
基于草地分类的草产量建模与数表编制方法研究
2023-01-29 09:39:32吴恒罗春林刘智军
草原与草坪 2022年5期
吴恒 ,罗春林 ,刘智军
(1.西南林业大学,云南 昆明 650224;2.国家林业和草原局昆明勘察设计院,云南 昆明 650216)
草原是我国重要的生态系统和自然资源,在维护国家生态安全、边疆稳定、民族团结和促进经济社会可持续发展、农牧民增收等方面具有基础性、战略性作用。全国草原调查始于20世纪50年代,以牧草资源调查为主。20世纪80年代初,第1次全国草地资源调查完成,明确了我国草地的类型、面积等状况。20世纪90年代到21世纪初,相继开展了植被生态特征调查及草畜平衡监测[1]。草原调查监测经历了区域性牧草资源调查、全国草地普查和草原生态状况监测等阶段,但长期以来缺少外业调查数表,限制着草原资源的外业调查工作的便捷性[2-3]。因此,开展草产量建模和数表编制,为调查监测提供技术支撑,已显得十分迫切和重要[4-5]。
在碳达峰与碳中和的战略背景下,草原作为陆地碳汇的重要组成部分,及时准确的获取草原植被调查监测数据对实现“双碳”目标的路径调整具有重要的现实意义[6]。传统的草产量调查计算方法是在草原类型面积的统计基础上,分别计算各草地类型样地的单位面积草产量,汇总得出区域内的草产量[7]。随着“3S”技术的融合发展,遥感技术已经运用于草原年度性动态监测实际工作中,采用遥感影像和多光谱无人机数据得到的归一化植被指数[8-9],与其同步的野外调查样地资料相对应,按不同估产区域建立分区估产模型[10],估测各类型单位面积产量[11],进而计算各类型、各区域草产量[12-15]。因而采用历史调查监测数据,建立区域盖度-草产量模型,并通过样地和样方调查数据修正县域草产量模型参数,对提高监测工作效率具有积极作用[16-19]。
1 数据来源和方法
1.1 数据来源
建模数据来源于云南省2010-2019年的草产量遥感监测数据和地面样地调查数据,各草地类型建模样本量分别为暖性灌草丛类770组数据、热性灌草丛类1 409组数据、山地草甸类1 287组数据、高寒草甸类62组数据,盖度、鲜重、干重、可食鲜重和可食干重描述性统计量见表1。模型修正数据来源于南方草地资源生态监测方法研究项目广南试点外业调查数据,合计88个样地、192个样方。按照NY/T2997‐2016《草地分类》[20],广南县山地草甸类、暖性灌草丛类、热性灌草丛类的盖度平均值分别为59%、66%、61%,总鲜重平均值分别为 8 926.1、8 610.0、10 400.2kg/hm2,可食鲜重平均值分别为5 121.1、4 887.0、6 645.4 kg/hm2,总 干 重 平 均 值 分 别 为 2 550.2、2 690.1、3 250.3 kg/hm2,可食干重平均值分别为1 463.1、1 527.0、2 077.2 kg/hm2。
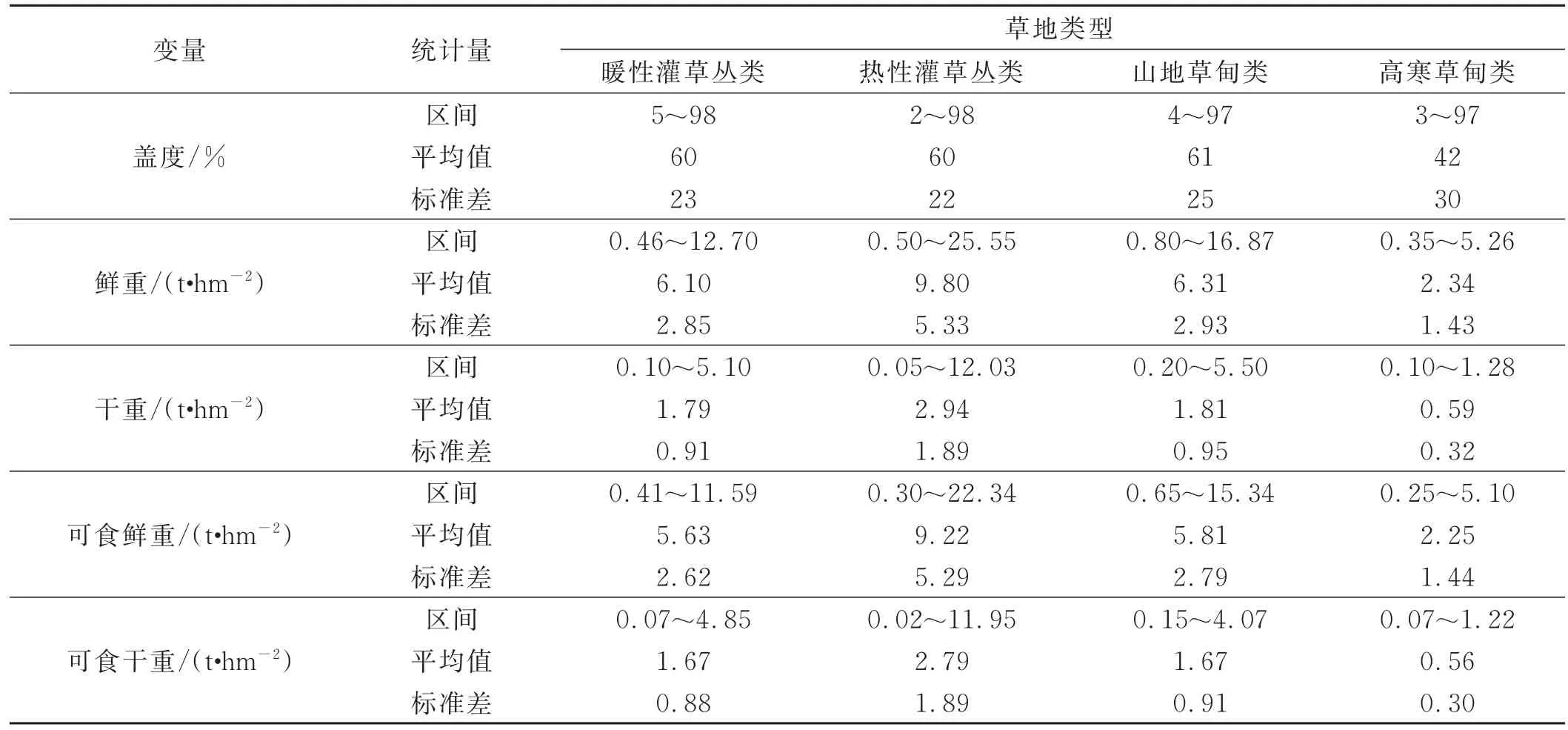
表1 建模样本描述性统计结果Table 1 Statistical results of dataset for modeling
1.2 研究方法
1.2.1 草产量模型构建 草产量模型的选择直接影响草产量监测估计的准确性,所选模型既要符合草产量随盖度变化的生物学规律,又要能对数据进行最优化拟合。良好的草产量模型曲线应该呈平滑的“S”型,并且具有上限渐近线。常用的模型形式有Stirling和Chapman‐Richard等(表2)。本研究采用了模型1-4进行盖度草产量拟合,根据模型拟合决定系数和曲线形式筛选适合的模型,采用80%的观测数据做建模样本组,20%的观测数据做检验样本。

表2 草产量拟合备选模型Table 2 Alternative models for grass yield fitting
1.2.2 哑变量设置 哑变量是虚拟的分类变量,用变量δ(x,i或j)表示成关于定性因子的(0,1)展开,即关于δ(x,i或j)=(δ(x,1),δ(x,2),……,δ(x,m)),其中一个定性变量(m个等级)对应一个向量,一个定性变量就变成可以进行数值运算的数值向量。第1种哑变量设置方法以可食类型、干鲜类型划分结果作为哑变量进行模型拟合,第2种哑变量设置方法以海拔、坡度、坡向、可食类型、干鲜类型划分结果作为哑变量进行模型拟合,第3种哑变量设置方法以草地类型、可食类型、干鲜类型划分结果作为哑变量进行模型拟合,综合分析草地分类对草产量建模精度的影响。
1.2.3 草产量表编制 基于建立的盖度-草产量哑变量模型,采用标准差调整法、变动系数调整法或相对等级法编制外业调查数据表。草产量等级分为Ⅰ级、Ⅱ级、Ⅲ级、Ⅳ级、Ⅴ级,按照4/5的样本作为建模数据,1/5的样本作为检验样本进行精度检验。
(1)标准差调整法 各盖度草产量标准差方程采用各盖度草产量标准差Si与盖度中值Coveragei拟合。将各盖度草产量标准差拟合值代入调整式,编制产量表。
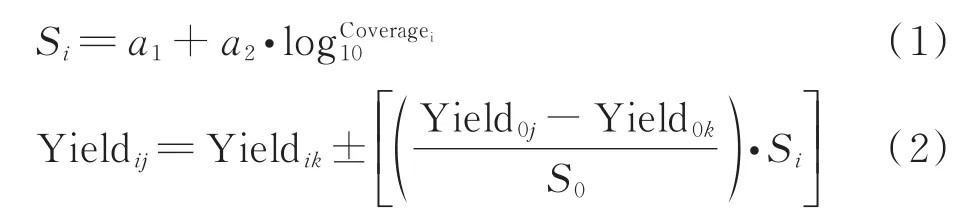
式中:Yieldij为第i盖度第j等级调整后的草产量;Yiel‐dik为第i盖度的导向曲线草产量;Yield0j为基准盖度第j等级的草产量;Yield0k为基准盖度时导向曲线草产量;S0为基准盖度所在草产量标准差理论值;Si为第i盖度草产量标准差理论值。
(2)变动系数调整法 各盖度草产量变动系数等于草产量标准差Si除以导向曲线草产量理论值Yiel‐dik。将各盖度草产量变动系数拟合值代入调整式,编制草产量表。
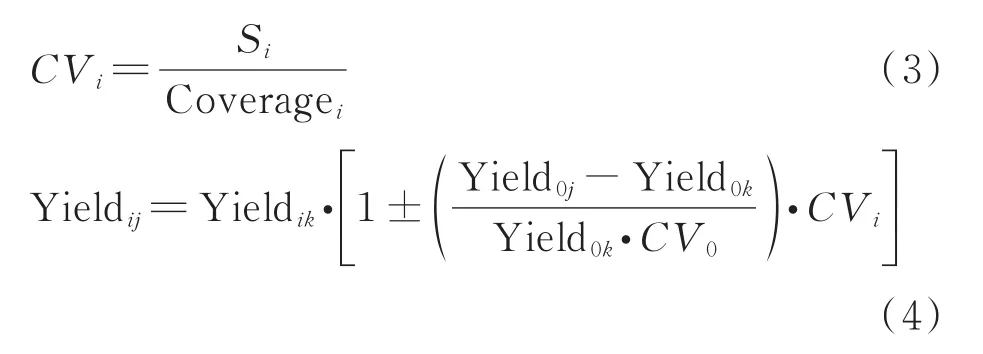
式中:CV0为基准盖度所在草产量变动系数理论值;CVi为第i盖度草产量变动系数理论值。
(3)相对等级法 该方法是按照一定的比例将草产量导向曲线平移的一种方法,将基准盖度带入导向曲线得到草产量理论值和调整系数,编制草产量表。
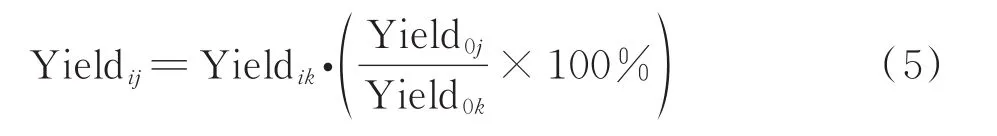
2 结果与分析
2.1 草产量模型拟合结果
2.1.1 不同模型拟合结果 不同草地类型鲜重拟合结果表明,模型1拟合决定系数平均值0.50,模型2拟合决定系数平均值0.56,模型3拟合决定系数平均值0.55,模型4拟合决定系数平均值0.57;不同草地类型干重拟合结果表明,模型1拟合决定系数平均值0.48,模型2拟合决定系数平均值0.54,模型3拟合决定系数平均值0.53,模型4拟合决定系数平均值0.54;不同草地类型可食鲜重拟合结果表明,模型1拟合决定系数平均值0.59,模型2拟合决定系数平均值0.70,模型3拟合决定系数平均值0.68,模型4拟合决定系数平均值0.70;不同草地类型可食干重拟合结果表明,模型1拟合决定系数平均值0.64,模型2拟合决定系数平均值0.66,模型3拟合决定系数平均值0.65,模型4拟合决定系数平均值0.66。综合分析表明,Chapman拟合决定系数平均值为0.62、标准估计误差平均值为1 229.28(表3),拟合结果优于其他备选模型,能用于草产量表导向曲线构建。
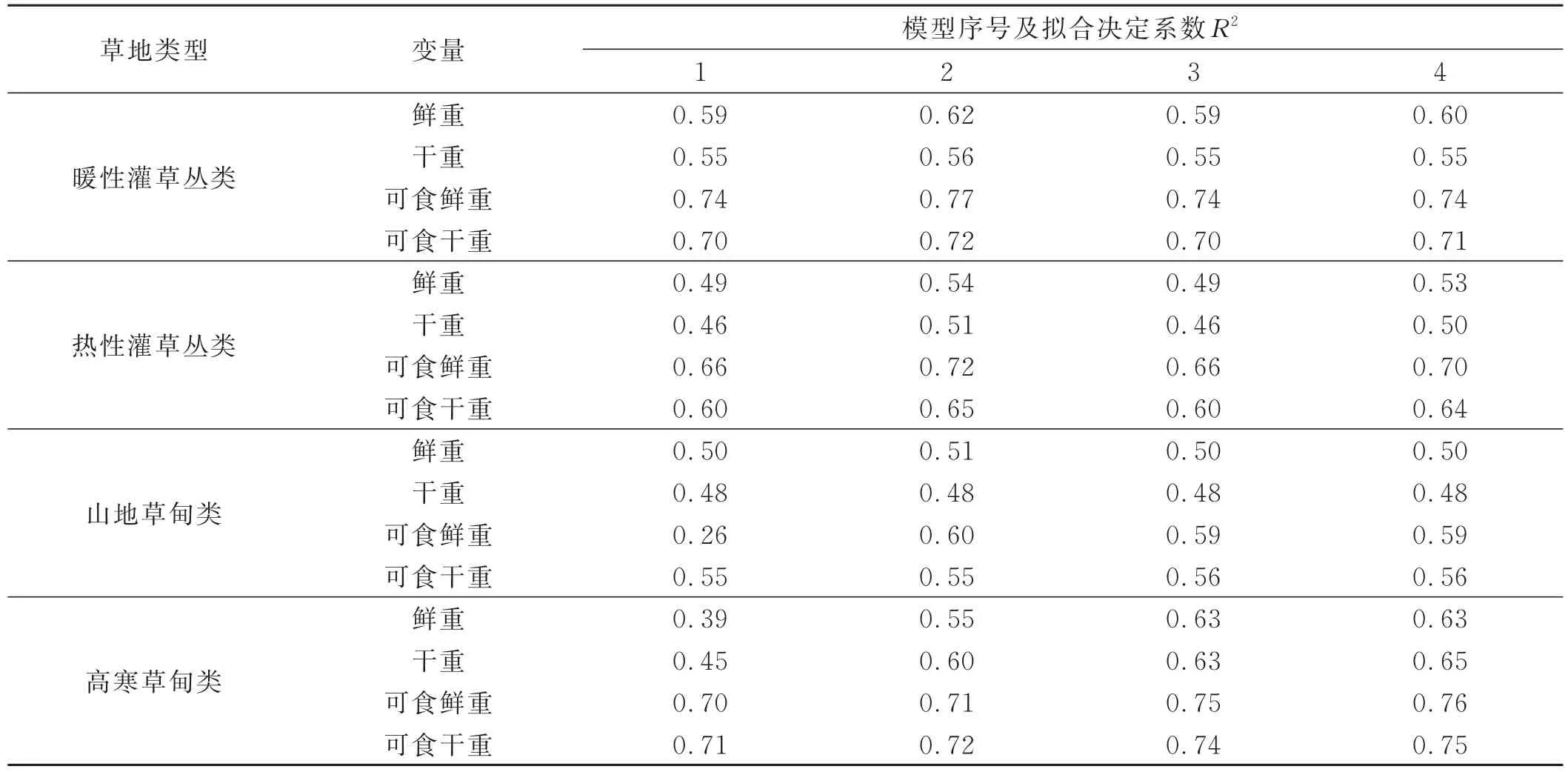
表3 不同备选模型草产量拟合结果Table 3 Fitting results of alternative models for grass yield
2.1.2 哑变量拟合结果 根据不同哑变量设置方法草产量拟合结果可知,仅以可食类型、干鲜类型划分结果作为哑变量进行模型拟合,各草地类型模型拟合决定系数0.64;以海拔、坡度、坡向、可食类型、干鲜类型划分结果作为哑变量进行模型拟合,各草地类型模型拟合决定系数0.47,加入立地因子降低了模型的拟合决定系数;以草地类型、可食类型、干鲜类型划分结果作为哑变量进行模型拟合,模型拟合决定系数0.81,以草地类型作为哑变量能显著提高模型的拟合效果(表4)。

表4 不同哑变量设置方法草产量拟合结果Table 4 Fitting results by different methods of dummy variables for grass yield
2.2 草产量表编制结果
2.2.1 基准盖度与产量级距 各草地类型草产量变异系数随盖度增加而逐渐增大,草地盖度大于60%之后趋于平缓,变异系数变化幅度趋于1,从而确定各草地类型的基准盖度为60%。暖性灌草丛干重产量级距0.5 t/hm2,可食干重产量级距0.4 t/hm2,鲜重产量级距1.0 t/hm2,可食鲜重产量级距1.0 t/hm2;热性灌草丛干重产量级距1.0 t/hm2,可食干重产量级距0.8 t/hm2,鲜重产量级距1.5 t/hm2,可食鲜重产量级距1.5 t/hm2;山地草甸干重产量级距0.5 t/hm2,可食干重产量级距0.5 t/hm2,鲜重产量级距1.0 t/hm2,可食鲜重产量级距1.0 t/hm2;高寒草甸干重产量级距0.2 t/hm2,可食干重产量级距0.2 t/hm2,鲜重产量级距0.5t/hm2,可食鲜重产量级距0.5t/hm2。指数级个数均为5,按照相对等级法为例展开得到各类型草产量曲线簇(图1)。
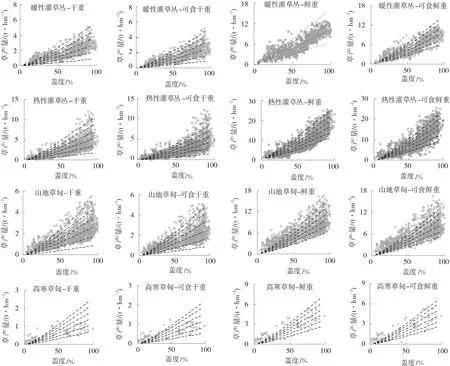
图1 各草地类型草产量散点和曲线簇Fig.1 Scatter and curves of yield by various grassland types
2.2.2 各草地类型草产量表精度检验结果 暖性灌草丛草产量表落点检验平均值为84.9%,其中干重、可食干重、鲜重和可食鲜重草产量表落点检验值分别为89.0%、87.8%、81.3%和81.3%;热性灌草从草产量表落点检验平均值为86.9%,其中干重、可食干重、鲜重和可食鲜重草产量表落点检验值分别为96.7%、96.0%、77.5%和77.3%;山地草甸草产量表落点检验平均值为86.7%,其中干重、可食干重、鲜重和可食鲜重草产量表落点检验值分别为97.2%、97.3%、76.0%和76.4%;高寒草甸草产量表落点检验平均值为86.5%,其中干重、可食干重、鲜重和可食鲜重草产量表落点检验值分别为94.2%、93.2%、78.6%和79.9%。各草地类型干重、可食干重、鲜重和可食鲜重草产量表落点检验平均值分别为94.3%、93.6%、78.3%和78.7%。各草地类型草产量表落点检验值均大于75%,能满足草原资源外业调查草产量调查的估算要求。
2.3 广南县草产量表修正结果
以草产量指数为例,采用相对等级法(式5)修正得到广南县各草地类型草产量表(表5),根据修正结果可知,基准盖度时暖性灌草丛总干重、可食干重、总鲜重和可食鲜重分别为 2.4、1.4、7.7和 4.4 t/hm2,热性灌草丛总干重、可食干重、总鲜重和可食鲜重分别为3.2、2.0、10.2和6.5 t/hm2,山地草甸总干重、可食干重、总鲜重和可食鲜重分别为2.6、1.5、9.1和5.2 t/hm2。广南县总干重平均值小于云南省0.6 t/hm2、可食干重大于0.3 t/hm2、总鲜重小于1.9 t/hm2、可食鲜重大于1.2 t/hm2,可食性较云南省平均水平高。
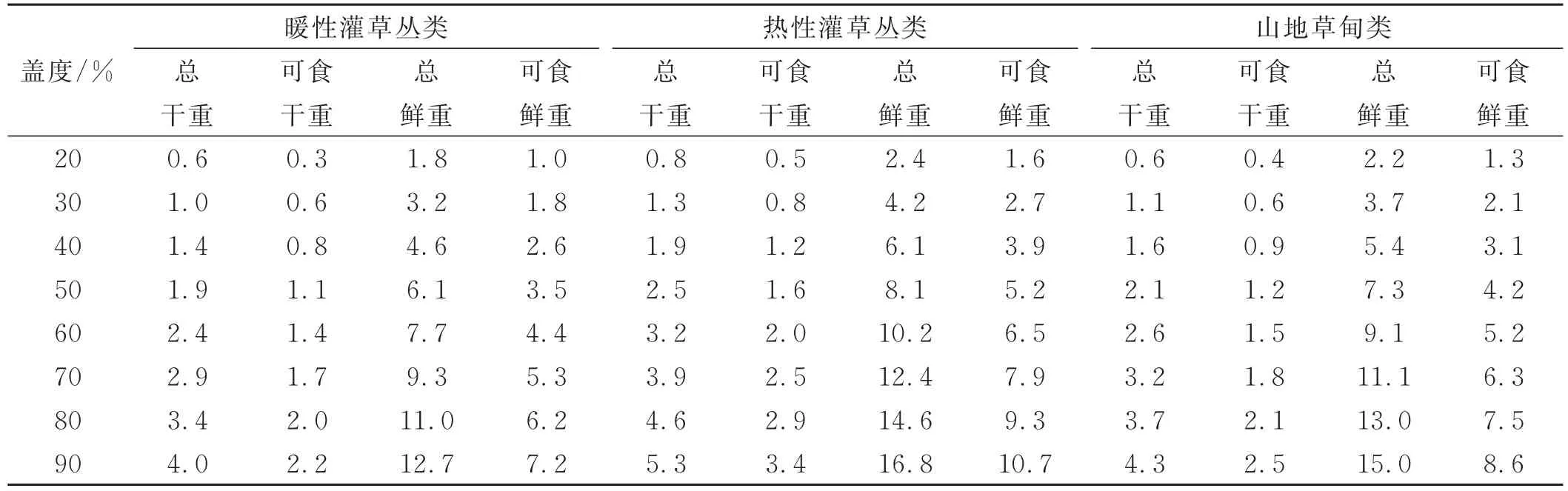
表5 广南县不同草地类型草产量表修正结果Table 5 Modified results by different grassland types in Guangnan County for grass yield t·hm-2
3 讨论
草产量导向曲线模型中草地类、可食性和干鲜重是类型变量,盖度是连续变量,草产量是因变量,采用哑变量的方法能克服单一拟合模型不兼容的问题,且模型拟合精度更高。以海拔、坡度、坡向、可食类型、干鲜类型划分结果作为哑变量进行模型拟合[21],模型的拟合决定系数降低了0.17;而以草地类型作为哑变量进行模型拟合,模型的拟合决定系数提高了0.26,只有增加解释意义的变量模型的拟合决定系数才会提高,当模型中的解释变量间存在共线性关系时,变量中的冗余信息也会提高模型的拟合决定系数,就需要运用AIC信息准则寻找可以最好地解释数据但包含最少自由参数的模型。草地类型作为哑变量加入模型中能有效提高模型拟合的决定系,数跟草地类型划分的条件有直接关系,草地类的划分条件包括湿润度、降水量、年积温和植被型组等,均是影响草产量的关键环境因子,因而加入模型后有效地提高了拟合决定系数。随着机器学习和深度学习等人工智能的发展,以遥感技术为主要手段的仿真系统,融合了计算机科学、遥感科学和草学等专业学科门类,能有效地提高区域尺度的草原资源调查监测效率。采用经验数据建立的参数模型能够考虑资源自身的特征因素,对待估参数进行阈值限定,避免过度拟合,但本研究未将草地类型作为混合效应,运用混合效应模型进行建模分析是后续研究需要改进的地方,以期获得更好的拟合效果。
为检验草产量表的准确性,本研究采用了2种方法进行验证,1)各草地类型草产量表落点检验值均大于75%,能满足草原资源外业调查草产量调查的估算要求;2)高寒草甸类、暖性灌草丛类、热性灌草丛类和山地草甸类检验样本的均方根误差(RSME)分别为6.0、10.3、22.1和 13.31 t/hm2,能满足调查的检验精度。由于不同草地类的植被型组差异导致了草产量的估算的差异,其中热性灌草丛存在有高大草本和灌木的分布,导致草产量估算的误差较其他草地类大。建立区域尺度的草产量模型后,不能准确反映县域尺度的草产量差异,外业样地调查结束后,应根据县域地面调查样地和样方的数据进行模型参数修正[13,17,19],模型参数可采用基于先验信息和后验信息的贝叶斯方法进行修正,也可以采用草产量指数的方法仅对模型的上限渐近线参数进行修正,在后续的研究中应该补充和完善两种方法的对比分析。2021年3月,国务院办公厅印发了《关于加强草原保护修复的若干意见》指出[22],在国土三调成果基础上,利用天空地一体化技术,开展草原资源专项调查,采用该方法建立草产量模型能够点面结合,在草原资源基况监测中将提供可参考的方法。
4 结论
草产量模型导向曲线采用Chapman拟合结果优于其他备选模型,拟合决定系数平均值为0.62、标准估计误差平均值为1 229.28。以草地类型作为哑变量加入到导向曲线模型中能显著提高模型的拟合效果,相较于其他哑变量设置方法,拟合决定系数提高了0.26。各草地类型草产量变异系数随盖度增加逐渐增大,草地盖度大于60%之后趋于平稳,确定各草地类型的基准盖度为60%。草产量表的产量级距介于0.2~1.5 t/hm2。
猜你喜欢
电脑与电信(2021年10期)2021-02-10 06:53:44
黑龙江工程学院学报(2020年5期)2020-10-21 05:37:10
南方农业学报(2020年4期)2020-06-04 15:51:13
南方农业学报(2020年10期)2020-01-21 15:36:41
水土保持研究(2019年6期)2019-10-19 03:33:32
科学与财富(2018年12期)2018-06-11 01:49:24
防护林科技(2015年5期)2015-06-10 11:42:52
海南热带海洋学院学报(2015年5期)2015-03-14 09:51:07
现代营销·经营版(2011年2期)2011-05-14 14:54:51
