
基于用电大数据的低压电力客户电费异常识别模型
2023-01-30 13:41:58何小宇董礼贤
微型电脑应用 2022年12期
何小宇, 董礼贤
(广东电网有限公司广州供电局, 广东, 广州 510000)
0 引言
供电局采集用电数据数量较多,广州电网每日采集数据高达百万余条。随着数据规模飞速增长,由于设备故障和电网波动等原因,导致用户电费异常数据时有发生,影响广东电网公司的运营管理[1]。在电力市场竞争日益加剧的现状下,部分低压电力用户为了自身利益采用一些恶劣手段窃取电源、拖欠电费等,严重影响了电力企业的正常工作运行,增加电力企业排查电量的成本[2]。为此,该领域相关研究人员进行了大量的研究。
文献[3]提出通过模糊聚类和孤立森林的用电数据异常检测。该方法针对电量数据规模、维度等,对电量数据进行预处理。通过模糊聚类算法,将电网中规模较大的异常数据进行分类,并通过孤立森林算法对异常用电量进行检测,分析电量异常点的产生原因,进而实现用户电费异常的识别。该方法可有效识别用户电力数据中的异常点,但该方法针对异常电量数据集中的数据点规模较小,不利于大规模异常点电费的识别。文献[4]提出通过熵序列的智能电网数据流异常状态监测方法,对用户电费异常情况进行识别。该方法通过采集智能电网中的相关数据流,确定一个窗口,对窗口的强度进行分析,通过其强度确定数据的异常情况。将判断后得到的异常电量数据作为研究样本,对其进行实时监测,完成用户电费的识别。该方法可有效判定用户电量是否异常,但对此类数据进行检测易出现以偏概全的问题,导致识别的误差较大。文献[5]提出基于三次指数平滑模型与DBSCAN聚类的电量数据异常检测方法,通过该方法检测电力用户电费异常情况。该方法首先采用三次指数平滑模型采集用户历史电费数据,将实际采集的电量值和预测值相减得到残差值,最后借助DBSCAN密度聚类算法将残差项进行识别,完成电费异常行为的识别。该方法可有效提升电量异常数据检测的精度,但操作过程中抗干扰能力较差,需要进一步改进。
为了解决传统方法中存在的不足,本文以广东电网有限公司广州供电局为例,设计基于用电大数据的低压电力客户电费异常识别模型。通过对用电大数据挖掘,为电费识别提供大量有效信息支撑,提高广州低压电力客户电费异常识别精度。实验结果表明:采用本文所提方法可有效识别用户电费异常情况,且识别速度较快。
1 低压电力客户电费异常识别模型设计
1.1 低压电力用户用电大数据的获取
为实现低压电力客户电费异常的识别,挖掘用电大数据中低压电力客户用电数据。由于用电数据量规模较大,故仅保留负荷数据和数据采集等字段,数据集字段详情,如表1 所示。
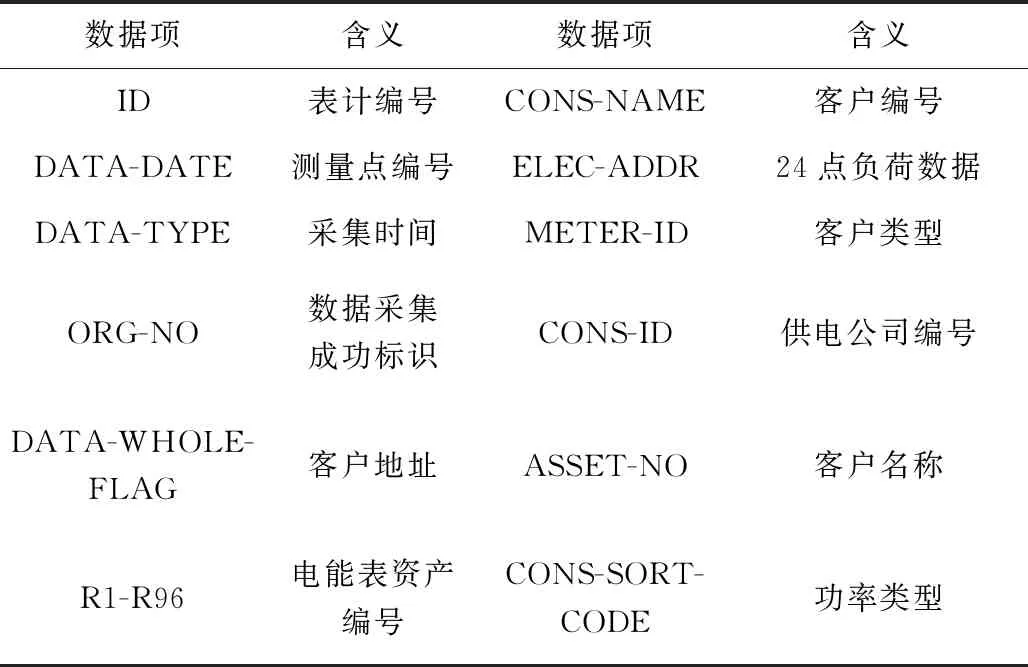
表1 低压电力客户用电大数据集
通过供电局负控终端采集的负荷数据,获取供电局日负荷数据,绘制n条日负荷曲线,将负荷数据精简为24点负荷数据,得到n×24阶初始负荷曲线矩阵,构成用电大数据集。
删除数据集中冗余数据,将客户名称和采集时间作为唯一确定的数据记录,删除具有相同记录的多余数据。判断缺失数据的严重程度,将日负荷曲线缺失20%的读数点,连续缺失2个以上的连续读数点定义为数据集数据严重缺失。采用多阶拉格朗日内插法,对日负荷曲线的缺失值进行修补[6],即:
(1)
式中,P为日负荷曲线的修补负荷值,m1为拉格朗日前推期数,m2为后推期数,t为负荷数据缺失时刻,Wt为t时刻时,n×24阶初始负荷曲线矩阵中的有效日负荷曲线[7]。
1.2 低压电力客户电费异常识别特征参数
由于低压电力客户用电数据集中数据较多,需要确定其中重要异常数据,获取用电数据关键特征。对基础数据进行降维,挖掘数据集中用电数据与电费识别的关联关系。利用流聚类技术设置阈值,选取用电数据集中初始簇的中心,计算用电数据到簇中心点的距离,选取小于阈值且靠近簇中心的用电数据作为数据集族簇,对其进行更新迭代[8]。更新族簇的公式为
(2)
式中,ci+1为更新迭代后的数据集族簇,i为更新迭代次数,ci为前一次计算得到的初始族簇,ni为当前批次加入族簇的点数量,ki为已经分配到族簇的点数,hi为当前批次的族簇中心,a为用电数据更新迭代的衰减因子。
通过式(2),得到低压电力客户数据集中最好的聚类结果。选取关联关系最大的用电数据点。聚集阈值内数据点到更新族簇,采用平方和误差最小函数,获得具有关联关系的目标函数,对目标函数进行更新,直到目标函数收敛。目标函数为
(3)
式中,E代表具有关联关系的目标函数,Q为数据集X中各个数据点,j为族簇的个数,γ为数据集中族簇的总数量,bj为j个族簇的平均值,V为特征参数的平方误差和[9]。将含有关联关系的集合E放于n维空间中,使每个维度空间具有完整的用电数据集,从中选取1个最近邻点,如图1所示。

图1 用电特征数据选择
图1中,对4个最近邻点进行加权,获得与电费识别关联关系最大的数据点,将数据值补充到n维空间的原点位置,得到最大关联特征用电数据。
1.3 低压电力客户电费异常识别模型构建
在低压用电客户电费异常识别中,对n维空间中所有电力特征参数进行处理。设用电特征参数总数量为α,每个用电参数在识别时间点β得到一个时间序列,则模型运行参数构成的时间序列矩阵Oα×β为
(4)
当时间序列矩阵中行数α小于β时,按维度空间的顺序拆分用电特征参数的时间序列,逐行叠加生成高维随机矩阵,将矩阵各列作为提取维数的单个个体,将高维随机矩阵转换为样本协方差矩阵。利用最大似然估计法,近似估计所得矩阵,将样本协方差矩阵中特征值映射到复数域,得到用电数据特征值分布规律[10],为
(5)
式中,M为样本协方差矩阵的行数,N为矩阵列数,d为矩阵中满足均值的复随机变量,σ2为矩阵方差,f为模型运行参数特征值的分布规律。
针对用电数据特征值分布规律,确定用电数据典型特征,需要满足以下约束条件,即:
(6)
式中,si代表用电特征值中的典型特征量。
当用电数据满足上述约束条件后,将用电特征量匹配后剩余的数据根据式(7)进行分解,得到用电特征量分布状态为
Y=〈Yl,si〉sil+Yl+1
(7)
式中,Yl代表用电特征匹配后余下数据,经过l+1次分解后得到的数据特征分布状态。此时,当f符合MP算法时,低压电力客户电费未发生异常,直接输出用电数据集中客户用电情况。当f不符合MP算法时,判断客户电费发生异常,即低压电力客户电费异常识别模型为
(8)
式中,y为特征值谱分布规律,L为数据集中的随机矩阵个数,z为协方差矩阵复数域的映射值。
2 仿真分析
2.1 仿真环境及参数
仿真环境配置为CentOS 6.5-x86-64,Spark 1.6.3,利用Spark单机模式与Spark+Streaming集群环境,通过Hadoop集群对客户进行Map和Reduce操作,使低压电力客户用电大数据横向聚类。仿真数据为广州低压电力客户2020年1月至2020年7月的日用电数据,总数据量为101 500条,用电量单位为兆瓦。仿真以30 min为时隙,对用电时间进行切割,日平均荷载情况如图2所示。

图2 日负荷总数据量
按照图2负荷变化曲线对低压用电客户进行分组,设置8:00~21:00为客户用电高峰段,电价为1.289 7元/kW·h,21:00~24:00为客户用电平段,电价为0.768 9元/kW·h,24:00~8:00为客户用电低谷段,电价为0.463 8元/kW·h。用电时间切割后,获得48个时间片的数据集。
2.2 结果分析
在Spark集群环境下,设置客户用电负载变量为6个时间片,待识别的用电数据为1 000条/s,采用3组识别模型:本文模型(A组识别模型)、基于模糊聚类和孤立森林的识别模型(B组识别模型)以及智能电网大数据异常状态识别模型(C组识别模型),分别接收1 000条用电数据,并对接收的数据进行聚类处理,分析3组识别方法的识别速率,结果如图3所示。
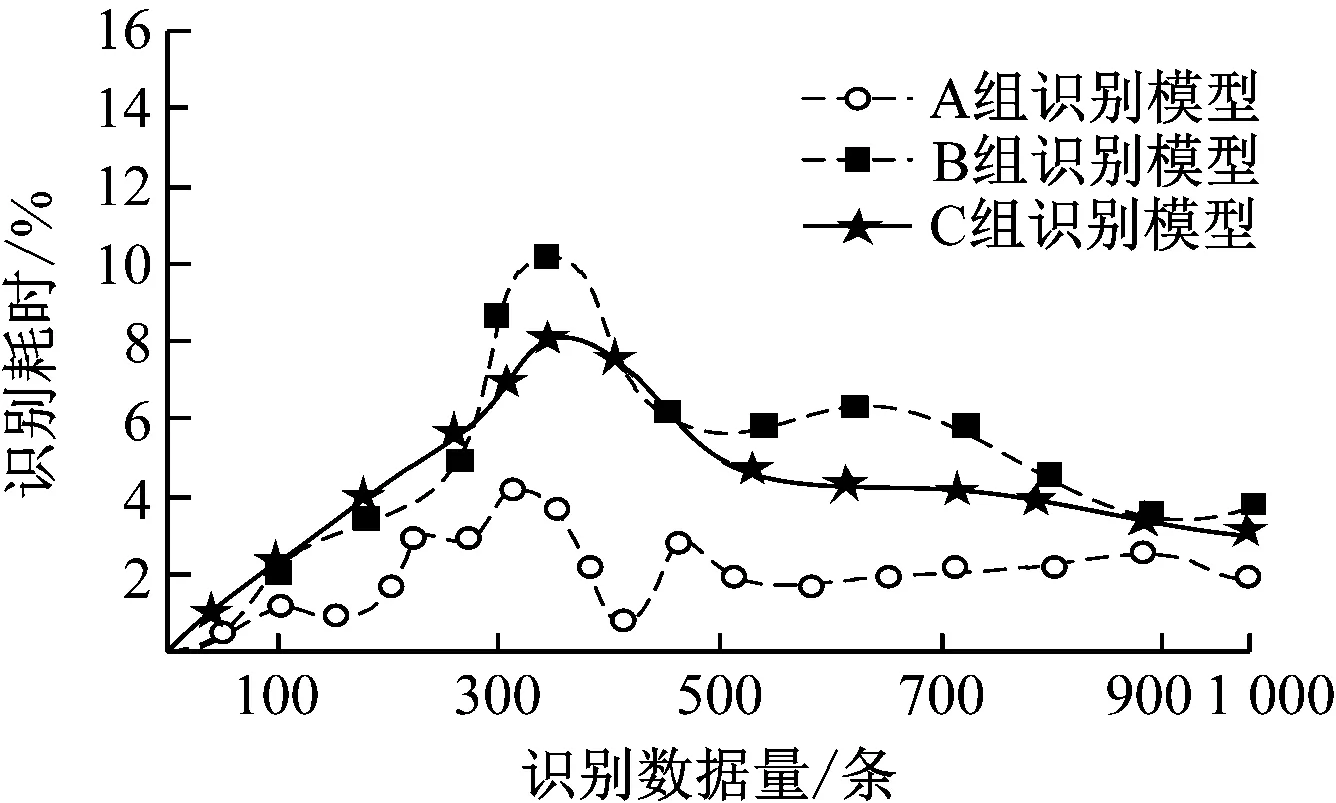
图3 不同识别模型的识别耗时对比
分析图3可知,采用3种模型对样本用电数据识别的耗时不同。其中,本文所提模型的识别耗时较短,约为0.1 s,其他2种识别模型的最短识别耗时分别约为3 s 和4 s,相比之下本文所提方法的识别速度最快。
实验分析3组识别模型对用户电费异常识别的精度,结果如图4 所示。

图4 不同识别模型的识别误差对比
分析图4可以看出,随着识别数据量的改变,3种识别模型的识别误差随之发生改变。其中,本文所提模型的识别误差最高约为2.1%,而其他2种模型的识别误差始终高于本文所提模型。这是由于本文所提模型采用平方和误差最小函数确定具有最大关联特征的用电数据;分析用电数据特征值分布规律,降低异常电费数据识别误差。
3 总结
本文设计基于用电大数据的低压电力客户电费异常识别模型,通过对低压用电客户的用电数据特征进行获取,采用平方和误差最小函数确定具有最大关联特征的用电数据;通过对n维空间中所有电力特征参数的处理,构建低压电力客户电费异常识别模型。本文所提模型对用电数据的识别耗时较短,识别误差较低,对低压电力客户电费异常识别具有一定意义。
猜你喜欢
经营者(2023年10期)2023-11-02 13:24:48
吉林电力(2022年1期)2022-11-10 09:20:40
学苑创造·B版(2022年9期)2022-05-30 18:16:10
中国化肥信息(2021年12期)2021-04-19 12:25:22
中学生数理化·中考版(2020年12期)2021-01-18 06:59:44
小学生必读(中年级版)(2018年10期)2019-01-04 05:11:10
四川水力发电(2018年4期)2018-03-25 14:04:35
中华建设(2017年3期)2017-06-08 05:49:29
铁道通信信号(2016年8期)2016-06-01 12:10:21
财经界(学术版)(2015年20期)2015-12-23 09:20:14
