
基于序列到序列预训练语言模型的楹联自动生成算法
2023-01-30 13:22乔露
微型电脑应用 2022年12期
乔露
(西北大学现代学院,文学院, 陕西, 西安 710130)
0 引言
楹联,是中华传统文化的瑰宝。楹联和楹联文化出现在人们生活的方方面面。作为楹联文化的活动形式之一,楹联应对是一种受到大众喜爱的游戏。其形式为出题者给出上联,应对者根据上联给出适当的下联。要求下联与给定的上联在文字上整齐对仗、意义上对照呼应、音律上平仄有节奏。
楹联应对在文字、意义以及音律上的要求,使楹联艺术具有形式美、意义美及声律美的审美体验的同时,也为楹联艺术在年轻人中传播以及初学者的学习,带来了一定阻碍。如果能开发一套楹联应对的算法系统,输入上联,机器自动给出符合要求的下联,则可以帮助楹联文化的初学者、爱好者更好地学习、交流楹联文化,从而对中国的传统文化进行有效传承。因此,本文在已有工作的基础上,对现有楹联生成算法进行了研究,并提出了基于序列到序列预训练神经网络语言模型的楹联自动生成算法。
1 相关研究
关于自动楹联生成,研究者尝试了多种方法来完成该任务。文献[1]提出了一种统计与规则相结合的古文对联应对模型,该方法使用统计方法建立软规则模型,同时在候选搜索阶段通过硬规则排除不合理的解。文献[2]提出了一种基于统计机器翻译的对联生成方法,这一方法为之后的研究者提供了新的思路。
近年来,随着深度学习技术的发展,神经网络技术在自然语言处理领域的多种任务上都取得了成功。相关的研究者也开始尝试将神经网络技术用于对联生成任务。文献[3-5]研究了基于循环神经网络和基于注意力机制的神经网络对联生成系统。文献[6]提出了一种基于多任务的古诗和对联自动生成方法,该方法通过同时学习古诗和对联生成任务,使两个任务的部分数据和参数共享,从而提升最终的生成效果。
2 方法介绍
基于神经网络的对联生成模型,相对传统基于规则和统计的方法,效果上有了明显提升。由于自然语言本身语法、语义上的复杂性,加上楹联中上下联需要满足文字、音律以及意义上的要求,机器自动生成的楹联效果仍难以达到高水平的楹联爱好者的水平。尤其是当楹联中涉及历史典故及世界知识时,利用少量的楹联数据训练的神经网络模型,通常难以生成出理想的下联。
为了解决这一问题,本文提出了一种基于预训练神经网络语言模型的楹联自动生成方法。核心思路:首先,利用预先在大规模语料上预训练语言模型学习到汉语言的语义、语法和世界知识;然后,通过在楹联数据上对预训练的模型进行微调,让模型在预训练学习到的知识基础之上,进一步学习生成符合楹联标准的下联。实验分析表明,本文提出的方法在效果上优于已有模型。
2.1 理论基础
2.1.1 Transformer
Transformer 是一种完全基于自注意力机制的神经网络结构,在文献[7]中首次被提出,并首先在机器翻译任务中被验证有效。为了区分原始序列位置信息,在输入层增加位置嵌入来建模词在句子中的位置信息。相对于传统的循环神经网络存在的时序依赖问题,Transformer 能够更好地并行计算,同时在多个任务上被证明具有更好的效果。
2.2 语言模型
在自然语言中,语言模型用于建模词序列概率分布。语言模型能够刻画词语与其上下文的关系,在多种自然语言处理任务,特别是将生成文本作为输出的任务上,语言模型被广泛应用。例如:语音识别、光学字符识别、输入法、信息检索、机器翻译等。常见的语言模型主要有基于统计的n元语法(n-gram)语言模型,以及基于神经网络的语言模型。
2.2.1 基于统计的n-gram语言模型
由于语言模型的目标是计算词序列出现的概率,在理想情况下,可以对所有出现过的词序列进行频率统计,并据此估出任意词序列出现的概率。但实践上我们不可能得到所有真实出现过的词序列机器频率,大多数可能存在的词序列都不能被观察到。因此,这种方法实际不可行。
2.2.2 神经网络语言模型
与基于统计的n-gram语言模型不同,基于神经网络的语言模型使用分散式的连续词向量来表示离散的词汇。通过神经网络将这些词向量进行非线性组合来建模。由于词向量的参数量大小与|V|呈线性关系,上层神经网络的参数量可以看做常数,因此这种方法可以一定程度避免维度灾难。正是由于具有该优势,基于神经网络的语言模型大幅提升了传统语言模型的性能,并取得了快速发展。
文献[8]首次提出了一种基于前馈神经网络的语言模型。该方法利用n-gram的思想,通过神经网络来将词语映射到低维连续向量空间中,从而提升基于统计的n-gram语言模型效果。此后循环神经网络语言模型、长短时记忆单元语言模型相继被提出。
3 方法设计
本章节介绍基于预训练神经网络语言模型的楹联自动生成方法设计方案。在任务上,该方法将楹联生成转换成一个序列到序列的文本生成问题,输入“上联”自递归的生成出“下联”。与已有的神经网络模型不同,本方法先在大规模无监督中文文本上对模型进行预训练,然后再在楹联生成数据集上进行微调,并得到最终用于楹联生成的模型结果。整体流程如图1所示。

图1 楹联自动生成流程图
3.1 模型结构及损失函数
我们采用序列到序列生成的模型范式,使用Transformer来作为编码器与解码器的基础神经网络模块,其中,编码器和解码器各由6层Transformer组成。整体的模型结构如图2所示。在编码时通过Transformer的双向自注意力机制对输入序列进行编码,得到每个位置的向量表示:

图2 楹联模型结构图
Henc=Encoder(X)=[h1,h2,…,hn]
(1)
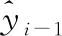
(2)
(3)
其中,MLP为多层感知机。训练阶段,模型的损失函数为
(4)
3.2 预训练
文献[9]提出的 ELMO将语言模型当作预训练任务,并证明经过预训练的模型在下游任务微调后,能表现出更好的泛化性能。此后BERT、GPT等预训练模型不断被提出。本文采用降噪序列到序列方法对楹联模型进行预训练。
在预训练阶段,模型需要学习如何恢复被破坏的文本片段,即输入经过人为破坏的文本,输入该文本破坏前的原始文本。具体的破坏方式有遮挡、删除、填充、句子重排及文本旋转等。在预训练阶段,模型需要学习到一定的知识,才能使训练损失降低。
3.3 微调
在大规模中文文本上预训练之后,模型还不具备进行楹联生成的能力,需要进一步在楹联数据集上进行序列到序列任务微调。微调阶段,模型学习的目标只有序列到序列的生成任务目标,没有破坏文档重建的目标。
具体来说,微调阶段将上联作为输入序列X=[x1,x2,…,xn],将下联作为Y=[y1,y2,…,ym]。由于楹联要求上下联字数必须相等,实际结果中m=n。训练的损失函数形式为式(5):
(5)
4 实验分析
4.1 数据集
实验采用网络公开可访问的楹联数据集,在此基础上利用敏感词词库对数据进行了过滤,删除了低俗或敏感的内容。进行实验前,本文对该数据集的长度情况进行了分析,主要统计信息如表1所示。
本文还对数据集中最常见的汉字进行了分析,发现上联与下联的常见字频率分布有一定差别,而训练集与测试集的整体分布趋势较为一致。详细结论如表2所示(括号内数字为该字出现的次数)。
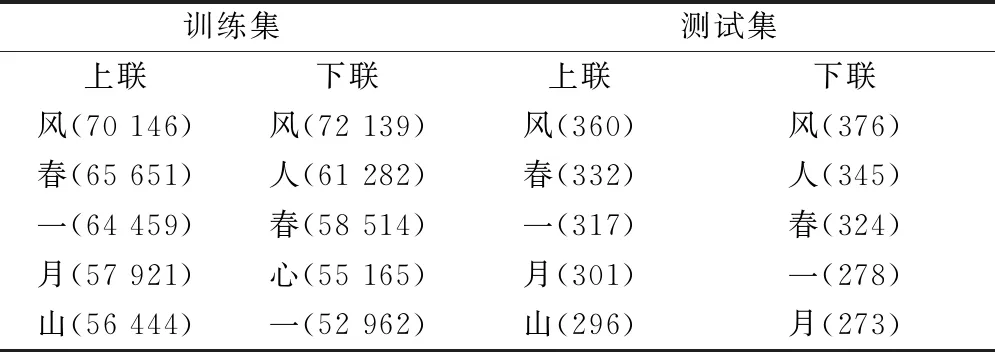
表2 楹联生成数据集常见汉字分析
4.2 评估方法
① 基于BLEU值进行量化分析。该方法优点是能够通过机器自动对大量模型生成的下联与原始数据中人工撰写的下联进行对比评估,缺点是不能体现生成结果是否合理;② 人工评估。对不同方法生成结果,寻找相关专业的志愿者进行人工评估。其优点是能够对生成结果进行更准确的评估,缺点是成本较高,难以进行大规模的评估。本文从句法和语义两个维度来判断一副楹联的好坏,每个维度打分范围为1~5分,得分越高越好。
4.3 实验结果
本文对现有基于长短时记忆元的自动楹联生成方法与本文提出方法进行了对比。从表3可以看到,在BLEU-1、BLEU-2及BLEU-3上,本文提出方法均优于基线方法。

表3 BLEU值得分结果
另外,我们邀请了13位文学专业学者,按照句法和语义两个维度,对基线方法和本文提出的方法生成的楹联结果随机抽取20对,进行了进一步人工评估。评估结果如表4所示。从表4可以看到,在句法和语义上,本文提出方法的效果显著优于基线方法。

表4 人工评估得分结果
4.4 样例分析
为了进一步研究基于预训练的方法是否能够学习到一定历史典故及相关知识,本文对测试数据中含有历史典故的对联进行了分析。从表5可以看到,本文提出的方法相对已有方法,能够更好地学习到历史典故知识。
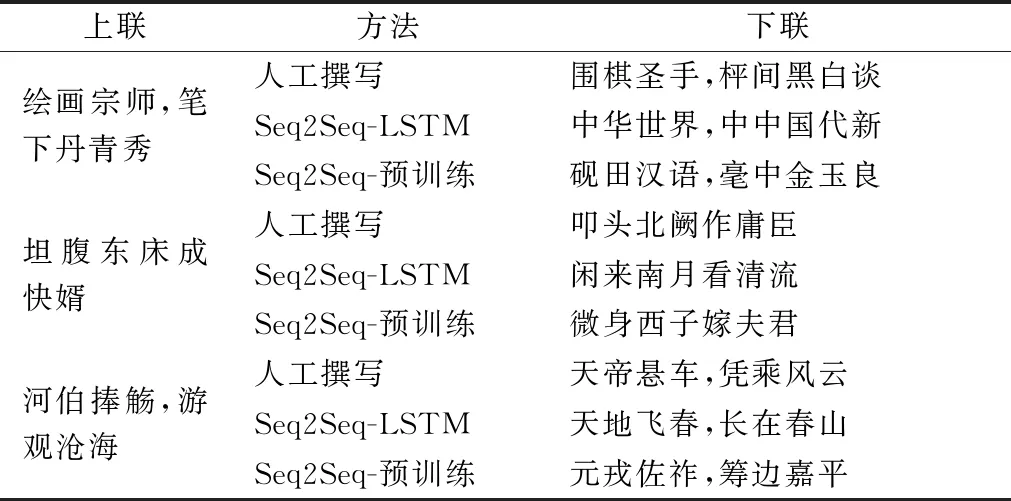
表5 人工评估得分结果
5 总结
本文对现有的楹联自动生成算法进行了研究,提出了一种基于序列到序列预训练神经网络语言模型的楹联自动生成算法。实验结果与人工评测表明,基于预训练模型的楹联生成算法在测试数据集上具有更好的效果。同时,进一步分析发现,该方法能够一定程度上学习到历史典故及世界知识,生成出更接近人类表达的楹联下联。
楹联作为中国民间文学的一种重要形式,却在当今社会的发展中陷入了发展困境。基于此,借助于算法优势致力于让民间文学主体在当下青年群体中“复活”,表现其国际化、本土化、审美化、现代化、人文化的多元化应用形态。
猜你喜欢
电子制作(2019年19期)2019-11-23
电子制作(2019年24期)2019-02-23
对联(2018年2期)2018-05-28
作文周刊·七年级读写版(2017年1期)2017-07-12
重型机械(2016年1期)2016-03-01
源流(2015年2期)2015-03-18
海军航空大学学报(2015年4期)2015-02-27
小资CHIC!ELEGANCE(2015年2期)2015-01-27
对联(2011年24期)2011-09-19
对联(2011年6期)2011-09-18
