
基于区块链加密的科研诚信数据分析与评估技术研究
2023-01-08 16:48:48赵婧帆潘利民黄永刚史宝林
电子设计工程 2023年1期
赵婧帆,潘利民,黄永刚,史宝林
(河北北方学院附属第一医院,河北张家口 075000)
随着科学技术发展水平的提升,科研诚信已成为了热点问题。加强科研诚信的建设,对于科技发展和保障社会公平正义具有重要的意义。随着科研数据量的快速增长,对其进行深入地分析不仅要针对现有数据,还需对未来快速增长的数据也进行准确可靠的预测。而区块链技术,恰好适合解决此类数据交互问题。
区块链也被称为分布式账本,其是一个防篡改的附加数据交易列表,并对这些交易使用密码学进行链接和保护。同时,区块链技术去中心化的组织模式,也保证了数据交互不会被篡改。因此,该文基于科研数据的建模,使用区块链技术研究了科研诚信数据的分析与评估问题。
1 科研数据建模
为了对科研数据进行评估,该文提出了一个诚信模型,其涉及相似性、可信度与最终声誉的测量。该模型根据事件进行更新,相似性测量依赖近邻数据的相关度量测。最终声誉通常使用一般声誉和基于近邻数据的声誉来评估可信度值。
1.1 相似度量测
该文使用皮尔逊相关系数量测两个数据之间的相关性[1]。数据u和数据k之间的相关性PCu,k可由式(1)得出:

1.2 可信度量测
可信度量化了数据与其邻近数据之间的关系[3]。若数据u对于邻近数据k的分析结果影响增大,则u在k中的可信度增加[4]。数据u和k之间的可信度Tu,k的计算如式(2)所示:

式中,nu,k表示由k传递给u的数据分析结果;Nu,k表示k被选为u的邻近数据的次数。
1.3 最终声誉量测
可信度是基于单一数据个体的科研数据可靠性量测指标,此外还使用最终声誉来量测总体数据的可靠性[5]。为此,该文采用了一般数据声誉和基于邻近数据的声誉两种不同数据的综合建模方法。
一般数据声誉采用数据本身的平均可信度来量化数据声誉。数据u在系统中的一般数据声誉Ru如式(3)所示:

式中,Tu,k可由式(2)得出,而U表示整体数据。
基于邻近数据的声誉使用数据与其邻近数据间的成对可信度来量化数据的声誉。数据k包含数据u的基于邻近数据的声誉Ru,k可由式(4)得出:
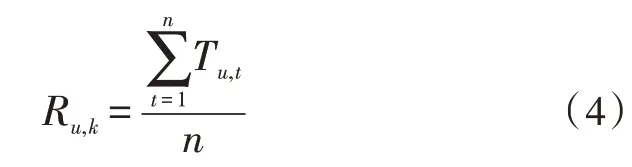
其中,t代表u和k之间的共同邻近数据;Tu,t是数据u和t之间的成对可信度;n是u和k之间的邻近数据总数[6-8]。
从式(1)-(4)可以看出,任何一个数据的邻近数据均会对算法产生重大影响。该文使用k-NN(k-Nearest Neighboors)算法,对科研数据进行在线聚类[9],并为每个传入的评级事件近乎实时地进行预测与模型更新。同时为了识别近邻数据,采用皮尔逊相关算法确定数据间的相关性,以检测最近的邻近数据。而聚类生成数据用于支持以下两种分析方法[10]:
1)使用式(1)来计算采用多标准评级的ru,i,然后通过式(5)确定数据u对特征i评分ru,i的预测。

式(5)中,*表示内积运算。
2)基于信任的数据分析方法。首先使用式(3)计算数据k被识别为数据u邻近数据的次数。式(6)定义了数据u的n个临近数据的可信度Tu,k为数据u对特征i的评级预测

2 基于区块链的数据分析方法
为确保数据分析的安全性,该文使用区块链技术,用于实现数据文件跟踪、验证与历史跟踪的流程。所使用的区块链系统如图1 所示[11-12]。

图1 系统框架
该系统支持现有存储基础架构中的数据保留、归档、文件验证和历史跟踪,并可监视由用户注释的文件或指示是否可以更改以及何时更改[13]。此外,该系统在区块链上还能够自动生成与部署这些智能合约,并提供审计功能和对存储在区块链上的元数据的安全访问。系统的主要功能包括存在证明、文件验证和历史跟踪。
2.1 文件跟踪
该节使用区块链技术监控文件的工作流程如图2 所示,其包括以下步骤[14]:

图2 区块链注释监控流程
1)用户对文件进行注释,以便进行长期文件跟踪。
2)根据文件跟踪模板,自动生成该文件的专用智能合约。
3)将生成的文件追踪合约提交至区块链。
4)成功部署到区块链后,返回唯一的智能合约地址,并将其作为元数据附加到存储系统的文件中,同时关联智能合约和文件。
5)使用加密单向散列函数计算文件散列。
6)将所有数据解析为对应的文件合约。
7)系统收到数据并将其写入区块链。
8)若存在某个文件的其他队列交易,系统将把所有交易按照时间顺序提交到区块链。
2.2 文件验证
验证跟踪文件的工作流程如图3 所示[15]。

图3 验证文件工作流程
验证文件的工作流程如下:
1)用户从文件系统中请求访问一个文件。
2)系统根据元数据附加的智能合约地址来加载相应的文件跟踪合约。
3)系统从加载的文件跟踪合约中寻找最后一个已知的哈希值。
4)智能合约验证功能在区块链的最新副本上进行本地执行,获取存储在区块链上的最后一个已知哈希值。
5)计算存储系统中存储文件版本的哈希值。
6)当前产生的哈希值与存储在智能合约中的最后一个值进行相互比较;若两个值匹配,则认定文件一致[16]。
7)系统允许用户加载验证文件。
此外,系统允许用户根据存储在区块链网络上的真实情况验证其本地文件副本,且无需接触远程文件。
2.3 文件历史跟踪
通过使用专用智能合约将包括存储系统维护等附加属性(例如所有者、时间戳及URI)的文件哈希存储在区块链上,从而能够确定文件的更改时间。若存储的文件被修改,则包括新文件哈希在内的更新文件属性将被附加到智能合约上,并存储于区块链网络中。而一旦交易被确认,便可唯一确定网络中的所有操作记录,这是因为区块链上的交易无法修改或删除。此外,文件历史追踪还能够在无任何第三方干扰的情况下完成。
3 数值实验验证
验证实验均采用节点集群,且每个节点都配备了一个四核Intel Xeon CPU,16 GBRAM 和三个1 TB的7 200 RPM 机械数据存储磁盘,且所有节点均通过单个交换机与一个千兆以太网相连。同时,节点内运行Linux 操作系统和Java1.8.0 软件语言。
为了对文中设计的技术进行研究,通过使用KNN算法预测评分,并评估该方法的预测及准确性。首先通过使用基于区块链的科研数据分析算法,在不同的数据近邻分类策略下,分别计算数据分析的召回率、目标召回率以及均方根误差,结果如表1 所示。其中,较低的均方根误差和较高的分类值(召回率和目标召回率)均可体现出算法具有较为理想的分析准确度。

表1 分析结果对比
从表1 可以看出,随着近邻数据个数的增加,算法对于数据分析的准确度逐渐上升,且均方根误差持续减小。
科研数据分析技术的优劣不仅取决于对数据的分析质量,还取决于分析技术的正式运行情况,因此,该文还对科研数据写入及验证文件的响应时间进行了测试。实验在Linux 操作系统下生成固定大小(64~8 192 MB)的随机文件,其写入时间的测试如图4所示。
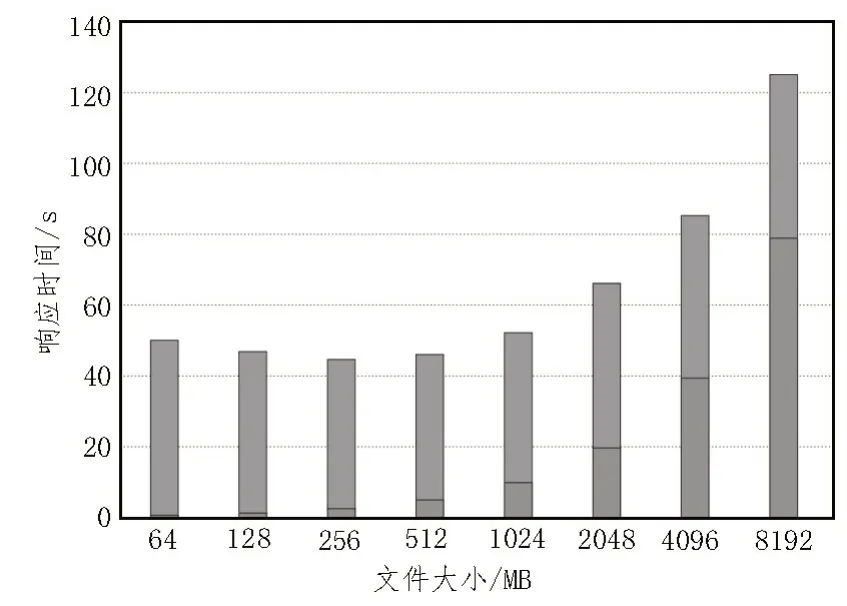
图4 文件写入时间测试
如图4 所示,科研文件大小均在1 024 MB 以内时,收集元数据以及发送和确认合约交易的平均响应时间为48.5 s,且写入响应时间大致相同,因此与文件大小关系并不明显。此外还可以发现,写入时间的最大值和最小值相差较大,分别为45.590 s 和125.843 s。这是因为交易确认占用了大部分响应时间,故测试网络在考虑效率的情况下应该将大型文件进行延迟处理。
图5 为系统验证不同大小文件响应时间的实验结果。在使用区块链技术读取文件之前,对文件进行了50 次修改,以生成相应文件跟踪合约内的数据。当文件较小时(小于1 024 MB),与写入响应时间相比,验证的耗时较少,且均在20 s 以内。原因是检索文件哈希智能合约的执行可在本地完成,所以无需在区块链网络上进行任何交易。
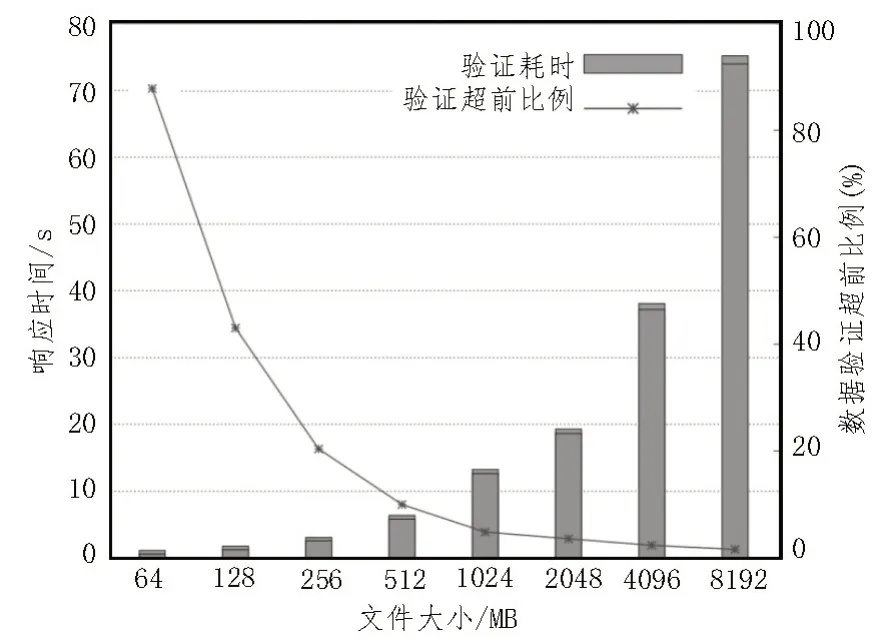
图5 验证响应时间实验
该文采用Gas 来衡量创建及修改单个文件的成本。Gas 是区块链技术中使用的特殊单位名称,其用于衡量一个动作或一组动作需要执行的工作量。实验时,首先生成一个1 024 MB 的文件;然后将文件加载到系统中,并重复10 次上述两个步骤,以覆盖系统的文件,即可以保证系统的数据安全可靠。在系统安全的前提下对文件的操作成本统计如下:当一个创建文件在部署相应的智能合约时,第一步需要花费147 060 Gas,且之后的每次修改均会持续花费132 060 Gas,这是因在测试网络上执行的操作数量完全相同。需要强调的是,测试网中的文件操作Gas 消耗量可能与公共网络上有所不同。因此,在公共网络上使用区块链分析技术时,不仅需要考虑到文件操作的成本,还应分析需要跟踪文件的成本及数量。
4 结束语
针对科研诚信数据的分析与评估问题,该文使用多种评价指标建立了一个诚信模型。同时为保证科研数据文件跟踪、验证和历史追踪的可靠性,利用区块链技术建立了数据分析方法,并通过实验验证了该技术的可靠性。更广泛的科研诚信数据具有大时间跨度的特点,且基于多种语言载体,其具有异常细节难以全面量化的问题,这将是未来研究的重点。
猜你喜欢
考试与评价·高二版(2020年3期)2020-09-10 07:22:44
中国科技信息(2016年16期)2016-09-10 03:12:33
工业设计(2016年8期)2016-04-16 02:43:34
计算机工程(2015年8期)2015-07-03 12:20:04
计算机工程(2014年6期)2014-02-28 01:25:40
河北金融年鉴(2014年0期)2014-02-27 13:20:15
电子设计工程(2014年12期)2014-02-27 11:58:03
中国工程咨询(2011年4期)2011-02-14 01:22:42
企业文明(2005年5期)2005-04-29 00:44:03
