
基于轻量化YOLOv5算法的口罩检测方法研究
2023-01-16 12:46王福康闫存莹田存伟
现代计算机 2022年22期
王福康,闫存莹,田存伟
(聊城大学物理科学与信息工程学院,聊城 252059)
0 引言
近年来,由于全球疫情的蔓延,全球社会都处于一种极度重视个人健康的状态下,我国也积极地采用常态化防控举措,使我国疫情的蔓延趋势得到极大缓解。而佩戴口罩作为一种经济且安全的有效防护方式,也逐渐成为了人们外出、工作时的一种行为习惯,不仅保护了自己安全,同时也给别人带来了方便。因此,一种更加智能化的口罩检测方法,成为了一种新兴的研究热点,在当前世界处于疫情的大环境下,它的重要意义不言而喻。
口罩检测作为目标检测的一种,其发展趋势也在不断进行改善。传统的目标检测任务,通常是通过区域选择、人工提取特征,然后根据特定的检测方法来进行识别[1]。通过滑动窗口等方式,根据目标颜色、纹理、色度等特征,通过一些典型提取算法,比如梯度直方图(histogram of oriented gradients,HOG)等,然后采用分类器进行分类,比如支持向量机(SVM)进行分类[2]。这种情况下的设计过程较为复杂,且准确率不高,泛化性较差,实用性不高。随着2006年以来神经网络算法思想的发展,因其本身具有较强的特征学习能力,极大地节省了人工提取特征这一步骤,使得目标检测这一方向无论是在实时性还是在准确性上都有了很大提升。目标检测大致上分为两种,一种是两阶段目标检测算法,另一种是单阶段目标检测算法[3]。两阶段目标检测算法的第一阶段是生成可能包含目标的候选区域,第二阶段则是对候选区域的目标进行校准分类,然后得出结果,其经典算法包括Girshick 等[4]提出的R-CNN(region-CNN)、Fast RCNN[5]、Faster RCNN[6];而单阶段目标检测算法是直接对输入图像进行处理,省去提取候选框这一步骤,得到最终检测结果,常见的为YOLO系列算法。2015年YOLOv1[7]首先被提出,它与Faster RCNN 类似,将图片输入后,在输出层上直接确定边界框以及分类;Redmon 等[8]在2017年提出了YOLOv2 算法,它采用了批量归一化、高分分类器和先验框等策略,提升了识别事物的数量以及识别准确率。后面经过改进的YOLOv3结构,更是引入了特征金字塔结构网络(feature pyramid network,FPN)[9],它可以融合三个不同尺寸大小的特征图层,并且可以通过改变网络结构,使计算速度和准确率大幅提高。YOLOv4[10]算法在通过输入网络分辨率以及卷积网络层数和参数等方面,使用多种数据增强技术进行不断调试,得出最佳平衡。YOLOv5 则是在YOLOv4 的基础上进行改进,在输入端通过数据加载器进行图像传递,在灵活性与训练速度上要优于YOLOv4。
对于口罩检测问题,已有多位学者进行过研究。文献[11]在YOLOv3的基础上,对空间金字塔结构进行改进,替换损失函数,相较于YOLOv3,其准确率提升14.9%;文献[12]通过YOLOv3 和YcrCb 相结合的方式,把识别率提升到82.48%;文献[13]通过在原YOLOv4 的基础上,加入注意力机制,复用空间金字塔池化方法,提升感受野提取并融合空间特征能力,使其在口罩检测的任务中平均准确率均值达到94.81%。
本文考虑为了使模型能够适应移动端设备,提出一种轻量化YOLOv5的检测模型,通过改变网络深度、替换特征提取结构等方法,把浮点数压缩为原来的四分之一,并且使模型大小压缩至原来的37.5%,使其在不改变网络检测性能的前提下,大大提高算法模型的可移植性,来提升口罩识别的检测效率。
1 理论部分
1.1 YOLOv5算法原理
YOLOv5 算法是YOLO 系列的第五代目标检测网络[14],它是在YOLOv3 以及YOLOv4 算法的基础上加以改进而产生的最新YOLO 模型,并且它提出了四个版本,即YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x,这四个版本的精度大小依次递增。其详细参数如表1所示。
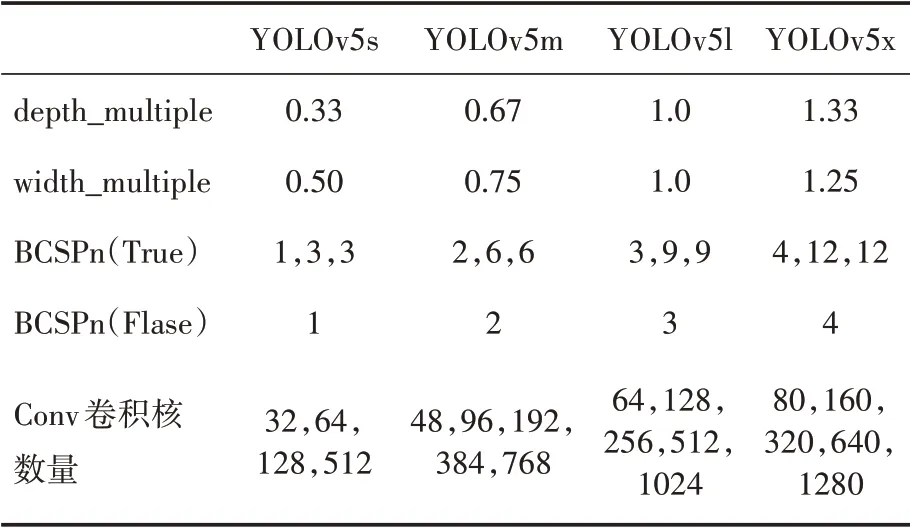
表1 各版本参数
本文的主要创新点在于使YOLO 模型轻量化,主要采用精度较小的YOLOv5s版本,在其基础上进一步改进结构,让模型能够在资源有限的移动终端上使用。YOLOv5s模型,也是经历了几次版本更迭,现在的较新版本是YOLOv5s-5.0,这一版本主要是将原来的瓶颈层(BottleneckCSP)模块转变为C3模块。C3模块相对于原BottleneckCSP 模块主要改动了两部分,把经历过残差输出后的Conv 模块去掉,concat 后的标准卷积模块中的激活函数也由LeakyRelu 变为SiLU。YOLOv5s 模型结构如图1所示,其中的CBS 为卷积模块,Res unit为残差模块,CSP1_X即由原BottleneckCSP 模块修改而成的C3 模块,CSP2_X 不包含残差模块,全部由卷积模块构成,SPP采用1x1,5x5,9x9,13x13的最大池化方式,是进行多尺度融合模块,FOCUS 模块是将输入进行Slice 切片操作,然后送入CBS 模块中。具体网络结构以及模块视图分别如图1、图2所示。

图1 YOLOv5s网络结构

图2 YOLOv5s网络结构各模块视图
1.2 GhostBottleneck 模块
GhostBottleneck 模块是根据GhostNet 模型中的“幻影卷积”(GhostConv)所设计。Ghost-Net[15]是一种新型端侧神经网络架构,它由华为诺亚方舟实验室提出。在提出时,作者认为在提取的特征中会含有大量的冗余特征图,为了保证对输入数据有详细的特征理解,于是在提取时,并不是所有特征图都要通过卷积操作得到,对于冗余的特征图可以通过更简单的线性变换解决,因此提出了GhostConv,其网络结构如图3所示。
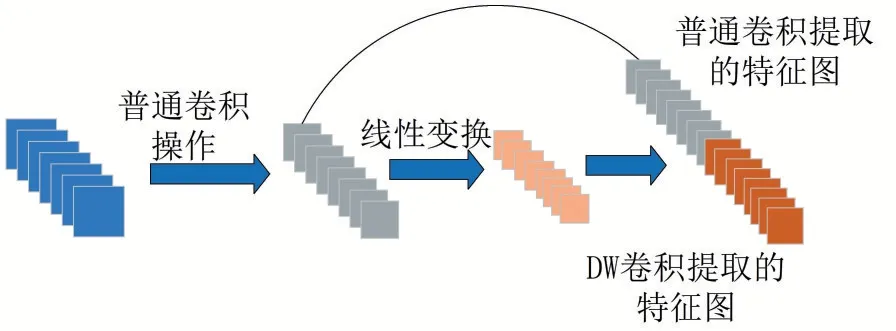
图3 GhostConv 结构图
其中Ghost 模块采用了深度卷积(Depthwise Convolution)作为更价廉的线性变换。分组卷积使通道间的相关性得到消除,使得当前通道特征仅与自身相关,显著降低了参数以及计算量。
在GhsotConv 中,假设对于给定的数据X∈R(h×w×c),其中h和w表示输入的高度和宽度,c表示输入通道数,分别用于生成n个特征图的普通卷积运算如公式(1)所示:

其中Y∈R(h'×w'×n)是生成的n个通道,大小为h'×w'的特征图,*为卷积运算,f∈R(c×k×k×n)是卷积核大小为k×k的卷积运算,b为偏置项。卷积过程中,由于存在的通道数和卷积核数量非常大,引起的FLOPs 数量也非常多,由卷积层生成的特征图会存在很多冗余,并且一些特征图十分相似,可以理解为部分特征图是由一次卷积运算生成的,假设m个特征图由一次运算生成,那么此时的卷积运算如公式(2)所示:

为了简单起见,把偏置项b省略,这里f'∈R(c×k×k×m),且m≪n,为了使输出特征图大小一致,进一步获得所需要的n个特征图,提出把Y'中的特征图用一系列线性运算,生成s个幻影特征图,线性运算如公式(3)所示:

其中y'i是Y'的第i个特征图,Φi,j表示第j个线性运算,每个Y'中的特征图都通过线性变换Φi,j得到GhostConv 输出特征图集合Y中的s个幻影特征图。

使用GhostConv 构建GhostBottleneck 模块,其GhostBottleneck网络结构如图4所示。
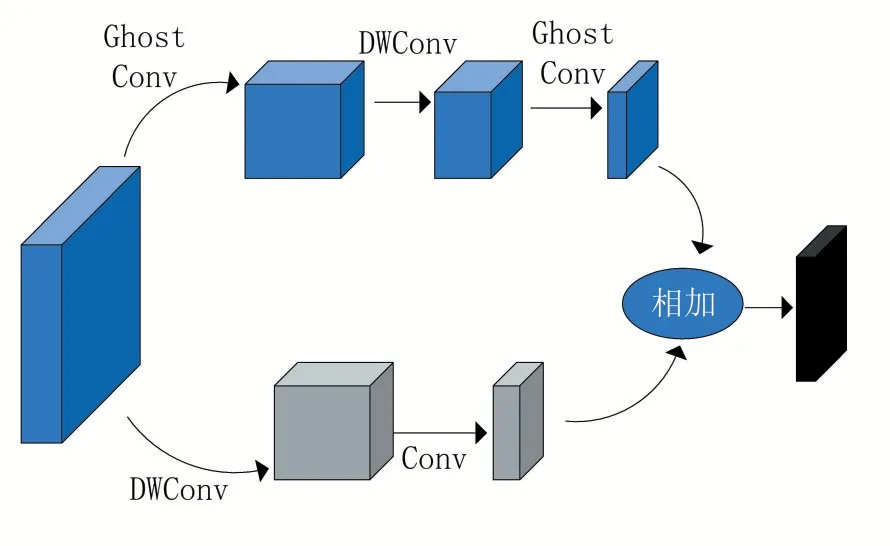
图4 GhostBottleneck 模块网络结构
1.3 深度可分离卷积
深度可分离卷积[16](Depthwise Separable Convolution,DSConv)由逐通道卷积(Depthwise Convolution,DWConv)和逐点卷积(Pointwise Convlution,PWConv)两部分组成。与普通卷积操作不同,普通卷积的卷积核同时作用于每一个通道,而DWConv 的一个卷积核只负责一个通道,也就是一个通道只被一个卷积核卷积,因此卷积核数量也与上一个通道数相同;PW 的卷积核尺寸为1*1*M,M表示上一层的通道数量,上一层的MAP 也就在这里进行深度方向的加权组合,生成新的特征图。图5所示为深度可分离卷积的网络结构图。
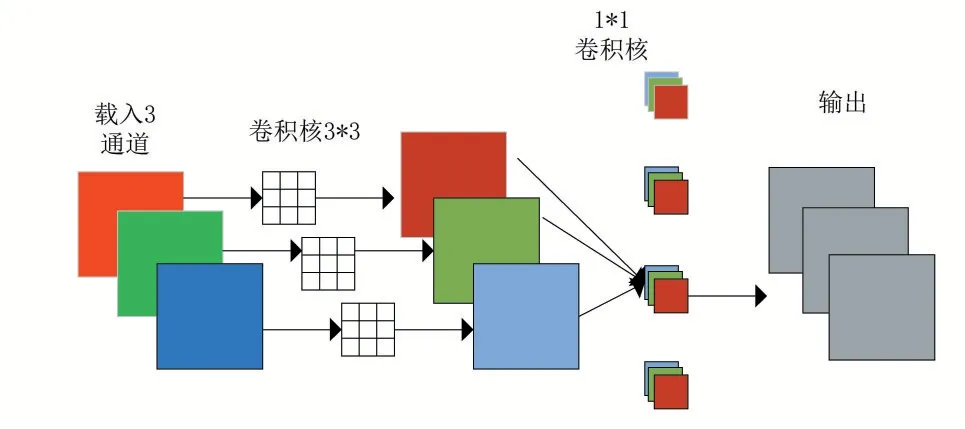
图5 深度可分离卷积网络结构
2 轻量型YOLOv5s-Ghost算法
2.1 构建YOLOv5s-Ghost网络结构
在口罩检测模型的选择上,将YOLOv5s 网络作为基础网络,根据1.1 节和1.2 节的内容,采用GhostBottleneck 模块替换YOLOv5s 原始特征提取网络中的C3 模块,并采用深度可分离卷积替换除输入端卷积层外的其余卷积层,得到本文所采用的YOLOv5s-Ghost 网络,其主干网络参数具体如表2所示。

表2 YOLOv5s-Ghost主干网络参数
3 实验结果与分析
3.1 实验环境
所采用的实验平台如表3所示。
表3 实验平台
3.2 获取数据集
实验所采用的数据集来自于现场拍摄、人群图像采集以及部分网络收集,一共有2000 张包含佩戴口罩以及未佩戴口罩的图像,并且部分图像中包括多个检测目标。将其中1200 张图像作为训练数据集,400张图像作为测试数据集,400张图像作为验证数据集。全部数据格式均采用PASCAL VOC格式,部分数据集如图6所示。

图6 部分数据集样本实例
3.3 数据预处理
在数据处理部分,本文使用Labellmg 软件将戴口罩与未戴口罩的图像分别进行标注,其中戴口罩的图像标为mask,未戴口罩的图像标为face。标签收集到的数据用txt 文本格式表示,格式内容为(class_id,x,y,w,h),其中class_id表示类别种类,本文共有两类,因此class_id 取值0 或1。x,y,w,h都是归一化后的位置参数,以原图像左上角为原点,x表示标签锚框横轴中心点与原图像宽度的比值,y表示标签锚框纵轴中心点与原图像高度的比值,w表示标签锚框宽度与原图像宽度的比值,h表示标签锚框高度与原图像高度的比值。
将数据集的图像进行resize 操作,使得图片输入大小均设置为640×640,并且采用Mosaic方法进行数据增强。Mosaic 数据增强[17]的原理是将一张选定的图片和随机的三张图片进行裁剪,然后将其拼接到一张图上进行训练。这样做的好处是间接提高了图片的batch_size,使得模型在训练的时候不会过多依赖一次训练所抓取的样本数量,使得模型的鲁棒性得到提高。
3.4 网络训练
在模型的训练过程中,使用损失函数Loss表示该模型性能的优劣。Loss 越小,模型的检测性能越好;Loss 越大,模型的检测性能越差。本文实验的epoch 为100,batch-size 设置为4,即将全部的数据样本训练100次,每一次训练时再分为25 批次(batch)进行,每一批次数据量的大小(batch-size)为4。在模型中初始设置学习率为0.01。图7展示了YOLOv5s-Ghost 模型在验证集上定位损失、置信度损失和分类损失的损失函数变化情况。

图7 YOLOv5s-Ghost模型的损失函数变化情况
图7所示横坐标为训练的epoch 轮数,单位为轮次;纵坐标依次为定位损失函数值、置信度损失函数值以及分类损失函数值,其函数值大小均在0~1 区间内。可以看到,模型从开始到第10 epoch,损失函数曲线急剧下降,从第10 epoch 到第50 epoch 时缓慢下降,从第50 epoch 到第100 epoch 趋于稳定。定位损失在0.045 时达到最优值,置信度损失在0.033 时达到最优值,分类损失在0.002时达到最优值。
3.5 模型的评价指标
YOLOv5s-Ghost 模型的评价指标主要有三种,精度(Precision)、召回率(Recall)与均值平均精确度(mAP_0.5、和mAP_0.5:0.95)。
精度和召回率主要由TP、FP、TN、FN 计算得出。TP是指被模型预测为正类的正样本(真正例),FP是指被模型预测为正类的负样本(假正例),TN是指被模型预测为负类的负样本(真反例),FN是指被模型预测为负类的正样本(假反例)。根据本文的实验指标,TP指预测为戴口罩实际上也是戴口罩的样本,FP指预测为戴口罩实际上未戴口罩的样本,TN指预测为未戴口罩实际上也是未带口罩的样本,FN指预测为未戴口罩实际上戴口罩的样本。AP表示平均精度,它指某一类在所有召回率的可能取值下对全部精度取平均值,在图像上表示的是PR曲线下的面积,衡量训练好的模型在某一类别下的好坏;mAP即在所有类别下的AP取平均值,衡量模型在所有类别上的好坏。其中精度、召回率、平均精度和均值平均精度的计算方式依次如公式(5)、公式(6)、公式(7)、公式(8)所示。

而mAP_0.5 和mAP_0.5:0.95 指的是mAP 分别在置信度阈值为0.5 和从0.5 到0.95 的情况下的均值平均精度。置信度阈值即预测框与真实框之间的重叠程度,用IoU 表示。当IoU=1 时,表示预测框与真实框完全重合。
3.6 结果分析
为了验证本文所提出的YOLOv5s-Ghost 算法具有更好的识别效果,使用本数据集分别在YOLOv5s、YOLOv5l、YOLOv5s-MobileNetV3[18]、YOLOv5s-Ghost 四种不同的算法上进行对比实验。其中MobileNetV3 是谷歌提出的一种轻量化网络模型,此模型加入了注意力机制,并且将激活函数设为h-swish[x]。实验结果分别用3.5节提到的指标来评价,其具体结果如表4所示。

表4 不同模型性能对比
由表4可以看出,当采用算法为YOLOv5l时,其精确度、召回率和mAP值会比YOLOv5s稍大,性能参数更高一些,但其浮点数是YOLOv5s模型的9.8倍,参数量为9.9倍,模型的体积大小也是9.6 倍,因此考虑到在资源有限的移动设备上实现模型的移植,YOLOv5s 无疑是更加优秀、便捷的。
当确定采用YOLOv5s 模型后,对其主干网络进行进一步优化,通过实验查看其优化效果。本文通过把其主干网络替换为GhostBottleneck 和MobileNetV3 进行测试。由表4所示:发现当主干网络为GhostBottleneck时,其精确度相较于YOLOv5s 来说大致不变,召回率大约低0.5%,mAP值低0.1%;而主干网络采用Mobile-NetV3 时,其精确度相较于YOLOv5s 大约低4.3%,召回率大约低4.2%,mAP值也是大约低2.9%。因此基于YOLOv5s 模型作比较,YOLOv5s-Ghost 比YOL0v5s-MobileNetV3 表现要更好一些。YOL0v5s-MobileNetV3 模型的计算量是YOLOv5s-Ghost 模型的1.43 倍,参数量是后者的2.19 倍,体积是后者的2.03 倍。因此在轻量化模型的部署上,YOLOv5s-Ghost 无疑是更好的选择。
3.7 效果图对比
本文采用YOLOv5s 模型和YOLOv5s-Ghost模型的测试效果图进行分析。通过图8可以看出,在预测距采集设备较近位置的目标时,两种模型的检测准确率都在70%、80%左右;而在预测中等距离的目标时,YOLOv5s 模型的准确率在60%左右,而YOLOv5s-Ghost 模型的准确率却在30%左右;在预测较远距离的目标时,两模型的准确率分别在30%以及40%左右。由此大致可以看出,YOLOv5s-Ghost 模型通过牺牲预测中远位置时的准确度来换取了更加轻量化的体积大小。因此,提升中远距离目标的预测准确度,是未来需要加以改进的方向。

图8 YOLOv5s和YOLOv5s-Ghost测试效果图
4 结语
本文提出了一种轻量化YOLOv5算法的口罩检测模型,通过降低算法深度,采用Ghost-Bottleneck模块来替换原始的C3模块,采用深度可分离卷积替换除输入端卷积层外的其余卷积层,得到YOLOv5s-Ghost 算法。实验结果表明,本算法在大致保持评价指标不降低的情况下,大大减少了浮点数的计算以及模型的参数量,更是将模型大小缩小至原来的37.5%,使其可以更好地在资源有限的移动端设备上进行部署,基本满足了现在用于口罩检测的均值精度需求。而在检测相对远距离的目标时,未来还会继续探索更加优化的算法。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
意林(2020年9期)2020-06-01
海峡姐妹(2020年4期)2020-05-30
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
作文大王·笑话大王(2019年3期)2019-04-22
北京航空航天大学学报(2018年1期)2018-04-20
军事运筹与系统工程(2016年4期)2016-07-10
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
智能系统学报(2015年4期)2015-12-27
