较大提高,网络更深,计算参数量却较少,轻量化成效显著,综合性能最佳,更适合嵌入式平台应用。
实验二:在Extended YaleB人脸数据集中选择9种不同角度共252幅人脸图像作为测试图像,衡量三种不同人脸检测模型的性能。
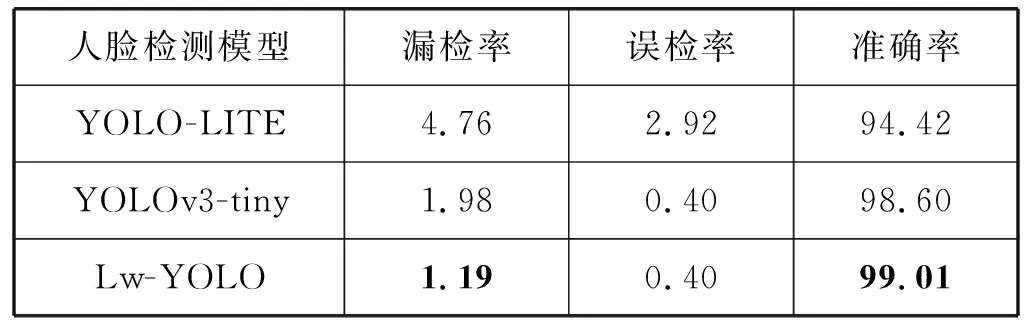
表4 三种人脸检测模型在不同角度下的性能指标(%)
可以看出,三种人脸检测模型在人脸角度一致的前提下,基于Lw-YOLO模型检测准确率最佳比YOLO-LITE模型高4.59百分点,漏检率最低。其次是基于YOLOV3-tiny模型,误检率与Lw-YOLO模型相同,准确率略低于改进的模型。最后是YOLO-LITE模型,漏检个数最多,准确率最低。实验结果表明,基于Lw-YOLO人脸检测模型相较于原始模型,检测性能有明显的提升,对不同角度鲁棒性最强。三种模型对不同角度检测效果如图8-图10所示。

(a) 仰视30度人脸(b) 俯视30度人脸(c) 侧面45度人脸图8 基于不同角度的YOLO-LITE人脸检测方法效果示例

(a) 仰视30度人脸(b) 俯视30度人脸(c) 侧面45度人脸图9 基于不同角度的YOLOv3-tiny人脸检测方法效果示例

(a) 仰视30度人脸(b) 俯视30度人脸(c) 侧面45度人脸图10 基于不同角度的Lw-YOLO人脸检测方法效果示例
实验三:在Extended YaleB人脸数据集选择64种共1 792幅不同角度光照环境下的正面人脸图像作为测试图像,衡量三种不同人脸检测模型的性能。
如表5所示,三种人脸检测模型在不同角度光照条件下有较好的检测效果,其中基于YOLO-LITE的人脸检测模型在64种光照条件下出现较多的漏检,漏检率比改进的模型高11.94百分点,准确率最低。而改进的Lw-YOLO模型在三者中准确率最高,漏检率和误检率都是最低,表明改进的模型鲁棒性较好,在光照条件不均匀的情况下,检测精度更高。三种模型对不同光照检测效果如图11-图13所示。
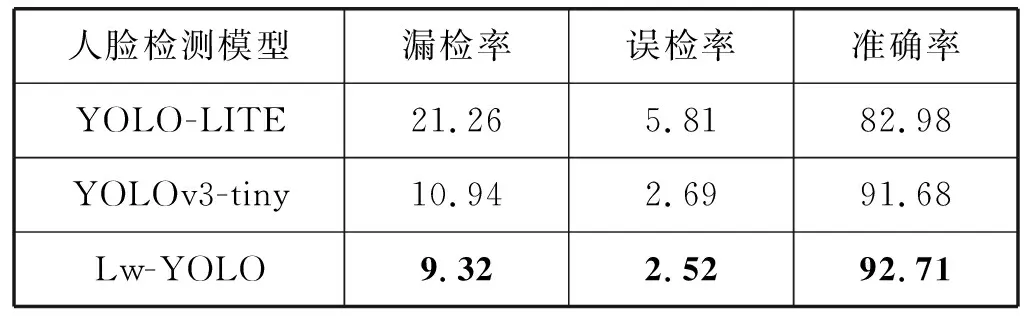
表5 三种人脸检测模型在不同光照角度下的性能指标(%)

(a) 上方45度光照(b) 下方30度光照(c) 侧面95度光照图11 基于不同光照的YOLO-LITE人脸检测方法效果示例

(a) 上方45度光照(b) 下方30度光照(c) 侧面95度光照图12 基于不同光照的YOLOv3-tiny人脸检测方法效果示例

(a) 上方45度光照(b) 下方30度光照(c) 侧面95度光照图13 基于不同光照的Lw-YOLO人脸检测方法效果示例
从上述3组实验结果可知,Lw-YOLO人脸检测方法相较于原始方法,性能有了较大的提升,并且在多角度、不同光照条件下人脸数据集的评测中,基于Lw-YOLO人脸检测模型的鲁棒性、准确性等性能表现综合最优,更适合实际应用场景下的人脸检测。
4 结 语
本文设计一个基于深度可分离的轻量化人脸检测网络,采用深度学习的方法,针对现有神经网络复杂、计算量大的缺点,提出一种解决无GPU嵌入式平台计算能力和内存空间不足的人脸检测网络Lw-YOLO。该网络将传统卷积换成深度可分离卷积,显著降低了网络参数量,提高了嵌入式平台的检测效率。同时利用多个1×1的点卷积提升网络深度,获得更多的特征,最后使用多尺度预测方法提高网络的检测精度。网络在WiderFace数据集的多次迭代训练,选择最优的权重,得到轻量化的人脸检测网络,实验结果表明该网络在树莓派3B+嵌入式平台上进行人脸检测,具有良好的检测效果,在检测速度和精度上大大提升,对实际场景下的人脸检测有较好的应用价值。
猜你喜欢
儿童时代·幸福宝宝(2021年11期)2021-12-21
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
小学科学(学生版)(2021年4期)2021-07-23
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
现代装饰(2020年4期)2020-05-20
动漫星空(2018年9期)2018-10-26
证券法律评论(2018年0期)2018-08-31
太空探索(2016年5期)2016-07-12
时代英语·高三(2014年5期)2014-08-26
