
分层集群技术与数据流负载均衡研究
2023-01-05 07:52钟云南陈行滨占彤平林旭军谢妙红
粘接 2022年12期
钟云南,陈行滨,占彤平,林旭军, 陈 珺,谢妙红
(1.国网福建省电力有限公司,福建 福州 350000; 2.国网信通亿力科技有限责任公司,福建 福州 350003)
随着智能电网的铺设,智能化设备大量投入使用,随之产生的数据量也急剧攀升,这种海量的数据流既带来了潜在的分析价值,也带来了处理上的挑战。数据量的激增势必引起一系列数据采集、监测、分析系统的性能问题,因此在大数据时代,性能优异且可靠性高的数据分发与调度机制在保障电力系统高速运算、提升系统稳定性方面非常有研究价值。
1 智能电网数据流与集群技术
1.1 数据流特点
随着智能设备的投运,电网中各类监测数据的规模日益增长,正常情况下,各类监测设备按照采集频率进行数据传输,但当电网出现故障或超限等情况时,复杂的数据流既包括时间紧迫的告警数据,又包括大量的异常状态以及常规采集数据,导致数据接收节点压力倍增,难以及时处理,甚至造成数据丢失,系统可靠性随之降低。
1.2 云计算及集群技术
云计算是一种分布式计算,具有规模大、高可靠、可扩展等特性,集群主要是利用互相连接的计算机构成分布式系统,负载均衡集群即可按照一定的策略将任务进行分发,实现迅速响应。云计算技术可以缓解智能电网数据量大带来的存储、分析问题,集群则可避免任务堵塞,提升处理性能[1-2]。
2 集群分层架构设计
2.1 集群分层架构
针对智能电网数据流的特点,选用云计算集群进行数据处理,云计算集群虽然可以提供优质的计算服务,但数据大批量到达时接收节点难以处理全部数据,分发至其他节点则涉及到中枢节点进行分配,不仅耗时耗力,而且部分节点资源利用率难以饱和,还容易造成数据堵塞或数据丢失。针对这一情况设计了“中枢层-次级层-区域层”的集群分层架构,具体如图1所示。利用划分区域后再合并为层,由中枢节点统一调配;区域需要进行扩展时只需操作本区域的控制节点,只有在区域的整体负载值过高时才由中枢节点调度迁移任务至同层的其他区域[3-4]。
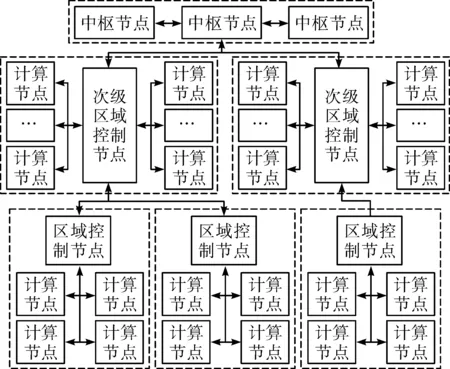
图1 集群分层架构Fig.1 Cluster hierarchical architecture
2.2 区域内节点结构
集群分层之后,每一层包含多个区域,每一个区域内需具备控制节点,在节点之上建立资源管理器、任务管理器与任务调度器,以此处理任务队列。各个节点的结构相同,结构如图2所示。数据流到达之后进行初步识别,然后进行分类处理;告警数据又分发队列快速广播,异常数据需要先进行备份,常规数据则按照优先级进行处理[5-6]。
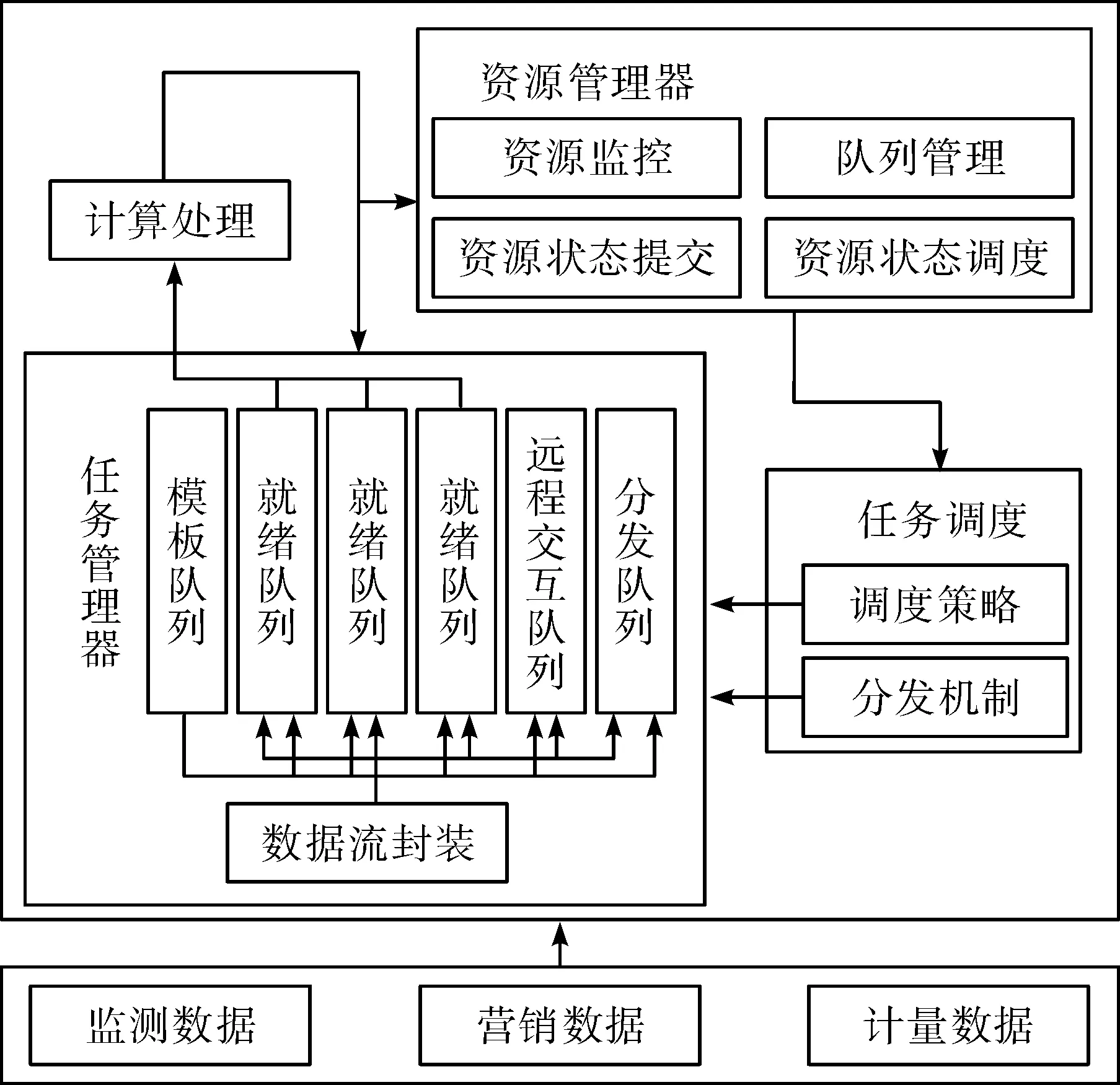
图2 集群节点结构Fig.2 Cluster node structure
3 最佳节点及区域寻优
3.1 目标节点选择流程
当数据流抵达之后,需要选择一个目标节点进行处理,先在区域内查找是否存在空闲节点,当区域内的节点负载都比较高时,扩展到同层级的相邻区域,确保区域资源利用状态最佳。首先,选择中枢节点作为聚类中心,利用带宽、时延等分量作为距离组成区域,利用区域的中枢节点再次聚类形成层级。其次,在节点负载过高时,利用改进蜂群算法向其他节点分发,均衡负载。最后,在本区域负载过高时,利用改进爬山算法向层级内其他区域分发。
3.2 基于改进蜂群算法的最优节点选择

基于改进的蜂群算法,将采蜜蜂和观察蜂合并,利用采蜜蜂联系对应节点记录资源状态,利用侦查蜂搜索信息,判断是否存在资源多的节点,寻找新节点的搜索空间可记为fid=fmin+φfd,其中fd为负载均衡度差值。当f≤fid则放弃资源最少节点,将新节点加入调度列表[9-10]。
3.3 基于改进爬山算法的最优区域选择

4 基于负载均衡的自动分发与任务调度
4.1 自动分发机制
针对智能电网不同时的数据类型,以云计算分层集群架构为基础,按照时间、优先级分发至不同的中枢控制节点,且在周边节点进行备份,提升系统可靠性,避免节点故障导致数据丢失[11-12]。分发机制包括:
(1)告警数据:优先封装送入分发队列,向本区域内所有节点进行广播,并且上报上层控制节点;
(2)异常数据:由区域的中枢控制节点选择本区域内的计算节点进行备份,不立即分析;
(3)常规数据:接收后按序执行,进行分析并存储。
4.2 调度优先级设定
对于智能电网的数据包括很多类型,不同的数据类型包含的信息差异性较大,比如告警数据比常规数据的价值更高,因此在进行调度时需关注数据流处理任务的优先级。处理任务特征主要包括价值和时间2个方面。
4.2.1价值特征
数据流处理任务的价值包括数据在整个系统中的核心程度g以及告警、常规、异常等数据类型价值k,2个部分共同组成处理任务的有效价值W。影响程度可利用公式:Wi=αgi+βki计算,其中α、β为系数。
4.2.2时间特征

结合任务的价值特征和时间特征动态分配处理任务的优先级,分配公式记作Pi=αTi+βWi,其中α为时间特征权值;β为价值特征权值[5]。
4.3 任务调度算法
对于到达的数据流处理任务,不仅需选择目标节点还要兼顾任务优先级。同时,在进行区域内调度时由于时延较短可选择优先处理时间紧急任务,在进行层级间调度时主要选择截止时限较远且本区域无法及时处理的任务[15]。任务调度过程如图3所示。
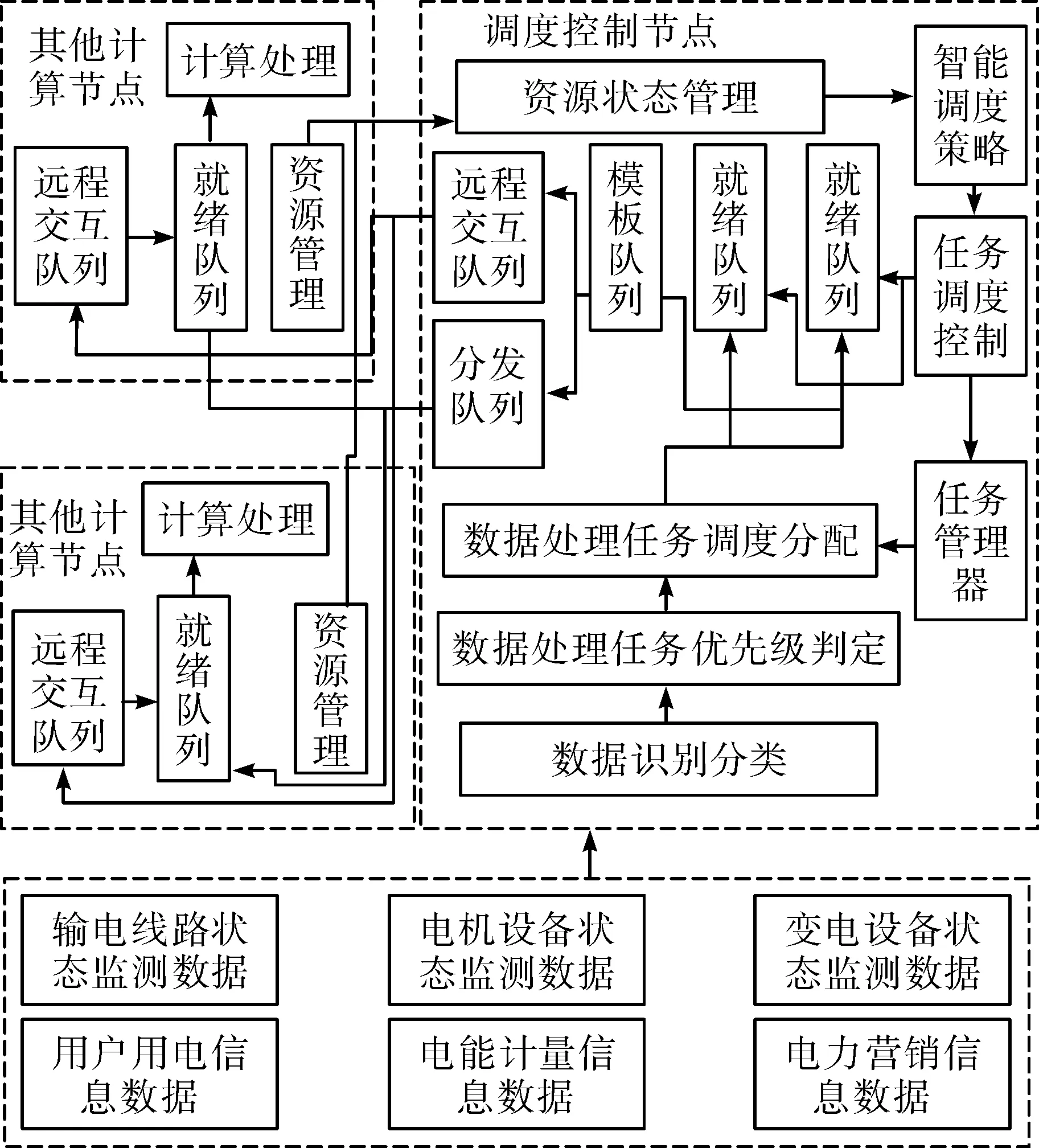
图3 任务调度算法Fig.3 Task scheduling algorithm
整体调度算法如下:
(1)调入处理队列,进行初始优先级判断,如果队列任务已满但节点任务未达到期望值,则创建新队列并调入;
(2)判断节点待处理任务数是否超出期望数量,超出则进行迁移,均衡负载;
(3)当节点待处理任务数未达到预期值,与队列阈值进行比较,未到阈值时比较队列元素与当前任务的优先级:如果当前任务优先级高则提交处理,否则优先处理原队列任务[16-17]。
5 算例分析验证
5.1 调度算法任务完成率对比
为验证本文构建任务调度模型的实际效果,部署Storm和Kafka作为云平台,搭建1个中枢节点,2个次级区域、每个区域5个计算节点的云计算分级集群架构。利用国内某小区半年内用电信息作为测试数据,将告警数据作为重要任务;利用本研究设计的任务调度算法进行自动分发,与经典的最早截止时间优先的EDF算法、最高价值优先的HVF算法进行对比[18],结果如表1所示。

表1 不同调度算法重要任务完成率Tab.1 Important task completion rate of different scheduling algorithms
5.2 任务处理完成时间对比
重要任务完成率是衡量调度算法优劣的一项指标;另外,由于智能电网的数据流具有时效性,还需要考虑算法的处理时长,同样与经典的EDF、HVF算法进行对比,结果如图4所示。

图4 不同调度算法任务处理完成时间Fig.4 Task processing completion time of different scheduling algorithms
5.3 结果分析
随着任务个数的增加,完成率会有所下降;但与其他经典算法相比,本研究设计的任务调度算法下降幅度相对平缓。与此同时,由于考虑到处理任务的价值特征及时间特征,相对来说本算法任务完成时间更短,调度效果更好[19-20]。
6 结语
针对智能电网的数据流特性,采用云计算分层集群架构,利用改进蜂群算法及爬山算法进行计算节点的选择,并引入价值特征与时间特征,综合判断处理任务优先级,制定动态分配策略,根据优先级进行分发与调度。通过与经典算法的对比,本研究算法完成率更平稳,且处理时间更短;但在单节点或任务数较少时计算资源消耗较大且实验数据量不大,这与实际应用的智能电网数据量存在差异,在性能方面还需进一步提升。
猜你喜欢
汽车维修与保养(2020年10期)2021-01-22
科学导报·学术(2020年26期)2020-10-21
汽车维修与保养(2020年11期)2020-06-09
小学生学习指导(低年级)(2020年4期)2020-06-02
软件(2020年3期)2020-04-20
数字通信世界(2020年3期)2020-04-06
制造技术与机床(2019年4期)2019-04-04
军营文化天地(2018年2期)2018-12-15
中南大学学报(自然科学版)(2018年7期)2018-08-08
现代防御技术(2016年1期)2016-06-01
