
融合社交关系和知识图谱的推荐算法
2023-01-17 09:32:18高仰,刘渊
计算机与生活 2023年1期
高 仰,刘 渊+
1.江南大学人工智能与计算机学院,江苏无锡214122
2.江苏省媒体设计与软件技术重点实验室(江南大学),江苏无锡214122
在这个信息技术和互联网高速发展的信息爆炸时代,可供选择的商品和服务也随之急剧增多,然而人的兴趣偏好各不相同,并且有些用户对自己的隐性需求并不明确,为了更好地帮助用户快速发现自己喜欢的商品,为了更精准地帮助商家推送自己的商品,推荐系统应运而生。推荐系统是一种信息过滤系统,用于预测用户对物品的评分或喜好程度,通过构建用户模型,推荐对象模型,推荐算法模型,把用户模型中兴趣需求信息和推荐对象模型中的特征信息匹配,同时使用相应的推荐算法进行计算筛选,找到用户可能感兴趣的推荐对象推给用户。传统的推荐方法可分为:基于内容的推荐方法,为用户推荐跟他的历史兴趣偏好相似的物品;基于协同过滤推荐方法,通过对用户历史行为数据的挖掘,发现用户的偏好,基于不同的偏好对用户进行群组划分并推荐品味相似的物品;混合推荐方法则是将前面的方法结合起来推荐,从而起到取长补短的推荐效果。
近年来,深度学习已经成为互联网大数据和人工智能的一个热潮。深度学习通过组合底层特征形成更加稠密的高层语义抽象,从而自动发现数据的分布式特征表示,很好地解决了传统机器学习中需要人工设计特征的问题[1]。由于深度学习的天然优势,使得其成为了推荐系统领域的主流研究方向,但发展时间较短,仍然存在可改进和提升的地方。深度学习技术应用于推荐系统不仅能学习用户或物品的潜在特征表示,而且可以学习用户与物品之间的复杂的线性交互特征,进而深入地分析用户偏好[2]。随着信息技术的高速发展,互联网中有越来越多的数据能够被感知获取,其中包括用户的社交关系、物品的文本和标签等属性信息以及用户和物品的交互信息等,这些多源异构数据蕴含着丰富的用户个性化需求信息,充分分析利用这些辅助信息可以有效缓解冷启动与数据稀疏问题,从而为用户提供更加良好的推荐服务。因此,如何高效利用这些辅助信息来增强推荐性能越来越受到研究者的重视。
基于以上背景及现状,本文通过分析社交关系数据、物品属性数据这些辅助信息来丰富用户和物品的特征表示,从而缓解推荐系统所面临的冷启动和数据稀疏问题。人是社会性动物,人们更愿意接纳熟人和所信任人的推荐,更愿意尝试熟人所尝试的物品,在推荐系统中,用户的社交关系数据反映了其熟人和信任人连接状态,分析社交关系数据可以丰富用户的特征表示,挖掘用户的潜在偏好。另外,海量的被推荐物品包含许多标签、文本,这些辅助信息反映了物品的内容、类别甚至在一定程度上反映了相似程度,将这些辅助信息采用知识图谱的形式构建成图,可以辅助分析物品的潜在联系,有利于推荐结果的发散。本文拟通过引入并高效合理应用大量辅助信息,来缓解推荐的冷启动和数据稀疏问题,提升推荐效果。
社交关系数据属于图数据,它包含着丰富的关系型信息,反映了用户的信任关系,图神经网络是图数据中相邻节点间信息传播和聚合的重要技术,可以有效地将深度学习的理念应用于非欧几里德空间的数据上[3]。采用图卷积神经网络分析提取社交网络数据,是从社交关系的角度计算用户的相似度,分析得到的用户信任关系和用户相似度可以丰富用户的表示向量,从而提升推荐效果。知识图谱是一种用图模型来描述知识和建模世界万物之间的关联关系的技术方法。知识图谱可以用于表示推荐系统中繁杂的物品和属性之间的语义关系,通过知识图谱表示学习分析物品属性知识图谱,是从物品属性的角度计算物品的相似度,分析得到的蕴含物品属性的物品表示向量,可以缓解冷启动与数据稀疏问题并增强推荐系统的性能。
该文采用深度学习的方法,使用图卷积神经网络来提取用户社交网络数据,得到用户的特征向量,使用基于语义的匹配模型来提取由物品属性构建的知识图谱,从而得到物品的向量表示,最后使用得到的用户和物品表示向量计算得到推荐列表。本文主要贡献如下:
(1)提出了一种改良的图卷积神经网络方法,用以挖掘用户的社交关系数据,该方法采用图中心性作为概率对节点邻居进行采样,使用word2vec 模型思想生成虚拟邻居以缓解社交数据的稀疏性,采用注意力机制对节点邻居进行聚合。
(2)为了丰富物品的语义表示,采用基于语义的匹配模型来提取物品属性构建的知识图谱,采用多任务学习技术训练推荐模块和知识图谱表示学习模块。
(3)结合上述方法,提出了一种融合社交关系和知识图谱的混合推荐框架,在多个数据集上进行了大量的实验,验证了其性能优势。
1 相关工作
1.1 图神经网络
随着计算机的出现和机器计算时代的到来,图作为一种能够有效且抽象地表达信息和数据中的实体以及实体之间关系的重要数据结构被广泛应用[3]。图神经网络(graph neural network,GNN)的研究主要是集中在相邻节点信息的传播与聚合上。其中,图卷积神经网络是研究时间最长、研究成果最多的,按照特征空间的不同,图卷积神经网络主要分为频域和空间域两个类型。频域的图卷积神经网络[4]基于图信号处理问题,将卷积层定义为一个滤波器,通过滤波器去除噪声信号从而得到输入信号的分类结果。基于空间的图卷积神经网络[5]通过计算中心单一节点与邻节点之间的卷积,来表示邻节点间信息的传递和聚合,并作为特征域的新的节点表示。文献[6]提出的基于图结构的传播卷积神经网络(diffusionconvolutional neural networks,DCNN)通过传播卷积的方式,扩散性地扫描图结构中的每一个顶点,替代了一般图卷积神经网络基于矩阵特征的卷积形式;针对大型图数据,文献[7]引入聚合函数的概念定义图卷积,提出了一种批量训练算法GraphSAGE(graph sample and aggregate);为了进一步提升图神经网络的性能,文献[8]提出的图注意力网络(graph attention networks,GAT)聚合节点邻居信息的时候使用注意力机制来确定每个邻居节点对中心节点的重要性,从而更准确地聚合邻居。文献[9]提出了一个多通道超图卷积网络(multi-channel hypergraph convolutional network,MHCN),利用高阶用户关系来增强社交推荐。图卷积神经网络在社交网络这类图数据上具有强大的嵌入表示能力,能够挖掘用户之间的信任关系,从而能够帮助推荐系统分析用户潜在偏好。
1.2 知识图谱
随着人工智能技术的发展和应用,知识图谱现已被广泛应用于智能搜索、个性化推荐等领域。知识图谱通常以三元组的形式存储实体及其关系,每一个三元组都由一个头实体、关系和尾实体构成,三元组不仅可以帮助理解知识实体之间的关系,也可以存储知识实体的属性[10]。将知识图谱引入到推荐系统不仅有利于信息的挖掘和推荐结果的发散,还可以增强推荐的可解释性。现有的基于知识图谱的推荐方法可以被分为两类:基于嵌入的方法和基于路经的方法。基于嵌入的方法主要通过图嵌入的方法对实体和关系进行表征,进而扩充原有用户和物品的表征的语义信息[10]。具体可分为基于距离的翻译模型[11]、基于语义的匹配模型[12]。Wang 等[13]提出了一种KGCN(knowledge graph convolutional networks)模型,它利用图神经网络分析知识图谱得到物品实体的表示向量,辅助推荐;文献[14]采用TransE(translating embedding)技术提取知识图谱得到实体和关系的表示向量,从而丰富物品的语义表示;另外,基于路径的方法[15]主要是挖掘基于图谱用户、物品之间多种连接关系作为样本,训练得到可以预测连接关系的模型。本文采用基于嵌入的知识图谱表示学习方法挖掘物品属性数据辅助推荐。
1.3 推荐算法
随着推荐技术的发展和对推荐算法的研究,现如今已有许多研究成果,其中,基于内容的推荐方法[16]是推荐引擎出现之初,应用最为广泛的方法,根据推荐物品或内容的元数据,发现物品或者内容的相关性,然后基于用户以往的喜好记录,向用户推荐相似的物品;协同过滤推荐方法[17]是根据用户对物品或者信息的偏好,发现物品或者内容本身的相关性,或者是发现用户的相关性,然后基于这些关联性进行推荐;此外,混合推荐技术[18]将现有的推荐方法组合,取长补短,从而获得更好的推荐效果。
随着深度学习技术的发展,神经网络已经应用到各种推荐场景,由于深度学习具有很强的特征提取能力,并且越来越多可用于增强推荐性能的辅助信息可被采集,因此越来越多的研究者使用深度学习技术提取文本、标签、社交关系等辅助信息来产生更加有效特征表示,以提高推荐性能[19]。文献[20]和文献[21]分别将经典的卷积神经网络和循环神经网络引入到推荐算法中,用于分析物品的标签、描述文本等辅助信息,从而提升推荐的准确性,这类模型通过重点分析物品的辅助信息来丰富物品的特征表示,在一定程度上缓解数据稀疏问题,但是往往忽略了辅助信息和物品之间的关联关系,且可扩展性差。针对这一问题,文献[13]和文献[22]引入知识图谱技术分析物品的辅助信息。文献[13]提出的KGCN 模型使用用户和物品的辅助信息构建知识图谱,清晰地表征了用户和物品与这些辅助信息之间的语义关系,采用基于嵌入的图卷积神经网络分析知识图谱得到用户和物品向量表示生成推荐。文献[22]采用物品的辅助信息构建知识图谱,并使用多任务学习的方式将知识图谱学习任务学习到的蕴含物品属性的物品表示向量融入到推荐任务中,从而增强推荐性能。为了构建更加精准的用户画像,缓解推荐系统的稀疏性和冷启动问题,研究者们提出将社交关系数据引入推荐算法。文献[23]提出的SocialMF(social matrix factorization)模型利用矩阵分解技术分析社交网络的信任传播,从而提高推荐的准确性。文献[24]提出的深度影响力传播模型(influence diffusion neural network,DiffNet),模拟用户受社交网络中邻居影响递归扩散的过程,从而得到更加精准的用户表示向量以提升推荐的准确度。文献[25]提出的GraphRec(graph neural network framework for social recommendations)模型使用图神经网络挖掘用户的社交网络得到用户的一个特征表示,同样使用图神经网络分析用户-物品交互网络得到用户和物品的特征表示,将两个用户特征表示进行拼接得到最终用户特征表示,最后使用用户和物品的特征表示生成推荐;上述融合社交关系的模型以及SoRec[26]、TrustSVD[27]、DICER[28]、DGRec[29]、EATNN[30]等模型大多忽略了社交关系数据的稀疏特性,并且大多只考虑了社交关系数据,没有同时融合物品相关的辅助数据。
从上述分析可以得出,知识图谱技术可以在清晰表征大量物品辅助信息的同时,也可以表示物品和对应辅助信息的语义关系,因此采用知识图谱技术分析物品的辅助信息可以有效帮助推荐算法利用物品辅助信息提升推荐性能。另外现有的融合社交关系的推荐算法大多忽略了社交数据的稀疏性且少有推荐算法同时也融合物品辅助信息。针对上述现有方法的不足,本文采用图卷积神经网络来提取社交关系这种图结构的辅助信息,创新地使用图中心性作为概率对节点邻居采样来过滤邻居,采用word2vec思想生成虚拟邻居来缓解社交数据的稀疏性,通过分析用户之间的社交记录,挖掘用户之间的信任关系,得到用户的表示向量。由于物品属性等辅助信息反映了物品的内容、类别等语义信息,本文采用基于语义的匹配模型来提取物品属性等辅助信息构建的知识图谱,得到物品的表示向量,最后通过得到的蕴含社交关系的用户表示向量和蕴含物品属性信息的物品表示向量生成推荐。
2 推荐模型
2.1 问题描述
在推荐系统中,假设有用户集合U={u1,u2,…}和物品集合V={v1,v2,…}。用户通过平台与物品交互,包括点击行为、浏览行为或评分行为,系统会生成一个交互矩阵Y={yuv|u∈U,v∈V},其中yuv的值为1 代表用户u和物品v之间存在交互,反之,yuv的值为0则表示用户u和物品v之间没有交互过。采用(ui,uj)这样的关系对表示用户社交关系S中用户ui关注用户uj。采用(h,r,t)三元组表示知识图谱G中大量的实体-关系-实体三元组,其中,h∈ε,r∈R,t∈ε分别代表三元组中的头、关系、尾,且ε、R分别代表知识图谱的实体和关系集合。给定交互矩阵Y,社交关系S和知识图谱G,模型旨在预测用户u对他未有过交互的物品v的兴趣。模型旨在构建一个预测函数=F(u,v;Θ),其中代表用户u将会访问物品v的概率,Θ代表函数F的相关参数。
2.2 模型描述
在实际生活中,人们选择物品时习惯倾听朋友的意见,这一现象表明,挖掘蕴含丰富用户关联信息的社交数据可以更好地构建用户画像,从而更精准地向用户生成推荐,对于社交关系数据的分析应该更注重影响力的传播,故本文采用图卷积神经网络来挖掘用户之间的潜在联系,分析用户之间的信任关系;另外,物品的辅助数据包含丰富的语义信息,知识图谱可以将这些辅助数据高效地组织表示起来,挖掘物品辅助信息构建的知识图谱可以构建更加丰富精准的物品特征表示,对于物品的属性数据的分析应该更注重物品与物品、物品和属性之间的语义关系,故采用知识图谱表示学习的方式来挖掘物品之间的潜在联系。挖掘社交关系数据和物品的属性数据这些辅助信息可以较好地缓解推荐系统所面临的数据稀疏、冷启动问题。基于以上思路,本文提出了MSAKR(multi-task feature learning approach for social relationship and knowledge graph enhanced recommendation)模型。该模型通过图卷积神经网络提取用户之间的社交关系,采用中心性邻居提取器筛选邻居,利用虚拟邻居提取器生成虚拟邻居,采用注意力机制聚集邻居,最终得到用户的特征向量;其次,采用多任务学习和基于语义匹配的模型来提取由物品属性构建的知识图谱,得到物品的向量表示;最后,根据得到的用户和物品特征向量计算生成推荐。MSAKR 模型结构如图1 所示。左侧推荐模块的输入为评分矩阵Y和社交关系S,物品表示向量经过交叉压缩单元(CCv)、多层神经网络(multilayer perceptron,MLP)得到vout,用户表示向量经过中心性邻居提取器(central neighbor extractor,CNE)得到按照中心性作为概率采样的邻居,经过虚拟邻居提取器得到虚拟邻居,用户和得到的邻居作为图卷积神经网络模块(graph convolutional network,GCN)的输入得到新的用户表示向量ugcn,再经过多层神经网络(MLP)得到uout,最终通过预测函数(prediction function,PF)得到用户u对物品v的预测评分;右侧知识图谱表示学习模块的输入为物品属性知识图谱,图谱中的头实体、关系表示向量经过交叉压缩单元(CCv)、多层神经网络(MLP)得到预测的尾实体,通过相似度度量函数对比和经过多层神经网络(MLP)得到的尾实体tv,从而拟合知识图谱中实体-关系-实体这样的三元组;推荐模块和知识图谱表示学习模块通过交叉压缩单元相互联系,多任务学习,最终得到一个能够预测评分的函数=F(u,v;Θ)。

图1 MSAKR 模型结构Fig.1 Framework of MSAKR
2.3 图卷积神经网络
本文采用基于空间的图卷积神经网络来挖掘社交关系数据中用户之间的潜在联系,采用节点中心性对节点的邻居进行采样,采用word2vec 思想生成虚拟邻居来缓解社交数据的稀疏性问题,其中中心性采样得到的邻居和生成的虚拟邻居共同视为节点采样所得的邻居参与图卷积神经网络的训练,使用注意力机制来对邻居进行聚集,最终得到用户的表示向量。
2.3.1 中心性邻居提取器
中心性是图分析中一个常用的概念,用以表达图中一个顶点在整个网络中所在中心的程度,也称之为中心度。在现实生活中,人们往往更容易听取有影响力人的意见,其中影响力在图数据结构中可通过中心度来体现。根据测定中心性方法的不同,可分为度中心性、接近中心性、中介中心性等。本文采用度中心性(degree centrality,DEG)对图节点的邻居进行采样,度量度中心性的公式为:

其中,CDEG(vi)表示节点vi的度中心性,deg(vi)表示节点vi的度,n表示图的节点数。得到各个节点的中心性后,对节点邻居的中心性进行归一化,以归一化后的数值为概率对邻居进行采样。如图2,对邻居节点的采样数为2,其中深色节点为按照中心性进行归一化概率采样被选中节点。

图2 图卷积示意图Fig.2 Schematic diagram of GCN
2.3.2 虚拟邻居提取器
社交关系数据普遍非常稀疏,有些节点可能没有直接相连的邻居,社交关系数据的稀疏性问题是将社交数据应用到推荐系统的重大挑战,本文采用word2vec 的思想为节点生成虚拟邻居以缓解社交关系数据的稀疏性,word2vec是从大量文本语料中以无监督的方式学习语义知识的一种模型,它被大量地用在自然语言处理中,随后Embedding 的思想被广泛应用到机器学习领域。在自然语言处理中word2vec 是针对句子,对句子中的词生成Embedding,本文将访问过同一个物品的所有用户视为一个“句子”,对“句子”中的“词”也就是单个用户生成Embedding,即通过word2vec 思想从用户物品的交互数据中得到用户的Embedding,把原来高维稀疏的数据映射到低维稠密的向量空间中,这样就可以用低维向量来表示用户,进而通过计算两个低维向量之间的相似度来衡量两个用户之间的相似性,本文采用标准化内积的方式来计算用户的相似度。
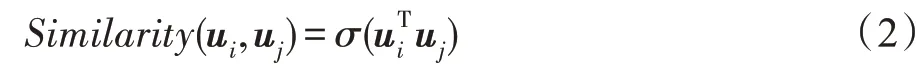
其中,σ代表Sigmoid函数,最后按照相似度排序,取出和用户向量相似度高的用户作为该用户的虚拟邻居。
该计算相似度的过程类似于协同过滤的思想,把user 看作word2vec 中的word,将访问过同一物品的用户集合视为句子,这样可以将没有直接关联,但是行为相似度很高的用户也采样为虚拟邻居关系,以缓解社交关系数据非常稀疏这一问题。如图3 所示,用户a 与用户b 购买了多个相同的物品,他们应该具有很高的相似度,同时用户a 关注了多个其他用户,而用户b 却没有关注任何用户,不利于从社交关系的角度为用户b 生成推荐,因此采用word2vec 的思想分析用户的行为记录,将和用户b 相似度高的用户(例如用户a)提取出来作为用户b 的虚拟邻居,一方面缓解了社交数据稀疏性这一问题,另一方面从用户行为的角度丰富了用户的邻居。
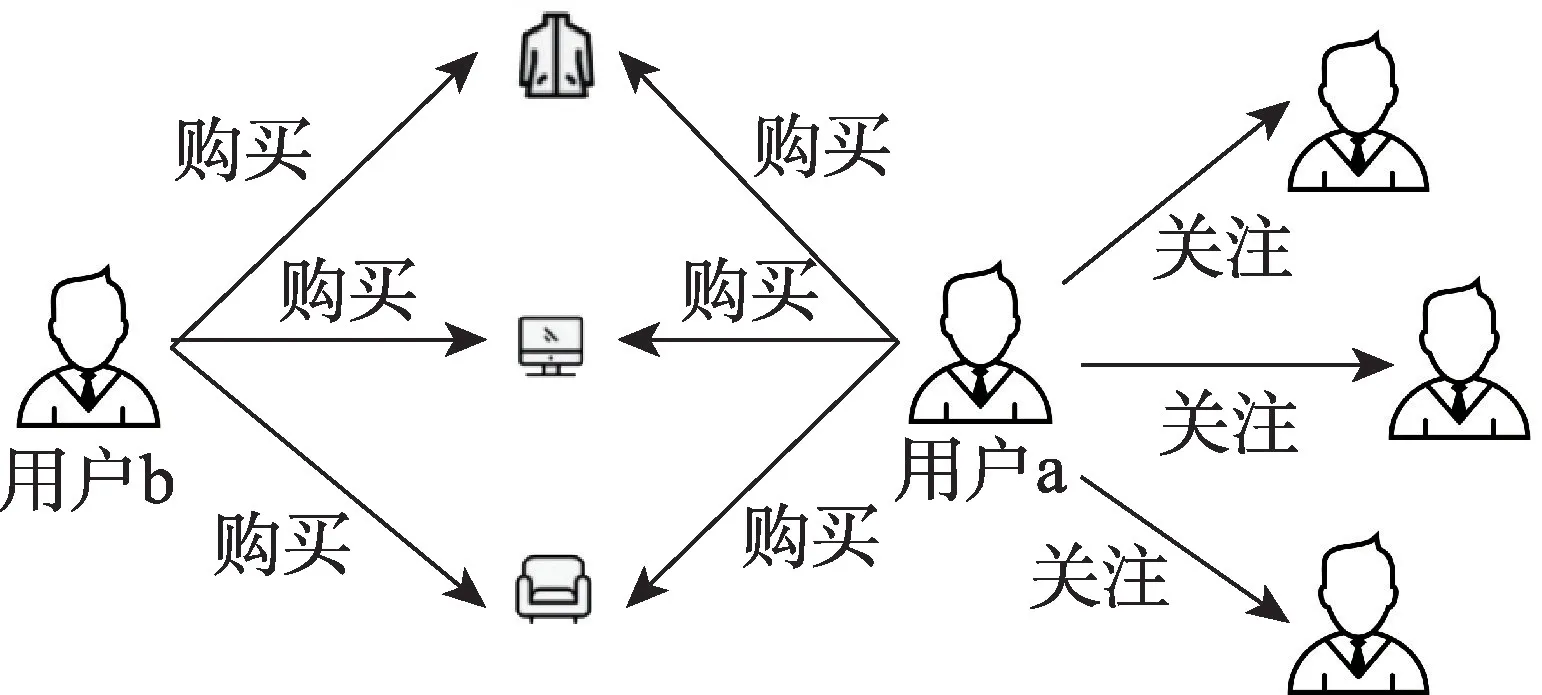
图3 社交关系示例Fig.3 Example of social relationships
2.3.3 注意力机制聚集层
常用的图节点邻居进行聚合的方式有Mean、LSTM(long short-term memory)、Pooling,本文采用self-attention 的方式来对图节点的邻居进行聚合。self-attention 可以在充分考虑各邻居对中心节点影响的同时,也能区分哪些邻居更为重要。该层的输入为邻居节点的特征向量集合h={h1,h2,…,hN},hi∈Rd与中心节点特征向量hC,其中N为节点邻居数,d为节点特征向量的维度,经聚集得到新的中心节点特征向量hC′,如图2。
该层先对邻居节点的特征向量进行非线性变换:
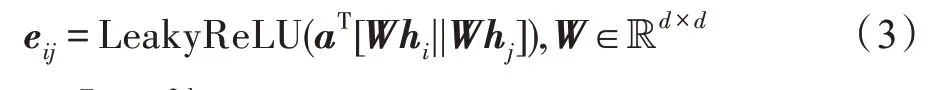
其中,aT∈R2d为权重向量,||为拼接操作。再采用Softmax 函数进行标准化:

中心节点hC的N个邻居节点经过self-attention聚集之后得到特征向量hagg,如下:

最终聚集得到新的中心节点特征向量hC′为:

其中,W、b分别为参数矩阵和偏置。
2.4 知识图谱学习模块
本文采用基于语义匹配的知识图谱学习模型来挖掘物品属性数据,从而找出物品之间的潜在联系,知识图谱模块和推荐模块采用交叉压缩单元进行连接,采用多任务学习的方式训练得到物品的表示向量。如图4 所示,电影数据集包括导演、体裁、演员等关系信息,此处以导演、演员两种关系为例,其中电影a 与电影b 由同一导演a 执导,电影c 由导演b 执导,在只考虑导演这一类关系时,电影a 与电影b 的相似度应该大于电影a 与电影c 的相似度;同理,电影a的主演是演员a,电影b 与电影c 的主演是同一演员b,在只考虑主演这一类关系时,电影a 与电影b 的相似度应该小于电影b 与电影c 的相似度。知识图谱学习模块可以综合考虑多类关系,生成精准全面的物品表示向量。
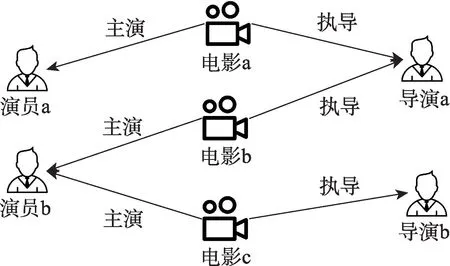
图4 知识图谱关系示例Fig.4 Example of knowledge graph relations
2.4.1 交叉压缩单元
多任务学习中的交叉压缩单元的处理思想来源于MKR[22]模型,可多层叠加使用,其结构如图5 所示。MKR 模型里的多任务学习思路可以很好地将知识图谱学习任务和推荐任务融合训练,能够更加充分地利用知识图谱来提升推荐性能。这一思路的核心思想在于推荐物品和知识图谱的实体有交叉,通过交叉压缩单元将知识图谱学习到的实体表示向量反馈到推荐模块中辅助推荐。

图5 交叉压缩单元示意图Fig.5 Schematic diagram of cross&compress unit
交叉压缩单元用于连接推荐模块和知识图谱表示学习模块,该单元的输入为推荐模块的物品特征向量vin和知识图谱特征学习模块的实体特征向量hin,输出为交叉融合后的vout和hout。
对于一个物品v和知识图谱里对应的实体h,首先构建交叉矩阵C∈Rd×d,其中d为物品和实体对应向量v和h的维度。

物品v和实体h经过交叉压缩单元的输出为:

2.4.2 基于神经网络的语义匹配模型
本文采用基于神经网络的语义匹配模型中的神经关联模型(neural association model,NAM)分析提取物品属性知识图谱。对于一个知识图谱三元组,该模型首先将头实体的表示向量和关系表示向量作为神经网络输入,经过多层神经网络得到一个隐藏层的输出,最后通过匹配这个隐藏层的输出和尾实体的表示向量来给出分数。头实体表示向量hin先经过交叉压缩单元得到hout,与关系表示向量r拼接,再经过MLP 得到隐藏层输出t^,最后采用相似度度量函数匹配输出的隐藏层和尾实体表示向量,并给出分数。
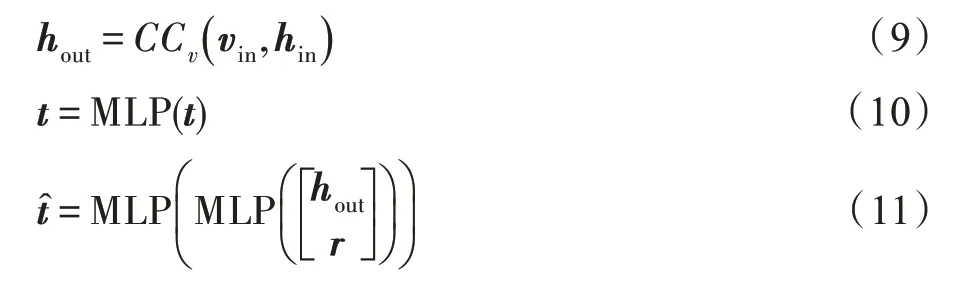
其中,CCv代表交叉压缩单元,MLP 为多层感知机,相似度度量函数为:

其中,σ为Sigmoid 函数,采用标准化内积的方法来计算相似度。
2.5 综合推荐
2.5.1 推荐模型
MSAKR 模型的推荐模块输入为描述用户和物品的特征向量u和v。给定用户的特征向量u,经过GCN 和MLP 处理后的uout为:
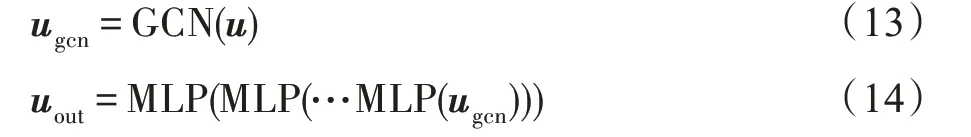
给定物品的特征向量v,经过交叉压缩单元和MLP 处理后为vout:
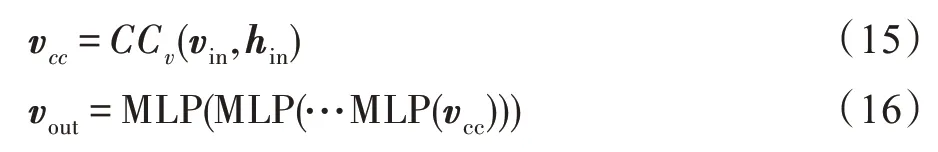
通过以上得到的uout和vout,计算用户u对物品v的兴趣概率公式为:

2.5.2 优化算法
损失函数为:

其中,ϑ为交叉熵损失函数;λ为正则化项系数;LRS是衡量推荐模型的损失值;LKG为衡量知识图谱表示学习模块中物品-关系-实体拟合程度的损失值。
MSAKR 模型的参数优化过程如算法1 所示。算法1 中,第1 到3 行是数据准备阶段,先构建用户社交关系的有向图,计算各节点的中心性,并按中心性对节点邻居进行采样,使用word2vec 思想生成用户表示向量,提取和用户相似度高的节点作为该用户的虚拟邻居,得到用户关系的邻接矩阵。第5 到9 行是推荐阶段,该阶段的输入为评分矩阵和用户关系的邻接矩阵。第10 到14 行是物品-关系-实体三元组拟合阶段,该阶段的输入为知识图谱数据G。在各个阶段把输入数据输入模型按照公式正向传播,随后对推荐模块使用Adam(adaptive moment estimation)优化算法,对知识图谱学习模块使用随机梯度下降(stochastic gradient descent,SGD)优化算法,反向传播更新模型参数Θ,多次迭代最终输出推荐预测函数=F(u,v;Θ)。
算法1MSAKR
输入:交互矩阵Y,知识图谱G,社交关系S。
输出:预测函数=F(u,v;Θ)。
1.初始化模型参数
2.构建物品属性知识图谱,构建社交关系有向图
3.按中心性提取邻居节点,生成虚拟邻居,得到最终的用户关系邻接矩阵
4.for 训练迭代次数do
5.//推荐任务
6.whilei+batchSize<len(Y) do
7.将Y、S中的miniBatch 传入推荐模块
8.使用Adam 算法,通过式(2)~(6)、(13)、(14)、(17)更新F的参数
9.i+=batchSize
10.end while
11.//知识图谱表示学习任务
12.whilei+batchSize<len(G) do
13.将G中的miniBatch 传入知识图谱模块
14.使用SGD 算法,通过式(7)~(12),(15)、(16)、(17)更新F的参数
15.i+=batchSize
16.end while
17.end for
3 实验分析
为了验证提出的MSAKR 模型的推荐性能,在相同的实验环境下,进行以下对比分析实验。
3.1 数据集
豆瓣电影评分数据集:豆瓣网是国内著名的社区网站,提供关于书籍、电影、电视、音乐、游戏、舞台剧等作品的信息,集品味系统、表达系统和交流系统于一体,其海量的用户和点评记录为本文提供了可靠的数据支撑,具有较强的工程应用意义。本文爬取了100 多万条评分记录,评分范围1~5 分,60 多万条社交用户相互关注的记录,7 万多条电影的属性信息,包括电影题材、导演、主演等。
Yelp 数据集:Yelp 是美国最大点评网站,囊括各地餐馆、购物中心、酒店、旅游等领域的商户,用户可以在Yelp 网站中给商户打分,提交评论,交流购物体验等。Yelp 公开数据集被广泛应用于推荐系统中,该数据集包含100 万条评分记录,评分范围1~5,同时也包含大量的商户的属性信息和用户的社交信息。
对于豆瓣电影评分数据集,将评分大于等于3 视为正样例,并且从豆瓣网爬取各个电影的详细信息(例如电影体裁、电影主演、电影导演等信息)来构建物品属性知识图谱,爬取用户之间的关注信息来构建用户社交网络。对于Yelp 数据集,将评分大于等于3 视为正样例,该公开数据集同时提供了商户的详细信息(例如商铺所在城市、商铺种类等)和用户的社交关系(例如朋友信息等),可用以构建商户属性知识图谱和用户的社交网络。各数据集的详细数据见表1。
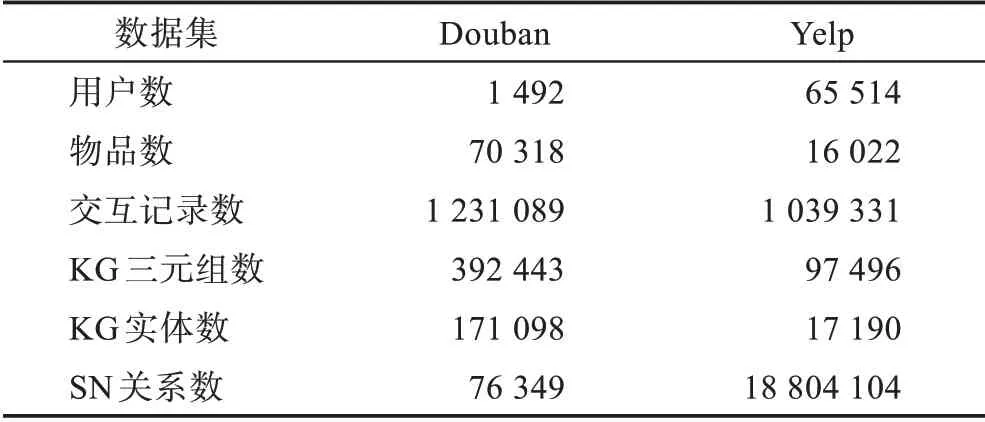
表1 数据集详细数据Table 1 Basic statistics for datasets
3.2 对比模型及实验设置
采用以下几个对比模型:
(1)MF[31]:最简单形式的矩阵分解模型,通过分解评分矩阵学习模型参数。
(2)EATNN[30]:Chen 等提出的一个高效自适应迁移神经网络,融合了社交信息来改善推荐效果。
(3)KGCN[13]:Wang 等提出的一种使用图神经网络分析辅助信息构建的知识图谱的推荐模型。
(4)MKR[22]:Wang 等提出的一种使用知识图谱分析辅助信息的多任务学习推荐模型。
(5)MSAKR:本文提出的融合社交关系和知识图谱的推荐算法。
实验将数据集过滤并序列化后,按照6∶2∶2 将数据集划分为训练集、验证集和测试集。采用ROC曲线下方面积大小(area under curve,AUC)和准确率(accuracy,ACC)作为CTR(click through rate)预测实验的评估指标,采用预测率(precision)、召回率(recall)和归一化折损累计增益(normalized discounted cumulative gain,NDCG)作为Top-K推荐实验的评估指标。设置用户和物品表示向量的维度d为32,batch_size 为128,正则化项系数λ为1E-6,图卷积神经网络的邻居聚集层数为2,各节点邻居采样总数η为8,虚拟邻居采样数占比γ为0.2,个数为小数时向上取整,推荐模块的优化器采用Adam,学习率为0.000 01,知识图谱表示学习模块的优化器采用SGD,学习率为0.001。实验验证得出,本文提出的模型在交叉压缩单元层数为1 时,各项评价指标效果更好,故在MSAKR 模型上交叉压缩单元层数设置为1,评分指标公式如下:


其中,TP(true positive)表示正样本被预测为正;TN(true negative)表示负样本被预测为负;FP(false positive)表示负样本被预测为正;FN(false negative)表示正样本被预测为负,P为正样本数量,N为负样本数量。AUC 被定义为ROC(receiver operating characteristic curve)曲线下方的面积。ROC 曲线的横坐标为假阳率(false positive rate,FPR),纵坐标为真阳率(true positive rate,TPR),得到ROC 曲线,然后对ROC 曲线的横轴做积分便可计算得到AUC 的值。IDCG(ideal discounted cumulative gain)为最理想的推荐排序结果按照DCG(discounted cumulative gain)公式计算的结果。
3.3 实验结果分析
3.3.1 各参数对算法的影响
首先分析了不同的参数d和参数η在CTR 预测中对AUC 和ACC 的影响。参数d代表用户物品表示向量的维度,d越大,表示用户和物品的向量就越复杂。MSAKR 模型在豆瓣数据集上,AUC 和ACC评价指标随参数d的变化如图6(a)。从图中可以看出当d=32,AUC 和ACC 评估指标取得了最好的结果,表示用户和物品的向量如果太简单会导致向量无法全面地描述用户和物品,反之如果太复杂会导致模型很难收敛。MSAKR 模型中的参数η表示节点邻居采样总数,η越大,表示可以影响用户的邻居节点越多,其中η包含中心性采样的邻居节点和生成的虚拟节点。MSAKR 模型在豆瓣数据集上,AUC和ACC 评价指标随参数η的变化如图6(b)。从图中可以看出当η=8,AUC 和ACC 评估指标取得了最好的结果,表示节点邻居采样总数的η如果太小会导致模型不能全面地提取邻居对中心节点的影响,反之如果太大会引入噪声邻居节点,导致效果变差。

图6 参数d、η 对模型的影响Fig.6 Influence of parameter d, η on model
3.3.2 CTR 预测对比
分析了所有模型在CTR 预测上的性能表现,各模型在两个数据集上的AUC 和ACC 结果如表2。其中在豆瓣数据集上,提出的MSAKR 模型较融合知识图谱的MKR 模型在AUC 评估指标上提升了0.013 0,在ACC 评估指标上提升了0.023 9,较融合社交关系的EATNN 模型在AUC 评估指标上提升了0.058 6,在ACC 评估指标上提升了0.021 1;在Yelp 数据集上,提出的MSAKR 模型较融合知识图谱的KGCN 模型在AUC 评估指标上提升了0.017 9,在ACC 评估指标上提升了0.013 6,较融合社交关系的EATNN 模型在AUC 评估指标上提升了0.034 1,在ACC 评估指标上提升了0.009 8。从实验结果可以看出本文提出的MSAKR,在CTR 预测上优于传统的推荐算法和单一融合社交关系或物品属性的算法,可见使用图卷积神经网络提取社交关系和使用知识图谱表示学习提取物品属性信息可以有效地提升推荐性能;采用图卷积神经网络来提取社交关系这种图结构的辅助信息,可以有效地模拟用户影响力的传播,从用户社交关系角度挖掘用户的偏好;其次,采用知识图谱表示学习提取物品属性信息,有助于构建精准全面的物品特征向量,从而提升推荐性能。另外,对比模型中的MKR 模型和本文提出的MSAKR 模型在结构上的区别仅仅是有无改良的图卷积神经网络模型,因此可以构成针对改良的图卷积神经网络分析社交关系模块的消融实验。从表2 的实验结果来看,加入改良的图卷积神经网络的MSAKR 模型在两个数据集的CTR预测实验中,AUC、ACC指标均有所提升,从而验证了本文提出的改良图卷积神经网络模块的优势。
3.3.3 Top-K 预测对比
针对豆瓣数据集,取η=8,d=32,各个模型Top-K推荐的预测率和召回率结果如图7,预测率代表预测的K个物品中预测正确的比例,反映了推荐的查准率。图7(a)表示K在不同取值时,各模型在豆瓣数据集上的预测率折线图,从图中可以看出MSAKR模型在预测率上较其他模型有较大提升,其中在K=5时,提出的模型较EATNN 模型提升6.73%,较KGCN模型提升15.62%,较MKR 模型提升了23.33%,较MF 模型提升了11.39%。图7(b)表示K在不同取值时,各模型在豆瓣数据集上的召回率折线图,召回率表示样本中的正例有多少被预测正确了,反映了推荐的查全率。从图中可以看出提出的MSAKR模型在召回率上较其他模型有较大的提升,其中在K=5 时,提出的模型较EATNN 模型提升10.13%,较KGCN 模型提升27.94%,较MKR模型提升19.17%,较MF模型提升42.62%,这表明,本文提出的MSAKR 算法在预测率和召回率指标上具有优越性。
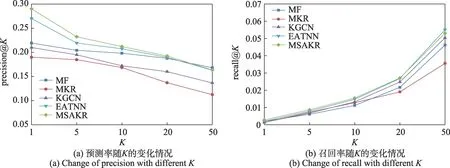
图7 豆瓣数据集上各模型Top-K 推荐效果Fig.7 Top-K recommendation effect of each model on Douban dataset
各模型在NDCG 指标的结果如表3,NDCG 是一种衡量排序质量的评价指标,反映推荐模型能否将用户最喜欢的物品优先推荐给用户的能力。从表3可以看出,提出的MSAKR 模型在K=1,5,10,20 较其他模型均取得了最好的结果,其中在K=5 时,提出的模型较EATNN 模型提升25.70%,较KGCN 模型提升19.19%,较MKR 模型提升5.93%,较MF 模型提升13.76%。另外,对比模型中的MKR 模型和本文提出的MSAKR 模型构成针对改良的图卷积神经网络分析社交关系模块的消融实验,从实验结果可以得出,加入改良的图卷积神经网络的MSAKR 模型在Top-K预测实验中,预测率、召回率、NDCG 指标均有较大提升,从而验证了本文提出的改良图卷积神经网络模块对于帮助提升推荐性能的优势。从图7 和表3可以得出,模型MF 忽略了用户之间的社交关系和物品的属性信息,由于评分数据稀疏问题导致模型MF在Top-K推荐中表现不佳;模型MKR 和模型KGCN融合了物品属性知识图谱,但未考虑用户受社交网络中邻居的影响,导致学习到的用户特征向量不够精准全面,从而影响推荐效果;模型EATNN 融合了用户的社交关系数据,但是社交关系数据比较稀疏,并且未考虑物品的属性信息,导致学习到的物品表示向量不够准确,从而影响推荐效果;本文提出的MSAKR 模型采用改良的图卷积神经网络来提取社交关系,采用word2vec 的思想为节点生成虚拟邻居以缓解社交关系数据的稀疏性,采用基于语义的匹配模型来挖掘物品属性知识图谱;采用多任务学习的方式,联合训练推荐模块和知识图谱表示学习模块。分别从用户受邻居影响的角度挖掘用户的偏好和从物品属性的角度挖掘物品的潜在联系,从而得到全面且准确的用户和物品表示向量,同时社交关系数据和物品属性信息这些辅助信息可以较好地缓解评分数据的稀疏性,因此提出的MSAKR 模型较其他基准模型在Top-K推荐上有较大的提升;此外,从表3 可以得出,提出的MSAKR 模型比基准模型在NDCG 指标有较大提升,表明提出的模型能够将用户最喜欢的物品排在前面推荐给用户,可以大大提升用户的体验。
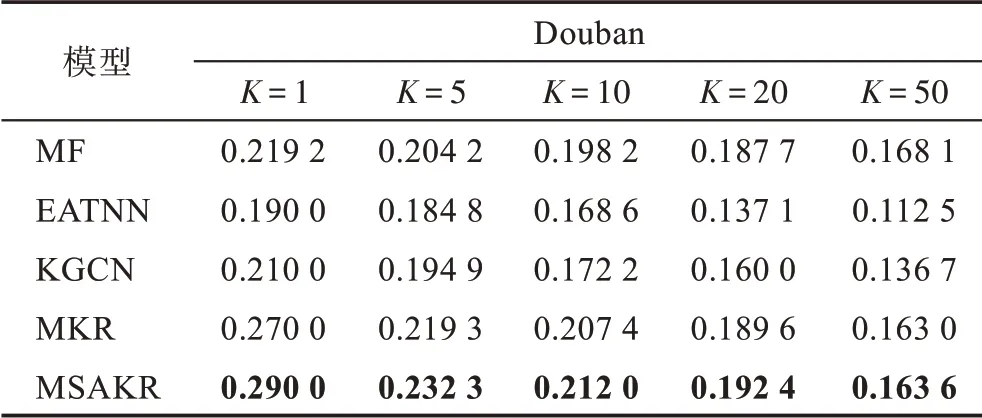
表3 各模型不同K 取值的NDCG 结果Table 3 Result of NDCG of each model with different K
3.3.4 冷启动及虚拟邻居提取器模块对比实验
冷启动是推荐系统面临的重要挑战之一,针对豆瓣数据集,设置用户冷启动实验,将数据集分为训练集和测试集,保证测试集中的用户不出现在训练集中,经实验得到冷启动各模型的NDCG 结果如表4。从表中可以看出,提出的MSAKR 模型在冷启动实验中较其他基准模型有较大提升,其中在K=5 时,提出的模型较EATNN 模型提升65.45%,较KGCN 模型提升68.31%,较MKR 模型提升120.87%,较MF 模型提升29.02%。本文提出的MSAKR 模型可通过用户社交关系数据,得到新用户关注人的表示向量,通过图卷积神经网络得到新用户的表示向量,该向量蕴含新用户邻居的偏好,实际意义为新用户的偏好和其关注的人的偏好相似;在得到新用户的偏好后,模型可以从物品的内容和属性角度,采用知识图谱技术深度挖掘物品之间的潜在联系,向用户推荐其可能感兴趣的物品。可以得出MSAKR 模型在用户冷启动实验上较其他基准模型有较大的提升。为进一步验证虚拟邻居提取模块的优势,设置如下对比实验,设置模型MSAKR 的邻居采样总数为6,虚拟邻居占比为0,得到模型MSAKR(-),也就让虚拟邻居不参加图神经网络的训练,两模型的结果对比如表5。从表中可以得出去除虚拟邻居提取模块的模型在多个指标略低于原模型,在真实的应用场景中,有的用户的邻居很多,有的用户的邻居个数极少甚至为0,存在严重的“长尾效应”,虚拟邻居提取器的引入,可以将用户行为相似度高的用户视为虚拟邻居,从而缓解社交数据的稀疏性,同时将用户行为相似度高的邻居偏好融合到中心节点用户中,有助于构建更加精准的用户特征向量,提升推荐性能。

表4 冷启动下各模型不同K 取值的NDCG 结果Table 4 Result of NDCG of each model with different K in cold start

表5 MSAKR 模型与MSAKR(-)模型的各项指标对比Table 5 Comparison of result between MSAKRand MSAKR(-)
4 结束语
由于现有的融合了社交关系的推荐算法大多忽略了社交数据的稀疏性,且少有同时融合物品的辅助信息,不能同时充分挖掘社交关系和物品属性数据来增强推荐性能。本文采用改良的图卷积神经网络来提取社交关系这种图结构的辅助信息;采用word2vec 的思想为节点生成虚拟邻居以缓解社交关系数据的稀疏性的问题;采用知识图谱表示学习来挖掘物品属性知识图谱;采用多任务学习的方式,联合训练推荐模块和知识图谱表示学习模块。此外,对比了一种传统推荐算法,一种融合社交关系的推荐算法,两种融合知识图谱的推荐算法,在豆瓣和Yelp 这两个真实的数据集上的大量实验结果验证了MSAKR 算法的准确性和优越性。但是本文采用的知识图谱学习算法只是简单表示学习,没有利用知识图谱强大的推理能力,同时采用社交关系辅助推荐,虽然提升了推荐准确性,但是由于采用的图卷积神经网络,训练时间长,由于神经网络是黑盒的,并没有利用社交关系数据提升推荐结果的可解释性。
猜你喜欢
小学生学习指导(低年级)(2022年5期)2022-05-31 08:33:14
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
疯狂英语·初中天地(2021年11期)2021-02-16 00:38:58
少先队活动(2020年12期)2021-01-14 01:47:40
电子制作(2019年11期)2019-07-04 00:34:38
少年漫画(艺术创想)(2019年2期)2019-06-06 07:47:02
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
中成药(2017年3期)2017-05-17 06:09:01
领导科学论坛(2016年9期)2016-06-05 14:59:58
小天使·一年级语数英综合(2015年8期)2015-07-06 06:23:32
