
BERT蒙古文词向量学习
2023-01-29 13:16王玉荣李艳玲
计算机工程与应用 2023年2期
王玉荣,林 民,李艳玲
内蒙古师范大学 计算机科学技术学院,呼和浩特010022
词向量(word embedding)是一种词的特征表示,能表达文本的语法、语义信息,是很多自然语言处理任务的基础步骤[1],如命名实体识别、机器翻译、信息检索等。以Word2Vec[2]为代表的蒙古文词向量技术是一直以来最常用的文本表示方法,它能捕获隐藏在单词上下文的语法、语义信息。但它只考虑固定大小窗口内的单词并且获得的词向量具有聚义现象,这种上下文无关的静态表示方法仅学习了文本的浅层表征,不能表达一词多义,并给其后的自然语言处理任务带来的提升非常有限。2018年底BERT(bidirectional encoder representations from transformers,BERT)[3]预训练模型的出现,解决了一词多义的问题。BERT模型的突出优势是通过海量语料的训练,得到了一组适用性十分广泛的词向量,同时还能在具体任务中进一步动态优化,生成上下文语境敏感的动态词向量,解决了以往Word2Vec、Glove等模型的聚义问题,在并行处理能力方面也优于之前的ELMo(embedings from language models)[4]等预训练模型。但是,BERT预训练模型的词表中没有传统蒙古文的单词,须通过有效的方法学习蒙古文词向量。本文将传统蒙古文转换为拉丁蒙古文输入到多语言BERT预训练模型中,将其精调(fine-tuning)过程与条件随机场(conditional random fields,CRF)[5]相结合,通过有效的方法融合在下游任务中训练的子词级向量,实现动态的蒙古文词向量表示。通过计算同一上下文中语义相近词向量之间的距离,表明了词向量对聚义词具有良好的区分性,采用K-means聚类算法对蒙古文词语进行聚类分析,表明学出的词向量更接近词义的真实分布,最后在嵌入式主题词挖掘任务中进行了验证。
1 相关工作
Bengio等[6]在2003年提出了神经网络语言模型(neural network language model,NNLM),NNLM在学习语言模型的同时可以得到词向量,此后越来越多的学者开始研究预训练模型,以提高词向量的语义表达能力。曹宜超[7]采用Word2Vec模型训练蒙古文词向量,利用跨语言词向量对齐的方法实现蒙汉神经机器翻译系统。但该方法中的蒙古文词向量是静态的,故很难解决词汇的聚义现象。樊文婷等[8]将词性特征融入到词向量表示中,来丰富词向量的语义特征。王炜华[9]利用循环神经网络(recurrent neural network,RNN)学习蒙古文词向量,应用于蒙古文命名实体识别,并得到了不错的效果。但RNN语言模型也没能兼顾语言的两个主要特性:第一,语句内局部语法正确性和语句间长距离的语义连贯性;第二,获得的词向量具有聚义现象,将处于不同语境的词汇多种语义综合表示成一个向量,不能表达一词多义。针对双向长短时记忆网络(bidirectional long short-term memory,BiLSTM)模型的输入层中蒙古文词素向量和字符级向量间存在信息表达能力不均衡的现象,熊玉竹[10]使用注意力机制动态组合两种特征向量,增强模型输入层的信息表达能力。朝汗[11]为了在BERT上学习到动态蒙古文词向量,将传统蒙古文转换为西里尔文蒙古文作为模型输入,但两种语言的机器翻译过程不能完全保留蒙古文语法结构,人工翻译又需要消耗大量时间和精力。
通过对蒙古文词向量训练任务的相关工作进行分析,可以发现,近年来学出的蒙古文词向量大都仅学出词的表层特征,是一种静态的表示方法,或没有使用预训练模型每次重新训练词向量以及通过翻译语料实现动态的蒙古文词向量。因此本文提出,利用少量的语料精调多语言BERT预训练模型获得动态的蒙古文词向量表示,解决词汇聚义问题。
2 基于BERT-CRF的蒙古文词向量学习算法
BERT模型分词器将不在词汇表中的单词分解为词汇表中包含的尽可能大的子词。例如,“embeddings”虽然不在词汇表中,但没有将它标记为未知词汇,而是分解为四个子词['em'、'##bed'、'##ding'、'##s'],这些子词将保留原单词的上下文含义。传统蒙古文所有单词都不在BERT的词汇表中,需要将其转换成拉丁蒙古文并重新融合这些子词。为了使融合后的单词更具有真实的语法、语义信息,并解决蒙古文没有大量人工标注的数据问题,以标记子词在单词中的位置(词首、词中、词尾、单个词)作为下游任务训练蒙古文词向量。
2.1 模型
模型的整体结构如图1所示。首先将BERT分词器分解的子词输入到BERT模型中,经过深层次的上下文语义编码,词向量被映射成词向量矩阵,然后利用CRF维特比算法解码输出标签序列的概率,概率最大的标签作为子词的分类结果(子词分为词首、词中、词尾、独立单词)。模型的输入如图2所示,是由词向量、句向量、位置向量3部分组成。

图1 模型整体结构Fig.1 Overall structure of model

图2 模型的输入Fig.2 Input of model
2.1.1 BERT模型
BERT模型由12个双向Transformer[12]编码器组成,有768个隐藏层,其目的是融合词向量两侧上下文的信息。为了感知模型在不同位置的注意力能力,采用多头注意力模式[13],如公式(1)所示:

其中Q、K、V是输入的子词向量矩阵,将子词向量矩阵输入到注意力机制中得到不同位置的信息[13]。
由于Transformer编码器舍弃了循环神经网络的循环式网络结构,所以无法捕捉序列信息,而序列信息又代表了全局的结构,因此采用序列信息的相对或绝对位置信息来计算序列信息[14],位置信息计算公式如下:

其中,p表示单词在句子中的位置,取值从0到句子的最大长度,i表示词向量的某一维度,dmodel表示每个子词的位置维度,dmodel=512。每个单词的位置信息仅和词向量维度和位置有关。
2.1.2 CRF序列标注模块
CRF常被用于词性标注、分词、命名实体识别等自然语言处理领域中[15],CRF层通过对预测标签添加约束,利用已知标签信息判断当前的标签,如子词标签“B”的下一个子词对应的标签应该是“M”或“E”。CRF还能在训练过程中从数据集中学习到某些约束,比如子词中第一个子词的标签应该是“B”或“S”。
CRF的输入特征序列X=(x1,x2,…,xn),经过特征提取得到输出矩阵Pn×k=(p1,p2,…,pn),其中n为词的个数,k为标签的个数,Pij表示第i个词的第j个标签的分数,对应的预测序列Y=(y1,y2,…,yn),定义它的评估函数公式如公式(4)所示[15]:
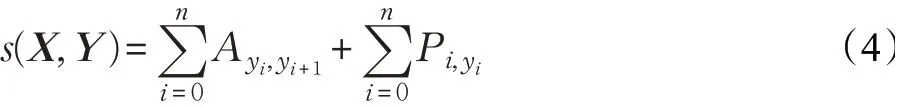
其中,Aij是i标签转移到j标签的得分,整个序列的分值是各位置分值之和,每个位置的分值由两部分组成,一部分是CRF的转移分数矩阵A,另一部分是特征提取模块的输出矩阵P[15]。
CRF模型在做预测时,利用动态规划算法中的维特比算法解码输出标签序列概率,得到子词的分类标签结果,如公式(5)所示:

其中,Yr为真实标注数据序列,Y*是预测标签,取所有预测标签结果中的最大值。
2.2 融合方法
蒙古文单词向量是通过融合子词向量得到的,本文提出全子词平均和取最后一子词向量两种融合方法。设蒙古文单词向量为W=(w1,w2,…,wn),其中wi表示某个单词的第i个子词的向量。全子词向量平均是,BERT分词器进行单词切分后,在学习蒙古文单词时,求BERT同一编码层一个单词的所有子词向量平均值作为整个单词的词向量值,如公式(6)所示。同样,取最后子词向量是求BERT分词器切分单词的同一编码层中该单词的所有子词的最后一子词向量作为整个单词的向量值,如公式(7)所示。

3 实验
实验使用的操作系统是Centos7.5,预训练模型是区分大小写的多语言BERT(multilingual BERT,Multi-BERT),编程语言是python 3.6,实验硬件环境配置如表1所示。

表1 硬件配置表Table 1 Hardware configuration table
3.1 实验数据和数据标注
实验使用的语料库来自于内蒙古师范大学的蒙古文硕博论文的15万句子,覆盖的蒙古文单词有14万。蒙古文语料做了Unicode编码,转换成内蒙古大学拉丁转写形式。文学领域的句子有10万,教育学领域的句子有5万,按照8∶1∶1的比例划分训练集、验证集和测试集,如表2所示。
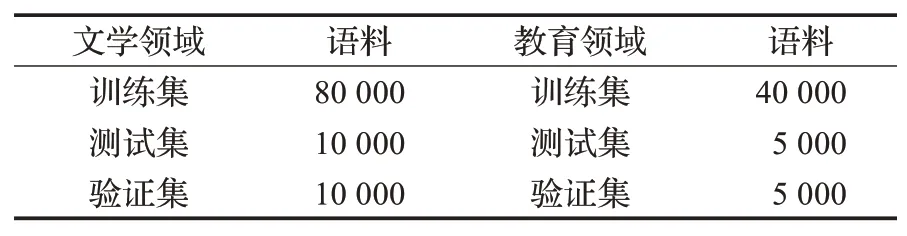
表2 训练语料Table 2 Training corpus
数据标注方式如表3所示,有机器辅助完成,以字母开头的都是B或S,以#开头且后一子词以字母开头都是E,其他都是M。但蒙古文进行分解后的子词有“_”“-”“--”“$”等符号会干扰机器的判断,如“VR_A”的子词是['$','ATV','##N'],机器给的标注是['S','B','E']。
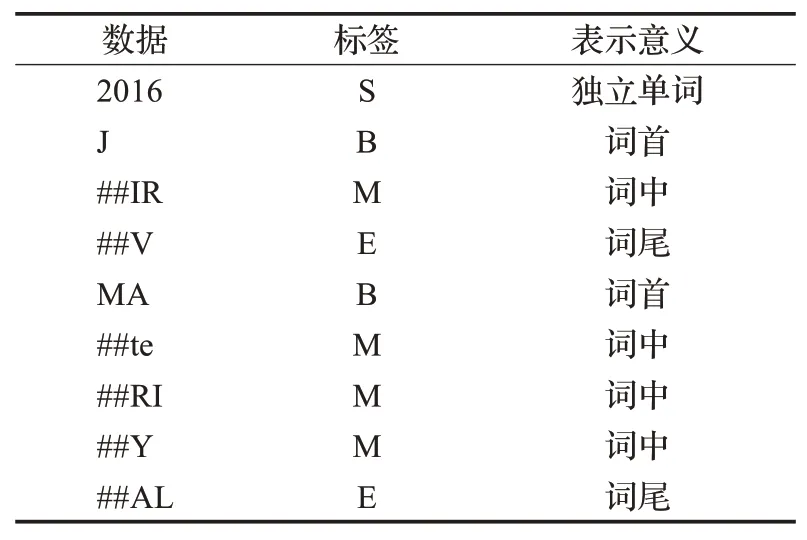
表3 数据标注Table 3 Data annotations
3.2 模型评价指标和词向量质量度量指标
因模型的任务和命名实体识别任务较相似,故采用精确率(P)、召回率(R)、F值做评判指标,其中P、R和F值的计算如公式(8)、(9)、(10):

考虑到词向量模型分布的差异性,采用比较严谨的方法衡量同义词对(A-B)词义相似度,设A和B的距离为s1、A和其他所有词的平均距离为s2、B和其他词的平均距离为s3,同义词词义计算公式如公式(11)所示,两词的距离用向量余弦相似度表示,如公式(12)所示。

此外,利用K-means聚类算法分析蒙古文词向量分布情况。聚类是一个将某方面相似的数据进行分类组织的过程,能够较好地表达内在结构。K-means是基于欧式距离的聚类算法,其认为两个点的距离越近,相似度越大。
3.3 实验结果与对比分析
3.3.1 模型
实验采用的BERT-CRF模型对蒙古文子词的标注准确率较高,F值为97.6%,说明该模型可以实现融合蒙古文子词的任务。经过分析,标注错误的主要原因是:一是模型看到的样本数据较少,对少量的独立词不敏感,如“$”词有两种标注情况“S”和“B”,标注为S时是一个独立的符号,标注为B的时候是蒙古文字母“ᠱᠨ”的拉丁转写,而训练集中常用作是蒙古文字母;另一个是蒙古文连接符“--”和控制符“_”在同一个单词中出现时偶尔不敏感,所以建议应用时做基于词素的切分,即附加成分的切分。
3.3.2 蒙古文同义词词向量相似度对比
BERT模型对于每个子词都有12层长度为768的向量,经过实验发现倒数第一层和倒数第二层的词向量具有竞争力。为体现提出融合方法的有效性,以最大子词向量和首尾子词向量平均作为对比实验。比较蒙古文同义词“ᠪᠷᠶᠯᠳᠦᠭᠨᠨ”(中文:竞赛)和“ᠤᠷᠦᠯᠳᠦᠭᠨᠨ”(中文:比赛)的词向量相似度,如表4所示,两词所在的语境为:ᠪᠭ ᠶᠨᠪᠷᠶᠯᠳᠦᠭᠨᠨ ᠤᠳᠦᠷᠶᠮᠪᠯᠪᠭ ᠶᠶᠨᠤᠷᠦᠯᠳᠦᠭᠨᠨ ᠤᠳᠦᠮᠳᠨᠡᠷᠭᠪᠰᠢᠵᠶᠷᠦᠮᠨᠭᠸᠳᠦᠭᠳᠨᠭᠨᠯᠬᠭᠳᠳᠦᠷᠶᠮᠵᠶᠯᠮᠦᠨ(中文:搏克竞赛规则是搏克比赛中所必须遵循的规定和法则)。第二、第三例子的语境为:美术(ᠤᠷᠨᠨᠵᠶᠷᠦᠭ)教育和身心健康(ᠡᠷᠨᠭᠯᠮᠨᠳᠸ)教育对于学生的创造能力培养和心理培养有多方面的关联。
表4的结果表明,无论是哪种融合方法,BERT模型倒数第一层学到的蒙古文同义词的相似度都高于倒数第二层,并且倒数第一层的全子词向量平均和取最后子词向量两种融合方法得到的同义词词向量相似度也高于取最大子词向量和首尾子词向量平均两种融合方法。

表4 BERT模型不同层不同融合方法得到的同义词词向量相似度比较Table 4 Similarity comparison of synonym word embedding obtained by different fusion methods at different layers in BERT model
为了验证本文学出的词向量对词义的有效解释性和动态性,与Word2Vec模型学出的蒙古文词向量作了对比实验,如表5所示。
表5的结果显示,通过BERT模型学出的同义词相似度平均比Word2Vec模型高,尤其在词根词缀都不同但词义相同的词对上有较大的提升,如“ᠬᠨᠶᠨ”和“ᠭᠭᠬ”。乌云塔那[16]等通过语义、语法检测蒙古文词向量的质量,他们提出动词“ᠶᠨᠪᠭᠳᠨᠭᠸ”和“ᠶᠨᠪᠭᠦᠯᠭᠸ”有相同的词根“ᠶᠨᠪ”,都表示“走”的不同形态,故有相似的概念,从表5的结果可以看出,本文方法学出的蒙古文词向量符合这个逻辑。比较同义词“ᠳᠦᠷᠦᠯ”和“ᠵᠦᠶᠯ”时,BERT学出的蒙古文词向量质量和Word2Vec模型的不分上下,而比较同义词“ᠳᠦᠷᠦᠯ”和“ᠰᠨᠳᠦᠨ”时,BERT模 型 学 出 的 词 向 量 相 似 度 比Word2Vec提升1.89%。“ᠳᠦᠷᠦᠯ”是一个多义词,Word2Vec将多种语义综合表示成一种静态的词向量,没有将每种语义都表示到极致,而BERT模型根据不同的上下文学出了动态的词向量,根据不同的语义学出了不同的词向量。此外,还能解决蒙古文因一些多音词,一种形式对应多种拼写、发音等错写造成的问题。如“ᠤᠯᠨᠨ”的拼写是“OLAN”,但往往输入者会写成“VLAN”,而BERT模型学出的两种拼写的距离非常接近。

表5 不同模型学出的同义词词向量相似度对比Table 5 Comparison of embedding similarity of synonyms learned from different models
3.3.3 词向量K-means聚类分析
通过词频统计选top100内的词进行K-means聚类分析,如图3、图4所示,图4中关键词汇的对应中文如表6、表7所示。可以看出,BERT模型学出的词向量相比Word2Vec有明显的聚类效果,特别是在同领域的关键词上如教育学领域词“ᠪᠭᠰᠢ ᠶᠶᠨ”“ᠰᠦᠷᠦᠭᠴᠶᠳ”“ᠰᠦᠷᠦᠯᠴᠨᠭᠸ”和文学领域词“ᠰᠦᠶᠦᠯ”“ᠵᠦᠬᠶᠨᠯ”“ᠭᠦᠸ ᠡ”等。图4左侧偏教育学领域词、右侧偏文学领域词。

图3 Word2Vec词向量K-means聚类Fig.3 Word2Vec word embedding K-means clustering

图4 BERT词向量K-means聚类Fig.4 BERT word embedding K-means clustering

表6 图4左侧聚类对应文字翻译Table 6 Fig.4 text translation corresponding to left clustering

表7 图4右侧聚类对应文字翻译Table 7 Fig.4 text translation corresponding to right clustering
3.3.4 嵌入式主题词挖掘
将训练出的蒙古文词向量应用到嵌入式主题模型中,在嵌入式主题模型的超参数设置中根据以往的经验以及语料的规模大小,主题个数K取10、20、30、50、80,当K取50时困惑度为最低。如表8所示,主体个数K为50时,选取的部分主题,并列出每个主题高相似度的八个主题词。从表中可以看出,每个主题下的主题词有着语义上的密切联系。

表8 主题-主题词Table 8 Topic-topic words
4 结束语
本文针对现有的蒙古文词向量学习模型是静态的、无法解决词汇聚义等问题,提出利用BERT-CRF模型学习上下文敏感的动态词向量。首先,将拉丁蒙古文输入到BERT模型得到子词级的向量,然后通过CRF解码得到最优序列标记,最后通过子词融合的方式得到蒙古文单词向量。实验证明,仅用15万蒙古文句子二次训练BERT模型得到的蒙古文单词,在向量空间中同义词、多义词的距离相比Word2Vec模型学出的词向量更加接近。通过K-means聚类发现学出的蒙古文单词有明显的词义聚类效果,在主题词挖掘任务中获取的主题词有密切的关联。在下一步的工作中继续扩大语料规模学出更高质量的蒙古文词向量,并从单语的自然语言处理任务迁移到跨语言的自然语言处理任务中,如在跨语言主题词抽取、跨语言信息检索等。
