
基于熵值比-DTW度量奇异值相似度指标的滚动轴承退化历程辨识
2023-01-09 09:48周建清朱文昌王恒
轴承 2023年1期
周建清,朱文昌,王恒
(1.常州市高级职业技术学校 电气工程学院,江苏 常州 213161; 2.南通大学 机械工程学院,江苏 南通 226019)
有效监测滚动轴承性能退化历程,制定针对性的维护计划,可避免设备损坏造成的财产损失及人员伤亡,具有重要意义[1]。基于数据分析的滚动轴承退化历程辨识得到了广泛研究,其关键在于如何构造单调性好且能准确刻画不同状态的性能退化指标。传统方法采用轴承振动信号的时域(如峭度、均方根)、频域(如重心频率、均方频率)及时频域(如小波包分解、经验模态分解)等特征进行分析[2]。文献[3]将 Kullback-Leibler散度作为轴承健康退化指标,可有效量化滚动轴承的不同退化阶段;文献[4]改进了卷积神经网络并用于深层次振动特征提取,结合迁移学习实现了不同工况下轴承运行状态的识别;文献[5]使用经验模态分解算法提取轴承故障特征,对特征向量进行 k-medoids 聚类以构建模型,可更精确地检测早期退化;文献[6]利用应用累积并对JRD(Jensen Renyi Divergence)进行改进,提高了退化指标的稳定性及单调性;文献[7]将排列熵(Permutation Entropy,PE)作为轴承退化特征,通过改进构造出熵能比(Entropy Energy Rate, EER)并作为滚动轴承性能退化指标,其对早期故障更敏感且与轴承故障发展趋势更加一致。
随着人工智能、机器学习的发展,以卷积神经网络(Convolutional Neural Network, CNN)为代表的深度学习算法在轴承特征提取方面也得到了广泛的应用[8],与传统方法相比,其能够挖掘轴承数据更深层次的信息,但由于池化层、隐含层的层数等超参数需要人为设定,缺乏一定的科学性。近年来,许多学者将矩阵论应用于滚动轴承状态监测领域,文献[9]提出一种非负矩阵分解,用于轴承特征提取并实现了轴承故障诊断;文献[10]基于随机矩阵理论对轴承特征矩阵进行分解,将矩阵特征值用于轴承退化指标构建与检测阈值设定,实现了滚动轴承的早期异常检测。
目前,常利用滚动轴承某个时刻退化指标的数值大小及变化趋势监测轴承当前时刻的状态,然而轴承性能退化是一个连续变化的过程,即当前状态与历史状态相关,如何将轴承当前状态及历史信息相结合,构建能准确反映轴承当前状态与正常状态之间差异的性能指标并提高指标对不同阶段的敏感性,避免数据波动干扰轴承退化状态的判定是值得深入研究的问题。动态时间规整(Dynamic Time Warping,DTW)是一种计算时间序列相似性的算法,将时间规整和距离测度计算相结合,利用对2个时序信号的拉伸、对齐等操作获得时间校准匹配路径,通过计算路径间的最短距离描述时间序列间的相似度与差异性[11]。文献[12]利用DTW算法计算时间序列间的相似性并进行状态匹配,与欧几里得距离相比,其对时间序列相似度的计算更为准确;文献[13]利用DTW算法分析手语运动轨迹间的相似性并判断其是否属于同一类别,提高了手语轨迹识别的准确率。传统DTW算法假设序列中的各个点有着相同的作用,从而计算序列间的相似度,而在轴承的实际退化过程中,不同时间段采集到的数据结构及组成可能存在较大的变化,因此利用DTW算法计算轴承信号相似度时不能仅考虑数据序列之间的距离,也应考虑不同状态数据间的差异性。
综上所述,本文基于奇异值分解(Singular Value Decomposition,SVD)算法对轴承数据进行特征提取,结合信息熵和DTW算法计算不同状态轴承退化数据间的相似度,并用其表征轴承全寿命过程中的不同退化历程。
1 基于奇异值分解的轴承特征提取
根据滚动轴承健康监测数据的采集特点,在时间T内对轴承进行N次采样,采样时间记为ti(i=1,2,…,N),采样点数为M,各数据点分别记为x(ti,j)(j=1,2,…,M),在ti时刻采集的数据可构成向量x(ti),即
x(ti)=[x(ti,1),x(ti,2),…,x(ti,M)] 。
(1)
向量x(ti)中涵盖ti时刻轴承不同位置的运行信息,可以看作矩阵x(ti)∈R1×M。对于一个实矩阵B∈RK×K,可引入特征值λ及特征向量y将其替代,λ可用于B中的有用信息,则
By=λy。
(2)
将采集的数据构建矩阵并进行特征分解,将特征值构造退化指标以识别轴承的不同退化阶段[14]。在矩阵论中,矩阵奇异值分解与特征值分解的作用较为相似,不同的是奇异值可适用于矩阵不满秩的情况,具有更大的应用范围。而在矩阵论中,对于一个实矩阵A∈RH×J,可对其进行奇异值分解,则A可写为
(3)
Λ=diag(σ1,σ2,…,σl),
式中:V与VT为正交特征向量矩阵;Λ为对角矩阵;σi为采样时刻ti对轴承数据进行奇异值分解后所对应的奇异值,且l=min(H,J)。
对ti时刻采集到的轴承数据x(ti)∈R1×M进行分解后,可从对角矩阵Λ中提取到一个奇异值,故在采样时间T内,对不同时刻的轴承数据进行分解并提取不同时刻的奇异值,可构造出退化时间序列G∈R1×N,即
G=[σ1,σ2,σ3,…,σi,…,σN]。
(4)
2 基于熵值比-动态时间规整构造奇异值相似度指标
滚动轴承由正常运行至完全失效是连续变化的过程,当轴承受到损伤进入退化状态,其损伤的衍变规律应与前n个历史状态有关,单独取某一时刻的特征去判断轴承状态是不合理的,因此本文将相互邻近的多个特征点构成时间序列,利用DTW算法分析轴承的退化历程。
确定一段轴承正常状态信号序列作为参考模版P=[p1,p2,…,pa],构造其他时间段的退化序列作为测试模板Q=[q1,q2,…,qb],其中pa和qb分别表示参考模板的第a个和测试模板的第b个特征矢量值。对齐路径li用于描述P与Q之间数据点的对齐关系,其被定义为包含s个二元组的集合,每个二元组包含2个分别来自时间序列P和Q的数据点,l可表示为

(5)
序列P与Q之间所有对齐路径的集合记为AP,Q。DTW的目标是最小化两段时序数据中所有对应数据点的局部距离值之和,其定义为
(6)
d(pa,qb)=∣pa-qb∣2,
(7)
式中:d(pa,qb)为矢量间的距离。
DTW算法采用动态规划思想,利用递归公式将以上问题转换为对P和Q中特征矢量距离的求解问题,即
(8)
将规整后路径间的距离作为量化指标,可对不同序列的相似性进行有效度量,规整后的距离越小则序列间相似度越大。在轴承的实际退化过程中,不同状态对应的数据结构及组成可能产生较大的变化,所蕴含的信息不同,在计算序列间相似性时应考虑不同状态数据结构间的差异性。熵值可反映信息可靠程度,系统混乱程度越高则熵值越大,本文将信息熵之比引入DTW算法中用于优化奇异值指标,其步骤如下:
1)从退化时间序列G∈R1×N选取a个连续的正常数据点作为参考模板P并保持不变。采用滑动时间窗口从时间序列G中提取不同时刻的数据作为测试模板,设置时间窗长度为b,则ti时刻构造的测试模板Q(ti)为
Q(ti)=[σi-b,…,σi-2,σi-1,σi] ;b≥i≥N,
(9)
从σb开始,滑动时间窗锁定的第1个测试模板为Q(t1)=[σ1,σ2,σ3,…,σb],随后时间窗每次后移1个单位,共移动N-b+1次。利用DTW算法计算2个模板间的相似度,在ti时刻测试模板Q(ti)与参考模板P的距离(即相似度)记为di。
2)分别计算参考模板和测试模版中奇异值对应相似信号的信息熵值及熵值比,即
(10)
(11)
式中:a,b分别为参考模板和测试模板中相似信号对应奇异值的个数;xk(ti,j)为将ti时刻所采集数据x(ti,j)分解k次后相似信号中第j个数据的值;wi为ti时刻测试模板与参考模板距离间的权值。
3)将ti时刻对应的权值wi与DTW相似度距离di点乘得到加权后的相似度dw,i。将不同时间段的相似度通过权熵值进行优化可得到加权后的距离矩阵D=(dw,1,dw,2,…,dw,i,…,dw,N-b+1),将其归一化处理后用于对轴承退化历程进行辨识。
综上所述,本文所提基于熵值比-DTW度量奇异值相似度指标的构造流程如图1所示。

图1 基于熵值比-DTW度量奇异值相似度指标构建流程图Fig.1 Constructed flowchart of singular value similarity index based on DTW optimized by entropy ratio
3 应用研究
3.1 数据来源
本文采用辛辛那提大学智能维护系统(IMS)中心的滚动轴承全寿命试验中轴承1的数据进行应用研究,该试验采用加速度传感器每 10 min采集一次轴承振动信号,采样频率为20 kHz,当轴承1外圈发生故障时结束试验,整个试验共经历9 830 min。取奇异值序列G中正常状态下的序列段[σ1,σ2,σ3,σ4,σ5]为参考模板,测试模板长度b=5,利用DTW计算其相似度并结合熵值比进行优化,采用优化后的相似度指标辨识轴承1的退化历程。
3.2 基于SVD算法的轴承奇异值特征提取
利用SVD算法对轴承各个时刻的数据进行分解,提取各个时刻对应的奇异值并进行归一化处理后,构建的轴承全寿命历程退化指标如图2所示,通过3σ准则可在5 370 min检测出轴承早期异常的发生[15],与文献[16-17]分别为5 350,5 330 min的检测结果比较接近,与峭度指标(图3)相比可提前1 122 min检测出轴承早期异常的发生,且奇异值指标在退化时期整体呈单调向上的趋势,数据曲线波动小,稳定性高。然而,在轴承“自愈现象”发生(7 000~9 000 min)时,奇异值指标存在明显“上升—下降—再上升”的起伏波动[18],给轴承状态判断带来了干扰,难以判断图3中A,B范围内具有相同指标值数据点所对应的退化状态。
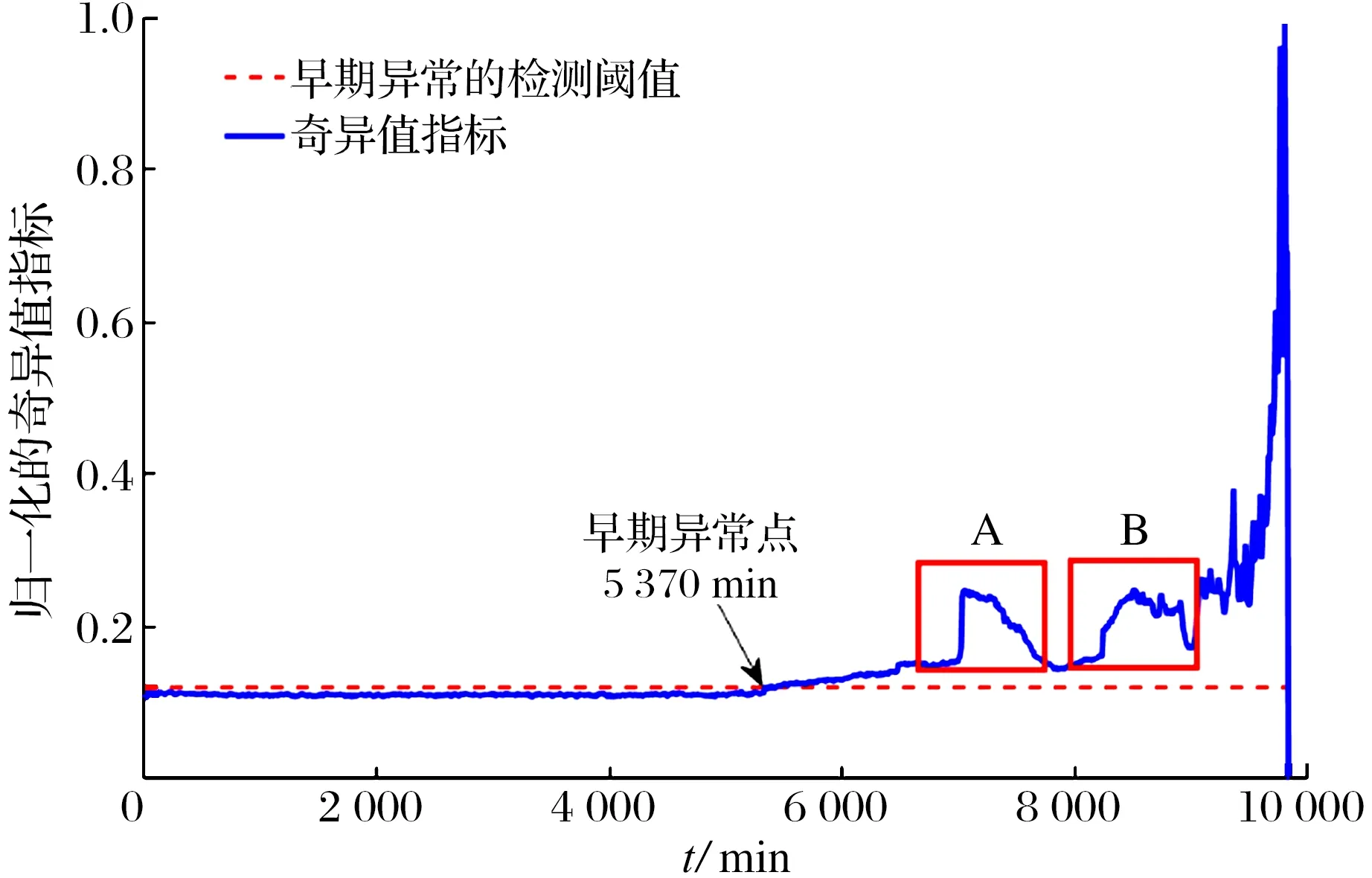
图2 基于奇异值指标轴承全寿命历程Fig.2 Bearing full life history based on singular value index
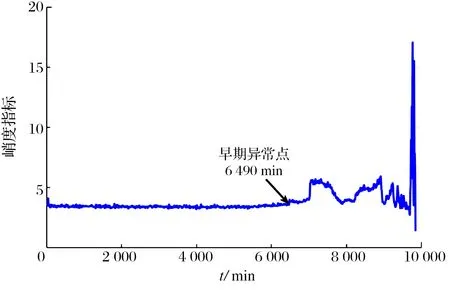
图3 基于峭度指标的轴承全寿命历程Fig.3 Bearing full life history based on kurtosis index
3.3 基于熵值比-DTW构造奇异值相似度指标
为进一步提高退化指标整体的单调性及对早期异常的敏感性,将动态时间规整算法与熵值法相结合,从时间序列及数据结构两方面共同对轴承奇异值指标进行处理。以10~50 min轴承正常状态奇异值序列为参考模版,提取1 210~1 250 min与8 010~8 050 min奇异值序列作为测试模板分别计算相似度,计算过程如图4、图5所示。在参考模板不变时,由图4a可发现测试模板为1 210~1 250 min时,对于2个原始序列变化趋势不同的曲线,可通过DTW算法对曲线进行伸长、对齐操作后将其转变为具有相同变化趋势的曲线,计算对齐后各对应点间的最小距离并最终得到规整后的最短路径(从数值较小的深色区经过),如图4b所示,累积距离大小为0.867,这是由于轴承在1 210~1 250 min期间处于正常状态,参考模板也处于正常状态,2个序列的相似度较高,规整得到累积距离较小;当测试模板为8 010~8 050 min 时,序列间的差异较大,DTW算法难以将其规整为相同退化趋势的曲线,且规划出的路径经过浅色区域,累计距离较大(11.415,约正常状态下相似度的13倍),如图5所示。因此, DTW算法可放大不同时间序列间的差异性。
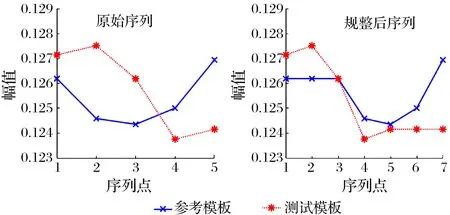
(a) 时间序列规整

(a) 时间序列规整
利用DTW处理轴承数据时只考虑了不同时间段时间序列的相似性,未考虑不同时间段数据结构之间的差异性。因此,本文采用熵值比分析轴承的全寿命历程,结果如图6所示:当轴承处于正常状态,熵值比近似为一条直线;当轴承进入异常状态,熵值比有明显的上升趋势;随着轴承故障加剧,熵值比不断增大,表明熵值比表征数据结构间的差异是可行的。

图6 滚动轴承全寿命历程的熵值比变化曲线Fig.6 Change curve based on entropy ratio of rolling bearing's full life history
以(10)、(11)式计算测试模板中奇异值所对应相似信号的熵值比作为权值,用其优化动态时间规整算法所测的相似度,最终构造出轴承1的性能退化曲线,结果如图7所示:利用3σ准则检测出轴承1的早期异常点在5 330 min,优化后的相似度指标可更早检测出轴承的早期异常点,且指标的整体单调性及对异常状态的敏感性均得到了较大的提高。
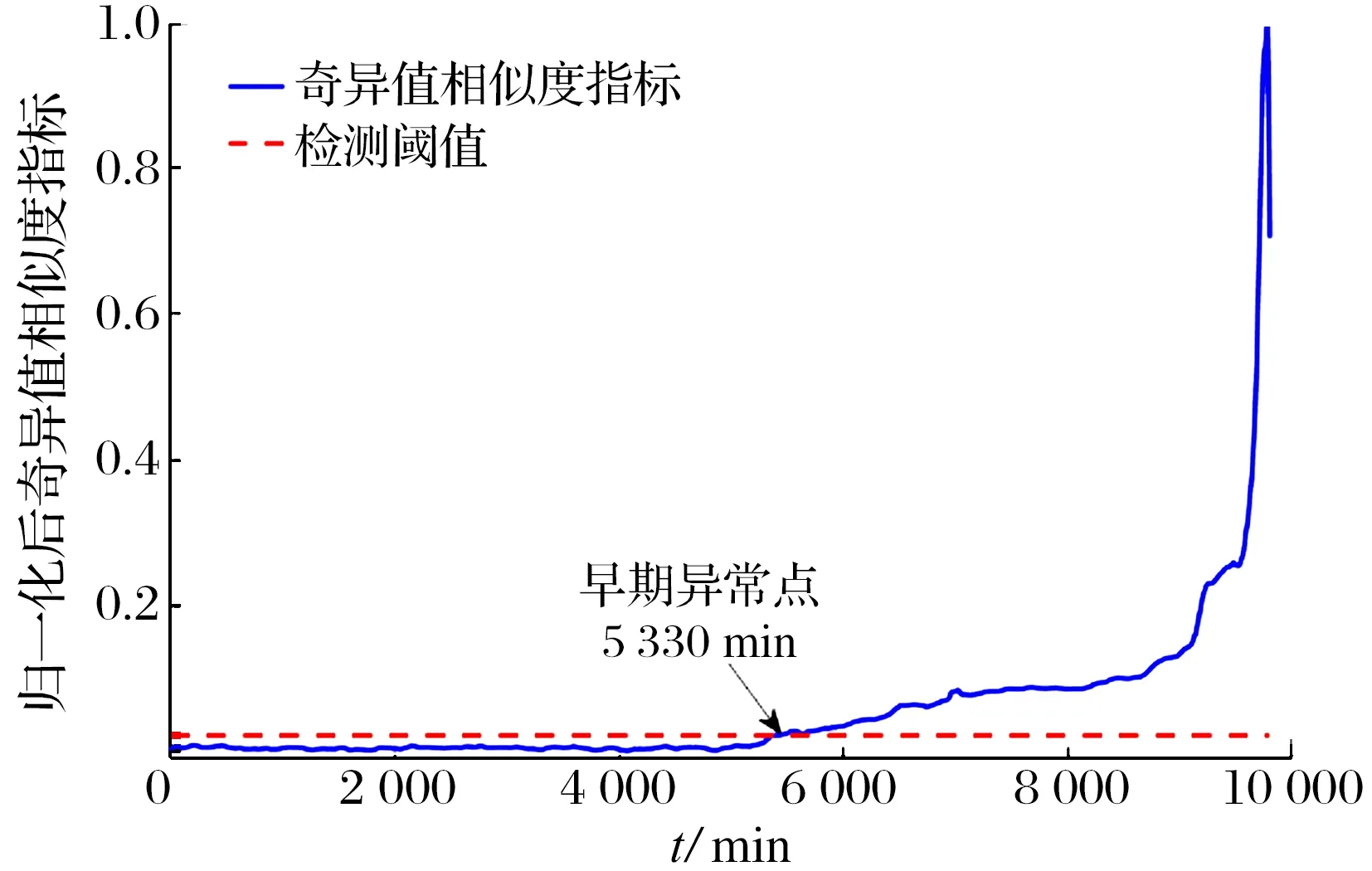
图7 基于奇异值相似度指标的轴承退化曲线Fig.7 Bearing degradation curve based on singular value similarity index
3.4 轴承退化历程辨识
基于奇异值相似度指标对轴承的退化历程辨识结果如图8所示:
1)在5 330 min前指标变化平缓,波动较小,可划分为正常阶段。
2)5 330~6 910 min期间退化指标较正常状态有较为明显的上升趋势,可定义为轴承的早期退化阶段。
3)7 020~8 640 min期间指标幅值比上一阶段更大,但上升并不明显,可定义为轴承的中期退化阶段。这是由于轴承1发生了“自愈现象”,即当前阶段轴承表面由于长时间运行出现了裂纹及小的剥落,滚动体不断运转将此缺陷抚平使轴承仍可保持较稳定的运行状态,但轴承的疲劳磨损仍在发生,指标仍有上升趋势。与处于相同阶段的指标相比(图2、图3),基于熵值比-DTW构建的奇异值相似度指标的单调性较好,避免了数据波动对状态判断带来的干扰。
4)轴承的严重退化发生在8 640~9 560 min期间,在此之前经历了“损伤—愈合—再损伤”的阶段,在8 640 min后,轴承损伤加剧,运行状态极不稳定,退化加速;直到9 560 min后,退化曲线上升剧烈,轴承失效并将完全损坏。
经过熵值比-DTW构造的奇异值相似度指标检测的早期异常点、严重故障的检测结果与文献[19-20]基本一致,证明了基于相似度退化曲线对轴承退化历程划分的有效性。
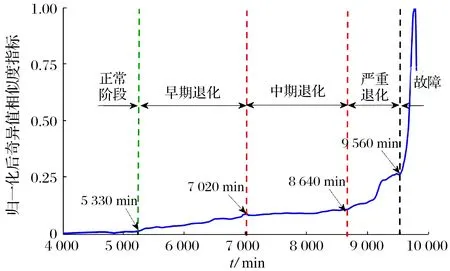
图8 基于奇异值相似度指标的轴承全寿命状态识别Fig.8 Identification of bearing full life state based on singular value similarity index
3.5 不同退化指标性能对比
为进一步研究奇异值相似度指标的有效性,从2个方面对指标进行量化分析:1)单调性,滚动轴承退化具有不可逆性,构建的退化指标是否随轴承运行时间共同增长;2)鲁棒性,构造出的退化指标是否具有抵抗数据频繁波动干扰的能力。单调性、鲁棒性分别定义为
m(D)=
(12)
(13)

提取轴承1 在5 330 min(早期异常点)后的退化序列进行单调性及鲁棒性分析,并与基于随机矩阵理论(RMT)和主成分分析(PCA)结合构造的融合特征指标[14],基于优化经验小波变换及卷积神经网络的EWT-CNN指标[19],传统峭度和均方根(RMS)指标进行对比,结果见表1。

表1 不同退化指标的单调性及鲁棒性Tab.1 Monotonicity and robustness of different degradation indexes
由表1可知:与其他退化指标相比,基于熵值比-DTW算法的奇异值相似度指标的单调性及鲁棒性均有明显提升;这是由于DTW算法通过计算轴承不同时间序列的相似度放大了时间段的差异,结合信息熵比进一步凸显了正常与异常状态数据结构内部的差异性,显著抑制了轴承全寿命历程中退化指标的“上升—下降”波动现象,可更准确地表征轴承全寿命历程中的损伤衍变过程。另外,奇异值相似度指标划分确定的轴承早期异常点及严重故障点与EWT-CNN指标的划分结果较为接近,可更好地辨识轴承的不同退化阶段。
4 结束语
本文借鉴矩阵特征值在轴承健康监测领域中的良好应用效果,对轴承信号进行奇异值分解并构造奇异值退化序列,同时考虑到轴承退化的连续性及所采集轴承数据间的差异性,将DTW及熵值比优化后构建出的奇异值相似度指标用于表征轴承异常的衍变过程,为轴承健康状态监测的研究提供了一种新思路。
对退化指标单调性及鲁棒性的量化分析表明本文奇异值相似度指标可有效克服轴承退化过程中由于数据频繁波动对不同退化阶段识别带来的干扰,且与其他退化指标相比具有更好的敏感性,整体性能较好;但本文所提优化算法的整体流程较复杂,需进一步研究算法复杂度的降低问题。
猜你喜欢
建材发展导向(2022年23期)2022-12-22
建材发展导向(2022年12期)2022-08-19
党员文摘(2022年14期)2022-08-06
哈尔滨轴承(2022年2期)2022-07-22
哈尔滨轴承(2022年1期)2022-05-23
党员文摘(2022年7期)2022-04-28
党员文摘(2022年1期)2022-02-14
党员文摘(2022年3期)2022-02-12
哈尔滨轴承(2021年2期)2021-08-12
哈尔滨轴承(2021年1期)2021-07-21
