
基于改进的YOLOv5实现中药饮片的检测识别
2023-01-16 12:46董苗苗梁允泉刘羿漩齐振岭牛慧娟葛广英
现代计算机 2022年22期
董苗苗,梁允泉,刘羿漩,2,齐振岭,2,牛慧娟,葛广英
(1.聊城大学物理科学与信息工程学院,聊城 252059;2.聊城大学山东省光通信科学与技术重点实验室,聊城 252059;3.聊城大学计算机学院,聊城 252059)
0 引言
中医药是中华民族的伟大创造,我们国家高度重视中医药事业的发展,随着医疗大数据和互联网技术的发展,人工智能领域已经逐渐深入到传统的中医药领域。中药饮片是药材分类中的一个特殊分类,其种类繁多,某些中药饮片外形相似,但其使用目的并不相同,因此需要对其正确识别分类。传统的人工分类方式受制于人的主观判断,需要人脑记忆很多种类的中药饮片及其药效功能,因此存在工作量大、工作效率低等问题,有一定的局限性。随着中药市场需求的不断扩大,建立一种快速、高效识别中药饮片的分类检测方法日益迫切。作为人工智能时代的眼睛,计算机视觉被广泛应用于目标分类和识别的许多领域,因此与中医领域的结合也是未来发展的重要方向。
近年来,对于中药饮片的分类检测,国内众多学者用深度学习的方法对其开展了诸多研究。黄方亮等[1]研究了AlextNet 网络模型在5 种中草药图像分类过程中的应用,在实验过程中采用CPU 训练,训练的时间较长,准确率不高,仅达到87.5%。陈雁等[2]引进沃瑟斯坦生成对抗神经网络(WGAN)模型和Wasserstein 间距的算法,在60 种中药饮片的数据集上得到的平均精度为85.9%。吕宇琛等[3]通过对方向梯度直方图(HOG)、局部二值模式(LBP)等特征提取及融合方式结合传统的SVM 分类器的算法,在30 种中药饮片的数据集上识别率为91.16%。张谊等[4]在12 种中药饮片的数据集上对比了传统算法与多种深度学习算法的识别差异。孙鑫等[5]在VGG16 的网络模型上对50 种中药饮片进行识别,最终的识别精度为70%。胡继礼等[6]基于深度迁移学习的方式,在Inception-V3模型的基础上,参考了DOC 和DAN 方法在模型中加入了自适应度量,在137种中药饮片的数据集上,模型的识别精度为88.3%。张万义等[7]选取了通道数较少的VGG 模型,在17 种中草药的数据集上识别率达到了96%。王建庆等[8]基于GoogLeNet 深度学习模型在100种中药饮片的数据集上进行训练和识别,识别率为92%。本文在研究中药饮片[9]的基础上,引用目标检测YOLOv5 算法,并对其加以改进,以期在保持较高精度的同时,最大限度地减少网络模型的计算量,从而达到最优效果。
1 YOLOv5算法及其改进
1.1 YOLOv5算法
本文以单阶段检测算法YOLOv5为基础实现对中药饮片的检测识别。YOLOv5的网络结构包含四个部分,分别是:Input 输入、Backbone 网络、Neck网络、输出层。
YOLOv5模型如图1所示,在输入端YOLOv5采用了Mosaic 数据增强,即随机缩放、随机裁剪、随机排布的方式进行拼接。在Backbone中,Conv 模块中封装了三个功能,包括卷积(Conv2d)、BatchNorm2d(BN)以及SiLU 激活函数;Bottleneck 模块有两个分支,一个分支采用两个Conv 卷积模块,与另一分支用add 进行特征融合,融合后的特征数保持不变;在C3 模块中,包含有三个Conv 卷积模块,以及N个Bottleneck 模块,该模块是对残差特征进行学习的主要模块,其结构共有两个分支,一支将Conv 卷积模块和N 个Bottleneck 模块堆叠,另一支仅使用Conv 模块,最后将两个分支经过concat 操作,再经过一个Conv 模块,最后输出;SPP 是空间金字塔池化,首先经过一个Conv 模块将输入通道减半,分别做kernel-size 为5,9,13 的Maxpooling,再对三次Maxpooling 的结果与没有经过Maxpooling 的数据进行concat,最后再经过一次Conv 模块输出,SPPF 是用5×5 的kernel-size 代替了SPP的5,9,13,目的就是减少计算量,提高速度。

图1 YOLOv5网络模型结构
在Neck 网络中,YOLOv5s采用了FPN+PAN结构。如图2所示,FPN结构是自顶向下进行上采样,使得底层的特征图包含更强的中药饮片的语义信息。如图3所示,在FPN结构的后面添加两个PAN 结构,PAN 结构自底向上进行下采样,使顶层特征包含更多的中药饮片的位置信息。

图2 FPN 结构
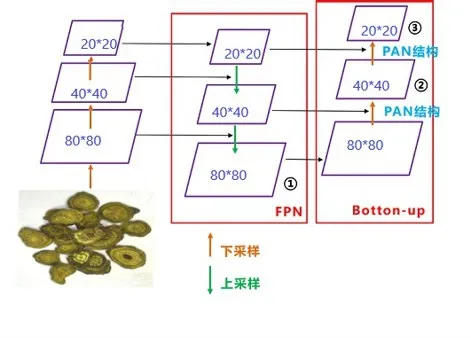
图3 FPN+PAN结构
1.2 GhostBottleneck 模块
针对于实际的应用场景,往往需要将深度学习的模型移植到嵌入式设备中来使用,如果硬件的算力不够,就很大程度上限制了深度学习的应用。因此,在YOLOv5 的Backbone 主干网络中设计了GhostBottleneck 模块[10],以此来降低主干网络中C3 模块的参数量,既能满足模型的轻量化要求,又能加快网络的推理速度。
假定输入X∈Rh×w×c,c是输入的通道数,h是输入数据的高度,w是输入数据的宽度,生成n个特征图的卷积层的计算为

其中*是卷积运算,b是偏差项,Y∈Rh'×w'×n是n个通道的输出特征图,f∈Rc×k×k×n是卷积层的卷积核,h'和w'是输出数据的高度和宽度,k×k是卷积核的大小。普通卷积的结构如图4所示,那么,普通卷积的计算量为


图4 普通卷积
相对于普通卷积,GhostBottleneck 中的卷积分两步进行,第一步先经过一个普通的卷积计算,生成一些少量的特征图,再将生成的特征图进行cheap operation 操作,生成一些冗余的特征图,最后将两者结合进行concat 操作,卷积过程如图5所示。

图5 GhostBottleneck中的卷积
GhostBottleneck中的卷积计算量为

其中s是每个通道产生的总映射(1 个特征图有s-1 个冗余特征图),s≪c。d·d是线性操作的平均核大小,和k·k相似。将GhostBottleneck中的卷积层命名为GhostConv,并仿照原YOLOv5的Bottleneck 中的结构顺序进行堆叠,新的GhostBottleneck结构如图6所示。

图6 GhostBottleneck 模块
通过公式(1)、公式(2)和公式(3)可知,GhostBottleneck 模块可以降低卷积层的计算成本。在YOLOv5s 模型的网络结构中,将C3 模块中原有的Conv 层替换为GhostConv 层,Bottleneck 替换为GhostBottleneck 组成新的C3Ghost 模块,大大降低了网络的参数计算量。
1.3 网络层中加入注意力机制
针对YOLOv5 算法容易丢失中药饮片的小目标信息的问题,在模型的网络结构中加入了Coordinate Attention[11](以下简称CA)来增强网络学习特征的能力。CA 注意力机制是将位置信息嵌入到通道注意力中,使轻量级的网络能够在更大的区域上进行注意力。CA 注意力机制分为Coordinate 信息嵌入和Coordinate Attention 生成两步,结构如图7所示。

图7 CA注意力机制
Coordinate 信息嵌入是将通道注意力在输入特征图的宽度和高度两个方向分别进行全局平均池化,分别获得两个方向上的特征图。假设,输入为X∈RH×W×C,使用尺寸(H,1)和(1,W)的池化核分别沿水平坐标方向和垂直坐标方向对每个通道进行编码,那么第C个通道在高度h处的输出可以表示为

在宽度w处的输出可以表示为

将这两个变换沿着两个空间方向进行特征聚合。Coordinate Attention 生成是将信息嵌入中的变换进行concat 操作,再使用卷积变换函数对其进行变换操作:
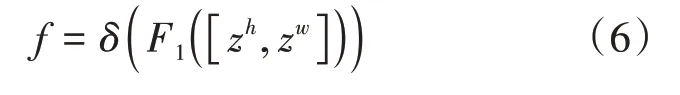
后沿着空间维数分解为两个单独的张量和。再利用两个卷积变换和sigmoid 激活函数得到两个具有相同通道数的张量,分别为

最后对输出的和进行扩展作为attention weights,CA注意力机制模块的输出可以写成

CA注意力机制很简单,可以灵活地插入到网络结构中。在YOLOv5s的网络结构中,本文在新设计的C3Ghost模块后加入CA注意力机制,以此来提高对中药饮片中存在的小目标的检测能力。
1.4 改进后的网络结构
同时为了减少加入注意力机制后对网络参数产生的影响,在YOLOv5 算法的Backbone 中使用了深度可分离卷积。深度可分离卷积是将一个完整的卷积运算分解成Depthwise Convolution(逐深度卷积)和Pointwise Convolution(逐点1*1)卷积两步来进行。深度可分离卷积的卷积方式可以减少网络参数数量,同时还可以减少参数占用的内存。
如图8所示,逐深度卷积是每一个通道都只被一个卷积核卷积,这个卷积过程产生的特征图的通道数和输入的通道数是一样的。

图8 逐深度卷积
如图9所示,逐点卷积是用1*1 的卷积来组合不同深度卷积的输出,并将上一步产生的特征图在深度方向上进行加权融合,又生成新的特征图,即有几个卷积核就有几个输出的特征图。

图9 逐点卷积
假设输入的特征图大小为Dk×Dk×M,卷积核大小为DF×DF×M,数量为N,对于标准卷积的计算量为
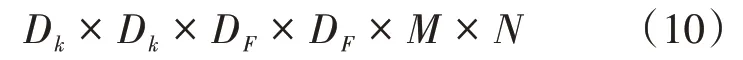
记为A1,深度可分离卷积的计算量为

记为A2,那么深度可分离卷积与标准卷积的计算量之比为
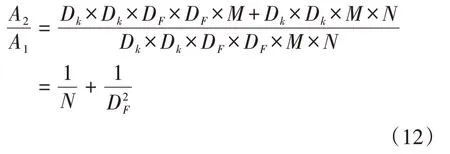
通过公式(12)的计算,本文网络模型中的深度可分离卷积的计算量占使用标准卷积计算量的11.5%。
综上所述,将改进后的YOLOv5算法命名为YOLOv5-Ghost-CA,其结构如图10所示。

图10 YOLOv5-Ghost-CA结构
2 数据集处理
2.1 中药饮片数据集的建立
由于目前没有公开的中药饮片的数据集,本文参考文献[1]至文献[8]中的数据集构建了107种中药饮片,对收集到的中药饮片进行图像采集,每种中药饮片采集到的图片有几十张,再运用图像处理的方式,包括平移、旋转、反转、图像增强等方式,达到扩充数据集的目的。经过数据处理后中药饮片的数据集一共有22380张图像,数据集中的中药饮片种类共计107 种,最后将数据集的22380 张图片利用labelimg 工具进行标注。数据集的训练集、验证集、测试集按照7∶2∶1的比例进行划分。
2.2 实验平台环境
本次模型训练基于Pytorch 深度学习框架,实验环境为Windows Server 2019操作系统,GPU为Quadro RTX 4000,内存64 G,torch 版本为1.10.1+cua102,实验参数设定见表1。

表1 实验参数设定
2.3 重新计算先验框
为了获取更好的模型效果,将原YOLOv5算法中预先设定的先验框利用K-means 算法重新获取,先验框获取前后对比见表2。

表2 先验框对比
3 模型分析
3.1 模型评价指标
常用的模型评价指标有查全率(Recall,R),查准率(Precision,P),F1-score,平均精度AP,平均精度均值mAP,计算量FLOPs,模型参数parameters 等。其解析式表达如公式(13)—公式(17)所示。

其中,TP指中药饮片中的正样本被预测为正样本的数量,FN指中药饮片中正样本被预测为负样本的数量,FP指中药饮片中负样本被预测为正样本的数量。AP是指PR曲线下的面积(一般来讲,PR曲线下的面积越大,模型越好),mAP指各类AP的平均值。N指数据集中的总类别数。YOLOv5 算法与YOLOv5-Ghost-CA 算法训练后的mAP@0.5值对比如图11所示。
表3给出了中药饮片数据集在两种模型上的具体指标值结果。根据图11可知,YOLOv5-Ghost-CA 算法比YOLOv5 算法模型mAP@0.5高,在第20 个epoch 时YOLOv5-Ghost-CA 模型的平均精度达到97.07%,并逐渐趋近于稳定,YOLOv5 算法模型在第39 个epoch 时模型的平均精度为93.59%,之后逐渐趋于稳定。结合表3分析可知,YOLOv5-Ghost-CA 算法模型大小仅6.61 MB,比YOLOv5 算法模型减少了53.45%,参数量减少了50%以上,计算量减少了57.14%,YOLOv5-Ghost-CA 算法在大幅度降低计算量的同时,模型的精度一直保持在较高的水平,mAP@0.5 的值比YOLOv5 算法提高了2.93%,mAP@0.5:0.95 的值YOLOv5 提高了2.9%。实验结果表明,改进后的模型对检测中药饮片有较高的精度,在此基础上,改进后的模型更小,更有利于部署到嵌入式设备上,满足实际应用场景的需求。

图11 mAP@0.5对比

表3 两种模型的评价指标对比
3.2 推理速度对比
为了证明YOLOv5-Ghost-CA 算法的有效性,本文选取了107种中药饮片的图片作为实际检测,根据表4分析,YOLOv5-Ghost-CA 算法比YOLOv5算法在推理速度方面提升了15.23%。

表4 推理速度对比
综上所述,YOLOv5-Ghost-CA 算法不仅在推理速度方面比YOLOv5算法有很大提升,而且在实际检测效果方面也优于YOLOv5算法。
3.3 消融实验对比
为了再次验证YOLOv5-Ghost-CA 算法的有效性,在YOLOv5算法的网络模型结构中,在不同的位置上做了改进,具体结果如表5所示。
根据表5中的结果可知,YOLOv5+CA 是在YOLOv5 算法的基础上只加入CA 注意力机制,模型平均精度提升了2.4%,但模型的参数量和计算量都有所增加,模型大小也比原模型大;YOLOv5+C3Ghost 是在YOLOv5 算法的基础上只加入C3Ghost 模块,模型的平均精度比YOLOv5算法提升2.82%,同时模型的参数量、计算量、模型的大小也大幅度降低;YOLOv5+C3Ghost+CA1 是融合了前两种的添加方式,在YOLOv5算法的基础上加入CA 注意力机制和C3Ghost 模块,模型的平均精度比原模型提升了2.88%;YOLOv5+C3Ghost+CA2 是在YOLOv5+C3Ghost+CA1 添加方式的基础上又在不同位置进行添加,模型的平均精度提升了2.91%。本文的YOLOv5-Ghost-CA 算法与前面的算法相比,在模型的平均精度、参数量、计算量、模型的大小都达到了最优,训练所获得的模型也更小,进一步验证了YOLOv5-Ghost-CA算法的有效性。

表5 不同位置改进的模型对比结果
4 结语
综上所述,本文首先建立一个符合实验的中药饮片的数据集,基于YOLOv5算法训练得到一个检测中药饮片的模型,针对YOLOv5算法的不足提出了一种轻量化的YOLOv5-Ghost-CA 算法,经过训练该算法模型的mAP@0.5 可以达到98.37%,能够准确检测中药饮片,同时YOLOv5-Ghost-CA 算法也将参数量和计算量降到最低,可以很好地应用于嵌入式设备当中。接下来的工作,将尝试通过基于Python 语言的Streamlit构建识别中药饮片的Web APP,可以在网页端对中药饮片进行检测识别,同时也可以部署到Streamlit 提供的Streamlit cloud 云端,供其他人访问;同时YOLOv5-Ghost-CA 算法在平均精度方面还有提升的空间,今后也将继续在此方面进行研究,以期望达到更好的模型精度。
猜你喜欢
一重技术(2021年5期)2022-01-18
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
中学生数理化·八年级物理人教版(2019年9期)2019-11-25
电子制作(2019年11期)2019-07-04
中学生数理化·八年级物理人教版(2019年12期)2019-05-21
电子制作(2018年11期)2018-08-04
北京航空航天大学学报(2018年1期)2018-04-20
中国卫生(2016年3期)2016-11-12
中国卫生标准管理(2015年25期)2016-01-14
