
人脸视频深度伪造检测方法综述
2023-01-17 09:30芦天亮杜彦辉
计算机与生活 2023年1期
张 璐,芦天亮,杜彦辉
1.中国人民公网络安全学院,北京100038
2.山东警察学院侦安大学信息查系,济南250200
2017 年12 月,一个名为“DeepFakes”的Reddit 用户正式发布了第一个利用深度神经网络生成的以好莱坞女星盖尔·加朵为主人公的伪造色情视频,这正式标志着人脸视频深度伪造技术的兴起。单词“深度伪造”(deepfake)源自“深度学习”(deep learning)与“造假”(fake)的组合,这成为利用深度学习实现人物换脸、表情编辑等视频伪造的一系列技术的统称,用以躲避识别、混淆视听、娱乐用户以及其他目的[1]。近年来深度伪造技术已经逐渐从娱乐领域渗透到了政治、媒体、体育等多个领域。在商业领域,电影特效、广告营销等是深度伪造技术两大应用方向。在政治领域,深度伪造技术易带来负面影响,尤其是在操纵选举方面极易带来负面的信任危机。例如2016 年美国大选期间由特朗普支持者所制作的佩洛西的伪造视频在互联网上被大肆传播;2018 年美国也出现了利用深度伪造视频伪造前任总统对时任总统进行辱骂的视频片段[2];近期伴随着俄乌战场形势的发展,在互联网上也出现了俄罗斯总统普京宣布已实现和平,以及乌克兰总统泽连斯基宣布放下武器的伪造视频。
深度伪造的技术原理简单,最常用的两种技术便是自动编码器与对抗生成网络(generative adversarial network,GAN)。近几年随着技术的发展,人脸视频深度伪造的成本与难度越来越低,出现了很多“傻瓜式”“一键式”的换脸软件与应用,这进一步使得互联网上各类针对人脸的深度伪造视频数量激增,颠覆了人们对于“耳听为虚、眼见为实”观念的认识。据统计,当前深度伪造产品泛滥成灾,增长率已超300%,其滥用已对私人权利、个人名誉甚至是社会稳定与国家安全产生威胁,因此对于人脸深度伪造视频,应当掌握一定的检测方法,以能够实现对绝大多数的伪造视频图像的鉴定分类。
本文以人脸深度伪造视频为研究对象,主要针对2019 年以来所公开的人脸视频深度伪造检测研究成果在采用特征的角度上进行总结。
1 数据集
数据集主要用来训练、验证及评估模型的质量与性能表现。与人脸识别、图像分类等传统计算机视觉任务相比,人脸视频深度伪造检测任务是近几年伴随着以DeepFake 为代表的图像/视频伪造技术的产生发展而诞生的,因此深度视频伪造的数据集种类与数量相对较少。当前使用较为广泛的人脸深度视频伪造数据集如表1 所示,其中DFDC(deepfake detection challenge)[3]、FaceForensics++[4]、Celeb-DF[5]等均是被广泛应用的数据集,但近几年随着研究思路的创新,针对不同技术方法、任务及特点也出现了许多新的数据集。

表1 人脸视频深度伪造检测各类数据集Table 1 Datasets of facial deepfake video detection
(1)UADFV、DF-TIMIT
UADFV[6]、DF-TIMIT[7]均是人脸视频深度伪造检测研究早期所提出的数据集,可作为基准测试数据集使用。其缺点在于数据集规模较小,伪造技术较浅,整体质量较低,因此检测难度低,各类基准方法均可取得较高检测率,无法有效判别模型的可用性。除此之外,DF-TIMIT 数据集带有原始视频的音轨信息,没有对音轨信息进行修改,因此可通过音画不同步对视频真伪进行检测,研究意义与价值相对较低。
(2)FaceForensics++
为弥补传统数据集伪造质量较低、伪造技术单一的缺点,FaceForensics++数据集被提出并被广泛应用。该数据集从YouTube 获取1 000 个原始视频,并对其分别运用多种篡改技术生成共5 000 个伪造视频,且具有三种不同压缩率(c0,c23,c40)。数据集的生成采用了DeepFakes、Face2Face、FaceSwap、Neural Textures 与FaceShifter 五种技术。其中,FaceSwap 是一种基于图形的方法,用于将面部区域从源视频传输到目标视频,其利用稀疏检测到的脸部特征点(landmarks)提取源人物与目标人物的脸部图像,并在脸部交换之后通过渲染模型与图像混合进行颜色校正并完成人脸替换;DeepFakes 基于自动编码器,编码器提取面部图像的潜在特征,解码器重建面部图像,为了在源图像和目标图像之间交换面部,需要两个编码器/解码器对;Face2Face[8]是一种面部重演系统,可将源视频的表情转移到目标视频,同时保持目标人的身份,是人脸属性编辑的典型代表;Neural Textures[9]使用原始视频数据来学习目标任务的神经纹理,模型只修改与嘴部区域相对应的面部表情,而眼睛区域保持不变,在模型训练过程中则使用Pix2Pix[10]中的基于补丁的GAN 损失;FaceShifter[11]克服了现有技术合成交换人脸时仅利用来自目标图像的有限信息的缺陷,解决交换的人像中可能存在的遮挡问题,提升面部替换逼真度。
“FaceForensics++”数据集特点是数据规模大,伪造技术种类较多,但是视觉效果较差,视频面部合成痕迹明显,因此常被用作模型训练,以进行后续的库内与跨库测试。
(3)Celeb-DF
鉴于上述各类数据集数据质量参差不齐的现状,Celeb-DF 数据集被提出与应用。该数据集从YouTube 上采集了59 位名人的590 个真实视频,视频考虑到不同的性别、年龄、种族的人群,并使用较为单一的DeepFakes 方式生成5 639 个平均长度为13 s的MPEG4.0 格式的伪造视频。数据集通过提升人脸分辨率,建立伪造视频与原始视频中人脸的颜色转换算法,更好地融合伪造区域与原始区域的边界等算法提高数据质量。
该数据集相较于之前各类数据集的整体质量较高,可以用于模拟真实环境中的伪造生成视频。其缺点是数据集整体规模较小,且正负样本不平衡,通常在模型的跨库测试中模拟现实世界中的伪造视频进行测试,衡量模型的泛化能力。
(4)DFDC
当前常用的人脸视频深度伪造检测数据集普遍存在数据规模较小的问题,基于此现状,DFDC 数据集被提出并应用。该数据集是目前较大的公开可用的领域内数据集之一,包含来自3 426 名付费演员的10 万多个视频片段,且均统一为10 s 的视频长度,便于模型的训练,减少预处理步骤。此外,数据集中的伪造视频通过多种DeepFakes、GAN 和Non-Learned方法生成,考虑了多种生成技术,相较于传统的UADFV 与DF-TIMIT 等数据集具有较高的多样性。
该数据集中视频来源为真人拍摄,故相较于其他数据集来说视频内容较为生活化,全真实场景,贴近现实。其缺点在于人脸所占部分较小,动作幅度较大时边界伪影会比较明显。
(5)DeeperForensics-1.0[12]
DeeperForensics-1.0[12]数据集共计包括60 000 个视频数据,其中真实视频50 000 个,伪造视频10 000个,总共1 760 万帧。数据集的生成采用了DF-VAE(deepfake variational auto-encoder)算法,考虑到质量逼真、多样性丰富、数量充足、视频有足够的压缩模糊等变化要求,其包括结构提取模块、解耦模块与融合模块,并通过光流差异最小化来优化时序的连续性,提高伪造视频的质量。
数据集的伪造生成充分考虑并模拟了现实世界的具体情况,考虑到不同的头部姿势、照明条件、脸部表情、相机角度、人物肤色、失真情况等多方面因素。其缺点在于伪造生成过程的方式较为单一,采用“面部识别-脸部交换”的自编码器模式。
(6)FFIW
传统数据集中,每一帧所出现的人脸数量通常为1,而在现实世界中的伪造视频却不受人脸数量的限制。同一帧画面中可能会出现多个人脸,并且选择其中部分或者全部的人脸进行篡改。因此为了增强模型在同一帧画面中的真伪辨别能力,Zhou 等人针对多场景下的伪造检测而建立了FFIW(face forensics in wild)数据集[13]。该数据集中共包括10 000 个高质量的伪造视频,每帧会出现多张人脸(最少1 张,最多15 张,平均为3 张人脸),其中部分或者全部人脸被篡改伪造,这更能代表真实世界环境中的伪造情况。数据集的生成采用了DeepFaceLab[14]、FSGAN(face swapping generative adversarial networks)[15]、FaceSwap 三种伪造技术。
该数据集除了视频级别的标注,还提供了人脸级别的标注,方便模型训练。伪造数据的生成基于对抗网络,节省人力成本,但是生成算法仍是基于人脸交换,因此数据集的难度取决于模型所采用的人脸交换算法。
(7)KoDF
当前大部分的数据集原始数据来源为YouTube截取或真人拍摄,其中绝大部分均为欧美人物主题,亚洲人在其中所占比例极低,数据不平衡现象严重。考虑到东西方人在脸型、骨形、行为习惯等方面的不同,Kwon 等人建立了一个基于韩国主题的伪造视频数据集KoDF(Korean deepfake)[16],其是第一个以亚洲人为视频人物主题的伪造视频检测数据集。数据集共包含403 个人物的175 776 个伪造视频与62 166 个真实视频,数据集规模巨大,且利用6 种不同的合成模型生成深度伪造视频。为了平衡亚洲人在现有的深度造假检测数据库中所占的比例,KoDF的参与者主要由韩国人组成,视频的收集考虑到人物的年龄、性别与所在地的分布,且在视频拍摄过程中引入了摄像机角度、焦距、位置、背景、道具、灯光等方面的细微变化。
数据集的生成采用了FaceSwap、DeepFakeLab[14]、FSGAN[15]、FOMM(first order motion model)[17]、ATFHP(audio-driven talking face head pose)[18]、Wav2Lip[19]六种伪造技术,数据质量整体较高。其缺点是质量差距较大,部分伪造视频中篡改痕迹明显,无法有效衡量模型分类能力。
(8)Vox-DeepFake
基于身份一致性的检测方法是人脸视频深度伪造检测的重要方法,且取得了较高的准确率,但是该方法依赖于具有大量参照对象的数据集,传统领域内数据集无法满足该方法的要求。因此Dong 等人建立了一个包含视频中所涉及人物的参考视频的数据集Vox-DeepFake[20],用于实现基于身份一致性的视频伪造检测。
Vox-DeepFake 数据集是在VoxCeleb 数据集基础上[21]进行建设的,是当前数据规模最大的数据集,包括4 000 个身份和超过100 万个伪造视频,平均每个身份对应25.2 个独立的伪造视频,因此提供了更大的参考多样性。该数据集的缺点是只考虑换脸这一种伪造类型,且数据集主要应用于“基于身份一致性”检测方法,虽然检测准确率较高,但主要针对具有参照视频的重要人物,故应用场景较少。
(9)WildDeepfake
当前大部分数据集中原始视频采集来源单一,且视频中场景单一,与真实世界中丰富多样的场景不符,在场景种类方面无法模拟真实现实。为克服此问题,Zi 等人建立了WildDeepfake 数据集[22],其中真实视频3 805 个,伪造视频3 509 个。数据集中的视频内容更加多样化,各种各样的活动(如广播、电影、采访、谈话和许多其他),不同的场景、背景、照明条件、压缩率、分辨率和格式等,更符合真实环境中的复杂情况。但该数据集整体规模较小,只能用作模型的测试与验证,无法有效利用其进行训练以增强模型表现。
(10)FFPMS
考虑到伪造视频中并非所有帧均为篡改帧与部分帧伪造质量较低,从而会影响到模型整体学习效果的特殊情况,Li 等人提出应用多实例学习的思想进行视频真伪检测,并基于该方法构建了FFPMS(face forensics plus with mixing samples)数据集,实现在帧级和视频级对不同的检测方法进行评估[23]。该数据集从压缩率为c40 的FaceForensics++数据集的每个视频中进行抽取,并在视频中出现多张人脸时随机对其进行部分或者全部的替换,因此视频包括帧级与视频级的数据标注。该数据集缺点是数据量较小,且整体伪造质量较低,部分视频伪造痕迹明显,无法用来进行有效的模型训练。
2 基于特征选择的人脸视频深度伪造检测方法
近几年伴随着深度学习的发展,人脸视频深度伪造的检测也逐渐摆脱了人工挖掘特征、传统机器学习分类的模式,使用各类深度神经网络进行检测鉴定。并在模型训练的过程中,利用多种训练方式不断提高精确度[24]。同时在特征利用方面,也呈现出选择范围广泛化、关键特征重点化的特点。本章首先总结了人脸视频深度伪造检测方面的难点,然后重点聚焦于近三年在该领域的研究成果,以模型所使用的视频图像特征为切入点,如图1 所示,从空间特征、时空融合特征、生物特征等方面,对在该领域内的最新研究进展进行梳理总结,并对这些检测方式中所呈现出的发展趋势进行分类整理,以期为后续的研究提供方向与借鉴。

图1 人脸视频深度伪造检测方法分类Fig.1 Classification of facial deepfake video detection methods
2.1 人脸视频深度伪造检测难点
人脸视频深度伪造检测技术在发展过程中出现了模型架构多样、特征选择灵活的特点,但当前的研究成果依然难以达到落地应用的标准。该挑战的难点主要体现在以下几方面:
(1)多模态数据的使用
在本文所介绍的各类常用伪造检测视频数据集中,大部分均不包括音频数据,只保留视觉数据。而当前随着伪造技术的不断发展,单纯使用图像画面,从空域、频域、时域等方面提取特征灌入模型进行训练以实现伪造检测的思路必将越来越呈现出局限性。因此对于多模态数据的使用也是该领域研究的难点之一,体现在如何有效提取多模态数据并将其特征化,以及如何有效融合多模态数据特征实现不同类型特征的相互融合、相互补充。为解决该问题,众多研究者从音画特征的提取与训练入手,取得了一定效果。但当前对于人脸视频深度伪造检测领域的多模态数据研究,依然处于起步阶段,研究人员与成果较少。
(2)训练数据质量与数量不一
人脸视频深度伪造检测常用数据集如前文所述,但其数据质量与数量不一。模型训练结果好坏极大程度取决于训练数据的规模与质量,因此如何有效利用已有数据集也是该领域研究难点之一。为解决该问题,众多研究者从创建新型数据集、采用各类数据增强方法等方面进行解决。
(3)代表性特征提取
模型泛化能力是人脸视频深度伪造检测模型的主要衡量指标,具体体现在模型跨库测试与跨伪造方法的测试等方面。因此,如何在训练数据中提取出不因伪造方法而异的区分性特征也是制约该领域发展的重要因素。为解决该问题,研究者从生成对抗、自监督、对比学习等方法提出了众多解决方案,并取得了一定成果。
2.2 基于空间特征的检测方法
基于空间特征对人脸深度伪造视频进行检测是较为传统和有效的检测方法,也是应用较广的特征选择方法,其是指在视频分解为帧的基础上,以每一个图像/帧为对象,在空域、频域等方面所进行的检测。因此,基于空间特征的检测方法适用于几乎全部的当前深度伪造视频数据集,将伪造视频的检测任务转化为针对每一帧图像的分类任务,属于经典的人脸分类任务范畴。基于空间特征的检测方法的优点在于简单有效,因为伪造视频势必会对原始图像的空域、频域分布产生扰动,所以研究提取这种局部与整体的不一致性便可作为模型训练与判别的特征。然而,由于每一帧的伪造是独立的,故在伪造当前帧时无法考虑到之前已伪造帧的情况,因此与真实视频相邻帧之间的连续性、关联性相比,伪造视频帧与帧之间存在着时空上的不连续性,而基于空间特征的检测方法却忽略了时序上的特征提取,导致特征提取的遗漏。同时,对于压缩率较高的数据集,由于其图像的空域、频域特征被压缩处理,故基于空间特征的检测方法效果较差。
基于空间特征的检测,根据所利用的具体特征不同,可以分为基于图像空间域的检测、基于图像频率域的检测和基于图像上下文空间的检测等。其中,基于图像空间域的检测是以图像/视频帧的像素域为主要对象,通过各类卷积神经网络(convolutional neural network,CNN)的卷积、池化等操作所提取特征进行检测的方法;基于图像频率域的检测,是指图像/视频帧的空间频率,是将图像看作二维平面的信号,以对应像素的灰度值(彩色图像对应RGB 三个分量)作为信号的幅值,其反映了图像的像素灰度在空间中的变化情况;基于图像上下文空间的检测,与前两者聚焦于完整图像不同,更加关注图像/视频帧内人脸及其他部分(即上下文)之间在空间上的区别联系,以其作为特征进行学习与分类。
2.2.1 基于图像空间域的检测方法
基于图像空间域的检测方法是较为传统且有效的检测方法。研究结果显示,直接将视频应用于CNN 及其各类变种网络中,并结合一定的注意力模块,便能取得较好的效果[13,25-37]。
朱新同等人[38]提取并融合YCbCr 与RGB 特征,使用Scharr 算子提取YCbCr 色彩空间中Cb 和Cr 分量的图像边缘信息,利用拉普拉斯算子(Laplacian)提取RGB 色彩空间中G 分量的图像边缘二阶梯度信息,并用EfficientNet-B0 进行分类。Nataraj 等人[39]提取了视频帧中像素级别的共现矩阵,并使用CNN 进行视频真伪的检测。Coccomini等人[33]将原始视频帧应用于EfficientNet[40]和ViT(vision transformer)及Cross-ViT[41]上,也取得了当前DFDC 任务的Benchmark,进一步表明了直接利用图像空间域特征进行伪造检测的简单有效性。
由于深度伪造视频中的人脸与真实人脸图像十分相似,而普通卷积在提取人脸面部特征时获得的卷积特征图过于单一,无法为模型后续检测工作提供有效依据。针对此问题,暴雨轩等人[34]在ResNet网络中引入分组卷积提取丰富特征,并在下采样过程中引入最大池化以强化关键特征,同时引入注意力通道为每个特征图分配不同权重,最后通过数据增强策略丰富数据集,并迫使模型学习到更丰富的特征表示。
传统CNN 网络进行分类时对于图像平移、扭曲、旋转等操作具有较高敏感性,容易带来误差从而影响后续模型分类。为克服此问题,Nguyen 等人[35]将胶囊网络应用于伪造视频的检测任务中,首先使用VGG-19 进行图像特征的提取,再将其灌入胶囊网络中。基于动态路由的胶囊网络的使用不仅可以有效避免图像平移、扭曲、旋转而带来的误差,同时能够使用更少的训练数据最大化地学习到有效信息。但是该模型无法避免胶囊网络训练速度慢、效率低的问题,因此也无法完全取代卷积神经网络进行人脸视频深度伪造检测。
前人工作主要是针对整幅图像的空间域特征进行广度提取,而不同区域中特征的重要程度与贡献度是不同的,因此会导致模型无法有效挖掘出局部的、具有区分性的分类特征。针对此问题,Zhao 等人[42]将人脸视频深度伪造检测表述为细粒度分类问题进行研究。如图2 所示[42],提出基于多注意力头的检测网络。该网络提出区域独立性损失作为损失函数,并通过多注意力头迫使网络注意到不同的局部特征,通过纹理特征增强块放大浅层特征中的细微假象,并在注意力图的指导下使用双线性池化聚合低层次的纹理特征和高层次的语义特征。类似的,为了增强图像伪造痕迹,抑制原始信息,Guo 等人[43]针对GAN 生成的伪造视频提出了预处理模块,利用多层的残差结构对图像进行卷积后作差,以突出和增强伪造痕迹。

图2 多注意力头的深度伪造检测Fig.2 Multi-attention head deepfake detection
对图像空间域进行分解与组合也是有效利用空间域特征的方法。Zhou等人[44]提出了融合人脸图像原始特征与基于块级别隐藏特征的双流网络,在图像空间域特征基础上结合了色彩滤波阵列(color filter array,CFA)、局部噪声残差这样的低级别相机特征,共同进行训练与分类。Zhu 等人[45]引入人脸的3D 重建中的信息作为原始空间域特征的补充,模型在库内检测取得了较好效果。但该方法只选择了重建后人脸的部分组成成分,因此涉及到部分图像特征被丢弃,并且对于无法进行重建的人脸图像不能进行训练和预测的情况。
由于单纯基于图像空域的伪造检测方法聚焦于单帧图像中的伪造痕迹提取,而不同伪造技术所对应的伪造痕迹特点不同,因此模型在泛化能力测试上表现较差。为增强模型跨库测试的能力,Liu等人[46]聚焦于增强模型鲁棒性,在挖掘空域特征之前,将原始图像划分为若干相同大小的块,并随机进行块内的像素打乱和块间的位置打乱,迫使模型挖掘更具有区分特性的伪造痕迹。但是该方法只是采用数据增强的思路提高模型鲁棒性,未能深度挖掘不同伪造技术的区别与共性,因此泛化能力提升有限。针对此问题,Chen 等人[47]采用对抗网络同时训练生成器与判别器,并用训练的判别器进行测试。其创新点在于生成器在伪造之前随机生成伪造配置,包括伪造区域、融合类型与融合比例,判别器在预测视频真伪的同时需要预测出对应的伪造配置,以此提高判别器对于不同伪造技术的泛化能力,在跨库测试中取得80%的准确率。类似的,Zhao 等人[48]也利用自监督学习策略,生成像素级别的标签数据,并认为经过伪造生成过程后的视频图像保留了不同源的特征,通过检测图像中像素之间的不一致性便可以判断视频真伪,因为真实视频图像的局部之间是具有一致性的。该模型在跨库测试中取得超过90%的准确率,是利用空间域特征进行人脸视频深度伪造检测研究中泛化能力最好的模型之一。但是该模型只能鉴定面部编辑的伪造视频图像,对于利用GAN网络直接生成全伪造图像无法进行鉴定与检测。
2.2.2 基于图像频率域的检测方法
基于图像频率域的检测方法在近几年研究论文中出现的频率不高,主要集中在挖掘图像频率信号中的高频信号、相位谱等,利用频域特征或者频域与空域的融合特征进行人脸深度伪造视频检测[49-52],具体体现在以下几方面。
目前基于空间域的检测方法倾向于过度拟合到某种造假算法所特有的纹理模式,因而缺乏泛化能力。当前的伪造生成模型在伪造过程中都必须经过上采样过程,而上采样之后图像的频域上和自然图像会出现明显的差异[53]。在图像频率域,高频信号祛除了颜色纹理,比低频信号更能够有效地区分真实与伪造视频[54]。因此,Li 等人[55]提出了自适应频率特征生成模块以挖掘频率信息,通过离散余弦变换(discrete cosine transform,DCT)将视频帧的各个通道的高频与低频信号进行分离后重新组合,再通过卷积与线性池化操作有效提取频率特征。同时,为了更好地挖掘伪造视频与真实视频之间的差异,文章还提出了单中心损失(single-center loss,SCL)作为损失函数辅助训练,以更好地聚焦类内差异,而拉大类间差异。Liu 等人[56]同样也是利用上采样过程中频域的变化,但认为真实视频与伪造视频频域中的相位谱较于幅度谱变化更加明显,更应当在模型学习中有重点的偏向和倾斜。
以上方法主要利用图像频率域特征进行深度伪造视频检测,却忽略了原始空域特征的像素特征,因此将频域与空域特征结合能够有效弥补两者不足,在库内与跨库检测中均取得较使用单一特征时更高的准确率。Wang 等人[57]则提出结合频域与空域的多模态方式,挖掘图像中不因伪造技术不同而变化的具有鲁棒性的伪造痕迹。Chen 等人[58]将原始的图像/视频帧划分为若干区域,考虑到真实区域之间差异较小、真实区域与伪造区域之间差距较大的特点,在将原始图像划分为若干区域的基础上,从频域特征与空域特征两方面计算两两区域之间的差异,以判断视频真伪。
2.2.3 基于图像上下文空间的检测方法
当前主流的生成人脸深度伪造视频的方法是利用生成对抗网络与自动编码器,其中前者更倾向于完全“从无到有”地创造出一个人的视频,后者倾向于在已有的真实的视频基础上,通过人脸识别与局部替换等步骤,生成面部替换或人脸属性编辑的伪造视频。而此类伪造视频,只是对于图像/视频帧中的人脸部分(或仅仅其中的局部)进行篡改,而画面中的其他部位(如人的躯干、图片背景)是不做更改的。因为被篡改和未被篡改的区域之间在理论上存在着必然的不同,所以利用这种不同进行人脸视频深度伪造的检测(即基于图像上下文空间的检测方法)也是近几年提出的重要方法。
Li 等人[59]较早地提出利用上下文进行伪造检测的思想。当前的伪造技术在实现细节上具有不同,所伪造的结果在特征表现上也是不同的,因此为了提高模型的泛化能力,应当聚焦于所有技术的共同点。文章观察到绝大多数的视频伪造算法都是把目标人物的脸裁剪下来,经过编辑后放到源人物的脸上,因此会有融合过程。既然要融合,就会有边界,边界的检测就可以作为判断视频真伪的标准。同时,因为此方法只关注融合边界,所以并不需要打好标签的真伪视频对作为训练数据,解决了数据量的问题。
如果在伪造过程中没有使用融合技术,上述模型就无法进行检测,并且该方法受图像噪声的影响很大,这意味着没有学习到人脸伪造检测的内在特征,检测效果不稳定。为克服此问题,Nirkin 等人[60]则在VGGFace2 数据集上预训练两个视觉网络,分别对应数据集中图像/视频帧中的人脸部位和扣除上下文背景信息部分,两个网络模型的输出作差便是人脸与上下文之间的差异信息。如图3 所示[60],配合第三个视觉网络,以待检测的真伪视频为训练数据,将三个网络的输出进行融合用作最后的分类。

图3 基于人脸及其上下文的深度伪造检测Fig.3 Deepfake detection based on face and context
2.2.4 基于空间特征检测技术测评结果
在人脸视频深度伪造检测方面,常用的指标是ACC 与AUC。其中,ACC(accuracy)为准确率,通过计算正确预测数量占全部测试集数量的比值获得;AUC(area under curve)为ROC 曲线所围出图形的面积。ROC(receiver operating characteristic curve)全称为受试者工作特征曲线,它是根据一系列不同的二分类方式(通常为阈值),以真阳性率为纵坐标,假阳性率为横坐标绘制的曲线。AUC 指数通过计算ROC 所围图形的面积来衡量分类器学习与分类效果优劣。
上文主要介绍了利用空间特征实现人脸视频深度伪造检测的各项技术方法,其中部分算法在数据集上测评结果如表2 所示(所列数据均为测试时的最好结果)。
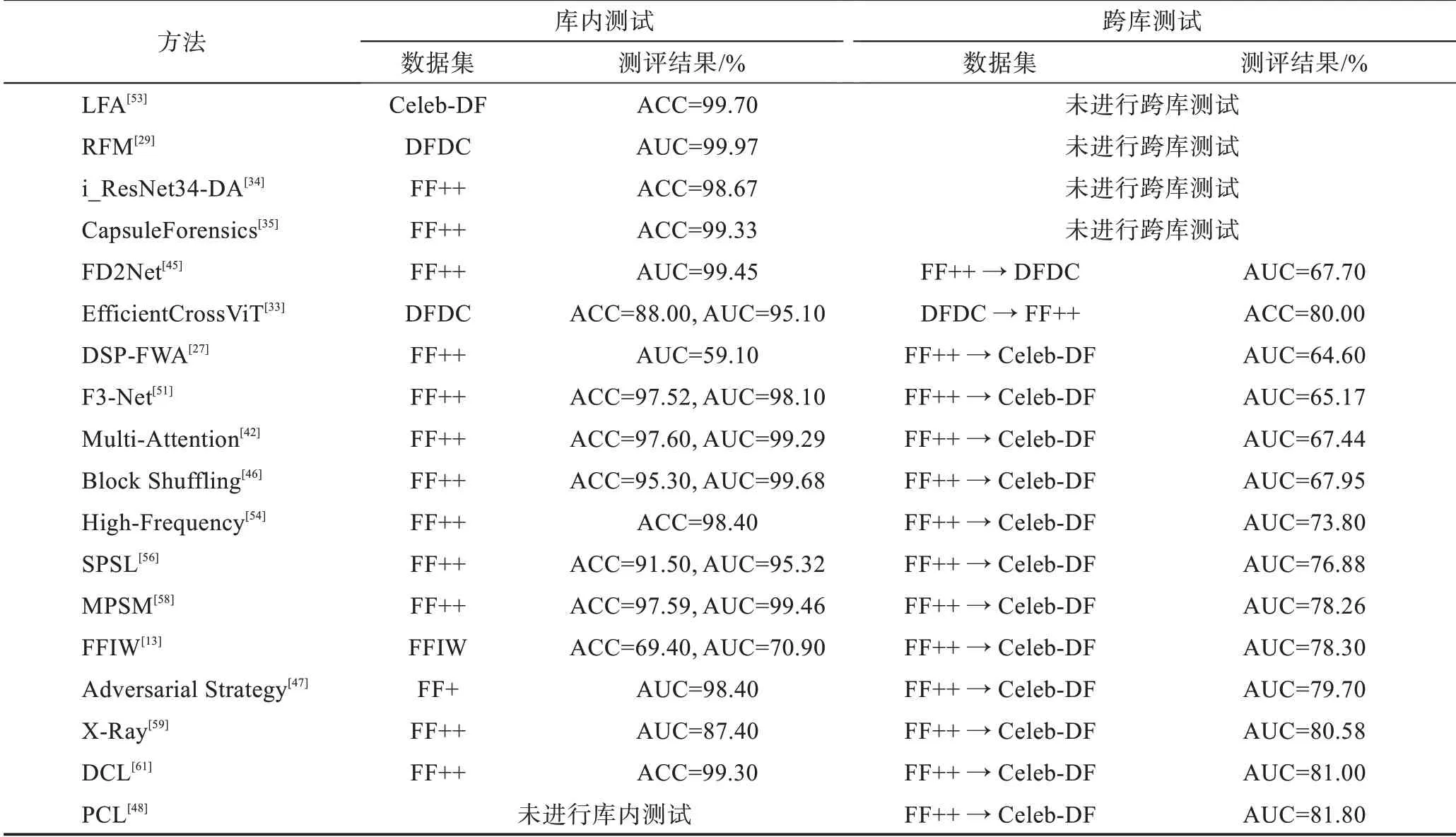
表2 基于空间特征的深度伪造检测技术测评结果Table 2 Test result of deepfake detection technologies based on spatial features
2.3 基于时空融合特征的检测方法
视频本质便是帧的快速切换。因此相邻帧之间在背景、人物动作上是具有联系的。而在人脸视频深度伪造的过程中,首先将原始视频分隔成帧,再对每一帧分别进行处理和伪造,最后再进行压缩编码,生成伪造后的视频。与基于空间特征的检测方法相对应的,基于时空融合特征的检测方法综合了空间与时间两个维度的不一致性,因此适用于几乎全部的当前深度伪造视频数据集。其优点主要体现在帧间特征的提取弥补了单纯利用图像空间特征所带来的特征缺失问题,在高压缩的数据集上的表现也稍好于后者。
基于时空融合特征的检测方法,根据所采用的模型结构与原理不同,可以分为基于循环神经网络(recurrent neural network,RNN)的时空融合特征检测、基于卷积的时空融合特征检测、基于像素位移的时空融合特征检测。其中,基于RNN 的时空融合特征检测主要依赖RNN(LSTM、GRU)挖掘帧与帧之间的连续性关系;基于卷积的时空融合特征检测通过精心设计的不同大小卷积核,挖掘时间上的连续性;基于像素位移的时空融合特征检测,是通过像素在时间域上的变化以及相邻帧之间的相关性来找到上一帧跟当前帧之间存在的对应关系,即光流法。
2.3.1 基于RNN 的时空融合特征检测方法
循环神经网络(RNN)在自然语言处理中经常被用来提取上下文之间的语义联系,在视频处理领域,也可用来挖掘相邻帧之间的相关性。近几年利用时空融合特征检测人脸深度伪造视频的工作中,基于RNN 的时空融合特征检测占据较大比例。
如图4 所示,Sabir 等人[62]直接将CNN 与RNN 进行组合得到较好的检测效果,首先利用CNN 进行每一图像/视频帧的特征提取,再使用RNN 挖掘相邻帧之间的时序关系。这也成为基于RNN 的时空融合特征检测方法的基本思路[63-64]。在此基础上,Chintha 等人[65]使用Xception[66]和Bi-LSTM 取代之前的CNN 和RNN,并在交叉熵损失基础上增加KL 散度损失以提高检测准确率。Fei 等人[67]发现人脸运动的振幅在视频中首先被放大,虚假视频会比原始视频表现出更严重的失真或闪烁,因此首先使用运动增强放大人脸的面部运动,然后用InceptionV3 提取每一帧的特征,最后结合LSTM(long short-term memory)提取时序信息。Wu 等人[68]则进一步在空间与时间特征基础上,增加了图像的隐写分析特征,检测隐藏的被篡改的痕迹,如图像像素的异常统计特征等。

图4 基于CNN 与RNN 的深度伪造检测Fig.4 Deepfake detection based on CNN and RNN
上述解决方案简单且经典,但是并没有结合深度伪造视频的独有特点,并不是专门为实现人脸深度伪造视频检测而设计的模型,因此在库内及跨库检测中并没有体现出太高的准确率。结合深度伪造视频所特有的视频帧之间的不连续性,很多研究提出了各自的解决方案。Amerini 等人[69]从伪造视频的生成阶段入手,认为视频在伪造的最后阶段对每一帧进行压缩编码时,在生成I 帧、B 帧、P 帧的过程中带来预测误差,可以以帧间的预测误差作为特征输入,经过CNN 的特征提取与LSTM 的时序提取,最终进行分类。
Masi 等人[70]提出一种双流网络,一路走普通的RGB,一路采用LoG 算子处理后的图像,用于抑制RGB 图像的内容信息,提取高频信号。两个分支均使用DenseNet 结构,之后使用融合模块将两路融合,并经过LSTM 抽取帧间的信息最后进行分类。另外,提出基于one-class-classification 的损失函数,让正样本拉近,同时推开负样本。
Montserrat 等人[71]为了增强模型的泛化能力,同时考虑每一帧的图像内容及伪造质量问题。每一帧在模型最终判断视频是否伪造的过程中所起到的作用是不同的,因此提出了自动脸部权重(automatic face weighting,AFW),通过自动加权,在预测时强调哪些是重要的,哪些是不重要的。如图5 所示[71],模型使用EfficientNet 提取帧的特征,并通过全连接层获取预测的逻辑概率与权重,最后连同特征本身一同输入GRU(gated recurrent unit)中提取时序特征,完成最后的分类。
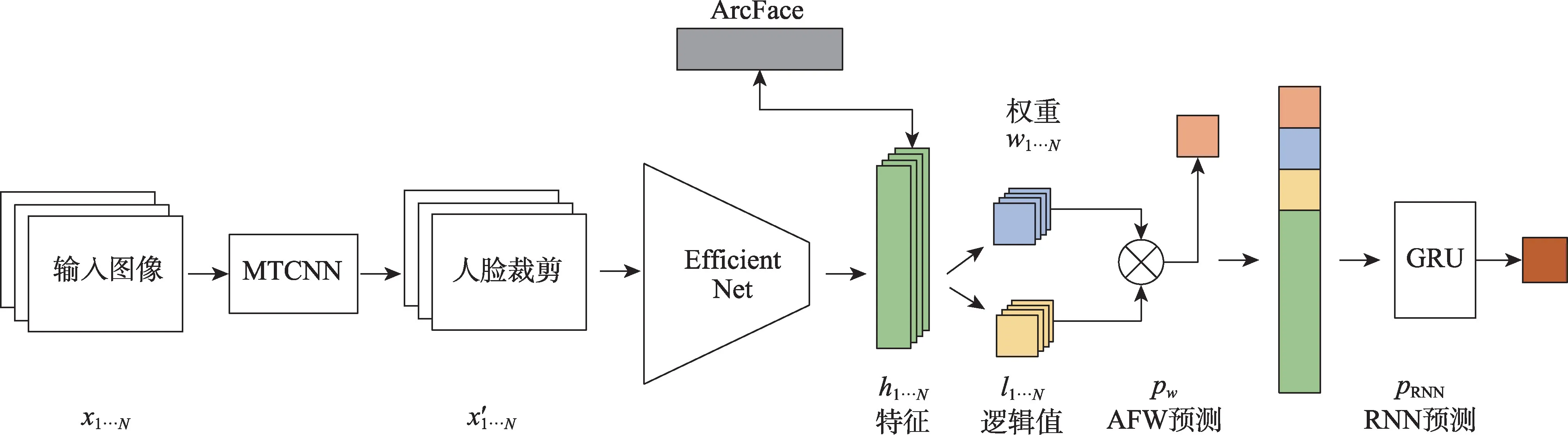
图5 基于自动权重分配的深度伪造检测Fig.5 Deepfake detection based on automatic face weighting
2.3.2 基于卷积的时空融合特征检测方法
与利用RNN 提取时序特征不同,基于卷积的时空融合特征检测更加依赖于卷积核的设计。通常的方法是对图像/视频帧的卷积核的时间维度进行设计,以提取帧间的连续性与相关性等特征。
邢豪等人[72]使用MTCNN(multi-task cascaded convolutional network)检测出视频中每一帧的人脸图像,并将64 个相邻帧组成一组输入灌入到3D 卷积网络中,以充分利用时间与空间特征时序特征。在此过程中,为迫使模型更好地关注脸部细节,也可在数据经过每一层卷积网络时结合注意力图,以更有针对性地提取特征[13]。但是此方法虽然使用3D 卷积,但依然更多地依赖空间上的特征,而对时间特征关注力度不够,这也是直接利用3DCNN 进行时序提取的普遍问题[73]。
为克服此问题,Zheng 等人[74]进一步提出利用视频不连续性实现深度伪造视频检测。首先,针对相邻帧之间的不连续性,如表3 所示,卷积核的时间维度进行手动设置,并将卷积核的长宽维度设置为1,使之能够在时间维度上充分挖掘特征,而不过多进行空间卷积。另外,考虑到某些情况下,视频帧间的不连续性并非出现在相邻帧,而是出现在相隔若干帧的两帧之间,因此选择使用将上一步骤中提取出来的特征信息灌入Transformer 中以捕捉长距离的不连续性。
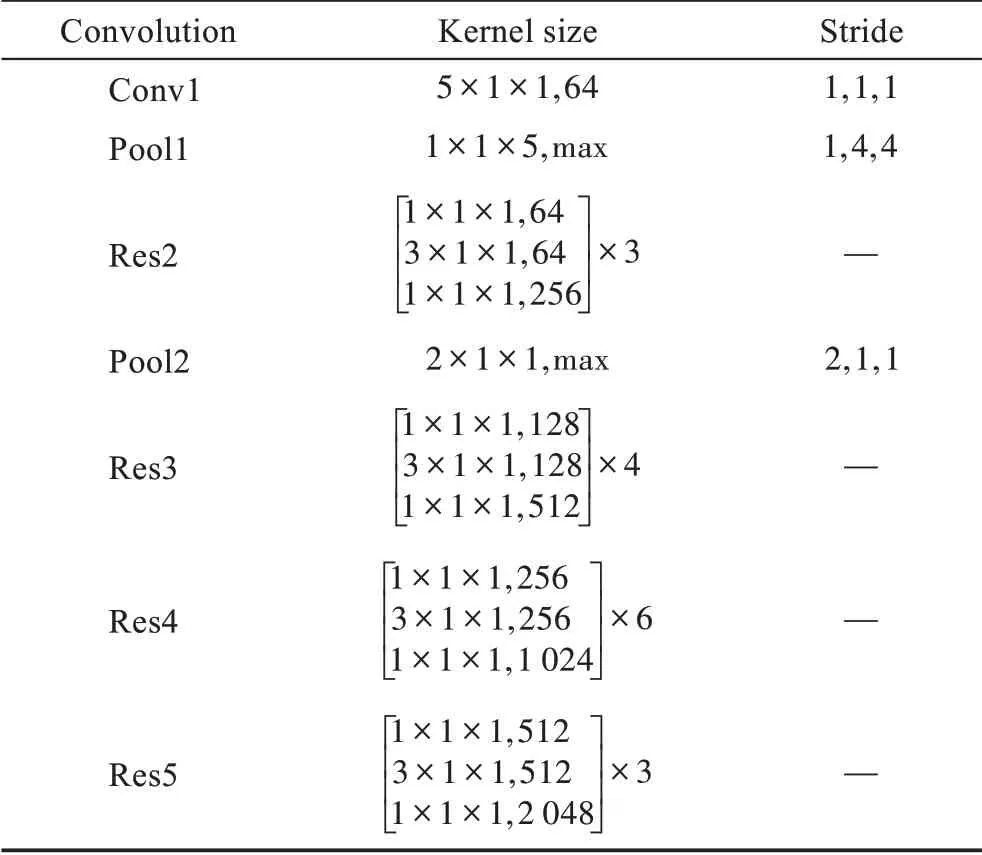
表3 模型参数设置Table 3 Model parameter settings
Li 等人[23]采用多实例学习的思想。在传统多实例学习中,实例与实例间是相互独立的,但由于DeepFakes 是单帧篡改的,导致同一人脸在相邻帧上会有一些抖动。于是,文章设计了时空实例,用来刻画帧间一致性,辅助DeepFakes 检测。具体而言,研究人员使用文本分类里常用的1-d卷积,使用不同大小的核对输入的人脸序列从多视角进行编码,从而得到时空实例,用于最终检测。
Gu 等人[75]进一步从局部的角度上时空上挖掘不一致,提出时空不一致学习(spatial-temporal inconsistency learning,STIL)模块。该模块可以嵌入任何的主干网络中辅助进行特征提取,创新地提出了在挖掘时间不一致时,除了利用卷积核在水平方向提取帧间不一致之外,也在垂直角度上挖掘时间特征,并将提取到的时间与空间特征进行拼接作为最终的分类特征。但是该方法对帧采取了稀疏采样策略,并且采样帧的间隔可能太大而无法捕捉到由细微运动引起的不一致。
为了克服上述问题,基于片段不一致(snippets inconsistency module,SIM)的方法被提出[76]。首先,将原始视频分为若干片段,各片段都由相同数量的相邻帧组成;然后,针对片段内部的不一致,分别从正反两方向计算水平与垂直时序特征;紧接着,对于片段之间的不一致,分别从正反两方向作差以表示前后片段之间不一致;最后,分别将片段内与片段间整合为统一的模块,嵌入到已有的主干网络中辅助特征提取并进行最后的分类。该模型在跨库测试中取得了接近80%的准确率。
2.3.3 基于像素位移的时空融合特征检测方法
基于像素位移即光流法(optical flow)。光流是空间运动物体在观察成像平面上像素运动的瞬时速度。光流法是利用图像序列中像素在时间域上的变化以及相邻帧之间的相关性来找到上一帧跟当前帧之间存在的对应关系,从而计算出相邻帧之间物体的运动信息的一种方法。通常将二维图像平面特定坐标点上的灰度瞬时变化率定义为光流矢量。
Amerini 等人[77]优先提出利用像素位移即光流法进行人脸视频深度伪造的检测。真实视频与伪造视频在所形成的光流的大小、方向、分布等方面存在差异,而这个差异可以被CNN 获取与分析。文章首先使用PWC-Net(pyramid,warping,and cost volume CNN-Net)[78]提取视频的光流特征,然后分别结合预训练的VGG16 和ResNet50 捕获光流差异,最后接入全连接层和Sigmoid 进行最后的二分类。模型在常见的DeepFakes、Face2Face、FaceSwap 的数据集上进行训练和测试,两种卷积网络分别取得了81.61%和75.46%的准确率。
Chintha 等人[79]在前人利用光流法进行检测的基础上,进一步利用OpenCV 的Canny 边缘检测方法获取每一帧的边缘信息以更加丰富特征表达,形成图像的“边-流特征图”。再与图像的原始RGB 以不同方式进行融合,共同形成输入模型的最终特征组合。根据融合方式不同选择不同的Xception 结构,并接入Bi-LSTM 网络挖掘帧间的关联性与相关性,最后使用全连接与Sigmoid 进行二分类。文章主要在常用的FaceForensics++、DFDC 等数据集上进行训练、验证与测试,训练与测试使用相同数据集时平均准确率最高达到97.94%,使用不同数据集时最高达到81.29%,表示了模型具有一定的泛化能力。
2.3.4 基于时空特征融合技术测评结果
上文主要介绍了利用空间与时间特征融合实现人脸视频深度伪造检测的各项技术方法,其中部分算法在数据集上测评结果如表4 所示(所列数据均为测试时的最好结果)。
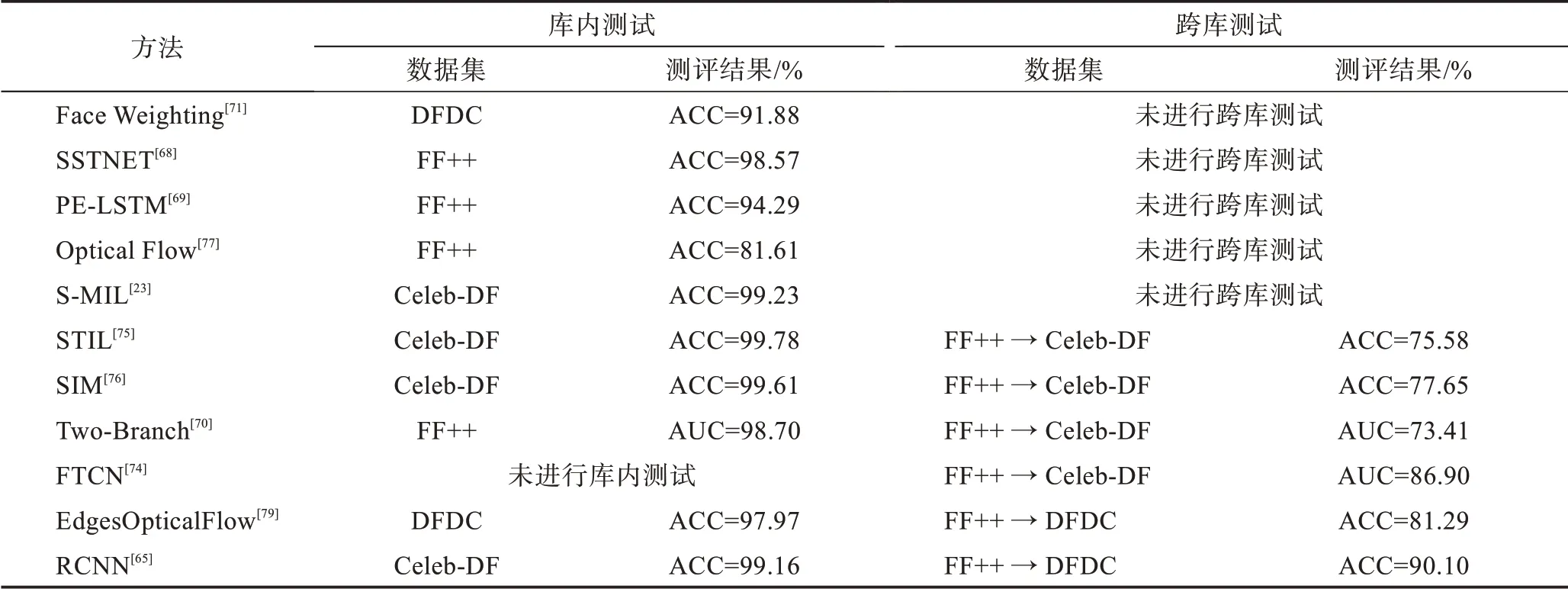
表4 基于时空特征融合的深度伪造检测技术测评结果Table 4 Test result of deepfake detection technologies based on spatial-temporal fusion features
2.4 基于生物特征的检测方法
人脸视频深度伪造归根结底是对人脸的伪造,作为伪造者来说,伪造的目的便是通过人脸的局部编辑、直接替换或者完整生成,以实现将目标人物人脸与源人物身份的缝合。伪造视频是对人身份的更改,因此从本质上来说,对人脸视频深度伪造检测的最有效方法是对视频中所出现的人的身份进行检测。前文所介绍的对于图片或视频的空间、时间、频率、像素等方面的检测只是对于载体的检测,而基于生物特征的检测则是基于人的,是不以伪造技术、承载介质不同而出现不同的。基于生物特征的检测主要依赖于两个假设:一是不同身份的人所表现出来的行为方式、说话习惯等是不同的,因此可以作为鉴定视频中所出现人物是否符合其所表现出来的身份的标准;二是真实的人与计算机生成和伪造的人相比,在行为表现上是不同的。真实的人是更具有生理特征的,例如眨眼频率、神态情感等。但是基于生物特征的检测方法却依赖于底层的图像处理技术,尤其是对图像或视频的空间处理与识别技术,如表情识别[80]、身份识别等[81]。基于生物特征的检测方法适用于大多数的深度伪造视频数据集,对于视频压缩率、是否包含音频等方面有一定的要求。该方法的优点在于脱离视频载体,从“人”的角度判别视频中人物对象的身份真伪,取得目前最高的跨库测试准确率;缺点在于该方法对数据集的要求相较于其他检测方法较高,泛化测试效果较好的检测方法均采用了辅助的外部数据集,主要用于对重要人物的伪造视频检测,应用场景较窄。
基于生物特征的检测方法根据具体使用的侧重点不同,可以分为基于身份一致性的检测、基于面部关键部位识别的检测、基于音画特征的伪造检测。其中,基于身份一致性的检测主要针对以重要人物或关键性人物为代表的具有大量该对象真实视频为参考的一类人群;基于人物生理信号的检测则是通过对图像/视频中所出现人物的面部(或整个头部)的行为、神态等进行识别分析,以判断是否是真实的人;基于音画特征的伪造检测方法则是以待检测视频为研究对象,对声音与画面在同步性、匹配性上进行关联关系分析,以判断是真实视频或是伪造视频。
2.4.1 基于身份一致性的检测方法
基于身份一致性的检测可以解释为“比较、对比”,通过对照参考集来判断检测集的真实性。此类方法的可靠性较高,但是应用范围相对较窄,应用的限制也较多,因此适合应用在涉及重要人物的视频的真实性检测上。
美国加州大学伯克利分校Hany Farid 教授团队的Agarwal 等人[82]对此类检测方式进行了较深的研究。文献[82]认为针对重要政治人物的深度伪造视频会对社会问题、国家安全造成不可估计的重大损失,因此针对重要人物专门建立了一套鉴定涉及其视频是否伪造的检测方法。文章对几位重要人物在公开场合的真实视频展开分析,并对不同人在讲话过程中的面部和头部运动进行降维后发现具有明显的区分特性,因此可以认定头部与面部动作可以作为视频中身份一致性检测的依据。文章首先对视频中人脸进行识别,并通过关键点(运动单元)从脸部提取20 个运动肌肉并对其动作进行建模;通过皮尔森相关性找出最相关的190 组特征向量,并将其作为最终特征用于模型的学习与分类。此类方法虽然检测效果较好,但是需要人工提取相关行为动作特征,并通过相关性分析确定与最终分类最相关的特征组合,效率较低,同时此模型的泛化能力较差。但是,此类方法的特点在于“定制性”,由于分类的高准确率,可将其应用于对重要商业人物与政治人物的保护上。
上述方法在特征挖掘时只利用到视频中人物的动态特征,而忽略掉静态特征,因此在特征选择上势必会丢掉一些有区别性的特征。为克服此问题,Agarwal等人[83]除了利用视频中人物的动态特征之外,也进一步以基于面部识别的静态生物特征进行特征补充。其中静态特征由VGG 提取,动态行为特征由FAb-Net(facial attributes-net)[84]提取,以两者作为与参照集的比对标准进行视频伪造的鉴定,实现了能够在4 s 的视频中判断出视频的真伪。
为了克服上述方法需要人工提取特征所带来的效率低下问题,Cozzolino 等人[85]提出时序ID 网络用来比较待检测视频人物与该对象的真实对照视频之间的相似度。训练过程如图6 所示[67],首先对视频中的每一帧提取出面部特征,并通过3D 模型将其映射成低维表示,然后使用时序ID 网络比较输入特征之间相似度,同时也作为判别器来与3DMM 生成网络进行对抗学习。3DMM 生成网络的作用是生成类似于经过DeepFake 篡改过的视频,通过对抗学习使得时序ID 网络能够学到有效区分的脸部特征。测试阶段如图7 所示[67],将时序ID 网络用作待测视频与对照参考视频的比较器,输出最终的分类结果。文章选择VoxCeleb2数据集进行训练,将其中的5 120个视频作为训练集,512 个作为验证集。每个Batch 包括64个96 帧的视频,其中的64 个视频又分别是8 个人的8段视频。测试集选择为DFD(deepfake dataset)数据集,准确率达84.8%。
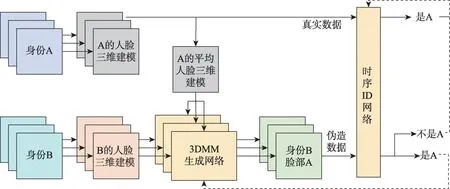
图6 训练过程Fig.6 Training process

图7 测试阶段Fig.7 Testing process
Dong 等人[86]提出利用人脸内部区域与外部区域的对比作为检测特征,结合外部参照集进行身份一致性检测。首先,将两组真实图像利用X-Ray[59]的方法分别交换内外脸生成两组训练数据,利用Transformer 分别提取人脸内部与外部区域,通过最小化内脸一致性、外脸一致性完成训练过程。在测试阶段,结合外部参照数据库,在其中找到与测试对象内脸A最接近的对应内脸A′,然后在参照集中找到A′所对应的外脸B′,计算B′与A的对应外脸B的相似度。测试对象的外脸同样进行如上相似度计算。通过以上计算,实现检测对象与外部参照集中对象的身份一致性检测,进而判断测试对象的身份真实性。该方法在模型的泛化测试上取得了较好的效果,在多个跨库测试中取得了96.34%的平均准确率。类似的,在测试时若不使用外部参照集,只是计算测试对象的内外脸之间一致性以判断对象真伪时,跨库平均准确率为87.01%。
2.4.2 基于人物生理信号的检测方法
基于人物生理信号的伪造检测是以视频中人脸动态图像为对象,通过使用Landmarks 对关键性部位的识别与追踪[87],分析其行为特征、生物特征[88]、生理特征,以识别视频中人物是否具有真实的人的生物特征的方法。
Yang 等人[89]认为伪造视频只是篡改替换了视频中人物的中心表情,而不是将整个头部进行替换。因此可以将中心表情的运动姿势和整个头部的运动姿势作为特征,结合支持向量机(support vector machine,SVM)分类器进行分类。
Li 等人[6]充分考虑到真实人物的生理特征。真实人物对象平均会在6 s 出现一次眨眼行为,而伪造视频则不会在伪造过程中对此进行建模,因此可使用VGG16 识别眼部特征,用LSTM 提取时序信号判断是否在一段时间内出现眨眼的行为以判断视频中人物的真伪。
同样基于人的生理特征,Qi等人[90]提出了利用心跳信号来检测视频中人物对象的真实性。文章认为,血液在流过脸部时会引起皮肤颜色的微小变化,这种变化肉眼无法看到,但通过视频中帧的像素点变化可以检测到,因此推测假的视频中的心率变化与真的视频中的心率变化不一致。文章首先在心率提取算法STR(spatial-temporal representation)[91]的基础上改进了从视频中放大并提取人物对象的心跳信号算法,并将其分解为RGB 三个通道的分量,获得运动放大时空映射(motion-magnified spatial-temporal map,MMST Map);然后将其作为输入,利用卷积池化与RNN 网络获取空间与时间的注意力模块;最后将所有结果进行合并,利用ResNet18 与Sigmoid 作为最后的分类器。Ciftci 等人[92]同样基于计算机视觉技术,从视频的人脸信号中提取生物特征,建立人脸纹理与心跳之间的关系,用作伪造视频的检测。Nguyen等人[93]在特征选择方面进行了创新,提出眉毛部分是合成图像中最易受到影响的区域,因此使用眉毛匹配作为特征进行伪造检测。
Matern 等人[94]提取眼睛、牙齿以及脸部轮廓等位置的特征来鉴定视频真伪,并使用Logistic 回归或浅层全连接网络等浅层分类器进行训练与分类。文章利用的特征主要包括全局一致性(global consistency)、光照估计(illumination estimation)和几何估计(geometry estimation)。其中,全局一致性指伪造视频中人物在全局上表现的矛盾性,例如瞳孔颜色、眼睛大小等不一致;光照估计指伪造过程中由数据隐式模拟入射光照时所带来的错误与不精准,容易在面部(尤其在鼻子附近)产生过暗的阴影,同时眼睛中的反射也会被简化为白色斑点或者消失;几何估计是指伪造过程中对原始人脸扣除或替换的过程导致缝合边界的出现或者细节的丢失。
2.4.3 基于音画特征的检测方法
音画特征即视频中声音与画面的相关特征,其包括时间上和内容上的同步性。目前部分的伪造视频存在关注于对视频内容伪造,而对音画匹配性注意力不够的问题,因此可以将其作为视频真伪鉴别的标准。但此方法只应用于同时包括声音与画面通道的视频,而对只有声音或画面的视频无法使用此类方法。
关注视频画面与声音的同步性是重要的检测思路与方法[95-96]。Chugh 等人[97]提出了画面与声音的模态不协调平分,通过训练集获取分数阈值来表征画面与声音的协调程度,以表示视频真伪。然而该方法对于视频音画特征的利用缺乏理论解释,也没有较为直观的说服力,而且最终检测效果依赖于通过训练集挖掘的分数阈值的质量,因此测试效果较差。为了克服该问题,深度挖掘视频中音画特征,并能够从理论上解释特征利用的有效性,应当着重于声音与画面人物动作的匹配性,其中使用最多的是对视频中声音与人物嘴部运动的相关性分析。
Haliassos 等人[98]利用伪造视频中的嘴唇运动的语义不连规则进行检测。如图8 所示[98],首先对待检测视频通过Landmarks 定位并裁剪出嘴唇部分;然后使用ResNet18 语义作为特征提取器提取语义特征,并将降维后的特征输入至时空网络中进行最终的分类。在具体训练之前,利用唇读数据集(lip reading dataset,LRD)[99],使用交叉熵作为损失函数,对Res-Net18 和时空网络进行预训练。此数据集是以嘴部的动作为训练数据,以对应的单词为标签,通过预训练学习到与自然嘴部动作相关的丰富的内部表征。在真正视频检测的训练中,则将ResNet 的特征提取层参数冻结,只对最后的分类网络进行微调。该方法在同数据集和跨数据集中的表现都非常优越,体现出较好的模型泛化能力。但是该方法需要借助已标注的其他训练数据(如唇读数据),在训练数据开发方面具有极高成本。

图8 基于嘴唇语义不连续的深度伪造检测Fig.8 Deepfake detection based on semantic irregularities of lips
为克服上述问题,Zhao 等人[100]采用自监督训练思想。首先,在训练过程中,分别提取成对真实视频中的音频与嘴部的视频进行对比学习,其中嘴部动作的提取利用Transformer 实现。通过训练,学习到真实视频中嘴部运动表示方式。然后,利用深度伪造视频数据集对Transformer 进行参数微调便可在跨库测试中取得较好效果。该方法虽然克服了预训练需要大量打标签的外部训练数据成本问题,但是在对伪造数据进行训练时,会冻结一半的网络,这可能会牺牲最终的检测性能。对应的,Haliassos进一步提出RealForensics 模型[101],采用BYOL(bootstrap your own latent)的自监督训练策略[102],并在BYOL 的基础上考虑声音与图像双模态,具体体现在分别利用声音与图像作为教师网络,利用真实视频中图像和音频模态的一致性,学习人物面部的运动表示。Real-Forensics在跨库测试中取得了较好的效果。
Lin 等人[103]同样关注嘴部的行为特征,通过检测嘴部动作与声音的匹配性来判断视频真伪。文章观察到一些词语的发音在嘴唇的行为特征上是具有较明显区别的,例如单词“Apple”的发音经历了嘴巴从扁平到聚合的过程,真实视频中对于这个单词的连续几帧的嘴部动作相较于伪造视频会更加连贯自然。基于此观察,文章建立了“音频-唇形”的映射,用于对视频中人物嘴唇行为与声音匹配性的检测,以达到视频真实性检测的目的。类似的,Agarwal 等人[104]也通过对视频中关键音节的识别来进行视频真伪检测,其主要通过音位(phoneme)和视位(visemes)的匹配情况来实现。音位是语言学中能够区别意义的最小语音单位。例如妈(ma)和发(fa)两个字的音调相同,用来对其进行区别的最小单位就是m 和f。视位表示发音一个词时的面部和口腔动作,是语音的基本可视构建基块。研究发现对于一些特殊音位,其视位也具有特殊性,因此重点关注视频中发音为M(mama)、B(baba)或P(papa)的单词相关的视位,通过比较音画的同步性来检测视频真伪。
Cheng 等人[105]在DFDC 中随机抽取2 000 段真实视频与10 000 段伪造视频,用VGG 网络分别提取其中声音与人脸特征,并通过降维在二维层面上分别展示真实与伪造视频中声音与人脸的欧氏距离,以此证明伪造视频中的音画不同步问题。同时,作者提取5 个人共计2 000 个真实语音片段的声音特征,并展示其在二维上的明显区别,证明声音是具备区分不同对象身份特征的。基于以上观察,即声音和人脸在一定程度上的同质性,提出从“声音-人脸”匹配的角度进行深度伪造检测的方法。为此,首先设计语音人脸匹配检测模型,在一个通用的视听数据集上度量两者的匹配程度。然后,该模型可以在不进行任何微调的情况下平稳地转移到深度造假数据集,从而增强了跨数据集的泛化能力。模型在DFDC和FakeAVCeleb 上的库内测试准确率较高,利用FF++和DFDC 的跨库测试也取得超过90%的准确率,但其未在跨库测试中使用常用的高伪造质量的Celeb-DF数据集进行测试。
除了嘴唇与声音的一致性检测之外,Agarwal 等人[106]还提出利用耳部和嘴部行为的协同关系判断是否是伪造视频。该方法认为真实的人说话时嘴唇(下颚)的运动和耳朵的微小运动(例如耳廓和耳道的微小形状变化)之间是有关联的,但是换脸技术一般只关注脸部替换,而不会对耳朵进行替换。但是此类方法限制较多,需要在视频中有完整耳部露出,因此应用范围相对较窄。Mittal 等人[107]进一步从视频与音频特征中使用MFN(memory fusion network)网络分别提取情感向量[108],从情感向量的角度比较音画的相似度关系。但是上述方法在特征的可解释性上较于嘴部运动分析较差,且测试效果相对较差,故相关研究较少。
2.4.4 基于生物特征检测技术测评结果
上文主要介绍了利用生物特征实现人脸视频深度伪造检测的各项技术方法,其中部分算法在数据集上测评结果如表5 所示(所列数据均为测试时的最好结果)。
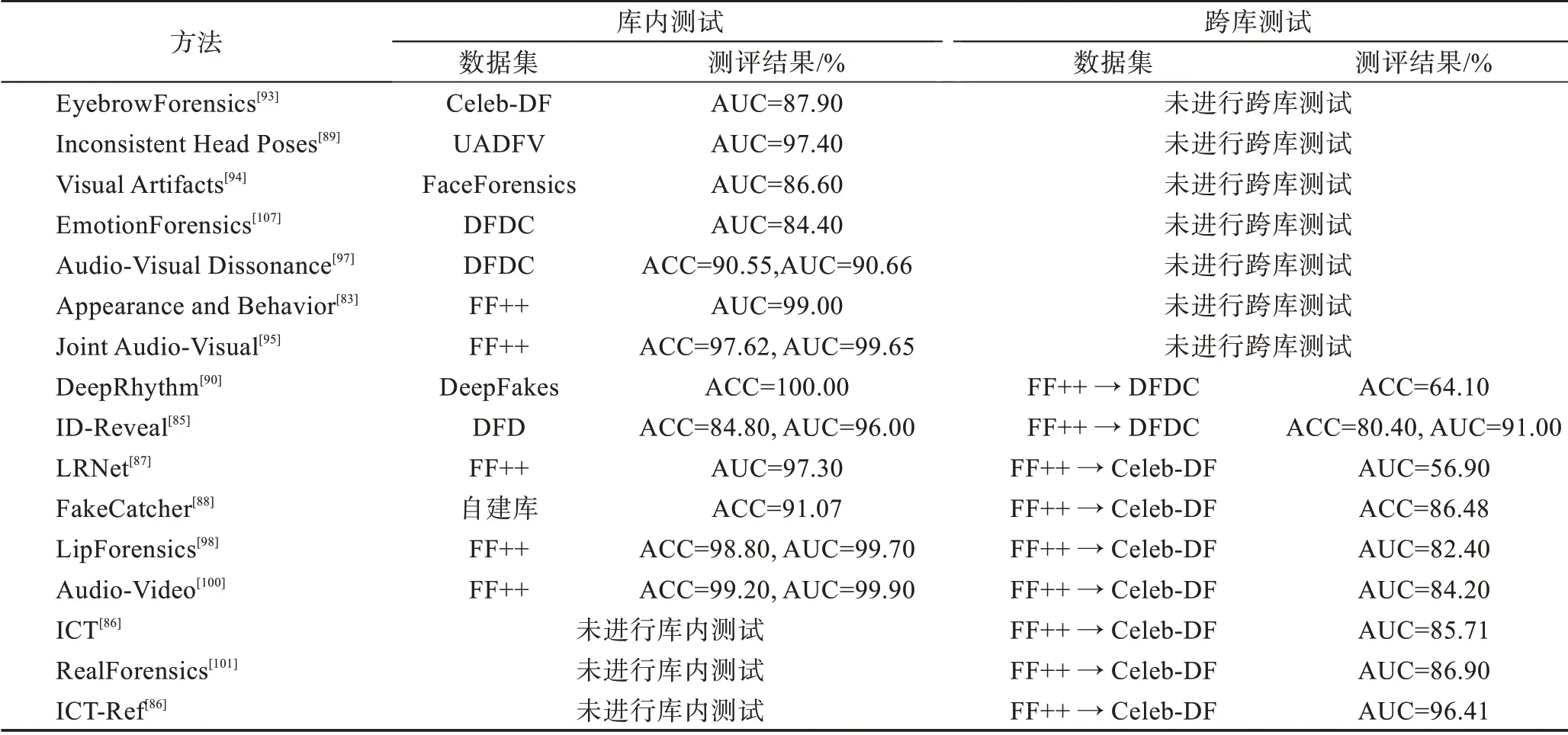
表5 基于生物特征的深度伪造检测技术测评结果Table 5 Test result of deepfake detection technologies based on biological features
3 其他检测方法
3.1 基于水印的检测方法
前文所述的所有方法均有较为明确的特征选择,并均属于被动检测,是在伪造视频已经产生并传播的情况下进行检测与鉴定,这也是目前绝大多数的人脸视频深度伪造检测所采用的主流思路。与被动检测相对应的是主动检测方式,最常用的便是基于水印技术的检测方法。该方法在生成、制作和发布人脸视频之前,在视频中加入水印[109]或者各类微小的信号噪声扰动[110],普通人眼无法看出区别,但任何对视频的二次编辑行为均会留下痕迹[111],通过对痕迹的鉴定以判断视频是否被篡改,并可以按照线索找寻篡改人。
Kim 等人[112]提出一个分散归因模型,使用一组与每个用户端模型相关联的二元线性分类器,每个分类器都由用户特定的密钥参数化,并将关联的模型分布与真实数据分布区分开来,即通过密钥实现将用户端模型的水印与无水印的用户进行区分,使得生成的视频具备用户属性,以保障实现后续对于伪造视频传播路径的追踪。
Yu 等人[113]主要针对由GAN 网络生成的各类伪造视频进行检测与主动防御。文章首先将数字指纹嵌入到训练数据中,然后发现并验证了数字指纹从训练数据到各类生成模型的专业性,并最后出现在最终生成的伪造结果中。整个过程对于图像级与模型级的其他干扰与扰动可以保持较好的鲁棒性。
Ma 等人[114]分析到之前的基于对视频关键帧编码进行伪造检测的主动防御方法具有耗时耗力的低效问题,因此提出了基于空间与时间特性的视频数字指纹生成算法。文章使用卷积网络和循环神经网络分别提取每一帧的空间特征与帧间的时间特征,以此作为视频的数字水印,实现了在传统图片水印的基础上补充时间信息的目的。Li 等人[115]提出并行的3D 卷积神经网络结构,提取连续帧之间的特征关联作为视频水印,以达到对视频复制的检测。Tang等人[116]提出一种对几何变换和空间变化均具有鲁棒性的视频哈希生成算法ST-PCT(spatial-temporal polar cosine transform)算法,它将视频视为三维矩阵,并在对视频执行DCT 变换后执行PCT 变换,这种变换可以提取时空域的特征,具有几何不变性。基于STPCT,进一步提出了用于视频拷贝检测的几何鲁棒视频水印生成方法,生成的视频特征被压缩并量化为紧凑的二进制哈希码,用于保证视频的完整性。
Koopman 等人[117]从视频的底层物理特性考量,将光响应非均匀性(photo response non-uniformity,PRNU)分析应用于人脸视频深度伪造的检测。数字图像的PRNU 模式是由数码相机的光敏感传感器的工件缺陷造成的噪声模式,这种噪声模式是高度个性化的,通常被称为数字图像的指纹。文章从待检测的视频中随机抽取部分关键帧,并将其进行分组。通过计算并比较各组视频帧的PRNU 得到视频的标准化互相关分数(normalized cross correlation score,NCCS)。实验证明,真实视频的NCCS 与伪造视频是不同的,可以作为视频真伪鉴定的标准。
Huang 等人[118]提出一种跨图像、跨模型的通用对抗水印生成方法CUMA(cross-model universal adversarial),只需少量的面部图像(128 张)进行训练,生成的水印就可以保护几乎所有的面部图片,使多种DeepFake 模型不能将其篡改。具体的,文章提出了两级扰动融合(two-level perturbation fusion)的策略,使得生成的水印进行图像级别融合(image-level fusion)、模型级别融合(model-level fusion),提高水印的迁移性。同时,为了减少迭代生成水印时步长对结果的影响,提高在不同模型之间的迁移性,CMUA使用TPE 自动搜索不同模型的更新步长。实验证明,该方法在伪造视频的检测与主动防御方面均具有较强的鲁棒性。
3.2 基于区块链的检测方法
近些年,区块链已在许多领域得到有效使用,到目前为止,针对基于该技术的人脸视频深度伪造检测问题的研究很少。它可以创建一系列唯一的不可更改的元数据块,因此是用于数字来源解决方案的出色工具。Hasan 等人[119]使用区块链与智能合约进行伪造视频的检测,认为只有视频具备可追溯性才可被认定是真实视频,否则是伪造视频。为此,文章提出智能合约用于存储数字内容及其元数据的星际文件系统(interplanetary file system,IPFS)的哈希值,因此使用以太坊智能合约来追踪数字内容的出处及其原始来源。每一个视频都有一个智能合约,该智能合约能够链接到其上级视频或来源视频,同理每一个视频也有一个指向其子视频或下级视频的链接,这样即使视频内容被复制多次,也有迹可循,可以按照链接找到其最原始的出处,对伪造行为也可做到有效追踪。
4 检测方法发展特点
从2019 年起,针对人脸视频深度伪造检测的研究数量增长较快,其中在特征选择、模型设计、训练思路等方面均出现了较多的新趋势与特点,主要集中在迁移学习的应用、注意力模块的使用以及非传统神经网络与学习方法的应用等方面。
4.1 特征选择
除了传统图像处理领域的特征提取之外,近几年在人脸视频深度伪造检测技术领域所涉及到的特征选择同样呈现出了一些新的趋势与特点。
一是特征选择更加细化。除了利用图像层面的空域特征之外,越来越多的研究文献倾向于进一步细挖图像频率的特征。且对于图像频率,也有更多的文献聚焦于高频与低频、相位谱与幅度谱等对人脸视频深度伪造检测的作用与价值。
二是更加注重生物特征的选择与利用。伪造视频归根结底是对人的身份的伪造,因此相较于从图像与视频的间接角度,鉴别视频真伪的根本还是从人的生物特征角度进行判别,从而对于生物特征的选择与利用成为该领域近几年新的特点。除了传统的眼球颜色、眼睛对称、视觉伪影等浅层生物特征之外,如耳部运动、心跳节奏、面部运动趋势等深层的生物特征也被用来进行真伪检测,并取得不错的效果,但当前应用最多的还是利用视频声音与人物嘴部运动表示之间的相关性作为伪造检测的特征。
4.2 迁移学习的应用
迁移学习的应用是当前人脸视频深度伪造检测方法研究领域所呈现的重要趋势特点之一,其出现包括两方面原因:一是相较于传统图像识别、分类等任务,视频真伪检测领域的训练数据的数量规模较小,数据整体质量参差不齐。同时深度伪造视频的检测依赖于底层对于视频人脸的提取、动作的识别,因此将成熟的模型进行迁移学习,能够最大程度在已学习知识的基础上,有效利用深度伪造视频数据集进行模型的训练与微调,节约训练成本,提高模型表现。二是随着生物特征在深度伪造检测中已证明其优越表现,基于视频中对象的生物及生理信号的提取训练将成为该领域的重要研究分支。其中将涉及到如嘴部运动[103]、语义连贯性分析[98]、人物对象微表情分析等领域的先验知识,因此通过迁移学习,将这些领域已成熟的训练模型用作底层特征提取,并在深度伪造数据集上进行微调,能够提高特征的针对性,进而提高模型表现。
Vision Transformer[120]与Swin Transformer[121]的预训练模型常被用来作为模型底层的特征提取器[31,33,57,122-125],通过在深度伪造数据集上对模型的微调以减少模型训练成本,提高模型最终的分类能力。Transformer的自注意力机制适用于挖掘图像中各Patch 之间的相关性,从而定位到图像中被伪造和篡改区域。同时,不同尺寸的Patch 设计也可以迫使Transformer 关注不同层面的图像特征,提高模型特征提取效率。
4.3 模型设计与训练思路
与图像分类、身份识别等计算机视觉领域传统任务相比,人脸视频深度伪造检测既有独有特点又有共通之处。前者体现在其作为伪造视频数据,与真实视频在空域、频域等方面必然存在偏差,因此研究的重点在于挖掘真伪样本之间的差异,而传统计算机视觉所研究对象均为真实或伪造数据,因此更多关注样本内容上的差异即可。后者体现在深度伪造检测的底层特征提取、特征融合、模型分类与传统计算机视觉任务是相同的,其中涉及到的人脸识别、动作识别等技术也具有共同之处。基于上述原因,在模型架构设计与训练思路两方面,人脸视频深度伪造检测与传统计算机视觉任务相比,也应当具有共同性与独特性,各类训练方法也能够迁移并应用到视频真伪检测模型的学习中。
4.3.1 损失函数的定制
在机器学习中,交叉熵常被用作分类问题中的损失函数。但随着越来越多复杂网络结构、训练方法的创新与使用,单纯的交叉熵损失无法完整地评估模型的好坏。另外,不同的损失函数对于同样的数据集,在相同的网络结构情况下,对最终的结果影响依然存在着较大的差异[126]。
另外,与传统视频图像的多分类不同,人脸视频深度伪造检测通常是“真-伪”两分类,并更注重挖掘真伪样本之间的差异。基于以上原因,使用单交叉熵作为损失的研究越来越少,更多的结合具体模型设计而提出的定制型损失函数被创新与应用。
Zhao 等人[42]提出区域独立性损失,确保每个注意力图集中在一个特定的区域而不重叠,并且集中的区域在不同的样本中是一致的。Sun等人[127]与Li等人[55]分别提出类内紧凑的损失函数与单中心损失,使同类数据更加聚集,同时推远非同类型数据。Chintha等人[65]则在交叉熵损失的基础上增加KL 散度作为补充。
因此,结合人脸视频深度伪造检测的任务要求,应当更有针对性地设计损失函数,使之能够更加突出真伪样本的差异性,聚集同类样本,排斥异类样本。
4.3.2 注意力机制的应用
注意力机制最早在自然语言处理和机器翻译对齐文本中提出并使用,并取得了不错的效果。在计算机视觉领域,也有一些学者探索了在视觉和卷积神经网络中使用注意力机制来提升网络性能的方法。注意力机制的基本原理很简单:网络中每层不同特征的重要性不同,后面的层应该更注重其中重要的信息,抑制不重要的信息。在人脸深度伪造视频中,对于人脸的替换与二次编辑只是针对视频中人物对象的完整脸部或者脸部中的具体位置(如眼睛、嘴巴等),而对于脸部以外的部位所篡改的概率较小,因此使用注意力机制能够更好地在图像层面让模型关注到易篡改区域。在频域层面,使用注意力机制也能够使模型更好地关注到随篡改行为有明显变化的频域范围[128]。
在模型设计中融入注意力机制是提高当前深度伪造视频检测模型表现的有效方法[13,42],聚焦于视频图像中的不同区域,提高图像特征的挖掘能力,配合模型实现分类。注意力作为模块,也可以插入到当前各类分类模型中,作为即插即用的组成部分[29,129],迫使模型挖掘视频图像底层特征,而非只关注域表层具有优良分类性能的特征,以提高模型的泛化能力。
4.3.3 学习方法的创新应用
由于领域内可用数据数量相对较少,单一模型性能有限,各类数据集之间特征差距较大所带来的对模型泛化能力的要求等多方面原因,近几年,越来越多的基于多任务和复杂模型的非传统神经网络结构与学习方式被应用于人脸视频深度伪造检测领域。
自监督学习的应用是近两年在人脸视频深度伪造检测领域被广泛应用的学习训练思路[47,61,86,100-101]。通过对无标签数据设计辅助任务来挖掘数据自身的表征特性作为监督信息,来提升模型的特征提取能力。自监督学习在深度伪造视频检测领域具有重要应用价值的原因有三方面:一是当前各类深度伪造视频数据集的质量参差不齐,既有Celeb-DF、Deeper-Forensics-1.0 等质量较高、贴近现实的数据集,也有FaceForensics++等数据整体质量较低、伪造痕迹明显的数据集,因此不同数据质量使得训练出的模型表现不一,无法达到应用级标准。二是当前深度伪造数据的规模与数量有待进一步提高,因此为更有效地利用当前数据集,采用自监督学习能够理论上无限制地扩大训练数据规模,确保模型能够获得充分训练,提高模型表现。三是实际部署的泛化能力要求使得模型必须能够兼顾识别挖掘出各类伪造数据的篡改痕迹,通过自监督的学习方式,迫使模型提取深层特征,而不因数据集种类的不同而提取不同层级的视频图像特征,进而提高模型的整体泛化能力,使之达到能够解决现实生活中伪造视频识别的目的。研究结果证明,自监督学习能够有效提升模型在跨库测试中的表现,无论训练集的伪造质量高低,其检测准确率均取得了较好效果[61]。
另外,多实例学习也是近几年在人脸视频深度伪造检测领域应用较多的学习方式。伪造视频的生成是将原始视频分隔成帧,然后对每一帧伪造后进行编码压缩发布。在这个过程中,可能存在帧与帧之间的伪造质量与效果不同,或者存在部分帧并没有进行伪造的情况。其中,不同帧的不同伪造质量会在训练阶段影响模型的参数学习,视频中部分未经过篡改的原始帧若被打标签为“被伪造”也同样会干扰模型的训练。基于此,可采用多实例学习的思想,把待检测的视频分割为若干个包(bag),其中包含若干个实例(帧),如果其中有一个实例被检测为伪造,则可以标记整个视频均是伪造的。因此,多实例学习可以仅在拥有视频级标签的情况下进行学习。Zhou 等人[13]与Li 等人[23]均在人脸视频深度伪造检测的过程中引入多实例学习的思想。
除此之外,元学习[127]、多任务学习[130]、孪生训练[30,131]也均是当前人脸视频深度伪造检测模型在训练学习阶段所呈现出的新特点。其中,通过元学习,可在多个数据域上训练,结合不同域的人脸对模型的贡献不同,使得模型更容易学习到具体每一个数据域的偏差特点;通过多任务学习,对于输入的待检测的视频,同时输出对其是否伪造的二分类结果与伪造区域的定位结果;通过孪生训练,使得在网络层的编码空间中学习一种能够很好地分离真实类和虚假类样本(即人脸)的表示[30,131],提高后续模型的分类能力。
5 总结展望
人脸视频深度伪造检测是近些年新兴的研究方向,也是人工智能领域的研究热点。本文主要对近三年的人脸视频深度伪造检测技术从特征选择方面进行了总结,主要包括以下内容:
(1)对常用数据集进行整理,包括领域内权威数据集和侧重不同学习方法、训练模型的新型数据集。以UADFV、DF-TIMIT 为代表的传统深度伪造数据集由于数量少、伪造质量低已不符合当前学术研究的要求。以DFDC、FaceForencies++、Celeb-DF 为代表的数据集是当前领域内研究常用的数据集,其中Celeb-DF 由于伪造质量较高常被用来模拟现实生活中的伪造视频,进而用于测试模型的泛化能力。另外,由于不同研究者的特征选择、模型结构、训练思路不同,进而提出若干新型数据集,如包含多实例人脸的FFIW 数据集、含有视频人物参考信息的Vox-DeepFake 数据集等。但总体来说,数据集的建立与伪造技术的发展之间仍然存在差距,若要使模型达到工业应用标准,势必需不断提高数据集质量。
(2)总结了基于空间特征的检测方法。根据挖掘空间特征的挖掘对象不同,分为基于图像空间域、图像频率域与图像上下文空间的检测方法。基于空间特征的检测方法集中于从单帧的视频图像中提取空域特征、频域特征与图像上下文差异特征,其优点是能够从图像底层挖掘真伪视频的差异,相对具有较高的模型泛化能力,但却忽略了视频中相邻帧之间由于伪造技术所带来的时序上不一致。
(3)总结了基于时空融合特征的检测方法。根据时序特征提取方法的不同,分为基于RNN、基于卷积与基于像素位移的时空融合特征检测方法。时空融合特征弥补了单纯基于空间特征的不足,将单帧的空间特征与相邻帧之间的时序不一致性进行统一融合,从“时间-空间”的角度综合分析视频真伪。但是如何有效表示时间特征,并如何将时间与空间特征进行融合,是重要的研究内容,直接关系到最终模型的测试效果。
(4)总结了基于生物特征的检测方法。根据利用的生物特征不同,分为基于身份一致性、人物生理信号与音画特征的检测方法。与空间特征、时空融合特征不同,该方法更从“人”的本质上判断视频中出现人物的真伪,进而判定视频真伪。此类方法在模型检测中取得不错的效果,但是对于生理特征的设计与挖掘需要部分的先验知识,特征提取效率较低。同时,外部参照集的使用降低了模型的应用范围,更适用于对重要人物的保护,同时也降低了模型的训练与预测速度。
(5)总结了基于水印技术及区块链的检测方法。包括基于数字签名、数字水印、区块链、智能合约的检测方法等。此类方法摆脱了传统的特征提取、模型训练的过程,但是需要大量的先验知识,应用场景也较少。
(6)总结了近些年各类检测方法所呈现出来的趋势,包括特征选择、模型设计、训练思路等方面的创新与特点。由于人脸视频深度伪造检测属于计算机视觉领域,但又有其独特性,同时该领域的数据集相对较少,因此需要结合任务的特点,选择设计合理的学习与训练策略,充分利用有限数据集,提升模型表现。
人脸视频深度伪造检测未来的发展方向,将体现在以下几方面:
(1)迁移学习与大规模预训练模型的使用。利用大规模数据集与成熟的网络模型,通过迁移学习实现对视频图像中丰富的人脸特征、局部特征的提取,以提高后续分类的准确度。
(2)数据集的真实性与模型泛化能力的提高。深度伪造技术发展迅速,越来越多的高质量伪造视频层出不穷,作为检测技术,应当更加贴近真实世界中的伪造现状,使用更具有泛化能力的模型检测各类伪造技术生成的篡改视频。
(3)主动防御技术的发展。目前绝大多数的检测均是事后的被动检测,只有主动防御才能从根本上杜绝伪造视频的生成与传播,这也是未来发展的方向。
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
当代陕西(2019年10期)2019-06-03
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
动漫星空(2018年9期)2018-10-26
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
数学小灵通·3-4年级(2017年9期)2017-10-13
