
融合时间和地理信息的兴趣点推荐研究
2023-01-11 00:43李建波吕志强董传浩
复杂系统与复杂性科学 2022年4期
赵 薇,李建波,吕志强,董传浩
(青岛大学计算机科学技术学院,山东 青岛 266071)
0 引言
随着智能手机和平板电脑等带GPS定位的移动终端设备的普及,位置社交网络(Location-Based Social Network,LBSN)得到了快速发展,用户可以轻松地获取已访问兴趣点的地理信息,并进行实时签到。由此产生了海量的签到数据,引起了学者的广泛关注[1-5]。如何从海量的签到数据中筛选出用户感兴趣的内容是一个值得研究的问题。对于兴趣点推荐的研究则可以解决这一难题。兴趣点推荐是一项致力于从大量的候选位置中为用户推荐满足其访问需求的兴趣点的研究,它既可以帮助用户制定合理的出行计划,探索未知的地理区域;也可以帮助商家向潜在的用户提供个性化服务,提高其营业收入;同时可以让政府提前进行交通规划,避免出行高峰期造成的道路阻塞。
现阶段,关于兴趣点推荐的研究主要是根据历史签到数据,挖掘用户潜在的移动模式,模拟用户访问下一个地点的决策过程,达到为用户推荐满足其访问要求的兴趣点的目的[6]。不同于传统的推荐任务,兴趣点推荐是一个融合时间和地理信息的推荐。例如,用户在每天早晨8点去早餐店吃早餐,在工作日下午3点去咖啡店买咖啡,在每周日晚上7点和朋友去电影院看电影。对于即将到来的一天,如何为用户合理地安排行程,推荐其感兴趣的地点。这时的兴趣点推荐任务一定是融合时间和地理信息的推荐。
在融合时间信息的兴趣点推荐工作中,He等[7]认为用户与兴趣点交互的时间戳是有规律的,它不仅是用户访问兴趣点的时间节点,还隐藏着用户访问行为的周期性特征。因此,时间信息在兴趣点推荐中起着重要作用[8]。Zhao等[9]通过门控机制来捕获两个相邻兴趣点之间的访问时间间隔。Feng等[10]提出注意力机制来捕获具有周期性特征的时间信息。另外,在融合地理信息的兴趣点推荐工作中,考虑到兴趣点之间的距离,Cheng等[11]将地理信息作为一种区域约束,结合马尔可夫链,提出了FPMC-LR模型。Sun等[12]提出了一个针对短期建模的地理空洞循环神经网络模型,该模型解决了已访问兴趣点在地理上分散的问题。Lian等[13]通过用户访问兴趣点的地理信息来捕捉用户访问行为的空间聚类现象。
综上所述,现有方法在一定程度上提高了兴趣点推荐准确率,但忽略了时间和地理信息之间的关系。虽然按时间周期对签到记录进行了划分,但忽略了不同时间用户访问行为受地点距离约束程度的差异性。例如,工作日用户的访问行为受区域限制较大,访问地点受距离约束严重;节假日用户的访问行为相对自由,访问的地点受距离约束程度相对较轻,访问的地点更具有随机性。
针对上述问题,本文对签到数据进行了工作日和节假日的划分,提出了一种融合时间和地理信息的兴趣点推荐模型。该模型主要分为两个部分:一是利用长短期记忆网络(Long Short-Term Memory,LSTM)提取当前轨迹中序列特征的时空关系模块;二是学习历史轨迹中地理信息的地理关系模块。在地理关系模块中,利用卷积神经网络捕获用户的局部地理偏好;根据用户之间的访问相似度,生成关于地理位置的评分矩阵。融合上述两部分,获得用户下一步访问兴趣点的推荐意见。
1 预备知识
1.1 兴趣点推荐
兴趣点推荐被认为是推荐领域中的一个重要任务。与传统的电影、音乐、新闻等推荐任务不同,兴趣点推荐需要用户去访问物理世界中真实存在的地点,因此推荐难度更大。在基于传统方法的研究中,协同过滤算法是被普遍认可的[14-16]。Ye等[17]基于用户的协同过滤框架,采用线性插值的方法,结合地理与社会影响进行兴趣点推荐。夏英等[18]先通过协同过滤算法模拟用户的社交关系,然后通过加权矩阵分解学习地理信息,进而将两者融合进行兴趣点推荐。另外,由于签到数据是连续的序列数据,因此采用马尔可夫链也可以很好地计算签到序列之间的转移概率。
近年来,深度学习的发展极大地推动了兴趣点推荐的研究。针对签到数据的特点,循环神经网络(Recurrent Neural Network,RNN)及其变体(LSTM、GRU)在兴趣点推荐领域的应用十分广泛。Zhong等[19]利用LSTM基于流行度和社交网络进行兴趣点推荐。Liu等[20]利用GRU基于类别感知进行推荐工作。Liu等[21]扩张了RNN,使用时间转移矩阵和距离转移矩阵来分别捕获时空上下文信息,并采用线性插值的方法缓解数据稀疏带来的影响。另外,卷积神经网络(Convolutional Neural Network,CNN)既可以从评论内容中获取语义和情感信息[22],也可以从最相似的友谊关系图中提取特征[23],因此在兴趣点推荐中得到了广泛应用。
1.2 兴趣点推荐问题定义

2 融合时间和地理信息的兴趣点推荐模型
图1展示了所提模型的总体架构,它主要由时空关系模块、地理关系模块和预测模块三部分组成。
2.1 时空关系模块
当前轨迹中的序列信息(位置、时间)反映了用户最近一段时间内的兴趣偏好,直接影响用户下一步的决策过程。因此,将当前轨迹中的不同信息通过嵌入学习,映射成对应的嵌入向量。然后,将时空嵌入向量进行连接,利用LSTM学习当前轨迹中的时空转换规律。计算公式为
(1)
ht=LSTM(elt,ht-1)
(2)

2.2 地理关系模块
2.2.1 时间判别器
考虑到用户的出行受时间和距离的影响程度不同,本文将签到数据按时间划分为工作日轨迹和节假日轨迹。在数据预处理时,为了减小训练量,提高训练效率,仅保留签到时间的“时”,作为该条记录的时间,例:“2021-7-1 12:34:23”,仅保留“12”作为该条签到记录的时间标签。为了区分工作日轨迹和节假日轨迹,令工作日的签到时间tday=t,0≤tday<24,节假日的签到时间tend=t+24,24≤tend<48。在将轨迹输入到地理关系模块之前,先根据当前轨迹的第一条签到记录判断该轨迹是工作日签到还是节假日签到,然后选择对应的历史轨迹。即:若t0<24成立,则选取历史轨迹中属于工作日的签到轨迹,反之,选择属于节假日的签到轨迹。另外,需要判断获得的历史轨迹是否为空,这样做可以排除已知的历史轨迹中仅包含某一种时间轨迹,而当前轨迹是另一种时间轨迹的情况,如:历史轨迹全部是节假日轨迹,而当前轨迹是工作日轨迹。针对这一情况,可以随机生成一个集合P={l1,l2,…,l|P|}作为历史轨迹,|P|为集合的长度。

图1 兴趣点推荐模型Fig.1 POI recommendation model

图2 邻居兴趣点访问次数Fig.2 Number of visits to neighbor POIs
2.2.2 局部地理偏好模块
由于邻居兴趣点的距离可以满足用户的时间可行性,用户下一步访问的兴趣点,极大概率是当前兴趣点的邻居兴趣点。图2为邻居兴趣点访问次数的分布图。可以看出:给定用户访问的兴趣点li,用户访问li的次数与访问li邻居的次数呈正相关,与距离呈负相关(颜色深浅表示访问次数,颜色越深表示访问次数越多)。
因此,根据距离,对时间判别器的输出结果进行筛选,生成更小的兴趣点候选集合Q。这里需要分别计算历史轨迹中的每一个兴趣点li,i∈{1,2,…,|P|}与当前轨迹中t-1时刻访问的兴趣点lt-1的距离:
(3)
其中,(lonli,latli)为历史轨迹中第i个兴趣点的经纬度,(lonlt-1,latlt-1)为当前轨迹中t-1时刻的兴趣点lt-1的经纬度。若di<Δd成立(Δd为距离阈值),则将兴趣点li添加到新的兴趣点候选集合Q中。新生成的兴趣点候选集合Q的长度要比历史轨迹的长度短很多,这样做既可以减少后续计算的成本花费,也可以避免某些距离较远的兴趣点对预测结果的影响。
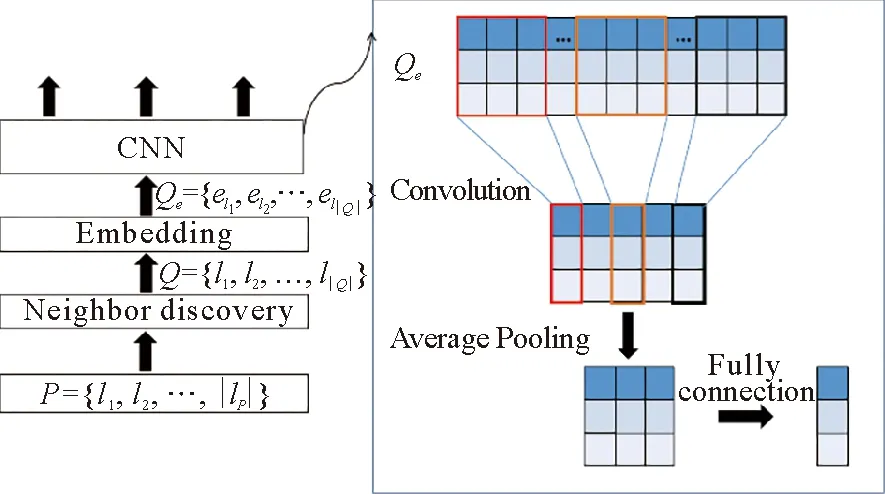
图3 局部地理偏好模块结构图Fig.3 Architecture of local geographical preferences module
为了进一步获得邻居兴趣点的地理特征,将兴趣点候选集合Q嵌入后可以得到Qe,然后通过卷积神经网络实现特征提取,如图3所示。
Z=ReLU(fconv(Qe))
(4)

2.2.3 位置评分模块
该模块主要是根据用户的历史轨迹,计算不同用户之间已访问兴趣点的相似度,进一步生成用户关于兴趣点的评分矩阵。
(5)
(6)
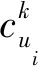
2.3 预测模块
预测模块由一个全连接层和一个输出层组成。全连接层将时空关系模块和地理关系模块的所有特征结合到一个新的向量中,并进一步将特征向量处理成一个维度更小、更具有表征意义的向量。然后,由输出层经过负采样后,输出预测结果。具体过程如下:

(7)
其中,y是一个融合时序特征、地理特征及用户个性化特征的向量,将其与评分矩阵做最后的融合,并经过softmax层处理后,得到模型预测输出,如式(8)所示:
out=softmax(y*W′*Cui)
(8)
其中,W′是一个可训练矩阵。out表示概率分布,概率最大的兴趣点是用户最有可能访问的位置。如果用户真实访问是兴趣点lt,其对应的概率为plt,那么损失函数可以表示为
(9)
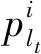
3 实验
3.1 实验数据
本文所用的数据集分别来自Foursquare、Weeplaces和Gowalla。其中,Foursquare数据集收集了2012年4月到2013年2月的845个真实用户在纽约的签到数据,共包括12 649个位置上的99 205条签到记录;Weeplaces数据集收集了2009年7月到2010年9月的307个真实用户在全球的签到数据,共包括18 288个位置上的127 974条签到记录;Gowalla数据集收集了2010年1月到2010年9月的384个真实用户在全球的签到数据,共包括16 486个位置上的79 356条签到记录。这3个数据集具有与模型相关的所有属性(用户ID、经纬度、兴趣点ID、签到时间)。
为了降低数据稀疏性的影响,本文对数据进行了预处理,将用户一天中所有的签到记录视为一条签到轨迹,仅保留拥有不少于5条签到轨迹且每条轨迹不少于3条签到记录的用户。对于每个用户的签到轨迹,前80%用作训练集,后20%用作测试集。
3.2 指标与参数设置
本文采用了3个常用的评估指标:准确率(Pre@K)、召回率(Rec@K),归一化贴现累计收益(NDCG@K),定义为
(10)
(11)
(12)
其中,K为给每个用户推荐的POIs数量,Ri为测试集中用户访问的真实位置集合,Vi为给用户推荐的K个POIs,Gi为给用户推荐的K个POIs的等级,|U|表示用户的数量。本文取K={5,10}来分别计算准确率、召回率和归一化贴现累计收益。
通过实验,本文将隐藏层节点数设置为300,兴趣点和用户ID的嵌入维度设置为300,时间的嵌入维度设置为10,批量大小设置为32,学习率设置为0.000 1,距离约束设置为Δd=4 km,候选历史轨迹长度设置为|P|=20。另外,本文采用了Adam优化算法对模型中的参数进行优化。
3.3 基线
本文选择了一些经典方法与所提出模型进行了性能比较:
Markov:作为一种经典的序列预测方法,可以学习序列之间的转移概率,从而预测用户未来的访问行为,是兴趣点推荐常用的基线模型。
RNN:一种基础的处理序列数据的循环神经网络模型,由输入层、隐藏层和输出层组成,层间采用全连接的方式。
LSTM:在传统RNN的基础上,增加了3个门控机制(更新门、遗忘门、输出门),可以用来捕获长期依赖。
ST-RNN:基于RNN的兴趣点推荐模型,将时间信息和地理信息同时融入循环结构中。
DeepMove:该模型利用历史注意力模块捕获历史轨迹中的周期性规律,并利用循环神经网络捕获当前轨迹的时空上下文。
LSTPM:该模型考虑了长期和短期偏好,使用上下文感知非局部结构来识别历史轨迹中的时空相关性,可以捕获当前轨迹中不连续兴趣点的地理影响。
3.4 实验分析
本文所提模型与基线模型在3个数据集上的实验结果如图4所示。从图4可以得出以下结论:
1)在3个数据集上,本文所提模型在所有指标上都明显优于基线模型。而在基线模型中,LSTPM模型在3个数据集上表现最好,DeepMove模型次之。这两个模型都将用户的轨迹划分为当前轨迹和历史轨迹,将用户的短期偏好和长期偏好分开考虑。其中,LSTPM模型的优势在于考虑了序列中的距离。因此,对于地理信息的处理在兴趣点推荐中十分重要。本文模型既利用距离关系生成了一个小的候选兴趣点集合,又对每一个兴趣点进行了评分。由于本文所提模型充分学习了地理信息对于用户选择的影响,所以在推荐准确率方面有了较大提升。
2)ST-RNN在推荐表现上优于LSTM、RNN,这说明除了学习序列信息,建模不同兴趣点之间的时空关系同样可以提高模型的预测能力。Markov方法的推荐效果最差,这表明仅使用用户访问位置的转换矩阵来进行预测所包含的信息太少,导致模型无法实现较好的推荐效果。
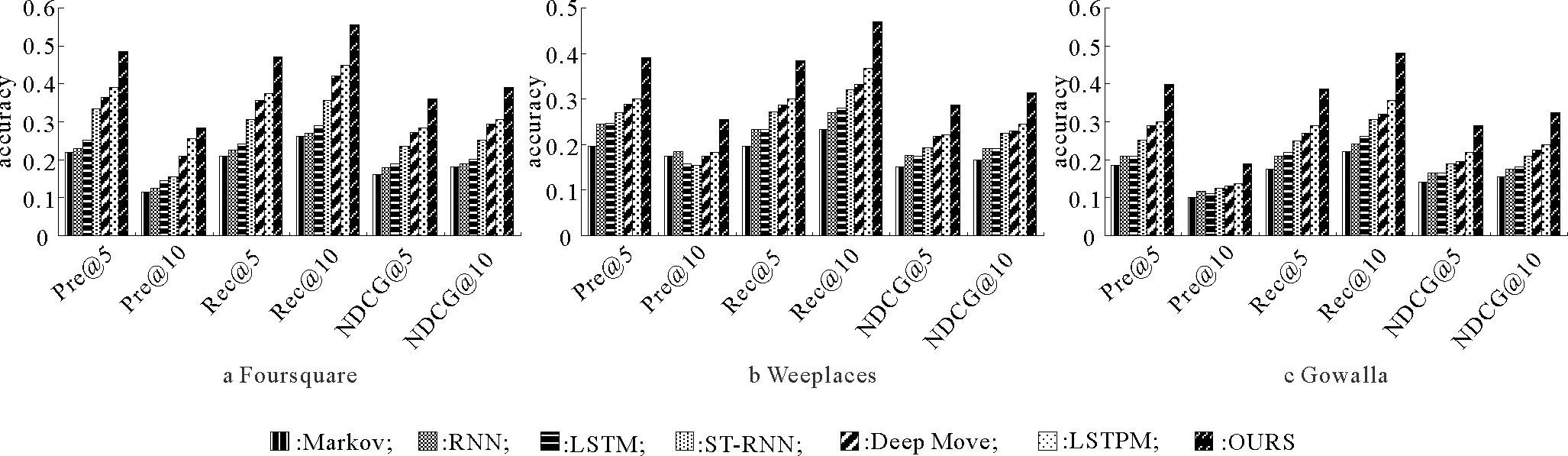
图4 3个数据集上的性能比较Fig.4 Performance comparison on three datasets
3.5 组件分析
为了验证模型中不同组件对于性能的增益,本文进一步简化了模型。
OURS-1:该模型移除了对于历史轨迹处理的组件,仅保留了处理当前轨迹的组件。
OURS-2:该模型移除了对于当前轨迹处理的组件,仅保留了处理历史轨迹的组件。

表1 不同简化模型的性能比较Tab.1 Performance comparison of different simplified models
简化模型在3个数据集上的实验结果如表1所示,可以看出:
1)模型OURS-2在所有指标上的表现都优于模型OURS-1。这说明OURS-2的推荐准确率更高。原因在于OURS-2可以更好地捕捉用户签到记录中的地理信息,更好地模拟用户的长期依赖。这说明地理信息在兴趣点推荐中十分重要,也清楚地展示了本文建模个性化地理影响的优势。
2)虽然OURS-1比OURS-2略差。但是OURS-1的预测能力比图4中的很多基线要好,如:RNN、LSTM。这说明对用户短期依赖的捕获,除了序列特征,对用户个性化信息的建模也同样重要。因此,本文所提模型将OURS-1和OURS-2组合在一起,在这3个数据集上都取得了最好的表现。
3.6 参数分析
本文分析了兴趣点嵌入维度、候选历史轨迹长度|P|对模型性能的影响。
图5a显示了在3个数据集上不同兴趣点嵌入维度在Pre@5上的结果,可以看出:嵌入维度在[300,500]范围内,模型性能基本是稳定。这是因为维度过低时,会丢失很多特征;维度过高时,又会产生无关的噪声信息。最终,本文将300作为兴趣点的嵌入维度,一方面可以减少参数量,另一方面可以提高运算效率。

图5 不同参数的性能比较Fig.5 Performance comparison of different parameters
图5b显示了在3个数据集上不同候选历史轨迹长度|P|在Rec@10上的结果,可以看出,候选历史轨迹长度|P|对于模型的预测性能几乎没有影响。这说明绝大多数用户不存在2.2.1节中所提到的历史轨迹不存在的情况。
4 结论
本文提出了一种融合时间和地理信息的兴趣点推荐模型。首先,针对时间对用户访问行为的不同影响,本文将用户轨迹划分为工作日轨迹和节假日轨迹,并在此基础上进行了当前轨迹和历史轨迹的划分。其次,模型分别利用时空关系模块和地理关系模块学习不同轨迹中的特征。具体而言,时空关系模块利用长短期记忆网络学习当前轨迹中的时空特征;地理关系模块一方面通过卷积神经网络学习邻居兴趣点的特征;另一方面根据用户之间的相似度,生成用户对兴趣点的评分矩阵。实验证明,本文所提模型在兴趣点推荐性能方面优于现有的其他模型。目前的兴趣点推荐研究都是针对单个用户,未来可以考虑根据社交关系以用户组的形式进行兴趣点推荐。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01
四川党的建设(2022年8期)2022-04-28
小学生学习指导(低年级)(2020年11期)2020-12-14
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
作文大王·低年级(2018年10期)2018-12-06
现代装饰(2018年5期)2018-05-26
中国三峡(2017年2期)2017-06-09
小猕猴智力画刊(2016年5期)2016-05-14
