
应用面向对象结合多时相哨兵-2A影像特征优选的毛竹林分布信息提取1)
2023-01-10 02:37张旷典郭孝玉康继刘健
东北林业大学学报 2023年1期
张旷典 郭孝玉 康继 刘健
(福建农林大学,福州,350028)(三明学院)(福建农林大学)(福建省资源环境监测与可持续经营利用重点实验室(三明学院))
毛竹(Phyllostachysedulis)林是我国重要的森林资源,具有生长迅速、产量高、成材时间短、固碳增汇能力强等特性,在乡村生态富民产业振兴和保持良好生态等方面发挥特殊作用[1]。因传统竹林资源调查十分耗时费力,无法满足现代监测的需要,遥感技术具有遥测时间短、监测范围广、再次获取信息时间短等特点,在竹林资源监测中发挥了重要的作用[2]。近几年,许多学者利用遥感技术开展了毛竹林分布信息提取研究。官凤英等[3]利用福建省顺昌县的TM影像,采用最大似然法、子像元分类和光谱特征分类3种方法进行竹林信息的提取,结果发现,子像元分类精度最高,其次为光谱分类,最大似然法分类精度最低,但是在对竹林面积信息进行前提取时光谱特征分类方法的精度最高,精度达95.68%。提取技术可分为基于像元的影像分类技术和面向对象的分类提取方法,研究人员利用不同的遥感数据源开展了大量的研究。传统基于像元的分类方法存在局限性,分类结果中“胡椒效应”现象比较明显[4],而形状大小特征等都未进行挖掘使用[5]。面向对象的分类方法可以有效减少“胡椒效应”,充分利用地物的光谱、纹理、形状等特征将影像分割成一个个对象单元,提高地物分类精度[6-7]。张宏涛等[8]应用哨兵-2A(Sentinel-2A)影像使用eCognition软件进行面向对象的土地覆被分类,综合光谱、纹理、形状信息实现土地覆被分类总体精度达97%;赵士肄等[9]应用面向对象通过Sentinel-2A为数据源,使用随机森林分类模型优选特征变量实现对旱地和大棚提取,提取精度分别达99.6%和88.4%。杜华强等[4]依据SPOT-5数据的纹理、光谱特征等,采用面向对象法等提取毛竹林信息的精度达92%。
多时相遥感数据蕴含植物物候光谱信息,利用多时相影像中表现出的光谱、纹理特征差异能提高树种的识别能力。植物物候光谱特征在森林类型遥感分类提取中具有重要价值,许多学者已研究证实:对森林类型识别的精度而言多时相的遥感数据比单一时相更有优势。Tigges et al.[10]利用多时相RapidEye卫星影像,结合支持向量机方法提取柏林市城区内的8类树种,研究结果表明多时相影像能提高城市树种分类精度。张猛等[11]使用时间序列的中分辨率成像光谱仪(MODIS)数据提取洞庭湖流域湿地中,发现多时相数据的地物信息特征区分度高、特征显著,有效减少错分漏分现象。陈继龙等[12]综合2018年1月、6月、9月多时相MODIS数据和Landsat数据提取板栗林的最佳物候时相和分类特征,采用支持向量机法获得较高的板栗林提取精度,达93.45%。红边波段光谱特征对树种分类识别有重要参考价值,Sentinel-2A影像作为目前唯一有3个红边波段(695~793 nm)的中高空间分辨率多光谱卫星影像,对遥感植被分类提取有重要意义[13]。李煜等[14]利用多时相Sentinel-2A影像对落叶松(Larixgmelinii)、红松(Pinuskoraiensis)、阔叶松(Pinuselliottii)等树种进行识别,发现多时相遥感影像的分类精度比单一时相总体精度提高了4%~7%。
目标树种的提取相比土地利用类型分类更复杂,往往需要考虑光谱、纹理、物候及地形等特征。为了充分利用影像对象的光谱、纹理、空间特征等,面向对象结合多时相数据分类时往往设置众多特征参与分类,特征维数过多,导致产生“维数灾难”现象而降低分类精度[15]。因此,从大量特征中选择少量优先特征参与分类是十分必要的工作,能降低特征维度以提高地物分类的精度。高国龙等[16]采用特征优选的面向对象方法,使用ReliefF算法筛选权重大的5个特征对毛竹林进行信息提取,与未进行特征优选前的提取结果、传统的分类回归树(CART)分类结果相比精度均有提高。刘代超等[17]使用多时相高分六号卫星(GF-6)影像对安徽省黄山市进行林地与非林地的识别,采用递归式特征消除(RFE)和随机森林结合的方法进行特征优选,研究表明特征优选能够有效的减少输入维数,并取得最高分类精度。对亚热带地区毛竹林信息提取,采用较高空间分辨率的多时相影像进行特征优选与分类的研究很少。本文以福建永安市试验区为例,采取多时相Sentinel-2A影像作为基础数据源,通过影像预处理后获得多种特征,通过“局部方差-方差变化率曲线”获取最佳分割尺度,利用随机森林算法实现特征优选,采用面向对象的方法提取山地毛竹林信息,并与单时相分类进行对比,旨在为毛竹林经营成效资源监测提供参考。
1 研究区概况
本研究区位于福建省永安市的上坪乡和西洋镇范围内,东经117°25′40″~117°31′35″,北纬25°52′25″~25°59′15″,该地区主要植被类型为毛竹(Phyllostachysedulis)林、杉木(Cunninghamialanceola)林、马尾松(PinusmassonianaLamb.)林以及常绿阔叶树林,年平均气温15 ℃,年平均降水量2 039 mm,并且多集中于5—9月期间,年平均湿度在80%以上。研究区及采样点示意图见图1。
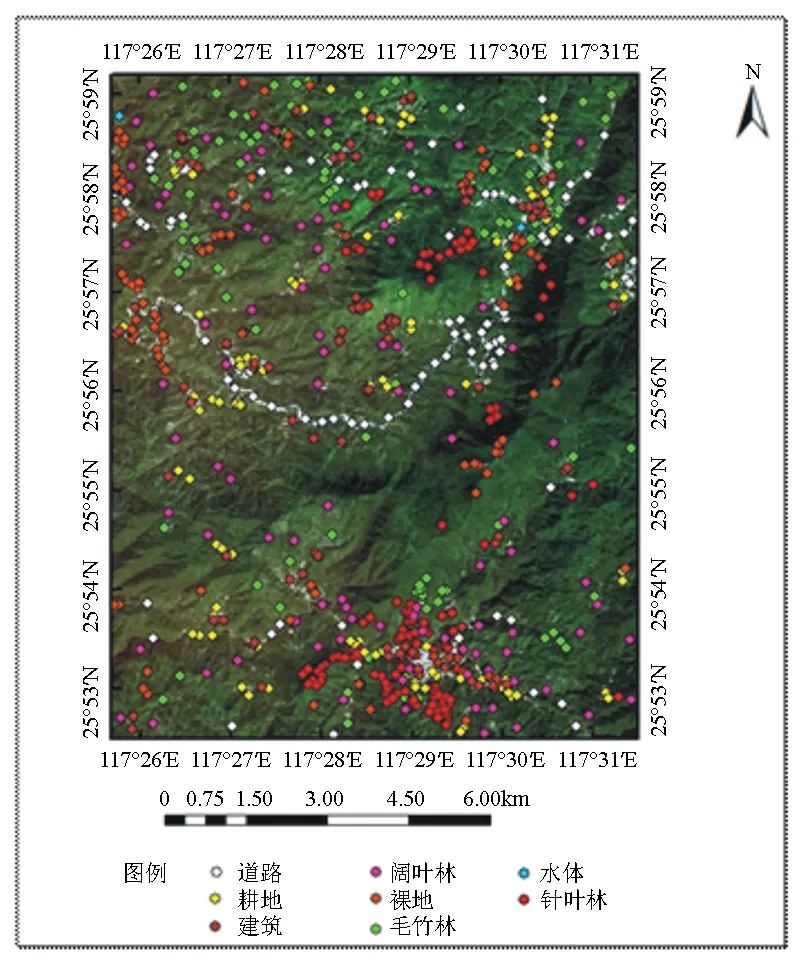
图1 研究区域及样点分布图
2 研究方法
2.1 数据来源
考虑毛竹林的关键叶物候特征,选择展叶前、展叶中、展叶后3个时相的典型多光谱数据,该数据来源于欧航局哥白尼数据共享网站(https://scihub.copernicus.eu/)的2019年12月、2020年4月和10月的三景Sentinel-2A无云影像(见表1)。Sentinel-2A影像波段信息见表2。

表1 Sentinel-2A数据信息

表2 Sentinel-2A波段信息
不同地物类型样本数据通过亚米级分辨率的Google Earth影像进行样本点解译与判读,耕地样本97个、建筑样本103个、裸地样本99个、道路样本99个、水体2个、毛竹林样本100个、阔叶林样本101个、针叶林样本125个,共726个。毛竹林、阔叶林、针叶林森林资源类型结合近期二类调查成果为基础,并到野外核查森林资源类型采样点,共核查240个。随机选取80%样点作为随机森林分类器的训练样本,20%样点作为验证样本。
2.2 数据预处理
由于实验获得Sentinel-2A的数据是经过几何校正和辐射校正的产品,大气校正使用欧洲航天局(ESA)官方提供的SNAP软件Sen2cor插件对原始的L1C级影像进行大气校正,得到L2A级影像数据;使用双线性重采样法将所有波段重采样为10 m分辨率,再影像转换为ENVI格式导出。采用ENVI5.3.1软件将波段B1、B9和B10去除并保留10个波段叠加生成影像,将2019年12月8日的影像作为基准图像,对其他两景影像分布进行配准,配准完毕按照研究区域范围剪裁并导出为TIFF格式。
2.3 研究技术路线
影像预处理后,将多时相光谱数据导入eCognition 9.0软件中,进行面向对象的影像分割过程。提取分割过后对象单元的多时相光谱特征、植被水体红边指数特征、纹理特征构建特征数据库,选择样本数据设计5种多时相特征组合方式和3种单时相方案,使用随机森林(RF)模型对8种方案进行毛竹信息提取,比较提取精度。最后使用所有特征进行优选方案和其他不同分类方法对毛竹林信息的提取效果的对比,研究技术路线见图2。

图2 技术路线框图
2.4 分割参数设置
在eCognition软件中进行面向对象的分割过程,形状因子和紧致度因子的设置区间均为0~1,形状因子越小,对象分割的越细碎,紧致度越小则分割对象的形状越不规则。设置分割尺度均为100的情况下,进行对比试验,设置紧致度为0.5、形状因子为0.4;紧致度为0.5、形状因子为0.5;紧致度为0.6、形状因子为0.5。如图3,图3中的影像为2020年10月的B8、B4、B3波段组成标准假彩色影像。
如图3所示,在紧致度不变情况下,形状因子设置为较小值时对植被的分割有利,在形状因子不变的情况下,紧致度较大时,边界特征较平滑但是与植被分布不相符合,因此需要较小的紧致度。经过多次试验,确定形状因子设置为0.1,紧致度设置为0.5。
采用eCognition软件中的ESP2插件评价分割尺度,ESP2插件采用Drǎgut et al.[18]提出的面向eCognition软件中的多尺度分割算法自动计算最佳分割尺度的插件,计算出目标的局部方差-变化率曲线,公式为:
(1)
式中:RC为方差变化率;VL,L为目标层L层的局部方差;VL,(L-1)为(L-1)层的局部方差。当方差变化率处于峰值时,此点所对应的分割尺度即为最佳分割尺度。
2.5 分类特征提取
本研究根据前人研究经验选取多时相光谱特征波段、植被指数、红边植被指数特征、纹理特征。光谱特征波段为多时相遥感图像的10个波段均值,植被指数选择归一化植被指数,比值植被指数,差值植被指数,增强植被指数[19-22],由于Sentinel-2数据具有丰富的红边波段,建立8个红边植被指数。孙晓艳等[23]的研究表明,添加纹理信息能够提高毛竹林的分类提取精度。冯建辉等[24]的研究指出,纹理特征是一种结构特征,以多种不同的波段计算出的纹理特征具有很强的相关性,因此计算灰度共生矩阵(GLCM)时仅使用一个波段计算即可,红光波段的原始分辨率较高,为10 m,因此选取红光波段作为GLCM的源数据计算纹理特征。据侯群群、陈美龙等的研究,众多纹理特征中存在冗余现象,而对比度、熵、角二阶矩、相关性这几个纹理特征的鉴别力强,足够稳定[25-27],因此选择对比度、熵、角二阶矩、相关性作为本研究的纹理特征。为了减小纹理特征的计算方向对其影响,采用0°、45°、90°、135°四个方向的均值作为纹理特征,具体分类特征见表3。

表3 纹理分类特征
2.6 多时相多种分类特征组合方案设计
本研究设计5种多时相分类特征组合方案,和3种单时相分类方案(见表4),方案1~4不采取特征优选,直接进行分类,目的是为了检验不同的特征组合方式对分类精度的影响,方案4和5则是为了检验采取特征优选方案对分类精度的影响。另设置3个单时相影像进行分类,将其分类结果与多时相方案进行对比。

表4 分类特征组合方案
2.7 应用随机森林算法分类及特征优选
随机森林算法:随机森林(RF)由Breiman[28]提出,由大量的决策树组成一个森林,每个决策树的分类结果代表着它的投票结果,再将这些结果集成为一个分类方案,提高模型的预测能力。
建立随机森林的步骤为:首先通过有放回的抽样抽取约2/3的原始特征数据组成一个数据集合,共抽取N次组成N个数据集合,再将这N个原始特征数据集合分别建立决策树。从每个决策树中的每个节点处随机抽取j个特征,总特征数为J,j≤J,通过不剪枝的方式依据j个特征生成决策树,共N个决策树。通过这N个决策树组成随机森林分类器,其最优分类结果由这些决策树分类结果投票产生。
随机森林算法特征优选:随机森林也有着特征选择的功能,可以对参与分类特征的重要性进行估计,随机森林分类时,每次抽样还剩约1/3没有被抽中,这一部分特征数据被称为袋外数据(OOB),通过这部分OOB可以估计内部误差及不同特征数据间的重要性[29-30]。其特征数据重要性计算公式为:
(2)
式中:M为特征变量;IM表示特征数据重要性;IM越大,其特征重要性越强;N为决策树数量;Bt是在M被噪声干扰时第t个决策树的OOB误差,B0是M没被噪声干扰时第t个决策树的OOB误差,干扰前后的误差差距越大则表明该特征影响分类结果的作用越大,其重要性就越强。
2.8 精度评价方法
利用验证样本对各个方案的毛竹林,针叶林和阔叶林分类结果进行验证,使用混淆矩阵评价指标:总体精度、生产者精度、Kappa系数、用户精度对各方案分类结果精度指标进行评价。
3 结果与分析
3.1 分割最佳尺度确定
在eCognition软件中的ESP2插件评价分割尺度,设置形状因子为0.1,紧致度为0.5时通过ESP2插件计算输出结果如图4,峰值有多个表示评价尺度有多个,所以最佳分割尺度也有多个,需要根据目视解译选择最佳分割尺度。

图4 分割尺度评价计算图
图4中黄色虚线为后期手动添加,由图选取最佳分割尺度有6个,分别为:37、42、51、61、94、113。采用这6个最佳分割尺度进行影像分割,如图5。

图a、b、c、d、e、f为形状因子为0.1、紧致度为0.5条件下,分割尺度分别为37、42、51、61、94、113时的影像分割结果。
通过对比,发现分割尺度为61、94、113时,有欠分割现象产生,不适宜选择这些分割尺度。综合对比剩下3个分割尺度的分割结果,分割尺度为37时分割效果最好,不同树种之间分割最准确也不会过于细碎。最后确定本研究影像分割设置参数为分割尺度37、形状因子0.1、紧致度0.5。
3.2 特征优选
特征优选应用EnMAP-BOX软件[31],利用EnMAP-BOX的随机森林分类器,将全部69个特征导入其中,计算各个特征重要性程度,并导出特征重要性表,按照重要性程度由高到低排列。在eCognition软件中,以5个特征为1个步长,直到所有特征都参与,分别进行随机森林分类,结合其分类精度和Kappa系数选取最优特征如表5。

表5 不同特征个数时的分类精度和Kappa系数
由表5所示,在逐步加入特征个数过程中,当前5个特征加入时,其总体分类精度已经达到了76.56%,表明根据特征重要性程度进行特征优选时,其冗余特征少、相关性低,有利于毛竹林的分类,当前10个特征加入时,分类精度反而出现了小幅降低,此时在不同特征中间可能已经出现了一些冗余。加入更多特征直到25个特征加入时,其分类精度达到一个小高峰,表明特征之间的冗余程度有所降低。当前40个特征参与分类时,分类精度和Kappa系数达到最大,分别为85.93%和0.7852,表明在此时,不同特征之间虽然有一些冗余,但是此时的冗余对分类的影响最小,即表明在特征优选个数为40个时能够实现分类精度的最大化。再直到所有特征都参与时,都未能超越前40个特征参与分类的精度,因此,选取重要性程度排名前40的特征作为优选特征。排名前40特征重要性程度见表6。
由表6可以看出,特征04-SWIR2、10-SWIR2的重要性最高,达到了0.87,而特征2020年4月红边归一化植被指数3的重要性程度最低,为0.19,未能排入前40个重要性特征。前40个特征包括19个光谱特征波段、15个植被指数特征和红边植被指数特征、6个纹理特征。在所选的40个最优特征中,2020年4月的特征最多,达到了16个,2020年10月的特征其次,共15个,说明在分类时2020年4月和10月影像包含的分类特征信息度高,对分类的重要性程度高。所有时相的短波红外波段、红边指数NDVI740、NDVIre1及对比度纹理特征都在40个优选特征中,表明这些特征即使在不同时相也有着较高的分类重要性。40个特征包含19个光谱特征波段、15个植被指数特征和红边植被指数特征,6个纹理特征,表明光谱特征波段及植被指数特征和红边植被指数特征对分类的贡献程度较高。

表6 特征重要性排名
3.3 分类精度评价结果
利用验证样本对各方案的分类结果对比计算混淆矩阵,通过混淆矩阵,计算毛竹林、阔叶林、针叶林各个分类方案及单时相分类方案的生产者精度、用户精度、总体精度及Kappa系数,评价结果如表7。
由表7可知,在多时相方案中,方案1仅使用光谱特征时,由于多时相光谱特征及Sentinel-2A丰富的红边波段信息,分类精度处于中等水平;方案2加入植被指数和红边植被指数特征后,其精度有所提升;方案3仅使用光谱特征和纹理特征时其分类精度却有所下降,说明纹理特征中存在冗余现象,导致其分类精度降低;方案4使用所有特征,分类精度相对于方案2并无明显提高;方案5在方案4的基础上进行特征优选,其分类精度最高,总体精度达到85.94%,Kappa系数0.785 2;而方案3由光谱特征和纹理特征组合的分类情况最差、精度最低。对比分类结果,单时相分类总体精度均低于多时相分类方案,表明多时相影像进行分类时分类效果较好,在毛竹林分类提取方面较有优势。

表7 各方案分类精度评价
3.4 不同分类器分类对比
面向对象的特征优选随机森林方案的分类精度在所有方案中最高,为了对比该方法提取毛竹林信息的优良性能,选取全部特征,选取支持向量机(SVM)和分类回归树(CART)分类器及随机森林(RF)进行分类对比(见表8)可知,SVM方法提取精度最低,总体精度仅59.38%,Kappa系数为0.403 6,CART方法分类精度中等,而本文特征优选的随机森林分类方法即方案5RF分类精度最高,比SVM和CART分类器分类方法精度高,更能有效、精准的提取毛竹林信息。

表8 其他分类器分类精度
应用本文方案5方法提取的毛竹林分布信息如图6。

图6 毛竹林分布信息提取结果
3.5 应用面向对象分类与像元分类对比
将应用像元的分类结果和面向对象的分类结果进行对比,如图7。应用面向对象的分类结果相比于应用像元分类结果的细碎性程度更低,噪声影响更小,能够显著降低“椒盐效应”的产生,增加分类的精度,提高毛竹林的分类效果。

图7 应用面向对象分类与应用像元分类的毛竹林分类信息对比
4 结论与讨论
Sentinel-2A影像有着丰富的光谱信息,在特征优选的40个特征中,光谱特征波段有19个,植被及红边植被指数特征有15个,证明Sentinel-2A影像的短波红外波段、红边波段及红边植被指数在分类时作为植被分类特征有着较高的重要性,在一定程度上对分类精度的提高有着重要贡献。
利用随机森林算法结合面向对象的方法,有效减少了“椒盐现象”产生,且随机森林算法分类稳定性较高,精度相对于SVM、CART分类器有一定程度的提高。
采用多时相数据,面向对象结合随机森林分类及优选的方法在各个方案中表现出更好的分类精度,验证随机森林算法在特征优选方面有效果,并且表明该方法对毛竹林分布信息提取的可行性。
本研究虽采用了多时相数据进行特征提取,但是,由于研究区域内大气云雾的影响,区域的气象现状的约束,无法满足按照月份数据源获得更多时相的数据,在后续的研究中将深入研究不同月份的时相对特征提取的贡献程度,从而实现毛竹林分布信息提取精度的进一步提高。
猜你喜欢
天津农林科技(2022年2期)2022-04-19
农业机械学报(2019年6期)2019-06-27
水土保持研究(2018年5期)2018-10-12
中国农业信息(2018年2期)2018-07-28
乡村科技(2018年8期)2018-06-27
湖南林业科技(2017年1期)2017-02-06
现代计算机(2016年12期)2016-02-28
遥感信息(2015年3期)2015-12-13
西藏科技(2015年1期)2015-09-26
中国交通信息化(2015年6期)2015-06-06
