
流域情景驱动的通用混合型水文模型研究
2023-01-18 11:22谢非,夏泽,杨琳
水利水电快报 2023年1期
谢 非,夏 泽,杨 琳
(长江信达软件技术(武汉)有限责任公司,湖北 武汉 430014)
0 引 言
流域水文模型是现代水文学最重要的研究领域,已经从经验模型、概念性集总模型发展到基于物理基础的半分布式和全分布式水文模型。经验模型的发展主要集中在19世纪后期至20世纪50年代之间,代表性模型包含降雨径流相关图模型、相应水位(或流量)模型、单位线模型[11]等。随着计算机及信息技术的发展,从20世纪50年代开始,概念性集总模型迅速发展,提出的模型包括美国斯坦福模型[12]、萨克拉门托模型[13]、日本TANK模型[14]和华东水利学院(现为河海大学)的新安江模型[15]。20世纪90年代,计算机技术、GIS、遥感技术和雷达技术的迅速发展,为流域分布式水文模型的发展提供了技术基础,其中典型的半分布式流域水文模型包含HSPF模型[16]、HBV模型[17]、PRMS模型[18]、HEC-HMS模型[19]、TOPMODEL模型[20]、SWAT模型[21];全分布式水文模型主要包含MIKESHE模型[22]、SHETRAN模型[23]、IHDM模型[24]、TOPKAPI模型[25]。
流域水文模型软件系统作为水文模型的技术外壳,为水文模型的推广应用提供技术支持与保障,随着流域水文模型的进一步发展,流域水文模型系统也随之发展进步,从而开发出基于流域尺度,为水文专业科研人员和流域管理人员提供决策支持的流域水文模型系统。例如BASINS[26],HMS[27],WMS[28],SMS[29],MMS[30],可将不同模拟过程和模拟阶段的水文模型进行系统集成,以满足用户流域尺度的模拟需要;如TOP-MODEL[31],DHSVM[32],AVSWAT[33],WetSpa[34],MIKESHE[35],HIMS[36],OpenMI[37],OMS[38]等以分布式水文模型为基础开发的系统软件,可为流域水资源综合管理提供有效的技术参考和决策支持。
由于水文模型都存在一定的局限性,在实际应用中,下垫面条件复杂,而模型种类往往单一,不能满足各种下垫面条件下的计算需求,影响了模型搭建的准确性及适用性。此外,在传统水文模型搭建过程中,需要运用多种软件,如GIS软件、模型软件、模型参数率定工具等,才能完成整个建模过程,建模过程的复杂性导致误差的增加。并且于各计算单元上的产汇流模型只能进行统一设置,难以反映各区域的产汇流规律。
1 研究目标
本文提出1套流域情景驱动的通用混合型水文模型,旨在解决流域水文模拟中以下技术问题。
(1) 解决传统模型建模方式中各计算单元上的产汇流模型单一性问题。建立适用于不同下垫面条件下的产汇流模型库,产流模型包括:适用于湿润半湿润地区的新安江模型、NAM模型,适合于干旱地区的水箱模型,适用于所有流域的API模型。坡面汇流模型包括:单位线模型,滞时演算模型。河道汇流模型包括:水动力学模型,马斯京根模型。以此为基础建立产汇流模型库,将有效提高模型搭建的准确性。
(2) 解决传统建模计算过程中通用性不强的问题。以成熟完善的技术方案为指导,建立1套通用的模型搭建系统,主要功能包括:数据导入,模型搭建,洪水摘录,模型率定,模型应用。通过以上功能将有效解决以往搭建工具通用性不足的问题,同时有效减少了模型搭建过程中人为因素所导致的误差,提升模型搭建的准确性与通用性。
农村水利现代化是一项跨领域的社会性系统工程,必须建立相应的机构专门推动,整体协调推进天津市农村水利现代化,尽快组织起草并以市政府名义印发《关于加快天津市农村水利现代化的意见》,统筹天津市发展改革、水务、财政、农业、国土房管等部门,密切配合,建立工作机制,强化部门合作,细化工作措施,支持农村水利现代化,明确农村水利现代化年度工作计划,制定相应的工作时间表;有农业区县是农村水利现代化的责任主体,应成立相应的组织机构,将各项工作任务落实到分解到部门、细化到责任人。
(3) 解决传统模型建模方式中各计算单元上的产汇流模型不能灵活配置的问题。通过自由选择的方式进行流域水文模型的智能搭建,在模型搭建过程中,用户可依据模型搭建的实际需求,实现各计算单元产汇流模型的自由组合,从而提高模型的计算精度。
2 研究方法
本文以JAVA平台为基础,开发通用预报模型产品库,对外提供标准化服务接口,并形成可灵活配置的模型后台,建立了1套完整流域情景驱动的通用混合型水文模型,实现了情景驱动的水文模型灵活组建,具体步骤如图1所示,包括数据输入,模型搭建,洪水摘录,模型率定,模型应用。

图1 基于情景驱动的水文模型灵活组建策略方法流程Fig.1 Flow chart of flexible establishment strategy of hydrological model based on scenario drive
2.1 模型自由组合构建
为了详尽地反映降雨的时空分布和下垫面水文地质条件的差异,更好地揭示各区域的产汇流规律,以提高预报成果的精度,通常建立分块式降雨-径流流域模型,即将预报流域适当地分成多个子流域,依据不同子流域的特点选用不同的水文模型进行产汇流计算,将水文模型在预报流域内进行多种方式组合,使整个流域的产汇流计算达到最优化,计算流程如图2所示,其中具体过程如下。

图2 模型组合计算原理Fig.2 Schematic diagram of model combination calculation
(1) 子流域出口流量计算。根据流域分布地理特点及汇流等流时特征,将流域划分成若干子流域,各子流域应用合适的流域水文模型进行产汇流计算,模型计算的流量为子流域出口流量。
(2) 干流出口流量计算。根据拓扑关系确定子流域的上下游关系,上一个子流域的出流断面为下一个子流域的入流断面,在每个子流域内,对入流断面的流量进行马斯京根流量演算,得到相应的干流出口流量。
(3) 流域出口流量计算。在每个子流域的出口断面,其相应子流域出口流量与干流出口流量按时差叠加,叠加后形成该子流域出口断面的总流量,即为下一个子流域入流断面的流量,依次向下一个子流域出口进行演算,最终推得流域出口的总流量。
2.2 参数自动率定
水文模型参数的率定方法主要有人工试错法和自动优化法。人工试错法率定模型参数主要依据个人主观评估模拟结果,很大程度上依赖调试人员的经验,从而增加了模型的不确定性。自动优化方法是随着计算机技术和应用数学的发展而迅速发展起来的参数率定方法,应用于水文模型参数率定的自动优化方法主要可以分为局部优化方法和全局优化方法。由于流域水文模型大多是非线性的,局部优化算法受起始点影响较大,对于不同的起始点会在不同的点结束运算,从而带来不同的优化结果。水文模型参数的全局优化具有搜索策略的局限性、目标函数的不连续性、参数间的高度非线性相互作用和影响等特征,从而使优选过程非常复杂,难以收敛到全局最优解。
SCE-UA算法是一种有效解决非线性约束最优化问题的方法,综合了确定性搜索、随机搜索和生物竞争进化等方法的优点,可以快速地搜索到水文模型参数全局最优解,目前在流域水文模型参数优选中应用十分广泛。本文采用SCE-UA算法,以NASH系数作为目标函数进行模型参数率定,如式(1)所示。
(1)

2.3 混合模型组件
不同模型之间的连接或耦合技术主要分为外部耦合、内部耦合、全耦合技术。但总体而言,基于内部耦合与全耦合技术来实现模型之间的联合模拟研究相对较少。外部耦合技术,即将一个模型的输出结果作为另一个模型的输入条件,通常被视为一种最有效、最简单的方法去实现不同模型的联合,进而完成对复杂流域系统的切实完整模拟。为了真实模拟复杂水动力过程的河流或地表水体,水动力模型通常需要连接流域水文模型来获取流量输入条件。耦合过程如下。
(1) 概念性水文模型与水动力学模型耦合。基于概念性水文模型用来模拟上游流域的径流输出,将其作为水动力模型的输入条件(边界条件)。根据需求利用一维水动力学模拟,演算至相应断面。通过概念性水文模型获取区间径流并汇入相应断面。将区间径流与上游河道的水动力学模拟流量叠加作为新的水动力模型输入条件(边界条件)。利用新的输入条件向下游继续演算。通过此耦合方式不断演算,最终至流域出口。
(2) 分布式水文模型与水动力学模型耦合。由于分布式水文模型将整个流域内部栅格化,每个栅格为一个独立计算单元,故在流域内部不满足一维水动力耦合条件,因此一维水动力与分布式水文模型耦合计算只存在于流域外部,具体耦合可分为如下两种情况:① 当计算流域为闭合流域时,则流域无上游来水,分布式模型计算上游来水为零,计算所得出口流量可作为水动力模型上边界条件,根据需求可以将出口流量演算至相应断面;② 当计算流域为非闭合流域时需考虑龙头断面入流情况,计算时将龙头断面入流通过水动力模型演算至子流域出口,与流域内产流一同演算至流域出口作为水动力模型上边界条件,然后根据需求演算至相应断面。
3 混合型水文模型平台研发技术路线
3.1 通用平台总体框架
以技术先进、系统实用、结构合理、产品主流、低成本、低维护量作为基本建设原则,通用平台规划的整体构架如图3所示,包括数据层、平台层、应用层、用户层。
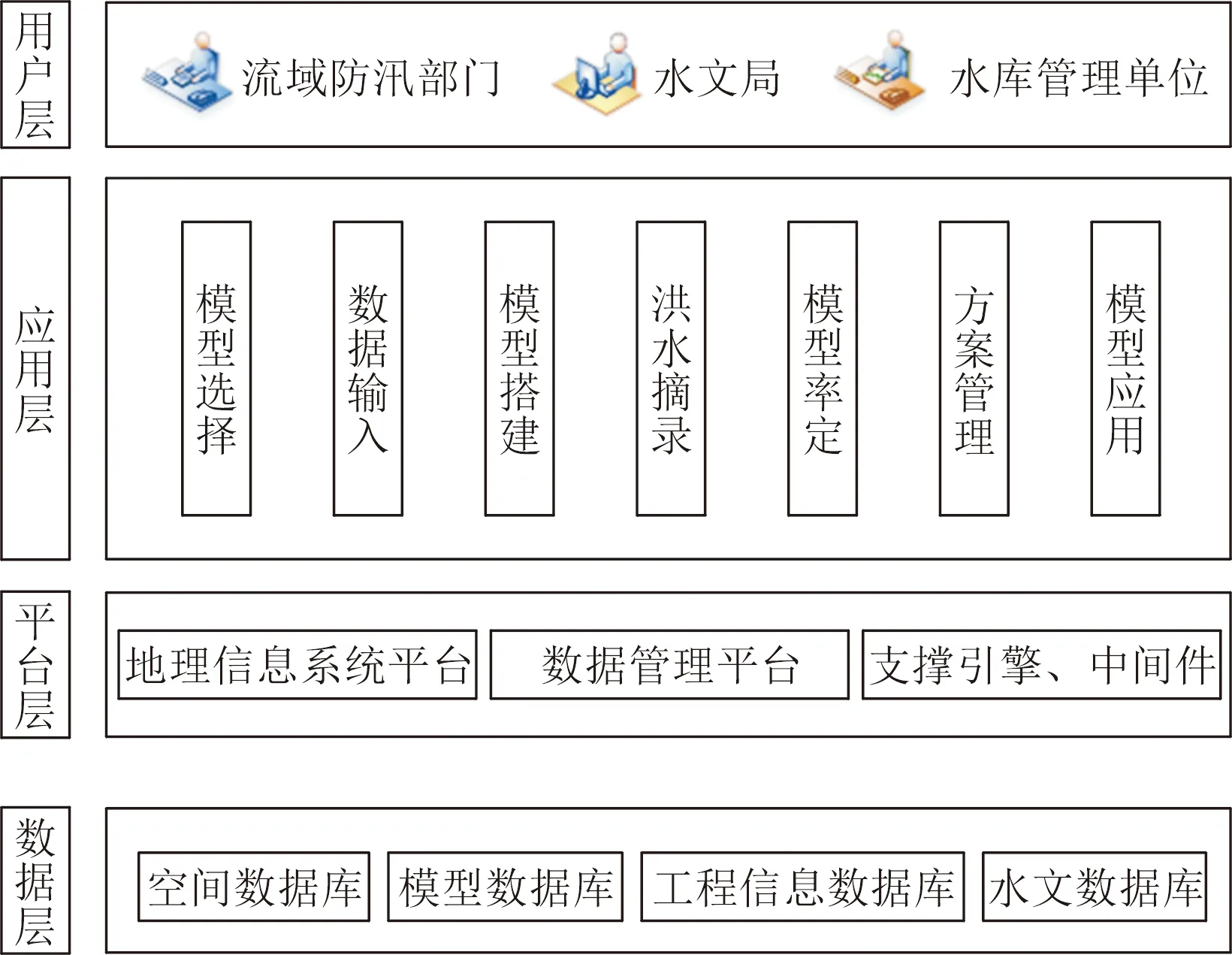
图3 通用平台总体框架Fig.3 General framework of general platform
(1) 数据层。数据层集中组织和管理洪水预报所需的各类数据,包括空间数据、模型数据、工程信息数据、水文数据。数据层为水文模型的展示提供数据支撑。
(2) 平台层。应用支撑平台层包括地理信息系统平台、数据管理平台和支撑业务系统的各类引擎和中间件。其中,地理信息系统平台负责空间数据及业务相关数据的管理维护和信息查询,数据管理平台包括数据交换、模型接口、用户管理等。
(3) 应用层。应用层包括应用层实现信息展示、应用服务等人机交互功能,为系统使用、维护人员,系统访问用户等提供美观、简洁和全新体验的操作界面,用户使用浏览器即可进行操作。应用层包括流域水文水资源通用模型系统的各个业务功能模块,分为模型选择、数据输入、模型搭建、洪水摘录、模型率定、方案管理、模型应用。
(4) 用户层。用户层包括整个系统的目标用户,主要包括流域防汛部门、水文局、水库管理单位等,各用户按不同的权限和业务需求,进行相应权限的内容获取与展示。
3.2 通用平台功能
通用平台提供集总式新安江模型、集总式API模型、集中式NAM模型、集总式TANK模型、集总式组合模型、分布式新安江模型、分布式NAM模型、分布式TANK模型、一维水动力模型供用户选择,如图4所示。
图4 模型选择Fig.4 Model selection
(1) 该平台提供多样数据输入方式,当用户选择模型后进入数据输入页面,用户可以以图层形式导入河流、子流域、雨量站、水文站、权重等信息,并指定模型的拓扑结构,按照平台提供的EXCEL模板进行雨量、流量数据的导入,如图5所示。

图5 数据输入Fig.5 Data input
(2) 该平台提供自由搭建模型,依据各子流域实际需要选择合适的产汇流模型,同时实现模型的自由组合,如图6所示。
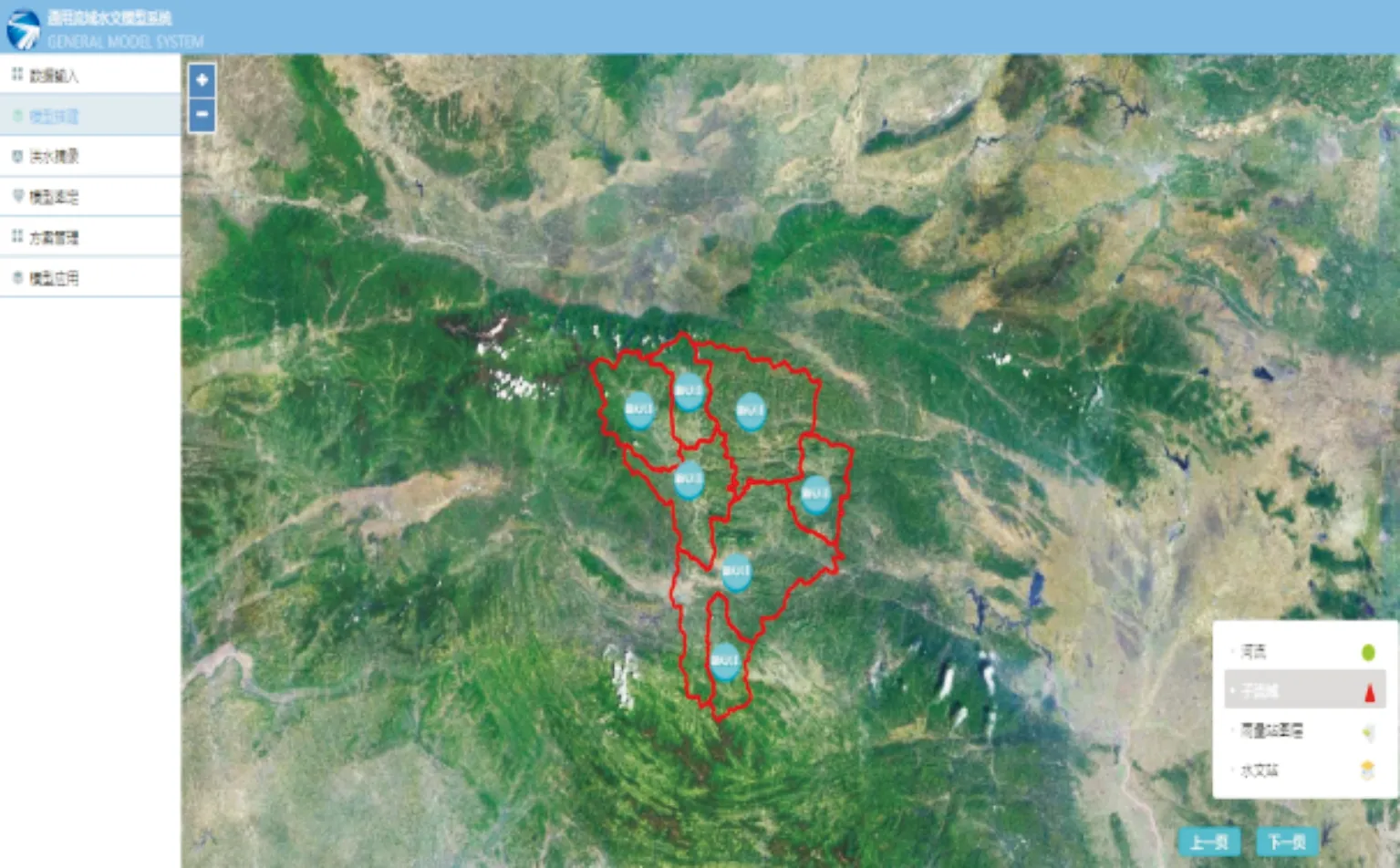
图6 模型搭建Fig.6 Model construction
(3) 该平台提供洪水摘录、管理功能。模型搭建后之后进行洪水摘录,摘录时自动完成数据插值和洪水特征值统计,如图7所示。
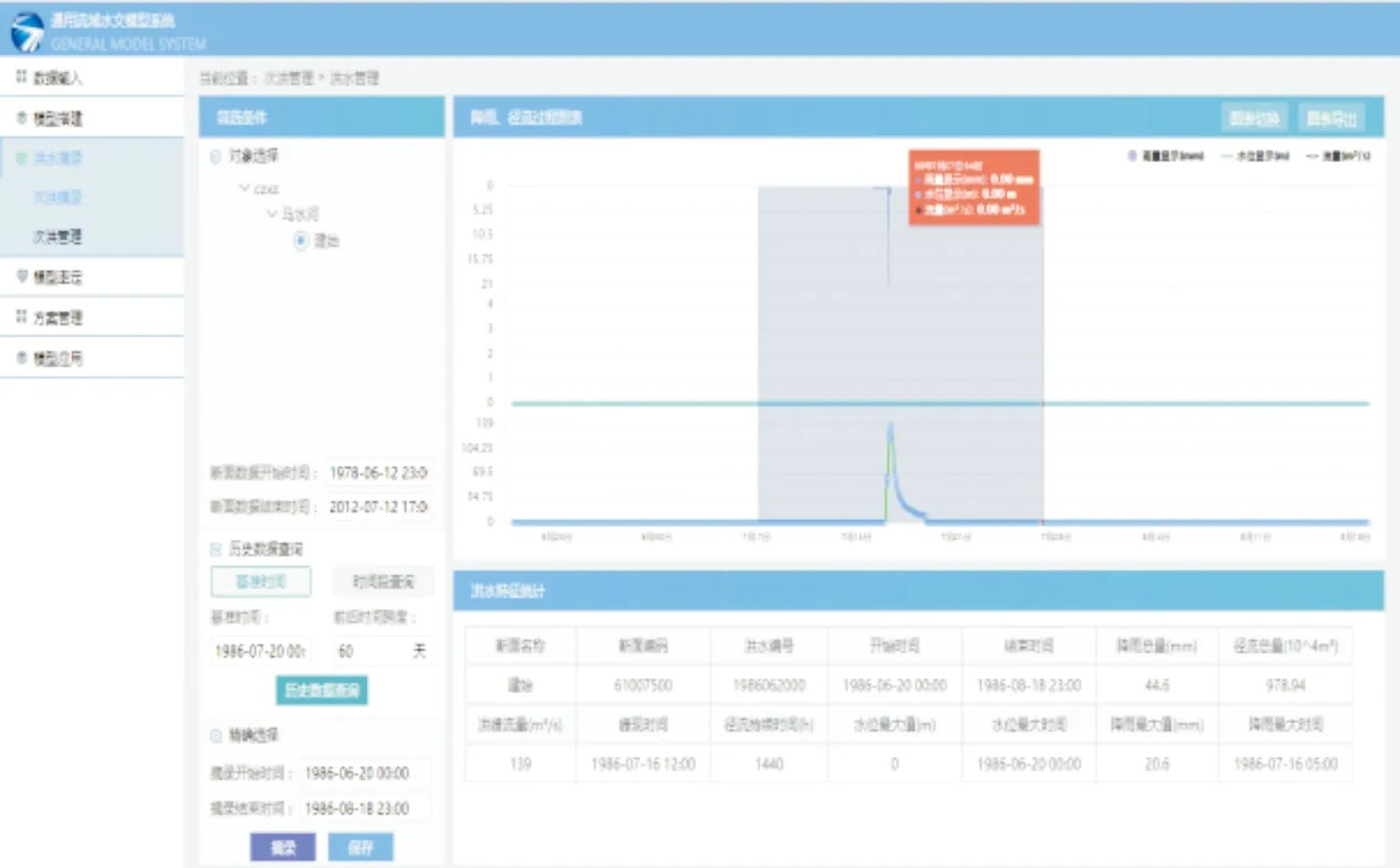
图7 次洪摘录Fig.7 Extract of flood
(4) 该平台提供自动率参和手动率参功能。以摘录的场次为基础,利用SCE_UA算法实现参数自动率定,同时支持手动率参功能,便于用户进行参数率定和参数验证,如图8所示。

图8 参数率定 Fig.8 Parameter calibration
(5) 该平台提供方案管理功能。预报成果管理通过方案名称(模糊查询)、方案类型、制作人、方案制作时间范围、方案开始时间范围以及方案结束时间范围查询预报成果实现,并能对单个成果方案进行查看和删除操作,如图9所示。

图9 方案管理Fig.9 Scheme management
(6) 该平台提供模型应用功能。利用存储的模型方案,输入雨量和流量数据进行水文模拟计算,如图10所示。

图10 模型应用Fig.10 Model application
4 应用案例分析
汉江是长江中游最大的一级支流,发源于陕西省汉中市宁强县潘冢山,自西向东流经陕西省汉中市、安康市,于安康市白河县出陕西进入湖北十堰,在湖北省丹江口与汉江最大的支流丹江汇合进入丹江口水库,出丹江口水库后继续向东南流,过襄阳、荆门等市,在武汉市汇入长江,全长1 577 km,流域面积15.9万km2。
选取汉江流域中的安康-白河区间作为此次模型验证的目标流域。该区间总面积为5 531 km2,包含安康、桂花园、向家坪、长沙坝、白河5个水文站,其中,桂花园水文站为支流坝河的控制站,向家坪水文站为支流旬河的控制站,长沙坝水文站为支流夹河的控制站,白河水文站为该区间出口断面控制站。洪水预报计算模型中涉及18个雨量站,分别为狮坪、秋坪、茨沟、花里墟、平利、六口、米粮、南宽坪、两河关、长枪铺、安康、县河口、桂花园、向家坪、蜀河、红军、长沙坝、白河雨量站,区间雨量站位置分布如图11所示。根据水文模型适用性和子流域的下垫面情况,区域子流域划分及模型选择情况如图12所示。安康-白河区间1992~2010年间的20场洪水作为全部样本,其中1992年7月11日至2000年间的12场洪水作为参数率定样本,用以得出系统所需要的各个参数并进行调整,2000~2010年间的8场洪水作为验证样本,用以验证率定所得参数是否正确,评估系统的模拟效果。

图11 流域水文站网构架Fig.11 Framework of hydrological station network in the basin

注:XAJ为新安江模型;API为API模型;TANK为水箱模型;NAM为NAM模型。图12 研究区域子流域划分及模型选择Fig.12 Sub watershed division and model selection in the study area
模拟结果如图13~14,表1~2所示。12场洪水在率定期的模拟值与实测值基本重合,洪峰合格率达到100%,平均确定性系数达到0.94,峰现时间合格率达到75%(以3 h以内为合格);8场洪水在验证期的模拟值与实测值基本重合,洪峰合格率达到91%,平均确定性系数达到0.91,峰现时间合格率达到75%(以3 h以内为合格),模拟精度较高,能够满足生产实际需求。

图13 12场洪水参数率定结果Fig.13 Calibration results of 12 flood parameters

注:为直观展示显示效果,本文重点验证洪峰流量,横坐标刻度未均匀分布,数值对应为洪峰出现时间。图14 8场洪水参数验证结果Fig.14 Verification results of 8 flood parameters

表1 12场洪水参数率定结果统计Tab.1 Statistical table of 12 flood parameter calibration results

表2 8场洪水参数验证结果统计Tab.2 Statistical table of verification results of 8 flood parameters
5 结 语
本研究适用于不同下垫面条件下的产汇流模型库,可有效提高模型搭建的准确性。通过自由选择的方式进行流域水文模型的智能搭建,在模型搭建过程中,用户可依据模型搭建的实际需求,实现各计算单元产汇流模型的自由组合,从而提高模型的计算精度。
猜你喜欢
河北地质(2021年3期)2021-11-05
河南水利年鉴(2020年0期)2020-06-09
河南水利年鉴(2020年0期)2020-06-09
能源(2017年10期)2017-12-20
能源(2017年5期)2017-07-06
河南水利年鉴(2017年0期)2017-05-19
智能建筑电气技术(2015年5期)2015-12-10
雷达与对抗(2015年3期)2015-12-09
雷达与对抗(2015年3期)2015-12-09
太阳能(2015年7期)2015-04-12
