
基于深度学习的风机叶片复杂场景目标定位检测算法
2023-01-11 02:04齐勇军汤海林翟敏焕
江西科学 2022年6期
齐勇军,汤海林,翟敏焕
(广东白云学院大数据与计算机学院,510450,广州)
0 引言
随着深度学习的发展,卷积神经网络在计算机视觉领域得到了广泛的应用,在语义分割[1-4],目标检测[5-8]等任务中,都有着优秀的表现。然后,这些方法都需要使用大量完整标注的数据进行训练。对大量数据进行精细标注需要耗费巨大的成本,近年来,基于卷积神经网络的弱监督目标定位算法,因其只需标注图像类别标签就可以定位图中的物体而受到学术界广泛的关注。由于不用标注图像中目标具体的边界框,只需对图像进行粗粒度的标注,因此它具有降低成本的优势。
在众多弱监督学习算法中,Class Activation Mapping(CAM)[9]是最具代表性的算法之一,它为后续的弱监督学习研究奠定了基础。图像经过CAM算法处理后,能够得到可视化的特征图,并映射到原图像中,最终得到对于不同类别物体图像中重点关注的区域。但是CAM也存在着缺点,它的注意力图中目标的区域往往只是目标物体最具有辨别力的部分,因此不能准确地定位目标的完整区域。
为了解决CAM算法的缺陷,不同的改进方法被提出。SPG[10]、ACoL[11]、ADL[12]、DANet[13]等算法基于CAM算法进行了改进,但是仍然存在着激活区域不准确的问题。Wang等人[14]提出了使用自适应注意力增强弱监督目标定位的方法A3进行位置修正。具体来说:在输入的图像通过特征提取器后,把得到的特征图输入到A3模块,在A3模块中,特征图被转换为指导图和补充图,指导图通过一个空间自注意力机制得到一个相关系数矩阵,来获取不同目标区域间的语义相关性,从而指导补充图获取更多的目标区域。另外,通过使用提出的Focal Dice损失函数,能够和分类损失函数制衡,来动态地增强补充注意力图中目标的注意力,降低背景区域的注意力。最终,将指导注意力图和补充注意力图融合,得到最终的目标定位区域。
本文提出一种基于风机叶片自适应特征矫正的弱监督目标定位算法,该算法基于Zhang等人提出的自适应注意力增强弱监督目标定位算法,引入自适应矫正模块对其进行了改进。通过使用自适应矫正模块,同时应用空间注意力机制和通道注意力机制,获得了更加准确的目标区域。相比于原本的弱监督目标定位方法A3,本文提出的方法能够获取更为完整的目标区域和更高的分类精度,且具有较好的视觉效果。
1 基于风机叶片自适应特征矫正的弱监督目标定位算法
1.1 研究方法概述
在Zhang等人提出的自适应注意力增强弱监督定位的方法A3中,只使用了自注意力机制来更好地获取到目标区域。本文在A3中最终的全局平均池化操作之前的卷积层中增加了自适应矫正模块,这个模块首先将输入的特征按通道分组,每组特征按照通道平均分为两部分,对这两部分特征分别使用空间注意力机制和改进的通道注意力机制,之后对两部分特征做拼接操作,最终对各组拼接后的特征做通道随机混合(channel shuffle)操作。使用本文提出的方法能够使网络更加关注目标有辨别力区域的特征信息,抑制不重要的特征,得到更加准确的目标区域。
1.2 模型设计
本文提出网络主要分为3个部分,分别为主干网络模块、A3模块、自适应矫正模块,如图1所示。

图1 基于自适应特征矫正弱监督目标定位算法网络结构图
对任意输入的图像I,它的类别标签为y,y={0,1,2,3,…,C-1},C为图像分类的类别个数。I首先输入到主干网络中,输出得到图像I的特征图F∈H×W×K,其中,H代表特征85图的高度,W代表宽度,K代表通道数。本文使用VGG16_bn网络[15]作为主干网络。随后,将F输入到A3模块中,在A3模块中,F分别通过一组1×1卷积被转换为指导图G∈H×W×N和补充图S∈H×W×N,其中H代表2个指导图的高度,W代表宽度,N代表通道数,本文设置N=K/2。指导图G通过自注意力机制生成一个相关矩阵,从这个相关矩阵中可以获取到一个物体不同部分之间的语义相关性信息。具体来说,先得到G的转置GT∈H×W×K,然后将G和GT的矩阵重塑为和和和使用矩阵乘法得到相关矩阵M∈(HW)×(HW)。
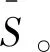



其中GMP代表全局最大池化操作(Global Max Pooling,GMP),W2和b2代表参数且W2∈N/2gx1,b2∈N/2gx1,σ代表Sigmoid激活函数,f代表矩阵拼接操作和3个3×3卷积操作,最终得到的X′∈N/2gxHxWx。经过上述操作后,得到各组的输出X′,X′为与在通道维度的拼接且X′∈N/gxHxW。最后,将各组的输出拼接起来,在进行通道随机混合操作,得到最终的输出且特征G在自适应矫正模块处理完成后,经过一个1×1×C的卷积,得到类别相关的特征图AMG∈C×H×W;特征在自适应矫正模块处理完成后,经过一个1×1×C的卷积,得到类别相关的特征图AMS∈C×H×W,W2∈N/2gx1。
在经过3个模块处理完之后,为了定位物体,首先将AMG和AMS通过全局平均池化得到类别得分vC∈c和vS∈c,随后使用集成的方式得到最终的类别得分vC∈c:vC=softmax(vG+vS),最终预测输入图像的类别为yc=argmax(vc)。
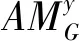
1.3 相关损失函数
本文算法中,使用的损失函数与A3中的损失函数一致,分别使用了FocalDice损失函数和交叉熵(Cross-Entropy)损失函数。
Focal Dice损失函数为:

其中:α为损失权重,CE为交叉熵损失函数。
2 实验设计与结果分析
2.1 实验数据集
本文算法使用的数据集主要为Caltech-UCSDBirds(CUB)数据。它是图像目标检测常用的数据集之一,包含了300种鸟类的图片,由6 000张训练图像和6 000张测试图像组成。在弱监督定位网络训练时,只使用该数据集的类别标签。
2.2 实验环境与设备
本项目在PyTorch1.7环境运行测试,CPU处理器是Intel(R) Xeon(R) CPU E5-1620v44核8线程,内存为64 GB,显卡是Nvidia GeForce RTX3080 10 GB,显存达到10 GB,Ubuntu20.04操作系统。
2.3 算法性能评价指标
本文主要使用Top-1定位准确率(Top-1Loc)和Top-1分类准确率(Top-1Cls)来评估算法的性能。Top-1Loc可以反映算法的定位能力,对于每一张图像,只有分类正确且预测定位框与实际定位框的交并比大于0.5时才被认为定位正确。Top-1Cls可以反映算法的分类能力。
2.4 实验结果
在训练阶段,设置批大小为32,初始化学习率为0.001,并且使用随机梯度下降的方法(stochastic gradient descent,SGD)优化模型参数,其中动量和权重衰减值分别设置为0.9和0.000 5,并在第10周期和15周期衰减到原来的0.1倍,一共被训练了30个周期。表1为提出的方法和A3在CUB数据集上的弱监督目标定位任务中对比的结果。

表1 CUB数据集弱监督定位结果对比
从表1中可以看出,本文提出的方法在定位精度上相比于A3有了明显的提升,在分类准确度上略低于A3,这是由于分类任务往往关注目标最具有辨别力的区域,而定位任务关注的是获取目标更为完整的区域,因此更好的定位能力会使得网络的分类能力略微下降,最终需要在网络的定位能力和分类能力之间取得一个平衡。本文还验证了自适应矫正模块主要部分处于不同位置时,算法的定位能力,如表2所示。

表2 矫正模块在不同位置定位结果对比
从表2中可以看出,当自适应矫正模块主要部分位于一组3×3卷积之后时,能够得到最好的定位准确率和分类准确率。这是由于经过一组3×3卷积之后,增加了网络深度,能够提取到更高维的特征,获取到更准确和完整的类激活图,从而使得目标的定位区域更加准确和完整。
3 结论
本文提出了一种改进的自适应弱监督定位方法,该方法通过引入自适应矫正模块,对自适应弱监督定位方法A3进行了改进。改进后的监督定位方法通过使用自适应矫正模块,可以同时应用空间注意力机制和改进的通道注意力机制,同时利用全局最大池化和全局平均池化,获得了更加准确的目标区域。理论分析和实验结果表明,相比于原本的自适应弱监督定位方法A3,本文提出的方法能够获取更为完整的目标区域和更高的分类精度,且具有较好的视觉效果。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
甘肃教育(2020年22期)2020-04-13
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
人民调解(2019年2期)2019-03-15
北京航空航天大学学报(2018年1期)2018-04-20
第二课堂(课外活动版)(2016年2期)2016-10-21
Coco薇(2015年7期)2015-08-13
中国医疗美容(2015年2期)2015-07-19
